Monitoreo, Logging y Depuración
Configurar el monitoreo y el logging para solucionar problemas de un clúster o depurar una aplicación en contenedores.
A veces las cosas salen mal. Esta guía tiene como objetivo solucionarlas. Tiene
dos secciones:
- Depuración de tu aplicación - Útil
para usuarios que están implementando código en Kubernetes y se preguntan por qué no funciona.
- Depuración de tu clúster - Útil
para administradores de clústeres y personas cuyo clúster de Kubernetes no funciona correctamente.
También debe comprobar los problemas conocidos del release
usado.
Obteniendo Ayuda
Si ninguna de las guías anteriores resuelve su problema, existen varias formas de obtener ayuda de la comunidad de Kubernetes.
Preguntas
La documentación de este sitio ha sido estructurada para brindar respuestas a una amplia gama de preguntas. Conceptos explican la arquitectura de Kubernetes
y cómo funciona cada componente, mientras Configuración proporciona
instrucciones prácticas para empezar. Tareas muestran cómo
realizar tareas de uso común, y Tutoriales son recorridos más completos de escenarios de desarrollo reales, específicos de la industria o de extremo a extremo. La sección de Referencia proporciona
documentación detallada sobre el Kubernetes API
y las interfaces de línea de comandos (CLIs), tal como kubectl.
¡Ayuda! ¡Mi pregunta no está tratada! ¡Necesito ayuda ahora!
Stack Exchange, Stack Overflow o Server Fault
Si tienes preguntas relacionadas con desarrollo de software para tu aplicación en contenedores,
puedes preguntar en Stack Overflow.
Si tienes preguntas sobre Kubernetes relacionadas con administración de clústeres o configuración,
puedes preguntar en Server Fault.
También hay varios sitios de Stack Exchange que podrían ser el lugar adecuado para hacer preguntas sobre Kubernetes en áreas como
DevOps,
Ingeniería de Software,
o InfoSec.
Es posible que otra persona de la comunidad ya haya hecho una pregunta similar o
pueda ayudar con su problema.
El equipo de Kubernetes también monitoreará
publicaciones etiquetadas con Kubernetes.
Si no hay ninguna pregunta existente que te ayude, asegúrate de que tu pregunta
sea sobre el tema en Stack Overflow,
Server Fault, o el Stack Exchange
correcto en el que estás preguntando, y lee las instrucciones sobre
Cómo hacer una nueva pregunta,
antes de preguntar una nueva!
Slack
Muchas personas de la comunidad de Kubernetes se reúnen en Kubernetes Slack en el canal #kubernetes-users.
Slack requiere registro; puedes solicitar una invitación, el registro está abierto a todos. No dudes en participar y hacer todas y cada una de las preguntas.
Una vez registrado, ingresa a la Organización de Kubernetes en Slack
a través de tu navegador web o mediante la aplicación dedicada de Slack.
Una vez que estés registrado, explora la creciente lista de canales para diversos temas de
interés. Por ejemplo, las personas nuevas en Kubernetes también pueden querer unirse al canal
#kubernetes-novice. Como otro ejemplo, los desarrolladores deberían unirse al canal
#kubernetes-contributors.
También hay muchos canales en idiomas locales o específicos de cada país. Siéntete libre de unirte a
estos canales para obtener soporte e información localizados:
Foro
Te invitamos a unirte al Foro oficial de Kubernetes: discuss.kubernetes.io.
Bugs y solicitudes de funcionalidades
Si tienes lo que parece ser un error (bug) o deseas realizar una solicitud de funcionalidades,
por favor utiliza el sistema de seguimiento de asuntos en el GitHub.
Antes de presentar un problema, busca problemas existentes para ver si tu problema ya está cubierto.
Si presenta un error, incluya información detallada sobre cómo reproducir el
problema, como por ejemplo:
- Versión de Kubernetes:
kubectl version
- Proveedor de nube, distribución del sistema operativo, configuración de red y versión del contenedor runtime
- Pasos para reproducir el problema
1.1 - Depurar Contenedores de Inicialización
Esta página muestra cómo investigar problemas relacionados con la ejecución
de los contenedores de inicialización (init containers). Las líneas de comando del ejemplo de abajo
se refieren al Pod como <pod-name> y a los Init Containers como <init-container-1> e
<init-container-2> respectivamente.
Antes de empezar
Debes tener un cluster Kubernetes a tu dispocición, y la herramienta de línea de comandos kubectl debe estar configurada. Si no tienes un cluster, puedes crear uno utilizando Minikube,
o puedes utilizar una de las siguientes herramientas en línea:
Para comprobar la versión, introduzca
kubectl version.
Comprobar el estado de los Init Containers
Muestra el estado de tu pod:
kubectl get pod <pod-name>
Por ejemplo, un estado de Init:1/2 indica que uno de los Init Containers
se ha ejecutado satisfactoriamente:
NAME READY STATUS RESTARTS AGE
<pod-name> 0/1 Init:1/2 0 7s
Echa un vistazo a Comprender el estado de un Pod para más ejemplos
de valores de estado y sus significados.
Obtener detalles acerca de los Init Containers
Para ver información detallada acerca de la ejecución de un Init Container:
kubectl describe pod <pod-name>
Por ejemplo, un Pod con dos Init Containers podría mostrar lo siguiente:
Init Containers:
<init-container-1>:
Container ID: ...
...
State: Terminated
Reason: Completed
Exit Code: 0
Started: ...
Finished: ...
Ready: True
Restart Count: 0
...
<init-container-2>:
Container ID: ...
...
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: ...
Finished: ...
Ready: False
Restart Count: 3
...
También puedes acceder al estado del Init Container de forma programática mediante
la lectura del campo status.initContainerStatuses dentro del Pod Spec:
kubectl get pod nginx --template '{{.status.initContainerStatuses}}'
Este comando devolverá la misma información que arriba en formato JSON.
Acceder a los logs de los Init Containers
Indica el nombre del Init Container así como el nombre del Pod para
acceder a sus logs.
kubectl logs <pod-name> -c <init-container-2>
Los Init Containers que ejecutan secuencias de línea de comandos muestran los comandos
conforme se van ejecutando. Por ejemplo, puedes hacer lo siguiente en Bash
indicando set -x al principio de la secuencia.
Comprender el estado de un Pod
Un estado de un Pod que comienza con Init: especifica el estado de la ejecución de
un Init Container. La tabla a continuación muestra algunos valores de estado de ejemplo
que puedes encontrar al depurar Init Containers.
| Estado |
Significado |
Init:N/M |
El Pod tiene M Init Containers, y por el momento se han completado N. |
Init:Error |
Ha fallado la ejecución de un Init Container. |
Init:CrashLoopBackOff |
Un Init Container ha fallado de forma repetida. |
Pending |
El Pod todavía no ha comenzado a ejecutar sus Init Containers. |
PodInitializing o Running |
El Pod ya ha terminado de ejecutar sus Init Containers. |
2.1 - Auditoría
La auditoría de Kubernetes proporciona un conjunto de registros cronológicos referentes a la seguridad
que documentan la secuencia de actividades que tanto los usuarios individuales, como
los administradores y otros componentes del sistema ha realizado en el sistema.
Así, permite al administrador del clúster responder a las siguientes cuestiones:
- ¿qué ha pasado?
- ¿cuándo ha pasado?
- ¿quién lo ha iniciado?
- ¿sobre qué ha pasado?
- ¿dónde se ha observado?
- ¿desde dónde se ha iniciado?
- ¿hacia dónde iba?
El componente Kube-apiserver lleva a cabo la auditoría. Cada petición en cada fase
de su ejecución genera un evento, que se pre-procesa según un cierto reglamento y
se escribe en un backend. Este reglamento determina lo que se audita
y los backends persisten los registros. Las implementaciones actuales de backend
incluyen los archivos de logs y los webhooks.
Cada petición puede grabarse junto con una "etapa" asociada. Las etapas conocidas son:
RequestReceived - La etapa para aquellos eventos generados tan pronto como
el responsable de la auditoría recibe la petición, pero antes de que sea delegada al
siguiente responsable en la cadena.ResponseStarted - Una vez que las cabeceras de la respuesta se han enviado,
pero antes de que el cuerpo de la respuesta se envíe. Esta etapa sólo se genera
en peticiones de larga duración (ej. watch).ResponseComplete - El cuerpo de la respuesta se ha completado y no se enviarán más bytes.Panic - Eventos que se generan cuando ocurre una situación de pánico.
Nota:
La característica de registro de auditoría incrementa el consumo de memoria del servidor API
porque requiere de contexto adicional para lo que se audita en cada petición.
De forma adicional, el consumo de memoria depende de la configuración misma del registro.
Reglamento de Auditoría
El reglamento de auditoría define las reglas acerca de los eventos que deberían registrarse y
los datos que deberían incluir. La estructura del objeto de reglas de auditoría se define
en el audit.k8s.io grupo de API. Cuando se procesa un evento, se compara
con la lista de reglas en orden. La primera regla coincidente establece el "nivel de auditoría"
del evento. Los niveles de auditoría conocidos son:
None - no se registra eventos que disparan esta regla.Metadata - se registra los metadatos de la petición (usuario que la realiza, marca de fecha y hora, recurso,
verbo, etc.), pero no la petición ni el cuerpo de la respuesta.Request - se registra los metadatos del evento y el cuerpo de la petición, pero no el cuerpo de la respuesta.
Esto no aplica para las peticiones que no son de recurso.RequestResponse - se registra los metadatos del evento, y los cuerpos de la petición y la respuesta.
Esto no aplica para las peticiones que no son de recurso.
Es posible indicar un archivo al definir el reglamento en el kube-apiserver
usando el parámetro --audit-policy-file. Si dicho parámetros se omite, no se registra ningún evento.
Nótese que el campo rules debe proporcionarse en el archivo del reglamento de auditoría.
Un reglamento sin (0) reglas se considera ilegal.
Abajo se presenta un ejemplo de un archivo de reglamento de auditoría:
apiVersion: audit.k8s.io/v1 # Esto es obligatorio.
kind: Policy
# No generar eventos de auditoría para las peticiones en la etapa RequestReceived.
omitStages:
- "RequestReceived"
rules:
# Registrar los cambios del pod al nivel RequestResponse
- level: RequestResponse
resources:
- group: ""
# Los recursos "pods" no hacen coincidir las peticiones a cualquier sub-recurso de pods,
# lo que es consistente con la regla RBAC.
resources: ["pods"]
# Registrar "pods/log", "pods/status" al nivel Metadata
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# No registrar peticiones al configmap denominado "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# No registrar peticiones de observación hechas por "system:kube-proxy" sobre puntos de acceso o servicios
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # Grupo API base
resources: ["endpoints", "services"]
# No registrar peticiones autenticadas a ciertas rutas URL que no son recursos.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Coincidencia por comodín.
- "/version"
# Registrar el cuerpo de la petición de los cambios de configmap en kube-system.
- level: Request
resources:
- group: "" # Grupo API base
resources: ["configmaps"]
# Esta regla sólo aplica a los recursos en el Namespace "kube-system".
# La cadena vacía "" se puede usar para seleccionar los recursos sin Namespace.
namespaces: ["kube-system"]
# Registrar los cambios de configmap y secret en todos los otros Namespaces al nivel Metadata.
- level: Metadata
resources:
- group: "" # Grupo API base
resources: ["secrets", "configmaps"]
# Registrar todos los recursos en core y extensions al nivel Request.
- level: Request
resources:
- group: "" # Grupo API base
- group: "extensions" # La versión del grupo NO debería incluirse.
# Regla para "cazar" todos las demás peticiones al nivel Metadata.
- level: Metadata
# Las peticiones de larga duración, como los watches, que caen bajo esta regla no
# generan un evento de auditoría en RequestReceived.
omitStages:
- "RequestReceived"
Puedes usar un archivo mínimo de reglamento de auditoría para registrar todas las peticiones al nivel Metadata de la siguiente forma:
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata
El perfil de auditoría utilizado por GCE debería servir como referencia para
que los administradores construyeran sus propios perfiles de auditoría.
Backends de auditoría
Los backends de auditoría persisten los eventos de auditoría en un almacenamiento externo.
El Kube-apiserver por defecto proporciona tres backends:
- Backend de logs, que escribe los eventos en disco
- Backend de webhook, que envía los eventos a una API externa
- Backend dinámico, que configura backends de webhook a través de objetos de la API AuditSink.
En todos los casos, la estructura de los eventos de auditoría se define por la API del grupo
audit.k8s.io. La versión actual de la API es
v1.
Nota:
En el caso de parches, el cuerpo de la petición es una matriz JSON con operaciones de parcheado, en vez
de un objeto JSON que incluya el objeto de la API de Kubernetes apropiado. Por ejemplo,
el siguiente cuerpo de mensaje es una petición de parcheado válida para
/apis/batch/v1/namespaces/some-namespace/jobs/some-job-name.
[
{
"op": "replace",
"path": "/spec/parallelism",
"value": 0
},
{
"op": "remove",
"path": "/spec/template/spec/containers/0/terminationMessagePolicy"
}
]
Backend de Logs
El backend de logs escribe los eventos de auditoría a un archivo en formato JSON.
Puedes configurar el backend de logs de auditoría usando el siguiente
parámetro de kube-apiserver flags:
--audit-log-path especifica la ruta al archivo de log que el backend utiliza para
escribir los eventos de auditoría. Si no se especifica, se deshabilita el backend de logs. - significa salida estándar--audit-log-maxage define el máximo número de días a retener los archivos de log--audit-log-maxbackup define el máximo número de archivos de log a retener--audit-log-maxsize define el tamaño máximo en megabytes del archivo de logs antes de ser rotado
Backend de Webhook
El backend de Webhook envía eventos de auditoría a una API remota, que se supone es la misma API
que expone el kube-apiserver. Puedes configurar el backend de webhook de auditoría usando
los siguientes parámetros de kube-apiserver:
--audit-webhook-config-file especifica la ruta a un archivo con configuración del webhook.
La configuración del webhook es, de hecho, un archivo kubeconfig.--audit-webhook-initial-backoff especifica la cantidad de tiempo a esperar tras una petición fallida
antes de volver a intentarla. Los reintentos posteriores se ejecutan con retraso exponencial.
El archivo de configuración del webhook usa el formato kubeconfig para especificar la dirección remota
del servicio y las credenciales para conectarse al mismo.
En la versión 1.13, los backends de webhook pueden configurarse dinámicamente.
Procesamiento por lotes
Tanto el backend de logs como el de webhook permiten procesamiento por lotes. Si usamos el webhook como ejemplo,
aquí se muestra la lista de parámetros disponibles. Para aplicar el mismo parámetro al backend de logs,
simplemente sustituye webhook por log en el nombre del parámetro. Por defecto,
el procesimiento por lotes está habilitado en webhook y deshabilitado en log. De forma similar,
por defecto la regulación (throttling) está habilitada en webhook y deshabilitada en log.
--audit-webhook-mode define la estrategia de memoria intermedia (búfer), que puede ser una de las siguientes:
batch - almacenar eventos y procesarlos de forma asíncrona en lotes. Esta es la estrategia por defecto.blocking - bloquear todas las respuestas del servidor API al procesar cada evento de forma individual.blocking-strict - igual que blocking, pero si ocurre un error durante el registro de la audtoría en la etapa RequestReceived, la petición completa al apiserver fallará.
Los siguientes parámetros se usan únicamente en el modo batch:
--audit-webhook-batch-buffer-size define el número de eventos a almacenar de forma intermedia antes de procesar por lotes.
Si el ritmo de eventos entrantes desborda la memoria intermedia, dichos eventos se descartan.--audit-webhook-batch-max-size define el número máximo de eventos en un único proceso por lotes.--audit-webhook-batch-max-wait define la cantidad máxima de tiempo a esperar de forma incondicional antes de procesar los eventos de la cola.--audit-webhook-batch-throttle-qps define el promedio máximo de procesos por lote generados por segundo.--audit-webhook-batch-throttle-burst define el número máximo de procesos por lote generados al mismo tiempo si el QPS permitido no fue usado en su totalidad anteriormente.
Ajuste de parámetros
Los parámetros deberían ajustarse a la carga del apiserver.
Por ejemplo, si kube-apiserver recibe 100 peticiones por segundo, y para cada petición se audita
las etapas ResponseStarted y ResponseComplete, deberías esperar unos ~200
eventos de auditoría generados por segundo. Asumiendo que hay hasta 100 eventos en un lote,
deberías establecer el nivel de regulación (throttling) por lo menos a 2 QPS. Además, asumiendo
que el backend puede tardar hasta 5 segundos en escribir eventos, deberías configurar el tamaño de la memoria intermedia para almacenar hasta 5 segundos de eventos, esto es,
10 lotes, o sea, 1000 eventos.
En la mayoría de los casos, sin embargo, los valores por defecto de los parámetros
deberían ser suficientes y no deberías preocuparte de ajustarlos manualmente.
Puedes echar un vistazo a la siguientes métricas de Prometheus que expone kube-apiserver
y también los logs para monitorizar el estado del subsistema de auditoría:
apiserver_audit_event_total métrica que contiene el número total de eventos de auditoría exportados.apiserver_audit_error_total métrica que contiene el número total de eventos descartados debido a un error durante su exportación.
Truncado
Tanto el backend de logs como el de webhook permiten truncado. Como ejemplo, aquí se indica la
lista de parámetros disponible para el backend de logs:
audit-log-truncate-enabled indica si el truncado de eventos y por lotes está habilitado.audit-log-truncate-max-batch-size indica el tamaño máximo en bytes del lote enviado al backend correspondiente.audit-log-truncate-max-event-size indica el tamaño máximo en bytes del evento de auditoría enviado al backend correspondiente.
Por defecto, el truncado está deshabilitado tanto en webhook como en log; un administrador del clúster debe configurar bien el parámetro audit-log-truncate-enabled o audit-webhook-truncate-enabled para habilitar esta característica.
Backend dinámico
FEATURE STATE:
Kubernetes v1.13 [alpha]
En la versión 1.13 de Kubernetes, puedes configurar de forma dinámica los backends de auditoría usando objetos de la API AuditSink.
Para habilitar la auditoría dinámica, debes configurar los siguientes parámetros de apiserver:
--audit-dynamic-configuration: el interruptor principal. Cuando esta característica sea GA, el único parámetro necesario.--feature-gates=DynamicAuditing=true: en evaluación en alpha y beta.--runtime-config=auditregistration.k8s.io/v1alpha1=true: habilitar la API.
Cuando se habilita, un objeto AuditSink se provisiona de la siguiente forma:
apiVersion: auditregistration.k8s.io/v1alpha1
kind: AuditSink
metadata:
name: mysink
spec:
policy:
level: Metadata
stages:
- ResponseComplete
webhook:
throttle:
qps: 10
burst: 15
clientConfig:
url: "https://audit.app"
Para una definición completa de la API, ver AuditSink. Múltiples objetos existirán como soluciones independientes.
Aquellos backends estáticos que se configuran con parámetros en tiempo de ejecución no se ven impactados por esta característica.
Sin embargo, estos backends dinámicos comparten las opciones de truncado del webhook estático, de forma que si dichas opciones se configura con parámetros en tiempo de ejecución, entonces se aplican a todos los backends dinámicos.
Reglamento
El reglamento de AuditSink es diferente del de la auditoría en tiempo de ejecución. Esto es debido a que el objeto de la API sirve para casos de uso diferentes. El reglamento continuará
evolucionando para dar cabida a más casos de uso.
El campo level establece el nivel de auditoría indicado a todas las peticiones. El campo stages es actualmente una lista de las etapas que se permite registrar.
Seguridad
Los administradores deberían tener en cuenta que permitir el acceso en modo escritura de esta característica otorga el modo de acceso de lectura
a toda la información del clúster. Así, el acceso debería gestionarse como un privilegio de nivel cluster-admin.
Rendimiento
Actualmente, esta característica tiene implicaciones en el apiserver en forma de incrementos en el uso de la CPU y la memoria.
Aunque debería ser nominal cuando se trata de un número pequeño de destinos, se realizarán pruebas adicionales de rendimiento para entender su impacto real antes de que esta API pase a beta.
Configuración multi-clúster
Si estás extendiendo la API de Kubernetes mediante la capa de agregación, puedes también
configurar el registro de auditoría para el apiserver agregado. Para ello, pasa las opciones
de configuración en el mismo formato que se describe arriba al apiserver agregado
y configura el mecanismo de ingestión de logs para que recolecte los logs de auditoría.
Cada uno de los apiservers puede tener configuraciones de auditoría diferentes con
diferentes reglamentos de auditoría.
Ejemplos de recolectores de Logs
Uso de fluentd para recolectar y distribuir eventos de auditoría a partir de un archivo de logs
Fluentd es un recolector de datos de libre distribución que proporciona una capa unificada de registros.
En este ejemplo, usaremos fluentd para separar los eventos de auditoría por nombres de espacio:
-
Instala fluentd, fluent-plugin-forest y fluent-plugin-rewrite-tag-filter en el nodo donde corre kube-apiserver
Nota:
Fluent-plugin-forest y fluent-plugin-rewrite-tag-filter son plugins de fluentd. Puedes obtener detalles de la instalación de estos plugins en el documento [fluentd plugin-management][fluentd_plugin_management_doc].
-
Crea un archivo de configuración para fluentd:
cat <<'EOF' > /etc/fluentd/config
# fluentd conf runs in the same host with kube-apiserver
<source>
@type tail
# audit log path of kube-apiserver
path /var/log/kube-audit
pos_file /var/log/audit.pos
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%N%z
tag audit
</source>
<filter audit>
#https://github.com/fluent/fluent-plugin-rewrite-tag-filter/issues/13
@type record_transformer
enable_ruby
<record>
namespace ${record["objectRef"].nil? ? "none":(record["objectRef"]["namespace"].nil? ? "none":record["objectRef"]["namespace"])}
</record>
</filter>
<match audit>
# route audit according to namespace element in context
@type rewrite_tag_filter
<rule>
key namespace
pattern /^(.+)/
tag ${tag}.$1
</rule>
</match>
<filter audit.**>
@type record_transformer
remove_keys namespace
</filter>
<match audit.**>
@type forest
subtype file
remove_prefix audit
<template>
time_slice_format %Y%m%d%H
compress gz
path /var/log/audit-${tag}.*.log
format json
include_time_key true
</template>
</match>
EOF
-
Arranca fluentd:
fluentd -c /etc/fluentd/config -vv
-
Arranca el componente kube-apiserver con las siguientes opciones:
--audit-policy-file=/etc/kubernetes/audit-policy.yaml --audit-log-path=/var/log/kube-audit --audit-log-format=json
-
Comprueba las auditorías de los distintos espacios de nombres en /var/log/audit-*.log
Uso de logstash para recolectar y distribuir eventos de auditoría desde un backend de webhook
Logstash es una herramienta de libre distribución de procesamiento de datos en servidor.
En este ejemplo, vamos a usar logstash para recolectar eventos de auditoría a partir de un backend de webhook,
y grabar los eventos de usuarios diferentes en archivos distintos.
-
Instala logstash
-
Crea un archivo de configuración para logstash:
cat <<EOF > /etc/logstash/config
input{
http{
#TODO, figure out a way to use kubeconfig file to authenticate to logstash
#https://www.elastic.co/guide/en/logstash/current/plugins-inputs-http.html#plugins-inputs-http-ssl
port=>8888
}
}
filter{
split{
# Webhook audit backend sends several events together with EventList
# split each event here.
field=>[items]
# We only need event subelement, remove others.
remove_field=>[headers, metadata, apiVersion, "@timestamp", kind, "@version", host]
}
mutate{
rename => {items=>event}
}
}
output{
file{
# Audit events from different users will be saved into different files.
path=>"/var/log/kube-audit-%{[event][user][username]}/audit"
}
}
EOF
-
Arranca logstash:
bin/logstash -f /etc/logstash/config --path.settings /etc/logstash/
-
Crea un archivo kubeconfig para el webhook del backend de auditoría de kube-apiserver:
cat <<EOF > /etc/kubernetes/audit-webhook-kubeconfig
apiVersion: v1
clusters:
- cluster:
server: http://<ip_of_logstash>:8888
name: logstash
contexts:
- context:
cluster: logstash
user: ""
name: default-context
current-context: default-context
kind: Config
preferences: {}
users: []
EOF
-
Arranca kube-apiserver con las siguientes opciones:
--audit-policy-file=/etc/kubernetes/audit-policy.yaml --audit-webhook-config-file=/etc/kubernetes/audit-webhook-kubeconfig
-
Comprueba las auditorías en los directorios /var/log/kube-audit-*/audit de los nodos de logstash
Nótese que además del plugin para salida en archivos, logstash ofrece una variedad de salidas adicionales
que permiten a los usuarios enviar la información donde necesiten. Por ejemplo, se puede enviar los eventos de auditoría
al plugin de elasticsearch que soporta búsquedas avanzadas y analíticas.
2.2 - Escribiendo Logs con Elasticsearch y Kibana
En la plataforma Google Compute Engine (GCE), por defecto da soporte a la escritura de logs haciendo uso de
Stackdriver Logging, el cual se describe en detalle en Logging con Stackdriver Logging.
Este artículo describe cómo configurar un clúster para la ingesta de logs en
Elasticsearch y su posterior visualización
con Kibana, a modo de alternativa a
Stackdriver Logging cuando se utiliza la plataforma GCE.
Nota:
No se puede desplegar de forma automática Elasticsearch o Kibana en un clúster alojado en Google Kubernetes Engine. Hay que desplegarlos de forma manual.
Para utilizar Elasticsearch y Kibana para escritura de logs del clúster, deberías configurar
la siguiente variable de entorno que se muestra a continuación como parte de la creación
del clúster con kube-up.sh:
KUBE_LOGGING_DESTINATION=elasticsearch
También deberías asegurar que KUBE_ENABLE_NODE_LOGGING=true (que es el valor por defecto en la plataforma GCE).
Así, cuando crees un clúster, un mensaje te indicará que la recolección de logs de los daemons de Fluentd
que corren en cada nodo enviará dichos logs a Elasticsearch:
...
Project: kubernetes-satnam
Zone: us-central1-b
... calling kube-up
Project: kubernetes-satnam
Zone: us-central1-b
+++ Staging server tars to Google Storage: gs://kubernetes-staging-e6d0e81793/devel
+++ kubernetes-server-linux-amd64.tar.gz uploaded (sha1 = 6987c098277871b6d69623141276924ab687f89d)
+++ kubernetes-salt.tar.gz uploaded (sha1 = bdfc83ed6b60fa9e3bff9004b542cfc643464cd0)
Looking for already existing resources
Starting master and configuring firewalls
Created [https://www.googleapis.com/compute/v1/projects/kubernetes-satnam/zones/us-central1-b/disks/kubernetes-master-pd].
NAME ZONE SIZE_GB TYPE STATUS
kubernetes-master-pd us-central1-b 20 pd-ssd READY
Created [https://www.googleapis.com/compute/v1/projects/kubernetes-satnam/regions/us-central1/addresses/kubernetes-master-ip].
+++ Logging using Fluentd to elasticsearch
Tanto los pods por nodo de Fluentd, como los pods de Elasticsearch, y los pods de Kibana
deberían ejecutarse en el namespace de kube-system inmediatamente después
de que el clúster esté disponible.
kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-v1-78nog 1/1 Running 0 2h
elasticsearch-logging-v1-nj2nb 1/1 Running 0 2h
fluentd-elasticsearch-kubernetes-node-5oq0 1/1 Running 0 2h
fluentd-elasticsearch-kubernetes-node-6896 1/1 Running 0 2h
fluentd-elasticsearch-kubernetes-node-l1ds 1/1 Running 0 2h
fluentd-elasticsearch-kubernetes-node-lz9j 1/1 Running 0 2h
kibana-logging-v1-bhpo8 1/1 Running 0 2h
kube-dns-v3-7r1l9 3/3 Running 0 2h
monitoring-heapster-v4-yl332 1/1 Running 1 2h
monitoring-influx-grafana-v1-o79xf 2/2 Running 0 2h
Los pods de fluentd-elasticsearch recogen los logs de cada nodo y los envían a los
pods de elasticsearch-logging, que son parte de un servicio llamado elasticsearch-logging.
Estos pods de Elasticsearch almacenan los logs y los exponen via una API REST.
El pod de kibana-logging proporciona una UI via web donde leer los logs almacenados en
Elasticsearch, y es parte de un servicio denominado kibana-logging.
Los servicios de Elasticsearch y Kibana ambos están en el namespace kube-system
y no se exponen de forma directa mediante una IP accesible públicamente. Para poder acceder a dichos logs,
sigue las instrucciones acerca de cómo Acceder a servicios corriendo en un clúster.
Si tratas de acceder al servicio de elasticsearch-logging desde tu navegador,
verás una página de estado que se parece a la siguiente:
A partir de ese momento, puedes introducir consultas de Elasticsearch directamente en el navegador, si lo necesitas.
Echa un vistazo a la documentación de Elasticsearch
para más detalles acerca de cómo hacerlo.
De forma alternativa, puedes ver los logs de tu clúster en Kibana (de nuevo usando las
instrucciones para acceder a un servicio corriendo en un clúster).
La primera vez que visitas la URL de Kibana se te presentará una página que te pedirá
que configures una vista de los logs. Selecciona la opción de valores de serie temporal
y luego @timestamp. En la página siguiente selecciona la pestaña de Discover
y entonces deberías ver todos los logs. Puedes establecer el intervalo de actualización
en 5 segundos para refrescar los logs de forma regular.
Aquí se muestra una vista típica de logs desde el visor de Kibana:
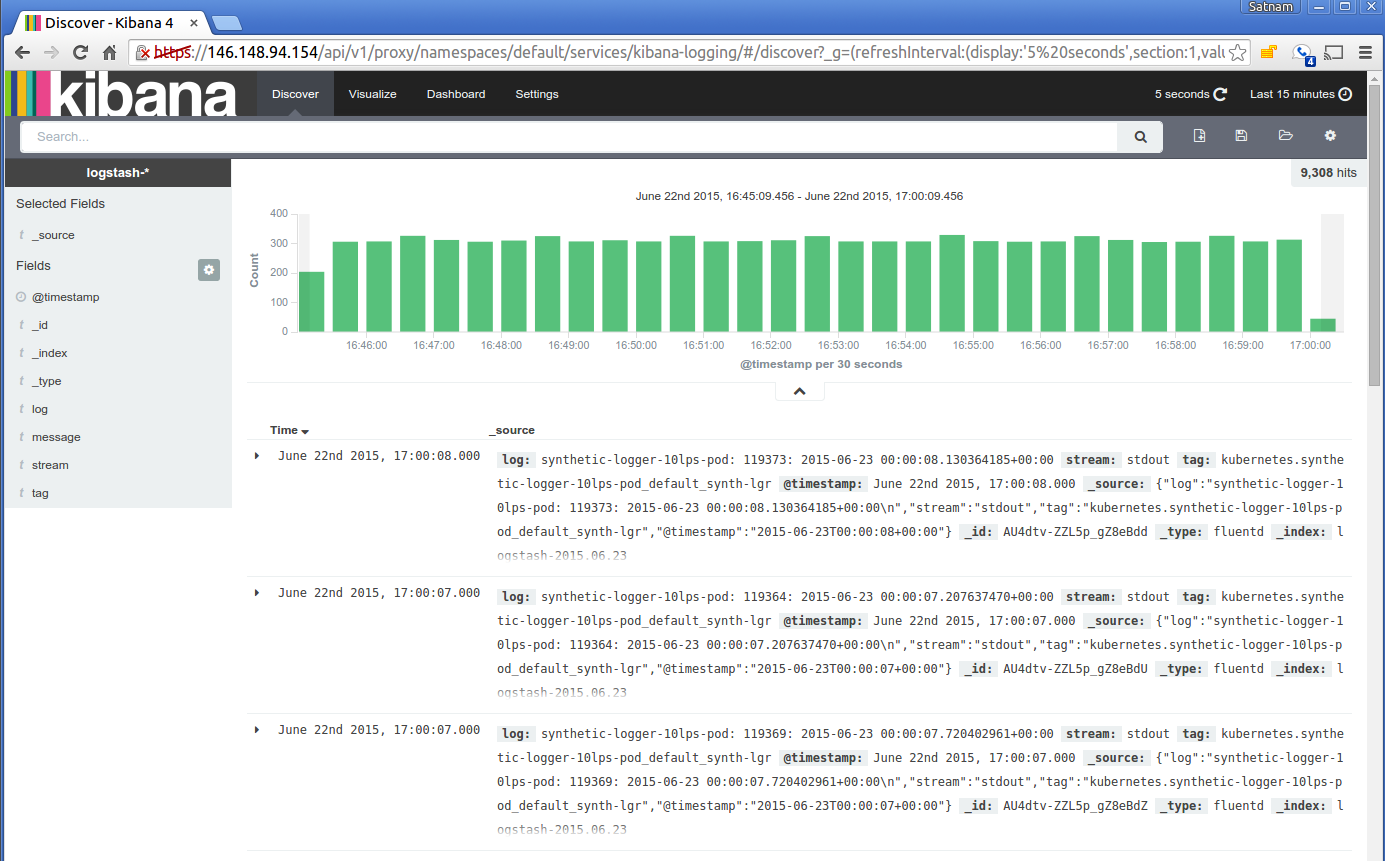
Siguientes pasos
¡Kibana te permite todo tipo de potentes opciones para explorar tus logs! Puedes encontrar
algunas ideas para profundizar en el tema en la documentación de Kibana.
2.3 - Pipeline de métricas de recursos
Desde Kubernetes 1.8, las métricas de uso de recursos, tales como el uso de CPU y memoria del contenedor,
están disponibles en Kubernetes a través de la API de métricas. Estas métricas son accedidas directamente
por el usuario, por ejemplo usando el comando kubectl top, o usadas por un controlador en el cluster,
por ejemplo el Horizontal Pod Autoscaler, para la toma de decisiones.
La API de Métricas
A través de la API de métricas, Metrics API en inglés, puedes obtener la cantidad de recursos usados
actualmente por cada nodo o pod. Esta API no almacena los valores de las métricas,
así que no es posible, por ejemplo, obtener la cantidad de recursos que fueron usados por
un nodo hace 10 minutos.
La API de métricas está completamente integrada en la API de Kubernetes:
- se expone a través del mismo endpoint que las otras APIs de Kubernetes bajo el path
/apis/metrics.k8s.io/
- ofrece las mismas garantías de seguridad, escalabilidad y confiabilidad
La API está definida en el repositorio k8s.io/metrics. Puedes encontrar
más información sobre la API ahí.
Nota:
La API requiere que el servidor de métricas esté desplegado en el clúster. En otro caso no estará
disponible.
Servidor de Métricas
El Servidor de Métricas es un agregador
de datos de uso de recursos de todo el clúster.
A partir de Kubernetes 1.8, el servidor de métricas se despliega por defecto como un objeto de
tipo Deployment en clústeres
creados con el script kube-up.sh. Si usas otro mecanismo de configuración de Kubernetes, puedes desplegarlo
usando los yamls de despliegue
proporcionados. Está soportado a partir de Kubernetes 1.7 (más detalles al final).
El servidor reune métricas de la Summary API, que es expuesta por el Kubelet en cada nodo.
El servidor de métricas se añadió a la API de Kubernetes utilizando el
Kubernetes aggregator introducido en Kubernetes 1.7.
Puedes aprender más acerca del servidor de métricas en el documento de diseño.