개념 섹션을 통해 쿠버네티스 시스템을 구성하는 요소와 클러스터를 표현하는데 사용되는 추상 개념에 대해 배우고 쿠버네티스가 작동하는 방식에 대해 보다 깊이 이해할 수 있다.
이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
개념
- 1: 쿠버네티스란 무엇인가?
- 1.1: 쿠버네티스 컴포넌트
- 1.2: 쿠버네티스 API
- 1.3: 쿠버네티스 오브젝트로 작업하기
- 1.3.1: 쿠버네티스 오브젝트 이해하기
- 1.3.2: 쿠버네티스 오브젝트 관리
- 1.3.3: 오브젝트 이름과 ID
- 1.3.4: 레이블과 셀렉터
- 1.3.5: 네임스페이스
- 1.3.6: 어노테이션
- 1.3.7: 필드 셀렉터
- 1.3.8: 파이널라이저
- 1.3.9: 권장 레이블
- 2: 클러스터 아키텍처
- 2.1: 노드
- 2.2: 컨트롤 플레인-노드 간 통신
- 2.3: 리스(Lease)
- 2.4: 컨트롤러
- 2.5: 클라우드 컨트롤러 매니저
- 2.6: 컨테이너 런타임 인터페이스(CRI)
- 2.7: 가비지(Garbage) 수집
- 3: 컨테이너
- 3.1: 이미지
- 3.2: 컨테이너 환경 변수
- 3.3: 런타임클래스(RuntimeClass)
- 3.4: 컨테이너 라이프사이클 훅(Hook)
- 4: 쿠버네티스에서의 윈도우
- 5: 워크로드
- 5.1: 파드
- 5.1.1: 파드 라이프사이클
- 5.1.2: 초기화 컨테이너
- 5.1.3: 중단(disruption)
- 5.1.4: 임시(Ephemeral) 컨테이너
- 5.1.5: 사용자 네임스페이스
- 5.1.6: 다운워드(Downward) API
- 5.2: 워크로드 리소스
- 5.2.1: 디플로이먼트
- 5.2.2: 레플리카셋
- 5.2.3: 스테이트풀셋
- 5.2.4: 데몬셋
- 5.2.5: 잡
- 5.2.6: 완료된 잡 자동 정리
- 5.2.7: 크론잡
- 5.2.8: 레플리케이션 컨트롤러
- 6: 서비스, 로드밸런싱, 네트워킹
- 6.1: 서비스
- 6.2: 인그레스(Ingress)
- 6.3: 인그레스 컨트롤러
- 6.4: 엔드포인트슬라이스
- 6.5: 네트워크 정책
- 6.6: 서비스 및 파드용 DNS
- 6.7: IPv4/IPv6 이중 스택
- 6.8: 토폴로지 인지 힌트
- 6.9: 윈도우에서의 네트워킹
- 6.10: 서비스 내부 트래픽 정책
- 6.11: 서비스 클러스터IP 할당
- 6.12: 토폴로지 키를 사용하여 토폴로지-인지 트래픽 라우팅
- 7: 스토리지
- 7.1: 볼륨
- 7.2: 퍼시스턴트 볼륨
- 7.3: 프로젝티드 볼륨
- 7.4: 임시 볼륨
- 7.5: 스토리지 클래스
- 7.6: 동적 볼륨 프로비저닝
- 7.7: 볼륨 스냅샷
- 7.8: 볼륨 스냅샷 클래스
- 7.9: CSI 볼륨 복제하기
- 7.10: 스토리지 용량
- 7.11: 노드 별 볼륨 한도
- 7.12: 볼륨 헬스 모니터링
- 7.13: 윈도우 스토리지
- 8: 구성
- 8.1: 구성 모범 사례
- 8.2: 컨피그맵(ConfigMap)
- 8.3: 시크릿(Secret)
- 8.4: 파드 및 컨테이너 리소스 관리
- 8.5: kubeconfig 파일을 사용하여 클러스터 접근 구성하기
- 8.6: 윈도우 노드의 자원 관리
- 9: 보안
- 9.1: 클라우드 네이티브 보안 개요
- 9.2: 파드 시큐리티 스탠다드
- 9.3: 파드 시큐리티 어드미션
- 9.4: 파드 시큐리티 폴리시
- 9.5: 윈도우 노드에서의 보안
- 9.6: 쿠버네티스 API 접근 제어하기
- 9.7: 역할 기반 접근 제어 (RBAC) 모범 사례
- 9.8: 쿠버네티스 시크릿 모범 사례
- 9.9: 멀티 테넌시(multi-tenancy)
- 10: 정책
- 10.1: 리밋 레인지(Limit Range)
- 10.2: 리소스 쿼터
- 10.3: 프로세스 ID 제한 및 예약
- 10.4: 노드 리소스 매니저
- 11: 스케줄링, 선점(Preemption), 축출(Eviction)
- 11.1: 쿠버네티스 스케줄러
- 11.2: 노드에 파드 할당하기
- 11.3: 파드 오버헤드
- 11.4: 파드 스케줄링 준비성(readiness)
- 11.5: 파드 토폴로지 분배 제약 조건
- 11.6: 테인트(Taints)와 톨러레이션(Tolerations)
- 11.7: 스케줄러 성능 튜닝
- 11.8: 리소스 빈 패킹(bin packing)
- 11.9: 파드 우선순위(priority)와 선점(preemption)
- 11.10: 노드-압박 축출
- 11.11: API를 이용한 축출(API-initiated Eviction)
- 12: 클러스터 관리
- 12.1: 인증서
- 12.2: 리소스 관리
- 12.3: 클러스터 네트워킹
- 12.4: 로깅 아키텍처
- 12.5: 쿠버네티스 시스템 컴포넌트에 대한 메트릭
- 12.6: 시스템 로그
- 12.7: 쿠버네티스 시스템 컴포넌트에 대한 추적(trace)
- 12.8: 쿠버네티스에서 프락시(Proxy)
- 12.9: 애드온 설치
- 13: 쿠버네티스 확장
- 13.1: 오퍼레이터(operator) 패턴
- 13.2: 컴퓨트, 스토리지 및 네트워킹 익스텐션
- 13.3: 쿠버네티스 API 확장하기
- 13.3.1: 커스텀 리소스
- 13.3.2: 쿠버네티스 API 애그리게이션 레이어(aggregation layer)
1 - 쿠버네티스란 무엇인가?
쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식할 수 있고, 확장 가능한 오픈소스 플랫폼으로, 선언적 구성과 자동화를 모두 지원한다. 쿠버네티스는 크고 빠르게 성장하는 생태계를 가지고 있다. 쿠버네티스 서비스, 지원 그리고 도구들은 광범위하게 제공된다.
이 페이지에서는 쿠버네티스 개요를 설명한다.
쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식성이 있고, 확장가능한 오픈소스 플랫폼이다. 쿠버네티스는 선언적 구성과 자동화를 모두 용이하게 해준다. 쿠버네티스는 크고, 빠르게 성장하는 생태계를 가지고 있다. 쿠버네티스 서비스, 기술 지원 및 도구는 어디서나 쉽게 이용할 수 있다.
쿠버네티스란 명칭은 키잡이(helmsman)나 파일럿을 뜻하는 그리스어에서 유래했다. K8s라는 표기는 "K"와 "s"와 그 사이에 있는 8글자를 나타내는 약식 표기이다. 구글이 2014년에 쿠버네티스 프로젝트를 오픈소스화했다. 쿠버네티스는 프로덕션 워크로드를 대규모로 운영하는 15년 이상의 구글 경험과 커뮤니티의 최고의 아이디어와 적용 사례가 결합되어 있다.
여정 돌아보기
시간이 지나면서 쿠버네티스가 왜 유용하게 되었는지 살펴보자.

전통적인 배포 시대: 초기 조직은 애플리케이션을 물리 서버에서 실행했었다. 한 물리 서버에서 여러 애플리케이션의 리소스 한계를 정의할 방법이 없었기에, 리소스 할당의 문제가 발생했다. 예를 들어 물리 서버 하나에서 여러 애플리케이션을 실행하면, 리소스 전부를 차지하는 애플리케이션 인스턴스가 있을 수 있고, 결과적으로는 다른 애플리케이션의 성능이 저하될 수 있었다. 이에 대한 해결책으로 서로 다른 여러 물리 서버에서 각 애플리케이션을 실행할 수도 있다. 그러나 이는 리소스가 충분히 활용되지 않는다는 점에서 확장 가능하지 않았으며, 조직이 많은 물리 서버를 유지하는 데에 높은 비용이 들었다.
가상화된 배포 시대: 그 해결책으로 가상화가 도입되었다. 이는 단일 물리 서버의 CPU에서 여러 가상 시스템 (VM)을 실행할 수 있게 한다. 가상화를 사용하면 VM간에 애플리케이션을 격리하고 애플리케이션의 정보를 다른 애플리케이션에서 자유롭게 액세스할 수 없으므로, 일정 수준의 보안성을 제공할 수 있다.
가상화를 사용하면 물리 서버에서 리소스를 보다 효율적으로 활용할 수 있으며, 쉽게 애플리케이션을 추가하거나 업데이트할 수 있고 하드웨어 비용을 절감할 수 있어 더 나은 확장성을 제공한다. 가상화를 통해 일련의 물리 리소스를 폐기 가능한(disposable) 가상 머신으로 구성된 클러스터로 만들 수 있다.
각 VM은 가상화된 하드웨어 상에서 자체 운영체제를 포함한 모든 구성 요소를 실행하는 하나의 완전한 머신이다.
컨테이너 개발 시대: 컨테이너는 VM과 유사하지만 격리 속성을 완화하여 애플리케이션 간에 운영체제(OS)를 공유한다. 그러므로 컨테이너는 가볍다고 여겨진다. VM과 마찬가지로 컨테이너에는 자체 파일 시스템, CPU 점유율, 메모리, 프로세스 공간 등이 있다. 기본 인프라와의 종속성을 끊었기 때문에, 클라우드나 OS 배포본에 모두 이식할 수 있다.
컨테이너는 다음과 같은 추가적인 혜택을 제공하기 때문에 유명해졌다.
- 기민한 애플리케이션 생성과 배포: VM 이미지를 사용하는 것에 비해 컨테이너 이미지 생성이 보다 쉽고 효율적이다.
- 지속적인 개발, 통합 및 배포: 안정적이고 주기적으로 컨테이너 이미지를 빌드해서 배포할 수 있고 (이미지의 불변성 덕에) 빠르고 효율적으로 롤백할 수 있다.
- 개발과 운영의 관심사 분리: 배포 시점이 아닌 빌드/릴리스 시점에 애플리케이션 컨테이너 이미지를 만들기 때문에, 애플리케이션이 인프라스트럭처에서 분리된다.
- 가시성(observability): OS 수준의 정보와 메트릭에 머무르지 않고, 애플리케이션의 헬스와 그 밖의 시그널을 볼 수 있다.
- 개발, 테스팅 및 운영 환경에 걸친 일관성: 랩탑에서도 클라우드에서와 동일하게 구동된다.
- 클라우드 및 OS 배포판 간 이식성: Ubuntu, RHEL, CoreOS, 온-프레미스, 주요 퍼블릭 클라우드와 어디에서든 구동된다.
- 애플리케이션 중심 관리: 가상 하드웨어 상에서 OS를 실행하는 수준에서 논리적인 리소스를 사용하는 OS 상에서 애플리케이션을 실행하는 수준으로 추상화 수준이 높아진다.
- 느슨하게 커플되고, 분산되고, 유연하며, 자유로운 마이크로서비스: 애플리케이션은 단일 목적의 머신에서 모놀리식 스택으로 구동되지 않고
보다 작고 독립적인 단위로 쪼개져서 동적으로 배포되고 관리될 수 있다.
- 리소스 격리: 애플리케이션 성능을 예측할 수 있다.
- 리소스 사용량: 고효율 고집적.
쿠버네티스가 왜 필요하고 무엇을 할 수 있나
컨테이너는 애플리케이션을 포장하고 실행하는 좋은 방법이다. 프로덕션 환경에서는 애플리케이션을 실행하는 컨테이너를 관리하고 가동 중지 시간이 없는지 확인해야 한다. 예를 들어 컨테이너가 다운되면 다른 컨테이너를 다시 시작해야 한다. 이 문제를 시스템에 의해 처리한다면 더 쉽지 않을까?
그것이 쿠버네티스가 필요한 이유이다! 쿠버네티스는 분산 시스템을 탄력적으로 실행하기 위한 프레임 워크를 제공한다. 애플리케이션의 확장과 장애 조치를 처리하고, 배포 패턴 등을 제공한다. 예를 들어, 쿠버네티스는 시스템의 카나리아 배포를 쉽게 관리할 수 있다.
쿠버네티스는 다음을 제공한다.
- 서비스 디스커버리와 로드 밸런싱 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
- 스토리지 오케스트레이션 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재할 수 있다
- 자동화된 롤아웃과 롤백 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
- 자동화된 빈 패킹(bin packing) 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
- 자동화된 복구(self-healing) 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
- 시크릿과 구성 관리 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트할 수 있다.
쿠버네티스가 아닌 것
쿠버네티스는 전통적인, 모든 것이 포함된 Platform as a Service(PaaS)가 아니다. 쿠버네티스는 하드웨어 수준보다는 컨테이너 수준에서 운영되기 때문에, PaaS가 일반적으로 제공하는 배포, 스케일링, 로드 밸런싱과 같은 기능을 제공하며, 사용자가 로깅, 모니터링 및 알림 솔루션을 통합할 수 있다. 하지만, 쿠버네티스는 모놀리식(monolithic)이 아니어서, 이런 기본 솔루션이 선택적이며 추가나 제거가 용이하다. 쿠버네티스는 개발자 플랫폼을 만드는 구성 요소를 제공하지만, 필요한 경우 사용자의 선택권과 유연성을 지켜준다.
쿠버네티스는:
- 지원하는 애플리케이션의 유형을 제약하지 않는다. 쿠버네티스는 상태 유지가 필요 없는(stateless) 워크로드, 상태 유지가 필요한(stateful) 워크로드, 데이터 처리를 위한 워크로드를 포함해서 극단적으로 다양한 워크로드를 지원하는 것을 목표로 한다. 애플리케이션이 컨테이너에서 구동될 수 있다면, 쿠버네티스에서도 잘 동작할 것이다.
- 소스 코드를 배포하지 않으며 애플리케이션을 빌드하지 않는다. 지속적인 통합과 전달과 배포, 곧 CI/CD 워크플로우는 조직 문화와 취향에 따를 뿐만 아니라 기술적인 요구사항으로 결정된다.
- 애플리케이션 레벨의 서비스를 제공하지 않는다. 애플리케이션 레벨의 서비스에는 미들웨어(예, 메시지 버스), 데이터 처리 프레임워크(예, Spark), 데이터베이스(예, MySQL), 캐시 또는 클러스터 스토리지 시스템(예, Ceph) 등이 있다. 이런 컴포넌트는 쿠버네티스 상에서 구동될 수 있고, 쿠버네티스 상에서 구동 중인 애플리케이션이 Open Service Broker와 같은 이식 가능한 메커니즘을 통해 접근할 수도 있다.
- 로깅, 모니터링 또는 경보 솔루션을 포함하지 않는다. 개념 증명을 위한 일부 통합이나, 메트릭을 수집하고 노출하는 메커니즘을 제공한다.
- 기본 설정 언어/시스템(예, Jsonnet)을 제공하거나 요구하지 않는다. 선언적 명세의 임의적인 형식을 목적으로 하는 선언적 API를 제공한다.
- 포괄적인 머신 설정, 유지보수, 관리, 자동 복구 시스템을 제공하거나 채택하지 않는다.
- 추가로, 쿠버네티스는 단순한 오케스트레이션 시스템이 아니다. 사실, 쿠버네티스는 오케스트레이션의 필요성을 없애준다. 오케스트레이션의 기술적인 정의는 A를 먼저 한 다음, B를 하고, C를 하는 것과 같이 정의된 워크플로우를 수행하는 것이다. 반면에, 쿠버네티스는 독립적이고 조합 가능한 제어 프로세스들로 구성되어 있다. 이 프로세스는 지속적으로 현재 상태를 입력받은 의도한 상태로 나아가도록 한다. A에서 C로 어떻게 갔는지는 상관이 없다. 중앙화된 제어도 필요치 않다. 이로써 시스템이 보다 더 사용하기 쉬워지고, 강력해지며, 견고하고, 회복력을 갖추게 되며, 확장 가능해진다.
다음 내용
- 쿠버네티스 구성요소 살펴보기
- 쿠버네티스 API 살펴보기
- 클러스터 아키텍처 살펴보기
- 시작할 준비가 되었는가?
1.1 - 쿠버네티스 컴포넌트
쿠버네티스 클러스터는 컴퓨터 집합인 노드 컴포넌트와 컨트롤 플레인 컴포넌트로 구성된다.
쿠버네티스를 배포하면 클러스터를 얻는다.
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드라고 하는 워커 머신의 집합. 모든 클러스터는 최소 한 개의 워커 노드를 가진다.
워커 노드는 애플리케이션의 구성요소인 파드를 호스트한다. 컨트롤 플레인은 워커 노드와 클러스터 내 파드를 관리한다. 프로덕션 환경에서는 일반적으로 컨트롤 플레인이 여러 컴퓨터에 걸쳐 실행되고, 클러스터는 일반적으로 여러 노드를 실행하므로 내결함성과 고가용성이 제공된다.
이 문서는 완전히 작동하는 쿠버네티스 클러스터를 갖기 위해 필요한 다양한 컴포넌트들에 대해 요약하고 정리한다.

쿠버네티스 클러스터 구성 요소
컨트롤 플레인 컴포넌트
컨트롤 플레인 컴포넌트는 클러스터에 관한 전반적인 결정(예를 들어, 스케줄링)을 수행하고 클러스터 이벤트(예를 들어, 디플로이먼트의 replicas 필드에 대한 요구 조건이 충족되지 않을 경우 새로운 파드를 구동시키는 것)를 감지하고 반응한다.
컨트롤 플레인 컴포넌트는 클러스터 내 어떠한 머신에서든지 동작할 수 있다. 그러나 간결성을 위하여, 구성 스크립트는 보통 동일 머신 상에 모든 컨트롤 플레인 컴포넌트를 구동시키고, 사용자 컨테이너는 해당 머신 상에 동작시키지 않는다. 여러 머신에서 실행되는 컨트롤 플레인 설정의 예제를 보려면 kubeadm을 사용하여 고가용성 클러스터 만들기를 확인해본다.
kube-apiserver
API 서버는 쿠버네티스 API를 노출하는 쿠버네티스 컨트롤 플레인 컴포넌트이다. API 서버는 쿠버네티스 컨트롤 플레인의 프론트 엔드이다.
쿠버네티스 API 서버의 주요 구현은 kube-apiserver 이다. kube-apiserver는 수평으로 확장되도록 디자인되었다. 즉, 더 많은 인스턴스를 배포해서 확장할 수 있다. 여러 kube-apiserver 인스턴스를 실행하고, 인스턴스간의 트래픽을 균형있게 조절할 수 있다.
etcd
모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소.
쿠버네티스 클러스터에서 etcd를 뒷단의 저장소로 사용한다면, 이 데이터를 백업하는 계획은 필수이다.
etcd에 대한 자세한 정보는, 공식 문서를 참고한다.
kube-scheduler
노드가 배정되지 않은 새로 생성된 파드 를 감지하고, 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트.
스케줄링 결정을 위해서 고려되는 요소는 리소스에 대한 개별 및 총체적 요구 사항, 하드웨어/소프트웨어/정책적 제약, 어피니티(affinity) 및 안티-어피니티(anti-affinity) 명세, 데이터 지역성, 워크로드-간 간섭, 데드라인을 포함한다.
kube-controller-manager
컨트롤러 프로세스를 실행하는 컨트롤 플레인 컴포넌트.
논리적으로, 각 컨트롤러는 분리된 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 단일 프로세스 내에서 실행된다.
이들 컨트롤러는 다음을 포함한다.
- 노드 컨트롤러: 노드가 다운되었을 때 통지와 대응에 관한 책임을 가진다.
- 잡 컨트롤러: 일회성 작업을 나타내는 잡 오브젝트를 감시한 다음, 해당 작업을 완료할 때까지 동작하는 파드를 생성한다.
- 엔드포인트슬라이스 컨트롤러: (서비스와 파드 사이의 연결고리를 제공하기 위해) 엔드포인트슬라이스(EndpointSlice) 오브젝트를 채운다
- 서비스어카운트 컨트롤러: 새로운 네임스페이스에 대한 기본 서비스어카운트(ServiceAccount)를 생성한다.
cloud-controller-manager
클라우드별 컨트롤 로직을 포함하는 쿠버네티스 컨트롤 플레인 컴포넌트이다. 클라우드 컨트롤러 매니저를 통해 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해 준다.cloud-controller-manager는 클라우드 제공자 전용 컨트롤러만 실행한다. 자신의 사내 또는 PC 내부의 학습 환경에서 쿠버네티스를 실행 중인 경우 클러스터에는 클라우드 컨트롤러 매니저가 없다.
kube-controller-manager와 마찬가지로 cloud-controller-manager는 논리적으로 독립적인 여러 컨트롤 루프를 단일 프로세스로 실행하는 단일 바이너리로 결합한다. 수평으로 확장(두 개 이상의 복제 실행)해서 성능을 향상시키거나 장애를 견딜 수 있다.
다음 컨트롤러들은 클라우드 제공 사업자의 의존성을 가질 수 있다.
- 노드 컨트롤러: 노드가 응답을 멈춘 후 클라우드 상에서 삭제되었는지 판별하기 위해 클라우드 제공 사업자에게 확인하는 것
- 라우트 컨트롤러: 기본 클라우드 인프라에 경로를 구성하는 것
- 서비스 컨트롤러: 클라우드 제공 사업자 로드밸런서를 생성, 업데이트 그리고 삭제하는 것
노드 컴포넌트
노드 컴포넌트는 동작 중인 파드를 유지시키고 쿠버네티스 런타임 환경을 제공하며, 모든 노드 상에서 동작한다.
kubelet
클러스터의 각 노드에서 실행되는 에이전트. Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리한다.
Kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙(PodSpec)의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 건강하게 동작하는 것을 확실히 한다. Kubelet은 쿠버네티스를 통해 생성되지 않는 컨테이너는 관리하지 않는다.
kube-proxy
kube-proxy는 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스 개념의 구현부이다.
kube-proxy는 노드의 네트워크 규칙을 유지 관리한다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해준다.
kube-proxy는 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용한다. 그렇지 않으면, kube-proxy는 트래픽 자체를 포워드(forward)한다.
컨테이너 런타임
컨테이너 런타임은 컨테이너 실행을 담당하는 소프트웨어이다.
쿠버네티스는 containerd, CRI-O와 같은 컨테이너 런타임 및 모든 Kubernetes CRI (컨테이너 런타임 인터페이스) 구현체를 지원한다.
애드온
애드온은 쿠버네티스 리소스(데몬셋,
디플로이먼트 등)를
이용하여 클러스터 기능을 구현한다. 이들은 클러스터 단위의 기능을 제공하기 때문에
애드온에 대한 네임스페이스 리소스는 kube-system 네임스페이스에 속한다.
선택된 일부 애드온은 아래에 설명하였고, 사용 가능한 전체 확장 애드온 리스트는 애드온을 참조한다.
DNS
여타 애드온들이 절대적으로 요구되지 않지만, 많은 예시에서 필요로 하기 때문에 모든 쿠버네티스 클러스터는 클러스터 DNS를 갖추어야만 한다.
클러스터 DNS는 구성환경 내 다른 DNS 서버와 더불어, 쿠버네티스 서비스를 위해 DNS 레코드를 제공해주는 DNS 서버다.
쿠버네티스에 의해 구동되는 컨테이너는 DNS 검색에서 이 DNS 서버를 자동으로 포함한다.
웹 UI (대시보드)
대시보드는 쿠버네티스 클러스터를 위한 범용의 웹 기반 UI다. 사용자가 클러스터 자체뿐만 아니라, 클러스터에서 동작하는 애플리케이션에 대한 관리와 문제 해결을 할 수 있도록 해준다.
컨테이너 리소스 모니터링
컨테이너 리소스 모니터링은 중앙 데이터베이스 내의 컨테이너들에 대한 포괄적인 시계열 매트릭스를 기록하고 그 데이터를 열람하기 위한 UI를 제공해 준다.
클러스터-레벨 로깅
클러스터-레벨 로깅 메커니즘은 검색/열람 인터페이스와 함께 중앙 로그 저장소에 컨테이너 로그를 저장하는 책임을 진다.
다음 내용
- 노드에 대해 더 배우기
- 컨트롤러에 대해 더 배우기
- kube-scheduler에 대해 더 배우기
- etcd의 공식 문서 읽기
1.2 - 쿠버네티스 API
쿠버네티스 API를 사용하면 쿠버네티스 오브젝트들의 상태를 쿼리하고 조작할 수 있다. 쿠버네티스 컨트롤 플레인의 핵심은 API 서버와 그것이 노출하는 HTTP API이다. 사용자와 클러스터의 다른 부분 및 모든 외부 컴포넌트는 API 서버를 통해 서로 통신한다.
쿠버네티스 컨트롤 플레인의 핵심은 API 서버이다. API 서버는 최종 사용자, 클러스터의 다른 부분 그리고 외부 컴포넌트가 서로 통신할 수 있도록 HTTP API를 제공한다.
쿠버네티스 API를 사용하면 쿠버네티스의 API 오브젝트(예: 파드(Pod), 네임스페이스(Namespace), 컨피그맵(ConfigMap) 그리고 이벤트(Event))를 질의(query)하고 조작할 수 있다.
대부분의 작업은 kubectl 커맨드 라인 인터페이스 또는 API를 사용하는 kubeadm과 같은 다른 커맨드 라인 도구를 통해 수행할 수 있다. 그러나, REST 호출을 사용하여 API에 직접 접근할 수도 있다.
쿠버네티스 API를 사용하여 애플리케이션을 작성하는 경우 클라이언트 라이브러리 중 하나를 사용하는 것이 좋다.
OpenAPI 명세
완전한 API 상세 내용은 OpenAPI를 활용해서 문서화했다.
OpenAPI V2
쿠버네티스 API 서버는 /openapi/v2 엔드포인트를 통해
통합된(aggregated) OpenAPI v2 스펙을 제공한다.
요청 헤더에 다음과 같이 기재하여 응답 형식을 지정할 수 있다.
| 헤더 | 사용할 수 있는 값 | 참고 |
|---|---|---|
Accept-Encoding |
gzip |
이 헤더를 제공하지 않는 것도 가능 |
Accept |
application/com.github.proto-openapi.spec.v2@v1.0+protobuf |
주로 클러스터 내부 용도로 사용 |
application/json |
기본값 | |
* |
JSON으로 응답 |
쿠버네티스는 주로 클러스터 내부 통신을 위해 대안적인 Protobuf에 기반한 직렬화 형식을 구현한다. 이 형식에 대한 자세한 내용은 쿠버네티스 Protobuf 직렬화 디자인 제안과 API 오브젝트를 정의하는 Go 패키지에 들어있는 각각의 스키마에 대한 IDL(인터페이스 정의 언어) 파일을 참고한다.
OpenAPI V3
기능 상태:
Kubernetes v1.24 [beta]
쿠버네티스 v1.31 버전은 OpenAPI v3 API 발행(publishing)에 대한 베타 지원을 제공한다.
이는 베타 기능이며 기본적으로 활성화되어 있다.
kube-apiserver 구성 요소에
OpenAPIV3 기능 게이트를 비활성화하여
이 베타 기능을 비활성화할 수 있다.
/openapi/v3 디스커버리 엔드포인트는 사용 가능한 모든
그룹/버전의 목록을 제공한다. 이 엔드포인트는 JSON 만을 반환한다.
이러한 그룹/버전은 다음과 같은 형식으로 제공된다.
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
}
위의 상대 URL은 변경 불가능한(immutable) OpenAPI 상세를 가리키고 있으며,
이는 클라이언트에서의 캐싱을 향상시키기 위함이다.
같은 목적을 위해 API 서버는 적절한 HTTP 캐싱 헤더를
설정한다(Expires를 1년 뒤로, Cache-Control을 immutable).
사용 중단된 URL이 사용되면, API 서버는 최신 URL로의 리다이렉트를 반환한다.
쿠버네티스 API 서버는
쿠버네티스 그룹 버전에 따른 OpenAPI v3 스펙을
/openapi/v3/apis/<group>/<version>?hash=<hash> 엔드포인트에 게시한다.
사용 가능한 요청 헤더 목록은 아래의 표를 참고한다.
| 헤더 | 사용할 수 있는 값 | 참고 |
|---|---|---|
Accept-Encoding |
gzip |
이 헤더를 제공하지 않는 것도 가능 |
Accept |
application/com.github.proto-openapi.spec.v3@v1.0+protobuf |
주로 클러스터 내부 용도로 사용 |
application/json |
기본값 | |
* |
JSON으로 응답 |
지속성
쿠버네티스는 오브젝트의 직렬화된 상태를 etcd에 기록하여 저장한다.
API 그룹과 버전 규칙
필드를 쉽게 제거하거나 리소스 표현을 재구성하기 위해,
쿠버네티스는 각각 /api/v1 또는 /apis/rbac.authorization.k8s.io/v1alpha1 과
같은 서로 다른 API 경로에서 여러 API 버전을 지원한다.
버전 규칙은 리소스나 필드 수준이 아닌 API 수준에서 수행되어 API가 시스템 리소스 및 동작에 대한 명확하고 일관된 보기를 제공하고 수명 종료 및/또는 실험적 API에 대한 접근을 제어할 수 있도록 한다.
보다 쉽게 발전하고 API를 확장하기 위해, 쿠버네티스는 활성화 또는 비활성화가 가능한 API 그룹을 구현한다.
API 리소스는 API 그룹, 리소스 유형, 네임스페이스 (네임스페이스 리소스용) 및 이름으로 구분된다. API 서버는 API 버전 간의 변환을 투명하게 처리한다. 서로 다른 모든 버전은 실제로 동일한 지속 데이터의 표현이다. API 서버는 여러 API 버전을 통해 동일한 기본 데이터를 제공할 수 있다.
예를 들어, 동일한 리소스에 대해 v1 과 v1beta1 이라는 두 가지 API 버전이
있다고 가정하자. API의 v1beta1 버전을 사용하여 오브젝트를 만든 경우,
v1beta1 버전이 사용 중단(deprecated)되고 제거될 때까지는
v1beta1 또는 v1 API 버전을 사용하여 해당 오브젝트를 읽거나, 업데이트하거나, 삭제할 수 있다.
그 이후부터는 v1 API를 사용하여 계속 오브젝트에 접근하고 수정할 수 있다.
API 변경 사항
성공적인 시스템은 새로운 유스케이스가 등장하거나 기존 사례가 변경됨에 따라 성장하고 변화해야 한다. 따라서, 쿠버네티스는 쿠버네티스 API가 지속적으로 변경되고 성장할 수 있도록 설계했다. 쿠버네티스 프로젝트는 기존 클라이언트와의 호환성을 깨지 않고 다른 프로젝트가 적응할 기회를 가질 수 있도록 장기간 해당 호환성을 유지하는 것을 목표로 한다.
일반적으로, 새 API 리소스와 새 리소스 필드는 자주 추가될 수 있다. 리소스 또는 필드를 제거하려면 API 지원 중단 정책을 따라야 한다.
쿠버네티스는 일반적으로 API 버전 v1 에서 안정 버전(GA)에 도달하면, 공식 쿠버네티스 API에
대한 호환성 유지를 강력하게 이행한다. 또한,
쿠버네티스는 공식 쿠버네티스 API의 베타 API 버전으로 만들어진 데이터와도 호환성을 유지하며,
해당 기능이 안정화되었을 때 해당 데이터가 안정 버전(GA)의 API 버전들에 의해 변환되고 접근될 수 있도록 보장한다.
만약 베타 API 버전을 사용했다면, 해당 API가 승급했을 때 후속 베타 버전 혹은 안정된 버전의 API로 전환해야 한다. 해당 작업은 오브젝트 접근을 위해 두 API 버전 모두 사용할 수 있는 베타 API의 사용 중단(deprecation) 시기일 때 진행하는 것이 최선이다. 베타 API의 사용 중단(deprecation) 시기가 끝나고 더 이상 사용될 수 없다면 반드시 대체 API 버전을 사용해야 한다.
참고:
비록 쿠버네티스는 알파 API 버전에 대한 호환성을 유지하는 것을 목표로 하지만, 일부 상황에서 이는 불가능하다. 알파 API 버전을 사용하는 경우, 클러스터를 업그레이드해야 할 때에는 API 변경으로 인해 호환성이 깨지고 업그레이드 전에 기존 오브젝트를 전부 제거해야 하는 상황에 대비하기 위해 쿠버네티스의 릴리스 정보를 확인하자.API 버전 수준 정의에 대한 자세한 내용은 API 버전 레퍼런스를 참조한다.
API 확장
쿠버네티스 API는 다음 두 가지 방법 중 하나로 확장할 수 있다.
- 커스텀 리소스를 사용하면 API 서버가 선택한 리소스 API를 제공하는 방법을 선언적으로 정의할 수 있다.
- 애그리게이션 레이어(aggregation layer)를 구현하여 쿠버네티스 API를 확장할 수도 있다.
다음 내용
- 자체 CustomResourceDefinition을 추가하여 쿠버네티스 API를 확장하는 방법에 대해 배우기.
- 쿠버네티스 API 접근 제어하기는 클러스터가 API 접근을 위한 인증 및 권한을 관리하는 방법을 설명한다.
- API 레퍼런스를 읽고 API 엔드포인트, 리소스 유형 및 샘플에 대해 배우기.
- API 변경 사항에서 호환 가능한 변경 사항을 구성하고, API를 변경하는 방법에 대해 알아본다.
1.3 - 쿠버네티스 오브젝트로 작업하기
쿠버네티스 오브젝트는 쿠버네티스 시스템의 영구 엔티티이다. 쿠버네티스는 이러한 엔티티들을 사용하여 클러스터의 상태를 나타낸다. 쿠버네티스 오브젝트 모델과 쿠버네티스 오브젝트를 사용하는 방법에 대해 학습한다.
1.3.1 - 쿠버네티스 오브젝트 이해하기
이 페이지에서는 쿠버네티스 오브젝트가 쿠버네티스 API에서 어떻게 표현되고, 그 오브젝트를
어떻게 .yaml 형식으로 표현할 수 있는지에 대해 설명한다.
쿠버네티스 오브젝트 이해하기
쿠버네티스 오브젝트 는 쿠버네티스 시스템에서 영속성을 가지는 오브젝트이다. 쿠버네티스는 클러스터의 상태를 나타내기 위해 이 오브젝트를 이용한다. 구체적으로 말하자면, 다음같이 기술할 수 있다.
- 어떤 컨테이너화된 애플리케이션이 동작 중인지 (그리고 어느 노드에서 동작 중인지)
- 그 애플리케이션이 이용할 수 있는 리소스
- 그 애플리케이션이 어떻게 재구동 정책, 업그레이드, 그리고 내고장성과 같은 것에 동작해야 하는지에 대한 정책
쿠버네티스 오브젝트는 하나의 "의도를 담은 레코드"이다. 오브젝트를 생성하게 되면, 쿠버네티스 시스템은 그 오브젝트 생성을 보장하기 위해 지속적으로 작동할 것이다. 오브젝트를 생성함으로써, 여러분이 클러스터의 워크로드를 어떤 형태로 보이고자 하는지에 대해 효과적으로 쿠버네티스 시스템에 전한다. 이것이 바로 여러분의 클러스터에 대해 의도한 상태 가 된다.
생성이든, 수정이든, 또는 삭제든 쿠버네티스 오브젝트를 동작시키려면,
쿠버네티스 API를 이용해야 한다. 예를 들어,
kubectl 커맨드-라인 인터페이스를 이용할 때, CLI는 여러분 대신 필요한 쿠버네티스 API를 호출해 준다.
또한, 여러분은 클라이언트 라이브러리 중 하나를
이용하여 여러분만의 프로그램에서 쿠버네티스 API를 직접 이용할 수도 있다.
오브젝트 명세(spec)와 상태(status)
거의 모든 쿠버네티스 오브젝트는 오브젝트의 구성을 결정해주는
두 개의 중첩된 오브젝트 필드를 포함하는데 오브젝트 spec 과 오브젝트 status 이다.
spec을 가진 오브젝트는 오브젝트를 생성할 때 리소스에
원하는 특징(의도한 상태)에 대한 설명을
제공해서 설정한다.
status 는 쿠버네티스 시스템과 컴포넌트에 의해 제공되고
업데이트된 오브젝트의 현재 상태 를 설명한다. 쿠버네티스
컨트롤 플레인은 모든 오브젝트의
실제 상태를 사용자가 의도한 상태와 일치시키기 위해 끊임없이 그리고
능동적으로 관리한다.
예를 들어, 쿠버네티스 디플로이먼트는 클러스터에서 동작하는 애플리케이션을 표현해줄 수 있는 오브젝트이다. 디플로이먼트를 생성할 때, 디플로이먼트 spec에 3개의 애플리케이션 레플리카가 동작되도록 설정할 수 있다. 쿠버네티스 시스템은 그 디플로이먼트 spec을 읽어 spec에 일치되도록 상태를 업데이트하여 3개의 의도한 애플리케이션 인스턴스를 구동시킨다. 만약, 그 인스턴스들 중 어느 하나가 어떤 문제로 인해 멈춘다면(상태 변화 발생), 쿠버네티스 시스템은 보정(이 경우에는 대체 인스턴스를 시작하여)을 통해 spec과 status간의 차이에 대응한다.
오브젝트 명세, 상태, 그리고 메타데이터에 대한 추가 정보는, Kubernetes API Conventions 를 참조한다.
쿠버네티스 오브젝트 기술하기
쿠버네티스에서 오브젝트를 생성할 때, (이름과 같은)오브젝트에 대한 기본적인 정보와 더불어,
의도한 상태를 기술한 오브젝트 spec을 제시해 줘야만 한다. 오브젝트를 생성하기 위해
(직접이든 또는 kubectl을 통해서든) 쿠버네티스 API를 이용할 때, API 요청은 요청 내용 안에
JSON 형식으로 정보를 포함시켜 줘야만 한다. 대부분의 경우 정보를 .yaml 파일로 kubectl에
제공한다. kubectl은 API 요청이 이루어질 때, JSON 형식으로 정보를
변환시켜 준다.
여기 쿠버네티스 디플로이먼트를 위한 필수 필드와 오브젝트 spec을 보여주는 .yaml 파일 예시가 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
위 예시와 같이 .yaml 파일을 이용하여 디플로이먼트를 생성하기 위한 하나의 방식으로는
kubectl 커맨드-라인 인터페이스에 인자값으로 .yaml 파일을 건네
kubectl apply 커맨드를 이용하는 것이다. 다음 예시와 같다.
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
그 출력 내용은 다음과 유사하다.
deployment.apps/nginx-deployment created
요구되는 필드
생성하고자 하는 쿠버네티스 오브젝트에 대한 .yaml 파일 내, 다음 필드를 위한 값들을 설정해 줘야한다.
apiVersion- 이 오브젝트를 생성하기 위해 사용하고 있는 쿠버네티스 API 버전이 어떤 것인지kind- 어떤 종류의 오브젝트를 생성하고자 하는지metadata-이름문자열,UID, 그리고 선택적인네임스페이스를 포함하여 오브젝트를 유일하게 구분지어 줄 데이터spec- 오브젝트에 대해 어떤 상태를 의도하는지
오브젝트 spec에 대한 정확한 포맷은 모든 쿠버네티스 오브젝트마다 다르고, 그 오브젝트 특유의
중첩된 필드를 포함한다. 쿠버네티스 API 레퍼런스 는
쿠버네티스를 이용하여 생성할 수 있는 오브젝트에 대한 모든 spec 포맷을 살펴볼 수 있도록 해준다.
예를 들어, 파드 API 레퍼런스를 보려면
spec 필드를 참조한다.
각 파드에 대해, .spec 필드는 파드 및 파드의 원하는 상태(desired state)를
기술한다(예: 파드의 각 컨테이너에 대한 컨테이너 이미지).
오브젝트 상세에 대한 또 다른 예시는 스테이트풀셋 API의
spec 필드이다.
스테이트풀셋의 경우, .spec 필드는 스테이트풀셋 및 스테이트풀셋의 원하는 상태(desired state)를 기술한다.
스테이트풀셋의 .spec에는 파드 오브젝트에 대한
템플릿이 존재한다.
이 템플릿은 스테이트풀셋 명세를 만족시키기 위해
스테이트풀셋 컨트롤러가 생성할 파드에 대한 상세 사항을 설명한다.
서로 다른 종류의 오브젝트는 서로 다른 .status를 가질 수 있다.
다시 한번 말하자면, 각 API 레퍼런스 페이지는 각 오브젝트 타입에 대해 해당 .status 필드의 구조와 내용에 대해 소개한다.
다음 내용
- 파드와 같이, 가장 중요하고 기본적인 쿠버네티스 오브젝트에 대해 배운다.
- 쿠버네티스의 컨트롤러에 대해 배운다.
- API 개념의 더 많은 설명은 쿠버네티스 API 사용을 본다.
1.3.2 - 쿠버네티스 오브젝트 관리
kubectl 커맨드라인 툴은 쿠버네티스 오브젝트를 생성하고 관리하기 위한
몇 가지 상이한 방법을 지원한다. 이 문서는 여러가지 접근법에 대한 개요를
제공한다. Kubectl로 오브젝트 관리하기에 대한 자세한 설명은
Kubectl 서적에서 확인한다.
관리 기법
경고:
쿠버네티스 오브젝트는 하나의 기법만 사용하여 관리해야 한다. 동일한 오브젝트에 대해 여러 기법을 혼용하는 것은 예상치 못한 동작을 초래하게 된다.| 관리기법 | 대상 | 권장 환경 | 지원하는 작업자 수 | 학습 난이도 |
|---|---|---|---|---|
| 명령형 커맨드 | 활성 오브젝트 | 개발 환경 | 1+ | 낮음 |
| 명령형 오브젝트 구성 | 개별 파일 | 프로덕션 환경 | 1 | 보통 |
| 선언형 오브젝트 구성 | 파일이 있는 디렉터리 | 프로덕션 환경 | 1+ | 높음 |
명령형 커맨드
명령형 커맨드를 사용할 경우, 사용자는 클러스터 내 활성 오브젝트를 대상으로
직접 동작시킨다. 사용자는 실행할 작업을 인수 또는 플래그로 kubectl 커맨드에
지정한다.
이것은 클러스터에서 일회성 작업을 개시시키거나 동작시키기 위한 추천 방법이다. 이 기법은 활성 오브젝트를 대상으로 직접적인 영향을 미치기 때문에, 이전 구성에 대한 이력을 제공해 주지 않는다.
예시
디플로이먼트 오브젝트를 생성하여 nginx 컨테이너의 인스턴스를 구동시킨다.
kubectl create deployment nginx --image nginx
트레이드 오프
오브젝트 구성에 비해 장점은 다음과 같다.
- 커맨드는 하나의 동작을 나타내는 단어로 표현된다.
- 커맨드는 클러스터를 수정하기 위해 단 하나의 단계만을 필요로 한다.
오브젝트 구성에 비해 단점은 다음과 같다.
- 커맨드는 변경 검토 프로세스와 통합되지 않는다.
- 커맨드는 변경에 관한 감사 추적(audit trail)을 제공하지 않는다.
- 커맨드는 활성 동작 중인 경우를 제외하고는 레코드의 소스를 제공하지 않는다.
- 커맨드는 새로운 오브젝트 생성을 위한 템플릿을 제공하지 않는다.
명령형 오브젝트 구성
명령형 오브젝트 구성에서는 kubectl 커맨드로 작업(생성, 교체 등), 선택적 플래그, 그리고 최소 하나의 파일 이름을 지정한다. 그 파일은 YAML 또는 JSON 형식으로 오브젝트의 완전한 정의를 포함해야만 한다.
오브젝트 정의에 대한 더 자세한 내용은 API 참조를 참고한다.
경고:
명령형replace 커맨드는 기존 spec을 새로 제공된 spec으로 바꾸고
구성 파일에서 누락된 오브젝트의 모든 변경 사항을 삭제한다.
이 방법은 spec이 구성 파일과는 별개로 업데이트되는 리소스 유형에는
사용하지 말아야한다.
예를 들어 LoadBalancer 유형의 서비스는 클러스터의 구성과 별도로
externalIPs 필드가 업데이트된다.예시
구성 파일에 정의된 오브젝트를 생성한다.
kubectl create -f nginx.yaml
두 개의 구성 파일에 정의된 오브젝트를 삭제한다.
kubectl delete -f nginx.yaml -f redis.yaml
활성 동작하는 구성을 덮어씀으로써 구성 파일에 정의된 오브젝트를 업데이트한다.
kubectl replace -f nginx.yaml
트레이드 오프
명령형 커맨드에 비해 장점은 다음과 같다.
- 오브젝트 구성은 Git과 같은 소스 컨트롤 시스템에 보관할 수 있다.
- 오브젝트 구성은 푸시와 감사 추적 전에 변경사항을 검토하는 것과 같은 프로세스들과 통합할 수 있다.
- 오브젝트 구성은 새로운 오브젝트 생성을 위한 템플릿을 제공한다.
명령형 커맨드에 비해 단점은 다음과 같다.
- 오브젝트 구성은 오브젝트 스키마에 대한 기본적인 이해를 필요로 한다.
- 오브젝트 구성은 YAML 파일을 기록하는 추가적인 과정을 필요로 한다.
선언형 오브젝트 구성에 비해 장점은 다음과 같다.
- 명령형 오브젝트 구성의 동작은 보다 간결하고 이해하기 쉽다.
- 쿠버네티스 버전 1.5 부터는 더 성숙한 명령형 오브젝트 구성을 제공한다.
선언형 오브젝트 구성에 비해 단점은 다음과 같다.
- 명령형 오브젝트 구성은 디렉터리가 아닌, 파일에 가장 적합하다.
- 활성 오브젝트에 대한 업데이트는 구성 파일에 반영되어야 한다. 그렇지 않으면 다음 교체 중에 손실된다.
선언형 오브젝트 구성
선언형 오브젝트 구성을 사용할 경우, 사용자는 로컬에 보관된 오브젝트
구성 파일을 대상으로 작동시키지만, 사용자는 파일에서 수행 할
작업을 정의하지 않는다. 생성, 업데이트, 그리고 삭제 작업은
kubectl에 의해 오브젝트마다 자동으로 감지된다. 이를 통해 다른 오브젝트에 대해
다른 조작이 필요할 수 있는 디렉터리에서 작업할 수 있다.
참고:
선언형 오브젝트 구성은 변경 사항이 오브젝트 구성 파일에 다시 병합되지 않더라도 다른 작성자가 작성한 변경 사항을 유지한다. 이것은 전체 오브젝트 구성 변경을 위한replace API를
사용하는 대신, patch API를 사용하여 인지되는 차이만
작성하기 때문에 가능하다.예시
configs 디렉터리 내 모든 오브젝트 구성 파일을 처리하고 활성 오브젝트를
생성 또는 패치한다. 먼저 어떠한 변경이 이루어지게 될지 알아보기 위해 diff
하고 나서 적용할 수 있다.
kubectl diff -f configs/
kubectl apply -f configs/
재귀적으로 디렉터리를 처리한다.
kubectl diff -R -f configs/
kubectl apply -R -f configs/
트레이드 오프
명령형 오브젝트 구성에 비해 장점은 다음과 같다.
- 활성 오브젝트에 직접 작성된 변경 사항은 구성 파일로 다시 병합되지 않더라도 유지된다.
- 선언형 오브젝트 구성은 디렉터리에서의 작업 및 오브젝트 별 작업 유형(생성, 패치, 삭제)의 자동 감지에 더 나은 지원을 제공한다.
명령형 오브젝트 구성에 비해 단점은 다음과 같다.
- 선언형 오브젝트 구성은 예상치 못한 결과를 디버깅하고 이해하기가 더 어렵다.
- diff를 사용한 부분 업데이트는 복잡한 병합 및 패치 작업을 일으킨다.
다음 내용
1.3.3 - 오브젝트 이름과 ID
클러스터의 각 오브젝트는 해당 유형의 리소스에 대하여 고유한 이름 을 가지고 있다. 또한, 모든 쿠버네티스 오브젝트는 전체 클러스터에 걸쳐 고유한 UID 를 가지고 있다.
예를 들어, 이름이 myapp-1234인 파드는 동일한 네임스페이스 내에서 하나만 존재할 수 있지만, 이름이 myapp-1234인 파드와 디플로이먼트는 각각 존재할 수 있다.
유일하지 않은 사용자 제공 속성의 경우 쿠버네티스는 레이블과 어노테이션을 제공한다.
이름
/api/v1/pods/some-name과 같이, 리소스 URL에서 오브젝트를 가리키는 클라이언트 제공 문자열.
특정 시점에 같은 종류(kind) 내에서는 하나의 이름은 하나의 오브젝트에만 지정될 수 있다. 하지만, 오브젝트를 삭제한 경우, 삭제된 오브젝트와 같은 이름을 새로운 오브젝트에 지정 가능하다.
참고:
물리적 호스트를 나타내는 노드와 같이 오브젝트가 물리적 엔티티를 나타내는 경우, 노드를 삭제한 후 다시 생성하지 않은 채 동일한 이름으로 호스트를 다시 생성하면, 쿠버네티스는 새 호스트를 불일치로 이어질 수 있는 이전 호스트로 취급한다.다음은 리소스에 일반적으로 사용되는 네 가지 유형의 이름 제한 조건이다.
DNS 서브도메인 이름
대부분의 리소스 유형에는 RFC 1123에 정의된 대로 DNS 서브도메인 이름으로 사용할 수 있는 이름이 필요하다. 이것은 이름이 다음을 충족해야 한다는 것을 의미한다.
- 253자를 넘지 말아야 한다.
- 소문자와 영숫자
-또는.만 포함한다. - 영숫자로 시작한다.
- 영숫자로 끝난다.
RFC 1123 레이블 이름
일부 리소스 유형은 RFC 1123에 정의된 대로 DNS 레이블 표준을 따라야 한다. 이것은 이름이 다음을 충족해야 한다는 것을 의미한다.
- 최대 63자이다.
- 소문자와 영숫자 또는
-만 포함한다. - 영숫자로 시작한다.
- 영숫자로 끝난다.
RFC 1035 레이블 이름
몇몇 리소스 타입은 자신의 이름을 RFC 1035에 정의된 DNS 레이블 표준을 따르도록 요구한다. 이것은 이름이 다음을 만족해야 한다는 의미이다.
- 최대 63개 문자를 포함
- 소문자 영숫자 또는 '-'만 포함
- 알파벳 문자로 시작
- 영숫자로 끝남
경로 세그먼트 이름
일부 리소스 유형에서는 이름을 경로 세그먼트로 안전하게 인코딩 할 수 있어야 한다. 즉 이름이 "." 또는 ".."이 아닐 수 있으며 이름에는 "/" 또는 "%"가 포함될 수 없다.
아래는 파드의 이름이 nginx-demo라는 매니페스트 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
참고:
일부 리소스 유형은 이름에 추가적인 제약이 있다.UID
오브젝트를 중복 없이 식별하기 위해 쿠버네티스 시스템이 생성하는 문자열.
쿠버네티스 클러스터가 구동되는 전체 시간에 걸쳐 생성되는 모든 오브젝트는 서로 구분되는 UID를 갖는다. 이는 기록상 유사한 오브젝트의 출현을 서로 구분하기 위함이다.
쿠버네티스 UID는 보편적으로 고유한 식별자이다(또는 UUID라고 한다). UUID는 ISO/IEC 9834-8 과 ITU-T X.667 로 표준화 되어 있다.
다음 내용
- 쿠버네티스의 레이블과 어노테이션에 대해 읽기.
- 쿠버네티스의 식별자와 이름 디자인 문서 읽기.
1.3.4 - 레이블과 셀렉터
레이블 은 파드와 같은 오브젝트에 첨부된 키와 값의 쌍이다. 레이블은 오브젝트의 특성을 식별하는 데 사용되어 사용자에게 중요하지만, 코어 시스템에 직접적인 의미는 없다. 레이블로 오브젝트의 하위 집합을 선택하고, 구성하는데 사용할 수 있다. 레이블은 오브젝트를 생성할 때에 붙이거나 생성 이후에 붙이거나 언제든지 수정이 가능하다. 오브젝트마다 키와 값으로 레이블을 정의할 수 있다. 오브젝트의 키는 고유한 값이어야 한다.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
레이블은 UI와 CLI에서 효율적인 쿼리를 사용하고 검색에 사용하기에 적합하다. 식별되지 않는 정보는 어노테이션으로 기록해야 한다.
사용 동기
레이블을 이용하면 사용자가 느슨하게 결합한 방식으로 조직 구조와 시스템 오브젝트를 매핑할 수 있으며, 클라이언트에 매핑 정보를 저장할 필요가 없다.
서비스 배포와 배치 프로세싱 파이프라인은 흔히 다차원의 엔티티들이다(예: 다중 파티션 또는 배포, 다중 릴리스 트랙, 다중 계층, 계층 속 여러 마이크로 서비스들). 관리에는 크로스-커팅 작업이 필요한 경우가 많은데 이 작업은 사용자보다는 인프라에 의해 결정된 엄격한 계층 표현인 캡슐화를 깨트린다.
레이블 예시:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
이 예시는 일반적으로 사용하는 레이블이며, 사용자는 자신만의 규칙(convention)에 따라 자유롭게 개발할 수 있다. 오브젝트에 붙여진 레이블 키는 고유해야 한다는 것을 기억해야 한다.
구문과 캐릭터 셋
레이블 은 키와 값의 쌍이다. 유효한 레이블 키에는 슬래시(/)로 구분되는 선택한 접두사와 이름이라는 2개의 세그먼트가 있다. 이름 세그먼트는 63자 미만으로 시작과 끝은 알파벳과 숫자([a-z0-9A-Z])이며, 대시(-), 밑줄(_), 점(.)과 함께 사용할 수 있다. 접두사는 선택이다. 만약 접두사를 지정한 경우 접두사는 DNS의 하위 도메인으로 해야 하며, 점(.)과 전체 253자 이하, 슬래시(/)로 구분되는 DNS 레이블이다.
접두사를 생략하면 키 레이블은 개인용으로 간주한다. 최종 사용자의 오브젝트에 자동화된 시스템 컴포넌트(예: kube-scheduler, kube-controller-manager, kube-apiserver, kubectl 또는 다른 타사의 자동화 구성 요소)의 접두사를 지정해야 한다.
kubernetes.io/와 k8s.io/ 접두사는 쿠버네티스의 핵심 컴포넌트로 예약되어 있다.
유효한 레이블 값은 다음과 같다.
- 63 자 이하여야 하고 (공백일 수도 있음),
- (공백이 아니라면) 시작과 끝은 알파벳과 숫자(
[a-z0-9A-Z])이며, - 알파벳과 숫자, 대시(
-), 밑줄(_), 점(.)을 중간에 포함할 수 있다.
다음의 예시는 파드에 environment: production 과 app: nginx 2개의 레이블이 있는 구성 파일이다.
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
레이블 셀렉터
이름과 UID와 다르게 레이블은 고유하지 않다. 일반적으로 우리는 많은 오브젝트에 같은 레이블을 가질 것으로 예상한다.
레이블 셀렉터를 통해 클라이언트와 사용자는 오브젝트를 식별할 수 있다. 레이블 셀렉터는 쿠버네티스 코어 그룹의 기본이다.
API는 현재 일치성 기준 과 집합성 기준 이라는 두 종류의 셀렉터를 지원한다.
레이블 셀렉터는 쉼표로 구분된 다양한 요구사항 에 따라 만들 수 있다. 다양한 요구사항이 있는 경우 쉼표 기호가 AND(&&) 연산자로 구분되는 역할을 하도록 해야 한다.
비어있거나 지정되지 않은 셀렉터는 상황에 따라 달라진다. 셀렉터를 사용하는 API 유형은 유효성과 의미를 문서화해야 한다.
참고:
레플리카셋(ReplicaSet)과 같은 일부 API 유형에서 두 인스턴스의 레이블 셀렉터는 네임스페이스 내에서 겹치지 않아야 한다. 그렇지 않으면 컨트롤러는 상충하는 명령으로 보고, 얼마나 많은 복제본이 필요한지 알 수 없다.주의:
일치성 기준과 집합성 기준 조건 모두에 대해 논리적인 OR (||) 연산자가 없다. 필터 구문이 적절히 구성되어 있는지 확인해야 한다.일치성 기준 요건
일치성 기준 또는 불일치 기준 의 요구사항으로 레이블의 키와 값의 필터링을 허용한다. 일치하는 오브젝트는 추가 레이블을 가질 수 있지만, 레이블의 명시된 제약 조건을 모두 만족해야 한다.
=,==,!= 이 세 가지 연산자만 허용한다. 처음 두 개의 연산자의 일치성(그리고 동의어), 나머지는 불일치 를 의미한다. 예를 들면,
environment = production
tier != frontend
전자는 environment를 키로 가지는 것과 production을 값으로 가지는 모든 리소스를 선택한다.
후자는 tier를 키로 가지고, 값을 frontend를 가지는 리소스를 제외한 모든 리소스를 선택하고, tier를 키로 가지며, 값을 공백으로 가지는 모든 리소스를 선택한다.
environment=production,tier!=frontend 처럼 쉼표를 통해 한 문장으로 frontend를 제외한 production을 필터링할 수 있다.
일치성 기준 레이블 요건에 대한 하나의 이용 시나리오는 파드가 노드를 선택하는 기준을 지정하는 것이다.
예를 들어, 아래 샘플 파드는 "accelerator=nvidia-tesla-p100"
레이블을 가진 노드를 선택한다.
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
집합성 기준 요건
집합성 기준 레이블 요건에 따라 값 집합을 키로 필터링할 수 있다. in,notin과 exists(키 식별자만 해당)의 3개의 연산자를 지원한다. 예를 들면,
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
- 첫 번째 예시에서 키가
environment이고 값이production또는qa인 모든 리소스를 선택한다. - 두 번째 예시에서 키가
tier이고 값이frontend와backend를 가지는 리소스를 제외한 모든 리소스와 키로tier를 가지고 값을 공백으로 가지는 모든 리소스를 선택한다. - 세 번째 예시에서 레이블의 값에 상관없이 키가
partition을 포함하는 모든 리소스를 선택한다. - 네 번째 예시에서 레이블의 값에 상관없이 키가
partition을 포함하지 않는 모든 리소스를 선택한다.
마찬가지로 쉼표는 AND 연산자로 작동한다. 따라서 partition,environment notin (qa)와 같이 사용하면 값과 상관없이 키가 partition인 것과 키가 environment이고 값이 qa와 다른 리소스를 필터링할 수 있다.
집합성 기준 레이블 셀렉터는 일반적으로 environment=production과 environment in (production)을 같은 것으로 본다. 유사하게는 !=과 notin을 같은 것으로 본다.
집합성 기준 요건은 일치성 기준 요건과 조합해서 사용할 수 있다. 예를 들어 partition in (customerA, customerB),environment!=qa
API
LIST와 WATCH 필터링
LIST와 WATCH 작업은 쿼리 파라미터를 사용해서 반환되는 오브젝트 집합을 필터링하기 위해 레이블 셀렉터를 지정할 수 있다. 다음의 두 가지 요건 모두 허용된다(URL 쿼리 문자열을 그대로 표기함).
- 일치성 기준 요건:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - 집합성 기준 요건:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
두 가지 레이블 셀렉터 스타일은 모두 REST 클라이언트를 통해 선택된 리소스를 확인하거나 목록을 볼 수 있다. 예를 들어, kubectl로 apiserver를 대상으로 일치성 기준 으로 하는 셀렉터를 다음과 같이 이용할 수 있다.
kubectl get pods -l environment=production,tier=frontend
또는 집합성 기준 요건을 사용하면
kubectl get pods -l 'environment in (production),tier in (frontend)'
앞서 안내한 것처럼 집합성 기준 요건은 더 보여준다. 예시에서 다음과 같이 OR 연산자를 구현할 수 있다.
kubectl get pods -l 'environment in (production, qa)'
또는 exists 연산자에 불일치한 것으로 제한할 수 있다.
kubectl get pods -l 'environment,environment notin (frontend)'
API 오브젝트에서 참조 설정
services 와
replicationcontrollers와 같은
일부 쿠버네티스 오브젝트는 레이블 셀렉터를 사용해서
파드와 같은 다른 리소스 집합을 선택한다.
서비스와 레플리케이션 컨트롤러
services에서 지정하는 파드 집합은 레이블 셀렉터로 정의한다. 마찬가지로 replicationcontrollers가 관리하는 파드의 오브젝트 그룹도 레이블 셀렉터로 정의한다.
서비스와 레플리케이션 컨트롤러의 레이블 셀렉터는 json 또는 yaml 파일에 매핑된 일치성 기준 요구사항의 셀렉터만 지원한다.
"selector": {
"component" : "redis",
}
or
selector:
component: redis
json 또는 yaml 서식에서 셀렉터는 component=redis 또는 component in (redis) 모두 같은 것이다.
세트-기반 요건을 지원하는 리소스
Job,
Deployment,
ReplicaSet 그리고
DaemonSet 같은
새로운 리소스들은 집합성 기준 의 요건도 지원한다.
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
matchLabels는 {key,value}의 쌍과 매칭된다. matchLabels에 매칭된 단일 {key,value}는 matchExpressions의 요소와 같으며 key 필드는 "key"로, operator는 "In" 그리고 values에는 "value"만 나열되어 있다. matchExpressions는 파드 셀렉터의 요건 목록이다. 유효한 연산자에는 In, NotIn, Exists 및 DoNotExist가 포함된다. In 및 NotIn은 설정된 값이 있어야 한다. matchLabels와 matchExpressions 모두 AND로 되어 있어 일치하기 위해서는 모든 요건을 만족해야 한다.
노드 셋 선택
레이블을 통해 선택하는 사용 사례 중 하나는 파드를 스케줄 할 수 있는 노드 셋을 제한하는 것이다. 자세한 내용은 노드 선택 문서를 참조한다.
1.3.5 - 네임스페이스
쿠버네티스에서, 네임스페이스 는 단일 클러스터 내에서의 리소스 그룹 격리 메커니즘을 제공한다. 리소스의 이름은 네임스페이스 내에서 유일해야 하며, 네임스페이스 간에서 유일할 필요는 없다. 네임스페이스 기반 스코핑은 네임스페이스 기반 오브젝트 (예: 디플로이먼트, 서비스 등) 에만 적용 가능하며 클러스터 범위의 오브젝트 (예: 스토리지클래스, 노드, 퍼시스턴트볼륨 등) 에는 적용 불가능하다.
여러 개의 네임스페이스를 사용하는 경우
네임스페이스는 여러 개의 팀이나, 프로젝트에 걸쳐서 많은 사용자가 있는 환경에서 사용하도록 만들어졌다. 사용자가 거의 없거나, 수 십명 정도가 되는 경우에는 네임스페이스를 전혀 고려할 필요가 없다. 네임스페이스가 제공하는 기능이 필요할 때 사용하도록 하자.
네임스페이스는 이름의 범위를 제공한다. 리소스의 이름은 네임스페이스 내에서 유일해야하지만, 네임스페이스를 통틀어서 유일할 필요는 없다. 네임스페이스는 서로 중첩될 수 없으며, 각 쿠버네티스 리소스는 하나의 네임스페이스에만 있을 수 있다.
네임스페이스는 클러스터 자원을 (리소스 쿼터를 통해) 여러 사용자 사이에서 나누는 방법이다.
동일한 소프트웨어의 다른 버전과 같이 약간 다른 리소스를 분리하기 위해 여러 네임스페이스를 사용할 필요는 없다. 동일한 네임스페이스 내에서 리소스를 구별하기 위해 레이블을 사용한다.
참고:
프로덕션 클러스터의 경우,default 네임스페이스를 사용하지 않는 것을 고려한다. 대신에, 다른 네임스페이스를 만들어 사용한다.초기 네임스페이스
쿠버네티스는 처음에 네 개의 초기 네임스페이스를 갖는다.
default- 쿠버네티스에는 이 네임스페이스가 포함되어 있으므로 먼저 네임스페이스를 생성하지 않고도 새 클러스터를 사용할 수 있다.
kube-node-lease- 이 네임스페이스는 각 노드와 연관된 리스 오브젝트를 갖는다. 노드 리스는 kubelet이 하트비트를 보내서 컨트롤 플레인이 노드의 장애를 탐지할 수 있게 한다.
kube-public- 이 네임스페이스는 모든 클라이언트(인증되지 않은 클라이언트 포함)가 읽기 권한으로 접근할 수 있다. 이 네임스페이스는 주로 전체 클러스터 중에 공개적으로 드러나서 읽을 수 있는 리소스를 위해 예약되어 있다. 이 네임스페이스의 공개적인 성격은 단지 관례이지 요구 사항은 아니다.
kube-system- 쿠버네티스 시스템에서 생성한 오브젝트를 위한 네임스페이스.
네임스페이스 다루기
네임스페이스의 생성과 삭제는 네임스페이스 관리자 가이드 문서에 기술되어 있다.
참고:
`kube-` 접두사로 시작하는 네임스페이스는 쿠버네티스 시스템용으로 예약되어 있으므로, 사용자는 이러한 네임스페이스를 생성하지 않는다.
네임스페이스 조회
사용 중인 클러스터의 현재 네임스페이스를 나열할 수 있다.
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
요청에 네임스페이스 설정하기
현재 요청에 대한 네임스페이스를 설정하기 위해서 --namespace 플래그를 사용한다.
예를 들면,
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here>
kubectl get pods --namespace=<insert-namespace-name-here>
선호하는 네임스페이스 설정하기
이후 모든 kubectl 명령에서 사용하는 네임스페이스를 컨텍스트에 영구적으로 저장할 수 있다.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
# 확인하기
kubectl config view --minify | grep namespace:
네임스페이스와 DNS
서비스를 생성하면 해당
DNS 엔트리가 생성된다.
이 엔트리는 <서비스-이름>.<네임스페이스-이름>.svc.cluster.local의 형식을 갖는데,
이는 컨테이너가 <서비스-이름>만 사용하는 경우, 네임스페이스 내에 국한된 서비스로 연결된다.
개발, 스테이징, 운영과 같이 여러 네임스페이스 내에서 동일한 설정을 사용하는 경우에 유용하다.
네임스페이스를 넘어서 접근하기 위해서는,
전체 주소 도메인 이름(FQDN)을 사용해야 한다.
그렇기 때문에, 모든 네임스페이스 이름은 유효한 RFC 1123 DNS 레이블이어야 한다.
경고:
네임스페이스의 이름을 공개 최상위 도메인 중 하나와 동일하게 만들면, 해당 네임스페이스 내의 서비스의 짧은 DNS 이름이 공개 DNS 레코드와 겹칠 수 있다. 어떠한 네임스페이스 내의 워크로드가 접미점(trailing dot) 없이 DNS 룩업을 수행하면 공개 DNS 레코드보다 우선하여 해당 서비스로 리다이렉트될 것이다.
이를 방지하기 위해, 신뢰하는 사용자만 네임스페이스를 생성할 수 있도록 권한을 제한한다. 필요한 경우, 추가적으로 써드파티 보안 컨트롤을 구성할 수 있으며, 예를 들어 어드미션 웹훅을 이용하여 공개 TLD와 동일한 이름의 네임스페이스 생성을 금지시킬 수 있다.
모든 오브젝트가 네임스페이스에 속하지는 않음
대부분의 쿠버네티스 리소스(예를 들어, 파드, 서비스, 레플리케이션 컨트롤러 외)는 네임스페이스에 속한다. 하지만 네임스페이스 리소스 자체는 네임스페이스에 속하지 않는다. 그리고 노드나 퍼시스턴트 볼륨과 같은 저수준 리소스는 어느 네임스페이스에도 속하지 않는다.
다음은 네임스페이스에 속하지 않는 쿠버네티스 리소스를 조회하는 방법이다.
# 네임스페이스에 속하는 리소스
kubectl api-resources --namespaced=true
# 네임스페이스에 속하지 않는 리소스
kubectl api-resources --namespaced=false
자동 레이블링
기능 상태:
Kubernetes 1.21 [beta]
쿠버네티스 컨트롤 플레인은 NamespaceDefaultLabelName 기능 게이트가
활성화된 경우 모든 네임스페이스에 변경할 수 없는(immutable) 레이블
kubernetes.io / metadata.name 을 설정한다.
레이블 값은 네임스페이스 이름이다.
다음 내용
- 신규 네임스페이스 생성에 대해 더 배우기.
- 네임스페이스 삭제에 대해 더 배우기.
1.3.6 - 어노테이션
쿠버네티스 어노테이션을 사용하여 임의의 비-식별 메타데이터를 오브젝트에 첨부할 수 있다. 도구 및 라이브러리와 같은 클라이언트는 이 메타데이터를 검색할 수 있다.
오브젝트에 메타데이터 첨부
레이블이나 어노테이션을 사용하여 쿠버네티스 오브젝트에 메타데이터를 첨부할 수 있다. 레이블을 사용하여 오브젝트를 선택하고, 특정 조건을 만족하는 오브젝트 컬렉션을 찾을 수 있다. 반면에, 어노테이션은 오브젝트를 식별하고 선택하는데 사용되지 않는다. 어노테이션의 메타데이터는 작거나 크고, 구조적이거나 구조적이지 않을 수 있으며, 레이블에서 허용되지 않는 문자를 포함할 수 있다.
어노테이션은 레이블과 같이 키/값 맵이다.
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
참고:
맵의 키와 값은 문자열이어야 한다. 다르게 말해서, 숫자, 불리언(boolean), 리스트 등의 다른 형식을 키나 값에 사용할 수 없다.다음은 어노테이션에 기록할 수 있는 정보의 예제이다.
-
필드는 선언적 구성 계층에 의해 관리된다. 이러한 필드를 어노테이션으로 첨부하는 것은 클라이언트 또는 서버가 설정한 기본 값, 자동 생성된 필드, 그리고 오토사이징 또는 오토스케일링 시스템에 의해 설정된 필드와 구분된다.
-
빌드, 릴리스, 또는 타임 스탬프, 릴리스 ID, git 브랜치, PR 번호, 이미지 해시 및 레지스트리 주소와 같은 이미지 정보.
-
로깅, 모니터링, 분석 또는 감사 리포지터리에 대한 포인터.
-
디버깅 목적으로 사용될 수 있는 클라이언트 라이브러리 또는 도구 정보: 예를 들면, 이름, 버전, 그리고 빌드 정보.
-
다른 생태계 구성 요소의 관련 오브젝트 URL과 같은 사용자 또는 도구/시스템 출처 정보.
-
경량 롤아웃 도구 메타데이터. 예: 구성 또는 체크포인트
-
책임자의 전화번호 또는 호출기 번호, 또는 팀 웹 사이트 같은 해당 정보를 찾을 수 있는 디렉터리 진입점.
-
행동을 수정하거나 비표준 기능을 수행하기 위한 최종 사용자의 지시 사항.
어노테이션을 사용하는 대신, 이 유형의 정보를 외부 데이터베이스 또는 디렉터리에 저장할 수 있지만, 이는 배포, 관리, 인트로스펙션(introspection) 등을 위한 공유 클라이언트 라이브러리와 도구 생성을 훨씬 더 어렵게 만들 수 있다.
문법과 캐릭터 셋
어노테이션 은 키/값 쌍이다. 유효한 어노테이션 키에는 두 개의 세그먼트가 있다. 두 개의 세그먼트는 선택적인 접두사와 이름(name)이며, 슬래시(/)로 구분된다. 이름 세그먼트는 필수이며, 영문 숫자([a-z0-9A-Z])로 시작하고 끝나는 63자 이하이어야 하고, 사이에 대시(-), 밑줄(_), 점(.)이 들어갈 수 있다. 접두사는 선택적이다. 지정된 경우, 접두사는 DNS 서브도메인이어야 한다. 점(.)으로 구분된 일련의 DNS 레이블은 총 253자를 넘지 않고, 뒤에 슬래시(/)가 붙는다.
접두사가 생략되면, 어노테이션 키는 사용자에게 비공개로 간주된다. 최종 사용자 오브젝트에 어노테이션을 추가하는 자동화된 시스템 구성 요소(예 :kube-scheduler, kube-controller-manager, kube-apiserver, kubectl, 또는 다른 써드파티 자동화)는 접두사를 지정해야 한다.
kubernetes.io/와 k8s.io/ 접두사는 쿠버네티스 핵심 구성 요소를 위해 예약되어 있다.
다음은 imageregistry: https://hub.docker.com/ 어노테이션이 있는 파드의 구성 파일 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
다음 내용
레이블과 셀렉터에 대해 알아본다.
1.3.7 - 필드 셀렉터
필드 셀렉터 는 한 개 이상의 리소스 필드 값에 따라 쿠버네티스 리소스를 선택하기 위해 사용된다. 필드 셀렉터 쿼리의 예시는 다음과 같다.
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
다음의 kubectl 커맨드는 status.phase 필드의 값이 Running 인 모든 파드를 선택한다.
kubectl get pods --field-selector status.phase=Running
참고:
필드 셀렉터는 본질적으로 리소스 필터 이다. 기본적으로 적용되는 셀렉터나 필드는 없으며, 이는 명시된 종류의 모든 리소스가 선택된다는 것을 의미한다. 여기에 따라오는kubectl 쿼리인 kubectl get pods 와 kubectl get pods --field-selector "" 는 동일하다.사용 가능한 필드
사용 가능한 필드는 쿠버네티스의 리소스 종류에 따라서 다르다. 모든 리소스 종류는 metadata.name 과 metadata.namespace 필드 셀렉터를 사용할 수 있다. 사용할 수 없는 필드 셀렉터를 사용하면 다음과 같이 에러를 출력한다.
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
사용 가능한 연산자
필드 셀렉터에서 =, ==, != 연산자를 사용할 수 있다 (=와 ==는 동일한 의미이다). 예를 들면, 다음의 kubectl 커맨드는 default 네임스페이스에 속해있지 않은 모든 쿠버네티스 서비스를 선택한다.
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
연계되는 셀렉터
레이블을 비롯한 다른 셀렉터처럼, 쉼표로 구분되는 목록을 통해 필드 셀렉터를 연계해서 사용할 수 있다. 다음의 kubectl 커맨드는 status.phase 필드가 Running 이 아니고, spec.restartPolicy 필드가 Always 인 모든 파드를 선택한다.
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
여러 개의 리소스 종류
필드 셀렉터를 여러 개의 리소스 종류에 걸쳐 사용할 수 있다. 다음의 kubectl 커맨드는 default 네임스페이스에 속해있지 않은 모든 스테이트풀셋(StatefulSet)과 서비스를 선택한다.
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
1.3.8 - 파이널라이저
파이널라이저는 쿠버네티스가 오브젝트를 완전히 삭제하기 이전, 삭제 표시를 위해 특정 조건이 충족될 때까지 대기하도록 알려주기 위한 네임스페이스에 속한 키(namespaced key)이다. 파이널라이저는 삭제 완료된 오브젝트가 소유한 리소스를 정리하기 위해 컨트롤러에게 알린다.
파이널라이저를 가진 특정한 오브젝트를 쿠버네티스가 삭제하도록 지시할 때,
쿠버네티스 API는 .metadata.deletionTimestamp을 덧붙여 삭제하도록 오브젝트에 표시하며,
202 상태코드(HTTP "Accepted")을 리턴한다. 대상 오브젝트가 Terminating 상태를 유지하는 동안 컨트롤 플레인
또는 다른 컴포넌트는 하나의 파이널라이저에서 정의한 작업을 수행한다.
정의된 작업이 완료 후에, 그 컨트롤러는 대상 오브젝트로부터 연관된 파이널라이저을 삭제한다.
metadata.finalizers 필드가 비어 있을 때, 쿠버네티스는
삭제가 완료된 것으로 간주하고 오브젝트를 삭제한다.
파이널라이저가 리소스들의 가비지 컬렉션을 제어하도록 사용할 수 있다. 예를 들어, 하나의 파이널라이저를 컨트롤러가 대상 리소소를 삭제하기 전에 연관된 리소스들 또는 인프라를 정리하도록 정의할 수 있다.
파이널라이저(Finalizer)를 사용하면 리소스를 삭제하기 전 특정 정리 작업을 수행하도록 컨트롤러(Controller)에 경고하여 리소스의 가비지(Garbage) 수집을 제어할 수 있다.
파이널라이저는 보통 실행할 코드를 지정하지 않는다. 대신 파이널라이저는 일반적으로 어노테이션과 비슷하게 특정 리소스에 대한 키들의 목록이다. 일부 파이널라이저는 쿠버네티스가 자동으로 지정하지만, 사용자가 직접 지정할 수도 있다.
파이널라이저의 작동 방식
매니페스트 파일을 사용해 리소스를 생성하면
metadata.finalizers 필드에 파이널라이저를 명시할 수 있다.
리소스를 삭제하려 할 때는
삭제 요청을 처리하는 API 서버가 finalizers 필드의 값을 인식하고 다음을 수행한다.
- 삭제를 시작한 시각과 함께
metadata.deletionTimestamp필드를 추가하도록 오브젝트를 수정한다. - 오브젝트의
metadata.finalizers필드가 비워질 때까지 오브젝트가 제거되지 않도록 한다. 202상태 코드를 리턴한다(HTTP "Accepted").
이 파이널라이저를 관리하는 컨트롤러는 metadata.deletionTimestamp를 설정하는 오브젝트가 업데이트 되었음을 인지하여
오브젝트의 삭제가 요청되었음을 나타낸다.
그런 다음 컨트롤러는 그 리소스에 지정된 파이널라이저의 요구사항을 충족하려 시도한다.
컨트롤러는 파이널라이저 조건이 충족될 때 마다
리소스의 finalizers 필드에서 해당 키(key)를 제거한다.
finalizers 필드가 비워지면 deletionTimestamp 필드가 설정된 오브젝트는 자동으로 삭제된다.
또한 파이널라이저를 사용하여 관리되지 않는 리소스가 삭제되지 않도록 할 수 있다.
파이널라이저의 일반적인 예로는 퍼시스턴트 볼륨(Persistent Volume) 오브젝트가 실수로 삭제되는 것을 방지하는 kubernetes.io/pv-protection가 있다.
파드가 퍼시스턴트 볼륨 오브젝트를 사용 중일 때
쿠버네티스는 pv-protection 파이널라이저를 추가한다.
퍼시스턴트 볼륨을 삭제하려 하면 Terminating 상태가 되지만
파이널라이저가 존재하기 때문에 컨트롤러가 삭제할 수 없다.
파드가 퍼시스턴트 볼륨의 사용을 중지하면
쿠버네티스가 pv-protection 파이널라이저를 해제하고 컨트롤러는 볼륨을 삭제한다.
소유자 참조, 레이블, 파이널라이저
레이블(Label)와 마찬가지로 쿠버네티스에서 소유자 참조(Owner reference)는 오브젝트 간의 관계를 설명하지만 다른 목적으로 사용된다. 컨트롤러(Controller)가 파드와 같은 오브젝트를 관리할 때 레이블을 사용하여 관련 오브젝트의 그룹에 대한 변경 사항을 추적한다. 예를 들어 잡(Job)이 하나 이상의 파드를 생성하면 잡 컨트롤러는 해당 파드에 레이블을 적용하고 클러스터 내 동일한 레이블을 갖는 파드에 대한 변경 사항을 추적한다.
또한, 잡 컨트롤러는 이러한 파드에 소유자 참조도 추가하여 파드를 생성한 잡을 가리킨다. 이 파드가 실행될 때 잡을 삭제하면 쿠버네티스는 사용자 참조(레이블 대신)를 사용하여 클러스터 내 어떤 파드가 정리되어야 하는지 결정한다.
쿠버네티스는 또한 삭제 대상 리소스에 대한 소유자 참조를 식별할 때 파이널라이저를 처리한다.
경우에 따라 파이널라이저는 종속 오브젝트의 삭제를 차단할 수 있으며 이로 인해 대상 소유자 오브젝트가 완전히 삭제되지 않고 예상보다 오래 유지될 수 있다. 이 경우 대상 소유자 및 종속 객체에 대한 파이널라이저와 소유자 참조를 확인해 원인을 해결해야 한다.
참고:
오브젝트가 삭제 상태에 있는 경우, 삭제를 계속하려면 파이널라이저를 수동으로 제거해서는 안 된다. 일반적으로 파이널라이저는 특정한 목적으로 가지고 리소스에 추가되므로, 강제로 제거하면 클러스터에 문제가 발생할 수 있다. 이는 파이널라이저의 목적을 이해하고 다른 방법(예를 들어, 일부 종속 객체를 수동으로 정리하는 것)으로 수행될 때만 수행해야 한다.다음 내용
- 쿠버네티스 블로그에서 파이널라이저를 사용해 삭제 제어하기를 읽어본다.
1.3.9 - 권장 레이블
kubectl과 대시보드와 같은 많은 도구들로 쿠버네티스 오브젝트를 시각화 하고 관리할 수 있다. 공통 레이블 셋은 모든 도구들이 이해할 수 있는 공통의 방식으로 오브젝트를 식별하고 도구들이 상호 운용적으로 작동할 수 있도록 한다.
권장 레이블은 지원 도구 외에도 쿼리하는 방식으로 애플리케이션을 식별하게 한다.
메타데이터는 애플리케이션 의 개념을 중심으로 정리된다. 쿠버네티스는 플랫폼 서비스(PaaS)가 아니며 애플리케이션에 대해 공식적인 개념이 없거나 강요하지 않는다. 대신 애플리케이션은 비공식적이며 메타데이터로 설명된다. 애플리케이션에 포함된 정의는 유연하다.
참고:
메타데이터들은 권장하는 레이블이다. 애플리케이션을 보다 쉽게 관리할 수 있지만 코어 도구에는 필요하지 않다.공유 레이블과 주석에는 공통 접두사인 app.kubernetes.io 가 있다.
접두사가 없는 레이블은 사용자가 개인적으로 사용할 수 있다.
공유 접두사는 공유 레이블이 사용자 정의 레이블을 방해하지 않도록 한다.
레이블
레이블을 최대한 활용하려면 모든 리소스 오브젝트에 적용해야 한다.
| 키 | 설명 | 예시 | 타입 |
|---|---|---|---|
app.kubernetes.io/name |
애플리케이션 이름 | mysql |
문자열 |
app.kubernetes.io/instance |
애플리케이션의 인스턴스를 식별하는 고유한 이름 | mysql-abcxzy |
문자열 |
app.kubernetes.io/version |
애플리케이션의 현재 버전 (예: a semantic version, revision hash 등.) | 5.7.21 |
문자열 |
app.kubernetes.io/component |
아키텍처 내 구성요소 | database |
문자열 |
app.kubernetes.io/part-of |
이 애플리케이션의 전체 이름 | wordpress |
문자열 |
app.kubernetes.io/managed-by |
애플리케이션의 작동을 관리하는 데 사용되는 도구 | helm |
문자열 |
위 레이블의 실제 예시는 다음 스테이트풀셋 오브젝트를 고려한다.
# 아래는 전체 명세의 일부분이다
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
애플리케이션과 애플리케이션 인스턴스
애플리케이션은 동일한 쿠버네티스 클러스터에, 심지어는 동일한 네임스페이스에도 한번 또는 그 이상 설치될 수 있다. 예를 들어, 하나의 쿠버네티스 클러스터에 WordPress가 여러 번 설치되어 각각 서로 다른 웹사이트를 서비스할 수 있다.
애플리케이션의 이름과 애플리케이션 인스턴스 이름은 별도로 기록된다.
예를 들어 WordPress는 애플리케이션 이름으로 app.kubernetes.io/name 이라는 레이블에 wordpress 라는 값을 가지며,
애플리케이션 인스턴스 이름으로는 app.kubernetes.io/instance 라는 레이블에
wordpress-abcxzy 라는 값을 가진다. 이를 통해 애플리케이션과 애플리케이션 인스턴스를
식별할 수 있다. 모든 애플리케이션 인스턴스는 고유한 이름을 가져야 한다.
예시
위 레이블을 사용하는 다른 방식에 대한 예시는 다양한 복잡성이 있다.
단순한 스테이트리스 서비스
Deployment 와 Service 오브젝트를 통해 배포된 단순한 스테이트리스 서비스의 경우를 보자. 다음 두 식별자는 레이블을 가장 간단한 형태로 사용하는 방법을 나타낸다.
Deployment 는 애플리케이션을 실행하는 파드를 감시하는 데 사용한다.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
Service는 애플리케이션을 노출하기 위해 사용한다.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
데이터베이스가 있는 웹 애플리케이션
Helm을 이용해서 데이터베이스(MySQL)을 이용하는 웹 애플리케이션(WordPress)을 설치한 것과 같이 좀 더 복잡한 애플리케이션을 고려할 수 있다. 다음 식별자는 이 애플리케이션을 배포하는 데 사용하는 오브젝트의 시작을 보여준다.
WordPress를 배포하는 데 다음과 같이 Deployment 로 시작한다.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
Service 는 애플리케이션을 노출하기 위해 사용한다.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL은 StatefulSet 에 MySQL의 소속과 상위 애플리케이션에 대한 메타데이터가 포함되어 노출된다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Service 는 WordPress의 일부로 MySQL을 노출하는 데 이용한다.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
MySQL StatefulSet 과 Service 로 MySQL과 WordPress가 더 큰 범위의 애플리케이션에 포함되어 있는 것을 알게 된다.
2 - 클러스터 아키텍처
쿠버네티스 뒤편의 구조와 설계 개념들
2.1 - 노드
쿠버네티스는 컨테이너를 파드내에 배치하고 노드 에서 실행함으로 워크로드를 구동한다. 노드는 클러스터에 따라 가상 또는 물리적 머신일 수 있다. 각 노드는 컨트롤 플레인에 의해 관리되며 파드를 실행하는 데 필요한 서비스를 포함한다.
일반적으로 클러스터에는 여러 개의 노드가 있으며, 학습 또는 리소스가 제한되는 환경에서는 하나만 있을 수도 있다.
노드의 컴포넌트에는 kubelet, 컨테이너 런타임 그리고 kube-proxy가 포함된다.
관리
API 서버에 노드를 추가하는 두가지 주요 방법이 있다.
- 노드의 kubelet으로 컨트롤 플레인에 자체 등록
- 사용자(또는 다른 사용자)가 노드 오브젝트를 수동으로 추가
노드 오브젝트 또는 노드의 kubelet으로 자체 등록한 후 컨트롤 플레인은 새 노드 오브젝트가 유효한지 확인한다. 예를 들어 다음 JSON 매니페스트에서 노드를 만들려는 경우이다.
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
쿠버네티스는 내부적으로 노드 오브젝트를 생성한다(표시한다). 쿠버네티스는
kubelet이 노드의 metadata.name 필드와 일치하는 API 서버에 등록이 되어 있는지 확인한다.
노드가 정상이면(예를 들어 필요한 모든 서비스가 실행중인 경우) 파드를 실행할 수 있게 된다.
그렇지 않으면, 해당 노드는 정상이 될 때까지 모든 클러스터 활동에
대해 무시된다.
노드 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
노드 이름 고유성
이름은 노드를 식별한다. 두 노드는 동시에 같은 이름을 가질 수 없다. 쿠버네티스는 또한 같은 이름의 리소스가 동일한 객체라고 가정한다. 노드의 경우, 동일한 이름을 사용하는 인스턴스가 동일한 상태(예: 네트워크 설정, 루트 디스크 내용)와 노드 레이블과 같은 동일한 속성(attribute)을 갖는다고 암시적으로 가정한다. 인스턴스가 이름을 변경하지 않고 수정된 경우 이로 인해 불일치가 발생할 수 있다. 노드를 대폭 교체하거나 업데이트해야 하는 경우, 기존 노드 오브젝트를 먼저 API 서버에서 제거하고 업데이트 후 다시 추가해야 한다.
노드에 대한 자체-등록(self-registration)
kubelet 플래그 --register-node가 참(기본값)일 경우, kubelet은 API 서버에
스스로 등록을 시도할 것이다. 이는 선호되는 패턴이며, 대부분의 배포판에서 사용된다.
자체-등록에 대해, kubelet은 다음 옵션과 함께 시작된다.
-
--kubeconfig- apiserver에 스스로 인증하기 위한 자격증명에 대한 경로. -
--cloud-provider- 자신에 대한 메터데이터를 읽기 위해 어떻게 클라우드 제공자와 소통할지에 대한 방법. -
--register-node- 자동으로 API 서버에 등록. -
--register-with-taints- 주어진 테인트(taint) 리스트(콤마로 분리된<key>=<value>:<effect>)를 가진 노드 등록.register-node가 거짓이면 동작 안 함. -
--node-ip- 노드의 IP 주소. -
--node-labels- 클러스터에 노드를 등록할 때 추가 할 레이블 (NodeRestriction admission plugin에 의해 적용되는 레이블 제한 사항 참고). -
--node-status-update-frequency- 얼마나 자주 kubelet이 API 서버에 해당 노드 상태를 게시할 지 정의.
Node authorization mode와 NodeRestriction admission plugin이 활성화 되면, 각 kubelet은 자신이 속한 노드의 리소스에 대해서만 생성/수정할 권한을 가진다.
참고:
노드 이름 고유성 섹션에서 언급했듯이,
노드 구성을 업데이트해야 하는 경우 API 서버에 노드를
다시 등록하는 것이 좋다. 예를 들어 kubelet이 --node-labels의 새로운 구성으로
다시 시작되더라도, 동일한 노드 이름이 사용된 경우
레이블이 해당 노드의 등록에 설정되기 때문에 변경 사항이 적용되지 않는다.
노드에 이미 스케줄된 파드는 해당 노드 구성이 kubelet 재시작에 의해 변경된 경우 오작동하거나 문제를 일으킬 수 있다. 예를 들어 이미 실행 중인 파드가 노드에 할당된 새 레이블에 대해 테인트(taint)될 수 있는 반면 해당 파드와 호환되지 않는 다른 파드는 새 레이블을 기반으로 스케줄링된다. 노드 재등록(re-registration)은 모든 파드를 비우고(drain) 다시 적절하게 스케줄링되도록 한다.
수동 노드 관리
kubectl을 사용해서 노드 오브젝트를 생성하고 수정할 수 있다.
노드 오브젝트를 수동으로 생성하려면 kubelet 플래그를 --register-node=false 로 설정한다.
--register-node 설정과 관계 없이 노드 오브젝트를 수정할 수 있다.
예를 들어 기존 노드에 레이블을 설정하거나, 스케줄 불가로 표시할 수 있다.
파드의 노드 셀렉터와 함께 노드의 레이블을 사용해서 스케줄링을 제어할 수 있다. 예를 들어, 사용 가능한 노드의 하위 집합에서만 실행되도록 파드를 제한할 수 있다.
노드를 스케줄 불가로 표시하면 스케줄러가 해당 노드에 새 파드를 배치할 수 없지만, 노드에 있는 기존 파드에는 영향을 미치지 않는다. 이는 노드 재부팅 또는 기타 유지보수 준비 단계에서 유용하다.
노드를 스케줄 불가로 표시하려면 다음을 실행한다.
kubectl cordon $NODENAME
보다 자세한 내용은 안전하게 노드를 드레인(drain)하기 를 참고한다.
참고:
데몬셋(DaemonSet)에 포함되는 일부 파드는 스케줄 불가 노드에서 실행될 수 있다. 일반적으로 데몬셋은 워크로드 애플리케이션을 비우는 경우에도 노드에서 실행되어야 하는 노드 로컬 서비스를 제공한다.노드 상태
노드의 상태는 다음의 정보를 포함한다.
kubectl 을 사용해서 노드 상태와 기타 세부 정보를 볼수 있다.
kubectl describe node <insert-node-name-here>
출력되는 각 섹션은 아래에 설명되어 있다.
주소
이 필드의 용법은 클라우드 제공사업자 또는 베어메탈 구성에 따라 다양하다.
- HostName: 노드의 커널에 의해 알려진 호스트명이다.
--hostname-override파라미터를 통해 치환될 수 있다. - ExternalIP: 일반적으로 노드의 IP 주소는 외부로 라우트 가능 (클러스터 외부에서 이용 가능) 하다 .
- InternalIP: 일반적으로 노드의 IP 주소는 클러스터 내에서만 라우트 가능하다.
컨디션
conditions 필드는 모든 Running 노드의 상태를 기술한다. 컨디션의 예로 다음을 포함한다.
| 노드 컨디션 | 설명 |
|---|---|
Ready |
노드가 상태 양호하며 파드를 수용할 준비가 되어 있는 경우 True, 노드의 상태가 불량하여 파드를 수용하지 못할 경우 False, 그리고 노드 컨트롤러가 마지막 node-monitor-grace-period (기본값 40 기간 동안 노드로부터 응답을 받지 못한 경우) Unknown |
DiskPressure |
디스크 사이즈 상에 압박이 있는 경우, 즉 디스크 용량이 넉넉치 않은 경우 True, 반대의 경우 False |
MemoryPressure |
노드 메모리 상에 압박이 있는 경우, 즉 노드 메모리가 넉넉치 않은 경우 True, 반대의 경우 False |
PIDPressure |
프로세스 상에 압박이 있는 경우, 즉 노드 상에 많은 프로세스들이 존재하는 경우 True, 반대의 경우 False |
NetworkUnavailable |
노드에 대해 네트워크가 올바르게 구성되지 않은 경우 True, 반대의 경우 False |
참고:
커맨드 라인 도구를 사용해서 통제된(cordoned) 노드의 세부 정보를 출력하는 경우 조건에는SchedulingDisabled 이 포함된다. SchedulingDisabled 은 쿠버네티스 API의 조건이 아니며,
대신 통제된(cordoned) 노드는 사양에 스케줄 불가로 표시된다.쿠버네티스 API에서, 노드의 컨디션은 노드 리소스의 .status 부분에
표현된다. 예를 들어, 다음의 JSON 구조는 상태가 양호한 노드를 나타낸다.
"conditions": [
{
"type": "Ready",
"status": "True",
"reason": "KubeletReady",
"message": "kubelet is posting ready status",
"lastHeartbeatTime": "2019-06-05T18:38:35Z",
"lastTransitionTime": "2019-06-05T11:41:27Z"
}
]
ready 컨디션의 status가 pod-eviction-timeout
(kube-controller-manager에 전달된 인수)보다 더 길게 Unknown 또는 False로 유지되는 경우,
노드 컨트롤러가 해당 노드에 할당된 전체 파드에 대해
API를 이용한 축출
을 트리거한다. 기본 축출 타임아웃 기간은
5분 이다.
노드에 접근이 불가할 때와 같은 경우, API 서버는 노드 상의 kubelet과 통신이 불가하다.
API 서버와의 통신이 재개될 때까지 파드 삭제에 대한 결정은 kubelet에 전해질 수 없다.
그 사이, 삭제되도록 스케줄 되어진 파드는 분할된 노드 상에서 계속 동작할 수도 있다.
노드 컨트롤러가 클러스터 내 동작 중지된 것을 확신할 때까지는 파드를 강제로 삭제하지 않는다.
파드가 Terminating 또는 Unknown 상태로 있을 때 접근 불가한 노드 상에서
동작되고 있는 것을 보게 될 수도 있다. 노드가 영구적으로 클러스터에서 삭제되었는지에
대한 여부를 쿠버네티스가 기반 인프라로부터 유추할 수 없는 경우, 노드가 클러스터를 영구적으로
탈퇴하게 되면, 클러스터 관리자는 손수 노드 오브젝트를 삭제해야 할 수도 있다.
쿠버네티스에서 노드 오브젝트를 삭제하면
노드 상에서 동작 중인 모든 파드 오브젝트가 API 서버로부터 삭제되며
파드가 사용하던 이름을 다시 사용할 수 있게 된다.
노드에서 문제가 발생하면, 쿠버네티스 컨트롤 플레인은 자동으로 노드 상태에 영향을 주는 조건과 일치하는 테인트(taints)를 생성한다. 스케줄러는 파드를 노드에 할당할 때 노드의 테인트를 고려한다. 또한 파드는 노드에 특정 테인트가 있더라도 해당 노드에서 동작하도록 톨러레이션(toleration)을 가질 수 있다.
자세한 내용은 컨디션별 노드 테인트하기를 참조한다.
용량과 할당가능
노드 상에 사용 가능한 리소스를 나타낸다. 리소스에는 CPU, 메모리 그리고 노드 상으로 스케줄 되어질 수 있는 최대 파드 수가 있다.
용량 블록의 필드는 노드에 있는 리소스의 총량을 나타낸다. 할당가능 블록은 일반 파드에서 사용할 수 있는 노드의 리소스 양을 나타낸다.
노드에서 컴퓨팅 리소스 예약하는 방법을 배우는 동안 용량 및 할당가능 리소스에 대해 자세히 읽어보자.
정보
커널 버전, 쿠버네티스 버전 (kubelet과 kube-proxy 버전), 컨테이너 런타임 상세 정보 및 노드가 사용하는 운영 체제가 무엇인지와 같은 노드에 대한 일반적인 정보가 기술된다. 이 정보는 Kubelet이 노드에서 수집하여 쿠버네티스 API로 전송한다.
하트비트
쿠버네티스 노드가 보내는 하트비트는 클러스터가 개별 노드가 가용한지를 판단할 수 있도록 도움을 주고, 장애가 발견된 경우 조치를 할 수 있게한다.
노드에는 두 가지 형태의 하트비트가 있다.
노드의 .status에 비하면, 리스는 경량의 리소스이다.
큰 규모의 클러스터에서는 리스를 하트비트에 사용하여
업데이트로 인한 성능 영향을 줄일 수 있다.
kubelet은 노드의 .status 생성과 업데이트 및
관련된 리스의 업데이트를 담당한다.
- kubelet은 상태가 변경되거나 설정된 인터벌보다 오래 업데이트가 없는 경우
노드의
.status를 업데이트한다. 노드의.status업데이트에 대한 기본 인터벌은 접근이 불가능한 노드에 대한 타임아웃인 40초 보다 훨씬 긴 5분이다. - kubelet은 리스 오브젝트를 (기본 업데이트 인터벌인) 매 10초마다
생성하고 업데이트한다. 리스 업데이트는 노드의
.status업데이트와는 독립적이다. 만약 리스 업데이트가 실패하면, kubelet은 200밀리초에서 시작하고 7초의 상한을 갖는 지수적 백오프를 사용해서 재시도한다.
노드 컨트롤러
노드 컨트롤러는 노드의 다양한 측면을 관리하는 쿠버네티스 컨트롤 플레인 컴포넌트이다.
노드 컨트롤러는 노드가 생성되어 유지되는 동안 다양한 역할을 한다. 첫째는 등록 시점에 (CIDR 할당이 사용토록 설정된 경우) 노드에 CIDR 블럭을 할당하는 것이다.
두 번째는 노드 컨트롤러의 내부 노드 리스트를 클라우드 제공사업자의 사용 가능한 머신 리스트 정보를 근거로 최신상태로 유지하는 것이다. 클라우드 환경에서 동작 중일 경우, 노드상태가 불량할 때마다, 노드 컨트롤러는 해당 노드용 VM이 여전히 사용 가능한지에 대해 클라우드 제공사업자에게 묻는다. 사용 가능하지 않을 경우, 노드 컨트롤러는 노드 리스트로부터 그 노드를 삭제한다.
세 번째는 노드의 동작 상태를 모니터링하는 것이다. 노드 컨트롤러는 다음을 담당한다.
- 노드가 접근 불가능(unreachable) 상태가 되는 경우,
노드의
.status필드의Ready컨디션을 업데이트한다. 이 경우에는 노드 컨트롤러가Ready컨디션을Unknown으로 설정한다. - 노드가 계속 접근 불가능 상태로 남아있는 경우, 해당 노드의 모든 파드에 대해서
API를 이용한 축출을
트리거한다. 기본적으로, 노드 컨트롤러는 노드를
Unknown으로 마킹한 뒤 5분을 기다렸다가 최초의 축출 요청을 시작한다.
기본적으로, 노드 컨트롤러는 5 초마다 각 노드의 상태를 체크한다.
체크 주기는 kube-controller-manager 구성 요소의
--node-monitor-period 플래그를 이용하여 설정할 수 있다.
축출 빈도 제한
대부분의 경우, 노드 컨트롤러는 초당 --node-eviction-rate(기본값 0.1)로
축출 속도를 제한한다. 이 말은 10초당 1개의 노드를 초과하여
파드 축출을 하지 않는다는 의미가 된다.
노드 축출 행위는 주어진 가용성 영역 내 하나의 노드가 상태가 불량할
경우 변화한다. 노드 컨트롤러는 영역 내 동시에 상태가 불량한 노드의 퍼센티지가 얼마나 되는지
체크한다(Ready 컨디션은 Unknown 또는
False 값을 가진다).
- 상태가 불량한 노드의 비율이 최소
--unhealthy-zone-threshold(기본값 0.55)가 되면 축출 속도가 감소한다. - 클러스터가 작으면 (즉
--large-cluster-size-threshold노드 이하면 - 기본값 50) 축출이 중지된다. - 이외의 경우, 축출 속도는 초당
--secondary-node-eviction-rate(기본값 0.01)로 감소된다.
이 정책들이 가용성 영역 단위로 실행되어지는 이유는 나머지가 연결되어 있는 동안 하나의 가용성 영역이 컨트롤 플레인으로부터 분할되어 질 수도 있기 때문이다. 만약 클러스터가 여러 클라우드 제공사업자의 가용성 영역에 걸쳐 있지 않는 이상, 축출 매커니즘은 영역 별 가용성을 고려하지 않는다.
노드가 가용성 영역들에 걸쳐 퍼져 있는 주된 이유는 하나의 전체 영역이
장애가 발생할 경우 워크로드가 상태 양호한 영역으로 이전되어질 수 있도록 하기 위해서이다.
그러므로, 하나의 영역 내 모든 노드들이 상태가 불량하면 노드 컨트롤러는
--node-eviction-rate 의 정상 속도로 축출한다. 코너 케이스란 모든 영역이
완전히 상태불량(클러스터 내 양호한 노드가 없는 경우)한 경우이다.
이러한 경우, 노드 컨트롤러는 컨트롤 플레인과 노드 간 연결에 문제가
있는 것으로 간주하고 축출을 실행하지 않는다. (중단 이후 일부 노드가
다시 보이는 경우 노드 컨트롤러는 상태가 양호하지 않거나 접근이 불가능한
나머지 노드에서 파드를 축출한다.)
또한, 노드 컨트롤러는 파드가 테인트를 허용하지 않을 때 NoExecute 테인트 상태의
노드에서 동작하는 파드에 대한 축출 책임을 가지고 있다.
추가로, 노드 컨틀로러는 연결할 수 없거나, 준비되지 않은 노드와 같은 노드 문제에 상응하는
테인트를 추가한다.
이는 스케줄러가 비정상적인 노드에 파드를 배치하지 않게 된다.
리소스 용량 추적
노드 오브젝트는 노드 리소스 용량에 대한 정보: 예를 들어, 사용 가능한 메모리의 양과 CPU의 수를 추적한다. 노드의 자체 등록은 등록하는 중에 용량을 보고한다. 수동으로 노드를 추가하는 경우 추가할 때 노드의 용량 정보를 설정해야 한다.
쿠버네티스 스케줄러는 노드 상에 모든 노드에 대해 충분한 리소스가 존재하도록 보장한다. 스케줄러는 노드 상에 컨테이너에 대한 요청의 합이 노드 용량보다 더 크지 않도록 체크한다. 요청의 합은 kubelet에서 관리하는 모든 컨테이너를 포함하지만, 컨테이너 런타임에 의해 직접적으로 시작된 컨 테이너는 제외되고 kubelet의 컨트롤 범위 밖에서 실행되는 모든 프로세스도 제외된다.
참고:
파드 형태가 아닌 프로세스에 대해 명시적으로 리소스를 확보하려면, 시스템 데몬에 사용할 리소스 예약하기을 본다.노드 토폴로지
기능 상태:
Kubernetes v1.18 [beta]
TopologyManager
기능 게이트(feature gate)를
활성화 시켜두면, kubelet이 리소스 할당 결정을 할 때 토폴로지 힌트를 사용할 수 있다.
자세한 내용은
노드의 컨트롤 토폴로지 관리 정책을 본다.
그레이스풀(Graceful) 노드 셧다운(shutdown)
기능 상태:
Kubernetes v1.21 [beta]
kubelet은 노드 시스템 셧다운을 감지하고 노드에서 실행 중인 파드를 종료하려고 시도한다.
Kubelet은 노드가 종료되는 동안 파드가 일반 파드 종료 프로세스를 따르도록 한다.
그레이스풀 노드 셧다운 기능은 systemd inhibitor locks를 사용하여 주어진 기간 동안 노드 종료를 지연시키므로 systemd에 의존한다.
그레이스풀 노드 셧다운은 1.21에서 기본적으로 활성화된 GracefulNodeShutdown
기능 게이트로
제어된다.
기본적으로, 아래 설명된 두 구성 옵션,
shutdownGracePeriod 및 shutdownGracePeriodCriticalPods 는 모두 0으로 설정되어 있으므로,
그레이스풀 노드 셧다운 기능이 활성화되지 않는다.
기능을 활성화하려면, 두 개의 kubelet 구성 설정을 적절하게 구성하고
0이 아닌 값으로 설정해야 한다.
그레이스풀 셧다운 중에 kubelet은 다음의 두 단계로 파드를 종료한다.
- 노드에서 실행 중인 일반 파드를 종료시킨다.
- 노드에서 실행 중인 중요(critical) 파드를 종료시킨다.
그레이스풀 노드 셧다운 기능은
두 개의 KubeletConfiguration 옵션으로 구성된다.
shutdownGracePeriod:- 노드가 종료를 지연해야 하는 총 기간을 지정한다. 이것은 모든 일반 및 중요 파드의 파드 종료에 필요한 총 유예 기간에 해당한다.
shutdownGracePeriodCriticalPods:- 노드 종료 중에 중요 파드를
종료하는 데 사용되는 기간을 지정한다.
이 값은
shutdownGracePeriod보다 작아야 한다.
- 노드 종료 중에 중요 파드를
종료하는 데 사용되는 기간을 지정한다.
이 값은
예를 들어, shutdownGracePeriod=30s,
shutdownGracePeriodCriticalPods=10s 인 경우, kubelet은 노드 종료를 30초까지
지연시킨다. 종료하는 동안 처음 20(30-10)초는 일반 파드의
유예 종료에 할당되고, 마지막 10초는
중요 파드의 종료에 할당된다.
참고:
그레이스풀 노드 셧다운 과정에서 축출된 파드는 셧다운(shutdown)된 것으로 표시된다.
kubectl get pods 명령을 실행하면 축출된 파드의 상태가 Terminated으로 표시된다.
그리고 kubectl describe pod 명령을 실행하면 노드 셧다운으로 인해 파드가 축출되었음을 알 수 있다.
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
논 그레이스풀 노드 셧다운
기능 상태:
Kubernetes v1.26 [beta]
전달한 명령이 kubelet에서 사용하는 금지 잠금 메커니즘(inhibitor locks mechanism)을 트리거하지 않거나, 또는 사용자 오류(예: ShutdownGracePeriod 및 ShutdownGracePeriodCriticalPods가 제대로 설정되지 않음)로 인해 kubelet의 노드 셧다운 관리자(Node Shutdown Mananger)가 노드 셧다운 액션을 감지하지 못할 수 있다. 자세한 내용은 위의 그레이스풀 노드 셧다운 섹션을 참조한다.
노드가 셧다운되었지만 kubelet의 노드 셧다운 관리자가 이를 감지하지 못하면, 스테이트풀셋에 속한 파드는 셧다운된 노드에 '종료 중(terminating)' 상태로 고착되어 다른 동작 중인 노드로 이전될 수 없다. 이는 셧다운된 노드의 kubelet이 파드를 지울 수 없어서 결국 스테이트풀셋이 동일한 이름으로 새 파드를 만들 수 없기 때문이다. 만약 파드가 사용하던 볼륨이 있다면, 볼륨어태치먼트(VolumeAttachment)도 기존의 셧다운된 노드에서 삭제되지 않아 결국 파드가 사용하던 볼륨이 다른 동작 중인 노드에 연결(attach)될 수 없다. 결과적으로, 스테이트풀셋에서 실행되는 애플리케이션이 제대로 작동하지 않는다. 기존의 셧다운된 노드가 정상으로 돌아오지 못하면, 이러한 파드는 셧다운된 노드에 '종료 중(terminating)' 상태로 영원히 고착될 것이다.
위와 같은 상황을 완화하기 위해, 사용자가 node.kubernetes.io/out-of-service 테인트를 NoExecute 또는 NoSchedule 값으로
추가하여 노드를 서비스 불가(out-of-service) 상태로 표시할 수 있다.
kube-controller-manager에 NodeOutOfServiceVolumeDetach기능 게이트
가 활성화되어 있고, 노드가 이 테인트에 의해 서비스 불가 상태로 표시되어 있는 경우,
노드에 매치되는 톨러레이션이 없다면 노드 상의 파드는 강제로 삭제될 것이고,
노드 상에서 종료되는 파드에 대한 볼륨 해제(detach) 작업은 즉시 수행될 것이다.
이를 통해 서비스 불가 상태 노드의 파드가 빠르게 다른 노드에서 복구될 수 있다.
논 그레이스풀 셧다운 과정 동안, 파드는 다음의 두 단계로 종료된다.
- 매치되는
out-of-service톨러레이션이 없는 파드를 강제로 삭제한다. - 이러한 파드에 대한 볼륨 해제 작업을 즉시 수행한다.
참고:
node.kubernetes.io/out-of-service테인트를 추가하기 전에, 노드가 완전한 셧다운 또는 전원 꺼짐 상태에 있는지 (재시작 중인 것은 아닌지) 확인한다.- 사용자가 서비스 불가 상태 테인트를 직접 추가한 것이기 때문에, 파드가 다른 노드로 옮겨졌고 셧다운 상태였던 노드가 복구된 것을 확인했다면 사용자가 서비스 불가 상태 테인트를 수동으로 제거해야 한다.
파드 우선순위 기반 그레이스풀 노드 셧다운
기능 상태:
Kubernetes v1.23 [alpha]
그레이스풀 노드 셧다운 시 파드 셧다운 순서에 더 많은 유연성을 제공할 수 있도록, 클러스터에 프라이어리티클래스(PriorityClass) 기능이 활성화되어 있으면 그레이스풀 노드 셧다운 과정에서 파드의 프라이어리티클래스가 고려된다. 이 기능으로 그레이스풀 노드 셧다운 시 파드가 종료되는 순서를 클러스터 관리자가 프라이어리티 클래스 기반으로 명시적으로 정할 수 있다.
위에서 기술된 것처럼, 그레이스풀 노드 셧다운 기능은 파드를 중요하지 않은(non-critical) 파드와 중요한(critical) 파드 2단계(phase)로 구분하여 종료시킨다. 셧다운 시 파드가 종료되는 순서를 명시적으로 더 상세하게 정해야 한다면, 파드 우선순위 기반 그레이스풀 노드 셧다운을 사용할 수 있다.
그레이스풀 노드 셧다운 과정에서 파드 우선순위가 고려되기 때문에, 그레이스풀 노드 셧다운이 여러 단계로 일어날 수 있으며, 각 단계에서 특정 프라이어리티 클래스의 파드를 종료시킨다. 정확한 단계와 단계별 셧다운 시간은 kubelet에 설정할 수 있다.
다음과 같이 클러스터에 커스텀 파드 프라이어리티 클래스가 있다고 가정하자.
| 파드 프라이어리티 클래스 이름 | 파드 프라이어리티 클래스 값 |
|---|---|
custom-class-a |
100000 |
custom-class-b |
10000 |
custom-class-c |
1000 |
regular/unset |
0 |
kubelet 환경 설정 안의
shutdownGracePeriodByPodPriority 설정은 다음과 같을 수 있다.
| 파드 프라이어리티 클래스 값 | 종료 대기 시간 |
|---|---|
| 100000 | 10 seconds |
| 10000 | 180 seconds |
| 1000 | 120 seconds |
| 0 | 60 seconds |
이를 나타내는 kubelet 환경 설정 YAML은 다음과 같다.
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 10
- priority: 10000
shutdownGracePeriodSeconds: 180
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60
위의 표에 의하면 priority 값이 100000 이상인 파드는 종료까지 10초만 주어지며,
10000 이상 ~ 100000 미만이면 180초,
1000 이상 ~ 10000 미만이면 120초가 주어진다.
마지막으로, 다른 모든 파드는 종료까지 60초가 주어질 것이다.
모든 클래스에 대해 값을 명시할 필요는 없다. 예를 들어, 대신 다음과 같은 구성을 사용할 수도 있다.
| 파드 프라이어리티 클래스 값 | 종료 대기 시간 |
|---|---|
| 100000 | 300 seconds |
| 1000 | 120 seconds |
| 0 | 60 seconds |
위의 경우, custom-class-b에 속하는 파드와 custom-class-c에 속하는 파드는
동일한 종료 대기 시간을 갖게 될 것이다.
특정 범위에 해당되는 파드가 없으면, kubelet은 해당 범위에 해당되는 파드를 위해 기다려 주지 않는다. 대신, kubelet은 즉시 다음 프라이어리티 클래스 값 범위로 넘어간다.
기능이 활성화되어 있지만 환경 설정이 되어 있지 않으면, 순서 지정 동작이 수행되지 않을 것이다.
이 기능을 사용하려면 GracefulNodeShutdownBasedOnPodPriority
기능 게이트를 활성화해야 하고,
kubelet config의
ShutdownGracePeriodByPodPriority를
파드 프라이어리티 클래스 값과 각 값에 대한 종료 대기 시간을 명시하여
지정해야 한다.
참고:
그레이스풀 노드 셧다운 과정에서 파드 프라이어리티를 고려하는 기능은 쿠버네티스 v1.23에서 알파 기능으로 도입되었다. 쿠버네티스 1.31에서 이 기능은 베타 상태이며 기본적으로 활성화되어 있다.graceful_shutdown_start_time_seconds 및 graceful_shutdown_end_time_seconds 메트릭은
노드 셧다운을 모니터링하기 위해 kubelet 서브시스템에서 방출된다.
스왑(swap) 메모리 관리
기능 상태:
Kubernetes v1.22 [alpha]
쿠버네티스 1.22 이전에는 노드가 스왑 메모리를 지원하지 않았다. 그리고 kubelet은 노드에서 스왑을 발견하지 못한 경우 시작과 동시에 실패하도록 되어 있었다. 1.22부터는 스왑 메모리 지원을 노드 단위로 활성화할 수 있다.
노드에서 스왑을 활성화하려면, NodeSwap 기능 게이트가 kubelet에서
활성화되어야 하며, 명령줄 플래그 --fail-swap-on 또는
구성 설정에서 failSwapOn가
false로 지정되어야 한다.
경고:
메모리 스왑 기능이 활성화되면, 시크릿 오브젝트의 내용과 같은 tmpfs에 기록되었던 쿠버네티스 데이터가 디스크에 스왑될 수 있다.사용자는 또한 선택적으로 memorySwap.swapBehavior를 구성할 수 있으며,
이를 통해 노드가 스왑 메모리를 사용하는 방식을 명시한다. 예를 들면,
memorySwap:
swapBehavior: LimitedSwap
swapBehavior에 가용한 구성 옵션은 다음과 같다.
LimitedSwap: 쿠버네티스 워크로드는 스왑을 사용할 수 있는 만큼으로 제한된다. 쿠버네티스에 의해 관리되지 않는 노드의 워크로드는 여전히 스왑될 수 있다.UnlimitedSwap: 쿠버네티스 워크로드는 요청한 만큼 스왑 메모리를 사용할 수 있으며, 시스템의 최대치까지 사용 가능하다.
만약 memorySwap 구성이 명시되지 않았고 기능 게이트가 활성화되어 있다면,
kubelet은 LimitedSwap 설정과 같은 행동을
기본적으로 적용한다.
LimitedSwap 설정에 대한 행동은 노드가 ("cgroups"으로 알려진)
제어 그룹이 v1 또는 v2 중에서 무엇으로 동작하는가에 따라서 결정된다.
- cgroupsv1: 쿠버네티스 워크로드는 메모리와 스왑의 조합을 사용할 수 있다. 파드의 메모리 제한이 설정되어 있다면 가용 상한이 된다.
- cgroupsv2: 쿠버네티스 워크로드는 스왑 메모리를 사용할 수 없다.
테스트를 지원하고 피드벡을 제공하기 위한 정보는 KEP-2400 및 디자인 제안에서 찾을 수 있다.
다음 내용
- 노드를 구성하는 컴포넌트에 대해 알아본다.
- 노드에 대한 API 정의를 읽어본다.
- 아키텍처 디자인 문서의 노드 섹션을 읽어본다.
- 테인트와 톨러레이션을 읽어본다.
2.2 - 컨트롤 플레인-노드 간 통신
이 문서는 API 서버와 쿠버네티스 클러스터 사이에 대한 통신 경로의 목록을 작성한다. 이는 사용자가 신뢰할 수 없는 네트워크(또는 클라우드 공급자의 완전한 퍼블릭 IP)에서 클러스터를 실행할 수 있도록 네트워크 구성을 강화하기 위한 맞춤 설치를 할 수 있도록 한다.
노드에서 컨트롤 플레인으로의 통신
쿠버네티스에는 "허브 앤 스포크(hub-and-spoke)" API 패턴을 가지고 있다. 노드(또는 노드에서 실행되는 파드들)의 모든 API 사용은 API 서버에서 종료된다. 다른 컨트롤 플레인 컴포넌트 중 어느 것도 원격 서비스를 노출하도록 설계되지 않았다. API 서버는 하나 이상의 클라이언트 인증 형식이 활성화된 보안 HTTPS 포트(일반적으로 443)에서 원격 연결을 수신하도록 구성된다. 특히 익명의 요청 또는서비스 어카운트 토큰이 허용되는 경우, 하나 이상의 권한 부여 형식을 사용해야 한다.
노드는 유효한 클라이언트 자격 증명과 함께 API 서버에 안전하게 연결할 수 있도록 클러스터에 대한 공개 루트 인증서(root certificate)로 프로비전해야 한다. 클라이언트 인증서(client certificate) 형식으로 kubelet의 클라이언트 자격 증명을 사용하는 것은 좋은 방법이다. kubelet 클라이언트 인증서(client certificate)의 자동 프로비저닝은 kubelet TLS 부트스트랩을 참고한다.
API 서버에 연결하려는 파드는 서비스 어카운트를 활용하여 안전하게
쿠버네티스가 공개 루트 인증서(root certificate)와 유효한 베어러 토큰(bearer token)을 파드가 인스턴스화될 때
파드에 자동으로 주입할 수 있다.
kubernetes 서비스(default 네임스페이스의)는 API 서버의 HTTPS 엔드포인트로 리디렉션되는
가상 IP 주소(kube-proxy를 통해)로 구성되어 있다.
컨트롤 플레인 컴포넌트는 보안 포트를 통해 클러스터 API 서버와도 통신한다.
결과적으로, 노드 및 노드에서 실행되는 파드에서 컨트롤 플레인으로 연결하기 위한 기본 작동 모드는 기본적으로 보호되며 신뢰할 수 없는 네트워크 및/또는 공용 네트워크에서 실행될 수 있다.
컨트롤 플레인에서 노드로의 통신
컨트롤 플레인(API 서버)에서 노드로는 두 가지 기본 통신 경로가 있다. 첫 번째는 API 서버에서 클러스터의 각 노드에서 실행되는 kubelet 프로세스이다. 두 번째는 API 서버의 프록시 기능을 통해 API 서버에서 모든 노드, 파드 또는 서비스에 이르는 것이다.
API 서버에서 kubelet으로의 통신
API 서버에서 kubelet으로의 연결은 다음의 용도로 사용된다.
- 파드에 대한 로그를 가져온다.
- 실행 중인 파드에 (보통의 경우 kubectl을 통해) 연결한다.
- kubelet의 포트-포워딩 기능을 제공한다.
위와 같은 연결은 kubelet의 HTTPS 엔드포인트에서 종료된다. 기본적으로, API 서버는 kubelet의 제공(serving) 인증서를 확인하지 않는다. 이는 연결이 중간자 공격(man-in-the-middle)에 시달리게 하며, 신뢰할 수 없는 네트워크 및/또는 공용 네트워크에서 실행하기에 안전하지 않다 .
이 연결을 확인하려면, --kubelet-certificate-authority 플래그를 사용하여
API 서버에 kubelet의 제공(serving) 인증서를 확인하는데 사용할 루트 인증서 번들을 제공한다.
이것이 가능하지 않은 경우, 신뢰할 수 없는 네트워크 또는 공용 네트워크를 통한 연결을 피하기 위해 필요한 경우, API 서버와 kubelet 간 SSH 터널링을 사용한다.
마지막으로, kubelet API를 보호하려면 Kubelet 인증 및/또는 인가를 활성화해야 한다.
API 서버에서 노드, 파드 및 서비스로의 통신
API 서버에서 노드, 파드 또는 서비스로의 연결은 기본적으로 일반 HTTP 연결로 연결되므로
인증되거나 암호화되지 않는다. 이 연결에서 URL을 노드, 파드 또는 서비스 이름에 접두어 https: 을 붙여
보안 HTTPS 연결이 되도록 실행할 수 있지만, HTTPS 엔드포인트가 제공한 인증서의 유효성을 검증하지 않으며
클라이언트 자격 증명도 제공하지 않는다.
그래서 연결이 암호화되는 동안 그 어떤 무결성도 보장되지 않는다.
이러한 연결은 신뢰할 수 없는 네트워크 및/또는 공용 네트워크에서 실행하기에 현재는 안전하지 않다 .
SSH 터널
쿠버네티스는 SSH 터널을 지원하여 컨트롤 플레인에서 노드로의 통신 경로를 보호한다. 이 구성에서, API 서버는 클러스터의 각 노드에 SSH 터널을 시작하고 (포트 22에서 수신 대기하는 ssh 서버에 연결) 터널을 통해 kubelet, 노드, 파드 또는 서비스로 향하는 모든 트래픽을 전달한다. 이 터널은 노드가 실행 중인 네트워크의 외부로 트래픽이 노출되지 않도록 한다.
참고:
SSH 터널은 현재 더 이상 사용되지 않으므로, 수행 중인 작업이 어떤 것인지 모른다면 사용하면 안 된다. Konnectivity 서비스가 SSH 통신 채널을 대체한다.Konnectivity 서비스
기능 상태:
Kubernetes v1.18 [beta]
SSH 터널을 대체로, Konnectivity 서비스는 컨트롤 플레인과 클러스터 간 통신에 TCP 레벨 프록시를 제공한다. Konnectivity 서비스는 컨트롤 플레인 네트워크의 Konnectivity 서버와 노드 네트워크의 Konnectivity 에이전트, 두 부분으로 구성된다. Konnectivity 에이전트는 Konnectivity 서버에 대한 연결을 시작하고 네트워크 연결을 유지한다. Konnectivity 서비스를 활성화한 후, 모든 컨트롤 플레인에서 노드로의 트래픽은 이 연결을 통과한다.
Konnectivity 서비스 태스크에 따라 클러스터에서 Konnectivity 서비스를 설정한다.
2.3 - 리스(Lease)
분산 시스템에는 종종 공유 리소스를 잠그고 노드 간의 활동을 조정하는 메커니즘을 제공하는 "리스(Lease)"가 필요하다.
쿠버네티스에서 "리스" 개념은 coordination.k8s.io API 그룹에 있는 Lease 오브젝트로 표현되며,
노드 하트비트 및 컴포넌트 수준의 리더 선출과 같은 시스템 핵심 기능에서 사용된다.
노드 하트비트
쿠버네티스는 리스 API를 사용하여 kubelet 노드의 하트비트를 쿠버네티스 API 서버에 전달한다.
모든 노드에는 같은 이름을 가진 Lease 오브젝트가 kube-node-lease 네임스페이스에 존재한다.
내부적으로, 모든 kubelet 하트비트는 이 Lease 오브젝트에 대한 업데이트 요청이며,
이 업데이트 요청은 spec.renewTime 필드를 업데이트한다.
쿠버네티스 컨트롤 플레인은 이 필드의 타임스탬프를 사용하여 해당 노드의 가용성을 확인한다.
자세한 내용은 노드 리스 오브젝트를 참조한다.
리더 선출
리스는 쿠버네티스에서도 특정 시간 동안 컴포넌트의 인스턴스 하나만 실행되도록 보장하는 데에도 사용된다.
이는 구성 요소의 한 인스턴스만 활성 상태로 실행되고 다른 인스턴스는 대기 상태여야 하는
kube-controller-manager 및 kube-scheduler와 같은 컨트롤 플레인 컴포넌트의
고가용성 설정에서 사용된다.
API 서버 신원
기능 상태:
Kubernetes v1.26 [beta]
쿠버네티스 v1.26부터, 각 kube-apiserver는 리스 API를 사용하여 시스템의 나머지 부분에 자신의 신원을 게시한다.
그 자체로는 특별히 유용하지는 않지만, 이것은 클라이언트가 쿠버네티스 컨트롤 플레인을 운영 중인 kube-apiserver 인스턴스 수를
파악할 수 있는 메커니즘을 제공한다.
kube-apiserver 리스의 존재는 향후 각 kube-apiserver 간의 조정이 필요할 때
기능을 제공해 줄 수 있다.
각 kube-apiserver가 소유한 리스는 kube-system 네임스페이스에서kube-apiserver-<sha256-hash>라는 이름의
리스 오브젝트를 확인하여 볼 수 있다. 또는 k8s.io/component=kube-apiserver 레이블 설렉터를 사용하여 볼 수도 있다.
$ kubectl -n kube-system get lease -l k8s.io/component=kube-apiserver
NAME HOLDER AGE
kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4 5m33s
kube-apiserver-dz2dqprdpsgnm756t5rnov7yka kube-apiserver-dz2dqprdpsgnm756t5rnov7yka_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
kube-apiserver-fyloo45sdenffw2ugwaz3likua kube-apiserver-fyloo45sdenffw2ugwaz3likua_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
리스 이름에 사용된 SHA256 해시는 kube-apiserver가 보는 OS 호스트 이름을 기반으로 한다.
각 kube-apiserver는 클러스터 내에서 고유한 호스트 이름을 사용하도록 구성해야 한다.
동일한 호스트명을 사용하는 새로운 kube-apiserver 인스턴스는 새 리스 오브젝트를 인스턴스화하는 대신 새로운 소유자 ID를 사용하여 기존 리스를 차지할 수 있다.
kube-apiserver가 사용하는 호스트네임은 kubernetes.io/hostname 레이블의 값을 확인하여 확인할 수 있다.
$ kubectl -n kube-system get lease kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a -o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2022-11-30T15:37:15Z"
labels:
k8s.io/component: kube-apiserver
kubernetes.io/hostname: kind-control-plane
name: kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a
namespace: kube-system
resourceVersion: "18171"
uid: d6c68901-4ec5-4385-b1ef-2d783738da6c
spec:
holderIdentity: kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4
leaseDurationSeconds: 3600
renewTime: "2022-11-30T18:04:27.912073Z"
더 이상 존재하지 않는 kube-apiserver의 만료된 임대는 1시간 후에 새로운 kube-apiserver에 의해 가비지 컬렉션된다.
2.4 - 컨트롤러
로보틱스와 자동화에서 컨트롤 루프 는 시스템 상태를 조절하는 종료되지 않는 루프이다.
컨트롤 루프의 예시: 실내 온도 조절기
사용자는 온도를 설정해서, 사용자가 의도한 상태 를 온도 조절기에 알려준다. 실제 실내 온도는 현재 상태 이다. 온도 조절기는 장비를 켜거나 꺼서 현재 상태를 의도한 상태에 가깝게 만든다.
쿠버네티스에서 컨트롤러는 클러스터 의 상태를 관찰 한 다음, 필요한 경우에 생성 또는 변경을 요청하는 컨트롤 루프이다. 각 컨트롤러는 현재 클러스터 상태를 의도한 상태에 가깝게 이동한다.컨트롤러 패턴
컨트롤러는 적어도 하나 이상의 쿠버네티스 리소스 유형을 추적한다. 이 오브젝트 는 의도한 상태를 표현하는 사양 필드를 가지고 있다. 해당 리소스의 컨트롤러(들)은 현재 상태를 의도한 상태에 가깝게 만드는 역할을 한다.
컨트롤러는 스스로 작업을 수행할 수 있다. 보다 일반적으로, 쿠버네티스에서는 컨트롤러가 API 서버 로 유용한 부수적인 효과가 있는 메시지를 발송한다. 그 예시는 아래에서 볼 수 있다.
API 서버를 통한 제어
잡(Job) 컨트롤러는 쿠버네티스 내장 컨트롤러의 예시이다. 내장 컨트롤러는 클러스터 API 서버와 상호 작용하며 상태를 관리한다.
잡은 단일 파드 또는 여러 파드를 실행하고, 작업을 수행한 다음 중지하는 쿠버네티스 리소스 이다.
(일단 스케줄되면, 파드 오브젝트는 kubelet 의 의도한 상태 중 일부가 된다.)
잡 컨트롤러가 새로운 작업을 확인하면, 클러스터 어딘가에서 노드 집합의 kubelet이 작업을 수행하기에 적합한 수의 파드를 실행하게 한다. 잡 컨트롤러는 어떤 파드 또는 컨테이너를 스스로 실행하지 않는다. 대신, 잡 컨트롤러는 API 서버에 파드를 생성하거나 삭제하도록 지시한다. 컨트롤 플레인의 다른 컴포넌트는 신규 정보 (예약 및 실행해야 하는 새 파드가 있다는 정보)에 대응하여, 결국 해당 작업을 완료시킨다.
새 잡을 생성하고 나면, 의도한 상태는 해당 잡을 완료하는 것이 된다. 잡 컨트롤러는 현재 상태를 의도한 상태에 가깝게 만들며, 사용자가 원하는 잡을 수행하기 위해 파드를 생성해서 잡이 완료에 가까워 지도록 한다.
또한, 컨트롤러는 오브젝트의 설정을 업데이트 한다.
예시: 잡을 위한 작업이 종료된 경우, 잡 컨트롤러는
잡 오브젝트가 Finished 로 표시되도록 업데이트한다.
(이것은 지금 방 온도가 설정한 온도인 것을 표시하기 위해 실내 온도 조절기의 빛을 끄는 것과 약간 비슷하다).
직접 제어
잡과는 대조적으로, 일부 컨트롤러는 클러스터 외부의 것을 변경해야 할 필요가 있다.
예를 들어, 만약 컨트롤 루프를 사용해서 클러스터에 충분한 노드들이 있도록 만드는 경우, 해당 컨트롤러는 필요할 때 새 노드를 설정할 수 있도록 현재 클러스터 외부의 무언가를 필요로 한다.
외부 상태와 상호 작용하는 컨트롤러는 API 서버에서 의도한 상태를 찾은 다음, 외부 시스템과 직접 통신해서 현재 상태를 보다 가깝게 만든다.
(실제로 클러스터의 노드를 수평으로 확장하는 컨트롤러가 있다.)
여기서 중요한 점은 컨트롤러가 의도한 상태를 가져오기 위해 약간의 변화를 주고, 현재 상태를 클러스터의 API 서버에 다시 보고한다는 것이다. 다른 컨트롤 루프는 보고된 데이터를 관찰하고 자체 조치를 할 수 있다.
온도 조절기 예에서 방이 매우 추우면 다른 컨트롤러가 서리 방지 히터를 켤 수도 있다. 쿠버네티스 클러스터에서는 쿠버네티스 확장을 통해 IP 주소 관리 도구, 스토리지 서비스, 클라우드 제공자의 API 및 기타 서비스 등과 간접적으로 연동하여 이를 구현한다.
의도한 상태와 현재 상태
쿠버네티스는 클라우드-네이티브 관점에서 시스템을 관찰하며, 지속적인 변화에 대응할 수 있다.
작업이 발생함에 따라 어떤 시점에서든 클러스터가 변경 될 수 있으며 컨트롤 루프가 자동으로 실패를 바로잡는다. 이는 잠재적으로, 클러스터가 안정적인 상태에 도달하지 못하는 것을 의미한다.
클러스터의 컨트롤러가 실행 중이고 유용한 변경을 수행할 수 있는 한, 전체 상태가 안정적인지 아닌지는 중요하지 않다.
디자인
디자인 원리에 따라, 쿠버네티스는 클러스터 상태의 각 특정 측면을 관리하는 많은 컨트롤러를 사용한다. 가장 일반적으로, 특정 컨트롤 루프 (컨트롤러)는 의도한 상태로서 한 종류의 리소스를 사용하고, 의도한 상태로 만들기 위해 다른 종류의 리소스를 관리한다. 예를 들어, 잡 컨트롤러는 잡 오브젝트(새 작업을 발견하기 위해)와 파드 오브젝트(잡을 실행하고, 완료된 시기를 확인하기 위해)를 추적한다. 이 경우 파드는 잡 컨트롤러가 생성하는 반면, 잡은 다른 컨트롤러가 생성한다.
컨트롤 루프들로 연결 구성된 하나의 모놀리식(monolithic) 집합보다, 간단한 컨트롤러를 여러 개 사용하는 것이 유용하다. 컨트롤러는 실패할 수 있으므로, 쿠버네티스는 이를 허용하도록 디자인되었다.
참고:
동일한 종류의 오브젝트를 만들거나 업데이트하는 여러 컨트롤러가 있을 수 있다. 이면에, 쿠버네티스 컨트롤러는 컨트롤 하고 있는 리소스에 연결된 리소스에만 주의를 기울인다.
예를 들어, 디플로이먼트와 잡을 가지고 있다. 이 두 가지 모두 파드를 생성한다. 잡 컨트롤러는 디플로이먼트가 생성한 파드를 삭제하지 않는다. 이는 컨트롤러가 해당 파드를 구별하기 위해 사용할 수 있는 정보(레이블)가 있기 때문이다.
컨트롤러를 실행하는 방법
쿠버네티스에는 kube-controller-manager 내부에서 실행되는 내장된 컨트롤러 집합이 있다. 이 내장 컨트롤러는 중요한 핵심 동작을 제공한다.
디플로이먼트 컨트롤러와 잡 컨트롤러는 쿠버네티스의 자체("내장" 컨트롤러)로 제공되는 컨트롤러 예시이다. 쿠버네티스를 사용하면 복원력이 뛰어난 컨트롤 플레인을 실행할 수 있으므로, 어떤 내장 컨트롤러가 실패하더라도 다른 컨트롤 플레인의 일부가 작업을 이어서 수행한다.
컨트롤 플레인의 외부에서 실행하는 컨트롤러를 찾아서 쿠버네티스를 확장할 수 있다. 또는, 원하는 경우 새 컨트롤러를 직접 작성할 수 있다. 소유하고 있는 컨트롤러를 파드 집합으로서 실행하거나, 또는 쿠버네티스 외부에서 실행할 수 있다. 가장 적합한 것은 특정 컨트롤러의 기능에 따라 달라진다.
다음 내용
- 쿠버네티스 컨트롤 플레인에 대해 읽기
- 쿠버네티스 오브젝트의 몇 가지 기본 사항을 알아보자.
- 쿠버네티스 API에 대해 더 배워 보자.
- 만약 자신만의 컨트롤러를 작성하기 원한다면, 쿠버네티스 확장하기의 확장 패턴을 본다.
2.5 - 클라우드 컨트롤러 매니저
기능 상태:
Kubernetes v1.11 [beta]
클라우드 인프라스트럭처 기술을 통해 퍼블릭, 프라이빗 그리고 하이브리드 클라우드에서 쿠버네티스를 실행할 수 있다. 쿠버네티스는 컴포넌트간의 긴밀한 결합 없이 자동화된 API 기반의 인프라스트럭처를 신뢰한다.
클라우드 컨트롤러 매니저는 클라우드별 컨트롤 로직을 포함하는 쿠버네티스 컨트롤 플레인 컴포넌트이다. 클라우드 컨트롤러 매니저를 통해 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해 준다.
쿠버네티스와 기본 클라우드 인프라스터럭처 간의 상호 운용성 로직을 분리함으로써, cloud-controller-manager 컴포넌트는 클라우드 공급자가 주요 쿠버네티스 프로젝트와 다른 속도로 기능들을 릴리스할 수 있도록 한다.
클라우드 컨트롤러 매니저는 다양한 클라우드 공급자가 자신의 플랫폼에 쿠버네티스를 통합할 수 있도록 하는 플러그인 메커니즘을 사용해서 구성된다.
디자인
클라우드 컨트롤러 매니저는 컨트롤 플레인에서 복제된 프로세스의 집합으로 실행된다(일반적으로, 파드의 컨테이너). 각 클라우드 컨트롤러 매니저는 단일 프로세스에 여러 컨트롤러를 구현한다.
참고:
또한 사용자는 클라우드 컨트롤러 매니저를 컨트롤 플레인의 일부가 아닌 쿠버네티스 애드온으로 실행할 수도 있다.클라우드 컨트롤러 매니저의 기능
클라우드 컨틀롤러 매니저의 내부 컨트롤러에는 다음 컨트롤러들이 포함된다.
노드 컨트롤러
노드 컨트롤러는 클라우드 인프라스트럭처에 새 서버가 생성될 때 노드 오브젝트를 업데이트하는 역할을 한다. 노드 컨트롤러는 클라우드 공급자의 사용자 테넌시 내에서 실행되는 호스트에 대한 정보를 가져온다. 노드 컨트롤러는 다음 기능들을 수행한다.
- 클라우드 공급자 API를 통해 획득한 해당 서버의 고유 ID를 노드 오브젝트에 업데이트한다.
- 클라우드 관련 정보(예를 들어, 노드가 배포되는 지역과 사용 가능한 리소스(CPU, 메모리 등))를 사용해서 노드 오브젝트에 어노테이션과 레이블을 작성한다.
- 노드의 호스트 이름과 네트워크 주소를 가져온다.
- 노드의 상태를 확인한다. 노드가 응답하지 않는 경우, 이 컨트롤러는 사용자가 이용하는 클라우드 공급자의 API를 통해 서버가 비활성화됨 / 삭제됨 / 종료됨인지 확인한다. 노드가 클라우드에서 삭제된 경우, 컨트롤러는 사용자의 쿠버네티스 클러스터에서 노드 오브젝트를 삭제한다.
일부 클라우드 공급자의 구현에서는 이를 노드 컨트롤러와 별도의 노드 라이프사이클 컨트롤러로 분리한다.
라우트 컨트롤러
라우트 컨트롤러는 사용자의 쿠버네티스 클러스터의 다른 노드에 있는 각각의 컨테이너가 서로 통신할 수 있도록 클라우드에서 라우트를 적절히 구성해야 한다.
클라우드 공급자에 따라 라우트 컨트롤러는 파드 네트워크 IP 주소 블록을 할당할 수도 있다.
서비스 컨트롤러
서비스 는 관리형 로드 밸런서, IP 주소, 네트워크 패킷 필터링 그리고 대상 상태 확인과 같은 클라우드 인프라스트럭처 컴포넌트와 통합된다. 서비스 컨트롤러는 사용자의 클라우드 공급자 API와 상호 작용해서 필요한 서비스 리소스를 선언할 때 로드 밸런서와 기타 인프라스트럭처 컴포넌트를 설정한다.
인가
이 섹션에서는 클라우드 컨트롤러 매니저가 작업을 수행하기 위해 다양한 API 오브젝트에 필요한 접근 권한을 세분화한다.
노드 컨트롤러
노드 컨트롤러는 노드 오브젝트에서만 작동한다. 노드 오브젝트를 읽고, 수정하려면 전체 접근 권한이 필요하다.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
라우트 컨트롤러
라우트 컨트롤러가 노드 오브젝트의 생성을 수신하고 적절하게 라우트를 구성한다. 노드 오브젝트에 대한 접근 권한이 필요하다.
v1/Node:
- Get
서비스 컨트롤러
서비스 컨트롤러는 서비스 오브젝트 생성, 업데이트 그리고 삭제 이벤트를 수신한 다음 해당 서비스에 대한 엔드포인트를 적절하게 구성한다(엔드포인트슬라이스(EndpointSlice)의 경우, kube-controller-manager가 필요에 따라 이들을 관리한다).
서비스에 접근하려면, 목록과 감시 접근 권한이 필요하다. 서비스를 업데이트하려면, 패치와 업데이트 접근 권한이 필요하다.
서비스에 대한 엔드포인트 리소스를 설정하려면 생성, 목록, 가져오기, 감시 그리고 업데이트에 대한 접근 권한이 필요하다.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
그 외의 것들
클라우드 컨트롤러 매니저의 핵심 구현을 위해 이벤트 오브젝트를 생성하고, 안전한 작동을 보장하기 위해 서비스어카운트(ServiceAccounts)를 생성해야 한다.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
클라우드 컨트롤러 매니저의 RBAC 클러스터롤(ClusterRole)은 다음과 같다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
다음 내용
클라우드 컨트롤러 매니저 관리에는 클라우드 컨트롤러 매니저의 실행과 관리에 대한 지침이 있다.
클라우드 컨트롤러 매니저를 사용하기 위해 HA 컨트롤 플레인을 업그레이드하려면, 클라우드 컨트롤러 매니저를 사용하기 위해 복제된 컨트롤 플레인 마이그레이션 하기를 참고한다.
자체 클라우드 컨트롤러 매니저를 구현하거나 기존 프로젝트를 확장하는 방법을 알고 싶은가?
클라우드 컨트롤러 매니저는 Go 인터페이스를 사용함으로써, 어떠한 클라우드에 대한 구현체(implementation)라도 플러그인 될 수 있도록 한다. 구체적으로는, kubernetes/cloud-provider의 cloud.go에 정의된 CloudProvider 인터페이스를 사용한다.
이 문서(노드, 라우트와 서비스)에서 강조된 공유 컨트롤러의 구현과 공유 cloudprovider 인터페이스와 함께 일부 스캐폴딩(scaffolding)은 쿠버네티스 핵심의 일부이다. 클라우드 공급자 전용 구현은 쿠버네티스의 핵심 바깥에 있으며 CloudProvider 인터페이스를 구현한다.
플러그인 개발에 대한 자세한 내용은 클라우드 컨트롤러 매니저 개발하기를 참조한다.
2.6 - 컨테이너 런타임 인터페이스(CRI)
컨테이너 런타임 인터페이스(CRI)는 클러스터 컴포넌트를 다시 컴파일하지 않아도 Kubelet이 다양한 컨테이너 런타임을 사용할 수 있도록 하는 플러그인 인터페이스다.
클러스터의 모든 노드에 동작 중인 컨테이너 런타임이 존재해야, kubelet이 파드들과 컨테이너들을 구동할 수 있다.
컨테이너 런타임 인터페이스(CRI)는 kubelet과 컨테이너 런타임 사이의 통신을 위한 주요 프로토콜이다.
쿠버네티스 컨테이너 런타임 인터페이스(CRI)는 클러스터 컴포넌트 kubelet과 container runtime 사이의 통신을 위한 주요 gRPC 프로토콜을 정의한다.
API
기능 상태:
Kubernetes v1.23 [stable]
Kubelet은 gRPC를 통해 컨테이너 런타임과 연결할 때 클라이언트의 역할을 수행한다.
런타임과 이미지 서비스 엔드포인트는 컨테이너 런타임 내에서 사용 가능해야 하며,
이는 각각 Kubelet 내에서 --image-service-endpoint와 --container-runtime-endpoint
커맨드라인 플래그
를 통해 설정할 수 있다.
쿠버네티스 v1.31에서는, Kubelet은 CRI v1을 사용하는 것을 권장한다.
컨테이너 런타임이 CRI v1 버전을 지원하지 않는다면,
Kubelet은 지원 가능한 이전 지원 버전으로 협상을 시도한다.
또한 v1.31 Kubelet은 CRI v1alpha2버전도 협상할 수 있지만,
해당 버전은 사용 중단(deprecated)으로 간주한다.
Kubelet이 지원되는 CRI 버전을 협상할 수 없는 경우,
Kubelet은 협상을 포기하고 노드로 등록하지 않는다.
업그레이드
쿠버네티스를 업그레이드할 때, Kubelet은 컴포넌트의 재시작 시점에서 최신 CRI 버전을 자동으로 선택하려고 시도한다. 이 과정이 실패하면 위에서 언급한 대로 이전 버전을 선택하는 과정을 거친다. 컨테이너 런타임이 업그레이드되어 gRPC 재다이얼이 필요하다면, 컨테이너 런타임도 처음에 선택된 버전을 지원해야 하며, 그렇지 못한 경우 재다이얼은 실패하게 될 것이다. 이 과정은 Kubelet의 재시작이 필요하다.
다음 내용
- CRI 프로토콜 정의를 자세히 알아보자.
2.7 - 가비지(Garbage) 수집
쿠버네티스가 클러스터 자원을 정리하기 위해 사용하는 다양한 방법을 종합한 용어이다. 다음과 같은 리소스를 정리한다:
- 종료된 잡
- 소유자 참조가 없는 오브젝트
- 사용되지 않는 컨테이너와 컨테이너 이미지
- 반환 정책이 삭제인 스토리지클래스에 의해 동적으로 생성된 퍼시스턴트볼륨
- Stale 또는 만료된 CertificateSigningRequests (CSRs)
- 노드 는 다음과 같은 상황에서 삭제된다:
- 클러스터가 클라우드 컨트롤러 매니저를 사용하는 클라우드
- 클러스터가 클라우드 컨트롤러 매니저와 유사한 애드온을 사용하는 온프레미스
- 노드 리스(Lease) 오브젝트
소유자(Owners)와 종속(dependents)
쿠버네티스의 많은 오브젝트는 owner references를 통해 서로 연결되어 있다.
소유자 참조(Owner references)는 컨트롤 플레인에게 어떤 오브젝트가 서로 종속적인지를 알려준다. 쿠버네티스는 소유자 참조를 사용하여 컨트롤 플레인과 다른 API 클라이언트에게 오브젝트를 삭제하기 전 관련 리소스를 정리하는 기회를 제공한다. 대부분의 경우, 쿠버네티스는 소유자 참조를 자동으로 관리한다.
소유권(Ownership)은 일부 리소스가 사용하는 레이블과 셀렉터
메커니즘과는 다르다. 예를 들어,
EndpointSlice 오브젝트를 생성하는 서비스를
생각해보자. 서비스는 레이블을 사용해 컨트롤 플레인이
어떤 EndpointSlice 오브젝트가 해당 서비스에 의해 사용되는지 판단하는 데 도움을 준다. 레이블과 더불어,
서비스를 대신해 관리되는 각 EndpointSlice 오브젝트는
소유자 참조를 가진다. 소유자 참조는 쿠버네티스의 다른 부분이 제어하지 않는
오브젝트를 방해하는 것을 방지하는 데 도움을 준다.
참고:
교차 네임스페이스(cross-namespace)의 소유자 참조는 디자인상 허용되지 않는다. 네임스페이스 종속 오브젝트는 클러스터 범위 또는 네임스페이스 소유자를 지정할 수 있다. 네임스페이스 소유자는 반드시 종속 오브젝트와 동일한 네임스페이스에 존재해야 한다. 그렇지 않다면, 소유자 참조는 없는 것으로 간주되어, 종속 오브젝트는 모든 소유자가 없는 것으로 확인되면 삭제될 수 있다.
클러스터 범위의 종속 오브젝트는 클러스터 범위의 소유자만 지정할 수 있다. v1.20 이상에서, 클러스터 범위의 종속 오브젝트가 네임스페이스 종류를 소유자로 지정하면, 확인할 수 없는 소유자 참조가 있는 것으로 간주되어 가비지 수집이 될 수 없다.
v1.20 이상에서, 가비지 수집기가 잘못된 교차 네임스페이스 ownerReference
또는 네임스페이스 종류를 참조하는 ownerReference가 있는 클러스터 범위의 종속 항목을 감지하면,
OwnerRefInvalidNamespace가 원인인 경고 이벤트와 유효하지 않은 종속 항목의 involvedObject가 보고된다.
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace
를 실행하여 이러한 종류의 이벤트를 확인할 수 있다.
캐스케이딩(Cascading) 삭제
쿠버네티스는 오브젝트를 삭제할 때 더 이상 소유자 참조가 없는지,
예를 들어 레플리카셋을 삭제할 때, 남겨진 파드가 없는지 확인하고 삭제한다.
오브젝트를 삭제할 때 쿠버네티스가 오브젝트의 종속 오브젝트들을 자동으로 삭제할 지 여부를 제어할 수 있다.
이 과정을 캐스케이딩 삭제라고 한다.
캐스케이딩 삭제에는 다음과 같은 두 가지 종류가 있다.
- 포그라운드 캐스케이딩 삭제(Foreground cascading deletion)
- 백그라운드 캐스케이딩 삭제(Background cascading deletion)
또한 쿠버네티스의 finalizers를 사용하여 가비지 수집이 소유자 참조가 있는 자원을 언제 어떻게 삭제할 것인지 제어할 수 있다.
포그라운드 캐스케이딩 삭제
포그라운드 캐스케이딩 삭제에서는 삭제하려는 소유자 오브젝트가 먼저 삭제 중 상태가 된다. 이 상태에서는 소유자 오브젝트에게 다음과 같은 일이 일어난다:
- 쿠버네티스 API 서버가 오브젝트의
metadata.deletionTimestamp필드를 오브젝트가 삭제 표시된 시간으로 설정한다. - 쿠버네티스 API 서버가
metadata.finalizers필드를foregroundDeletion로 설정한다. - 오브젝트는 삭제 과정이 완료되기 전까지 쿠버네티스 API를 통해 조회할 수 있다.
소유자 오브젝트가 삭제 중 상태가 된 이후, 컨트롤러는 종속 오브젝트들을 삭제한다. 모든 종속 오브젝트들이 삭제되고나면, 컨트롤러가 소유자 오브젝트를 삭제한다. 이 시점에서 오브젝트는 더 이상 쿠버네티스 API를 통해 조회할 수 없다.
포그라운드 캐스케이딩 삭제 중에 소유자 오브젝트의 삭제를 막는
종속 오브젝트는ownerReference.blockOwnerDeletion=true필드를 가진 오브젝트다.
더 자세한 내용은 Use foreground cascading deletion를
참고한다.
백그라운드 캐스케이딩 삭제
백그라운드 캐스케이딩 삭제에서는 쿠버네티스 API 서버가 소유자 오브젝트를 즉시 삭제하고 백그라운드에서 컨트롤러가 종속 오브젝트들을 삭제한다. 쿠버네티스는 수동으로 포그라운드 삭제를 사용하거나 종속 오브젝트를 분리하지 않는다면, 기본적으로 백그라운드 캐스케이딩 삭제를 사용한다.
더 자세한 내용은 Use background cascading deletion를 참고한다.
분리된 종속 (Orphaned dependents)
쿠버네티스가 소유자 오브젝트를 삭제할 때, 남은 종속 오브젝트는 분리된 오브젝트라고 부른다. 기본적으로 쿠버네티스는 종속 오브젝트를 삭제한다. 이 행동을 오버라이드하는 방법을 보려면, Delete owner objects and orphan dependents를 참고한다.
사용되지 않는 컨테이너와 이미지 가비지 수집
kubelet은 사용되지 않는 이미지에 대한 가비지 수집을 5분마다, 컨테이너에 대한 가비지 수집을 1분마다 수행한다. 외부 가비지 수집 도구는 kubelet 의 행동을 중단시키고 존재해야만 하는 컨테이너를 삭제할 수 있으므로 사용을 피해야 한다.
사용되지 않는 컨테이너와 이미지에 대한 가비지 수집 옵션을 구성하려면,
configuration file 사용하여
kubelet 을 수정하거나
KubeletConfiguration 리소스 타입의
가비지 수집과 관련된 파라미터를 수정한다.
컨테이너 이미지 라이프사이클
쿠버네티스는 kubelet의 일부인 이미지 관리자가 cadvisor와 협동하여 모든 이미지의 라이프사이클을 관리한다. kubelet은 가비지 수집 결정을 내릴 때, 다음 디스크 사용량 제한을 고려한다.
HighThresholdPercentLowThresholdPercent
HighThresholdPercent 값을 초과한 디스크 사용량은
마지막으로 사용된 시간을 기준으로 오래된 이미지순서대로 이미지를 삭제하는
가비지 수집을 트리거한다. kubelet은 디스크 사용량이 LowThresholdPercent 값에 도달할 때까지
이미지를 삭제한다.
컨테이너 이미지 가비지 수집
kubelet은 사용자가 정의할 수 있는 다음 변수들을 기반으로 사용되지 않는 컨테이너들을 삭제한다:
MinAge: kubelet이 가비지 수집할 수 있는 최소 나이.0으로 세팅하여 비활성화할 수 있다.MaxPerPodContainer: 각 파드 쌍이 가질 수 있는 죽은 컨테이너의 최대 개수.0으로 세팅하여 비활성화할 수 있다.MaxContainers: 클러스터가 가질 수 있는 죽은 컨테이너의 최대 개수0으로 세팅하여 비활성화할 수 있다.
위 변수와 더불어, kubelet은 식별할 수 없고 삭제된 컨테이너들을 오래된 순서대로 가비지 수집한다.
MaxPerPodContainer와 MaxContainer는
파드의 최대 컨테이너 개수(MaxPerPodContainer)를 유지하는 것이
전체 죽은 컨테이너의 개수 제한(MaxContainers)을 초과하게 될 때,
서로 충돌이 발생할 수 있다.
이 상황에서 kubelet은 충돌을 해결하기 위해 MaxPodPerContainer를 조절한다.
최악의 시나리오에서는 MaxPerPodContainer를 1로 다운그레이드하고
가장 오래된 컨테이너들을 축출한다.
또한, 삭제된 파드가 소유한 컨테이너들은 MinAge보다 오래되었을 때 삭제된다.
참고:
kubelet은 자신이 관리하는 컨테이너에 대한 가비지 수집만을 수행한다.가비지 수집 구성하기
자원을 관리하는 컨트롤러의 옵션을 구성하여 가비지 컬렉션을 수정할 수 있다. 다음 페이지에서 어떻게 가비지 수집을 구성할 수 있는지 확인할 수 있다.
다음 내용
- 쿠버네티스 오브젝트의 소유권에 대해 알아보자.
- 쿠버네티스 finalizers에 대해 알아보자.
- 완료된 잡을 정리하는 TTL 컨트롤러 (beta) 에 대해 알아보자.
3 - 컨테이너
런타임 의존성과 함께 애플리케이션을 패키징하는 기술
실행하는 각 컨테이너는 반복 가능하다. 의존성이 포함된 표준화는 어디에서 실행하던지 동일한 동작을 얻는다는 것을 의미한다.
컨테이너는 기본 호스트 인프라에서 애플리케이션을 분리한다. 따라서 다양한 클라우드 또는 OS 환경에서 보다 쉽게 배포할 수 있다.
쿠버네티스 클러스터에 있는 개별 node는 해당 노드에 할당된 파드를 구성하는 컨테이너들을 실행한다. 파드 내부에 컨테이너들은 같은 노드에서 실행될 수 있도록 같은 곳에 위치하고 함께 스케줄된다.
컨테이너 이미지
컨테이너 이미지는 애플리케이션을 실행하는 데 필요한 모든 것이 포함된 실행할 준비가 되어 있는(ready-to-run) 소프트웨어 패키지이다. 여기에는 실행하는 데 필요한 코드와 모든 런타임, 애플리케이션 및 시스템 라이브러리, 그리고 모든 필수 설정에 대한 기본값이 포함된다.
컨테이너는 스테이트리스하며 불변(immutable)일 것으로 계획되었다. 즉, 이미 실행 중인 컨테이너의 코드를 수정해서는 안된다. 만일 컨테이너화된 애플리케이션에 수정을 가하고 싶다면, 수정 내역을 포함한 새로운 이미지를 빌드하고, 업데이트된 이미지로부터 컨테이너를 새로 생성하는 것이 올바른 방법이다.
컨테이너 런타임
컨테이너 런타임은 컨테이너 실행을 담당하는 소프트웨어이다.
쿠버네티스는 containerd, CRI-O와 같은 컨테이너 런타임 및 모든 Kubernetes CRI (컨테이너 런타임 인터페이스) 구현체를 지원한다.
일반적으로 클러스터에서 파드의 기본 컨테이너 런타임을 선택하도록 허용할 수 있다. 만일 클러스터에서 복수의 컨테이너 런타임을 사용해야 하는 경우, 파드에 대해 런타임클래스(RuntimeClass)을 명시함으로써 쿠버네티스가 특정 컨테이너 런타임으로 해당 컨테이너들을 실행하도록 설정할 수 있다.
또한 런타임클래스을 사용하면 하나의 컨테이너 런타임을 사용하여 복수의 파드들을 각자 다른 설정으로 실행할 수도 있다.
3.1 - 이미지
컨테이너 이미지는 애플리케이션과 모든 소프트웨어 의존성을 캡슐화하는 바이너리 데이터를 나타낸다. 컨테이너 이미지는 독립적으로 실행할 수 있고 런타임 환경에 대해 잘 정의된 가정을 만드는 실행 가능한 소프트웨어 번들이다.
일반적으로 파드에서 참조하기 전에 애플리케이션의 컨테이너 이미지를 생성해서 레지스트리로 푸시한다.
이 페이지는 컨테이너 이미지 개념의 개요를 제공한다.
참고:
(v1.31와 같은 최신 마이너 릴리즈와 같은) 쿠버네티스 릴리즈에 대한 컨테이너 이미지를 찾고 있다면 쿠버네티스 다운로드를 확인하라.이미지 이름
컨테이너 이미지는 일반적으로 pause, example/mycontainer 또는 kube-apiserver 와 같은 이름을 부여한다.
이미지는 또한 레지스트리 호스트 이름을 포함할 수 있다. 예를 들어 fictional.registry.example/imagename
와 같다. 그리고 fictional.registry.example:10443/imagename 와 같이 포트 번호도 포함할 수 있다.
레지스트리 호스트 이름을 지정하지 않으면, 쿠버네티스는 도커 퍼블릭 레지스트리를 의미한다고 가정한다.
이미지 이름 부분 다음에 tag 를 추가할 수 있다(docker 또는 podman 과 같은 명령을 사용할 때와 동일한 방식으로).
태그를 사용하면 동일한 시리즈 이미지의 다른 버전을 식별할 수 있다.
이미지 태그는 소문자와 대문자, 숫자, 밑줄(_),
마침표(.) 및 대시(-)로 구성된다.
이미지 태그 안에서 구분 문자(_, - 그리고 .)를
배치할 수 있는 위치에 대한 추가 규칙이 있다.
태그를 지정하지 않으면, 쿠버네티스는 태그 latest 를 의미한다고 가정한다.
이미지 업데이트
디플로이먼트,
스테이트풀셋, 파드 또는 파드
템플릿은 포함하는 다른 오브젝트를 처음 만들 때 특별히 명시하지 않은 경우
기본적으로 해당 파드에 있는 모든 컨테이너의 풀(pull)
정책은 IfNotPresent로 설정된다. 이 정책은
kubelet이 이미 존재하는
이미지에 대한 풀을 생략하게 한다.
이미지 풀(pull) 정책
컨테이너에 대한 imagePullPolicy와 이미지의 태그는
kubelet이 특정 이미지를 풀(다운로드)하려고 할 때 영향을 준다.
다음은 imagePullPolicy에 설정할 수 있는 값의 목록과
효과이다.
IfNotPresent- 이미지가 로컬에 없는 경우에만 내려받는다.
Always- kubelet이 컨테이너를 기동할 때마다, kubelet이 컨테이너 이미지 레지스트리에 이름과 이미지의 다이제스트가 있는지 질의한다. 일치하는 다이제스트를 가진 컨테이너 이미지가 로컬에 있는 경우, kubelet은 캐시된 이미지를 사용한다. 이외의 경우, kubelet은 검색된 다이제스트를 가진 이미지를 내려받아서 컨테이너를 기동할 때 사용한다.
Never- kubelet은 이미지를 가져오려고 시도하지 않는다. 이미지가 어쨌든 이미 로컬에 존재하는 경우, kubelet은 컨테이너 기동을 시도한다. 이외의 경우 기동은 실패한다. 보다 자세한 내용은 미리 내려받은 이미지를 참조한다.
이미지 제공자에 앞서 깔린 캐시의 의미 체계는 레지스트리에 안정적으로 접근할 수 있는 한,
imagePullPolicy: Always인 경우 조차도 효율적이다.
컨테이너 런타임은 노드에 이미 존재하는 이미지 레이어를 알고
다시 내려받지 않는다.
참고:
프로덕션 환경에서 컨테이너를 배포하는 경우 :latest 태그 사용을 지양해야 하는데,
이미지의 어떤 버전이 기동되고 있는지 추적이 어렵고
제대로 롤백하기 어렵게 되기 때문이다.
대신, v1.42.0과 같이 의미있는 태그를 명기한다.
파드가 항상 컨테이너 이미지의 같은 버전을 사용하는 것을 확실히 하려면,
이미지의 다이제스트를 명기할 수 있다.
<image-name>:<tag>를 <image-name>@<digest>로 교체한다.
(예를 들어, image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2).
이미지 태그를 사용하는 경우, 이미지 레지스트리에서 한 이미지를 나타내는 태그에 코드를 변경하게 되면, 기존 코드와 신규 코드를 구동하는 파드가 섞이게 되고 만다. 이미지 다이제스트를 통해 이미지의 특정 버전을 유일하게 식별할 수 있기 때문에, 쿠버네티스는 매번 해당 이미지 이름과 다이제스트가 명시된 컨테이너를 기동해서 같은 코드를 구동한다. 이미지를 다이제스트로 명시하면 구동할 코드를 고정시켜서 레지스트리에서의 변경으로 인해 버전이 섞이는 일이 발생하지 않도록 해 준다.
파드(및 파드 템플릿)가 생성될 때 구동 중인 워크로드가 태그가 아닌 이미지 다이제스트를 통해 정의되도록 조작해주는 서드-파티 어드미션 컨트롤러가 있다. 이는 레지스트리에서 태그가 변경되는 일이 발생해도 구동 중인 워크로드가 모두 같은 코드를 사용하고 있다는 것을 보장하기를 원하는 경우 유용할 것이다.
기본 이미지 풀 정책
사용자(또는 컨트롤러)가 신규 파드를 API 서버에 요청할 때,
특정 조건에 부합하면 클러스터가 imagePullPolicy 필드를 설정한다.
imagePullPolicy필드를 생략하고 컨테이너 이미지의 태그가:latest인 경우,imagePullPolicy는 자동으로Always로 설정된다.imagePullPolicy필드를 생략하고 컨테이너 이미지의 태그를 명기하지 않은 경우,imagePullPolicy는 자동으로Always로 설정된다.imagePullPolicy필드를 생략하고, 명기한 컨테이너 이미지의 태그가:latest가 아니면,imagePullPolicy는 자동으로IfNotPresent로 설정된다.
참고:
컨테이너의 imagePullPolicy 값은 오브젝트가 처음 created 일 때 항상
설정되고 나중에 이미지 태그가 변경되더라도 업데이트되지 않는다.
예를 들어, 태그가 :latest가 아닌 이미지로 디플로이먼트를 생성하고,
나중에 해당 디플로이먼트의 이미지를 :latest 태그로 업데이트하면
imagePullPolicy 필드가 Always 로 변경되지 않는다. 오브젝트를
처음 생성 한 후 모든 오브젝트의 풀 정책을 수동으로 변경해야 한다.
이미지 풀 강제
이미지를 내려받도록 강제하려면, 다음 중 한가지 방법을 사용한다.
- 컨테이너의
imagePullPolicy를Always로 설정한다. imagePullPolicy를 생략하고 사용할 이미지 태그로:latest를 사용한다. 그러면 사용자가 파드를 요청할 때 쿠버네티스가 정책을Always로 설정한다.imagePullPolicy와 사용할 이미지의 태그를 생략한다. 그러면 사용자가 파드를 요청할 때 쿠버네티스가 정책을Always로 설정한다.- AlwaysPullImages 어드미션 컨트롤러를 활성화 한다.
이미지풀백오프(ImagePullBackOff)
kubelet이 컨테이너 런타임을 사용하여 파드의 컨테이너 생성을 시작할 때,
ImagePullBackOff로 인해 컨테이너가
Waiting 상태에 있을 수 있다.
ImagePullBackOff라는 상태는 (이미지 이름이 잘못됨, 또는 imagePullSecret 없이
비공개 레지스트리에서 풀링 시도 등의 이유로) 쿠버네티스가 컨테이너 이미지를
가져올 수 없기 때문에 컨테이너를 실행할 수 없음을 의미한다. BackOff라는 단어는
쿠버네티스가 백오프 딜레이를 증가시키면서 이미지 풀링을 계속 시도할 것임을 나타낸다.
쿠버네티스는 시간 간격을 늘려가면서 시도를 계속하며, 시간 간격의 상한은 쿠버네티스 코드에 300초(5분)로 정해져 있다.
이미지 인덱스가 있는 다중 아키텍처 이미지
바이너리 이미지를 제공할 뿐만 아니라, 컨테이너 레지스트리는
컨테이너 이미지 인덱스를
제공할 수도 있다. 이미지 인덱스는 컨테이너의 아키텍처별 버전에 대한 여러
이미지 매니페스트를 가리킬 수 있다.
아이디어는 이미지의 이름(예를 들어, pause, example/mycontainer, kube-apiserver)을 가질 수 있다는 것이다.
그래서 다른 시스템들이 사용하고 있는 컴퓨터 아키텍처에 적합한 바이너리 이미지를 가져올 수 있다.
쿠버네티스 자체는 일반적으로 -$(ARCH) 접미사로 컨테이너 이미지의 이름을 지정한다. 이전 버전과의 호환성을 위해,
접미사가 있는 오래된 이미지를 생성한다. 아이디어는 모든 아키텍처에 대한 매니페스트가 있는 pause 이미지와 이전 구성
또는 이전에 접미사로 이미지를 하드 코딩한 YAML 파일과 호환되는 pause-amd64 라고 하는 이미지를 생성한다.
프라이빗 레지스트리 사용
프라이빗 레지스트리는 해당 레지스트리에서 이미지를 읽을 수 있는 키를 요구할 것이다. 자격 증명(credential)은 여러 가지 방법으로 제공될 수 있다.
- 프라이빗 레지스트리에 대한 인증을 위한 노드 구성
- 모든 파드는 구성된 프라이빗 레지스트리를 읽을 수 있음
- 클러스터 관리자에 의한 노드 구성 필요
- Kubelet 자격증명 제공자(Credential Provider)를 통해 프라이빗 레지스트리로부터 동적으로 자격증명을 가져오기
- kubelet은 특정 프라이빗 레지스트리에 대해 자격증명 제공자 실행 플러그인(credential provider exec plugin)을 사용하도록 설정될 수 있다.
- 미리 내려받은(pre-pulled) 이미지
- 모든 파드는 노드에 캐시된 모든 이미지를 사용 가능
- 셋업을 위해서는 모든 노드에 대해서 root 접근이 필요
- 파드에 ImagePullSecrets을 명시
- 자신의 키를 제공하는 파드만 프라이빗 레지스트리에 접근 가능
- 공급 업체별 또는 로컬 확장
- 사용자 정의 노드 구성을 사용하는 경우, 사용자(또는 클라우드 제공자)가 컨테이너 레지스트리에 대한 노드 인증 메커니즘을 구현할 수 있다.
이들 옵션은 아래에서 더 자세히 설명한다.
프라이빗 레지스트리에 인증하도록 노드 구성
크리덴셜 설정에 대한 상세 지침은 사용하는 컨테이너 런타임 및 레지스트리에 따라 다르다. 가장 정확한 정보는 솔루션 설명서를 참조해야 한다.
프라이빗 컨테이너 이미지 레지스트리 구성 예시를 보려면, 프라이빗 레지스트리에서 이미지 가져오기를 참조한다. 해당 예시는 도커 허브에서 제공하는 프라이빗 레지스트리를 사용한다.
인증된 이미지를 가져오기 위한 Kubelet 자격증명 제공자(Credential Provider)
참고:
해당 방식은 kubelet이 자격증명을 동적으로 가져와야 할 때 특히 적절하다. 가장 일반적으로 클라우드 제공자로부터 제공받은 레지스트리에 대해 사용된다. 인증 토큰의 수명이 짧기 때문이다.kubelet에서 플러그인 바이너리를 호출하여 컨테이너 이미지에 대한 레지스트리 자격증명을 동적으로 가져오도록 설정할 수 있다. 이는 프라이빗 레지스트리에서 자격증명을 가져오는 방법 중 가장 강력하며 휘발성이 있는 방식이지만, 활성화하기 위해 kubelet 수준의 구성이 필요하다.
자세한 내용은 kubelet 이미지 자격증명 제공자 설정하기를 참고한다.
config.json 파일 해석
config.json 파일의 해석에 있어서, 기존 도커의 구현과 쿠버네티스의 구현에 차이가 있다.
도커에서는 auths 키에 특정 루트 URL만 기재할 수 있으나,
쿠버네티스에서는 glob URL과 접두사-매칭 경로도 기재할 수 있다.
이는 곧 다음과 같은 config.json도 유효하다는 뜻이다.
{
"auths": {
"*my-registry.io/images": {
"auth": "…"
}
}
}
루트 URL(*my-registry.io)은 다음 문법을 사용하여 매치된다.
pattern:
{ term }
term:
'*' 구분자가 아닌 모든 문자와 매치됨
'?' 구분자가 아닌 문자 1개와 매치됨
'[' [ '^' ] { character-range } ']'
문자 클래스 (비어 있으면 안 됨))
c 문자 c에 매치됨 (c != '*', '?', '\\', '[')
'\\' c 문자 c에 매치됨
character-range:
c 문자 c에 매치됨 (c != '\\', '-', ']')
'\\' c 문자 c에 매치됨
lo '-' hi lo <= c <= hi 인 문자 c에 매치됨
이미지 풀 작업 시, 모든 유효한 패턴에 대해 크리덴셜을 CRI 컨테이너 런타임에 제공할 것이다. 예를 들어 다음과 같은 컨테이너 이미지 이름은 성공적으로 매치될 것이다.
my-registry.io/imagesmy-registry.io/images/my-imagemy-registry.io/images/another-imagesub.my-registry.io/images/my-imagea.sub.my-registry.io/images/my-image
kubelet은 인식된 모든 크리덴셜을 순차적으로 이용하여 이미지 풀을 수행한다. 즉,
config.json에 다음과 같이 여러 항목을 기재할 수도 있다.
{
"auths": {
"my-registry.io/images": {
"auth": "…"
},
"my-registry.io/images/subpath": {
"auth": "…"
}
}
}
이제 컨테이너가 my-registry.io/images/subpath/my-image
이미지를 풀 해야 한다고 명시하면,
kubelet은 크리덴셜을 순차적으로 사용하여 풀을 시도한다.
미리 내려받은 이미지
참고:
이 방법은 노드의 구성을 제어할 수 있는 경우에만 적합하다. 이 방법은 클라우드 제공자가 노드를 관리하고 자동으로 교체한다면 안정적으로 작동하지 않을 것이다.기본적으로, kubelet은 지정된 레지스트리에서 각 이미지를 풀 하려고 한다.
그러나, 컨테이너의 imagePullPolicy 속성이 IfNotPresent 또는 Never으로 설정되어 있다면,
로컬 이미지가 사용된다(우선적으로 또는 배타적으로).
레지스트리 인증의 대안으로 미리 풀 된 이미지에 의존하고 싶다면, 클러스터의 모든 노드가 동일한 미리 내려받은 이미지를 가지고 있는지 확인해야 한다.
이것은 특정 이미지를 속도를 위해 미리 로드하거나 프라이빗 레지스트리에 대한 인증의 대안으로 사용될 수 있다.
모든 파드는 미리 내려받은 이미지에 대해 읽기 접근 권한을 가질 것이다.
파드에 ImagePullSecrets 명시
참고:
이 방법은 프라이빗 레지스트리의 이미지를 기반으로 컨테이너를 실행하는 데 권장된다.쿠버네티스는 파드에 컨테이너 이미지 레지스트리 키를 명시하는 것을 지원한다.
imagePullSecrets은 모두 파드와 동일한 네임스페이스에 있어야 한다.
참조되는 시크릿의 타입은 kubernetes.io/dockercfg 이거나 kubernetes.io/dockerconfigjson 이어야 한다.
도커 구성으로 시크릿 생성
레지스트리에 인증하기 위해서는, 레지스트리 호스트네임 뿐만 아니라, 사용자 이름, 비밀번호 및 클라이언트 이메일 주소를 알아야 한다. 대문자 값을 적절히 대체하여, 다음 커맨드를 실행한다.
kubectl create secret docker-registry <name> --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
만약 도커 자격 증명 파일이 이미 존재한다면, 위의 명령을 사용하지 않고, 자격 증명 파일을 쿠버네티스 시크릿으로 가져올 수 있다. 기존 도커 자격 증명으로 시크릿 생성에서 관련 방법을 설명하고 있다.
kubectl create secret docker-registry는
하나의 프라이빗 레지스트리에서만 작동하는 시크릿을 생성하기 때문에,
여러 프라이빗 컨테이너 레지스트리를 사용하는 경우 특히 유용하다.
참고:
파드는 이미지 풀 시크릿을 자신의 네임스페이스에서만 참조할 수 있다. 따라서 이 과정은 네임스페이스 당 한 번만 수행될 필요가 있다.파드의 imagePullSecrets 참조
이제, imagePullSecrets 섹션을 파드의 정의에 추가함으로써 해당 시크릿을
참조하는 파드를 생성할 수 있다.
예를 들면 다음과 같다.
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
이것은 프라이빗 레지스트리를 사용하는 각 파드에 대해서 수행될 필요가 있다.
그러나, 이 필드의 셋팅은 서비스 어카운트 리소스에 imagePullSecrets을 셋팅하여 자동화할 수 있다.
자세한 지침을 위해서는 서비스 어카운트에 ImagePullSecrets 추가를 확인한다.
이것은 노드 당 .docker/config.json와 함께 사용할 수 있다. 자격 증명은
병합될 것이다.
유스케이스
프라이빗 레지스트리를 구성하기 위한 많은 솔루션이 있다. 다음은 여러 가지 일반적인 유스케이스와 제안된 솔루션이다.
- 비소유 이미지(예를 들어, 오픈소스)만 실행하는 클러스터의 경우. 이미지를 숨길 필요가 없다.
- 퍼블릭 레지스트리의 퍼블릭 이미지를 사용한다.
- 설정이 필요 없다.
- 일부 클라우드 제공자는 퍼블릭 이미지를 자동으로 캐시하거나 미러링하므로, 가용성이 향상되고 이미지를 가져오는 시간이 줄어든다.
- 퍼블릭 레지스트리의 퍼블릭 이미지를 사용한다.
- 모든 클러스터 사용자에게는 보이지만, 회사 외부에는 숨겨야하는 일부 독점 이미지를
실행하는 클러스터의 경우.
- 호스트된 프라이빗 레지스트리를 사용한다.
- 프라이빗 레지스트리에 접근해야 하는 노드에 수동 설정이 필요할 수 있다
- 또는, 방화벽 뒤에서 읽기 접근 권한을 가진 내부 프라이빗 레지스트리를 실행한다.
- 쿠버네티스 구성은 필요하지 않다.
- 이미지 접근을 제어하는 호스팅된 컨테이너 이미지 레지스트리 서비스를 사용한다.
- 그것은 수동 노드 구성에 비해서 클러스터 오토스케일링과 더 잘 동작할 것이다.
- 또는, 노드의 구성 변경이 불편한 클러스터에서는,
imagePullSecrets를 사용한다.
- 호스트된 프라이빗 레지스트리를 사용한다.
- 독점 이미지를 가진 클러스터로, 그 중 일부가 더 엄격한 접근 제어를 필요로 하는 경우.
- AlwaysPullImages 어드미션 컨트롤러가 활성화되어 있는지 확인한다. 그렇지 않으면, 모든 파드가 잠재적으로 모든 이미지에 접근 권한을 가진다.
- 민감한 데이터는 이미지 안에 포장하는 대신, "시크릿" 리소스로 이동한다.
- 멀티-테넌트 클러스터에서 각 테넌트가 자신의 프라이빗 레지스트리를 필요로 하는 경우.
- AlwaysPullImages 어드미션 컨트롤러가 활성화되어 있는지 확인한다. 그렇지 않으면, 모든 파드가 잠재적으로 모든 이미지에 접근 권한을 가진다.
- 인가가 요구되도록 프라이빗 레지스트리를 실행한다.
- 각 테넌트에 대한 레지스트리 자격 증명을 생성하고, 시크릿에 넣고, 각 테넌트 네임스페이스에 시크릿을 채운다.
- 테넌트는 해당 시크릿을 각 네임스페이스의 imagePullSecrets에 추가한다.
다중 레지스트리에 접근해야 하는 경우, 각 레지스트리에 대해 하나의 시크릿을 생성할 수 있다.
다음 내용
3.2 - 컨테이너 환경 변수
이 페이지는 컨테이너 환경에서 컨테이너에 가용한 리소스에 대해 설명한다.
컨테이너 환경
쿠버네티스 컨테이너 환경은 컨테이너에 몇 가지 중요한 리소스를 제공한다.
컨테이너 정보
컨테이너의 호스트네임 은 컨테이너가 동작 중인 파드의 이름과 같다.
그것은 hostname 커맨드 또는 libc의
gethostname
함수 호출을 통해서 구할 수 있다.
파드 이름과 네임스페이스는 다운워드(Downward) API를 통해 환경 변수로 구할 수 있다.
컨테이너 이미지에 정적으로 명시된 환경 변수와 마찬가지로, 파드 정의에서의 사용자 정의 환경 변수도 컨테이너가 사용할 수 있다.
클러스터 정보
컨테이너가 생성될 때 실행 중이던 모든 서비스의 목록은 환경 변수로 해당 컨테이너에서 사용할 수 있다. 이 목록은 새로운 컨테이너의 파드 및 쿠버네티스 컨트롤 플레인 서비스와 동일한 네임스페이스 내에 있는 서비스로 한정된다.
bar 라는 이름의 컨테이너에 매핑되는 foo 라는 이름의 서비스에 대해서는, 다음의 형태로 변수가 정의된다.
FOO_SERVICE_HOST=<서비스가 동작 중인 호스트>
FOO_SERVICE_PORT=<서비스가 동작 중인 포트>
서비스에 지정된 IP 주소가 있고 DNS 애드온이 활성화된 경우, DNS를 통해서 컨테이너가 서비스를 사용할 수 있다.
다음 내용
- 컨테이너 라이프사이클 훅(hooks)에 대해 더 배워 보기.
- 컨테이너 라이프사이클 이벤트에 핸들러 부착 실제 경험 얻기.
3.3 - 런타임클래스(RuntimeClass)
기능 상태:
Kubernetes v1.20 [stable]
이 페이지는 런타임클래스 리소스와 런타임 선택 메커니즘에 대해서 설명한다.
런타임클래스는 컨테이너 런타임을 구성을 선택하는 기능이다. 컨테이너 런타임 구성은 파드의 컨테이너를 실행하는 데 사용된다.
동기
서로 다른 파드간에 런타임클래스를 설정하여 성능과 보안의 균형을 유지할 수 있다. 예를 들어, 일부 작업에서 높은 수준의 정보 보안 보증이 요구되는 경우, 하드웨어 가상화를 이용하는 컨테이너 런타임으로 파드를 실행하도록 예약하는 선택을 할 수 있다. 그러면 몇가지 추가적인 오버헤드는 있지만 대체 런타임을 추가 분리하는 유익이 있다.
또한 런타임클래스를 사용하여 컨테이너 런타임이 같으나 설정이 다른 여러 파드를 실행할 수 있다.
셋업
- CRI 구현(implementation)을 노드에 설정(런타임에 따라서).
- 상응하는 런타임클래스 리소스 생성.
1. CRI 구현을 노드에 설정
런타임클래스를 통한 가능한 구성은 컨테이너 런타임 인터페이스(CRI) 구현에 의존적이다. 사용자의 CRI 구현에 따른 설정 방법은 연관된 문서를 통해서 확인한다(아래).
참고:
런타임클래스는 기본적으로 클러스터 전체에 걸쳐 동질의 노드 설정 (모든 노드가 컨테이너 런타임에 준하는 동일한 방식으로 설정되었음을 의미)을 가정한다. 이종의(heterogeneous) 노드 설정을 지원하기 위해서는, 아래 스케줄을 참고한다.해당 설정은 상응하는 handler 이름을 가지며, 이는 런타임클래스에 의해서 참조된다.
런타임 핸들러는 유효한 DNS 1123 서브도메인(알파-숫자 + -와 .문자)을 가져야 한다.
2. 상응하는 런타임클래스 리소스 생성
1단계에서 셋업 한 설정은 연관된 handler 이름을 가져야 하며, 이를 통해서 설정을 식별할 수 있다.
각 런타임 핸들러(그리고 선택적으로 비어있는 "" 핸들러)에 대해서, 상응하는 런타임클래스 오브젝트를 생성한다.
현재 런타임클래스 리소스는 런타임클래스 이름(metadata.name)과 런타임 핸들러
(handler)로 단 2개의 중요 필드만 가지고 있다. 오브젝트 정의는 다음과 같은 형태이다.
# 런타임클래스는 node.k8s.io API 그룹에 정의되어 있음
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
# 런타임클래스 참조에 사용될 이름
# 런타임클래스는 네임스페이스가 없는 리소스임
name: myclass
# 상응하는 CRI 설정의 이름
handler: myconfiguration
런타임클래스 오브젝트의 이름은 유효한 DNS 레이블 이름어이야 한다.
참고:
런타임클래스 쓰기 작업(create/update/patch/delete)은 클러스터 관리자로 제한할 것을 권장한다. 이것은 일반적으로 기본 설정이다. 더 자세한 정보는 권한 개요를 참고한다.사용
클러스터에 런타임클래스를 설정하고 나면,
다음과 같이 파드 스펙에 runtimeClassName를 명시하여 해당 런타임클래스를 사용할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
이것은 kubelet이 지명된 런타임클래스를 사용하여 해당 파드를 실행하도록 지시할 것이다.
만약 지명된 런타임클래스가 없거나, CRI가 상응하는 핸들러를 실행할 수 없는 경우, 파드는
Failed 터미널 단계로 들어간다.
에러 메시지에 상응하는 이벤트를
확인한다.
만약 명시된 runtimeClassName가 없다면, 기본 런타임 핸들러가 사용되며,
런타임클래스 기능이 비활성화되었을 때와 동일하게 동작한다.
CRI 구성
CRI 런타임 설치에 대한 자세한 내용은 CRI 설치를 확인한다.
containerd
런타임 핸들러는 containerd의 구성 파일인 /etc/containerd/config.toml 통해 설정한다.
유효한 핸들러는 runtimes 단락 아래에서 설정한다.
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
더 자세한 내용은 containerd의 구성 문서를 살펴본다.
CRI-O
런타임 핸들러는 CRI-O의 구성파일인 /etc/crio/crio.conf을 통해 설정한다.
crio.runtime 테이블 아래에
유효한 핸들러를 설정한다.
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
더 자세한 것은 CRI-O의 설정 문서를 본다.
스케줄
기능 상태:
Kubernetes v1.16 [beta]
RuntimeClass에 scheduling 필드를 지정하면, 이 RuntimeClass로 실행되는 파드가
이를 지원하는 노드로 예약되도록 제약 조건을 설정할 수 있다.
scheduling이 설정되지 않은 경우 이 RuntimeClass는 모든 노드에서 지원되는 것으로 간주된다.
파드가 지정된 런타임클래스를 지원하는 노드에 안착한다는 것을 보장하려면,
해당 노드들은 runtimeClass.scheduling.nodeSelector 필드에서 선택되는 공통 레이블을 가져야한다.
런타임 클래스의 nodeSelector는 파드의 nodeSelector와 어드미션 시 병합되어서, 실질적으로
각각에 의해 선택된 노드의 교집합을 취한다. 충돌이 있는 경우,
파드는 거부된다.
지원되는 노드가 테인트(taint)되어서 다른 런타임클래스 파드가 노드에서 구동되는 것을 막고 있다면,
tolerations를 런타임클래스에 추가할 수 있다. nodeSelector를 사용하면, 어드미션 시
해당 톨러레이션(toleration)이 파드의 톨러레이션과 병합되어, 실질적으로 각각에 의해 선택된
노드의 합집합을 취한다.
노드 셀렉터와 톨러레이션 설정에 대해 더 배우려면 노드에 파드 할당을 참고한다.
파드 오버헤드
기능 상태:
Kubernetes v1.24 [stable]
파드 실행과 연관되는 오버헤드 리소스를 지정할 수 있다. 오버헤드를 선언하면 클러스터(스케줄러 포함)가 파드와 리소스에 대한 결정을 내릴 때 처리를 할 수 있다.
파드 오버헤드는 런타임 클래스에서 overhead 필드를 통해 정의된다. 이 필드를 사용하면,
해당 런타임 클래스를 사용해서 구동 중인 파드의 오버헤드를 특정할 수 있고 이 오버헤드가
쿠버네티스 내에서 처리된다는 것을 보장할 수 있다.
다음 내용
- 런타임클래스 설계
- 런타임클래스 스케줄링 설계
- 파드 오버헤드 개념에 대해 읽기
- 파드 오버헤드 기능 설계
3.4 - 컨테이너 라이프사이클 훅(Hook)
이 페이지는 kubelet이 관리하는 컨테이너가 관리 라이프사이클 동안의 이벤트에 의해 발동되는 코드를 실행하기 위해서 컨테이너 라이프사이클 훅 프레임워크를 사용하는 방법에 대해서 설명한다.
개요
Angular와 같이, 컴포넌트 라이프사이클 훅을 가진 많은 프로그래밍 언어 프레임워크와 유사하게, 쿠버네티스도 컨테이너에 라이프사이클 훅을 제공한다. 훅은 컨테이너가 관리 라이프사이클의 이벤트를 인지하고 상응하는 라이프사이클 훅이 실행될 때 핸들러에 구현된 코드를 실행할 수 있게 한다.
컨테이너 훅
컨테이너에 노출되는 훅은 두 가지가 있다.
PostStart
이 훅은 컨테이너가 생성된 직후에 실행된다. 그러나, 훅이 컨테이너 엔트리포인트에 앞서서 실행된다는 보장은 없다. 파라미터는 핸들러에 전달되지 않는다.
PreStop
이 훅은 API 요청이나 활성 프로브(liveness probe) 실패, 선점, 자원 경합
등의 관리 이벤트로 인해 컨테이너가 종료되기 직전에 호출된다. 컨테이너가 이미
terminated 또는 completed 상태인 경우에는 PreStop 훅 요청이 실패하며,
훅은 컨테이너를 중지하기 위한 TERM 신호가 보내지기 이전에 완료되어야 한다. 파드의 그레이스 종료
기간(termination grace period)의 초읽기는 PreStop 훅이 실행되기 전에 시작되어,
핸들러의 결과에 상관없이 컨테이너가 파드의 그레이스 종료 기간 내에 결국 종료되도록 한다.
어떠한 파라미터도 핸들러에게 전달되지 않는다.
종료 동작에 더 자세한 대한 설명은 파드의 종료에서 찾을 수 있다.
훅 핸들러 구현
컨테이너는 훅의 핸들러를 구현하고 등록함으로써 해당 훅에 접근할 수 있다. 구현될 수 있는 컨테이너의 훅 핸들러에는 두 가지 유형이 있다.
- Exec - 컨테이너의 cgroups와 네임스페이스 안에서,
pre-stop.sh와 같은, 특정 커맨드를 실행. 커맨드에 의해 소비된 리소스는 해당 컨테이너에 대해 계산된다. - HTTP - 컨테이너의 특정 엔드포인트에 대해서 HTTP 요청을 실행.
훅 핸들러 실행
컨테이너 라이프사이클 관리 훅이 호출되면,
쿠버네티스 관리 시스템은 훅 동작에 따라 핸들러를 실행하고,
httpGet 와 tcpSocket 은 kubelet 프로세스에 의해 실행되고, exec 은 컨테이너에서 실행된다.
훅 핸들러 호출은 해당 컨테이너를 포함하고 있는 파드의 컨텍스트와 동기적으로 동작한다.
이것은 PostStart 훅에 대해서,
훅이 컨테이너 엔트리포인트와는 비동기적으로 동작함을 의미한다.
그러나, 만약 해당 훅이 너무 오래 동작하거나 어딘가에 걸려 있다면,
컨테이너는 running 상태에 이르지 못한다.
PreStop 훅은 컨테이너 중지 신호에서 비동기적으로 실행되지 않는다. 훅은
TERM 신호를 보내기 전에 실행을 완료해야 한다. 실행 중에 PreStop 훅이 중단되면,
파드의 단계는 Terminating 이며 terminationGracePeriodSeconds 가
만료된 후 파드가 종료될 때까지 남아 있다. 이 유예 기간은 PreStop 훅이
실행되고 컨테이너가 정상적으로 중지되는 데 걸리는 총 시간에 적용된다. 예를 들어,
terminationGracePeriodSeconds 가 60이고, 훅이 완료되는 데 55초가 걸리고,
컨테이너가 신호를 수신한 후 정상적으로 중지하는 데 10초가 걸리면, terminationGracePeriodSeconds 이후
컨테이너가 정상적으로 중지되기 전에 종료된다. 이 두 가지 일이 발생하는 데
걸리는 총 시간(55+10)보다 적다.
만약 PostStart 또는 PreStop 훅이 실패하면,
그것은 컨테이너를 종료시킨다.
사용자는 훅 핸들러를 가능한 한 가볍게 만들어야 한다. 그러나, 컨테이너가 멈추기 전 상태를 저장하는 것과 같이, 오래 동작하는 커맨드가 의미 있는 경우도 있다.
훅 전달 보장
훅 전달은 한 번 이상 으로 의도되어 있는데,
이는 PostStart 또는 PreStop와 같은 특정 이벤트에 대해서,
훅이 여러 번 호출될 수 있다는 것을 의미한다.
이것을 올바르게 처리하는 것은 훅의 구현에 달려 있다.
일반적으로, 전달은 단 한 번만 이루어진다. 예를 들어, HTTP 훅 수신기가 다운되어 트래픽을 받을 수 없는 경우에도, 재전송을 시도하지 않는다. 그러나, 드문 경우로, 이중 전달이 발생할 수 있다. 예를 들어, 훅을 전송하는 도중에 kubelet이 재시작된다면, Kubelet이 구동된 후에 해당 훅은 재전송될 것이다.
훅 핸들러 디버깅
훅 핸들러의 로그는 파드 이벤트로 노출되지 않는다.
만약 핸들러가 어떠한 이유로 실패하면, 핸들러는 이벤트를 방송한다.
PostStart의 경우 FailedPostStartHook 이벤트이며,
PreStop의 경우 FailedPreStopHook 이벤트이다.
실패한 FailedPostStartHook 이벤트를 직접 생성하려면, lifecycle-events.yaml 파일을 수정하여 postStart 명령을 "badcommand"로 변경하고 이를 적용한다.
다음은 kubectl describe pod lifecycle-demo 를 실행하여 볼 수 있는 이벤트 출력 예시이다.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
다음 내용
- 컨테이너 환경에 대해 더 배우기.
- 컨테이너 라이프사이클 이벤트에 핸들러 부착 실습 경험하기.
4 - 쿠버네티스에서의 윈도우
4.1 - 쿠버네티스에서의 윈도우 컨테이너
윈도우 애플리케이션은 많은 조직에서 실행되는 서비스 및 애플리케이션의 상당 부분을 구성한다. 윈도우 컨테이너는 프로세스와 패키지 종속성을 캡슐화하는 현대적인 방법을 제공하여, 데브옵스(DevOps) 사례를 더욱 쉽게 사용하고 윈도우 애플리케이션의 클라우드 네이티브 패턴을 따르도록 한다.
윈도우 기반 애플리케이션과 리눅스 기반 애플리케이션에 투자한 조직은 워크로드를 관리하기 위해 별도의 오케스트레이터를 찾을 필요가 없으므로, 운영 체제와 관계없이 배포 전반에 걸쳐 운영 효율성이 향상된다.
쿠버네티스에서의 윈도우 노드
쿠버네티스에서 윈도우 컨테이너 오케스트레이션을 활성화하려면, 기존 리눅스 클러스터에 윈도우 노드를 추가한다. 쿠버네티스에서 파드 내의 윈도우 컨테이너를 스케줄링하는 것은 리눅스 기반 컨테이너를 스케줄링하는 것과 유사하다.
윈도우 컨테이너를 실행하려면, 쿠버네티스 클러스터가 여러 운영 체제를 포함하고 있어야 한다. 컨트롤 플레인은 리눅스에서만 실행할 수 있는 반면, 워커 노드는 윈도우 또는 리눅스를 실행할 수 있다.
노드의 운영 체제가 Windows Server 2019인 경우에만 윈도우 노드로써 사용할 수 있다.
이 문서에서 윈도우 컨테이너라는 용어는 프로세스 격리 기반의 윈도우 컨테이너를 의미한다. 쿠버네티스는 Hyper-V 격리 기반의 윈도우 컨테이너를 지원하지 않는다.
호환성 및 제한
일부 노드 기능은 특정 컨테이너 런타임을 사용할 때에만 이용 가능하며, 윈도우 노드에서 사용할 수 없는 기능도 있다. 예시는 다음과 같다.
- HugePages: 윈도우 컨테이너에서 지원되지 않음
- 특권을 가진(Privileged) 컨테이너: 윈도우 컨테이너에서 지원되지 않음. HostProcess 컨테이너가 비슷한 기능을 제공한다.
- TerminationGracePeriod: containerD를 필요로 한다.
공유 네임스페이스(shared namespaces)의 모든 기능이 지원되는 것은 아니다. 자세한 내용은 API 호환성을 참조한다.
윈도우 OS 버전 호환성에서 쿠버네티스와의 동작이 테스트된 윈도우 버전 상세사항을 확인한다.
API 및 kubectl의 관점에서, 윈도우 컨테이너는 리눅스 기반 컨테이너와 거의 같은 방식으로 작동한다. 그러나, 주요 기능에서 몇 가지 주목할 만한 차이점이 있으며, 이 섹션에서 소개된다.
리눅스와의 비교
윈도우에서 주요 쿠버네티스 요소는 리눅스와 동일한 방식으로 작동한다. 이 섹션에서는 몇 가지 주요 워크로드 추상화 및 이들이 윈도우에서 어떻게 매핑되는지를 다룬다.
-
파드는 쿠버네티스의 기본 빌딩 블록이며, 이는 쿠버네티스 오브젝트 모델에서 생성하고 배포하는 가장 작고 간단한 단위임을 의미한다. 동일한 파드에 윈도우 컨테이너와 리눅스 컨테이너를 배포할 수 없다. 파드의 모든 컨테이너는 단일 노드로 스케줄되며 이 때 각 노드는 특정 플랫폼 및 아키텍처를 갖는다. 다음과 같은 파드 기능, 속성 및 이벤트가 윈도우 컨테이너에서 지원된다.
-
프로세스 격리 및 볼륨 공유 기능을 갖춘 파드 당 하나 또는 여러 개의 컨테이너
-
파드의
status필드 -
준비성 프로브(readinessprobe), 활성 프로브(liveness probe) 및 시작 프로브(startup probe)
-
postStart 및 preStop 컨테이너 라이프사이클 훅
-
컨피그맵(ConfigMap), 시크릿(Secrets): 환경 변수 또는 볼륨 형태로
-
emptyDir볼륨 -
명명된 파이프 호스트 마운트
-
리소스 제한
-
OS 필드:
특정 파드가 윈도우 컨테이너를 사용하고 있다는 것을 나타내려면
.spec.os.name필드를windows로 설정해야 한다.참고:
쿠버네티스 1.25부터, `IdentifyPodOS` 기능 게이트는 GA 단계이며 기본적으로 활성화되어 있다..spec.os.name필드를windows로 설정했다면, 해당 파드의.spec내의 다음 필드는 설정하지 않아야 한다.spec.hostPIDspec.hostIPCspec.securityContext.seLinuxOptionsspec.securityContext.seccompProfilespec.securityContext.fsGroupspec.securityContext.fsGroupChangePolicyspec.securityContext.sysctlsspec.shareProcessNamespacespec.securityContext.runAsUserspec.securityContext.runAsGroupspec.securityContext.supplementalGroupsspec.containers[*].securityContext.seLinuxOptionsspec.containers[*].securityContext.seccompProfilespec.containers[*].securityContext.capabilitiesspec.containers[*].securityContext.readOnlyRootFilesystemspec.containers[*].securityContext.privilegedspec.containers[*].securityContext.allowPrivilegeEscalationspec.containers[*].securityContext.procMountspec.containers[*].securityContext.runAsUserspec.containers[*].securityContext.runAsGroup
위의 리스트에서 와일드카드(
*)는 목록의 모든 요소를 가리킨다. 예를 들어,spec.containers[*].securityContext는 모든 컨테이너의 시큐리티컨텍스트(SecurityContext) 오브젝트를 나타낸다. 위의 필드 중 하나라도 설정되어 있으면, API 서버는 해당 파드는 수용하지 않을 것이다.
-
-
다음과 같은 워크로드 리소스:
- 레플리카셋(ReplicaSet)
- 디플로이먼트(Deployment)
- 스테이트풀셋(StatefulSet)
- 데몬셋(DaemonSet)
- 잡(Job)
- 크론잡(CronJob)
- 레플리케이션컨트롤러(ReplicationController)
-
서비스 로드 밸런싱과 서비스에서 상세 사항을 확인한다.
파드, 워크로드 리소스 및 서비스는 쿠버네티스에서 윈도우 워크로드를 관리하는 데 중요한 요소이다. 그러나 그 자체만으로는 동적인 클라우드 네이티브 환경에서 윈도우 워크로드의 적절한 라이프사이클 관리를 수행하기에 충분하지 않다.
kubectl exec- 파드 및 컨테이너 메트릭
- Horizontal pod autoscaling
- 리소스 쿼터(Resource quota)
- 스케쥴러 선점(preemption)
kubelet을 위한 명령줄 옵션
윈도우에서는 일부 kubelet 명령줄 옵션이 다르게 동작하며, 아래에 설명되어 있다.
--windows-priorityclass를 사용하여 kubelet 프로세스의 스케줄링 우선 순위를 설정할 수 있다. (CPU 리소스 관리 참고)--kube-reserved,--system-reserved및--eviction-hard플래그는 NodeAllocatable을 업데이트한다.--enforce-node-allocable을 이용한 축출은 구현되어 있지 않다.--eviction-hard및--eviction-soft를 이용한 축출은 구현되어 있지 않다.- 윈도우 노드에서 실행되는 kubelet은 메모리 및 CPU 제한을 받지 않는다.
NodeAllocatable에서--kube-reserved와--system-reserved가 차감될 뿐이며 워크로드에 제공될 리소스는 보장되지 않는다. 추가 정보는 윈도우 노드의 리소스 관리를 참고한다. MemoryPressure컨디션은 구현되어 있지 않다.- kubelet은 메모리 부족(OOM, Out-of-Memory) 축출 동작을 수행하지 않는다.
API 호환성
운영 체제와 컨테이너 런타임의 차이로 인해, 윈도우에 대해 쿠버네티스 API가 동작하는 방식에 미묘한 차이가 있다. 일부 워크로드 속성은 리눅스에 맞게 설계되었으며, 이로 인해 윈도우에서 실행되지 않는다.
높은 수준에서, OS 개념에 대해 다음과 같은 차이점이 존재한다.
- ID - 리눅스는 정수형으로 표시되는 userID(UID) 및 groupID(GID)를 사용한다.
사용자와 그룹 이름은 정식 이름이 아니다.
UID+GID에 대한
/etc/groups또는/etc/passwd의 별칭일 뿐이다. 윈도우는 윈도우 보안 계정 관리자(Security Account Manager, SAM) 데이터베이스에 저장된 더 큰 이진 보안 식별자(SID)를 사용한다. 이 데이터베이스는 호스트와 컨테이너 간에 또는 컨테이너들 간에 공유되지 않는다. - 파일 퍼미션 - 윈도우는 SID 기반 접근 제어 목록을 사용하는 반면, 리눅스와 같은 POSIX 시스템은 오브젝트 권한 및 UID+GID 기반의 비트마스크(bitmask)를 사용하며, 접근 제어 목록도 선택적으로 사용한다.
- 파일 경로 - 윈도우의 규칙은
/대신\를 사용하는 것이다. Go IO 라이브러리는 두 가지 파일 경로 분리자를 모두 허용한다. 하지만, 컨테이너 내부에서 해석되는 경로 또는 커맨드 라인을 설정할 때\가 필요할 수 있다. - 신호(Signals) - 윈도우 대화형(interactive) 앱은 종료를 다르게 처리하며,
다음 중 하나 이상을 구현할 수 있다.
- UI 스레드는
WM_CLOSE등의 잘 정의된(well-defined) 메시지를 처리한다. - 콘솔 앱은 컨트롤 핸들러(Control Handler)를 사용하여 Ctrl-c 또는 Ctrl-break를 처리한다.
- 서비스는
SERVICE_CONTROL_STOP제어 코드를 수용할 수 있는 Service Control Handler 함수를 등록한다.
- UI 스레드는
컨테이너 종료 코드는 리눅스와 동일하게 성공이면 0, 실패이면 0이 아닌 디른 수이다. 상세 오류 코드는 윈도우와 리눅스 간에 다를 수 있다. 그러나 쿠버네티스 컴포넌트(kubelet, kube-proxy)에서 전달된 종료 코드는 변경되지 않는다.
컨테이너 명세의 필드 호환성
다음 목록은 윈도우와 리눅스에서 파드 컨테이너 명세가 어떻게 다르게 동작하는지 기술한다.
- Huge page는 윈도우 컨테이너 런타임에서 구현되지 않았으며, 따라서 사용할 수 없다. 컨테이너에 대해 구성할 수 없는(not configurable) 사용자 권한(user privilege) 어설트(assert)가 필요하다.
requests.cpu및requests.memory- 요청(requests)이 노드의 사용 가능한 리소스에서 차감되며, 이는 노드 오버프로비저닝을 방지하기 위해 사용될 수 있다. 그러나, 오버프로비저닝된 노드 내에서 리소스를 보장하기 위해서는 사용될 수 없다. 운영자가 오버 프로비저닝을 완전히 피하려는 경우 모범 사례로 모든 컨테이너에 적용해야 한다.securityContext.allowPrivilegeEscalation- 어떠한 기능도 연결되지 않아서, 윈도우에서는 사용할 수 없다.securityContext.capabilities- POSIX 기능은 윈도우에서 구현되지 않았다.securityContext.privileged- 윈도우는 특권을 가진(privileged) 컨테이너를 지원하지 않는다. 대신 호스트 프로세스 컨테이너를 사용한다.securityContext.procMount- 윈도우에는/proc파일시스템이 없다.securityContext.readOnlyRootFilesystem- 윈도우에서는 사용할 수 없으며, 이는 레지스트리 및 시스템 프로세스가 컨테이너 내부에서 실행될 때 쓰기 권한이 필요하기 때문이다.securityContext.runAsGroup- 윈도우에서는 GID가 지원되지 않으므로 사용할 수 없다.securityContext.runAsNonRoot- 이 설정은 컨테이너가ContainerAdministrator사용자로 실행되는 것을 방지하는데, 이는 리눅스의 root 사용자와 가장 가까운 윈도우 역할이다.securityContext.runAsUser- 대신runAsUserName을 사용한다.securityContext.seLinuxOptions- SELinux는 리눅스 전용이므로 윈도우에서는 사용할 수 없다.terminationMessagePath- 윈도우가 단일 파일 매핑을 지원하지 않음으로 인하여 몇 가지 제한이 있다. 기본값은/dev/termination-log이며, 이 경로가 기본적으로 윈도우에 존재하지 않기 때문에 정상적으로 작동한다.
파드 명세의 필드 호환성
다음 목록은 윈도우와 리눅스에서 파드 명세가 어떻게 다르게 동작하는지 기술한다.
hostIPC및hostpid- 호스트 네임스페이스 공유 기능은 윈도우에서 사용할 수 없다.hostNetwork- 하단 참조dnsPolicy- 윈도우에서 호스트 네트워킹이 지원되지 않기 때문에dnsPolicy를ClusterFirstWithHostNet로 설정할 수 없다. 파드는 항상 컨테이너 네트워크와 함께 동작한다.podSecurityContext하단 참조shareProcessNamespace- 이것은 베타 기능이며, 윈도우에서 구현되지 않은 리눅스 네임스페이스에 의존한다. 윈도우는 프로세스 네임스페이스 또는 컨테이너의 루트 파일시스템을 공유할 수 없다. 네트워크만 공유할 수 있다.terminationGracePeriodSeconds- 이것은 윈도우용 도커에서 완전히 구현되지 않았다. GitHub 이슈를 참고한다. 현재 동작은ENTRYPOINT프로세스가CTRL_SHUTDOWN_EVENT로 전송된 다음, 윈도우가 기본적으로 5초를 기다린 후, 마지막으로 정상적인 윈도우 종료 동작을 사용하여 모든 프로세스를 종료하는 것이다. 5초 기본값은 실제로는 컨테이너 내부 윈도우 레지스트리에 있으므로 컨테이너를 빌드할 때 재정의할 수 있다.volumeDevices- 이것은 베타 기능이며, 윈도우에서 구현되지 않았다. 윈도우는 원시 블록 장치(raw block device)를 파드에 연결할 수 없다.volumesemptyDir볼륨을 정의한 경우, 이 볼륨의 소스(source)를memory로 설정할 수는 없다.
mountPropagation- 마운트 전파(propagation)는 윈도우에서 지원되지 않으므로 이 필드는 활성화할 수 없다.
호스트 네트워크(hostNetwork)의 필드 호환성
기능 상태:
Kubernetes v1.26 [alpha]
이제 kubelet은, 윈도우 노드에서 실행되는 파드가 새로운 파드 네트워크 네임스페이스를 생성하는 대신 호스트의 네트워크 네임스페이스를 사용하도록 요청할 수 있다.
이 기능을 활성화하려면 kubelet에 --feature-gates=WindowsHostNetwork=true를 전달한다.
참고:
이 기능을 지원하는 컨테이너 런타임을 필요로 한다.파드 시큐리티 컨텍스트의 필드 호환성
파드 securityContext의 모든 필드는 윈도우에서 작동하지 않는다.
노드 문제 감지기
노드 문제 감지기(노드 헬스 모니터링하기 참조)는 기초적인 윈도우 지원을 포함한다. 더 자세한 정보는 프로젝트의 GitHub 페이지를 참고한다.
퍼즈(pause) 컨테이너
쿠버네티스 파드에서, 컨테이너를 호스팅하기 위해 먼저 "퍼즈" 컨테이너라는 인프라 컨테이너가 생성된다. 리눅스에서, 파드를 구성하는 cgroup과 네임스페이스가 계속 유지되기 위해서는 프로세스가 필요하며, 퍼즈 프로세스가 이를 담당한다. 동일한 파드에 속한 (인프라 및 워커) 컨테이너는 공통의 네트워크 엔드포인트(공통 IPv4/IPv6 주소, 공통 네트워크 포트 공간)를 공유한다. 쿠버네티스는 퍼즈 컨테이너를 사용하여 워커 컨테이너가 충돌하거나 재시작하여도 네트워킹 구성을 잃지 않도록 한다.
쿠버네티스는 윈도우 지원을 포함하는 다중 아키텍처 이미지를 유지보수한다.
쿠버네티스 v1.31의 경우
권장 퍼즈 이미지는 registry.k8s.io/pause:3.6이다.
소스 코드는 GitHub에서 찾을 수 있다.
Microsoft는 리눅스 및 윈도우 amd64를 지원하는 다중 아키텍처 이미지를
mcr.microsoft.com/oss/kubernetes/pause:3.6에서 유지보수하고 있다.
이 이미지는 쿠버네티스가 유지 관리하는 이미지와 동일한 소스코드에서 생성되었지만,
모든 윈도우 바이너리가 Microsoft에 의해
인증 코드(authenticode)로 서명되었다.
서명된 바이너리를 필요로 하는 프로덕션 또는 프로덕션에 준하는 환경에 파드를 배포하는 경우,
Microsoft가 유지 관리하는 이미지를 사용하는 것을 권장한다.
컨테이너 런타임
파드가 각 노드에서 실행될 수 있도록, 클러스터의 각 노드에 컨테이너 런타임을 설치해야 한다.
다음 컨테이너 런타임은 윈도우에서 동작한다.
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
ContainerD
기능 상태:
Kubernetes v1.20 [stable]
ContainerD 1.4.0+를 윈도우 노드의 컨테이너 런타임으로 사용할 수 있다.
윈도우 노드에 ContainerD를 설치하는 방법을 확인한다.
참고:
containerd와 GMSA 사용 시 윈도우 네트워크 공유 접근에 대한 알려진 제한이 있으며, 이는 커널 패치를 필요로 한다.Mirantis Container Runtime
Mirantis Container Runtime(MCR)은 Windows Server 2019 및 이후 버전을 지원하는 컨테이너 런타임이다.
더 많은 정보는 Windows Server에 MCR 설치하기를 참고한다.
윈도우 운영 체제 버전 호환성
윈도우에는 호스트 OS 버전이 컨테이너 베이스 이미지 OS 버전과 일치해야 한다는 엄격한 호환성 규칙이 있다. 컨테이너 운영 체제가 Windows Server 2019인 윈도우 컨테이너만이 완전히 지원된다.
쿠버네티스 v1.31에서, 윈도우 노드(및 파드)에 대한 운영 체제 호환성은 다음과 같다.
- Windows Server LTSC 릴리스
- Windows Server 2019
- Windows Server 2022
- Windows Server SAC 릴리스
- Windows Server 버전 20H2
쿠버네티스 버전 차이 정책 또한 적용된다.
도움 받기 및 트러블슈팅
쿠버네티스 클러스터 트러블슈팅을 위한 기본 도움말은 이 섹션을 먼저 찾아 본다.
이 섹션에는 몇 가지 추가 윈도우 관련 트러블슈팅 도움말이 포함되어 있다. 로그는 쿠버네티스에서 트러블슈팅하는 데 중요한 요소이다. 다른 기여자로부터 트러블슈팅 지원을 구할 때마다 이를 포함시켜야 한다. SIG Windows의 로그 수집에 대한 기여 가이드의 지침을 따른다.
이슈 리포팅 및 기능 요청
버그처럼 보이는 부분이 있거나 기능 요청을 하고 싶다면, SIG Windows 기여 가이드를 참고하여 새 이슈를 연다. 먼저 이전에 이미 보고된 이슈가 있는지 검색하고, 이슈에 대한 경험과 추가 로그를 기재해야 한다. 티켓을 만들기 전에, 쿠버네티스 슬랙의 SIG Windows 채널 또한 초기 지원 및 트러블슈팅 아이디어를 얻을 수 있는 좋은 곳이다.
배포 도구
kubeadm 도구는 클러스터를 관리할 컨트롤 플레인과 워크로드를 실행할 노드를 제공함으로써 쿠버네티스 클러스터를 배포할 수 있게 해 준다. 윈도우 노드 추가하기 문서에서 kubeadm을 사용해 어떻게 클러스터에 윈도우 노드를 배포하는지를 설명한다.
쿠버네티스 클러스터 API 프로젝트는 윈도우 노드 배포를 자동화하는 수단을 제공한다.
윈도우 배포 채널
윈도우 배포 채널에 대한 자세한 설명은 Microsoft 문서를 참고한다.
각각의 Windows Server 서비스 채널 및 지원 모델은 Windows Server 서비스 채널에서 확인할 수 있다.
4.2 - 쿠버네티스에서 윈도우 컨테이너 스케줄링을 위한 가이드
많은 조직에서 실행하는 서비스와 애플리케이션의 상당 부분이 윈도우 애플리케이션으로 구성된다. 이 가이드는 쿠버네티스에서 윈도우 컨테이너를 구성하고 배포하는 단계를 안내한다.
목표
- 윈도우 노드에서 윈도우 컨테이너를 실행하는 예시 디플로이먼트를 구성한다.
- 쿠버네티스의 윈도우 관련 기능을 강조한다.
시작하기 전에
- 컨트롤 플레인과 윈도우 서버로 운영되는 워커 노드를 포함하는 쿠버네티스 클러스터를 생성한다.
- 쿠버네티스에서 서비스와 워크로드를 생성하고 배포하는 것은 리눅스나 윈도우 컨테이너 모두 비슷한 방식이라는 것이 중요하다. kubectl 커맨드로 클러스터에 접속하는 것은 동일하다. 아래 단원의 예시를 통해 윈도우 컨테이너와 좀 더 빨리 친숙해질 수 있다.
시작하기: 윈도우 컨테이너 배포하기
아래 예시 YAML 파일은 윈도우 컨테이너 안에서 실행되는 간단한 웹서버 애플리케이션을 배포한다.
아래 내용으로 채운 서비스 스펙을 win-webserver.yaml이라는 이름으로 생성한다.
apiVersion: v1
kind: Service
metadata:
name: win-webserver
labels:
app: win-webserver
spec:
ports:
# 이 서비스가 서비스를 제공할 포트
- port: 80
targetPort: 80
selector:
app: win-webserver
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
replicas: 2
selector:
matchLabels:
app: win-webserver
template:
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
containers:
- name: windowswebserver
image: mcr.microsoft.com/windows/servercore:ltsc2019
command:
- powershell.exe
- -command
- "<#code used from https://gist.github.com/19WAS85/5424431#> ; $$listener = New-Object System.Net.HttpListener ; $$listener.Prefixes.Add('http://*:80/') ; $$listener.Start() ; $$callerCounts = @{} ; Write-Host('Listening at http://*:80/') ; while ($$listener.IsListening) { ;$$context = $$listener.GetContext() ;$$requestUrl = $$context.Request.Url ;$$clientIP = $$context.Request.RemoteEndPoint.Address ;$$response = $$context.Response ;Write-Host '' ;Write-Host('> {0}' -f $$requestUrl) ; ;$$count = 1 ;$$k=$$callerCounts.Get_Item($$clientIP) ;if ($$k -ne $$null) { $$count += $$k } ;$$callerCounts.Set_Item($$clientIP, $$count) ;$$ip=(Get-NetAdapter | Get-NetIpAddress); $$header='<html><body><H1>Windows Container Web Server</H1>' ;$$callerCountsString='' ;$$callerCounts.Keys | % { $$callerCountsString+='<p>IP {0} callerCount {1} ' -f $$ip[1].IPAddress,$$callerCounts.Item($$_) } ;$$footer='</body></html>' ;$$content='{0}{1}{2}' -f $$header,$$callerCountsString,$$footer ;Write-Output $$content ;$$buffer = [System.Text.Encoding]::UTF8.GetBytes($$content) ;$$response.ContentLength64 = $$buffer.Length ;$$response.OutputStream.Write($$buffer, 0, $$buffer.Length) ;$$response.Close() ;$$responseStatus = $$response.StatusCode ;Write-Host('< {0}' -f $$responseStatus) } ; "
nodeSelector:
kubernetes.io/os: windows
참고:
포트 매핑도 지원하지만, 이 예시에서는 간결성을 위해 컨테이너 포트 80을 서비스로 직접 노출한다.-
모든 노드가 건강한지 확인한다.
kubectl get nodes -
서비스를 배포하고 파드 갱신을 지켜보자.
kubectl apply -f win-webserver.yaml kubectl get pods -o wide -w이 서비스가 정확히 배포되면 모든 파드는 Ready로 표기된다. 지켜보기를 중단하려면, Ctrl+C 를 누르자.
-
이 디플로이먼트가 성공적인지 확인한다. 다음을 검토하자.
- 리눅스 컨트롤 플레인 노드에서 나열된 두 파드가 존재하는지 확인하려면,
kubectl get pods를 사용한다. - 네트워크를 통한 노드에서 파드로의 통신이 되는지 확인하려면, 리눅스 컨트롤 플레인 노드에서
curl을 파드 IP 주소의 80 포트로 실행하여 웹 서버 응답을 확인한다. - 파드 간 통신이 되는지 확인하려면,
docker exec나kubectl exec를 이용해 파드 간에 핑(ping)한다(윈도우 노드가 2대 이상이라면, 서로 다른 노드에 있는 파드 간 통신도 확인할 수 있다). - 서비스에서 파드로의 통신이 되는지 확인하려면, 리눅스 컨트롤 플레인 노드와 독립 파드에서
curl을 가상 서비스 IP 주소(kubectl get services로 볼 수 있는)로 실행한다. - 서비스 검색(discovery)이 되는지 확인하려면, 쿠버네티스 기본 DNS 접미사와 서비스 이름으로
curl을 실행한다. - 인바운드 연결이 되는지 확인하려면, 클러스터 외부 장비나 리눅스 컨트롤 플레인 노드에서 NodePort로
curl을 실행한다. - 아웃바운드 연결이 되는지 확인하려면,
kubectl exec를 이용해서 파드에서 외부 IP 주소로curl을 실행한다.
- 리눅스 컨트롤 플레인 노드에서 나열된 두 파드가 존재하는지 확인하려면,
참고:
윈도우 컨테이너 호스트는 현재 윈도우 네트워킹 스택의 플랫폼 제한으로 인해, 그 안에서 스케줄링하는 서비스의 IP 주소로 접근할 수 없다. 윈도우 파드만 서비스 IP 주소로 접근할 수 있다.가시성
워크로드에서 로그 캡쳐하기
로그는 가시성의 중요한 요소이다. 로그는 사용자가 워크로드의 운영측면을
파악할 수 있도록 하며 문제 해결의 핵심 요소이다.
윈도우 컨테이너, 그리고 윈도우 컨테이너 내의 워크로드는 리눅스 컨테이너와는 다르게 동작하기 때문에,
사용자가 로그를 수집하기 어려웠고 이로 인해 운영 가시성이 제한되어 왔다.
예를 들어 윈도우 워크로드는 일반적으로 ETW(Event Tracing for Windows)에 로그인하거나
애플리케이션 이벤트 로그에 항목을 푸시하도록 구성한다.
Microsoft의 오픈 소스 도구인 LogMonitor는
윈도우 컨테이너 안에 구성된 로그 소스를 모니터링하는 권장하는 방법이다.
LogMonitor는 이벤트 로그, ETW 공급자 그리고 사용자 정의 애플리케이션 로그 모니터링을 지원하고
kubectl logs <pod> 에 의한 사용을 위해 STDOUT으로 파이프한다.
LogMonitor GitHub 페이지의 지침에 따라 모든 컨테이너 바이너리와 설정 파일을 복사하고, LogMonitor가 로그를 STDOUT으로 푸시할 수 있도록 필요한 엔트리포인트를 추가한다.
컨테이너 사용자 구성하기
설정 가능한 컨테이너 username 사용하기
윈도우 컨테이너는 이미지 기본값과는 다른 username으로 엔트리포인트와 프로세스를 실행하도록 설정할 수 있다. 여기에서 이에 대해 추가적으로 배울 수 있다.
그룹 매니지드 서비스 어카운트를 이용하여 워크로드 신원 관리하기
윈도우 컨테이너 워크로드는 그룹 매니지드 서비스 어카운트(GMSA, Group Managed Service Account)를 이용하여 구성할 수 있다. 그룹 매니지드 서비스 어카운트는 액티브 디렉터리 어카운트의 특정한 종류로 자동 암호 관리 기능, 단순화된 서비스 주체 이름(SPN, simplified service principal name), 여러 서버의 다른 관리자에게 관리를 위임하는 기능을 제공한다. GMSA로 구성한 컨테이너는 GMSA로 구성된 신원을 들고 있는 동안 외부 액티브 디렉터리 도메인 리소스를 접근할 수 있다. 윈도우 컨테이너를 위한 GMSA를 이용하고 구성하는 방법은 여기에서 알아보자.
테인트(Taint)와 톨러레이션(Toleration)
사용자는 리눅스와 윈도우 워크로드를 (동일한 OS를 실행하는) 적절한 노드에 스케줄링되도록 하기 위해 테인트와 노드셀렉터(nodeSelector)의 조합을 이용해야 한다. 아래는 권장되는 방식의 개요인데, 이것의 주요 목표 중에 하나는 이 방식이 기존 리눅스 워크로드와 호환되어야 한다는 것이다.
1.25부터, 파드의 컨테이너가 어떤 운영체제 용인지를 파드의 .spec.os.name에 설정할 수 있다(그리고 설정해야 한다).
리눅스 컨테이너를 실행하는 파드에는 .spec.os.name을 linux로 설정한다.
윈도우 컨테이너를 실행하는 파드에는 .spec.os.name을
windows로 설정한다.
참고:
1.25부터,IdentifyPodOS 기능은 GA 단계이며 기본적으로 활성화되어 있다.스케줄러는 파드를 노드에 할당할 때
.spec.os.name 필드의 값을 사용하지 않는다.
컨트롤 플레인이 파드를 적절한 운영 체제가 실행되고 있는 노드에 배치하도록 하려면,
파드를 노드에 할당하는
일반적인 쿠버네티스 메카니즘을 사용해야 한다.
.spec.os.name 필드는 윈도우 파드의 스케줄링에는 영향을 미치지 않기 때문에,
윈도우 파드가 적절한 윈도우 노드에 할당되도록 하려면
테인트, 톨러레이션 및 노드 셀렉터가 여전히 필요하다.
특정 OS 워크로드를 적절한 컨테이너 호스트에서 처리하도록 보장하기
사용자는 테인트와 톨러레이션을 이용하여 윈도우 컨테이너가 적절한 호스트에서 스케줄링되기를 보장할 수 있다. 오늘날 모든 쿠버네티스 노드는 다음 기본 레이블을 가지고 있다.
- kubernetes.io/os = [windows|linux]
- kubernetes.io/arch = [amd64|arm64|...]
파드 사양에 노드 셀렉터를 "kubernetes.io/os": windows와 같이 지정하지 않았다면,
그 파드는 리눅스나 윈도우, 아무 호스트에나 스케줄링될 수 있다.
윈도우 컨테이너는 윈도우에서만 운영될 수 있고 리눅스 컨테이너는 리눅스에서만 운영될 수 있기 때문에 이는 문제를 일으킬 수 있다.
가장 좋은 방법은 노드 셀렉터를 사용하는 것이다.
그러나 많은 경우 사용자는 이미 존재하는 대량의 리눅스 컨테이너용 디플로이먼트를 가지고 있을 뿐만 아니라, 헬름(Helm) 차트 커뮤니티 같은 상용 구성의 에코시스템이나, 오퍼레이터(Operator) 같은 프로그래밍 방식의 파드 생성 사례가 있음을 알고 있다. 이런 상황에서는 노드 셀렉터를 추가하는 구성 변경을 망설일 수 있다. 이에 대한 대안은 테인트를 사용하는 것이다. Kubelet은 등록하는 동안 테인트를 설정할 수 있기 때문에, 윈도우에서만 운영할 때에 자동으로 테인트를 추가하기 쉽다.
예를 들면, --register-with-taints='os=windows:NoSchedule'
모든 윈도우 노드에 테인트를 추가하여 아무 것도 거기에 스케줄링하지 않게 될 것이다(존재하는 리눅스 파드를 포함하여). 윈도우 파드가 윈도우 노드에 스케줄링되도록 하려면, 윈도우 노드가 선택되도록 하기 위한 노드 셀렉터 및 적합하게 일치하는 톨러레이션이 모두 필요하다.
nodeSelector:
kubernetes.io/os: windows
node.kubernetes.io/windows-build: '10.0.17763'
tolerations:
- key: "os"
operator: "Equal"
value: "windows"
effect: "NoSchedule"
동일 클러스터에서 여러 윈도우 버전을 조작하는 방법
파드에서 사용하는 윈도우 서버 버전은 노드의 윈도우 서버 버전과 일치해야 한다. 만약 동일한 클러스터에서 여러 윈도우 서버 버전을 사용하려면, 추가로 노드 레이블과 nodeSelectors를 설정해야 한다.
쿠버네티스 1.17은 이것을 단순화하기 위해 새로운 레이블인 node.kubernetes.io/windows-build 를 자동으로 추가한다.
만약 이전 버전을 실행 중인 경우, 이 레이블을 윈도우 노드에 수동으로 추가하는 것을 권장한다.
이 레이블은 호환성을 위해 일치시켜야 하는 윈도우 메이저, 마이너 및 빌드 번호를 나타낸다. 각 윈도우 서버 버전에 대해 현재 사용하고 있는 빌드 번호는 다음과 같다.
| 제품 이름 | 빌드 번호 |
|---|---|
| Windows Server 2019 | 10.0.17763 |
| Windows Server, 버전 20H2 | 10.0.19042 |
| Windows Server 2022 | 10.0.20348 |
RuntimeClass로 단순화
런타임클래스(RuntimeClass)를 사용해서 테인트(taint)와 톨러레이션(toleration)을 사용하는 프로세스를 간소화 할 수 있다.
클러스터 관리자는 이 테인트와 톨러레이션을 캡슐화하는 데 사용되는 RuntimeClass 오브젝트를 생성할 수 있다.
- 이 파일을
runtimeClasses.yml로 저장한다. 여기에는 윈도우 OS, 아키텍처 및 버전에 적합한nodeSelector가 포함되어 있다.
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: windows-2019
handler: 'docker'
scheduling:
nodeSelector:
kubernetes.io/os: 'windows'
kubernetes.io/arch: 'amd64'
node.kubernetes.io/windows-build: '10.0.17763'
tolerations:
- effect: NoSchedule
key: os
operator: Equal
value: "windows"
- 클러스터 관리자로
kubectl create -f runtimeClasses.yml를 실행해서 사용한다. - 파드 사양에 적합한
runtimeClassName: windows-2019를 추가한다.
예시:
apiVersion: apps/v1
kind: Deployment
metadata:
name: iis-2019
labels:
app: iis-2019
spec:
replicas: 1
template:
metadata:
name: iis-2019
labels:
app: iis-2019
spec:
runtimeClassName: windows-2019
containers:
- name: iis
image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
resources:
limits:
cpu: 1
memory: 800Mi
requests:
cpu: .1
memory: 300Mi
ports:
- containerPort: 80
selector:
matchLabels:
app: iis-2019
---
apiVersion: v1
kind: Service
metadata:
name: iis
spec:
type: LoadBalancer
ports:
- protocol: TCP
port: 80
selector:
app: iis-2019
5 - 워크로드
쿠버네티스에서 배포할 수 있는 가장 작은 컴퓨트 오브젝트인 파드와, 이를 실행하는 데 도움이 되는 하이-레벨(higher-level) 추상화
워크로드는 쿠버네티스에서 구동되는 애플리케이션이다.
워크로드가 단일 컴포넌트이거나 함께 작동하는 여러 컴포넌트이든 관계없이, 쿠버네티스에서는 워크로드를 일련의
파드 집합 내에서 실행한다.
쿠버네티스에서 Pod 는 클러스터에서 실행 중인 컨테이너
집합을 나타낸다.
쿠버네티스 파드에는 정의된 라이프사이클이 있다.
예를 들어, 일단 파드가 클러스터에서 실행되고 나서
해당 파드가 동작 중인 노드에
심각한 오류가 발생하면 해당 노드의 모든 파드가 실패한다. 쿠버네티스는 이 수준의 실패를
최종(final)으로 취급한다. 사용자는 향후 노드가 복구되는 것과 상관 없이 Pod 를 새로 생성해야 한다.
그러나, 작업이 훨씬 쉽도록, 각 Pod 를 직접 관리할 필요는 없도록 만들었다.
대신, 사용자를 대신하여 파드 집합을 관리하는 워크로드 리소스 를 사용할 수 있다.
이러한 리소스는 지정한 상태와 일치하도록 올바른 수의 올바른 파드 유형이
실행되고 있는지 확인하는 컨트롤러를
구성한다.
쿠버네티스는 다음과 같이 여러 가지 빌트인(built-in) 워크로드 리소스를 제공한다.
Deployment및ReplicaSet(레거시 리소스 레플리케이션컨트롤러(ReplicationController)를 대체).Deployment는Deployment의 모든Pod가 필요 시 교체 또는 상호 교체 가능한 경우, 클러스터의 스테이트리스 애플리케이션 워크로드를 관리하기에 적합하다.StatefulSet는 어떻게든 스테이트(state)를 추적하는 하나 이상의 파드를 동작하게 해준다. 예를 들면, 워크로드가 데이터를 지속적으로 기록하는 경우, 사용자는Pod와PersistentVolume을 연계하는StatefulSet을 실행할 수 있다. 전체적인 회복력 향상을 위해서,StatefulSet의Pods에서 동작 중인 코드는 동일한StatefulSet의 다른Pods로 데이터를 복제할 수 있다.DaemonSet은 노드-로컬 기능(node-local facilities)을 제공하는Pods를 정의한다. 이러한 기능들은 클러스터를 운용하는 데 기본적인 것일 것이다. 예를 들면, 네트워킹 지원 도구 또는 add-on 등이 있다.DaemonSet의 명세에 맞는 노드를 클러스터에 추가할 때마다, 컨트롤 플레인은 해당 신규 노드에DaemonSet을 위한Pod를 스케줄한다.Job및CronJob은 실행 완료 후 중단되는 작업을 정의한다.CronJobs이 스케줄에 따라 반복되는 반면, 잡은 단 한 번의 작업을 나타낸다.
더 넓은 쿠버네티스 에코시스템 내에서는 추가적인 동작을 제공하는 제 3자의 워크로드
리소스도 찾을 수 있다.
커스텀 리소스 데피니션을 사용하면,
쿠버네티스 코어에서 제공하지 않는 특별한 동작을 원하는 경우 제 3자의 워크로드 리소스를
추가할 수 있다. 예를 들어, 사용자 애플리케이션을 위한 Pods 의 그룹을 실행하되
모든 파드가 가용한 경우가 아닌 경우 멈추고 싶다면(아마도 높은 처리량의 분산 처리를 하는 상황 같은),
사용자는 해당 기능을 제공하는 확장을 구현하거나 설치할 수 있다.
다음 내용
각 리소스에 대해 읽을 수 있을 뿐만 아니라, 리소스와 관련된 특정 작업에 대해서도 알아볼 수 있다.
Deployment를 사용하여 스테이트리스(stateless) 애플리케이션 실행- 스테이트풀(stateful) 애플리케이션을 단일 인스턴스 또는 복제된 세트로 실행
CronJob을 사용하여 자동화된 작업 실행
코드를 구성(configuration)에서 분리하는 쿠버네티스의 메커니즘을 배우기 위해서는, 구성을 참고하길 바란다.
다음은 쿠버네티스가 애플리케이션의 파드를 어떻게 관리하는지를 알 수 있게 해주는 두 가지 개념이다.
- 가비지(Garbage) 수집은 소유하는 리소스 가 제거된 후 클러스터에서 오브젝트를 정리한다.
- time-to-live after finished 컨트롤러는 잡이 완료된 이후에 정의된 시간이 경과되면 잡을 제거한다.
일단 애플리케이션이 실행되면, 인터넷에서 서비스로 사용하거나, 웹 애플리케이션의 경우에만 인그레스(Ingress)를 이용하여 사용할 수 있다.
5.1 - 파드
파드(Pod) 는 쿠버네티스에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위이다.
파드 (고래 떼(pod of whales)나 콩꼬투리(pea pod)와 마찬가지로)는 하나 이상의 컨테이너의 그룹이다. 이 그룹은 스토리지 및 네트워크를 공유하고, 해당 컨테이너를 구동하는 방식에 대한 명세를 갖는다. 파드의 콘텐츠는 항상 함께 배치되고, 함께 스케줄되며, 공유 콘텍스트에서 실행된다. 파드는 애플리케이션 별 "논리 호스트"를 모델링한다. 여기에는 상대적으로 밀접하게 결합된 하나 이상의 애플리케이션 컨테이너가 포함된다. 클라우드가 아닌 콘텍스트에서, 동일한 물리 또는 가상 머신에서 실행되는 애플리케이션은 동일한 논리 호스트에서 실행되는 클라우드 애플리케이션과 비슷하다.
애플리케이션 컨테이너와 마찬가지로, 파드에는 파드 시작 중에 실행되는 초기화 컨테이너가 포함될 수 있다. 클러스터가 제공하는 경우, 디버깅을 위해 임시 컨테이너를 삽입할 수도 있다.
파드란 무엇인가?
참고:
도커가 가장 일반적으로 잘 알려진 컨테이너 런타임이지만, 쿠버네티스는 도커 외에도 다양한 컨테이너 런타임을 지원하며, 파드를 설명할 때 도커 관련 용어를 사용하면 더 쉽게 설명할 수 있다.파드의 공유 콘텍스트는 리눅스 네임스페이스, 컨트롤 그룹(cgroup) 및 컨테이너를 격리하는 것과 같이 잠재적으로 다른 격리 요소들이다. 파드의 콘텍스트 내에서 개별 애플리케이션은 추가적으로 하위 격리가 적용된다.
파드는 공유 네임스페이스와 공유 파일시스템 볼륨이 있는 컨테이너들의 집합과 비슷하다.
파드의 사용
다음은 nginx:1.14.2 이미지를 실행하는 컨테이너로 구성되는 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
위에서 설명한 파드를 생성하려면, 다음 명령을 실행한다.
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
일반적으로 파드는 직접 생성하지는 않으며, 대신 워크로드 리소스를 사용하여 생성한다. 파드 작업 섹션에서 파드와 워크로드 리소스의 관계에 대한 더 많은 정보를 확인한다.
Workload resources for managing pods
일반적으로 싱글톤(singleton) 파드를 포함하여 파드를 직접 만들 필요가 없다. 대신, 디플로이먼트(Deployment) 또는 잡(Job)과 같은 워크로드 리소스를 사용하여 생성한다. 파드가 상태를 추적해야 한다면, 스테이트풀셋(StatefulSet) 리소스를 고려한다.
쿠버네티스 클러스터의 파드는 두 가지 주요 방식으로 사용된다.
-
단일 컨테이너를 실행하는 파드. "파드 당 하나의 컨테이너" 모델은 가장 일반적인 쿠버네티스 유스케이스이다. 이 경우, 파드를 단일 컨테이너를 둘러싼 래퍼(wrapper)로 생각할 수 있다. 쿠버네티스는 컨테이너를 직접 관리하는 대신 파드를 관리한다.
-
함께 작동해야 하는 여러 컨테이너를 실행하는 파드. 파드는 밀접하게 결합되어 있고 리소스를 공유해야 하는 함께 배치된 여러 개의 컨테이너로 구성된 애플리케이션을 캡슐화할 수 있다. 이런 함께 배치된 컨테이너는 하나의 결합된 서비스 단위를 형성한다. 예를 들어, 하나의 컨테이너는 공유 볼륨에 저장된 데이터를 퍼블릭에 제공하는 반면, 별도의 사이드카 컨테이너는 해당 파일을 새로 고치거나 업데이트한다. 파드는 이러한 컨테이너, 스토리지 리소스, 임시 네트워크 ID를 단일 단위로 함께 래핑한다.
참고:
단일 파드에서 함께 배치된 또는 함께 관리되는 여러 컨테이너를 그룹화하는 것은 비교적 고급 유스케이스이다. 이 패턴은 컨테이너가 밀접하게 결합된 특정 인스턴스에서만 사용해야 한다.
각 파드는 특정 애플리케이션의 단일 인스턴스를 실행하기 위한 것이다. 더 많은 인스턴스를 실행하여 더 많은 전체 리소스를 제공하기 위해 애플리케이션을 수평적으로 확장하려면, 각 인스턴스에 하나씩, 여러 파드를 사용해야 한다. 쿠버네티스에서는 이를 일반적으로 레플리케이션 이라고 한다. 복제된 파드는 일반적으로 워크로드 리소스와 해당 컨트롤러에 의해 그룹으로 생성되고 관리된다.
쿠버네티스가 워크로드 리소스와 해당 컨트롤러를 사용하여 애플리케이션 스케일링과 자동 복구를 구현하는 방법에 대한 자세한 내용은 파드와 컨트롤러를 참고한다.
파드가 여러 컨테이너를 관리하는 방법
파드는 응집력있는 서비스 단위를 형성하는 여러 협력 프로세스(컨테이너)를 지원하도록 설계되었다. 파드의 컨테이너는 클러스터의 동일한 물리 또는 가상 머신에서 자동으로 같은 위치에 배치되고 함께 스케줄된다. 컨테이너는 리소스와 의존성을 공유하고, 서로 통신하고, 종료 시기와 방법을 조정할 수 있다.
예를 들어, 다음 다이어그램에서와 같이 공유 볼륨의 파일에 대한 웹 서버 역할을 하는 컨테이너와, 원격 소스에서 해당 파일을 업데이트하는 별도의 "사이드카" 컨테이너가 있을 수 있다.

일부 파드에는 앱 컨테이너 뿐만 아니라 초기화 컨테이너를 갖고 있다. 초기화 컨테이너는 앱 컨테이너가 시작되기 전에 실행되고 완료된다.
파드는 기본적으로 파드에 속한 컨테이너에 네트워킹과 스토리지라는 두 가지 종류의 공유 리소스를 제공한다.
파드 작업
사용자가 쿠버네티스에서 직접 개별 파드를 만드는 경우는 거의 없다. 싱글톤 파드도 마찬가지이다. 이는 파드가 상대적으로 일시적인, 일회용 엔티티로 설계되었기 때문이다. 파드가 생성될 때(사용자가 직접 또는 컨트롤러가 간접적으로), 새 파드는 클러스터의 노드에서 실행되도록 스케줄된다. 파드는 파드 실행이 완료되거나, 파드 오브젝트가 삭제되거나, 리소스 부족으로 인해 파드가 축출 되거나, 노드가 실패할 때까지 해당 노드에 남아있다.
참고:
파드에서 컨테이너를 다시 시작하는 것과 파드를 다시 시작하는 것을 혼동해서는 안된다. 파드는 프로세스가 아니라 컨테이너를 실행하기 위한 환경이다. 파드는 삭제될 때까지 유지된다.파드 오브젝트에 대한 매니페스트를 만들 때, 지정된 이름이 유효한 DNS 서브도메인 이름인지 확인한다.
파드 OS
기능 상태:
Kubernetes v1.25 [stable]
파드를 실행할 때 OS를 표시하려면 .spec.os.name 필드를 windows 또는
linux로 설정해야 한다. 이 두 가지 운영체제는 현재 쿠버네티스에서 지원되는
유일한 운영체제이다. 앞으로 이 목록이 확장될 수 있다.
쿠버네티스 v1.31에서, 이 필드에 대해 설정한 값은
파드의 스케줄링에 영향을 미치지 않는다.
.spec.os.name을 설정하면 파드 검증 시
OS를 식별하는 데 도움이 된다.
kubelet은
자신이 실행되고 있는 노드의 운영체제와
동일하지 않은 파드 OS가 명시된 파드의 실행을 거부한다.
파드 시큐리티 스탠다드도 이 필드를 사용하여 해당 운영체제와 관련이 없는 정책을 시행하지 않도록 한다.
파드와 컨트롤러
워크로드 리소스를 사용하여 여러 파드를 만들고 관리할 수 있다. 리소스에 대한 컨트롤러는 파드 장애 시 복제 및 롤아웃과 자동 복구를 처리한다. 예를 들어, 노드가 실패하면, 컨트롤러는 해당 노드의 파드가 작동을 중지했음을 인식하고 대체 파드를 생성한다. 스케줄러는 대체 파드를 정상 노드에 배치한다.
다음은 하나 이상의 파드를 관리하는 워크로드 리소스의 몇 가지 예시이다.
파드 템플릿
워크로드 리소스에 대한 컨트롤러는 파드 템플릿 에서 파드를 생성하고 사용자 대신 해당 파드를 관리한다.
파드템플릿(PodTemplate)은 파드를 생성하기 위한 명세이며, 디플로이먼트, 잡 및 데몬셋과 같은 워크로드 리소스에 포함된다.
워크로드 리소스의 각 컨트롤러는 워크로드 오브젝트 내부의 PodTemplate 을
사용하여 실제 파드를 생성한다. PodTemplate 은 앱을 실행하는 데 사용되는 워크로드 리소스가
무엇이든지 원하는 상태의 일부이다.
아래 샘플은 하나의 컨테이너를 시작하는 template 이 있는 간단한 잡의
매니페스트이다. 해당 파드의 컨테이너는 메시지를 출력한 다음 일시 중지한다.
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 여기서부터 파드 템플릿이다
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# 여기까지 파드 템플릿이다
파드 템플릿을 수정하거나 새로운 파드 템플릿으로 바꿔도 이미 존재하는 파드에는 직접적인 영향을 주지 않는다. 워크로드 리소스의 파드 템플릿을 변경하는 경우, 해당 리소스는 수정된 템플릿을 사용하는 대체 파드를 생성해야 한다.
예를 들어, 스테이트풀셋 컨트롤러는 실행 중인 파드가 각 스테이트풀셋 오브젝트에 대한 현재 파드 템플릿과 일치하는지 확인한다. 스테이트풀셋을 수정하여 파드 템플릿을 변경하면, 스테이트풀셋이 업데이트된 템플릿을 기반으로 새로운 파드를 생성하기 시작한다. 결국, 모든 이전의 파드가 새로운 파드로 교체되고, 업데이트가 완료된다.
각 워크로드 리소스는 파드 템플릿의 변경 사항을 처리하기 위한 자체 규칙을 구현한다. 스테이트풀셋에 대해 자세히 알아 보려면, 스테이트풀셋 기본 튜토리얼에서 업데이트 전략을 읽어본다.
노드에서 kubelet은 파드 템플릿과 업데이트에 대한 상세 정보를 직접 관찰하거나 관리하지 않는다. 이러한 상세 내용은 추상화된다. 이러한 추상화와 관심사 분리(separation of concerns)는 시스템 시맨틱을 단순화하고, 기존 코드를 변경하지 않고도 클러스터의 동작을 확장할 수 있게 한다.
파드 갱신 및 교체
이전 섹션에서 언급한 바와 같이, 워크로드 리소스의 파드 템플릿이 바뀌면, 컨트롤러는 기존의 파드를 갱신하거나 패치하는 대신 갱신된 템플릿을 기반으로 신규 파드를 생성한다.
쿠버네티스는 사용자가 파드를 직접 관리하는 것을 막지는 않는다.
동작 중인 파드의 필드를 갱신하는 것도 가능하다.
그러나,
patch 및
replace와 같은
파드 갱신 작업에는 다음과 같은 제약이 있다.
-
파드에 대한 대부분의 메타데이터는 불변(immutable)이다. 예를 들면, 사용자는
namespace,name,uid, 또는creationTimestamp필드를 변경할 수 없다. 그리고generation필드는 고유하다. 이 필드는 필드의 현재 값을 증가시키는 갱신만 허용한다. -
metadata.deletionTimestamp가 설정된 경우,metadata.finalizers리스트에 새로운 항목이 추가될 수 없다. -
파드 갱신은
spec.containers[*].image,spec.initContainers[*].image,spec.activeDeadlineSeconds, 또는spec.tolerations이외의 필드는 변경하지 않을 것이다.spec.tolerations에 대해서만 새로운 항목을 추가할 수 있다. -
spec.activeDeadlineSeconds필드를 추가할 때는, 다음의 두 가지 형태의 갱신만 허용한다.- 지정되지 않은 필드를 양수로 설정;
- 필드의 양수를 음수가 아닌 더 작은 숫자로 갱신.
리소스 공유와 통신
파드는 파드에 속한 컨테이너 간의 데이터 공유와 통신을 지원한다.
파드 스토리지
파드는 공유 스토리지 볼륨의 집합을 지정할 수 있다. 파드의 모든 컨테이너는 공유 볼륨에 접근할 수 있으므로, 해당 컨테이너가 데이터를 공유할 수 있다. 또한 볼륨은 내부 컨테이너 중 하나를 다시 시작해야 하는 경우 파드의 영구 데이터를 유지하도록 허용한다. 쿠버네티스가 공유 스토리지를 구현하고 파드에서 사용할 수 있도록 하는 방법에 대한 자세한 내용은 스토리지를 참고한다.
파드 네트워킹
각 파드에는 각 주소 패밀리에 대해 고유한 IP 주소가 할당된다.
파드의 모든 컨테이너는 네트워크 네임스페이스를 공유하며,
여기에는 IP 주소와 네트워크 포트가 포함된다.
파드 내부(이 경우에 만 해당)에서, 파드에 속한 컨테이너는
localhost 를 사용하여 서로 통신할 수 있다.
파드의 컨테이너가 파드 외부의 엔티티와 통신할 때,
공유 네트워크 리소스(포트와 같은)를 사용하는 방법을 조정해야 한다.
파드 내에서 컨테이너는 IP 주소와 포트 공간을 공유하며,
localhost 를 통해 서로를 찾을 수 있다.
파드의 컨테이너는 SystemV 세마포어 또는 POSIX 공유 메모리와 같은
표준 프로세스 간 통신을 사용하여 서로 통신할 수도 있다.
다른 파드의 컨테이너는 고유한 IP 주소를 가지며 특별한 구성 없이 OS 수준의 IPC로 통신할 수 없다.
다른 파드에서 실행되는 컨테이너와 상호 작용하려는 컨테이너는 IP 네트워킹을 사용하여 통신할 수 있다.
파드 내의 컨테이너는 시스템 호스트명이 파드에 대해 구성된
name 과 동일한 것으로 간주한다. 네트워킹 섹션에 이에 대한
자세한 내용이 있다.
컨테이너에 대한 특권 모드
리눅스에서, 파드의 모든 컨테이너는 컨테이너 명세의 보안 컨텍스트에 있는 privileged (리눅스) 플래그를 사용하여 특권 모드를 활성화할 수 있다. 이는 네트워크 스택 조작이나 하드웨어 장치 접근과 같은 운영 체제 관리 기능을 사용하려는 컨테이너에 유용하다.
클러스터가 WindowsHostProcessContainers 기능을 활성화하였다면, 파드 스펙의 보안 컨텍스트의 windowsOptions.hostProcess 에 의해 윈도우 HostProcess 파드를 생성할 수 있다. 이러한 모든 컨테이너는 윈도우 HostProcess 컨테이너로 실행해야 한다. HostProcess 파드는 직접적으로 호스트에서 실행하는 것으로, 리눅스 특권있는 컨테이너에서 수행되는 관리 태스크 수행에도 사용할 수 있다. 파드의 모든 컨테이너는 윈도우 HostProcess 컨테이너로 반드시 실행해야 한다. HostProcess 파드는 호스트에서 직접 실행되며 리눅스 특권있는 컨테이너에서 수행되는 것과 같은 관리 작업을 수행하는데도 사용할 수 있다.
참고:
이 설정을 사용하려면 사용자의 컨테이너 런타임이 특권이 있는 컨테이너의 개념을 지원해야 한다.정적 파드
정적 파드 는 API 서버가 관찰하는 대신 특정 노드의 kubelet 데몬에 의해 직접 관리된다. 대부분의 파드는 컨트롤 플레인(예를 들어, 디플로이먼트)에 의해 관리되고, 정적 파드의 경우, kubelet이 각 정적 파드를 직접 감독한다(실패하면 다시 시작한다).
정적 파드는 항상 특정 노드의 Kubelet 하나에 바인딩된다. 정적 파드의 주요 용도는 자체 호스팅 컨트롤 플레인을 실행하는 것이다. 즉, kubelet을 사용하여 개별 컨트롤 플레인 컴포넌트를 감독한다.
kubelet은 자동으로 각 정적 파드에 대한 쿠버네티스 API 서버에서 미러 파드를 생성하려고 한다. 즉, 노드에서 실행되는 파드는 API 서버에서 보이지만, 여기에서 제어할 수는 없다는 의미이다.
컨테이너 프로브
_프로브_는 컨테이너의 kubelet에 의해 주기적으로 실행되는 진단이다. 진단을 수행하기 위하여 kubelet은 다음과 같은 작업을 호출할 수 있다.
ExecAction(컨테이너 런타임의 도움을 받아 수행)TCPSocketAction(kubelet에 의해 직접 검사)HTTPGetAction(kubelet에 의해 직접 검사)
프로브에 대한 자세한 내용은 파드 라이프사이클 문서를 참고한다.
다음 내용
- 파드의 라이프사이클에 대해 알아본다.
- 런타임클래스(RuntimeClass)와 이를 사용하여 다양한 컨테이너 런타임 구성으로 다양한 파드를 설정하는 방법에 대해 알아본다.
- PodDisruptionBudget과 이를 사용하여 서비스 중단 중에 애플리케이션 가용성을 관리하는 방법에 대해 읽어본다.
- 파드는 쿠버네티스 REST API의 최상위 리소스이다. Pod 오브젝트 정의는 오브젝트를 상세히 설명한다.
- 분산 시스템 툴킷: 컴포지트 컨테이너에 대한 패턴은 둘 이상의 컨테이너가 있는 파드의 일반적인 레이아웃을 설명한다.
- 파드 토폴로지 분배 제약 조건에 대해 읽어본다.
쿠버네티스가 다른 리소스(스테이트풀셋이나 디플로이먼트와 같은)에서 공통 파드 API를 래핑하는 이유에 대한 콘텍스트를 이해하기 위해서, 다음과 같은 선행 기술에 대해 읽어볼 수 있다.
5.1.1 - 파드 라이프사이클
이 페이지에서는 파드의 라이프사이클을 설명한다. 파드는 정의된 라이프사이클을 따른다.
Pending 단계에서 시작해서, 기본 컨테이너 중 적어도 하나
이상이 OK로 시작하면 Running 단계를 통과하고, 그런 다음 파드의 컨테이너가
실패로 종료되었는지 여부에 따라 Succeeded 또는 Failed 단계로 이동한다.
파드가 실행되는 동안, kubelet은 일종의 오류를 처리하기 위해 컨테이너를 다시 시작할 수 있다. 파드 내에서, 쿠버네티스는 다양한 컨테이너 상태를 추적하고 파드를 다시 정상 상태로 만들기 위해 취할 조치를 결정한다.
쿠버네티스 API에서 파드는 명세와 실제 상태를 모두 가진다. 파드 오브젝트의 상태는 일련의 파드 컨디션으로 구성된다. 사용자의 애플리케이션에 유용한 경우, 파드의 컨디션 데이터에 사용자 정의 준비성 정보를 삽입할 수도 있다.
파드는 파드의 수명 중 한 번만 스케줄된다. 파드가 노드에 스케줄(할당)되면, 파드는 중지되거나 종료될 때까지 해당 노드에서 실행된다.
파드의 수명
개별 애플리케이션 컨테이너와 마찬가지로, 파드는 비교적 임시(계속 이어지는 것이 아닌) 엔티티로 간주된다. 파드가 생성되고, 고유 ID(UID)가 할당되고, 종료(재시작 정책에 따라) 또는 삭제될 때까지 남아있는 노드에 스케줄된다. 만약 노드가 종료되면, 해당 노드에 스케줄된 파드는 타임아웃 기간 후에 삭제되도록 스케줄된다.
파드는 자체적으로 자가 치유되지 않는다. 파드가 노드에 스케줄된 후에 해당 노드가 실패하면, 파드는 삭제된다. 마찬가지로, 파드는 리소스 부족 또는 노드 유지 관리 작업으로 인한 축출에서 살아남지 못한다. 쿠버네티스는 컨트롤러라 부르는 하이-레벨 추상화를 사용하여 상대적으로 일회용인 파드 인스턴스를 관리하는 작업을 처리한다.
UID로 정의된 특정 파드는 다른 노드로 절대 "다시 스케줄"되지 않는다. 대신, 해당 파드는 사용자가 원한다면 이름은 같지만, UID가 다른, 거의 동일한 새 파드로 대체될 수 있다.
볼륨과 같은 어떤 것이 파드와 동일한 수명을 갖는다는 것은, 특정 파드(정확한 UID 포함)가 존재하는 한 그것이 존재함을 의미한다. 어떤 이유로든 해당 파드가 삭제되고, 동일한 대체 파드가 생성되더라도, 관련된 그것(이 예에서는 볼륨)도 폐기되고 새로 생성된다.
Pod diagram
컨테이너 간의 공유 스토리지에 퍼시스턴트 볼륨을 사용하는 웹 서버와 파일 풀러(puller)가 포함된 다중 컨테이너 파드이다.
파드의 단계
파드의 status 필드는
phase 필드를 포함하는
PodStatus 오브젝트로 정의된다.
파드의 phase는 파드가 라이프사이클 중 어느 단계에 해당하는지 표현하는 간단한 고수준의 요약이다. Phase는 컨테이너나 파드의 관측 정보에 대한 포괄적인 롤업이나, 포괄적인 상태 머신을 표현하도록 의도되지는 않았다.
파드 phase 값에서 숫자와 의미는 엄격하게 지켜진다.
여기에 문서화된 내용 이외에는, 파드와 파드에 주어진 phase 값에 대해서
어떤 사항도 가정되어서는 안 된다.
phase에 가능한 값은 다음과 같다.
| 값 | 의미 |
|---|---|
Pending |
파드가 쿠버네티스 클러스터에서 승인되었지만, 하나 이상의 컨테이너가 설정되지 않았고 실행할 준비가 되지 않았다. 여기에는 파드가 스케줄되기 이전까지의 시간 뿐만 아니라 네트워크를 통한 컨테이너 이미지 다운로드 시간도 포함된다. |
Running |
파드가 노드에 바인딩되었고, 모든 컨테이너가 생성되었다. 적어도 하나의 컨테이너가 아직 실행 중이거나, 시작 또는 재시작 중에 있다. |
Succeeded |
파드에 있는 모든 컨테이너들이 성공적으로 종료되었고, 재시작되지 않을 것이다. |
Failed |
파드에 있는 모든 컨테이너가 종료되었고, 적어도 하나 이상의 컨테이너가 실패로 종료되었다. 즉, 해당 컨테이너는 non-zero 상태로 빠져나왔거나(exited) 시스템에 의해서 종료(terminated)되었다. |
Unknown |
어떤 이유에 의해서 파드의 상태를 얻을 수 없다. 이 단계는 일반적으로 파드가 실행되어야 하는 노드와의 통신 오류로 인해 발생한다. |
참고:
파드가 삭제될 때, 일부 kubectl 커맨드에서Terminating 이 표시된다.
이 Terminating 상태는 파드의 단계에 해당하지 않는다.
파드에는 그레이스풀하게(gracefully) 종료되도록 기간이 부여되며, 그 기본값은 30초이다.
강제로 파드를 종료하려면 --force 플래그를 설정하면 된다.노드가 죽거나 클러스터의 나머지와의 연결이 끊어지면, 쿠버네티스는
손실된 노드의 모든 파드의 phase 를 Failed로 설정하는 정책을 적용한다.
컨테이너 상태
전체 파드의 단계뿐 아니라, 쿠버네티스는 파드 내부의 각 컨테이너 상태를 추적한다. 컨테이너 라이프사이클 훅(hook)을 사용하여 컨테이너 라이프사이클의 특정 지점에서 실행할 이벤트를 트리거할 수 있다.
일단 스케줄러가
노드에 파드를 할당하면, kubelet은 컨테이너 런타임을
사용하여 해당 파드에 대한 컨테이너 생성을 시작한다.
표시될 수 있는 세 가지 컨테이너 상태는 Waiting, Running 그리고 Terminated 이다.
파드의 컨테이너 상태를 확인하려면, kubectl describe pod <name-of-pod> 를
사용할 수 있다. 출력 결과는 해당 파드 내의 각 컨테이너 상태가
표시된다.
각 상태에는 특정한 의미가 있다.
Waiting
만약 컨테이너가 Running 또는 Terminated 상태가 아니면, Waiting 상태이다.
Waiting 상태의 컨테이너는 시작을 완료하는 데 필요한
작업(예를 들어, 컨테이너 이미지 레지스트리에서 컨테이너 이미지 가져오거나,
시크릿(Secret) 데이터를 적용하는 작업)을
계속 실행하고 있는 중이다.
kubectl 을 사용하여 컨테이너가 Waiting 인 파드를 쿼리하면, 컨테이너가
해당 상태에 있는 이유를 요약하는 Reason 필드도 표시된다.
Running
Running 상태는 컨테이너가 문제없이 실행되고 있음을 나타낸다. postStart 훅이
구성되어 있었다면, 이미 실행되고 완료되었다. kubectl 을
사용하여 컨테이너가 Running 인 파드를 쿼리하면, 컨테이너가 Running 상태에 진입한 시기에 대한
정보도 볼 수 있다.
Terminated
Terminated 상태의 컨테이너는 실행을 시작한 다음 완료될 때까지
실행되었거나 어떤 이유로 실패했다. kubectl 을 사용하여 컨테이너가 Terminated 인 파드를
쿼리하면, 이유와 종료 코드 그리고 해당 컨테이너의 실행 기간에 대한 시작과
종료 시간이 표시된다.
컨테이너에 구성된 preStop 훅이 있는 경우,
이 혹은 컨테이너가 Terminated 상태에 들어가기 전에 실행된다.
컨테이너 재시작 정책
파드의 spec 에는 restartPolicy 필드가 있다. 사용 가능한 값은 Always, OnFailure 그리고
Never이다. 기본값은 Always이다.
restartPolicy 는 파드의 모든 컨테이너에 적용된다. restartPolicy 는
동일한 노드에서 kubelet에 의한 컨테이너 재시작만을 의미한다. 파드의 컨테이너가
종료된 후, kubelet은 5분으로 제한되는 지수 백오프 지연(10초, 20초, 40초, …)으로
컨테이너를 재시작한다. 컨테이너가 10분 동안 아무런 문제없이 실행되면,
kubelet은 해당 컨테이너의 재시작 백오프 타이머를 재설정한다.
파드의 컨디션
파드는 하나의 PodStatus를 가지며, 그것은 파드가 통과했거나 통과하지 못한 PodConditions 배열을 가진다. kubelet은 다음 PodConditions를 관리한다.
PodScheduled: 파드가 노드에 스케줄되었다.PodHasNetwork: (알파 기능; 반드시 명시적으로 활성화해야 함) 샌드박스가 성공적으로 생성되고 네트워킹이 구성되었다.ContainersReady: 파드의 모든 컨테이너가 준비되었다.Initialized: 모든 초기화 컨테이너가 성공적으로 완료(completed)되었다.Ready: 파드는 요청을 처리할 수 있으며 일치하는 모든 서비스의 로드 밸런싱 풀에 추가되어야 한다.
| 필드 이름 | 설명 |
|---|---|
type |
이 파드 컨디션의 이름이다. |
status |
가능한 값이 "True", "False", 또는 "Unknown"으로, 해당 컨디션이 적용 가능한지 여부를 나타낸다. |
lastProbeTime |
파드 컨디션이 마지막으로 프로브된 시간의 타임스탬프이다. |
lastTransitionTime |
파드가 한 상태에서 다른 상태로 전환된 마지막 시간에 대한 타임스탬프이다. |
reason |
컨디션의 마지막 전환에 대한 이유를 나타내는 기계가 판독 가능한 UpperCamelCase 텍스트이다. |
message |
마지막 상태 전환에 대한 세부 정보를 나타내는 사람이 읽을 수 있는 메시지이다. |
파드의 준비성(readiness)
기능 상태:
Kubernetes v1.14 [stable]
애플리케이션은 추가 피드백 또는 신호를 PodStatus: Pod readiness
와 같이 주입할 수 있다. 이를 사용하기 위해, kubelet이 파드의 준비성을 평가하기
위한 추가적인 컨디션들을 파드의 spec 내 readinessGate 필드를 통해서 지정할 수 있다.
준비성 게이트는 파드에 대한 status.condition 필드의 현재
상태에 따라 결정된다. 만약 쿠버네티스가 status.conditions 필드에서 해당하는
컨디션을 찾지 못한다면, 그 컨디션의 상태는
기본 값인 "False"가 된다.
여기 예제가 있다.
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 내장된 PodCondition이다
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 추가적인 PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...
추가하는 파드 상태에는 쿠버네티스 레이블 키 포맷을 충족하는 이름이 있어야 한다.
파드 준비성 상태
kubectl patch 명령어는 아직 오브젝트 상태 패치(patching)를 지원하지 않는다.
이러한 status.conditions 을 파드에 설정하려면 애플리케이션과
오퍼레이터의
PATCH 액션을 필요로 한다.
쿠버네티스 클라이언트 라이브러리를
사용해서 파드 준비성에 대한 사용자 지정 파드 컨디션을 설정하는 코드를 작성할 수 있다.
사용자 지정 컨디션을 사용하는 파드의 경우, 다음 두 컨디션이 모두 적용되는 경우에 만 해당 파드가 준비된 것으로 평가된다.
- 파드 내의 모든 컨테이너들이 준비 상태이다.
readinessGates에 지정된 모든 컨디션들이True이다.
파드의 컨테이너가 Ready 이나 적어도 한 개의 사용자 지정 컨디션이 빠졌거나 False 이면,
kubelet은 파드의 컨디션을 ContainerReady 로 설정한다.
파드 네트워크 준비성(readiness)
기능 상태:
Kubernetes v1.25 [alpha]
파드가 노드에 스케줄링되면, kubelet이 이 파드를 승인해야 하고
모든 볼륨이 마운트되어야 한다. 이러한 단계가 완료되면 kubelet은
(컨테이너 런타임 인터페이스(Container runtime interface, CRI)를 사용하여) 컨테이너 런타임과
통신하여 런타임 샌드박스를 설정하고 파드에 대한 네트워킹을 구성한다. 만약
PodHasNetworkCondition 기능 게이트가 활성화되면,
Kubelet은 파드의 status.conditions 필드에 있는 PodHasNetwork 컨디션을 통해
파드가 초기화 마일스톤에 도달했는지 여부를 보고한다.
Kubelet이 파드에 네트워킹이 구성된 런타임 샌드박스가
없음을 탐지했을 때 PodHasNetwork 컨디션은 False로 설정된다. 이것은 다음
시나리오에서 발생한다.
- 파드 라이프사이클 초기에, kubelet이 컨테이너 런타임을 사용하여 파드를 위한 샌드박스 생성을 아직 시작하지 않은 때.
- 파드 라이프사이클 후기에, 파드 샌드박스가 다음중 하나의 이유로
파괴되었을 때.
- 파드 축출 없이, 노드가 재부팅됨
- 격리를 위해 가상 머신을 사용하는 컨테이너 런타임을 사용하는 경우, 파드 샌드박스 가상 머신이 재부팅됨(이후, 새로운 샌드박스 및 새로운 컨테이너 네트워크 구성 생성이 필요함)
런타임 플러그인이 파드를 위한 샌드박스 생성 및 네트워크 구성을 성공적으로 완료하면
kubelet이 PodHasNetwork 컨디션을 True로 설정한다.
PodHasNetwork 컨디션이 True로 설정되면
kubelet이 컨테이너 이미지를 풀링하고 컨테이너를 생성할 수 있다.
초기화 컨테이너가 있는 파드의 경우, kubelet은 초기화 컨테이너가
성공적으로 완료(런타임 플러그인에 의한 성공적인 샌드박스 생성 및 네트워크 구성이 완료되었음을 의미)된 후
Initialized 컨디션을 True로 설정한다.
초기화 컨테이너가 없는 파드의 경우, kubelet은 샌드박스 생성 및 네트워크 구성이
시작되기 전에 Initialized 컨디션을 True로 설정한다.
컨테이너 프로브(probe)
프로브 는 컨테이너에서 kubelet에 의해 주기적으로 수행되는 진단(diagnostic)이다. 진단을 수행하기 위해서, kubelet은 컨테이너 안에서 코드를 실행하거나, 또는 네트워크 요청을 전송한다.
체크 메커니즘
프로브를 사용하여 컨테이너를 체크하는 방법에는 4가지가 있다. 각 프로브는 다음의 4가지 메커니즘 중 단 하나만을 정의해야 한다.
exec- 컨테이너 내에서 지정된 명령어를 실행한다. 명령어가 상태 코드 0으로 종료되면 진단이 성공한 것으로 간주한다.
grpc- gRPC를 사용하여
원격 프로시저 호출을 수행한다.
체크 대상이 gRPC 헬스 체크를 구현해야 한다.
응답의
status가SERVING이면 진단이 성공했다고 간주한다. gRPC 프로브는 알파 기능이며GRPCContainerProbe기능 게이트를 활성화해야 사용할 수 있다. httpGet- 지정한 포트 및 경로에서 컨테이너의 IP주소에 대한
HTTP
GET요청을 수행한다. 응답의 상태 코드가 200 이상 400 미만이면 진단이 성공한 것으로 간주한다. tcpSocket- 지정된 포트에서 컨테이너의 IP주소에 대해 TCP 검사를 수행한다. 포트가 활성화되어 있다면 진단이 성공한 것으로 간주한다. 원격 시스템(컨테이너)가 연결을 연 이후 즉시 닫는다면, 이 또한 진단이 성공한 것으로 간주한다.
프로브 결과
각 probe는 다음 세 가지 결과 중 하나를 가진다.
Success- 컨테이너가 진단을 통과함.
Failure- 컨테이너가 진단에 실패함.
Unknown- 진단 자체가 실패함(아무런 조치를 수행해서는 안 되며, kubelet이 추가 체크를 수행할 것이다)
프로브 종류
kubelet은 실행 중인 컨테이너들에 대해서 선택적으로 세 가지 종류의 프로브를 수행하고 그에 반응할 수 있다.
livenessProbe- 컨테이너가 동작 중인지 여부를 나타낸다. 만약
활성 프로브(liveness probe)에 실패한다면, kubelet은 컨테이너를 죽이고, 해당 컨테이너는
재시작 정책의 대상이 된다. 만약 컨테이너가
활성 프로브를 제공하지 않는 경우, 기본 상태는
Success이다. readinessProbe- 컨테이너가 요청을 처리할 준비가 되었는지 여부를 나타낸다.
만약 준비성 프로브(readiness probe)가 실패한다면, 엔드포인트 컨트롤러는
파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거한다. 준비성 프로브의
초기 지연 이전의 기본 상태는
Failure이다. 만약 컨테이너가 준비성 프로브를 지원하지 않는다면, 기본 상태는Success이다. startupProbe- 컨테이너 내의 애플리케이션이 시작되었는지를 나타낸다.
스타트업 프로브(startup probe)가 주어진 경우, 성공할 때까지 다른 나머지 프로브는
활성화되지 않는다. 만약 스타트업 프로브가 실패하면, kubelet이 컨테이너를 죽이고,
컨테이너는 재시작 정책에 따라 처리된다. 컨테이너에 스타트업
프로브가 없는 경우, 기본 상태는
Success이다.
활성, 준비성 및 스타트업 프로브를 설정하는 방법에 대한 추가적인 정보는, 활성, 준비성 및 스타트업 프로브 설정하기를 참조하면 된다.
언제 활성 프로브를 사용해야 하는가?
기능 상태:
Kubernetes v1.0 [stable]
만약 컨테이너 속 프로세스가 어떠한 이슈에 직면하거나 건강하지 못한
상태(unhealthy)가 되는 등 프로세스 자체의 문제로 중단될 수 있더라도, 활성 프로브가
반드시 필요한 것은 아니다. 그 경우에는 kubelet이 파드의 restartPolicy에
따라서 올바른 대처를 자동적으로 수행할 것이다.
프로브가 실패한 후 컨테이너가 종료되거나 재시작되길 원한다면, 활성 프로브를
지정하고, restartPolicy를 항상(Always) 또는 실패 시(OnFailure)로 지정한다.
언제 준비성 프로브를 사용해야 하는가?
기능 상태:
Kubernetes v1.0 [stable]
프로브가 성공한 경우에만 파드에 트래픽 전송을 시작하려고 한다면, 준비성 프로브를 지정하길 바란다. 이 경우에서는, 준비성 프로브가 활성 프로브와 유사해 보일 수도 있지만, 스팩에 준비성 프로브가 존재한다는 것은 파드가 트래픽을 받지 않는 상태에서 시작되고 프로브가 성공하기 시작한 이후에만 트래픽을 받는다는 뜻이다.
만약 컨테이너가 유지 관리를 위해서 자체 중단되게 하려면, 준비성 프로브를 지정하길 바란다. 준비성 프로브는 활성 프로브와는 다르게 준비성에 특정된 엔드포인트를 확인한다.
만약 애플리케이션이 백엔드 서비스에 엄격한 의존성이 있다면, 활성 프로브와 준비성 프로브 모두 활용할 수도 있다. 활성 프로브는 애플리케이션 스스로가 건강한 상태면 통과하지만, 준비성 프로브는 추가적으로 요구되는 각 백-엔드 서비스가 가용한지 확인한다. 이를 이용하여, 오류 메시지만 응답하는 파드로 트래픽이 가는 것을 막을 수 있다.
만약 컨테이너가 시동 시 대량 데이터의 로딩, 구성 파일, 또는 마이그레이션에 대한 작업을 수행해야 한다면, 스타트업 프로브를 사용하면 된다. 그러나, 만약 failed 애플리케이션과 시동 중에 아직 데이터를 처리하고 있는 애플리케이션을 구분하여 탐지하고 싶다면, 준비성 프로브를 사용하는 것이 더 적합할 것이다.
참고:
파드가 삭제될 때 요청들을 흘려 보내기(drain) 위해 준비성 프로브가 꼭 필요한 것은 아니다. 삭제 시에, 파드는 프로브의 존재 여부와 무관하게 자동으로 스스로를 준비되지 않은 상태(unready)로 변경한다. 파드는 파드 내의 모든 컨테이너들이 중지될 때까지 준비되지 않은 상태로 남아 있다.언제 스타트업 프로브를 사용해야 하는가?
기능 상태:
Kubernetes v1.20 [stable]
스타트업 프로브는 서비스를 시작하는 데 오랜 시간이 걸리는 컨테이너가 있는 파드에 유용하다. 긴 활성 간격을 설정하는 대신, 컨테이너가 시작될 때 프로브를 위한 별도의 구성을 설정하여, 활성 간격보다 긴 시간을 허용할 수 있다.
컨테이너가 보통 initialDelaySeconds + failureThreshold × periodSeconds
이후에 기동된다면, 스타트업 프로브가
활성화 프로브와 같은 엔드포인트를 확인하도록 지정해야 한다.
periodSeconds의 기본값은 10s 이다. 이 때 컨테이너가 활성화 프로브의
기본값 변경 없이 기동되도록 하려면, failureThreshold 를 충분히 높게 설정해주어야
한다. 그래야 데드락(deadlocks)을 방지하는데 도움이 된다.
파드의 종료
파드는 클러스터의 노드에서 실행되는 프로세스를 나타내므로, 해당 프로세스가
더 이상 필요하지 않을 때 정상적으로 종료되도록 하는 것이 중요하다(KILL
시그널로 갑자기 중지되고 정리할 기회가 없는 것 보다).
디자인 목표는 삭제를 요청하고 프로세스가 종료되는 시기를 알 수 있을 뿐만 아니라, 삭제가 결국 완료되도록 하는 것이다. 사용자가 파드의 삭제를 요청하면, 클러스터는 파드가 강제로 종료되기 전에 의도한 유예 기간을 기록하고 추적한다. 강제 종료 추적이 적용되면, kubelet은 정상 종료를 시도한다.
일반적으로, 컨테이너 런타임은 각 컨테이너의 기본 프로세스에 TERM 신호를
전송한다. 많은 컨테이너 런타임은 컨테이너 이미지에 정의된 STOPSIGNAL 값을 존중하며
TERM 대신 이 값을 보낸다.
일단 유예 기간이 만료되면, KILL 시그널이 나머지 프로세스로
전송되고, 그런 다음 파드는
API 서버로부터 삭제된다. 프로세스가
종료될 때까지 기다리는 동안 kubelet 또는 컨테이너 런타임의 관리 서비스가 다시 시작되면, 클러스터는
전체 원래 유예 기간을 포함하여 처음부터 다시 시도한다.
플로우의 예는 다음과 같다.
- 이
kubectl도구를 사용하여 기본 유예 기간(30초)으로 특정 파드를 수동으로 삭제한다. - API 서버의 파드는 유예 기간과 함께 파드가 "dead"로 간주되는
시간으로 업데이트된다.
kubectl describe를 사용하여 삭제하려는 파드를 확인하면, 해당 파드가 "Terminating"으로 표시된다. 파드가 실행 중인 노드에서, kubelet이 파드가 종료된 것(terminating)으로 표시되었음을 확인하는 즉시(정상적인 종료 기간이 설정됨), kubelet은 로컬 파드의 종료 프로세스를 시작한다.- 파드의 컨테이너 중 하나가
preStop훅을 정의한 경우, kubelet은 컨테이너 내부에서 해당 훅을 실행한다. 유예 기간이 만료된 후preStop훅이 계속 실행되면, kubelet은 2초의 작은 일회성 유예 기간 연장을 요청한다.참고:
`preStop` 훅을 완료하는 데 기본 유예 기간이 허용하는 것보다 오랜 시간이 필요한 경우, 이에 맞게 `terminationGracePeriodSeconds` 를 수정해야 한다. - kubelet은 컨테이너 런타임을 트리거하여 각 컨테이너 내부의 프로세스 1에 TERM 시그널을
보낸다.
참고:
파드의 컨테이너는 서로 다른 시간에 임의의 순서로 TERM 시그널을 수신한다. 종료 순서가 중요한 경우, `preStop` 훅을 사용하여 동기화하는 것이 좋다.
- 파드의 컨테이너 중 하나가
- kubelet이 정상 종료를 시작하는 동시에, 컨트롤 플레인은 구성된 셀렉터가 있는 서비스를 나타내는 엔드포인트슬라이스(EndpointSplice)(그리고 엔드포인트) 오브젝트에서 종료된 파드를 제거한다. 레플리카셋(ReplicaSet)과 기타 워크로드 리소스는 더 이상 종료된 파드를 유효한 서비스 내 복제본으로 취급하지 않는다. 로드 밸런서(서비스 프록시와 같은)가 종료 유예 기간이 시작되는 즉시 엔드포인트 목록에서 파드를 제거하므로 느리게 종료되는 파드는 트래픽을 계속 제공할 수 없다.
- 유예 기간이 만료되면, kubelet은 강제 종료를 트리거한다. 컨테이너 런타임은
SIGKILL을 파드의 모든 컨테이너에서 여전히 실행 중인 모든 프로세스로 전송한다. kubelet은 해당 컨테이너 런타임이 하나를 사용하는 경우 숨겨진pause컨테이너도 정리한다. - kubelet은 유예 기간을 0(즉시 삭제)으로 설정하여, API 서버에서 파드 오브젝트의 강제 삭제를 트리거한다.
- API 서버가 파드의 API 오브젝트를 삭제하면, 더 이상 클라이언트에서 볼 수 없다.
강제 파드 종료
주의:
강제 삭제는 일부 워크로드와 해당 파드에 대해서 잠재적으로 중단될 수 있다.기본적으로, 모든 삭제는 30초 이내에는 정상적으로 수행된다. kubectl delete 명령은
기본값을 재정의하고 사용자의 고유한 값을 지정할 수 있는 --grace-period=<seconds> 옵션을
지원한다.
유예 기간을 0 로 강제로 즉시 설정하면 API 서버에서 파드가
삭제된다. 파드가 노드에서 계속 실행 중인 경우, 강제 삭제는 kubelet을 트리거하여
즉시 정리를 시작한다.
참고:
강제 삭제를 수행하려면--grace-period=0 와 함께 추가 플래그 --force 를 지정해야 한다.강제 삭제가 수행되면, API 서버는 실행 중인 노드에서 파드가 종료되었다는 kubelet의 확인을 기다리지 않는다. API에서 즉시 파드를 제거하므로 동일한 이름으로 새로운 파드를 생성할 수 있다. 노드에서 즉시 종료되도록 설정된 파드는 강제 종료되기 전에 작은 유예 기간이 계속 제공된다.
주의:
즉시 제거는 실행 중인 자원이 정상적으로 종료되는 것을 보장하지 않는다. 자원은 클러스터에서 영원히 회수되지 않을 수 있다.스테이트풀셋(StatefulSet)의 일부인 파드를 강제 삭제해야 하는 경우, 스테이트풀셋에서 파드를 삭제하기에 대한 태스크 문서를 참고한다.
파드의 가비지 콜렉션
실패한 파드의 경우, API 오브젝트는 사람이나 컨트롤러 프로세스가 명시적으로 파드를 제거할 때까지 클러스터의 API에 남아 있다.
컨트롤 플레인에서의 컨트롤러 역할인 파드 가비지 콜렉터(PodGC)는, 파드 수가 구성된 임계값(kube-controller-manager에서
terminated-pod-gc-threshold 에 의해 결정됨)을 초과할 때 종료된 파드(Succeeded 또는
Failed 단계 포함)를 정리한다.
이렇게 하면 시간이 지남에 따라 파드가 생성되고 종료될 때 리소스 유출이 방지된다.
추가적으로 PodGC는 다음과 같은 조건들 중 하나라도 만족하는 파드들을 정리한다.
- 고아 파드 - 더 이상 존재하지 않는 노드에 종속되어있는 파드이거나,
- 스케줄되지 않은 종료 중인 파드이거나,
NodeOutOfServiceVolumeDetach기능 게이트가 활성화되어 있을 때,node.kubernetes.io/out-of-service에 테인트된 준비되지 않은 노드에 속한 종료 중인 파드인 경우에 적용된다.
PodDisruptionConditions 기능 게이트가 활성화된 경우, PodGC는
파드를 정리하는 것 뿐만 아니라 해당 파드들이 non-terminal 단계에 있는 경우
그들을 실패했다고 표시하기도 한다.
또한, PodGC는 고아 파드를 정리할 때 파드 중단 조건을 추가하기도 한다.
(자세한 내용은 파드 중단 조건을 확인한다.)
다음 내용
-
컨테이너 라이프사이클 이벤트에 핸들러를 연결하는 핸즈온 연습을 해보자.
-
활성, 준비성 및 스타트업 프로브 설정하는 핸즈온 연습을 해보자.
-
컨테이너 라이프사이클 훅에 대해 자세히 알아보자.
-
API의 파드와 컨테이너 상태에 대한 자세한 내용은 파드의
.status에 대해 다루는 API 레퍼런스 문서를 참고한다.
5.1.2 - 초기화 컨테이너
이 페이지는 초기화 컨테이너에 대한 개요를 제공한다. 초기화 컨테이너는 파드의 앱 컨테이너들이 실행되기 전에 실행되는 특수한 컨테이너이다. 초기화 컨테이너는 앱 이미지에는 없는 유틸리티 또는 설정 스크립트 등을 포함할 수 있다.
초기화 컨테이너는 containers 배열(앱 컨테이너를 기술하는)과 나란히
파드 스펙에 명시할 수 있다.
초기화 컨테이너 이해하기
파드는 앱들을 실행하는 다수의 컨테이너를 포함할 수 있고, 또한 앱 컨테이너 실행 전에 동작되는 하나 이상의 초기화 컨테이너도 포함할 수 있다.
다음의 경우를 제외하면, 초기화 컨테이너는 일반적인 컨테이너와 매우 유사하다.
- 초기화 컨테이너는 항상 완료를 목표로 실행된다.
- 각 초기화 컨테이너는 다음 초기화 컨테이너가 시작되기 전에 성공적으로 완료되어야 한다.
만약 파드의 초기화 컨테이너가 실패하면, kubelet은 초기화 컨테이너가 성공할 때까지 반복적으로 재시작한다.
그러나, 만약 파드의 restartPolicy 를 절대 하지 않음(Never)으로 설정하고, 해당 파드를 시작하는 동안 초기화 컨테이너가 실패하면, 쿠버네티스는 전체 파드를 실패한 것으로 처리한다.
컨테이너를 초기화 컨테이너로 지정하기 위해서는,
파드 스펙에 initContainers 필드를
container 항목(앱 container 필드 및 내용과 유사한)들의 배열로서 추가한다.
컨테이너에 대한 더 상세한 사항은
API 레퍼런스를 참고한다.
초기화 컨테이너의 상태는 컨테이너
상태의 배열(.status.containerStatuses 필드와 유사)로 .status.initContainerStatuses
필드에 반환된다.
일반적인 컨테이너와의 차이점
초기화 컨테이너는 앱 컨테이너의 리소스 상한(limit), 볼륨, 보안 세팅을 포함한 모든 필드와 기능을 지원한다. 그러나, 초기화 컨테이너를 위한 리소스 요청량과 상한은 리소스에 문서화된 것처럼 다르게 처리된다.
또한, 초기화 컨테이너는 lifecycle, livenessProbe, readinessProbe 또는 startupProbe 를 지원하지 않는다.
왜냐하면 초기화 컨테이너는 파드가 준비 상태가 되기 전에 완료를 목표로 실행되어야 하기 때문이다.
만약 다수의 초기화 컨테이너가 파드에 지정되어 있다면, kubelet은 해당 초기화 컨테이너들을 한 번에 하나씩 실행한다. 각 초기화 컨테이너는 다음 컨테이너를 실행하기 전에 꼭 성공해야 한다. 모든 초기화 컨테이너들이 실행 완료되었을 때, kubelet은 파드의 애플리케이션 컨테이너들을 초기화하고 평소와 같이 실행한다.
초기화 컨테이너 사용하기
초기화 컨테이너는 앱 컨테이너와는 별도의 이미지를 가지고 있기 때문에, 시동(start-up)에 관련된 코드로서 몇 가지 이점을 가진다.
- 앱 이미지에는 없는 셋업을 위한 유틸리티 또는 맞춤 코드를 포함할 수 있다.
예를 들어, 셋업 중에 단지
sed,awk,python, 또는dig와 같은 도구를 사용하기 위해서 다른 이미지로부터(FROM) 새로운 이미지를 만들 필요가 없다. - 애플리케이션 이미지 빌더와 디플로이어 역할은 독립적으로 동작될 수 있어서 공동의 단일 앱 이미지 형태로 빌드될 필요가 없다.
- 초기화 컨테이너는 앱 컨테이너와 다른 파일 시스템 뷰를 가지도록 리눅스 네임스페이스를 사용한다. 결과적으로, 초기화 컨테이너에는 앱 컨테이너가 가질 수 없는 시크릿에 접근 권한이 주어질 수 있다.
- 앱 컨테이너들은 병렬로 실행되는 반면, 초기화 컨테이너들은 어떠한 앱 컨테이너라도 시작되기 전에 실행 완료되어야 하므로, 초기화 컨테이너는 사전 조건들이 충족될 때까지 앱 컨테이너가 시동되는 것을 막거나 지연시키는 간편한 방법을 제공한다.
- 초기화 컨테이너는 앱 컨테이너 이미지의 보안성을 떨어뜨릴 수도 있는 유틸리티 혹은 커스텀 코드를 안전하게 실행할 수 있다. 불필요한 툴들을 분리한 채로 유지함으로써 앱 컨테이너 이미지의 공격에 대한 노출을 제한할 수 있다.
예제
초기화 컨테이너를 사용하는 방법에 대한 몇 가지 아이디어는 다음과 같다.
-
다음과 같은 셸 커맨드로, 서비스가 생성될 때까지 기다리기.
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; done; exit 1 -
다음과 같은 커맨드로, 다운워드 API(Downward API)를 통한 원격 서버에 해당 파드를 등록하기.
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)' -
다음과 같은 커맨드로 앱 컨테이너가 시작되기 전에 일정 시간 기다리기.
sleep 60 -
Git 저장소를 볼륨 안에 클론하기.
-
설정 파일에 값을 지정하고 메인 앱 컨테이너를 위한 설정 파일을 동적으로 생성하기 위한 템플릿 도구를 실행하기. 예를 들어, 설정에
POD_IP값을 지정하고 메인 앱 설정 파일을 Jinja를 통해서 생성.
사용 중인 초기화 컨테이너
쿠버네티스 1.5에 대한 다음의 yaml 파일은 두 개의 초기화 컨테이너를 포함한 간단한 파드에 대한 개요를 보여준다.
첫 번째는 myservice 를 기다리고 두 번째는 mydb 를 기다린다. 두 컨테이너들이
완료되면, 파드가 시작될 것이다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
다음 커맨드들을 이용하여 파드를 시작하거나 디버깅할 수 있다.
kubectl apply -f myapp.yaml
출력 결과는 다음과 같다.
pod/myapp-pod created
그리고 파드의 상태를 확인한다.
kubectl get -f myapp.yaml
출력 결과는 다음과 같다.
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
혹은 좀 더 자세히 살펴본다.
kubectl describe -f myapp.yaml
출력 결과는 다음과 같다.
Name: myapp-pod
Namespace: default
[...]
Labels: app.kubernetes.io/name=MyApp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container init-myservice
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container init-myservice
파드의 초기화 컨테이너의 상태를 보기 위해, 다음을 실행한다.
kubectl logs myapp-pod -c init-myservice # Inspect the first init container
kubectl logs myapp-pod -c init-mydb # Inspect the second init container
mydb 및 myservice 서비스를 시작하고 나면, 초기화 컨테이너가 완료되고
myapp-pod 가 생성된 것을 볼 수 있다.
여기에 이 서비스를 보이기 위해 사용할 수 있는 구성이 있다.
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
mydb 와 myservice 서비스 생성하기.
kubectl apply -f services.yaml
출력 결과는 다음과 같다.
service/myservice created
service/mydb created
초기화 컨테이너들이 완료되는 것과 myapp-pod 파드가 Running 상태로
변경되는 것을 볼 것이다.
kubectl get -f myapp.yaml
출력 결과는 다음과 같다.
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
이 간단한 예제는 사용자만의 초기화 컨테이너를 생성하는데 영감을 줄 것이다. 다음 순서에는 더 자세한 예제의 링크가 있다.
자세한 동작
파드 시작 시에 kubelet은 네트워크와 스토리지가 준비될 때까지 초기화 컨테이너의 실행을 지연시킨다. 그런 다음 kubelet은 파드 사양에 나와있는 순서대로 파드의 초기화 컨테이너를 실행한다.
각 초기화 컨테이너는 다음 컨테이너가 시작되기 전에 성공적으로
종료되어야 한다. 만약 런타임 문제나 실패 상태로 종료되는 문제로인하여 초기화 컨테이너의 시작이
실패된다면, 초기화 컨테이너는 파드의 restartPolicy 에 따라서 재시도 된다. 다만,
파드의 restartPolicy 가 항상(Always)으로 설정된 경우, 해당 초기화 컨테이너는
restartPolicy 를 실패 시(OnFailure)로 사용한다.
파드는 모든 초기화 컨테이너가 성공되기 전까지 Ready 될 수 없다. 초기화 컨테이너의 포트는
서비스 하에 합쳐지지 않는다. 초기화 중인 파드는 Pending 상태이지만
Initialized 가 거짓이 되는 조건을 가져야 한다.
만약 파드가 재시작되었다면, 모든 초기화 컨테이너는 반드시 다시 실행된다.
초기화 컨테이너 스펙 변경은 컨테이너 이미지 필드에서만 한정적으로 가능하다. 초기화 컨테이너 이미지 필드를 변경하는 것은 파드를 재시작하는 것과 같다.
초기화 컨테이너는 재시작되거나, 재시도, 또는 재실행 될 수 있기 때문에, 초기화 컨테이너
코드는 멱등성(idempotent)을 유지해야 한다. 특히, EmptyDirs 에 있는 파일에 쓰기를 수행하는 코드는
출력 파일이 이미 존재할 가능성에 대비해야 한다.
초기화 컨테이너는 앱 컨테이너의 필드를 모두 가지고 있다. 그러나, 쿠버네티스는
readinessProbe 가 사용되는 것을 금지한다. 초기화 컨테이너가 완료 상태와 준비성을
구분해서 정의할 수 없기 때문이다. 이것은 유효성 검사 중에 시행된다.
초기화 컨테이너들이 실패를 영원히 지속하는 상황을 방지하기 위해서
파드의 activeDeadlineSeconds를 사용한다.
Active deadline은 초기화 컨테이너를 포함한다.
그러나 팀에서 애플리케이션을 잡(job)으로 배포한 경우에만 activeDeadlineSeconds를 사용하길 추천한다. 왜냐하면, activeDeadlineSeconds는 초기화 컨테이너가 완료된 이후에도 영향을 주기 때문이다.
이미 정상적으로 동작하고 있는 파드도 activeDeadlineSeconds를 설정한 경우 종료(killed)될 수 있다.
파드 내의 각 앱과 초기화 컨테이너의 이름은 유일해야 한다. 어떤 컨테이너가 다른 컨테이너와 같은 이름을 공유하는 경우 유효성 오류가 발생한다.
리소스
초기화 컨테이너에게 명령과 실행이 주어진 경우, 리소스 사용에 대한 다음의 규칙이 적용된다.
- 모든 컨테이너에 정의된 특정 리소스 요청량 또는 상한 중 가장 높은 것은 유효 초기화 요청량/상한 이다. 리소스 제한이 지정되지 않은 리소스는 이 유효 초기화 요청량/상한을 가장 높은 요청량/상한으로 간주한다.
- 리소스를 위한 파드의 유효한 초기화 요청량/상한 은 다음 보다 더 높다.
- 모든 앱 컨테이너의 리소스에 대한 요청량/상한의 합계
- 리소스에 대한 유효한 초기화 요청량/상한
- 스케줄링은 유효한 요청/상한에 따라 이루어진다. 즉, 초기화 컨테이너는 파드의 삶에서는 사용되지 않는 초기화를 위한 리소스를 예약할 수 있다.
- 파드의 유효한 QoS 계층 에서 QoS(서비스의 품질) 계층은 초기화 컨테이너들과 앱 컨테이너들의 QoS 계층과 같다.
쿼터 및 상한은 유효한 파드의 요청량 및 상한에 따라 적용된다.
파드 레벨 cgroup은 유효한 파드 요청량 및 상한을 기반으로 한다. 이는 스케줄러와 같다.
파드 재시작 이유
파드는 다음과 같은 사유로, 초기화 컨테이너들의 재-실행을 일으키는, 재시작을 수행할 수 있다.
- 파드 인프라스트럭처 컨테이너가 재시작된 상황. 이는 일반적인 상황이 아니며 노드에 대해서 root 접근 권한을 가진 누군가에 의해서 수행됐을 것이다.
- 초기화 컨테이너의 완료 기록이 가비지 수집 때문에 유실된 상태에서,
restartPolicy가 Always로 설정된 파드의 모든 컨테이너가 종료되어 모든 컨테이너를 재시작해야 하는 상황
초기화 컨테이너 이미지가 변경되거나 초기화 컨테이너의 완료 기록이 가비지 수집 때문에 유실된 상태이면 파드는 재시작되지 않는다. 이는 쿠버네티스 버전 1.20 이상에 적용된다. 이전 버전의 쿠버네티스를 사용하는 경우 해당 쿠버네티스 버전의 문서를 참고한다.
다음 내용
5.1.3 - 중단(disruption)
이 가이드는 고가용성 애플리케이션을 구성하려는 소유자와 파드에서 발생하는 장애 유형을 이해하기 원하는 애플리케이션 소유자를 위한 것이다.
또한 클러스터의 업그레이드와 오토스케일링과 같은 클러스터의 자동화 작업을 하려는 관리자를 위한 것이다.
자발적 중단과 비자발적 중단
파드는 누군가(사람 또는 컨트롤러)가 파괴하거나 불가피한 하드웨어 오류 또는 시스템 소프트웨어 오류가 아니면 사라지지 않는다.
우리는 이런 불가피한 상황을 애플리케이션의 비자발적 중단 으로 부른다. 예시:
- 노드를 지원하는 물리 머신의 하드웨어 오류
- 클러스터 관리자의 실수로 VM(인스턴스) 삭제
- 클라우드 공급자 또는 하이퍼바이저의 오류로 인한 VM 장애
- 커널 패닉
- 클러스터 네트워크 파티션의 발생으로 클러스터에서 노드가 사라짐
- 노드의 리소스 부족으로 파드가 축출됨
리소스 부족을 제외한 나머지 조건은 대부분의 사용자가 익숙할 것이다. 왜냐하면 그 조건은 쿠버네티스에 국한되지 않기 때문이다.
우리는 다른 상황을 자발적인 중단 으로 부른다. 여기에는 애플리케이션 소유자의 작업과 클러스터 관리자의 작업이 모두 포함된다. 다음은 대표적인 애플리케이션 소유자의 작업이다.
- 디플로이먼트 제거 또는 다른 파드를 관리하는 컨트롤러의 제거
- 재시작을 유발하는 디플로이먼트의 파드 템플릿 업데이트
- 파드를 직접 삭제(예: 우연히)
클러스터 관리자의 작업은 다음을 포함한다.
- 복구 또는 업그레이드를 위한 노드 드레이닝.
- 클러스터의 스케일 축소를 위한 노드 드레이닝(클러스터 오토스케일링에 대해 알아보기 ).
- 노드에 다른 무언가를 추가하기 위해 파드를 제거.
위 작업은 클러스터 관리자가 직접 수행하거나 자동화를 통해 수행하며, 클러스터 호스팅 공급자에 의해서도 수행된다.
클러스터에 자발적인 중단을 일으킬 수 있는 어떤 원인이 있는지 클러스터 관리자에게 문의하거나 클라우드 공급자에게 문의하고, 배포 문서를 참조해서 확인해야 한다. 만약 자발적인 중단을 일으킬 수 있는 원인이 없다면 Pod Disruption Budget의 생성을 넘길 수 있다.
주의:
모든 자발적인 중단이 Pod Disruption Budget에 연관되는 것은 아니다. 예를 들어 디플로이먼트 또는 파드의 삭제는 Pod Disruption Budget을 무시한다.중단 다루기
비자발적인 중단으로 인한 영향을 경감하기 위한 몇 가지 방법은 다음과 같다.
- 파드가 필요로 하는 리소스를 요청하는지 확인한다.
- 고가용성이 필요한 경우 애플리케이션을 복제한다. (복제된 스테이트리스 및 스테이트풀 애플리케이션에 대해 알아보기.)
- 복제된 애플리케이션의 구동 시 훨씬 더 높은 가용성을 위해 랙 전체 (안티-어피니티 이용) 또는 영역 간 (다중 영역 클러스터를 이용한다면)에 애플리케이션을 분산해야 한다.
자발적 중단의 빈도는 다양하다. 기본적인 쿠버네티스 클러스터에서는 자동화된 자발적 중단은 발생하지 않는다(사용자가 지시한 자발적 중단만 발생한다). 그러나 클러스터 관리자 또는 호스팅 공급자가 자발적 중단이 발생할 수 있는 일부 부가 서비스를 운영할 수 있다. 예를 들어 노드 소프트웨어의 업데이트를 출시하는 경우 자발적 중단이 발생할 수 있다. 또한 클러스터(노드) 오토스케일링의 일부 구현에서는 단편화를 제거하고 노드의 효율을 높이는 과정에서 자발적 중단을 야기할 수 있다. 클러스터 관리자 또는 호스팅 공급자는 예측 가능한 자발적 중단 수준에 대해 문서화해야 한다. 파드 스펙 안에 프라이어리티클래스 사용하기와 같은 특정 환경설정 옵션 또한 자발적(+ 비자발적) 중단을 유발할 수 있다.
파드 disruption budgets
기능 상태:
Kubernetes v1.21 [stable]
쿠버네티스는 자발적인 중단이 자주 발생하는 경우에도 고 가용성 애플리케이션을 실행하는 데 도움이 되는 기능을 제공한다.
애플리케이션 소유자로써, 사용자는 각 애플리케이션에 대해 PodDisruptionBudget(PDB)을 만들 수 있다. PDB는 자발적 중단으로 일시에 중지되는 복제된 애플리케이션 파드의 수를 제한한다. 예를 들어, 정족수 기반의 애플리케이션이 실행 중인 레플리카의 수가 정족수 이하로 떨어지지 않도록 한다. 웹 프런트 엔드는 부하를 처리하는 레플리카의 수가 일정 비율 이하로 떨어지지 않도록 보장할 수 있다.
클러스터 관리자와 호스팅 공급자는 직접적으로 파드나 디플로이먼트를 제거하는 대신 Eviction API로 불리는 PodDisruptionBudget을 준수하는 도구를 이용해야 한다.
예를 들어, kubectl drain 하위 명령을 사용하면 노드를 서비스 중단으로 표시할 수
있다. kubectl drain 을 실행하면, 도구는 사용자가 서비스를 중단하는 노드의
모든 파드를 축출하려고 한다. kubectl 이 사용자를 대신하여 수행하는
축출 요청은 일시적으로 거부될 수 있으며,
도구는 대상 노드의 모든 파드가 종료되거나
설정 가능한 타임아웃이 도래할 때까지 주기적으로 모든 실패된 요청을 다시 시도한다.
PDB는 애플리케이션이 필요로 하는 레플리카의 수에 상대적으로, 용인할 수 있는 레플리카의 수를 지정한다.
예를 들어 .spec.replicas: 5 의 값을 갖는 디플로이먼트는 어느 시점에든 5개의 파드를 가져야 한다.
만약 해당 디플로이먼트의 PDB가 특정 시점에 파드를 4개 허용한다면,
Eviction API는 한 번에 1개(2개의 파드가 아닌)의 파드의 자발적인 중단을 허용한다.
파드 그룹은 레이블 셀렉터를 사용해서 지정한 애플리케이션으로 구성되며 애플리케이션 컨트롤러(디플로이먼트, 스테이트풀셋 등)를 사용한 것과 같다.
파드의 "의도"하는 수량은 해당 파드를 관리하는 워크로드 리소스의 .spec.replicas 를
기반으로 계산한다. 컨트롤 플레인은 파드의 .metadata.ownerReferences 를 검사하여
소유하는 워크로드 리소스를 발견한다.
비자발적 중단은 PDB로는 막을 수 없지만, 버짓은 차감된다.
애플리케이션의 롤링 업그레이드로 파드가 삭제되거나 사용할 수 없는 경우 중단 버짓에 영향을 준다. 그러나 워크로드 리소스(디플로이먼트, 스테이트풀셋과 같은)는 롤링 업데이트 시 PDB의 제한을 받지 않는다. 대신, 애플리케이션 업데이트 중 실패 처리는 특정 워크로드 리소스에 대한 명세에서 구성된다.
Eviction API를 사용하여 파드를 축출하면,
PodSpec의
terminationGracePeriodSeconds 설정을 준수하여 정상적으로 종료됨 상태가 된다.
PodDisruptionBudget 예시
node-1 부터 node-3 까지 3개의 노드가 있는 클러스터가 있다고 하자.
클러스터에는 여러 애플리케이션을 실행하고 있다.
여러 애플리케이션 중 하나는 pod-a, pod-b, pod-c 로 부르는 3개의 레플리카가 있다. 여기에 pod-x 라고 부르는 PDB와 무관한 파드가 보인다.
초기에 파드는 다음과 같이 배치된다.
| node-1 | node-2 | node-3 |
|---|---|---|
| pod-a available | pod-b available | pod-c available |
| pod-x available |
전체 3개 파드는 디플로이먼트의 일부분으로 전체적으로 항상 3개의 파드 중 최소 2개의 파드를 사용할 수 있도록 하는 PDB를 가지고 있다.
예를 들어, 클러스터 관리자가 커널 버그를 수정하기위해 새 커널 버전으로 재부팅하려는 경우를 가정해보자.
클러스터 관리자는 첫째로 node-1 을 kubectl drain 명령어를 사용해서 비우려 한다.
kubectl 은 pod-a 과 pod-x 를 축출하려고 한다. 이는 즉시 성공한다.
두 파드는 동시에 terminating 상태로 진입한다.
이렇게 하면 클러스터는 다음의 상태가 된다.
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating |
디플로이먼트는 한 개의 파드가 중지되는 것을 알게되고, pod-d 라는 대체 파드를 생성한다.
node-1 은 차단되어 있어 다른 노드에 위치한다.
무언가가 pod-x 의 대체 파드로 pod-y 도 생성했다.
(참고: 스테이트풀셋은 pod-0 처럼 불릴, pod-a 를
교체하기 전에 완전히 중지해야 하며, pod-0 로 불리지만, 다른 UID로 생성된다.
그렇지 않으면 이 예시는 스테이트풀셋에도 적용된다.)
이제 클러스터는 다음과 같은 상태이다.
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating | pod-d starting | pod-y |
어느 순간 파드가 종료되고, 클러스터는 다음과 같은 상태가 된다.
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d starting | pod-y |
이 시점에서 만약 성급한 클러스터 관리자가 node-2 또는 node-3 을
비우려고 하는 경우 디플로이먼트에 available 상태의 파드가 2개 뿐이고,
PDB에 필요한 최소 파드는 2개이기 때문에 drain 명령이 차단된다. 약간의 시간이 지나면 pod-d 가 available 상태가 된다.
이제 클러스터는 다음과 같은 상태이다.
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d available | pod-y |
이제 클러스터 관리자는 node-2 를 비우려고 한다.
drain 커멘드는 pod-b 에서 pod-d 와 같이 어떤 순서대로 두 파드를 축출하려 할 것이다.
drain 커멘드는 pod-b 를 축출하는데 성공했다.
그러나 drain 커멘드가 pod-d 를 축출하려 하는 경우
디플로이먼트에 available 상태의 파드는 1개로 축출이 거부된다.
디플로이먼트는pod-b 를 대체할 pod-e 라는 파드를 생성한다.
클러스터에 pod-e 를 스케줄하기 위한 충분한 리소스가 없기 때문에
드레이닝 명령어는 차단된다.
클러스터는 다음 상태로 끝나게 된다.
| node-1 drained | node-2 | node-3 | no node |
|---|---|---|---|
| pod-b terminating | pod-c available | pod-e pending | |
| pod-d available | pod-y |
이 시점에서 클러스터 관리자는 클러스터에 노드를 추가해서 업그레이드를 진행해야 한다.
쿠버네티스에 중단이 발생할 수 있는 비율을 어떻게 변화시키는지 다음의 사례를 통해 알 수 있다.
- 애플리케이션에 필요한 레플리카의 수
- 인스턴스를 정상적으로 종료하는데 소요되는 시간
- 새 인스턴스를 시작하는데 소요되는 시간
- 컨트롤러의 유형
- 클러스터의 리소스 용량
파드 중단 조건
기능 상태:
Kubernetes v1.26 [beta]
참고:
만약 쿠버네티스 1.31 보다 낮은 버전을 사용하고 있다면, 해당 버전의 문서를 참조하자.이 기능이 활성화되면, 파드 전용 DisruptionTarget 컨디션이 추가되어
중단(disruption)으로 인해 파드가 삭제될 예정임을 나타낸다.
추가로 컨디션의 reason 필드는
파드 종료에 대한 다음 원인 중 하나를 나타낸다.
PreemptionByKubeScheduler- 파드는 더 높은 우선순위를 가진 새 파드를 수용하기 위해 스케줄러에 의해 선점(preempted)된다. 자세한 내용은 파드 우선순위(priority)와 선점(preemption)을 참조해보자.
DeletionByTaintManager- 허용하지 않는
NoExecute테인트(taint) 때문에 파드가 테인트 매니저(kube-controller-manager내의 노드 라이프사이클 컨트롤러의 일부)에 의해 삭제될 예정이다. taint 기반 축출을 참조해보자. EvictionByEvictionAPI- 파드에 쿠버네티스 API를 이용한 축출이 표시되었다.
DeletionByPodGC- 더 이상 존재하지 않는 노드에 바인딩된 파드는 파드의 가비지 콜렉션에 의해 삭제될 예정이다.
TerminationByKubelet- 노드 압박-축출 또는 그레이스풀 노드 셧다운으로 인해 kubelet이 파드를 종료시켰다.
참고:
파드 중단은 중단될 수 있다. 컨트롤 플레인은 동일한 파드의 중단을 계속 다시 시도하지만, 파드의 중단이 보장되지는 않는다. 결과적으로,DisruptionTarget 컨디션이 파드에 추가될 수 있지만, 해당 파드는 사실상
삭제되지 않았을 수 있다. 이러한 상황에서는, 일정 시간이 지난 뒤에
파드 중단 상태가 해제된다.잡(또는 크론잡(CronJob))을 사용할 때, 이러한 파드 중단 조건을 잡의 파드 실패 정책의 일부로 사용할 수 있다.
클러스터 소유자와 애플리케이션 소유자의 역할 분리
보통 클러스터 매니저와 애플리케이션 소유자는 서로에 대한 지식이 부족한 별도의 역할로 생각하는 것이 유용하다. 이와 같은 책임의 분리는 다음의 시나리오에서 타당할 수 있다.
- 쿠버네티스 클러스터를 공유하는 애플리케이션 팀이 많고, 자연스럽게 역할이 나누어진 경우
- 타사 도구 또는 타사 서비스를 이용해서 클러스터 관리를 자동화 하는 경우
Pod Disruption Budget은 역할 분리에 따라 역할에 맞는 인터페이스를 제공한다.
만약 조직에 역할 분리에 따른 책임의 분리가 없다면 Pod Disruption Budget을 사용할 필요가 없다.
클러스터에서 중단이 발생할 수 있는 작업을 하는 방법
만약 클러스터 관리자라면, 그리고 클러스터 전체 노드에 노드 또는 시스템 소프트웨어 업그레이드와 같은 중단이 발생할 수 있는 작업을 수행하는 경우 다음과 같은 옵션을 선택한다.
- 업그레이드 하는 동안 다운타임을 허용한다.
- 다른 레플리카 클러스터로 장애조치를 한다.
- 다운타임은 없지만, 노드 사본과 전환 작업을 조정하기 위한 인력 비용이 많이 발생할 수 있다.
- PDB를 이용해서 애플리케이션의 중단에 견디도록 작성한다.
- 다운타임 없음
- 최소한의 리소스 중복
- 클러스터 관리의 자동화 확대 적용
- 내결함성이 있는 애플리케이션의 작성은 까다롭지만 자발적 중단를 허용하는 작업의 대부분은 오토스케일링과 비자발적 중단를 지원하는 작업과 겹친다.
다음 내용
-
Pod Disruption Budget 설정하기의 단계를 따라서 애플리케이션을 보호한다.
-
노드 비우기에 대해 자세히 알아보기
-
롤아웃 중에 가용성을 유지하는 단계를 포함하여 디플로이먼트 업데이트에 대해 알아보기
5.1.4 - 임시(Ephemeral) 컨테이너
기능 상태:
Kubernetes v1.25 [stable]
이 페이지는 임시 컨테이너에 대한 개요를 제공한다. 이 특별한 유형의 컨테이너는 트러블슈팅과 같은 사용자가 시작한 작업을 완료하기 위해 기존 파드에서 임시적으로 실행된다. 임시 컨테이너는 애플리케이션을 빌드하는 경우보다는 서비스 점검과 같은 경우에 더 적합하다.
임시 컨테이너 이해하기
파드 는 쿠버네티스 애플리케이션의 기본 구성 요소이다. 파드는 일회용이고, 교체 가능한 것으로 의도되었기 때문에, 사용자는 파드가 한번 생성되면, 컨테이너를 추가할 수 없다. 대신, 사용자는 보통 디플로이먼트 를 사용해서 제어하는 방식으로 파드를 삭제하고 교체한다.
그러나 때때로 재현하기 어려운 버그의 문제 해결을 위해 기존 파드의 상태를 검사해야 할 수 있다. 이 경우 사용자는 기존 파드에서 임시 컨테이너를 실행해서 상태를 검사하고, 임의의 명령을 실행할 수 있다.
임시 컨테이너는 무엇인가?
임시 컨테이너는 리소스 또는 실행에 대한 보증이 없다는 점에서
다른 컨테이너와 다르며, 결코 자동으로 재시작되지 않는다. 그래서
애플리케이션을 만드는데 적합하지 않다. 임시 컨테이너는
일반 컨테이너와 동일한 ContainerSpec 을 사용해서 명시하지만, 많은 필드가
호환되지 않으며 임시 컨테이너에는 허용되지 않는다.
- 임시 컨테이너는 포트를 가지지 않을 수 있으므로,
ports,livenessProbe,readinessProbe와 같은 필드는 허용되지 않는다. - 파드에 할당된 리소스는 변경할 수 없으므로,
resources설정이 허용되지 않는다. - 허용되는 필드의 전체 목록은 임시컨테이너 참조 문서를 본다.
임시 컨테이너는 pod.spec 에 직접 추가하는 대신
API에서 특별한 ephemeralcontainers 핸들러를 사용해서 만들어지기 때문에
kubectl edit을 사용해서 임시 컨테이너를 추가할 수 없다.
일반 컨테이너와 마찬가지로, 사용자는 임시 컨테이너를 파드에 추가한 이후에 변경하거나 제거할 수 없다.
참고:
임시 컨테이너는 스태틱 파드에서 지원되지 않는다.임시 컨테이너의 사용
임시 컨테이너는 컨테이너가 충돌 되거나 또는 컨테이너 이미지에
디버깅 도구가 포함되지 않은 이유로 kubectl exec 이 불충분할 때
대화형 문제 해결에 유용하다.
특히, distroless 이미지
를 사용하면 공격 표면(attack surface)과 버그 및 취약점의 노출을 줄이는 최소한의
컨테이너 이미지를 배포할 수 있다. distroless 이미지는 셸 또는 어떤 디버깅 도구를
포함하지 않기 때문에, kubectl exec 만으로는 distroless
이미지의 문제 해결이 어렵다.
임시 컨테이너 사용 시 프로세스 네임스페이스 공유를 활성화하면 다른 컨테이너 안의 프로세스를 보는 데 도움이 된다.
다음 내용
- 임시 컨테이너 디버깅하기에 대해 알아보기.
5.1.5 - 사용자 네임스페이스
기능 상태:
Kubernetes v1.25 [alpha]
이 페이지에서는 사용자 네임스페이스가 쿠버네티스 파드에서 사용되는 방법에 대해 설명한다. 사용자 네임스페이스는 컨테이너 내에서 실행 중인 사용자와 호스트의 사용자를 분리할 수 있도록 한다.
컨테이너에서 루트(root)로 실행되는 프로세스는 호스트에서 다른 (루트가 아닌) 사용자로 실행될 수 있다. 즉, 프로세스는 사용자 네임스페이스 내부 작업에 대해 특권을 갖지만(privileged) 네임스페이스 외부의 작업에서는 특권을 갖지 않는다.
이러한 기능을 사용하여 훼손(compromised)된 컨테이너가 호스트나 동일한 노드의 다른 파드에 미칠 수 있는 손상을 줄일 수 있다. HIGH 또는 CRITICAL 등급의 일부 보안 취약점은 사용자 네임스페이스가 Active 상태일 때 사용할 수 없다. 사용자 네임스페이스는 일부 미래의 취약점들도 완화시킬 수 있을 것으로 기대된다.
시작하기 전에
🛇 이 항목은 쿠버네티스에 속하지 않는 써드파티 프로젝트 또는 제품의 링크로 연결됩니다. 추가 정보
이것은 리눅스 전용 기능이다. 또한 컨테이너 런타임에서 이 기능을 쿠버네티스 스테이트리스(stateless) 파드와 함께 사용하려면 지원이 필요하다.
-
CRI-O: v1.25에는 사용자 네임스페이스가 지원된다.
-
containerd: 1.7 릴리즈에서 지원이 계획돼 있다. 자세한 내용은 containerd 이슈 #7063를 참조한다.
cri-dockerd에서의 지원은 아직 계획되지 않았다.
개요
사용자 네임스페이스는 컨테이너의 사용자를 호스트의 다른 사용자에게 매핑할 수 있는 리눅스 기능이다. 또한 사용자 네임스페이스의 파드에 부여된 기능은 네임스페이스 내부에서만 유효하고 외부에서는 무효하다.
파드는 pod.spec.hostUsers 필드를 false로 설정해
사용자 네임스페이스를 사용하도록 선택할 수 있다.
kubelet은 동일 노드에 있는 두 개의 스테이트리스 파드가 동일한 매핑을 사용하지 않도록 보장하는 방식으로 파드가 매핑된 호스트 UID나 GID를 선택한다.
pod.spec의 runAsUser, runAsGroup, fsGroup 등의 필드는 항상
컨테이너 내의 사용자를 가리킨다.
이 기능을 활성화한 경우 유효한 UID/GID의 범위는 0부터 65535까지이다.
이는 파일 및 프로세스(runAsUser, runAsGroup 등)에 적용된다.
이 범위를 벗어나는 UID/GID를 사용하는 파일은 오버플로 ID,
주로 65534(/proc/sys/kernel/overflowuid와 /proc/sys/kernel/overflowgid에서 설정됨)에
속하는 것으로 간주된다.
그러나 65534 사용자/그룹으로 실행하더라도 이러한 파일을 수정할 수 없다.
루트로 실행돼야 하지만 다른 호스트 네임스페이스나 리소스에 접근하지 않는 대부분의 애플리케이션은 사용자 네임스페이스를 활성화한 경우 변경할 필요 없이 계속 정상적으로 실행돼야 한다.
스테이트리스 파드의 사용자 네임스페이스 이해하기
기본 설정의 여러 컨테이너 런타임(Docker Engine, containerd, CRI-O 등)은 격리를 위해 리눅스 네임스페이스를 사용한다. 다른 기술도 존재하며 위와 같은 런타임에도 사용할 수 있다. (예를 들어, Kata Container는 리눅스 네임스페이스 대신 VM을 사용한다.) 이 페이지는 격리를 위해 리눅스 네임스페이스를 사용하는 컨테이너 런타임에 주안을 둔다.
파드를 생성할 때 기본적으로 컨테이너의 네트워크를 분리하는 네임스페이스, 프로세스 보기를 분리하는 PID 네임스페이스 등 여러 새로운 네임스페이스가 격리에 사용된다. 사용자 네임스페이스를 사용하면 컨테이너의 사용자와 노드의 사용자가 격리된다.
이는 컨테이너가 루트로 실행될 수 있고 호스트의 루트가 아닌 사용자에게 매핑될 수 있다는 것을 의미한다.
컨테이너 내부에서 프로세스는 자신이 루트로 실행된다고 생각하지만
(따라서 apt, yum 등과 같은 도구가 정상적으로 작동)
실제로 프로세스는 호스트에 대한 권한이 없다.
예를 들어, 호스트에서 ps aux를 실행함으로써
컨테이너 프로세스가 어느 사용자에 의해 실행 중인지 확인할 수 있다.
사용자 ps는 컨테이너 안에서 명령 id를 실행하면 나타나는 사용자와 동일하지 않다.
이 추상화는 컨테이너가 호스트로 탈출하는 것과 같은 상황을 제한한다. 컨테이너가 호스트에서 권한이 없는 사용자로 실행 중이기 때문에 호스트에게 수행할 수 있는 작업은 제한된다.
또한, 각 파드의 사용자는 호스트의 서로 겹치지 않는 다른 사용자에게 매핑되므로 다른 파드에 대해서도 수행할 수 있는 작업이 제한된다.
파드에 부여된 기능 또한 파드 사용자 네임스페이스로 제한되는데 대부분 유효하지 않고 심지어 일부는 완전히 무효하다. 다음은 두 가지 예시이다.
CAP_SYS_MODULE은 사용자 네임스페이스를 사용하여 파드에 부여돼도 아무런 효과가 없으며 파드는 커널 모듈을 로드할 수 없다.CAP_SYS_ADMIN은 파드의 사용자 네임스페이스로 제한되며 네임스페이스 외부에서는 유효하지 않다.
사용자 네임스페이스를 사용하지 않고 루트로 실행되는 컨테이너는 컨테이너 브레이크아웃(container breakout)의 경우 노드에 대한 루트 권한을 가진다. 컨테이너에 일부 기능이 부여된 경우 호스트에서도 해당 기능이 유효하다. 사용자 네임스페이스를 사용할 경우 이 중 어느 것도 사실이 아니다.
사용자 네임스페이스 사용 시 변경사항에 대한 자세한 내용은
man 7 user_namespace를 참조한다.
사용자 네임스페이스를 지원하도록 노드 설정하기
호스트의 파일 및 프로세스에서 0 ~ 65535 범위의 UID/GID를 사용하는 것이 좋다.
kubelet은 파드에 그것보다 더 높은 UID/GID를 할당한다. 따라서 가능한 많은 격리를 보장하려면 호스트의 파일 및 호스트의 프로세스에 사용되는 UID/GID가 0-65535 범위여야 한다.
이 권장 사항은 파드가 호스트의 임의의 파일을 잠재적으로 읽을 수 있는 CVE-2021-25741과 같은 CVE의 영향을 완화하기 위해 중요하다. 파드와 호스트의 UID/GID가 겹치지 않으면 파드가 수행할 수 있는 작업이 제한된다. 즉, 파드 UID/GID가 호스트의 파일 소유자/그룹과 일치하지 않게 된다.
제약 사항
파드에 사용자 네임스페이스를 사용하는 경우
다른 호스트 네임스페이스를 사용할 수 없다.
특히 hostUsers: false를 설정하면 다음 중 하나를 설정할 수 없다.
hostNetwork: truehostIPC: truehostPID: true
파드는 볼륨을 전혀 사용하지 않거나 볼륨을 사용하는 경우에는 다음 볼륨 유형만 사용할 수 있다.
- configmap
- secret
- projected
- downwardAPI
- emptyDir
파드가 이러한 볼륨의 파일을 읽을 수 있도록 하기 위해
파드에 .spec.securityContext.fsGroup을
0으로 지정한 것처럼 볼륨이 생성된다.
이 값이 다른 값으로 지정되면 당연히 이 다른 값이 대신 적용된다.
이로 인해 볼륨의 특정 항목에 대한 defaultMode나 mode가
그룹에 대한 권한 없이 지정되었더라도
이러한 볼륨에 대한 폴더와 파일은 그룹에 대한 권한을 갖는다.
예를 들어 파일에 소유자에 대한 권한만 있는 방식으로
이러한 볼륨을 마운트할 수 없다.
5.1.6 - 다운워드(Downward) API
실행 중인 컨테이너에 파드 및 컨테이너 필드를 노출하는 두 가지 방법이 있다. 환경 변수를 활용하거나, 그리고 특수한 볼륨 타입으로 채워진 파일을 이용한다. 파드 및 컨테이너 필드를 노출하는 이 두 가지 방법을 다운워드 API라고 한다.
컨테이너가 쿠버네티스에 지나치게 종속되지 않으면서도 자기 자신에 대한 정보를 알고 있으면 유용할 때가 있다. 다운워드 API는 컨테이너가 자기 자신 혹은 클러스터에 대한 정보를, 쿠버네티스 클라이언트나 API 서버 없이도 사용할 수 있게 한다.
예를 들어, 잘 알려진 특정 환경 변수에다가 고유한 식별자를 넣어 사용하는 애플리케이션이 있다고 하자. 해당 애플리케이션에 맞게 작업할 수도 있겠지만, 이는 지루하고 오류가 나기 쉬울뿐더러, 낮은 결합이라는 원칙에도 위배된다. 대신, 파드의 이름을 식별자로 사용하고 잘 알려진 환경 변수에 파드의 이름을 넣는 것도 괜찮은 방법이다.
쿠버네티스에는 실행 중인 컨테이너에 파드 및 컨테이너 필드를 노출하는 두 가지 방법이 있다.
파드 및 컨테이너 필드를 노출하는 이 두 가지 방법을 다운워드 API라고 한다.
사용 가능한 필드
쿠버네티스 API 필드 중 일부만이 다운워드 API를 통해 접근 가능하다. 이 페이지에서는 사용 가능한 필드를 나열한다.
사용 가능한 파드 필드에 대한 정보는 fieldRef를 통해 넘겨줄 수 있다.
API 레벨에서, 파드의 spec은 항상 하나 이상의
컨테이너를 정의한다.
사용 가능한 컨테이너 필드에 대한 정보는
resourceFiledRef를 통해 넘겨줄 수 있다.
fieldRef를 통해 접근 가능한 정보
대부분의 파드 필드는 환경 변수로써,
또는 다운워드 API 볼륨을 사용하여 컨테이너에 제공할 수 있다.
이런 두 가지 방법을 통해 사용 가능한 필드는 다음과 같다.
metadata.name- 파드의 이름
metadata.namespace- 파드가 속한 네임스페이스
metadata.uid- 파드의 고유 ID
metadata.annotations['<KEY>']- 파드의 어노테이션에서
<KEY>에 해당하는 값 (예를 들어,metadata.annotations['myannotation']) metadata.labels['<KEY>']- 파드의 레이블에서
<KEY>에 해당하는 문자열 (예를 들어,metadata.labels['mylabel']) spec.serviceAccountName- 파드의 서비스 어카운트
spec.nodeName- 파드가 실행중인 노드명
status.hostIP- 파드가 할당된 노드의 기본 IP 주소
status.podIP- 파드의 기본 IP 주소 (일반적으로 IPv4 주소)
추가적으로 아래 필드는 환경 변수가 아닌,
다운워드 API 볼륨의 fieldRef로만 접근 가능하다.
metadata.labels- 파드의 모든 레이블로, 한 줄마다 하나의 레이블을 갖는(
label-key="escaped-label-value") 형식을 취함 metadata.annotations- 파드의 모든 어노테이션으로, 한 줄마다 하나의 어노테이션을 갖는(
annotation-key="escaped-annotation-value") 형식을 취함
resourceFieldRef를 통해 접근 가능한 정보
컨테이너 필드는 CPU와 메모리 같은 리소스에 대한 요청 및 제한 값을 제공한다.
resource: limits.cpu- 컨테이너의 CPU 제한
resource: requests.cpu- 컨테이너의 CPU 요청
resource: limits.memory- 컨테이너의 메모리 제한
resource: requests.memory- 컨테이너의 메모리 요청
resource: limits.hugepages-*- 컨테이너의 hugepage 제한 (
DownwardAPIHugePages기능 게이트가 활성화 된 경우) resource: requests.hugepages-*- 컨테이너의 hugepage 요청 (
DownwardAPIHugePages기능 게이트가 활성화 된 경우) resource: limits.ephemeral-storage- 컨테이너의 임시 스토리지 제한
resource: requests.ephemeral-storage- 컨테이너의 임시 스토리지 요청
리소스 제한에 대한 참고 정보
컨테이너의 CPU와 메모리 제한을 명시하지 않고 다운워드 API로 이 정보들을 제공하려고 할 경우, kubelet은 기본적으로 노드의 할당 가능량에 기반하여 CPU와 메모리에 할당 가능한 최댓값을 노출시킨다.
다음 내용
자세한 정보는 다운워드API 볼륨를 참고한다.
다운워드 API를 사용하여 파드 및 컨테이너 정보를 노출시켜보자.
5.2 - 워크로드 리소스
5.2.1 - 디플로이먼트
디플로이먼트(Deployment) 는 파드와 레플리카셋(ReplicaSet)에 대한 선언적 업데이트를 제공한다.
디플로이먼트에서 의도하는 상태 를 설명하고, 디플로이먼트 컨트롤러(Controller)는 현재 상태에서 의도하는 상태로 비율을 조정하며 변경한다. 새 레플리카셋을 생성하는 디플로이먼트를 정의하거나 기존 디플로이먼트를 제거하고, 모든 리소스를 새 디플로이먼트에 적용할 수 있다.
참고:
디플로이먼트가 소유하는 레플리카셋은 관리하지 말아야 한다. 사용자의 유스케이스가 다음에 포함되지 않는 경우 쿠버네티스 리포지터리에 이슈를 올릴 수 있다.유스케이스
다음은 디플로이먼트의 일반적인 유스케이스이다.
- 레플리카셋을 롤아웃 할 디플로이먼트 생성. 레플리카셋은 백그라운드에서 파드를 생성한다. 롤아웃 상태를 체크해서 성공 여부를 확인한다.
- 디플로이먼트의 PodTemplateSpec을 업데이트해서 파드의 새로운 상태를 선언한다. 새 레플리카셋이 생성되면, 디플로이먼트는 파드를 기존 레플리카셋에서 새로운 레플리카셋으로 속도를 제어하며 이동하는 것을 관리한다. 각각의 새로운 레플리카셋은 디플로이먼트의 수정 버전에 따라 업데이트한다.
- 만약 디플로이먼트의 현재 상태가 안정적이지 않은 경우 디플로이먼트의 이전 버전으로 롤백한다. 각 롤백은 디플로이먼트의 수정 버전에 따라 업데이트한다.
- 더 많은 로드를 위해 디플로이먼트의 스케일 업.
- 디플로이먼트 롤아웃 일시 중지로 PodTemplateSpec에 여러 수정 사항을 적용하고, 재개하여 새로운 롤아웃을 시작한다.
- 롤아웃이 막혀있는지를 나타내는 디플로이먼트 상태를 이용.
- 더 이상 필요 없는 이전 레플리카셋 정리.
디플로이먼트 생성
다음은 디플로이먼트의 예시이다. 예시는 3개의 nginx 파드를 불러오기 위한 레플리카셋을 생성한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
이 예시에 대한 설명은 다음과 같다.
-
.metadata.name필드에 따라,nginx-deployment이름을 가진 디플로이먼트가 생성된다. -
.spec.replicas필드에 따라, 디플로이먼트는 3개의 레플리카 파드를 생성하는 레플리카셋을 생성한다. -
.spec.selector필드는, 생성된 레플리카셋이 관리할 파드를 찾아내는 방법을 정의한다. 이 사례에서는 파드 템플릿에 정의된 레이블(app: nginx)을 선택한다. 그러나 파드 템플릿 자체의 규칙이 만족되는 한, 보다 정교한 선택 규칙의 적용이 가능하다.참고:
.spec.selector.matchLabels필드는 {key,value}의 쌍으로 매핑되어 있다.matchLabels에 매핑된 단일 {key,value}은matchExpressions의 요소에 해당하며,key필드는 "key"에 그리고operator는 "In"에 대응되며value배열은 "value"만 포함한다. 매칭을 위해서는matchLabels와matchExpressions의 모든 요건이 충족되어야 한다. -
template필드에는 다음 하위 필드가 포함되어 있다.- 파드는
.metadata.labels필드를 사용해서app: nginx라는 레이블을 붙인다. - 파드 템플릿의 사양 또는
.template.spec필드는 파드가 도커 허브의nginx1.14.2 버전 이미지를 실행하는nginx컨테이너 1개를 실행하는 것을 나타낸다. - 컨테이너 1개를 생성하고,
.spec.template.spec.containers[0].name필드를 사용해서nginx이름을 붙인다.
- 파드는
시작하기 전에, 쿠버네티스 클러스터가 시작되고 실행 중인지 확인한다. 위의 디플로이먼트를 생성하려면 다음 단계를 따른다.
- 다음 명령어를 실행해서 디플로이먼트를 생성한다.
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
kubectl get deployments을 실행해서 디플로이먼트가 생성되었는지 확인한다.
만약 디플로이먼트가 여전히 생성 중이면, 다음과 유사하게 출력된다.
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 0 0 1s
클러스터에서 디플로이먼트를 점검할 때, 다음 필드가 표시된다.
NAME은 네임스페이스에 있는 디플로이먼트 이름의 목록이다.READY는 사용자가 사용할 수 있는 애플리케이션의 레플리카의 수를 표시한다. ready/desired 패턴을 따른다.UP-TO-DATE는 의도한 상태를 얻기 위해 업데이트된 레플리카의 수를 표시한다.AVAILABLE은 사용자가 사용할 수 있는 애플리케이션 레플리카의 수를 표시한다.AGE는 애플리케이션의 실행된 시간을 표시한다.
.spec.replicas 필드에 따라 의도한 레플리카의 수가 3개인지 알 수 있다.
-
디플로이먼트의 롤아웃 상태를 보려면,
kubectl rollout status deployment/nginx-deployment를 실행한다.다음과 유사하게 출력된다.
Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment "nginx-deployment" successfully rolled out -
몇 초 후
kubectl get deployments를 다시 실행한다. 다음과 유사하게 출력된다.NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 18s디플로이먼트에서 3개의 레플리카가 생성되었고, 모든 레플리카는 최신 상태(최신 파드 템플릿을 포함)이며 사용 가능한 것을 알 수 있다.
-
디플로이먼트로 생성된 레플리카셋(
rs)을 보려면,kubectl get rs를 실행한다. 다음과 유사하게 출력된다.NAME DESIRED CURRENT READY AGE nginx-deployment-75675f5897 3 3 3 18s레플리카셋의 출력에는 다음 필드가 표시된다.
NAME은 네임스페이스에 있는 레플리카셋 이름의 목록이다.DESIRED는 디플로이먼트의 생성 시 정의된 의도한 애플리케이션 레플리카 의 수를 표시한다. 이것이 의도한 상태 이다.CURRENT는 현재 실행 중인 레플리카의 수를 표시한다.READY는 사용자가 사용할 수 있는 애플리케이션의 레플리카의 수를 표시한다.AGE는 애플리케이션의 실행된 시간을 표시한다.
레플리카셋의 이름은 항상
[DEPLOYMENT-NAME]-[HASH]형식으로 된 것을 알 수 있다.HASH문자열은 레플리카셋의pod-template-hash레이블과 같다. -
각 파드에 자동으로 생성된 레이블을 보려면,
kubectl get pods --show-labels를 실행한다. 다음과 유사하게 출력된다.NAME READY STATUS RESTARTS AGE LABELS nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453 nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453 nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453만들어진 레플리카셋은 실행 중인 3개의
nginx파드를 보장한다.
참고:
디플로이먼트에는 파드 템플릿 레이블과 적절한 셀렉터를 반드시 명시해야 한다
(이 예시에서는 app: nginx).
레이블 또는 셀렉터는 다른 컨트롤러(다른 디플로이먼트와 스테이트풀셋(StatefulSet) 포함)와 겹치지 않아야 한다. 쿠버네티스는 겹치는 것을 막지 않으며, 만약 다중 컨트롤러가 겹치는 셀렉터를 가지는 경우 해당 컨트롤러의 충돌 또는 예기치 않은 동작을 야기할 수 있다.
Pod-template-hash 레이블
주의:
이 레이블은 변경하면 안 된다.pod-template-hash 레이블은 디플로이먼트 컨트롤러에 의해서 디플로이먼트가 생성 또는 채택한 모든 레플리카셋에 추가된다.
이 레이블은 디플로이먼트의 자식 레플리카셋이 겹치지 않도록 보장한다. 레플리카셋의 PodTemplate 을 해싱하고, 해시 결과를 레플리카셋 셀렉터,
파드 템플릿 레이블 및 레플리카셋 이 가질 수 있는 기존의 모든 파드에 레이블 값으로 추가해서 사용하도록 생성한다.
디플로이먼트 업데이트
참고:
디플로이먼트의 파드 템플릿(즉,.spec.template)이 변경된 경우에만 디플로이먼트의 롤아웃이 트리거(trigger) 된다.
예를 들면 템플릿의 레이블이나 컨테이너 이미지가 업데이트된 경우이다. 디플로이먼트의 스케일링과 같은 다른 업데이트는 롤아웃을 트리거하지 말아야 한다.다음 단계에 따라 디플로이먼트를 업데이트한다.
-
nginx:1.14.2이미지 대신nginx:1.16.1이미지를 사용하도록 nginx 파드를 업데이트 한다.kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1또는 다음의 명령어를 사용한다.
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1다음과 유사하게 출력된다.
deployment.apps/nginx-deployment image updated대안으로 디플로이먼트를
edit해서.spec.template.spec.containers[0].image를nginx:1.14.2에서nginx:1.16.1로 변경한다.kubectl edit deployment/nginx-deployment다음과 유사하게 출력된다.
deployment.apps/nginx-deployment edited -
롤아웃 상태를 보려면 다음을 실행한다.
kubectl rollout status deployment/nginx-deployment이와 유사하게 출력된다.
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...또는
deployment "nginx-deployment" successfully rolled out
업데이트된 디플로이먼트에 대해 자세한 정보 보기
-
롤아웃이 성공하면
kubectl get deployments를 실행해서 디플로이먼트를 볼 수 있다. 이와 유사하게 출력된다.NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 36s -
kubectl get rs를 실행해서 디플로이먼트가 새 레플리카셋을 생성해서 파드를 업데이트 했는지 볼 수 있고, 새 레플리카셋을 최대 3개의 레플리카로 스케일 업, 이전 레플리카셋을 0개의 레플리카로 스케일 다운한다.kubectl get rs이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 6s nginx-deployment-2035384211 0 0 0 36s -
get pods를 실행하면 새 파드만 표시된다.kubectl get pods이와 유사하게 출력된다.
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-khku8 1/1 Running 0 14s nginx-deployment-1564180365-nacti 1/1 Running 0 14s nginx-deployment-1564180365-z9gth 1/1 Running 0 14s다음에 이러한 파드를 업데이트 하려면 디플로이먼트의 파드 템플릿만 다시 업데이트 하면 된다.
디플로이먼트는 업데이트되는 동안 일정한 수의 파드만 중단되도록 보장한다. 기본적으로 적어도 의도한 파드 수의 75% 이상이 동작하도록 보장한다(최대 25% 불가).
또한 디플로이먼트는 의도한 파드 수 보다 더 많이 생성되는 파드의 수를 제한한다. 기본적으로, 의도한 파드의 수 기준 최대 125%까지만 추가 파드가 동작할 수 있도록 제한한다(최대 25% 까지).
예를 들어, 위 디플로이먼트를 자세히 살펴보면 먼저 새로운 파드를 생성한 다음, 이전 파드를 삭제하고, 또 다른 새로운 파드를 만든 것을 볼 수 있다. 충분한 수의 새로운 파드가 나올 때까지 이전 파드를 죽이지 않으며, 충분한 수의 이전 파드들이 죽기 전까지 새로운 파드를 만들지 않는다. 이것은 최소 3개의 파드를 사용할 수 있게 하고, 최대 4개의 파드를 사용할 수 있게 한다. 디플로이먼트의 레플리카 크기가 4인 경우, 파드 숫자는 3개에서 5개 사이이다.
-
디플로이먼트의 세부 정보 가져오기
kubectl describe deployments이와 유사하게 출력된다.
Name: nginx-deployment Namespace: default CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=2 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3 Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1 Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2 Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2 Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1 Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3 Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0처음 디플로이먼트를 생성했을 때, 디플로이먼트가 레플리카셋(nginx-deployment-2035384211)을 생성하고 3개의 레플리카로 직접 스케일 업한 것을 볼 수 있다. 디플로이먼트를 업데이트하자, 새 레플리카셋(nginx-deployment-1564180365)을 생성하고, 1개로 스케일 업한 다음 모두 실행될 때까지 대기하였다. 그 뒤 이전 레플리카셋을 2개로 스케일 다운하고 새 레플리카셋을 2개로 스케일 업하여 모든 시점에 대해 최소 3개 / 최대 3개의 파드가 존재하도록 하였다. 이후 지속해서 같은 롤링 업데이트 정책으로 새 레플리카셋은 스케일 업하고 이전 레플리카셋은 스케일 다운한다. 마지막으로 새로운 레플리카셋에 3개의 사용 가능한 레플리카가 구성되며, 이전 레플리카셋은 0개로 스케일 다운된다.
참고:
쿠버네티스가availableReplicas 수를 계산할 때 종료 중인(terminating) 파드는 포함하지 않으며,
이 수는 replicas - maxUnavailable 와 replicas + maxSurge 사이에 존재한다.
그 결과, 롤아웃 중에는 파드의 수가 예상보다 많을 수 있으며,
종료 중인 파드의 terminationGracePeriodSeconds가 만료될 때까지는 디플로이먼트가 소비하는 총 리소스가 replicas + maxSurge 이상일 수 있다.롤오버(일명 인-플라이트 다중 업데이트)
디플로이먼트 컨트롤러는 각 시간마다 새로운 디플로이먼트에서 레플리카셋이
의도한 파드를 생성하고 띄우는 것을 주시한다. 만약 디플로이먼트가 업데이트되면, 기존 레플리카셋에서
.spec.selector 레이블과 일치하는 파드를 컨트롤 하지만, 템플릿과 .spec.template 이 불일치하면 스케일 다운이 된다.
결국 새로운 레플리카셋은 .spec.replicas 로 스케일되고, 모든 기존 레플리카셋은 0개로 스케일된다.
만약 기존 롤아웃이 진행되는 중에 디플로이먼트를 업데이트하는 경우 디플로이먼트가 업데이트에 따라 새 레플리카셋을 생성하고, 스케일 업하기 시작한다. 그리고 이전에 스케일 업 하던 레플리카셋에 롤오버 한다. --이것은 기존 레플리카셋 목록에 추가하고 스케일 다운을 할 것이다.
예를 들어 디플로이먼트로 nginx:1.14.2 레플리카를 5개 생성을 한다.
하지만 nginx:1.14.2 레플리카 3개가 생성되었을 때 디플로이먼트를 업데이트해서 nginx:1.16.1
레플리카 5개를 생성성하도록 업데이트를 한다고 가정한다. 이 경우 디플로이먼트는 즉시 생성된 3개의
nginx:1.14.2 파드 3개를 죽이기 시작하고 nginx:1.16.1 파드를 생성하기 시작한다.
이것은 과정이 변경되기 전 nginx:1.14.2 레플리카 5개가
생성되는 것을 기다리지 않는다.
레이블 셀렉터 업데이트
일반적으로 레이블 셀렉터를 업데이트 하는 것을 권장하지 않으며 셀렉터를 미리 계획하는 것을 권장한다. 어떤 경우든 레이블 셀렉터의 업데이트를 해야하는 경우 매우 주의하고, 모든 영향을 파악했는지 확인해야 한다.
참고:
API 버전apps/v1 에서 디플로이먼트의 레이블 셀렉터는 생성 이후에는 변경할 수 없다.- 셀렉터 추가 시 디플로이먼트의 사양에 있는 파드 템플릿 레이블도 새 레이블로 업데이트해야 한다. 그렇지 않으면 유효성 검사 오류가 반환된다. 이 변경은 겹치지 않는 변경으로 새 셀렉터가 이전 셀렉터로 만든 레플리카셋과 파드를 선택하지 않게 되고, 그 결과로 모든 기존 레플리카셋은 고아가 되며, 새로운 레플리카셋을 생성하게 된다.
- 셀렉터 업데이트는 기존 셀렉터 키 값을 변경하며, 결과적으로 추가와 동일한 동작을 한다.
- 셀렉터 삭제는 디플로이먼트 셀렉터의 기존 키를 삭제하며 파드 템플릿 레이블의 변경을 필요로 하지 않는다. 기존 레플리카셋은 고아가 아니고, 새 레플리카셋은 생성되지 않는다. 그러나 제거된 레이블은 기존 파드와 레플리카셋에 여전히 존재한다는 점을 참고해야 한다.
디플로이먼트 롤백
때때로 디플로이먼트의 롤백을 원할 수도 있다. 예를 들어 디플로이먼트가 지속적인 충돌로 안정적이지 않은 경우. 기본적으로 모든 디플로이먼트의 롤아웃 기록은 시스템에 남아있어 언제든지 원할 때 롤백이 가능하다 (이 사항은 수정 기록에 대한 상한 수정을 통해서 변경할 수 있다).
참고:
디플로이먼트의 수정 버전은 디플로이먼트 롤아웃시 생성된다. 이는 디플로이먼트 파드 템플릿 (.spec.template)이 변경되는 경우에만 새로운 수정 버전이 생성된다는 것을 의미한다.
예를 들어 템플릿의 레이블 또는 컨테이너 이미지를 업데이트 하는 경우.
디플로이먼트의 스케일링과 같은 다른 업데이트시 디플로이먼트 수정 버전은 생성되지 않으며 수동-스케일링 또는 자동-스케일링을 동시에 수행할 수 있다.
이는 이전 수정 버전으로 롤백을 하는 경우에 디플로이먼트 파드 템플릿 부분만
롤백된다는 것을 의미한다.-
디플로이먼트를 업데이트하는 동안 이미지 이름을
nginx:1.16.1이 아닌nginx:1.161로 입력해서 오타를 냈다고 가정한다.kubectl set image deployment/nginx-deployment nginx=nginx:1.161이와 유사하게 출력된다.
deployment.apps/nginx-deployment image updated -
롤아웃이 고착 된다. 고착된 롤아웃 상태를 확인할 수 있다.
kubectl rollout status deployment/nginx-deployment이와 유사하게 출력된다.
Waiting for rollout to finish: 1 out of 3 new replicas have been updated... -
Ctrl-C 를 눌러 위의 롤아웃 상태 보기를 중지한다. 고착된 롤아웃 상태에 대한 자세한 정보는 이 것을 더 읽어본다.
-
이전 레플리카는 2개(
nginx-deployment-1564180365과nginx-deployment-2035384211), 새 레플리카는 1개(nginx-deployment-3066724191)임을 알 수 있다.kubectl get rs이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 25s nginx-deployment-2035384211 0 0 0 36s nginx-deployment-3066724191 1 1 0 6s -
생성된 파드를 보면, 새로운 레플리카셋에 생성된 1개의 파드가 이미지 풀 루프(pull loop)에서 고착된 것을 볼 수 있다.
kubectl get pods이와 유사하게 출력된다.
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-70iae 1/1 Running 0 25s nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s nginx-deployment-1564180365-hysrc 1/1 Running 0 25s nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s참고:
디플로이먼트 컨트롤러가 잘못된 롤아웃을 자동으로 중지하고, 새로운 레플리카셋의 스케일 업을 중지한다. 이는 지정한 롤링 업데이트의 파라미터(구체적으로 `maxUnavailable`)에 따라 달라진다. 쿠버네티스는 기본값으로 25%를 설정한다. -
디플로이먼트에 대한 설명 보기
kubectl describe deployment이와 유사하게 출력된다.
Name: nginx-deployment Namespace: default CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700 Labels: app=nginx Selector: app=nginx Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.161 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True ReplicaSetUpdated OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created) NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created) Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1이 문제를 해결하려면 디플로이먼트를 안정적인 이전 수정 버전으로 롤백해야 한다.
디플로이먼트의 롤아웃 기록 확인
다음 순서에 따라 롤아웃 기록을 확인한다.
-
먼저 이 디플로이먼트의 수정 사항을 확인한다.
kubectl rollout history deployment/nginx-deployment이와 유사하게 출력된다.
deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161CHANGE-CAUSE는 수정 생성시 디플로이먼트 주석인kubernetes.io/change-cause에서 복사한다. 다음에 대해CHANGE-CAUSE메시지를 지정할 수 있다.- 디플로이먼트에
kubectl annotate deployment/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"로 주석을 단다. - 수동으로 리소스 매니페스트 편집.
- 디플로이먼트에
-
각 수정 버전의 세부 정보를 보려면 다음을 실행한다.
kubectl rollout history deployment/nginx-deployment --revision=2이와 유사하게 출력된다.
deployments "nginx-deployment" revision 2 Labels: app=nginx pod-template-hash=1159050644 Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP QoS Tier: cpu: BestEffort memory: BestEffort Environment Variables: <none> No volumes.
이전 수정 버전으로 롤백
다음 단계에 따라 디플로이먼트를 현재 버전에서 이전 버전인 버전 2로 롤백한다.
-
이제 현재 롤아웃의 실행 취소 및 이전 수정 버전으로 롤백 하기로 결정했다.
kubectl rollout undo deployment/nginx-deployment이와 유사하게 출력된다.
deployment.apps/nginx-deployment rolled back또는 특정 수정 버전으로 롤백하려면
--to-revision옵션에 해당 수정 버전을 명시한다.kubectl rollout undo deployment/nginx-deployment --to-revision=2이와 유사하게 출력된다.
deployment.apps/nginx-deployment rolled back롤아웃 관련 명령에 대한 자세한 내용은
kubectl rollout을 참조한다.이제 디플로이먼트가 이전 안정 수정 버전으로 롤백 된다. 버전 2로 롤백하기 위해
DeploymentRollback이벤트가 디플로이먼트 컨트롤러에서 생성되는 것을 볼 수 있다. -
만약 롤백에 성공하고, 디플로이먼트가 예상대로 실행되는지 확인하려면 다음을 실행한다.
kubectl get deployment nginx-deployment이와 유사하게 출력된다.
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 30m -
디플로이먼트의 설명 가져오기.
kubectl describe deployment nginx-deployment이와 유사하게 출력된다.
Name: nginx-deployment Namespace: default CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=4 kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1 Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2 Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
디플로이먼트 스케일링
다음 명령어를 사용해서 디플로이먼트의 스케일을 할 수 있다.
kubectl scale deployment/nginx-deployment --replicas=10
이와 유사하게 출력된다.
deployment.apps/nginx-deployment scaled
가령 클러스터에서 horizontal Pod autoscaling를 설정 한 경우 디플로이먼트에 대한 오토스케일러를 설정할 수 있다. 그리고 기존 파드의 CPU 사용률을 기준으로 실행할 최소 파드 및 최대 파드의 수를 선택할 수 있다.
kubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80
이와 유사하게 출력된다.
deployment.apps/nginx-deployment scaled
비례적 스케일링(Proportional Scaling)
디플로이먼트 롤링업데이트는 여러 버전의 애플리케이션을 동시에 실행할 수 있도록 지원한다. 사용자 또는 오토스케일러가 롤아웃 중에 있는 디플로이먼트 롤링 업데이트를 스케일링 하는 경우(진행중 또는 일시 중지 중), 디플로이먼트 컨트롤러는 위험을 줄이기 위해 기존 활성화된 레플리카셋(파드와 레플리카셋)의 추가 레플리카의 균형을 조절 한다. 이것을 proportional scaling 라 부른다.
예를 들어, 10개의 레플리카를 디플로이먼트로 maxSurge=3, 그리고 maxUnavailable=2 로 실행 한다.
-
디플로이먼트에 있는 10개의 레플리카가 실행되는지 확인한다.
kubectl get deploy이와 유사하게 출력된다.
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 10 10 10 10 50s -
클러스터 내부에서 확인할 수 없는 새 이미지로 업데이트 된다.
kubectl set image deployment/nginx-deployment nginx=nginx:sometag이와 유사하게 출력된다.
deployment.apps/nginx-deployment image updated -
이미지 업데이트는 레플리카셋 nginx-deployment-1989198191 으로 새로운 롤 아웃이 시작하지만, 위에서 언급한
maxUnavailable의 요구 사항으로 인해 차단된다. 롤아웃 상태를 확인한다.kubectl get rs이와 유사하게 출력된다.NAME DESIRED CURRENT READY AGE nginx-deployment-1989198191 5 5 0 9s nginx-deployment-618515232 8 8 8 1m -
그 다음 디플로이먼트에 대한 새로운 스케일링 요청이 함께 따라온다. 오토스케일러는 디플로이먼트 레플리카를 15로 증가시킨다. 디플로이먼트 컨트롤러는 새로운 5개의 레플리카의 추가를 위한 위치를 결정해야 한다. 만약 비례적 스케일링을 사용하지 않으면 5개 모두 새 레플리카셋에 추가된다. 비례적 스케일링으로 추가 레플리카를 모든 레플리카셋에 걸쳐 분산할 수 있다. 비율이 높을수록 가장 많은 레플리카가 있는 레플리카셋으로 이동하고, 비율이 낮을 수록 적은 레플리카가 있는 레플리카셋으로 이동한다. 남은 것들은 대부분의 레플리카가 있는 레플리카셋에 추가된다. 0개의 레플리카가 있는 레플리카셋은 스케일 업 되지 않는다.
위의 예시에서 기존 레플리카셋에 3개의 레플리카가 추가되고, 2개의 레플리카는 새 레플리카에 추가된다. 결국 롤아웃 프로세스는 새 레플리카가 정상이라고 가정하면 모든 레플리카를 새 레플리카셋으로 이동시킨다. 이를 확인하려면 다음을 실행한다.
kubectl get deploy
이와 유사하게 출력된다.
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
롤아웃 상태는 레플리카가 각 레플리카셋에 어떻게 추가되었는지 확인한다.
kubectl get rs
이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
디플로이먼트 롤아웃 일시 중지와 재개
디플로이먼트를 업데이트할 때 (또는 계획할 때), 하나 이상의 업데이트를 트리거하기 전에 해당 디플로이먼트에 대한 롤아웃을 일시 중지할 수 있다. 변경 사항을 적용할 준비가 되면, 디플로이먼트 롤아웃을 재개한다. 이러한 방법으로, 불필요한 롤아웃을 트리거하지 않고 롤아웃 일시 중지와 재개 사이에 여러 수정 사항을 적용할 수 있다.
-
예를 들어, 생성된 디플로이먼트의 경우
디플로이먼트 상세 정보를 가져온다.
kubectl get deploy이와 유사하게 출력된다.
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx 3 3 3 3 1m롤아웃 상태를 가져온다.
kubectl get rs이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 1m -
다음 명령을 사용해서 일시 중지한다.
kubectl rollout pause deployment/nginx-deployment이와 유사하게 출력된다.
deployment.apps/nginx-deployment paused -
그런 다음 디플로이먼트의 이미지를 업데이트 한다.
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1이와 유사하게 출력된다.
deployment.apps/nginx-deployment image updated -
새로운 롤아웃이 시작되지 않는다.
kubectl rollout history deployment/nginx-deployment이와 유사하게 출력된다.
deployments "nginx" REVISION CHANGE-CAUSE 1 <none> -
기존 레플리카셋이 변경되지 않았는지 확인하기 위해 롤아웃 상태를 출력한다.
kubectl get rs이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 2m -
예를 들어 사용할 리소스를 업데이트하는 것처럼 원하는 만큼 업데이트할 수 있다.
kubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi이와 유사하게 출력된다.
deployment.apps/nginx-deployment resource requirements updated디플로이먼트 롤아웃을 일시 중지하기 전 디플로이먼트의 초기 상태는 해당 기능을 지속한다. 그러나 디플로이먼트 롤아웃이 일시 중지한 상태에서는 디플로이먼트의 새 업데이트에 영향을 주지 않는다.
-
결국, 디플로이먼트 롤아웃을 재개하고 새로운 레플리카셋이 새로운 업데이트를 제공하는 것을 관찰한다.
kubectl rollout resume deployment/nginx-deployment이와 유사하게 출력된다.
deployment.apps/nginx-deployment resumed -
롤아웃이 완료될 때까지 상태를 관찰한다.
kubectl get rs -w이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-2142116321 2 2 2 2m nginx-3926361531 2 2 0 6s nginx-3926361531 2 2 1 18s nginx-2142116321 1 2 2 2m nginx-2142116321 1 2 2 2m nginx-3926361531 3 2 1 18s nginx-3926361531 3 2 1 18s nginx-2142116321 1 1 1 2m nginx-3926361531 3 3 1 18s nginx-3926361531 3 3 2 19s nginx-2142116321 0 1 1 2m nginx-2142116321 0 1 1 2m nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 20s -
롤아웃 최신 상태를 가져온다.
kubectl get rs이와 유사하게 출력된다.
NAME DESIRED CURRENT READY AGE nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 28s
참고:
일시 중지된 디플로이먼트를 재개할 때까지 롤백할 수 없다.디플로이먼트 상태
디플로이먼트는 라이프사이클 동안 다양한 상태로 전환된다. 이는 새 레플리카셋을 롤아웃하는 동안 진행 중이 될 수 있고, 완료이거나 진행 실패일 수 있다.
디플로이먼트 진행 중
쿠버네티스는 다음 작업중 하나를 수행할 때 디플로이먼트를 진행 중 으로 표시한다.
- 디플로이먼트로 새 레플리카셋을 생성.
- 디플로이먼트로 새로운 레플리카셋을 스케일 업.
- 디플로이먼트로 기존 레플리카셋을 스케일 다운.
- 새 파드가 준비되거나 이용할 수 있음(최소 준비 시간(초) 동안 준비됨).
롤아웃이 "진행 중" 상태가 되면,
디플로이먼트 컨트롤러는 디플로이먼트의 .status.conditions에 다음 속성을 포함하는 컨디션을 추가한다.
type: Progressingstatus: "True"reason: NewReplicaSetCreated|reason: FoundNewReplicaSet|reason: ReplicaSetUpdated
kubectl rollout status 를 사용해서 디플로이먼트의 진행사황을 모니터할 수 있다.
디플로이먼트 완료
쿠버네티스는 다음과 같은 특성을 가지게 되면 디플로이먼트를 완료 로 표시한다.
- 디플로이먼트과 관련된 모든 레플리카가 지정된 최신 버전으로 업데이트 되었을 때. 즉, 요청한 모든 업데이트가 완료되었을 때.
- 디플로이먼트와 관련한 모든 레플리카를 사용할 수 있을 때.
- 디플로이먼트에 대해 이전 복제본이 실행되고 있지 않을 때.
롤아웃이 "완료" 상태가 되면,
디플로이먼트 컨트롤러는 디플로이먼트의 .status.conditions에 다음 속성을 포함하는 컨디션을 추가한다.
type: Progressingstatus: "True"reason: NewReplicaSetAvailable
이 Progressing 컨디션은 새로운 롤아웃이 시작되기 전까지는 "True" 상태값을 유지할 것이다.
레플리카의 가용성이 변경되는 경우에도(이 경우 Available 컨디션에 영향을 미침)
컨디션은 유지된다.
kubectl rollout status 를 사용해서 디플로이먼트가 완료되었는지 확인할 수 있다.
만약 롤아웃이 성공적으로 완료되면 kubectl rollout status 는 종료 코드로 0이 반환된다.
kubectl rollout status deployment/nginx-deployment
이와 유사하게 출력된다.
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
그리고 kubectl rollout 의 종료 상태는 0(success)이다.
echo $?
0
디플로이먼트 실패
디플로이먼트시 새 레플리카셋인 완료되지 않은 상태에서는 배포를 시도하면 고착될 수 있다. 이 문제는 다음 몇 가지 요인으로 인해 발생한다.
- 할당량 부족
- 준비성 프로브(readiness probe)의 실패
- 이미지 풀 에러
- 권한 부족
- 범위 제한
- 애플리케이션 런타임의 잘못된 구성
이 조건을 찾을 수 있는 한 가지 방법은 디플로이먼트 스펙에서 데드라인 파라미터를 지정하는 것이다
(.spec.progressDeadlineSeconds). .spec.progressDeadlineSeconds 는
(디플로이먼트 상태에서) 디플로이먼트의 진행이 정지되었음을 나타내는 디플로이먼트 컨트롤러가
대기하는 시간(초)를 나타낸다.
다음 kubectl 명령어로 progressDeadlineSeconds 를 설정해서 컨트롤러가
10분 후 디플로이먼트 롤아웃에 대한 진행 상태의 부족에 대한 리포트를 수행하게 한다.
kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
이와 유사하게 출력된다.
deployment.apps/nginx-deployment patched
만약 데드라인을 넘어서면 디플로이먼트 컨트롤러는 디플로이먼트의 .status.conditions 속성에 다음의
디플로이먼트 컨디션(DeploymentCondition)을 추가한다.
type: Progressingstatus: "False"reason: ProgressDeadlineExceeded
이 컨디션은 일찍 실패할 수도 있으며 이러한 경우 ReplicaSetCreateError를 이유로 상태값을 "False"로 설정한다.
또한, 디플로이먼트 롤아웃이 완료되면 데드라인은 더 이상 고려되지 않는다.
컨디션 상태에 대한 자세한 내용은 쿠버네티스 API 규칙을 참고한다.
참고:
쿠버네티스는reason: ProgressDeadlineExceeded 과 같은 상태 조건을
보고하는 것 이외에 정지된 디플로이먼트에 대해 조치를 취하지 않는다. 더 높은 수준의 오케스트레이터는 이를 활용할 수 있으며,
예를 들어 디플로이먼트를 이전 버전으로 롤백할 수 있다.참고:
만약 디플로이먼트 롤아웃을 일시 중지하면 쿠버네티스는 지정된 데드라인과 비교하여 진행 상황을 확인하지 않는다. 롤아웃 중에 디플로이먼트 롤아웃을 안전하게 일시 중지하고, 데드라인을 넘기도록 하는 조건을 트리거하지 않고 재개할 수 있다.설정한 타임아웃이 낮거나 일시적으로 처리될 수 있는 다른 종료의 에러로 인해 디플로이먼트에 일시적인 에러가 발생할 수 있다. 예를 들어, 할당량이 부족하다고 가정해보자. 만약 디플로이먼트를 설명하려면 다음 섹션을 확인한다.
kubectl describe deployment nginx-deployment
이와 유사하게 출력된다.
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
만약 kubectl get deployment nginx-deployment -o yaml 을 실행하면 디플로이먼트 상태는 다음과 유사하다.
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
결국, 디플로이먼트 진행 데드라인을 넘어서면, 쿠버네티스는 진행 컨디션의 상태와 이유를 업데이트한다.
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
디플로이먼트를 스케일 다운하거나, 실행 중인 다른 컨트롤러를 스케일 다운하거나,
네임스페이스에서 할당량을 늘려서 할당량이 부족한 문제를 해결할 수 있다.
만약 할당량 컨디션과 디플로이먼트 롤아웃이 완료되어 디플로이먼트 컨트롤러를 만족한다면
성공한 컨디션의 디플로이먼트 상태가 업데이트를 볼 수 있다(status: "True" 와 reason: NewReplicaSetAvailable).
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
type: Available 과 status: "True" 는 디플로이먼트가 최소한의 가용성을 가지고 있는 것을 의미한다.
최소한의 가용성은 디플로이먼트 계획에 명시된 파라미터에 의해 결정된다. type: Progressing 과 status: "True" 는 디플로이먼트가
롤아웃 도중에 진행 중 이거나, 성공적으로 완료되었으며, 진행 중 최소한으로 필요한 새로운 레플리카를 이용 가능하다는 것이다.
(자세한 내용은 특정 조건의 이유를 참조한다.
이 경우 reason: NewReplicaSetAvailable 는 배포가 완료되었음을 의미한다.)
kubectl rollout status 를 사용해서 디플로이먼트의 진행이 실패되었는지 확인할 수 있다.
kubectl rollout status 는 디플로이먼트의 진행 데드라인을 초과하면 0이 아닌 종료 코드를 반환한다.
kubectl rollout status deployment/nginx-deployment
이와 유사하게 출력된다.
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
그리고 kubectl rollout 의 종료 상태는 1(error를 의미함)이다.
echo $?
1
실패한 디플로이먼트에서의 운영
완료된 디플로이먼트에 적용되는 모든 행동은 실패한 디플로이먼트에도 적용된다. 디플로이먼트 파드 템플릿에서 여러 개의 수정사항을 적용해야하는 경우 스케일 업/다운 하거나, 이전 수정 버전으로 롤백하거나, 일시 중지할 수 있다.
정책 초기화
디플로이먼트의 .spec.revisionHistoryLimit 필드를 설정해서
디플로이먼트에서 유지해야 하는 이전 레플리카셋의 수를 명시할 수 있다. 나머지는 백그라운드에서 가비지-수집이 진행된다.
기본적으로 10으로 되어 있다.
참고:
명시적으로 이 필드를 0으로 설정하면 그 결과로 디플로이먼트의 기록을 전부 초기화를 하고, 디플로이먼트는 롤백할 수 없게 된다.카나리 디플로이먼트
만약 디플로이먼트를 이용해서 일부 사용자 또는 서버에 릴리스를 롤아웃 하기 위해서는 리소스 관리에 설명된 카나리 패던에 따라 각 릴리스 마다 하나씩 여러 디플로이먼트를 생성할 수 있다.
디플로이먼트 사양 작성
다른 모든 쿠버네티스 설정과 마찬가지로 디플로이먼트에는 .apiVersion, .kind 그리고 .metadata 필드가 필요하다.
설정 파일 작업에 대한 일반적인 내용은
애플리케이션 배포하기,
컨테이너 구성하기 그리고 kubectl을 사용해서 리소스 관리하기 문서를 참조한다.
디플로이먼트 오브젝트의 이름은 유효한
DNS 서브도메인 이름이어야 한다.
디플로이먼트에는 .spec 섹션도 필요하다.
파드 템플릿
.spec.template 과 .spec.selector 은 .spec 에서 유일한 필수 필드이다.
.spec.template 는 파드 템플릿이다. 이것은 파드와 정확하게 동일한 스키마를 가지고 있고, 중첩된 것을 제외하면 apiVersion 과 kind 를 가지고 있지 않는다.
파드에 필요한 필드 외에 디플로이먼트 파드 템플릿은 적절한 레이블과 적절한 재시작 정책을 명시해야 한다. 레이블의 경우 다른 컨트롤러와 겹치지 않도록 해야 한다. 자세한 것은 셀렉터를 참조한다.
.spec.template.spec.restartPolicy 에는 오직 Always 만 허용되고,
명시되지 않으면 기본값이 된다.
레플리카
.spec.replicas 은 필요한 파드의 수를 지정하는 선택적 필드이다. 이것의 기본값은 1이다.
예를 들어 kubectl scale deployment deployment --replicas=X 명령으로
디플로이먼트의 크기를 수동으로 조정한 뒤,
매니페스트를 이용하여 디플로이먼트를 업데이트하면(예: kubectl apply -f deployment.yaml 실행),
수동으로 설정했던 디플로이먼트의 크기가 오버라이드된다.
HorizontalPodAutoscaler(또는 수평 스케일링을 위한 유사 API)가
디플로이먼트 크기를 관리하고 있다면, .spec.replicas 를 설정해서는 안 된다.
대신, 쿠버네티스
컨트롤 플레인이
.spec.replicas 필드를 자동으로 관리한다.
셀렉터
.spec.selector 는 디플로이먼트의 대상이 되는 파드에 대해 레이블 셀렉터를
지정하는 필수 필드이다.
.spec.selector 는 .spec.template.metadata.labels 과 일치해야 하며, 그렇지 않으면 API에 의해 거부된다.
API 버전 apps/v1 에서는 .spec.selector 와 .metadata.labels 이 설정되지 않으면 .spec.template.metadata.labels 은 기본 설정되지 않는다. 그래서 이것들은 명시적으로 설정되어야 한다. 또한 apps/v1 에서는 디플로이먼트를 생성한 후에는 .spec.selector 이 변경되지 않는 점을 참고한다.
디플로이먼트는 템플릿의 .spec.template 와 다르거나 파드의 수가 .spec.replicas 를 초과할 경우
셀렉터와 일치하는 레이블을 가진 파드를 종료할 수 있다.
파드의 수가 의도한 수량보다 적을 경우 .spec.template 에 맞는 새 파드를 띄운다.
참고:
다른 디플로이먼트를 생성하거나, 레플리카셋 또는 레플리케이션컨트롤러와 같은 다른 컨트롤러를 사용해서 직접적으로 레이블과 셀렉터가 일치하는 다른 파드를 생성하지 말아야 한다. 만약 이렇게 하면 첫 번째 디플로이먼트는 다른 파드를 만들었다고 생각한다. 쿠버네티스는 이 일을 막지 않는다.만약 셀렉터가 겹치는 컨트롤러가 어러 개 있는 경우, 컨트롤러는 서로 싸우고 올바르게 작동하지 않는다.
전략
.spec.strategy 는 이전 파드를 새로운 파드로 대체하는 전략을 명시한다.
.spec.strategy.type 은 "재생성" 또는 "롤링업데이트"가 될 수 있다.
"롤링업데이트"가 기본값이다.
디플로이먼트 재생성
기존의 모든 파드는 .spec.strategy.type==Recreate 이면 새 파드가 생성되기 전에 죽는다.
참고:
이렇게 하면 업그레이드를 생성하기 전에 파드 종료를 보장할 수 있다. 디플로이먼트를 업그레이드하면, 이전 버전의 모든 파드가 즉시 종료된다. 신규 버전의 파드가 생성되기 전에 성공적으로 제거가 완료되기를 대기한다. 파드를 수동으로 삭제하면, 라이프사이클은 레플리카셋에 의해 제어되며(이전 파드가 여전히 종료 상태에 있는 경우에도) 교체용 파드가 즉시 생성된다. 파드에 대해 "최대" 보장이 필요한 경우 스테이트풀셋의 사용을 고려해야 한다.디플로이먼트 롤링 업데이트
디플로이먼트는 .spec.strategy.type==RollingUpdate 이면 파드를 롤링 업데이트
방식으로 업데이트 한다. maxUnavailable 와 maxSurge 를 명시해서
롤링 업데이트 프로세스를 제어할 수 있다.
최대 불가(Max Unavailable)
.spec.strategy.rollingUpdate.maxUnavailable 은 업데이트 프로세스 중에 사용할 수 없는 최대 파드의 수를 지정하는 선택적 필드이다.
이 값은 절대 숫자(예: 5) 또는 의도한 파드 비율(예: 10%)이 될 수 있다.
절대 값은 내림해서 백분율로 계산한다.
만약 .spec.strategy.rollingUpdate.maxSurge 가 0이면 값이 0이 될 수 없다. 기본 값은 25% 이다.
예를 들어 이 값을 30%로 설정하면 롤링업데이트 시작시 즉각 이전 레플리카셋의 크기를 의도한 파드 중 70%를 스케일 다운할 수 있다. 새 파드가 준비되면 기존 레플리카셋을 스케일 다운할 수 있으며, 업데이트 중에 항상 사용 가능한 전체 파드의 수는 의도한 파드의 수의 70% 이상이 되도록 새 레플리카셋을 스케일 업할 수 있다.
최대 서지(Max Surge)
.spec.strategy.rollingUpdate.maxSurge 는 의도한 파드의 수에 대해 생성할 수 있는 최대 파드의 수를 지정하는 선택적 필드이다.
이 값은 절대 숫자(예: 5) 또는 의도한 파드 비율(예: 10%)이 될 수 있다.
MaxUnavailable 값이 0이면 이 값은 0이 될 수 없다.
절대 값은 올림해서 백분율로 계산한다. 기본 값은 25% 이다.
예를 들어 이 값을 30%로 설정하면 롤링업데이트 시작시 새 레플리카셋의 크기를 즉시 조정해서 기존 및 새 파드의 전체 갯수를 의도한 파드의 130%를 넘지 않도록 한다. 기존 파드가 죽으면 새로운 래플리카셋은 스케일 업할 수 있으며, 업데이트하는 동안 항상 실행하는 총 파드의 수는 최대 의도한 파드의 수의 130%가 되도록 보장한다.
진행 기한 시간(초)
.spec.progressDeadlineSeconds 는 디플로어먼트가 표면적으로 type: Progressing, status: "False"의
상태 그리고 리소스가 reason: ProgressDeadlineExceeded 상태로 진행 실패를 보고하기 전에
디플로이먼트가 진행되는 것을 대기시키는 시간(초)를 명시하는 선택적 필드이다.
디플로이먼트 컨트롤러는 디플로이먼트를 계속 재시도 한다. 기본값은 600(초)이다.
미래에 자동화된 롤백이 구현된다면 디플로이먼트 컨트롤러는 상태를 관찰하고,
그 즉시 디플로이먼트를 롤백할 것이다.
만약 명시된다면 이 필드는 .spec.minReadySeconds 보다 커야 한다.
최소 대기 시간(초)
.spec.minReadySeconds 는 새롭게 생성된 파드의 컨테이너가 어떤 것과도 충돌하지 않고 사
용할 수 있도록 준비되어야 하는 최소 시간(초)을 지정하는 선택적 필드이다.
이 기본 값은 0이다(파드는 준비되는 즉시 사용할 수 있는 것으로 간주됨).
파드가 준비되었다고 간주되는 시기에 대한 자세한 내용은 컨테이너 프로브를 참조한다.
수정 버전 기록 제한
디플로이먼트의 수정 버전 기록은 자신이 컨트롤하는 레플리카셋에 저장된다.
.spec.revisionHistoryLimit 은 롤백을 허용하기 위해 보존할 이전 레플리카셋의 수를 지정하는 선택적 필드이다.
이 이전 레플리카셋은 etcd 의 리소스를 소비하고, kubectl get rs 의 결과를 가득차게 만든다. 각 디플로이먼트의 구성은 디플로이먼트의 레플리카셋에 저장된다. 이전 레플리카셋이 삭제되면 해당 디플로이먼트 수정 버전으로 롤백할 수 있는 기능이 사라진다. 기본적으로 10개의 기존 레플리카셋이 유지되지만 이상적인 값은 새로운 디플로이먼트의 빈도와 안정성에 따라 달라진다.
더욱 구체적으로 이 필드를 0으로 설정하면 레플리카가 0이 되며 이전 레플리카셋이 정리된다. 이 경우, 새로운 디플로이먼트 롤아웃을 취소할 수 없다. 새로운 디플로이먼트 롤아웃은 수정 버전 이력이 정리되기 때문이다.
일시 정지
.spec.paused 는 디플로이먼트를 일시 중지나 재개하기 위한 선택적 부울 필드이다.
일시 중지 된 디플로이먼트와 일시 중지 되지 않은 디플로이먼트 사이의 유일한 차이점은
일시 중지된 디플로이먼트는 PodTemplateSpec에 대한 변경 사항이 일시중지 된 경우 새 롤아웃을 트리거 하지 않는다.
디플로이먼트는 생성시 기본적으로 일시 중지되지 않는다.
다음 내용
- 파드에 대해 배운다.
- 디플로이먼트를 사용해서 상태를 유지하지 않는 애플리케이션을 구동한다.
Deployment는 쿠버네티스 REST API에서 상위-수준 리소스이다. 디플로이먼트 API를 이해하기 위해서 Deployment 오브젝트 정의를 읽는다.- PodDisruptionBudget과 이를 사용해서 어떻게 중단 중에 애플리케이션 가용성을 관리할 수 있는지에 대해 읽는다.
5.2.2 - 레플리카셋
레플리카셋의 목적은 레플리카 파드 집합의 실행을 항상 안정적으로 유지하는 것이다. 이처럼 레플리카셋은 보통 명시된 동일 파드 개수에 대한 가용성을 보증하는데 사용한다.
레플리카셋의 작동 방식
레플리카셋을 정의하는 필드는 획득 가능한 파드를 식별하는 방법이 명시된 셀렉터, 유지해야 하는 파드 개수를 명시하는 레플리카의 개수, 그리고 레플리카 수 유지를 위해 생성하는 신규 파드에 대한 데이터를 명시하는 파드 템플릿을 포함한다. 그러면 레플리카셋은 필드에 지정된 설정을 충족하기 위해 필요한 만큼 파드를 만들고 삭제한다. 레플리카셋이 새로운 파드를 생성해야 할 경우, 명시된 파드 템플릿을 사용한다.
레플리카셋은 파드의 metadata.ownerReferences 필드를 통해 파드에 연결되며, 이는 현재 오브젝트가 소유한 리소스를 명시한다. 레플리카셋이 가지고 있는 모든 파드의 ownerReferences 필드는 해당 파드를 소유한 레플리카셋을 식별하기 위한 소유자 정보를 가진다. 이 링크를 통해 레플리카셋은 자신이 유지하는 파드의 상태를 확인하고 이에 따라 관리 한다.
레플리카셋은 셀렉터를 이용해서 필요한 새 파드를 식별한다. 만약 파드에 OwnerReference가 없거나, OwnerReference가 컨트롤러(Controller) 가 아니고 레플리카셋의 셀렉터와 일치한다면 레플리카셋이 즉각 파드를 가지게 될 것이다.
레플리카셋을 사용하는 시기
레플리카셋은 지정된 수의 파드 레플리카가 항상 실행되도록 보장한다. 그러나 디플로이먼트는 레플리카셋을 관리하고 다른 유용한 기능과 함께 파드에 대한 선언적 업데이트를 제공하는 상위 개념이다. 따라서 별도의 사용자 정의(custom) 업데이트 오케스트레이션이 필요한 경우 또는 업데이트가 전혀 필요 없는 경우가 아니라면, 레플리카셋을 직접 사용하기보다는 디플로이먼트를 사용하는 것을 권장한다.
이는 레플리카셋 오브젝트를 직접 조작할 필요가 없다는 것을 의미한다. 대신 디플로이먼트를 이용하고 사양 부분에서 애플리케이션을 정의하면 된다.
예시
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# 케이스에 따라 레플리카를 수정한다.
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
이 매니페스트를 frontend.yaml에 저장하고 쿠버네티스 클러스터에 적용하면 정의되어 있는 레플리카셋이
생성되고 레플리카셋이 관리하는 파드가 생성된다.
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
현재 배포된 레플리카셋을 확인할 수 있다.
kubectl get rs
그리고 생성된 프런트엔드를 볼 수 있다.
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 6s
또한 레플리카셋의 상태를 확인할 수 있다.
kubectl describe rs/frontend
출력은 다음과 유사할 것이다.
Name: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"ReplicaSet","metadata":{"annotations":{},"labels":{"app":"guestbook","tier":"frontend"},"name":"frontend",...
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 117s replicaset-controller Created pod: frontend-wtsmm
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-b2zdv
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-vcmts
마지막으로 파드가 올라왔는지 확인할 수 있다.
kubectl get pods
다음과 유사한 파드 정보를 볼 수 있다.
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 6m36s
frontend-vcmts 1/1 Running 0 6m36s
frontend-wtsmm 1/1 Running 0 6m36s
또한 파드들의 소유자 참조 정보가 해당 프런트엔드 레플리카셋으로 설정되어 있는지 확인할 수 있다. 확인을 위해서는 실행 중인 파드 중 하나의 yaml을 확인한다.
kubectl get pods frontend-b2zdv -o yaml
메타데이터의 ownerReferences 필드에 설정되어 있는 프런트엔드 레플리카셋의 정보가 다음과 유사하게 나오는 것을 볼 수 있다.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-02-12T07:06:16Z"
generateName: frontend-
labels:
tier: frontend
name: frontend-b2zdv
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: frontend
uid: f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...
템플릿을 사용하지 않는 파드의 획득
단독(bare) 파드를 생성하는 것에는 문제가 없지만, 단독 파드가 레플리카셋의 셀렉터와 일치하는 레이블을 가지지 않도록 하는 것을 강력하게 권장한다. 그 이유는 레플리카셋이 소유하는 파드가 템플릿에 명시된 파드에만 국한되지 않고, 이전 섹션에서 명시된 방식에 의해서도 다른 파드의 획득이 가능하기 때문이다.
이전 프런트엔드 레플리카셋 예제와 다음의 매니페스트에 명시된 파드를 가져와 참조한다.
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
tier: frontend
spec:
containers:
- name: hello1
image: gcr.io/google-samples/hello-app:2.0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
labels:
tier: frontend
spec:
containers:
- name: hello2
image: gcr.io/google-samples/hello-app:1.0
기본 파드는 소유자 관련 정보에 컨트롤러(또는 오브젝트)를 가지지 않기 때문에 프런트엔드 레플리카셋의 셀렉터와 일치하면 즉시 레플리카셋에 소유된다.
프런트엔드 레플리카셋이 배치되고 초기 파드 레플리카가 셋업된 이후에, 레플리카 수 요구 사항을 충족시키기 위해서 신규 파드를 생성한다고 가정해보자.
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
새로운 파드는 레플리카셋에 의해 인식되며 레플리카셋이 필요한 수량을 초과하면 즉시 종료된다.
파드를 가져온다.
kubectl get pods
결과에는 새로운 파드가 이미 종료되었거나 종료가 진행 중인 것을 보여준다.
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1s
파드를 먼저 생성한다.
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
그 다음 레플리카셋을 생성한다.
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
레플리카셋이 해당 파드를 소유한 것을 볼 수 있으며 새 파드 및 기존 파드의 수가 레플리카셋이 필요로 하는 수와 일치할 때까지 사양에 따라 신규 파드만 생성한다. 파드를 가져온다.
kubectl get pods
다음 출력에서 볼 수 있다.
NAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36s
이러한 방식으로 레플리카셋은 템플릿을 사용하지 않는 파드를 소유하게 된다.
레플리카셋 매니페스트 작성하기
레플리카셋은 모든 쿠버네티스 API 오브젝트와 마찬가지로 apiVersion, kind, metadata 필드가 필요하다.
레플리카셋에 대한 kind 필드의 값은 항상 레플리카셋이다.
레플리카셋 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
레플리카셋도 .spec 섹션이 필요하다.
파드 템플릿
.spec.template은 레이블을 붙이도록 되어 있는 파드 템플릿이다.
우리는 frontend.yaml 예제에서 tier: frontend이라는 레이블을 하나 가지고 있다.
이 파드를 다른 컨트롤러가 취하지 않도록 다른 컨트롤러의 셀렉터와 겹치지 않도록 주의해야 한다.
템플릿의 재시작 정책 필드인
.spec.template.spec.restartPolicy는 기본값인 Always만 허용된다.
파드 셀렉터
.spec.selector 필드는 레이블 셀렉터이다.
앞서 논의한 것처럼 이 레이블은 소유될 가능성이 있는 파드를 식별하는데 사용된다.
우리 frontend.yaml 예제에서의 셀렉터는 다음과 같다.
matchLabels:
tier: frontend
레플리카셋에서 .spec.template.metadata.labels는 spec.selector과 일치해야 하며
그렇지 않으면 API에 의해 거부된다.
참고:
2개의 레플리카셋이 동일한.spec.selector필드를 지정한 반면, 다른
.spec.template.metadata.labels와 .spec.template.spec 필드를 명시한 경우, 각 레플리카셋은
다른 레플리카셋이 생성한 파드를 무시한다.레플리카
.spec.replicas를 설정해서 동시에 동작하는 파드의 수를 지정할 수 있다.
레플리카셋은 파드의 수가 일치하도록 생성 및 삭제한다.
만약 .spec.replicas를 지정하지 않으면 기본값은 1이다.
레플리카셋 작업
레플리카셋과 해당 파드 삭제
레플리카셋 및 모든 파드를 삭제하려면
kubectl delete를 사용한다.
가비지 수집기는
기본적으로 종속되어 있는 모든 파드를 자동으로 삭제한다.
REST API 또는 client-go 라이브러리를 이용할 때는 -d 옵션으로 propagationPolicy를
Background또는 Foreground로 설정해야 한다. 예시:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
> -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
> -H "Content-Type: application/json"
레플리카셋만 삭제하기
kubectl delete에
--cascade=orphan 옵션을 사용하여
연관 파드에 영향을 주지 않고 레플리카셋을 삭제할 수 있다.
REST API 또는 client-go 라이브러리를 이용할 때는 propagationPolicy에 Orphan을 설정해야 한다.
예시:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
> -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
> -H "Content-Type: application/json"
원본이 삭제되면 새 레플리카셋을 생성해서 대체할 수 있다.
기존 .spec.selector와 신규 .spec.selector가 같으면 새 레플리카셋은 기존 파드를 선택한다.
하지만 신규 레플리카셋은 기존 파드를 신규 레플리카셋의 새롭고 다른 파드 템플릿에 일치시키는 작업을 수행하지는 않는다.
컨트롤 방식으로 파드를 새로운 사양으로 업데이트 하기 위해서는
디플로이먼트를 이용하면 된다.
이는 레플리카셋이 롤링 업데이트를 직접적으로 지원하지 않기 때문이다.
레플리카셋에서 파드 격리
레이블을 변경하면 레플리카셋에서 파드를 제거할 수 있다. 이 방식은 디버깅과 데이터 복구 등을 위해 서비스에서 파드를 제거하는 데 사용할 수 있다. 이 방식으로 제거된 파드는 자동으로 교체된다( 레플리카의 수가 변경되지 않는다고 가정한다).
레플리카셋의 스케일링
레플리카셋을 손쉽게 스케일 업 또는 다운하는 방법은 단순히 .spec.replicas 필드를 업데이트하면 된다.
레플리카셋 컨트롤러는 일치하는 레이블 셀렉터가 있는 파드가 의도한 수 만큼 가용하고 운영 가능하도록 보장한다.
스케일 다운할 때, 레플리카셋 컨트롤러는 스케일 다운할 파드의 우선순위를 정하기 위해 다음의 기준으로 가용 파드를 정렬하여 삭제할 파드를 결정한다.
- Pending 상태인 (+ 스케줄링할 수 없는) 파드가 먼저 스케일 다운된다.
controller.kubernetes.io/pod-deletion-cost어노테이션이 설정되어 있는 파드에 대해서는, 낮은 값을 갖는 파드가 먼저 스케일 다운된다.- 더 많은 레플리카가 있는 노드의 파드가 더 적은 레플리카가 있는 노드의 파드보다 먼저 스케일 다운된다.
- 파드 생성 시간이 다르면, 더 최근에 생성된 파드가
이전에 생성된 파드보다 먼저 스케일 다운된다.
(
LogarithmicScaleDown기능 게이트가 활성화되어 있으면 생성 시간이 정수 로그 스케일로 버킷화된다)
모든 기준에 대해 동등하다면, 스케일 다운할 파드가 임의로 선택된다.
파드 삭제 비용
기능 상태:
Kubernetes v1.22 [beta]
controller.kubernetes.io/pod-deletion-cost 어노테이션을 이용하여,
레플리카셋을 스케일 다운할 때 어떤 파드부터 먼저 삭제할지에 대한 우선순위를 설정할 수 있다.
이 어노테이션은 파드에 설정되어야 하며, [-2147483647, 2147483647] 범위를 갖는다. 이 어노테이션은 하나의 레플리카셋에 있는 다른 파드와의 상대적 삭제 비용을 나타낸다. 삭제 비용이 낮은 파드는 삭제 비용이 높은 파드보다 삭제 우선순위가 높다.
파드에 대해 이 값을 명시하지 않으면 기본값은 0이다. 음수로도 설정할 수 있다. 유효하지 않은 값은 API 서버가 거부한다.
이 기능은 베타 상태이며 기본적으로 활성화되어 있다.
kube-apiserver와 kube-controller-manager에 대해 PodDeletionCost
기능 게이트를 이용하여 비활성화할 수 있다.
참고:
- 이 기능은 best-effort 방식으로 동작하므로, 파드 삭제 순서를 보장하지는 않는다.
- 이 값을 자주 바꾸는 것은 피해야 한다 (예: 메트릭 값에 따라 변경). apiserver에서 많은 양의 파드 업데이트를 동반하기 때문이다.
사용 예시
한 애플리케이션 내의 여러 파드는 각각 사용률이 다를 수 있다. 스케일 다운 시,
애플리케이션은 사용률이 낮은 파드를 먼저 삭제하고 싶을 수 있다. 파드를 자주
업데이트하는 것을 피하기 위해, 애플리케이션은 controller.kubernetes.io/pod-deletion-cost 값을
스케일 다운하기 전에 1회만 업데이트해야 한다 (파드 사용률에 비례하는 값으로 설정).
이 방식은 Spark 애플리케이션의 드라이버 파드처럼 애플리케이션이 스스로 다운스케일링을 수행하는 경우에 유효하다.
레플리카셋을 Horizontal Pod Autoscaler 대상으로 설정
레플리카셋은 Horizontal Pod Autoscalers (HPA)의 대상이 될 수 있다. 즉, 레플리카셋은 HPA에 의해 오토스케일될 수 있다. 다음은 이전에 만든 예시에서 만든 레플리카셋을 대상으로 하는 HPA 예시이다.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: frontend-scaler
spec:
scaleTargetRef:
kind: ReplicaSet
name: frontend
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 50
이 매니페스트를 hpa-rs.yaml로 저장한 다음 쿠버네티스
클러스터에 적용하면 CPU 사용량에 따라 파드가 복제되는
오토스케일 레플리카셋 HPA가 생성된다.
kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yaml
또는 kubectl autoscale 커맨드을 사용해서 동일한 작업을 할 수 있다.
(그리고 더 쉽다!)
kubectl autoscale rs frontend --max=10 --min=3 --cpu-percent=50
레플리카셋의 대안
디플로이먼트(권장)
디플로이먼트는 레플리카셋을 소유하거나 업데이트를 하고,
파드의 선언적인 업데이트와 서버측 롤링 업데이트를 할 수 있는 오브젝트이다.
레플리카셋은 단독으로 사용할 수 있지만, 오늘날에는 주로 디플로이먼트로 파드의 생성과 삭제 그리고 업데이트를 오케스트레이션하는 메커니즘으로 사용한다.
디플로이먼트를 이용해서 배포할 때 생성되는 레플리카셋을 관리하는 것에 대해 걱정하지 않아도 된다.
디플로이먼트는 레플리카셋을 소유하거나 관리한다.
따라서 레플리카셋을 원한다면 디플로이먼트를 사용하는 것을 권장한다.
기본 파드
사용자가 직접 파드를 생성하는 경우와는 다르게, 레플리카셋은 노드 장애 또는 노드의 커널 업그레이드와 같은 관리 목적의 중단 등 어떤 이유로든 종료되거나 삭제된 파드를 교체한다. 이런 이유로 애플리케이션이 단일 파드가 필요하더라도 레플리카셋을 이용하는 것을 권장한다. 레플리카셋을 프로세스 관리자와 비교해서 생각해본다면, 레플리카셋은 단일 노드에서의 개별 프로세스들이 아닌 다수의 노드에 걸쳐있는 다수의 파드를 관리하는 것이다. 레플리카셋은 로컬 컨테이너의 재시작을 노드에 있는 Kubelet과 같은 에이전트에게 위임한다.
잡
스스로 종료되는 것이 예상되는 파드의 경우에는 레플리카셋 대신
잡을 이용한다 (즉, 배치 잡).
데몬셋
머신 모니터링 또는 머신 로깅과 같은 머신-레벨의 기능을 제공하는 파드를 위해서는 레플리카셋 대신
데몬셋을 사용한다.
이러한 파드의 수명은 머신의 수명과 연관되어 있고, 머신에서 다른 파드가 시작하기 전에 실행되어야 하며,
머신의 재부팅/종료가 준비되었을 때, 해당 파드를 종료하는 것이 안전하다.
레플리케이션 컨트롤러
레플리카셋은 레플리케이션 컨트롤러를 계승하였다. 이 두 개의 용도는 동일하고, 유사하게 동작하며, 레플리케이션 컨트롤러가 레이블 사용자 가이드에 설명된 설정-기반의 셀렉터의 요건을 지원하지 않는다는 점을 제외하면 유사하다. 따라서 레플리카셋이 레플리케이션 컨트롤러보다 선호된다.
다음 내용
- 파드에 대해 배운다.
- 디플로이먼트에 대해 배운다.
- 레플리카셋에 의존해서 동작하는 디플로이먼트로 스테이트리스 애플리케이션을 실행한다.
ReplicaSet는 쿠버네티스 REST API의 상위-수준 리소스이다. 레플리카셋 API에 대해 이해하기 위해 ReplicaSet 오브젝트 정의를 읽는다.- PodDisruptionBudget과 이를 사용해서 어떻게 중단 중에 애플리케이션 가용성을 관리할 수 있는지에 대해 읽는다.
5.2.3 - 스테이트풀셋
스테이트풀셋은 애플리케이션의 스테이트풀을 관리하는데 사용하는 워크로드 API 오브젝트이다.
파드 집합의 디플로이먼트와 스케일링을 관리하며, 파드들의 순서 및 고유성을 보장한다 .
디플로이먼트와 유사하게, 스테이트풀셋은 동일한 컨테이너 스펙을 기반으로 둔 파드들을 관리한다. 디플로이먼트와는 다르게, 스테이트풀셋은 각 파드의 독자성을 유지한다. 이 파드들은 동일한 스팩으로 생성되었지만, 서로 교체는 불가능하다. 다시 말해, 각각은 재스케줄링 간에도 지속적으로 유지되는 식별자를 가진다.
스토리지 볼륨을 사용해서 워크로드에 지속성을 제공하려는 경우, 솔루션의 일부로 스테이트풀셋을 사용할 수 있다. 스테이트풀셋의 개별 파드는 장애에 취약하지만, 퍼시스턴트 파드 식별자는 기존 볼륨을 실패한 볼륨을 대체하는 새 파드에 더 쉽게 일치시킬 수 있다.
스테이트풀셋 사용
스테이트풀셋은 다음 중 하나 또는 이상이 필요한 애플리케이션에 유용하다.
- 안정된, 고유한 네트워크 식별자.
- 안정된, 지속성을 갖는 스토리지.
- 순차적인, 정상 배포(graceful deployment)와 스케일링.
- 순차적인, 자동 롤링 업데이트.
위의 안정은 파드의 (재)스케줄링 전반에 걸친 지속성과 같은 의미이다. 만약 애플리케이션이 안정적인 식별자 또는 순차적인 배포, 삭제 또는 스케일링이 필요하지 않으면, 스테이트리스 레플리카셋(ReplicaSet)을 제공하는 워크로드 오브젝트를 사용해서 애플리케이션을 배포해야 한다. 디플로이먼트 또는 레플리카셋과 같은 컨트롤러가 스테이트리스 요구에 더 적합할 수 있다.
제한사항
- 파드에 지정된 스토리지는 관리자에 의해
퍼시스턴트 볼륨 프로비저너
를 기반으로 하는
storage class를 요청해서 프로비전하거나 사전에 프로비전이 되어야 한다. - 스테이트풀셋을 삭제 또는 스케일 다운해도 스테이트풀셋과 연관된 볼륨이 삭제되지 않는다. 이는 일반적으로 스테이트풀셋과 연관된 모든 리소스를 자동으로 제거하는 것보다 더 중요한 데이터의 안전을 보장하기 위함이다.
- 스테이트풀셋은 현재 파드의 네트워크 신원을 책임지고 있는 헤드리스 서비스 가 필요하다. 사용자가 이 서비스를 생성할 책임이 있다.
- 스테이트풀셋은 스테이트풀셋의 삭제 시 파드의 종료에 대해 어떠한 보증을 제공하지 않는다. 스테이트풀셋에서는 파드가 순차적이고 정상적으로 종료(graceful termination)되도록 하려면, 삭제 전 스테이트풀셋의 스케일을 0으로 축소할 수 있다.
- 롤링 업데이트와 기본
파드 매니지먼트 폴리시 (
OrderedReady)를 함께 사용시 복구를 위한 수동 개입이 필요한 파손 상태로 빠질 수 있다.
구성 요소
아래의 예시에서는 스테이트풀셋의 구성요소를 보여 준다.
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # .spec.template.metadata.labels 와 일치해야 한다
serviceName: "nginx"
replicas: 3 # 기본값은 1
minReadySeconds: 10 # 기본값은 0
template:
metadata:
labels:
app: nginx # .spec.selector.matchLabels 와 일치해야 한다
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
위의 예시에서:
- 이름이 nginx라는 헤드리스 서비스는 네트워크 도메인을 컨트롤하는데 사용 한다.
- 이름이 web인 스테이트풀셋은 3개의 nginx 컨테이너의 레플리카가 고유의 파드에서 구동될 것이라 지시하는 Spec을 갖는다.
- volumeClaimTemplates은 퍼시스턴트 볼륨 프로비저너에서 프로비전한 퍼시스턴트 볼륨을 사용해서 안정적인 스토리지를 제공한다.
스테이트풀셋 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
파드 셀렉터
스테이트풀셋의 .spec.selector 필드는
.spec.template.metadata.labels 레이블과 일치하도록 설정해야 한다. 해당되는 파드 셀렉터를 찾지 못하면
스테이트풀셋 생성 과정에서 검증 오류가 발생한다.
볼륨 클레임 템플릿
.spec.volumeClaimTemplates 를 설정하여, 퍼시스턴트볼륨 프로비저너에 의해 프로비전된
퍼시스턴트볼륨을 이용하는 안정적인 스토리지를
제공할 수 있다.
최소 준비 시간 초
기능 상태:
Kubernetes v1.25 [stable]
.spec.minReadySeconds 는 파드가 '사용 가능(available)'이라고 간주될 수 있도록 파드의 모든 컨테이너가
문제 없이 실행되고 준비되는 최소 시간(초)을 나타내는 선택적인 필드이다.
롤링 업데이트 전략을 사용할 때 롤아웃 진행 상황을 확인하는 데 사용된다.
이 필드의 기본값은 0이다(이 경우, 파드가 Ready 상태가 되면 바로 사용 가능하다고 간주된다.)
파드가 언제 사용 가능하다고 간주되는지에 대한 자세한 정보는 컨테이너 프로브(probe)를 참고한다.
파드 신원
스테이트풀셋 파드는 순서, 안정적인 네트워크 신원 그리고 안정적인 스토리지로 구성되는 고유한 신원을 가진다. 신원은 파드가 어떤 노드에 있고, (재)스케줄과도 상관없이 파드에 붙어있다.
순서 색인
N개의 레플리카가 있는 스테이트풀셋은 스테이트풀셋에 있는 각 파드에 0에서 N-1 까지의 정수가 순서대로 할당되며 해당 스테이트풀셋 내에서 고유 하다. 기본적으로 파드는 0부터 N-1까지의 순서대로 할당된다.
시작 순서
기능 상태:
Kubernetes v1.26 [alpha]
.spec.ordinals은 각 파드에 할당할 순서에 대한
정수값을 설정할 수 있게 해주는 선택적인 필드로, 기본값은 nil이다.
이 필드를 사용하기 위해서는
StatefulSetStartOrdinal 기능 게이트를 활성화해야 한다.
활성화 시, 다음과 같은 옵션들을 설정할 수 있다.
.spec.ordinals.start: 만약.spec.ordinals.start필드가 세팅되지 않을 경우, 파드는.spec.ordinals.start부터.spec.ordinals.start + .spec.replicas - 1의 순서대로 할당된다.
안정적인 네트워크 신원
스테이트풀셋의 각 파드는 스테이트풀셋의 이름과 파드의 순번에서
호스트 이름을 얻는다. 호스트 이름을 구성하는 패턴은
$(statefulset name)-$(ordinal) 이다. 위의 예시에서 생성된 3개 파드의 이름은
web-0,web-1,web-2 이다.
스테이트풀셋은 스테이트풀셋에 있는 파드의 도메인을 제어하기위해
헤드리스 서비스를 사용할 수 있다.
이 서비스가 관리하는 도메인은 $(service name).$(namespace).svc.cluster.local 의 형식을 가지며,
여기서 "cluster.local"은 클러스터 도메인이다.
각 파드는 생성되면 $(podname).$(governing service domain) 형식을 가지고
일치되는 DNS 서브도메인을 가지며, 여기서 거버닝 서비스(governing service)는
스테이트풀셋의 serviceName 필드에 의해 정의된다.
클러스터에서 DNS가 구성된 방식에 따라, 새로 실행된 파드의 DNS 이름을 즉시 찾지 못할 수 있다. 이 동작은 클러스터의 다른 클라이언트가 파드가 생성되기 전에 파드의 호스트 이름에 대한 쿼리를 이미 보낸 경우에 발생할 수 있다. 네거티브 캐싱(DNS에서 일반적)은 이전에 실패한 조회 결과가 파드가 실행된 후에도 적어도 몇 초 동안 기억되고 재사용됨을 의미한다.
파드를 생성한 후 즉시 파드를 검색해야 하는 경우, 몇 가지 옵션이 있다.
- DNS 조회에 의존하지 않고 쿠버네티스 API를 직접(예를 들어 watch 사용) 쿼리한다.
- 쿠버네티스 DNS 공급자의 캐싱 시간(일반적으로 CoreDNS의 컨피그맵을 편집하는 것을 의미하며, 현재 30초 동안 캐시함)을 줄인다.
제한사항 섹션에서 언급한 것처럼 사용자는 파드의 네트워크 신원을 책임지는 헤드리스 서비스를 생성할 책임이 있다.
여기 클러스터 도메인, 서비스 이름, 스테이트풀셋 이름을 선택을 하고, 그 선택이 스테이트풀셋 파드의 DNS이름에 어떻게 영향을 주는지에 대한 약간의 예시가 있다.
| 클러스터 도메인 | 서비스 (ns/이름) | 스테이트풀셋 (ns/이름) | 스테이트풀셋 도메인 | 파드 DNS | 파드 호스트 이름 |
|---|---|---|---|---|---|
| cluster.local | default/nginx | default/web | nginx.default.svc.cluster.local | web-{0..N-1}.nginx.default.svc.cluster.local | web-{0..N-1} |
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1}.nginx.foo.svc.cluster.local | web-{0..N-1} |
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0..N-1}.nginx.foo.svc.kube.local | web-{0..N-1} |
안정된 스토리지
스테이트풀셋에 정의된 VolumeClaimTemplate 항목마다, 각 파드는 하나의
PersistentVolumeClaim을 받는다. 위의 nginx 예시에서 각 파드는 my-storage-class 라는 스토리지 클래스와
1 Gib의 프로비전된 스토리지를 가지는 단일 퍼시스턴트 볼륨을 받게 된다. 만약 스토리지 클래스가
명시되지 않은 경우, 기본 스토리지 클래스가 사용된다. 파드가 노드에서 스케줄 혹은 재스케줄이 되면
파드의 volumeMounts 는 퍼시스턴트 볼륨 클레임과 관련된 퍼시스턴트 볼륨이 마운트 된다.
참고로, 파드 퍼시스턴트 볼륨 클레임과 관련된 퍼시스턴트 볼륨은
파드 또는 스테이트풀셋이 삭제되더라도 삭제되지 않는다.
이것은 반드시 수동으로 해야 한다.
파드 이름 레이블
스테이트풀셋 컨트롤러
가 파드를 생성할 때 파드 이름으로 statefulset.kubernetes.io/pod-name
레이블이 추가된다. 이 레이블로 스테이트풀셋의 특정 파드에 서비스를
연결할 수 있다.
디플로이먼트와 스케일링 보증
- N개의 레플리카가 있는 스테이트풀셋이 파드를 배포할 때 연속해서 {0..N-1}의 순서로 생성한다.
- 파드가 삭제될 때는 {N-1..0}의 순서인 역순으로 종료된다.
- 파드에 스케일링 작업을 적용하기 전에 모든 선행 파드가 Running 및 Ready 상태여야 한다.
- 파드가 종료되기 전에 모든 후속 파드가 완전히 종료 되어야 한다.
스테이트풀셋은 pod.Spec.TerminationGracePeriodSeconds 을 0으로 명시해서는 안된다. 이 방법은
안전하지 않으며, 사용하지 않기를 강권한다. 자세한 설명은
스테이트풀셋 파드 강제 삭제를 참고한다.
위의 nginx 예시가 생성될 때 web-0, web-1, web-2 순서로 3개 파드가 배포된다. web-1은 web-0이 Running 및 Ready 상태가 되기 전에는 배포되지 않으며, web-2 도 web-1이 Running 및 Ready 상태가 되기 전에는 배포되지 않는다. 만약 web-1이 Running 및 Ready 상태가 된 이후, web-2가 시작되기 전에 web-0이 실패하게 된다면, web-2는 web-0이 성공적으로 재시작이되고, Running 및 Ready 상태가 되기 전까지 시작되지 않는다.
만약 사용자가 배포된 예제의 스테이트풀셋을 replicas=1 으로 패치해서
스케일한 경우 web-2가 먼저 종료된다. web-1은 web-2가 완전히 종료 및 삭제되기
전까지 정지되지 않는다. 만약 web-2의 종료 및 완전히 중지되고, web-1이 종료되기 전에
web-0이 실패할 경우 web-1은 web-0이 Running 및 Ready 상태가
되기 전까지 종료되지 않는다.
파드 관리 정책
스테이트풀셋의 .spec.podManagementPolicy 필드를 통해
고유성 및 신원 보증을 유지하면서 순차 보증을 완화한다.
OrderedReady 파드 관리
OrderedReady 파드 관리는 스테이트풀셋의 기본이다.
이것은 위에서 설명한 행위를 구현한다.
Parallel 파드 관리
Parallel 파드 관리는 스테이트풀셋 컨트롤러에게 모든 파드를
병렬로 실행 또는 종료하게 한다. 그리고 다른 파드의 실행이나
종료에 앞서 파드가 Running 및 Ready 상태가 되거나 완전히 종료되기를 기다리지 않는다.
이 옵션은 오직 스케일링 작업에 대한 동작에만 영향을 미친다. 업데이트는 영향을
받지 않는다.
업데이트 전략
스테이트풀셋의 .spec.updateStrategy 필드는 스테이트풀셋의
파드에 대한 컨테이너, 레이블, 리소스의 요청/제한 그리고 주석에 대한 자동화된 롤링 업데이트를
구성하거나 비활성화할 수 있다. 두 가지 가능한 전략이 있다.
OnDelete(삭제시)- 스테이트풀셋의
.spec.updateStrategy.type은OnDelete를 설정하며, 스테이트풀셋 컨트롤러는 스테이트풀셋의 파드를 자동으로 업데이트하지 않는다. 사용자는 컨트롤러가 스테이트풀셋의.spec.template를 반영하는 수정된 새로운 파드를 생성하도록 수동으로 파드를 삭제해야 한다. RollingUpdate(롤링 업데이트)RollingUpdate업데이트 전략은 스테이트풀셋의 파드에 대한 롤링 업데이트를 구현한다. 기본 업데이트 전략이다.
롤링 업데이트
스테이트풀셋에 롤링 업데이트 가 .spec.updateStrategy.type 에 설정되면
스테이트풀셋 컨트롤러는 스테이트풀셋의 각 파드를 삭제 및 재생성한다. 이 과정에서 똑같이
순차적으로 파드가 종료되고(가장 큰 순서 색인에서부터에서 작은 순서 색인쪽으로),
각 파드의 업데이트는 한 번에 하나씩 한다.
쿠버네티스 컨트롤 플레인은 이전 버전을 업데이트 하기 전에, 업데이트된 파드가 실행 및 준비될 때까지 기다린다.
.spec.minReadySeconds(최소 준비 시간 초 참조)를
설정한 경우,
컨트롤 플레인은 파드가 준비 상태로 전환된 후 해당 시간을 추가로 기다린 후 이동한다.
파티션 롤링 업데이트
롤링 업데이트 의 업데이트 전략은 .spec.updateStrategy.rollingUpdate.partition
를 명시해서 파티션 할 수 있다. 만약 파티션을 명시하면 스테이트풀셋의 .spec.template 가
업데이트 될 때 부여된 수가 파티션보다 크거나 같은 모든 파드가 업데이트 된다.
파티션보다 작은 수를 가진 모든 파드는 업데이트 되지 않으며,
삭제 된 경우라도 이전 버전에서 재생성된다.
만약 스테이트풀셋의 .spec.updateStrategy.rollingUpdate.partition 이
.spec.replicas 보다 큰 경우 .spec.template 의 업데이트는 해당 파드에 전달하지 않는다.
대부분의 케이스는 파티션을 사용할 필요가 없지만 업데이트를 준비하거나,
카나리의 롤 아웃 또는 단계적인 롤 아웃을 행하려는 경우에는 유용하다.
최대 사용 불가능(unavailable) 파드 수
기능 상태:
Kubernetes v1.24 [alpha]
.spec.updateStrategy.rollingUpdate.maxUnavailable 필드를 명시하여,
업데이트 과정에서 사용 불가능(unavailable) 파드를 최대 몇 개까지 허용할 것인지를 조절할 수 있다.
값은 절대값(예: 5) 또는 목표 파드 퍼센티지(예: 10%)로 명시할 수 있다.
절대값은 퍼센티지 값으로 계산한 뒤 올림하여 얻는다.
이 필드는 0일 수 없다. 기본값은 1이다.
이 필드는 0 에서 replicas - 1 사이 범위에 있는 모든 파드에 적용된다.
이 범위 내에 사용 불가능한 파드가 있으면,
maxUnavailable로 집계된다.
강제 롤백
기본 파드 관리 정책 (OrderedReady)과
함께 롤링 업데이트를 사용할 경우
직접 수동으로 복구를 해야하는 고장난 상태가 될 수 있다.
만약 파드 템플릿을 Running 및 Ready 상태가 되지 않는 구성으로 업데이트하는 경우(예시: 잘못된 바이너리 또는 애플리케이션-레벨 구성 오류로 인한) 스테이트풀셋은 롤아웃을 중지하고 기다린다.
이 상태에서는 파드 템플릿을 올바른 구성으로 되돌리는 것으로 충분하지 않다. 알려진 이슈로 인해 스테이트풀셋은 손상된 파드가 준비(절대 되지 않음)될 때까지 기다리며 작동하는 구성으로 되돌아가는 시도를 하기 전까지 기다린다.
템플릿을 되돌린 이후에는 스테이트풀셋이 이미 잘못된 구성으로 실행하려고 시도한 모든 파드를 삭제해야 한다. 그러면 스테이트풀셋은 되돌린 템플릿을 사용해서 파드를 다시 생성하기 시작한다.
퍼시스턴트볼륨클레임 유보
기능 상태:
Kubernetes v1.23 [alpha]
선택적 필드인 .spec.persistentVolumeClaimRetentionPolicy 는
스테이트풀셋의 생애주기동안 PVC를 삭제할 것인지,
삭제한다면 어떻게 삭제하는지를 관리한다.
이 필드를 사용하려면 API 서버와 컨트롤러 매니저에 StatefulSetAutoDeletePVC 기능 게이트를 활성화해야 한다.
활성화 시, 각 스테이트풀셋에 대해 두 가지 정책을 설정할 수 있다.
whenDeleted- 스테이트풀셋이 삭제될 때 적용될 볼륨 유보 동작을 설정한다.
whenScaled- 스테이트풀셋의 레플리카 수가 줄어들 때, 예를 들면 스테이트풀셋을 스케일 다운할 때 적용될 볼륨 유보 동작을 설정한다.
설정 가능한 각 정책에 대해, 그 값을 Delete 또는 Retain 으로 설정할 수 있다.
DeletevolumeClaimTemplate스테이트풀셋으로부터 생성된 PVC는 정책에 영향을 받는 각 파드에 대해 삭제된다.whenDeleted가 이 값으로 설정되어 있으면volumeClaimTemplate으로부터 생성된 모든 PVC는 파드가 삭제된 뒤에 삭제된다.whenScaled가 이 값으로 설정되어 있으면 스케일 다운된 파드 레플리카가 삭제된 뒤, 삭제된 파드에 해당되는 PVC만 삭제된다.Retain(기본값)- 파드가 삭제되어도
volumeClaimTemplate으로부터 생성된 PVC는 영향을 받지 않는다. 이는 이 신기능이 도입되기 전의 기본 동작이다.
이러한 정책은 파드의 삭제가 스테이트풀셋 삭제 또는 스케일 다운으로 인한 것일 때에만 적용됨에 유의한다. 예를 들어, 스테이트풀셋의 파드가 노드 실패로 인해 실패했고, 컨트롤 플레인이 대체 파드를 생성했다면, 스테이트풀셋은 기존 PVC를 유지한다. 기존 볼륨은 영향을 받지 않으며, 새 파드가 실행될 노드에 클러스터가 볼륨을 연결(attach)한다.
정책의 기본값은 Retain 이며, 이는 이 신기능이 도입되기 전의 스테이트풀셋 기본 동작이다.
다음은 정책 예시이다.
apiVersion: apps/v1
kind: StatefulSet
...
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Delete
...
스테이트풀셋 컨트롤러는 자신이 소유한 PVC에
소유자 정보(reference)를
추가하며, 파드가 종료된 이후에는 가비지 콜렉터가 이 정보를 삭제한다.
이로 인해 PVC가 삭제되기 전에
(그리고 유보 정책에 따라, 매칭되는 기반 PV와 볼륨이 삭제되기 전에)
파드가 모든 볼륨을 깨끗하게 언마운트할 수 있다.
whenDeleted 정책을 Delete 로 설정하면,
해당 스테이트풀셋에 연결된 모든 PVC에 스테이트풀셋 인스턴스의 소유자 정보가 기록된다.
whenScaled 정책은 파드가 스케일 다운되었을 때에만 PVC를 삭제하며,
파드가 다른 원인으로 삭제되면 PVC를 삭제하지 않는다.
조정 상황 발생 시, 스테이트풀셋 컨트롤러는 목표 레플리카 수와 클러스터 상의 실제 파드 수를 비교한다.
레플리카 카운트보다 큰 ID를 갖는 스테이트풀셋 파드는 부적격 판정을 받으며 삭제 대상으로 표시된다.
whenScaled 정책이 Delete 이면, 부적격 파드는 삭제되기 전에,
연결된 스테이트풀셋 템플릿 PVC의 소유자로 지정된다.
이로 인해, 부적격 파드가 종료된 이후에만 PVC가 가비지 콜렉트된다.
이는 곧 만약 컨트롤러가 강제 종료되어 재시작되면, 파드의 소유자 정보가 정책에 적합하게 업데이트되기 전에는 어떤 파드도 삭제되지 않을 것임을 의미한다. 만약 컨트롤러가 다운된 동안 부적격 파드가 강제로 삭제되면, 컨트롤러가 강제 종료된 시점에 따라 소유자 정보가 설정되었을 수도 있고 설정되지 않았을 수도 있다. 소유자 정보가 업데이트되기까지 몇 번의 조정 절차가 필요할 수 있으며, 따라서 일부 부적격 파드는 소유자 정보 설정을 완료하고 나머지는 그러지 못했을 수 있다. 이러한 이유로, 컨트롤러가 다시 켜져서 파드를 종료하기 전에 소유자 정보를 검증할 때까지 기다리는 것을 추천한다. 이것이 불가능하다면, 관리자는 PVC의 소유자 정보를 확인하여 파드가 강제 삭제되었을 때 해당되는 오브젝트가 삭제되도록 해야 한다.
레플리카
.spec.replicas 은 필요한 파드의 수를 지정하는 선택적 필드이다. 기본값은 1이다.
예를 들어 kubectl scale deployment deployment --replicas=X 명령으로
디플로이먼트의 크기를 수동으로 조정한 뒤,
매니페스트를 이용하여 디플로이먼트를 업데이트하면(예: kubectl apply -f deployment.yaml 실행),
수동으로 설정했던 디플로이먼트의 크기가
오버라이드된다.
HorizontalPodAutoscaler(또는 수평 스케일링을 위한 유사 API)가
디플로이먼트 크기를 관리하고 있다면, .spec.replicas 를 설정해서는 안 된다.
대신, 쿠버네티스
컨트롤 플레인이
.spec.replicas 필드를 자동으로 관리한다.
다음 내용
- 파드에 대해 배운다.
- 스테이트풀셋을 사용하는 방법을 알아본다.
- 스테이트풀셋 애플리케이션 배포 예제를 따라한다.
- 스테이트풀셋으로 카산드라 배포 예제를 따라한다.
- 복제된 스테이트풀셋 애플리케이션 구동하기 예제를 따라한다.
- 스테이트풀셋 확장하기에 대해 배운다.
- 스테이트풀셋을 삭제하면 어떤 일이 수반되는지를 배운다.
- 스토리지의 볼륨을 사용하는 파드 구성을 하는 방법을 배운다.
- 스토리지로 퍼시스턴트볼륨(PersistentVolume)을 사용하도록 파드 설정하는 방법을 배운다.
StatefulSet은 쿠버네티스 REST API의 상위-수준 리소스이다. 스테이트풀셋 API에 대해 이해하기 위해 StatefulSet 오브젝트 정의를 읽는다.- PodDisruptionBudget과 이를 사용해서 어떻게 중단 중에 애플리케이션 가용성을 관리할 수 있는지에 대해 읽는다.
5.2.4 - 데몬셋
데몬셋 은 모든(또는 일부) 노드가 파드의 사본을 실행하도록 한다. 노드가 클러스터에 추가되면 파드도 추가된다. 노드가 클러스터에서 제거되면 해당 파드는 가비지(garbage)로 수집된다. 데몬셋을 삭제하면 데몬셋이 생성한 파드들이 정리된다.
데몬셋의 일부 대표적인 용도는 다음과 같다.
- 모든 노드에서 클러스터 스토리지 데몬 실행
- 모든 노드에서 로그 수집 데몬 실행
- 모든 노드에서 노드 모니터링 데몬 실행
단순한 케이스에서는, 각 데몬 유형의 처리를 위해서 모든 노드를 커버하는 하나의 데몬셋이 사용된다. 더 복잡한 구성에서는 단일 유형의 데몬에 여러 데몬셋을 사용할 수 있지만, 각기 다른 하드웨어 유형에 따라 서로 다른 플래그, 메모리, CPU 요구가 달라진다.
데몬셋 사양 작성
데몬셋 생성
YAML 파일에 데몬셋 명세를 작성할 수 있다. 예를 들어 아래 daemonset.yaml 파일은
fluentd-elasticsearch 도커 이미지를 실행하는 데몬셋을 설명한다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 이 톨러레이션(toleration)은 데몬셋이 컨트롤 플레인 노드에서 실행될 수 있도록 만든다.
# 컨트롤 플레인 노드가 이 파드를 실행해서는 안 되는 경우, 이 톨러레이션을 제거한다.
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
YAML 파일을 기반으로 데몬셋을 생성한다.
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
필수 필드
다른 모든 쿠버네티스 설정과 마찬가지로 데몬셋에는 apiVersion, kind 그리고 metadata 필드가 필요하다.
일반적인 설정파일 작업에 대한 정보는
스테이트리스 애플리케이션 실행하기와
kubectl을 사용한 오브젝트 관리를 참고한다.
데몬셋 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
데몬셋에는
.spec
섹션도 필요하다.
파드 템플릿
.spec.template 는 .spec 의 필수 필드 중 하나이다.
.spec.template 는 파드 템플릿이다.
이것은 중첩되어 있다는 점과 apiVersion 또는 kind 를 가지지 않는 것을 제외하면
파드와 정확히 같은 스키마를 가진다.
데몬셋의 파드 템플릿에는 파드의 필수 필드 외에도 적절한 레이블이 명시되어야 한다(파드 셀렉터를 본다).
데몬셋의 파드 템플릿의 RestartPolicy는 Always 를 가져야 하며,
명시되지 않은 경우 기본으로 Always가 된다.
파드 셀렉터
.spec.selector 필드는 파드 셀렉터이다. 이것은
잡의 .spec.selector 와 같은 동작을 한다.
.spec.template의 레이블과 매치되는
파드 셀렉터를 명시해야 한다.
또한, 한 번 데몬셋이 만들어지면
.spec.selector 는 바꿀 수 없다.
파드 셀렉터를 변형하면 의도치 않게 파드가 고아가 될 수 있으며, 이는 사용자에게 혼란을 주는 것으로 밝혀졌다.
.spec.selector 는 다음 2개의 필드로 구성된 오브젝트이다.
matchLabels- 레플리케이션 컨트롤러의.spec.selector와 동일하게 작동한다.matchExpressions- 키, 값 목록 그리고 키 및 값에 관련된 연산자를 명시해서 보다 정교한 셀렉터를 만들 수 있다.
2개의 필드가 명시되면 두 필드를 모두 만족하는 것(ANDed)이 결과가 된다.
.spec.selector 는 .spec.template.metadata.labels 와 일치해야 한다.
이 둘이 서로 일치하지 않는 구성은 API에 의해 거부된다.
오직 일부 노드에서만 파드 실행
만약 .spec.template.spec.nodeSelector 를 명시하면 데몬셋 컨트롤러는
노드 셀렉터와
일치하는 노드에 파드를 생성한다.
마찬가지로 .spec.template.spec.affinity 를 명시하면
데몬셋 컨트롤러는 노드 어피니티와 일치하는 노드에 파드를 생성한다.
만약 둘 중 하나를 명시하지 않으면 데몬셋 컨트롤러는 모든 노드에서 파드를 생성한다.
데몬 파드가 스케줄 되는 방법
기본 스케줄러로 스케줄
기능 상태:
Kubernetes 1.17 [stable]
데몬셋은 자격이 되는 모든 노드에서 파드 사본이 실행하도록 보장한다. 일반적으로 쿠버네티스 스케줄러에 의해 파드가 실행되는 노드가 선택된다. 그러나 데몬셋 파드는 데몬셋 컨트롤러에 의해 생성되고 스케줄된다. 이에 대한 이슈를 소개한다.
- 파드 동작의 불일치: 스케줄 되기 위해서 대기 중인 일반 파드는
Pending상태로 생성된다. 그러나 데몬셋 파드는Pending상태로 생성되지 않는다. 이것은 사용자에게 혼란을 준다. - 파드 선점은 기본 스케줄러에서 처리한다. 선점이 활성화되면 데몬셋 컨트롤러는 파드 우선순위와 선점을 고려하지 않고 스케줄 한다.
ScheduleDaemonSetPods 로 데몬셋 파드에 .spec.nodeName 용어 대신
NodeAffinity 용어를 추가해서 데몬셋 컨트롤러 대신 기본
스케줄러를 사용해서 데몬셋을 스케줄할 수 있다. 이후에 기본
스케줄러를 사용해서 대상 호스트에 파드를 바인딩한다. 만약 데몬셋 파드에
이미 노드 선호도가 존재한다면 교체한다(대상 호스트를 선택하기 전에
원래 노드의 어피니티가 고려된다). 데몬셋 컨트롤러는
데몬셋 파드를 만들거나 수정할 때만 이런 작업을 수행하며,
데몬셋의 spec.template 은 변경되지 않는다.
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-name
또한, 데몬셋 파드에 node.kubernetes.io/unschedulable:NoSchedule 이 톨러레이션(toleration)으로
자동으로 추가된다. 기본 스케줄러는 데몬셋 파드를
스케줄링시 unschedulable 노드를 무시한다.
테인트(taints)와 톨러레이션(tolerations)
데몬 파드는 테인트와 톨러레이션을 존중하지만, 다음과 같이 관련 기능에 따라 자동적으로 데몬셋 파드에 톨러레이션을 추가한다.
| 톨러레이션 키 | 영향 | 버전 | 설명 |
|---|---|---|---|
node.kubernetes.io/not-ready |
NoExecute | 1.13+ | 네트워크 파티션과 같은 노드 문제가 발생해도 데몬셋 파드는 축출되지 않는다. |
node.kubernetes.io/unreachable |
NoExecute | 1.13+ | 네트워크 파티션과 같은 노드 문제가 발생해도 데몬셋 파드는 축출되지 않는다. |
node.kubernetes.io/disk-pressure |
NoSchedule | 1.8+ | 데몬셋 파드는 기본 스케줄러에서 디스크-압박(disk-pressure) 속성을 허용한다. |
node.kubernetes.io/memory-pressure |
NoSchedule | 1.8+ | 데몬셋 파드는 기본 스케줄러에서 메모리-압박(memory-pressure) 속성을 허용한다. |
node.kubernetes.io/unschedulable |
NoSchedule | 1.12+ | 데몬셋 파드는 기본 스케줄러의 스케줄할 수 없는(unschedulable) 속성을 극복한다. |
node.kubernetes.io/network-unavailable |
NoSchedule | 1.12+ | 호스트 네트워크를 사용하는 데몬셋 파드는 기본 스케줄러에 의해 이용할 수 없는 네트워크(network-unavailable) 속성을 극복한다. |
데몬 파드와 통신
데몬셋의 파드와 통신할 수 있는 몇 가지 패턴은 다음과 같다.
- 푸시(Push): 데몬셋의 파드는 통계 데이터베이스와 같은 다른 서비스로 업데이트를 보내도록 구성되어 있다. 그들은 클라이언트들을 가지지 않는다.
- 노드IP와 알려진 포트: 데몬셋의 파드는
호스트 포트를 사용할 수 있으며, 노드IP를 통해 파드에 접근할 수 있다. 클라이언트는 노드IP를 어떻게든지 알고 있으며, 관례에 따라 포트를 알고 있다. - DNS: 동일한 파드 셀렉터로 헤드리스 서비스를 만들고,
그 다음에
엔드포인트리소스를 사용해서 데몬셋을 찾거나 DNS에서 여러 A레코드를 검색한다. - 서비스: 동일한 파드 셀렉터로 서비스를 생성하고, 서비스를 사용해서 임의의 노드의 데몬에 도달한다(특정 노드에 도달할 방법이 없다).
데몬셋 업데이트
만약 노드 레이블이 변경되면, 데몬셋은 새로 일치하는 노드에 즉시 파드를 추가하고, 새로 일치하지 않는 노드에서 파드를 삭제한다.
사용자는 데몬셋이 생성하는 파드를 수정할 수 있다. 그러나 파드는 모든 필드가 업데이트 되는 것을 허용하지 않는다. 또한 데몬셋 컨트롤러는 다음에 노드(동일한 이름으로)가 생성될 때 원본 템플릿을 사용한다.
사용자는 데몬셋을 삭제할 수 있다. 만약 kubectl 에서 --cascade=orphan 를 명시하면
파드는 노드에 남게 된다. 이후에 동일한 셀렉터로 새 데몬셋을 생성하면,
새 데몬셋은 기존 파드를 채택한다. 만약 파드를 교체해야 하는 경우 데몬셋은
updateStrategy 에 따라 파드를 교체한다.
사용자는 데몬셋에서 롤링 업데이트를 수행할 수 있다.
데몬셋의 대안
초기화 스크립트
데몬 프로세스를 직접 노드에서 시작해서 실행하는 것도 당연히 가능하다.
(예: init, upstartd 또는 systemd 를 사용). 이 방법도 문제는 전혀 없다. 그러나 데몬셋을 통해 데몬
프로세스를 실행하면 몇 가지 이점 있다.
- 애플리케이션과 동일한 방법으로 데몬을 모니터링하고 로그 관리를 할 수 있다.
- 데몬 및 애플리케이션과 동일한 구성 언어와 도구(예: 파드 템플릿,
kubectl). - 리소스 제한이 있는 컨테이너에서 데몬을 실행하면 앱 컨테이너에서 데몬간의 격리를 증가시킨다. 그러나 이것은 파드가 아닌 컨테이너에서 데몬을 실행해서 이루어진다.
베어(Bare) 파드
직접적으로 파드를 실행할 특정한 노드를 명시해서 파드를 생성할 수 있다. 그러나 데몬셋은 노드 장애 또는 커널 업그레이드와 같이 변경사항이 많은 노드 유지보수의 경우를 비롯하여 어떠한 이유로든 삭제되거나 종료된 파드를 교체한다. 따라서 개별 파드를 생성하는 것보다는 데몬 셋을 사용해야 한다.
스태틱(static) 파드
Kubelet이 감시하는 특정 디렉터리에 파일을 작성하는 파드를 생성할 수 있다. 이것을 스태틱 파드라고 부른다. 데몬셋과는 다르게 스태틱 파드는 kubectl 또는 다른 쿠버네티스 API 클라이언트로 관리할 수 없다. 스태틱 파드는 API 서버에 의존하지 않기 때문에 클러스터 부트스트랩(bootstraping)하는 경우에 유용하다. 또한 스태틱 파드는 향후에 사용 중단될 수 있다.
디플로이먼트
데몬셋은 파드를 생성한다는 점에서 디플로이먼트와 유사하고, 해당 파드에서는 프로세스가 종료되지 않을 것으로 예상한다(예: 웹 서버).
파드가 실행되는 호스트를 정확하게 제어하는 것보다 레플리카의 수를 스케일링 업 및 다운 하고, 업데이트 롤아웃이 더 중요한 프런트 엔드와 같은 것은 스테이트리스 서비스의 디플로이먼트를 사용한다. 데몬셋이 특정 노드에서 다른 파드가 올바르게 실행되도록 하는 노드 수준 기능을 제공한다면, 파드 사본이 항상 모든 호스트 또는 특정 호스트에서 실행되는 것이 중요한 경우에 데몬셋을 사용한다.
예를 들어, 네트워크 플러그인은 데몬셋으로 실행되는 컴포넌트를 포함할 수 있다. 데몬셋 컴포넌트는 작동 중인 노드가 정상적인 클러스터 네트워킹을 할 수 있도록 한다.
다음 내용
- 파드에 대해 배운다.
- 데몬셋을 어떻게 사용하는지 알아본다.
- 데몬셋 롤링 업데이트 수행하기
- 데몬셋 롤백하기 (예를 들어, 롤 아웃이 예상대로 동작하지 않은 경우).
- 쿠버네티스가 파드를 노드에 할당하는 방법을 이해한다.
- 데몬셋으로 구동되곤 하는, 디바이스 플러그인과 애드온에 대해 배운다.
DaemonSet은 쿠버네티스 REST API에서 상위-수준 리소스이다. 데몬셋 API에 대해 이해하기 위해 DaemonSet 오브젝트 정의를 읽는다.
5.2.5 - 잡
잡에서 하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료될 때까지 계속해서 파드의 실행을 재시도한다. 파드가 성공적으로 완료되면, 성공적으로 완료된 잡을 추적한다. 지정된 수의 성공 완료에 도달하면, 작업(즉, 잡)이 완료된다. 잡을 삭제하면 잡이 생성한 파드가 정리된다. 작업을 일시 중지하면 작업이 다시 재개될 때까지 활성 파드가 삭제된다.
간단한 사례는 잡 오브젝트를 하나 생성해서 파드 하나를 안정적으로 실행하고 완료하는 것이다. 첫 번째 파드가 실패 또는 삭제된 경우(예로는 노드 하드웨어의 실패 또는 노드 재부팅) 잡 오브젝트는 새로운 파드를 기동시킨다.
잡을 사용하면 여러 파드를 병렬로 실행할 수도 있다.
잡을 스케줄에 따라 구동하고 싶은 경우(단일 작업이든, 여러 작업의 병렬 수행이든), 크론잡(CronJob)을 참고한다.
예시 잡 실행하기
다음은 잡 설정 예시이다. 예시는 파이(π)의 2000 자리까지 계산해서 출력한다. 이를 완료하는 데 약 10초가 소요된다.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
이 명령으로 예시를 실행할 수 있다.
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
출력 결과는 다음과 같다.
job.batch/pi created
kubectl 을 사용해서 잡 상태를 확인한다.
Name: pi
Namespace: default
Selector: controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
job-name=pi
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"batch/v1","kind":"Job","metadata":{"annotations":{},"name":"pi","namespace":"default"},"spec":{"backoffLimit":4,"template":...
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 14m job-controller Created pod: pi-5rwd7
apiVersion: batch/v1
kind: Job
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"batch/v1","kind":"Job","metadata":{"annotations":{},"name":"pi","namespace":"default"},"spec":{"backoffLimit":4,"template":{"spec":{"containers":[{"command":["perl","-Mbignum=bpi","-wle","print bpi(2000)"],"image":"perl","name":"pi"}],"restartPolicy":"Never"}}}}
creationTimestamp: "2022-06-15T08:40:15Z"
generation: 1
labels:
controller-uid: 863452e6-270d-420e-9b94-53a54146c223
job-name: pi
name: pi
namespace: default
resourceVersion: "987"
uid: 863452e6-270d-420e-9b94-53a54146c223
spec:
backoffLimit: 4
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
controller-uid: 863452e6-270d-420e-9b94-53a54146c223
suspend: false
template:
metadata:
creationTimestamp: null
labels:
controller-uid: 863452e6-270d-420e-9b94-53a54146c223
job-name: pi
spec:
containers:
- command:
- perl
- -Mbignum=bpi
- -wle
- print bpi(2000)
image: perl:5.34.0
imagePullPolicy: Always
name: pi
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
active: 1
ready: 1
startTime: "2022-06-15T08:40:15Z"
kubectl get pods 를 사용해서 잡의 완료된 파드를 본다.
잡에 속하는 모든 파드를 기계적으로 읽을 수 있는 양식으로 나열하려면, 다음과 같은 명령을 사용할 수 있다.
pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $pods
출력 결과는 다음과 같다.
pi-5rwd7
여기서 셀렉터는 잡의 셀렉터와 동일하다. --output=jsonpath 옵션은 반환된
목록에 있는 각 파드의 이름으로 표현식을 지정한다.
파드 중 하나를 표준 출력으로 본다.
kubectl logs $pods
출력 결과는 다음과 같다.
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
잡 사양 작성하기
다른 쿠버네티스의 설정과 마찬가지로 잡에는 apiVersion, kind 그리고 metadata 필드가 필요하다.
잡의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
잡에는 .spec 섹션도 필요하다.
파드 템플릿
.spec.template 은 .spec 의 유일한 필수 필드이다.
.spec.template 은 파드 템플릿이다. 이것은 apiVersion 또는 kind 가 없다는 것을 제외한다면 파드와 정확하게 같은 스키마를 가지고 있다.
추가로 파드의 필수 필드 외에도 잡의 파드 템플릿은 적절한 레이블(파드 셀렉터를 본다)과 적절한 재시작 정책을 명시해야 한다.
Never 또는 OnFailure 와 같은 RestartPolicy만 허용된다.
파드 셀렉터
.spec.selector 필드는 선택 사항이다. 대부분의 케이스에서 지정해서는 안된다.
자신의 파드 셀렉터를 지정하기 섹션을 참고한다.
잡에 대한 병렬 실행
잡으로 실행하기에 적합한 작업 유형은 크게 세 가지가 있다.
- 비-병렬(Non-parallel) 잡:
- 일반적으로, 파드가 실패하지 않은 한, 하나의 파드만 시작된다.
- 파드가 성공적으로 종료하자마자 즉시 잡이 완료된다.
- 고정적(fixed)인 완료 횟수 를 가진 병렬 잡:
.spec.completions에 0이 아닌 양수 값을 지정한다.- 잡은 전체 작업을 나타내며,
.spec.completions성공한 파드가 있을 때 완료된다. .spec.completionMode="Indexed"를 사용할 때, 각 파드는 0에서.spec.completions-1범위 내의 서로 다른 인덱스를 가져온다.
- 작업 큐(queue) 가 있는 병렬 잡:
.spec.completions를 지정하지 않고,.spec.parallelism를 기본으로 한다.- 파드는 각자 또는 외부 서비스 간에 조정을 통해 각각의 작업을 결정해야 한다. 예를 들어 파드는 작업 큐에서 최대 N 개의 항목을 일괄로 가져올(fetch) 수 있다.
- 각 파드는 모든 피어들의 작업이 완료되었는지 여부를 독립적으로 판단할 수 있으며, 결과적으로 전체 잡이 완료되게 한다.
- 잡의 모든 파드가 성공적으로 종료되면, 새로운 파드는 생성되지 않는다.
- 하나 이상의 파드가 성공적으로 종료되고, 모든 파드가 종료되면 잡은 성공적으로 완료된다.
- 성공적으로 종료된 파드가 하나라도 생긴 경우, 다른 파드들은 해당 작업을 지속하지 않아야 하며 어떠한 출력도 작성하면 안 된다. 파드들은 모두 종료되는 과정에 있어야 한다.
비-병렬 잡은 .spec.completions 와 .spec.parallelism 모두를 설정하지 않은 채로 둘 수 있다. 이때 둘 다
설정하지 않은 경우 1이 기본으로 설정된다.
고정적인 완료 횟수 잡은 .spec.completions 을 필요한 완료 횟수로 설정해야 한다.
.spec.parallelism 을 설정할 수 있고, 설정하지 않으면 1이 기본으로 설정된다.
작업 큐 잡은 .spec.completions 를 설정하지 않은 상태로 두고, .spec.parallelism 을
음수가 아닌 정수로 설정해야 한다.
다른 유형의 잡을 사용하는 방법에 대한 더 자세한 정보는 잡 패턴 섹션을 본다.
병렬 처리 제어하기
요청된 병렬 처리(.spec.parallelism)는 음수가 아닌 값으로 설정할 수 있다.
만약 지정되지 않은 경우에는 1이 기본이 된다.
만약 0으로 지정되면 병렬 처리가 증가할 때까지 사실상 일시 중지된다.
실제 병렬 처리(모든 인스턴스에서 실행되는 파드의 수)는 여러가지 이유로 요청된 병렬 처리보다 많거나 적을 수 있다.
- 고정적인 완료 횟수(fixed completion count) 잡의 경우, 병렬로 실행 중인 파드의 수는 남은 완료 수를
초과하지 않는다.
.spec.parallelism의 더 큰 값은 사실상 무시된다. - 작업 큐 잡은 파드가 성공한 이후에 새로운 파드가 시작되지 않는다. 그러나 나머지 파드는 완료될 수 있다.
- 만약 잡 컨트롤러 가 반응할 시간이 없는 경우
- 만약 잡 컨트롤러가 어떤 이유(
ResourceQuota의 부족, 권한 부족 등)로든 파드 생성에 실패한 경우, 요청한 것보다 적은 수의 파드가 있을 수 있다. - 잡 컨트롤러는 동일한 잡에서 과도하게 실패한 이전 파드들로 인해 새로운 파드의 생성을 조절할 수 있다.
- 파드가 정상적으로(gracefully) 종료되면, 중지하는데 시간이 소요된다.
완료 모드
기능 상태:
Kubernetes v1.24 [stable]
완료 횟수가 고정적인 완료 횟수 즉, null이 아닌 .spec.completions 가 있는 잡은
.spec.completionMode 에 지정된 완료 모드를 가질 수 있다.
-
NonIndexed(기본값):.spec.completions가 성공적으로 완료된 파드가 있는 경우 작업이 완료된 것으로 간주된다. 즉, 각 파드 완료는 서로 상동하다(homologous). null.spec.completions가 있는 잡은 암시적으로NonIndexed이다. -
Indexed: 잡의 파드는 연결된 완료 인덱스를 0에서.spec.completions-1까지 가져온다. 이 인덱스는 다음의 세 가지 메카니즘으로 얻을 수 있다.- 파드 어노테이션
batch.kubernetes.io/job-completion-index. - 파드 호스트네임 중 일부(
$(job-name)-$(index)형태). 인덱스된(Indexed) 잡과 서비스를 결합하여 사용하고 있다면, 잡에 속한 파드는 DNS를 이용하여 서로를 디스커버 하기 위해 사전에 결정된 호스트네임을 사용할 수 있다. 이를 어떻게 설정하는지에 대해 궁금하다면, 파드 간 통신을 위한 잡를 확인한다. - 컨테이너화된 태스크의 경우, 환경 변수
JOB_COMPLETION_INDEX에 있다.
각 인덱스에 대해 성공적으로 완료된 파드가 하나 있으면 작업이 완료된 것으로 간주된다. 이 모드를 사용하는 방법에 대한 자세한 내용은 정적 작업 할당을 사용한 병렬 처리를 위해 인덱싱된 잡을 참고한다. 참고로, 드물기는 하지만, 동일한 인덱스에 대해 둘 이상의 파드를 시작할 수 있지만, 그 중 하나만 완료 횟수에 포함된다.
- 파드 어노테이션
파드와 컨테이너 장애 처리하기
파드내 컨테이너의 프로세스가 0이 아닌 종료 코드로 종료되었거나 컨테이너 메모리 제한을
초과해서 죽는 등의 여러가지 이유로 실패할 수 있다. 만약 이런 일이
발생하고 .spec.template.spec.restartPolicy = "OnFailure" 라면 파드는
노드에 그대로 유지되지만, 컨테이너는 다시 실행된다. 따라서 프로그램은 로컬에서 재시작될 때의
케이스를 다루거나 .spec.template.spec.restartPolicy = "Never" 로 지정해야 한다.
더 자세한 정보는 파드 라이프사이클의 restartPolicy 를 본다.
파드가 노드에서 내보내지는 경우(노드 업그레이드, 재부팅, 삭제 등) 또는 파드의 컨테이너가 실패
되고 .spec.template.spec.restartPolicy = "Never" 로 설정됨과 같은 여러 이유로
전체 파드가 실패할 수 있다. 파드가 실패하면 잡 컨트롤러는
새 파드를 시작한다. 이 의미는 애플리케이션이 새 파드에서 재시작될 때 이 케이스를 처리해야
한다는 점이다. 특히, 이전 실행으로 인한 임시파일, 잠금, 불완전한 출력 그리고 이와 유사한
것들을 처리해야 한다.
기본적으로 파드의 실패는 .spec.backoffLimit 제한값으로 계산되며,
자세한 내용은 파드 백오프(backoff) 실패 정책을 확인한다. 그러나,
잡의 파드 실패 정책을 설정하여 파드의 실패 수준을 조절하여 사용할 수도 있다.
.spec.parallelism = 1, .spec.completions = 1 그리고
.spec.template.spec.restartPolicy = "Never" 를 지정하더라도 같은 프로그램을
두 번 시작하는 경우가 있다는 점을 참고한다.
.spec.parallelism 그리고 .spec.completions 를 모두 1보다 크게 지정한다면 한번에
여러 개의 파드가 실행될 수 있다. 따라서 파드는 동시성에 대해서도 관대(tolerant)해야 한다.
만약 기능 게이트인
PodDisruptionConditions와 JobPodFailurePolicy가 모두 활성화되어 있고,
.spec.podFailurePolicy 필드가 설정되어 있다면, 잡 컨트롤러는 종료 중인
파드(.metadata.deletionTimestamp 필드가 설정된 파드)가 종료 상태(.status.phase 값이 Failed 혹은 Succeeded)가 될 때 까지
해당 파드를 실패로 간주하지 않는다. 그러나, 잡 컨트롤러는
파드가 명백히 종료되었다고 판단하면 곧바로 대체 파드를 생성한다.
파드가 한 번 종료되면, 잡 컨트롤러는 방금 종료된 파드를 고려하여
관련 작업에 대해 .backoffLimit과 .podFailurePolicy를 평가한다.
이러한 조건들이 하나라도 충족되지 않을 경우, 잡 컨트롤러는
종료 중인 파드가 추후 phase: "Succeded"로 종료된다고 할지라도,
해당 파드를 실패한 파드로 즉시 간주한다.
파드 백오프(backoff) 실패 정책
구성에 논리적 오류가 포함되어 있어서 몇 회의 재시도 이후에
잡이 실패되도록 만들어야 하는 경우가 있다.
이렇게 하려면 .spec.backoffLimit의 값에
재시도(잡을 실패로 처리하기 이전까지) 횟수를 설정한다. 백오프 제한은 기본적으로 6으로 설정되어 있다.
잡에 연계된 실패 상태 파드는 6분 내에서 지수적으로 증가하는
백-오프 지연(10초, 20초, 40초 ...)을 적용하여, 잡 컨트롤러에 의해 재생성된다.
재시도 횟수는 다음 두 가지 방법으로 계산된다.
.status.phase = "Failed"인 파드의 수.restartPolicy = "OnFailure"를 사용하는 경우,.status.phase가Pending이거나Running인 파드들이 가지고 있는 모든 컨테이너의 수.
계산 중 하나가 .spec.backoffLimit에 도달하면, 잡이
실패한 것으로 간주한다.
참고:
만약 잡에restartPolicy = "OnFailure" 가 있는 경우 잡 백오프 한계에
도달하면 잡을 실행 중인 파드가 종료된다. 이로 인해 잡 실행 파일의 디버깅이
더 어려워질 수 있다. 디버깅하거나 로깅 시스템을 사용해서 실패한 작업의 결과를 실수로 손실되지 않도록
하려면 restartPolicy = "Never" 로 설정하는 것을 권장한다.잡의 종료와 정리
잡이 완료되면 파드가 더 이상 생성되지도 않지만, 일반적으로는 삭제되지도 않는다.
이를 유지하면
완료된 파드의 로그를 계속 보며 에러, 경고 또는 다른 기타 진단 출력을 확인할 수 있다.
잡 오브젝트는 완료된 후에도 상태를 볼 수 있도록 남아 있다. 상태를 확인한 후 이전 잡을 삭제하는 것은 사용자의 몫이다.
kubectl 로 잡을 삭제할 수 있다 (예: kubectl delete jobs/pi 또는 kubectl delete -f ./job.yaml). kubectl 을 사용해서 잡을 삭제하면 생성된 모든 파드도 함께 삭제된다.
기본적으로 파드의 실패(restartPolicy=Never) 또는 컨테이너가 오류(restartPolicy=OnFailure)로 종료되지 않는 한, 잡은 중단되지 않고 실행되고
이때 위에서 설명했던 .spec.backoffLimit 까지 연기된다. .spec.backoffLimit 에 도달하면 잡은 실패로 표기되고 실행 중인 모든 파드는 종료된다.
잡을 종료하는 또 다른 방법은 유효 데드라인을 설정하는 것이다.
잡의 .spec.activeDeadlineSeconds 필드를 초 단위로 설정하면 된다.
activeDeadlineSeconds 는 생성된 파드의 수에 관계 없이 잡의 기간에 적용된다.
잡이 activeDeadlineSeconds 에 도달하면, 실행 중인 모든 파드가 종료되고 잡의 상태는 reason: DeadlineExceeded 와 함께 type: Failed 가 된다.
잡의 .spec.activeDeadlineSeconds 는 .spec.backoffLimit 보다 우선한다는 점을 참고한다. 따라서 하나 이상 실패한 파드를 재시도하는 잡은 backoffLimit 에 도달하지 않은 경우에도 activeDeadlineSeconds 에 지정된 시간 제한에 도달하면 추가 파드를 배포하지 않는다.
예시:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-timeout
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
잡의 사양과 잡의 파드 템플릿 사양에는 모두 activeDeadlineSeconds 필드가 있다는 점을 참고한다. 이 필드를 적절한 레벨로 설정해야 한다.
restartPolicy 는 잡 자체에 적용되는 것이 아니라 파드에 적용된다는 점을 유념한다. 잡의 상태가 type: Failed 이 되면, 잡의 자동 재시작은 없다.
즉, .spec.activeDeadlineSeconds 와 .spec.backoffLimit 로 활성화된 잡의 종료 메커니즘은 영구적인 잡의 실패를 유발하며 이를 해결하기 위해 수동 개입이 필요하다.
완료된 잡을 자동으로 정리
완료된 잡은 일반적으로 시스템에서 더 이상 필요로 하지 않는다. 시스템 내에 이를 유지한다면 API 서버에 부담이 된다. 만약 크론잡과 같은 상위 레벨 컨트롤러가 잡을 직접 관리하는 경우, 지정된 용량 기반 정리 정책에 따라 크론잡이 잡을 정리할 수 있다.
완료된 잡을 위한 TTL 메커니즘
기능 상태:
Kubernetes v1.23 [stable]
완료된 잡 (Complete 또는 Failed)을 자동으로 정리하는 또 다른 방법은
잡의 .spec.ttlSecondsAfterFinished 필드를 지정해서 완료된 리소스에 대해
TTL 컨트롤러에서
제공하는 TTL 메커니즘을 사용하는
것이다.
TTL 컨트롤러는 잡을 정리하면 잡을 계단식으로 삭제한다. 즉, 잡과 함께 파드와 같은 종속 오브젝트를 삭제한다. 잡을 삭제하면 finalizer와 같은 라이프사이클 보증이 보장되는 것을 참고한다.
예시:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
pi-with-ttl 잡은 완료 후 100 초 이후에
자동으로 삭제될 수 있다.
만약 필드를 0 으로 설정하면, 잡이 완료된 직후에 자동으로
삭제되도록 할 수 있다. 만약 필드를 설정하지 않으면, 이 잡이 완료된
후에 TTL 컨트롤러에 의해 정리되지 않는다.
참고:
ttlSecondsAfterFinished 필드를 설정하는 것을 권장하는데,
이는 관리되지 않는 잡(직접 생성한,
크론잡 등 다른 워크로드 API를 통해 간접적으로 생성하지 않은 잡)의
기본 삭제 정책이 orphanDependents(관리되지 않는 잡이 완전히 삭제되어도
해당 잡에 의해 생성된 파드를 남겨둠)이기 때문이다.
삭제된 잡의 파드가 실패하거나 완료된 뒤
컨트롤 플레인이 언젠가
가비지 콜렉션을 한다고 해도,
이렇게 남아 있는 파드는 클러스터의 성능을 저하시키거나
최악의 경우에는 이 성능 저하로 인해 클러스터가 중단될 수도 있다.
리밋 레인지(Limit Range)와 리소스 쿼터를 사용하여 특정 네임스페이스가 사용할 수 있는 자원량을 제한할 수 있다.
잡 패턴
잡 오브젝트를 사용해서 신뢰할 수 있는 파드의 병렬 실행을 지원할 수 있다. 잡 오브젝트는 과학 컴퓨팅(scientific computing)에서 일반적으로 사용되는 밀접하게 통신하는 병렬 프로세스를 지원하도록 설계되지 않았다. 잡 오브젝트는 독립적이지만 관련된 작업 항목 집합의 병렬 처리를 지원한다. 여기에는 전송할 이메일들, 렌더링할 프레임, 코드 변환이 필요한 파일, NoSQL 데이터베이스에서의 키 범위 스캔 등이 있다.
복잡한 시스템에는 여러 개의 다른 작업 항목 집합이 있을 수 있다. 여기서는 사용자와 함께 관리하려는 하나의 작업 항목 집합 — 배치 잡 을 고려하고 있다.
병렬 계산에는 몇몇 다른 패턴이 있으며 각각의 장단점이 있다. 트레이드오프는 다음과 같다.
- 각 작업 항목에 대한 하나의 잡 오브젝트 vs 모든 작업 항목에 대한 단일 잡 오브젝트. 후자는 작업 항목 수가 많은 경우 더 적합하다. 전자는 사용자와 시스템이 많은 수의 잡 오브젝트를 관리해야 하는 약간의 오버헤드를 만든다.
- 작업 항목과 동일한 개수의 파드 생성 vs 각 파드에서 다수의 작업 항목을 처리. 전자는 일반적으로 기존 코드와 컨테이너를 거의 수정할 필요가 없다. 후자는 이전 글 머리표(-)와 비슷한 이유로 많은 수의 작업 항목에 적합하다.
- 여러 접근 방식이 작업 큐를 사용한다. 이를 위해서는 큐 서비스를 실행하고, 작업 큐를 사용하도록 기존 프로그램이나 컨테이너를 수정해야 한다. 다른 접근 방식들은 기존에 컨테이너화된 애플리케이션에 보다 쉽게 적용할 수 있다.
여기에 트레이드오프가 요약되어 있고, 2열에서 4열까지가 위의 트레이드오프에 해당한다. 패턴 이름은 예시와 더 자세한 설명을 위한 링크이다.
| 패턴 | 단일 잡 오브젝트 | 작업 항목보다 파드가 적은가? | 수정되지 않은 앱을 사용하는가? |
|---|---|---|---|
| 작업 항목 당 파드가 있는 큐 | ✓ | 때때로 | |
| 가변 파드 수를 가진 큐 | ✓ | ✓ | |
| 정적 작업 할당을 사용한 인덱싱된 잡 | ✓ | ✓ | |
| 잡 템플릿 확장 | ✓ | ||
| 파드 간 통신을 위한 잡 | ✓ | 때때로 | 때때로 |
.spec.completions 로 완료를 지정할 때, 잡 컨트롤러에 의해 생성된 각 파드는
동일한 사양을 갖는다. 이 의미는
작업의 모든 파드는 동일한 명령 줄과 동일한 이미지,
동일한 볼륨, (거의) 동일한 환경 변수를 가진다는 점이다. 이 패턴은
파드가 다른 작업을 수행하도록 배열하는 다른 방법이다.
이 표는 각 패턴에 필요한 .spec.parallelism 그리고 .spec.completions 설정을 보여준다.
여기서 W 는 작업 항목의 수이다.
| 패턴 | .spec.completions |
.spec.parallelism |
|---|---|---|
| 작업 항목 당 파드가 있는 큐 | W | any |
| 가변 파드 수를 가진 큐 | null | any |
| 정적 작업 할당을 사용한 인덱싱된 잡 | W | any |
| 잡 템플릿 확장 | 1 | 1이어야 함 |
| 파드 간 통신을 위한 잡 | W | W |
고급 사용법
잡 일시 중지
기능 상태:
Kubernetes v1.24 [stable]
잡이 생성되면, 잡 컨트롤러는 잡의 요구 사항을 충족하기 위해 즉시 파드 생성을 시작하고 잡이 완료될 때까지 계속한다. 그러나, 잡의 실행을 일시적으로 중단하고 나중에 재개하거나, 잡을 중단 상태로 생성하고 언제 시작할지를 커스텀 컨트롤러가 나중에 결정하도록 하고 싶을 수도 있다.
잡을 일시 중지하려면, 잡의 .spec.suspend 필드를 true로
업데이트할 수 있다. 이후에, 다시 재개하려면, false로 업데이트한다.
.spec.suspend 로 설정된 잡을 생성하면 일시 중지된 상태로
생성된다.
잡이 일시 중지에서 재개되면, 해당 .status.startTime 필드가
현재 시간으로 재설정된다. 즉, 잡이 일시 중지 및 재개되면 .spec.activeDeadlineSeconds
타이머가 중지되고 재설정된다.
잡을 일시 중지하면, Completed 상태가 아닌 모든 실행중인 파드가 SIGTERM 시그널로 종료된다.
파드의 정상 종료 기간이 적용되며 사용자의 파드는 이 기간 동안에
이 시그널을 처리해야 한다. 나중에 진행 상황을 저장하거나
변경 사항을 취소하는 작업이 포함될 수 있다. 이 방법으로 종료된 파드는
잡의 completions 수에 포함되지 않는다.
일시 중지된 상태의 잡 정의 예시는 다음과 같다.
kubectl get job myjob -o yaml
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
suspend: true
parallelism: 1
completions: 5
template:
spec:
...
명령 줄에서 잡을 패치하여 잡 일시 중지를 전환할 수 있다.
활성화된 잡 일시 중지
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":true}}'
일시 중지된 잡 재개
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":false}}'
잡의 상태를 사용하여 잡이 일시 중지되었는지 또는 과거에 일시 중지되었는지 확인할 수 있다.
kubectl get jobs/myjob -o yaml
apiVersion: batch/v1
kind: Job
# .metadata and .spec omitted
status:
conditions:
- lastProbeTime: "2021-02-05T13:14:33Z"
lastTransitionTime: "2021-02-05T13:14:33Z"
status: "True"
type: Suspended
startTime: "2021-02-05T13:13:48Z"
"True" 상태인 "Suspended" 유형의 잡의 컨디션은 잡이
일시 중지되었음을 의미한다. 이 lastTransitionTime 필드는 잡이 일시 중지된
기간을 결정하는 데 사용할 수 있다. 해당 컨디션의 상태가 "False"이면, 잡이
이전에 일시 중지되었다가 현재 실행 중이다. 이러한 컨디션이
잡의 상태에 없으면, 잡이 중지되지 않은 것이다.
잡이 일시 중지 및 재개될 때에도 이벤트가 생성된다.
kubectl describe jobs/myjob
Name: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumed
마지막 4개의 이벤트, 특히 "Suspended" 및 "Resumed" 이벤트는
.spec.suspend 필드를 전환한 결과이다. 이 두 이벤트 사이의 시간동안
파드가 생성되지 않았지만, 잡이 재개되자마자 파드 생성이 다시
시작되었음을 알 수 있다.
가변적 스케줄링 지시
기능 상태:
Kubernetes v1.23 [beta]
병렬 잡에서 대부분의 경우 파드를 특정 제약 조건 하에서 실행하고 싶을 것이다. (예를 들면 동일 존에서 실행하거나, 또는 GPU 모델 x 또는 y를 사용하지만 둘을 혼합하지는 않는 등)
suspend 필드는 이러한 목적을 달성하기 위한 첫 번째 단계이다. 이 필드를 사용하면 커스텀 큐(queue) 컨트롤러가 잡이 언제 시작될지를 결정할 수 있다. 그러나, 잡이 재개된 이후에는, 커스텀 큐 컨트롤러는 잡의 파드가 실제로 어디에 할당되는지에 대해서는 영향을 주지 않는다.
이 기능을 이용하여 잡이 실행되기 전에 잡의 스케줄링 지시를 업데이트할 수 있으며, 이를 통해 커스텀 큐 컨트롤러가 파드 배치에 영향을 줌과 동시에 노드로의 파드 실제 할당 작업을 kube-scheduler로부터 경감시켜 줄 수 있도록 한다. 이는 이전에 재개된 적이 없는 중지된 잡에 대해서만 허용된다.
잡의 파드 템플릿 필드 중, 노드 어피니티(node affinity), 노드 셀렉터(node selector), 톨러레이션(toleration), 레이블(label), 어노테이션(annotation)은 업데이트가 가능하다.
자신의 파드 셀렉터를 지정하기
일반적으로 잡 오브젝트를 생성할 때 .spec.selector 를 지정하지 않는다.
시스템의 기본적인 로직은 잡이 생성될 때 이 필드를 추가한다.
이것은 다른 잡과 겹치지 않는 셀렉터 값을 선택한다.
그러나, 일부 케이스에서는 이 자동화된 설정 셀렉터를 재정의해야 할 수도 있다.
이를 위해 잡의 .spec.selector 를 설정할 수 있다.
이 것을 할 때는 매우 주의해야 한다. 만약 해당 잡의 파드에 고유하지
않고 연관이 없는 파드와 일치하는 레이블 셀렉터를 지정하면, 연관이 없는 잡의 파드가 삭제되거나,
해당 잡이 다른 파드가 완료한 것으로 수를 세거나, 하나 또는
양쪽 잡 모두 파드 생성이나 실행 완료를 거부할 수도 있다. 만약 고유하지 않은 셀렉터가
선택된 경우, 다른 컨트롤러(예: 레플리케이션 컨트롤러)와 해당 파드는
예측할 수 없는 방식으로 작동할 수 있다. 쿠버네티스는 당신이 .spec.selector 를 지정할 때
발생하는 실수를 막을 수 없을 것이다.
다음은 이 기능을 사용하려는 경우의 예시이다.
잡 old 가 이미 실행 중이다. 기존 파드가 계속
실행되기를 원하지만, 잡이 생성한 나머지 파드에는 다른
파드 템플릿을 사용하고 잡으로 하여금 새 이름을 부여하기를 원한다.
그러나 관련된 필드들은 업데이트가 불가능하기 때문에 잡을 업데이트할 수 없다.
따라서 kubectl delete jobs/old --cascade=orphan 명령을 사용해서
잡 old 를 삭제하지만, 파드를 실행 상태로 둔다.
삭제하기 전에 어떤 셀렉터를 사용하는지 기록한다.
kubectl get job old -o yaml
출력 결과는 다음과 같다.
kind: Job
metadata:
name: old
...
spec:
selector:
matchLabels:
controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
그런 이후에 이름이 new 인 새 잡을 생성하고, 동일한 셀렉터를 명시적으로 지정한다.
기존 파드에는 controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002
레이블이 있기에 잡 new 에 의해서도 제어된다.
시스템이 일반적으로 자동 생성하는 셀렉터를 사용하지 않도록 하기 위해
새 잡에서 manualSelector: true 를 지정해야 한다.
kind: Job
metadata:
name: new
...
spec:
manualSelector: true
selector:
matchLabels:
controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
새 잡 자체는 a8f3d00d-c6d2-11e5-9f87-42010af00002 와 다른 uid 를 가지게 될 것이다.
manualSelector: true 를 설정하면 시스템에게 사용자가 무엇을 하는지 알고 있으며
이런 불일치를 허용한다고 알릴 수 있다.
파드 실패 정책
기능 상태:
Kubernetes v1.26 [beta]
참고:
잡(Job)에 대한 파드 실패 정책은JobPodFailurePolicy 기능 게이트가
클러스터에서 활성화됐을 경우에만 구성할 수 있다. 추가적으로,
파드 장애 정책의 파드 중단 조건 (참조:
파드 중단 조건)을
감지하고 처리할 수 있도록 PodDisruptionConditions 기능 게이트를 활성화하는 것을 권장한다. 두 기능 게이트 모두
쿠버네티스 1.31에서 사용할 수 있다..spec.podFailurePolicy 필드로 정의되는 파드 실패 정책은, 클러스터가
컨테이너 종료 코드와 파드 상태를 기반으로 파드의 실패를
처리하도록 활성화한다.
어떤 상황에서는, 파드의 실패를 처리할 때 잡(Job)의 .spec.backoffLimit을 기반으로 하는
파드 백오프(backoff) 실패 정책에서
제공하는 제어보다 더 나은 제어를 원할 수 있다. 다음은 사용 사례의 몇 가지 예시다.
- 불필요한 파드 재시작을 방지하여 워크로드 실행 비용을 최적화하려면, 파드 중 하나가 소프트웨어 버그를 나타내는 종료 코드와 함께 실패하는 즉시 잡을 종료할 수 있다.
- 중단이 있더라도 잡이 완료되도록 하려면,
중단(예: 선점(preemption),
API를 이용한 축출(API-initiated Eviction)
또는 축출 기반 테인트(Taints))으로 인한
파드 실패를 무시하여
.spec.backoffLimit재시도 한도에 포함되지 않도록 할 수 있다.
위의 사용 사례를 충족하기 위해
.spec.podFailurePolicy 필드에 파드 실패 정책을 구성할 수 있다.
이 정책은 컨테이너 종료 코드 및 파드 상태를 기반으로 파드 실패를 처리할 수 있다.
다음은 podFailurePolicy를 정의하는 잡의 매니페스트이다.
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-example
spec:
completions: 12
parallelism: 3
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"] # FailJob 액션을 트리거시키는 버그를 만들어내는 예제 명령어
args:
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main # 선택 사항
operator: In # [In / NotIn] 중 하나
values: [42]
- action: Ignore # [Ignore, FailJob, Count] 중 하나
onPodConditions:
- type: DisruptionTarget # 파드의 중단을 나타냄
위 예시에서, 파드 실패 정책의 첫 번째 규칙은 main 컨테이너가 42 종료코드와
함께 실패하면 잡도 실패로 표시되는 것으로
지정한다. 다음은 구체적으로 main 컨테이너에 대한 규칙이다.
- 종료 코드 0은 컨테이너가 성공했음을 의미한다.
- 종료 코드 42는 전체 잡이 실패했음을 의미한다.
- 다른 모든 종료 코드는 컨테이너 및 전체 파드가 실패했음을
나타낸다. 재시작 횟수인
backoffLimit까지 파드가 다시 생성된다. 만약backoffLimit에 도달하면 전체 잡이 실패한다.
참고:
파드 템플릿이restartPolicy: Never로 지정되었기 때문에,
kubelet은 특정 파드에서 main 컨테이너를 재시작하지 않는다.DisruptionTarget 컨디션을 갖는 실패한 파드에 대해
Ignore 동작을 하도록 명시하고 있는 파드 실패 정책의 두 번째 규칙으로 인해,
.spec.backoffLimit 재시도 한도 계산 시 파드 중단(disruption)은 횟수에서 제외된다.
참고:
파드 실패 정책 또는 파드 백오프 실패 정책에 의해 잡이 실패하고, 잡이 여러 파드를 실행중이면, 쿠버네티스는 아직 보류(Pending) 또는 실행(Running) 중인 해당 잡의 모든 파드를 종료한다.다음은 API의 몇 가지 요구 사항 및 의미이다.
- 잡에
.spec.podFailurePolicy필드를 사용하려면,.spec.restartPolicy가Never로 설정된 잡의 파드 템플릿 또한 정의해야 한다. spec.podFailurePolicy.rules에 기재한 파드 실패 정책 규칙은 기재한 순서대로 평가된다. 파드 실패 정책 규칙이 파드 실패와 매치되면 나머지 규칙은 무시된다. 파드 실패와 매치되는 파드 실패 정책 규칙이 없으면 기본 처리 방식이 적용된다.spec.podFailurePolicy.rules[*].containerName에 컨테이너 이름을 지정하여 파드 실패 규칙을 특정 컨테이너에게만 제한할 수 있다. 컨테이너 이름을 지정하지 않으면 파드 실패 규칙은 모든 컨테이너에 적용된다. 컨테이너 이름을 지정한 경우, 이는 파드 템플릿의 컨테이너 또는initContainer이름 중 하나와 일치해야 한다.- 파드 실패 정책이
spec.podFailurePolicy.rules[*].action과 일치할 때 취할 동작을 지정할 수 있다. 사용 가능한 값은 다음과 같다.FailJob: 파드의 잡을Failed로 표시하고 실행 중인 모든 파드를 종료해야 함을 나타낸다.Ignore:.spec.backoffLimit에 대한 카운터가 증가하지 않아야 하고 대체 파드가 생성되어야 함을 나타낸다.Count: 파드가 기본 방식으로 처리되어야 함을 나타낸다..spec.backoffLimit에 대한 카운터가 증가해야 한다.
종료자(finalizers)를 이용한 잡 추적
기능 상태:
Kubernetes v1.26 [stable]
참고:
컨트롤 플레인을 1.26으로 업그레이드하더라도, 기능 게이트JobTrackingWithFinalizers가 비활성화되어 있을 때 생성된 잡이라면,
컨트롤 플레인은 종료자를 사용하는 잡을 추적하지 않는다.컨트롤 플레인은 잡에 속한 파드들을 계속 추적하고,
API 서버로부터 제거된 파드가 있는지에 대해 알려준다. 이를 위해 잡 컨트롤러는
batch.kubernetes.io/job-tracking 종료자를 갖는 파드를 생성한다.
컨트롤러는 파드가 잡 상태로 처리된 이후에만 종료자를 제거하여,
다른 컨트롤러나 사용자가 파드를 제거할 수 있도록 한다.
쿠버네티스를 1.26으로 업그레이드하기 전이나, 기능 게이트
JobTrackingWithFinalizers를 활성화시키기 전에 생성한 잡은 파드 종료자를 사용하지 않고
추적된다.
잡 컨트롤러는
클러스터에 존재하는 파드들에 대해서만 succeded와 failed 파드들에 대한 상태 카운터를 갱신한다.
만약 파드가 클러스터에서 제거된다면,
컨트롤 플레인은 잡의 진행 상황을 제대로 추적하지 못할 수 있다.
잡이 batch.kubernetes.io/job-tracking 어노테이션을 가지고 있는지 확인함으로써
컨트롤 플레인이 파드 종료자를 사용하여 잡을 추적하고 있는지 알 수 있다.
따라서 잡으로부터 이 어노테이션을 수동으로 추가하거나 제거해서는 안 된다.
그 대신, 파드 종료자를 사용하여
추적이 가능한 잡을 재생성하면 된다.
대안
베어(Bare) 파드
파드가 실행 중인 노드가 재부팅되거나 실패하면 파드가 종료되고 재시작되지 않는다. 그러나 잡은 종료된 항목을 대체하기 위해 새 파드를 생성한다. 따라서, 애플리케이션에 단일 파드만 필요한 경우에도 베어 파드 대신 잡을 사용하는 것을 권장한다.
레플리케이션 컨트롤러
잡은 레플리케이션 컨트롤러를 보완한다. 레플리케이션 컨트롤러는 종료하지 않을 파드(예: 웹 서버)를 관리하고, 잡은 종료될 것으로 예상되는 파드(예: 배치 작업)를 관리한다.
파드 라이프사이클에서 설명한 것처럼, 잡 은 오직
OnFailure 또는 Never 와 같은 RestartPolicy 를 사용하는 파드에만 적절하다.
(참고: RestartPolicy 가 설정되지 않은 경우에는 기본값은 Always 이다.)
단일 잡으로 컨트롤러 파드 시작
또 다른 패턴은 단일 잡이 파드를 생성한 후 다른 파드들을 생성해서 해당 파드들에 일종의 사용자 정의 컨트롤러 역할을 하는 것이다. 이를 통해 최대한의 유연성을 얻을 수 있지만, 시작하기에는 다소 복잡할 수 있으며 쿠버네티스와의 통합성이 낮아진다.
이 패턴의 한 예시는 파드를 시작하는 잡이다. 파드는 스크립트를 실행해서 스파크(Spark) 마스터 컨트롤러 (스파크 예시를 본다)를 시작하고, 스파크 드라이버를 실행한 다음, 정리한다.
이 접근 방식의 장점은 전체 프로세스가 잡 오브젝트의 완료를 보장하면서도, 파드 생성과 작업 할당 방법을 완전히 제어하고 유지한다는 것이다.
다음 내용
- 파드에 대해 배운다.
- 다른 방식으로 잡을 구동하는 방법에 대해서 읽는다.
- 작업 대기열을 사용한 거친 병렬 처리
- 작업 대기열을 사용한 정밀 병렬 처리
- 병렬 처리를 위한 정적 작업 할당으로 인덱스된 잡 사용
- 템플릿 기반으로 복수의 잡 생성: 확장을 사용한 병렬 처리
- 완료된 잡을 자동으로 정리 섹션 내 링크를 따라서 클러스터가 완료되거나 실패된 태스크를 어떻게 정리하는지에 대해 더 배운다.
Job은 쿠버네티스 REST API의 일부이다. 잡 API에 대해 이해하기 위해 Job 오브젝트 정의를 읽는다.- 스케줄을 기반으로 실행되는 일련의 잡을 정의하는데 사용할 수 있고, 유닉스 툴
cron과 유사한CronJob에 대해 읽는다. - 단계별로 구성된 예제를 통해,
podFailurePolicy를 사용하여 재시도 가능 및 재시도 불가능 파드의 실패 처리를 하기위한 구성 방법을 연습한다.
5.2.6 - 완료된 잡 자동 정리
기능 상태:
Kubernetes v1.23 [stable]
완료-이후-TTL(TTL-after-finished) 컨트롤러는 실행이 완료된 리소스 오브젝트의 수명을 제한하는 TTL (time to live) 메커니즘을 제공한다. TTL 컨트롤러는 잡만을 제어한다.
완료-이후-TTL 컨트롤러
완료-이후-TTL 컨트롤러는 잡만을 지원한다. 클러스터 운영자는
예시
와 같이 .spec.ttlSecondsAfterFinished 필드를 명시하여
완료된 잡(완료 또는 실패)을 자동으로 정리하기 위해 이 기능을 사용할 수 있다.
잡의 작업이 완료된 TTL 초(sec) 후 (다른 말로는, TTL이 만료되었을 때),
완료-이후-TTL 컨트롤러는 해당 잡이 정리될 수 있다고 가정한다.
완료-이후-TTL 컨트롤러가 잡을 정리할때 잡을 연속적으로 삭제한다. 이는
의존하는 오브젝트도 해당 잡과 함께 삭제되는 것을 의미한다. 잡이 삭제되면 완료자(finalizers)와
같은 라이프 사이클 보증이 적용 된다.
TTL 초(sec)는 언제든지 설정이 가능하다. 여기에 잡 필드 중
.spec.ttlSecondsAfterFinished 를 설정하는 몇 가지 예시가 있다.
- 작업이 완료된 다음, 일정 시간 후에 자동으로 잡이 정리될 수 있도록 잡 메니페스트에 이 필드를 지정한다.
- 이미 완료된 기존 잡에 이 새 기능을 적용하기 위해서 이 필드를 설정한다.
- 어드미션 웹후크 변형 을 사용해서 잡 생성시 이 필드를 동적으로 설정 한다. 클러스터 관리자는 이것을 사용해서 완료된 잡에 대해 TTL 정책을 적용할 수 있다.
- 잡이 완료된 이후에 어드미션 웹후크 변형 을 사용해서 이 필드를 동적으로 설정하고, 잡의 상태, 레이블 등에 따라 다른 TTL 값을 선택한다.
경고
TTL 초(sec) 업데이트
TTL 기간은, 예를 들어 잡의 .spec.ttlSecondsAfterFinished 필드는
잡을 생성하거나 완료한 후에 수정할 수 있다. 그러나, 잡을
삭제할 수 있게 되면(TTL이 만료된 경우) 시스템은 TTL을 연장하기
위한 업데이트가 성공적인 API 응답을 리턴하더라도
작업이 유지되도록 보장하지 않는다.
시간 차이(Skew)
완료-이후-TTL 컨트롤러는 쿠버네티스 잡에 저장된 타임스탬프를 사용해서 TTL의 만료 여부를 결정하기 때문에, 이 기능은 클러스터 간의 시간 차이에 민감하며, 시간 차이에 의해서 완료-이후-TTL 컨트롤러가 잘못된 시간에 잡 오브젝트를 정리하게 될 수 있다.
시계가 항상 정확한 것은 아니지만, 그 차이는 아주 작아야 한다. 0이 아닌 TTL을 설정할때는 이 위험에 대해 유의해야 한다.
다음 내용
5.2.7 - 크론잡
기능 상태:
Kubernetes v1.21 [stable]
크론잡은 반복 일정에 따라 잡을 만든다.
하나의 크론잡 오브젝트는 크론탭 (크론 테이블) 파일의 한 줄과 같다. 크론잡은 잡을 크론 형식으로 쓰여진 주어진 일정에 따라 주기적으로 동작시킨다.
주의:
모든 크론잡 일정: 시간은
kube-controller-manager의 시간대를 기준으로 한다.
컨트롤 플레인이 파드 또는 베어 컨테이너에서 kube-controller-manager를 실행하는 경우, kube-controller-manager 컨테이너에 설정된 시간대는 크론잡 컨트롤러가 사용하는 시간대로 결정한다.
주의:
v1 CronJob API은 위에서 설명한 타임존 설정을 공식적으로 지원하지는 않는다.
CRON_TZ 또는 TZ 와 같은 변수를 설정하는 것은 쿠버네티스 프로젝트에서 공식적으로 지원하지는 않는다.
CRON_TZ 또는 TZ 와 같은 변수를 설정하는 것은
크론탭을 파싱하고 다음 잡 생성 시간을 계산하는 내부 라이브러리의 구현 상세사항이다.
프로덕션 클러스터에서는 사용을 권장하지 않는다.
크론잡 리소스에 대한 매니페스트를 생성할 때에는 제공하는 이름이 유효한 DNS 서브도메인 이름이어야 한다. 이름은 52자 이하여야 한다. 이는 크론잡 컨트롤러는 제공된 잡 이름에 11자를 자동으로 추가하고, 작업 이름의 최대 길이는 63자라는 제약 조건이 있기 때문이다.
크론잡
크론잡은 백업, 리포트 생성 등의 정기적 작업을 수행하기 위해 사용된다. 각 작업은 무기한 반복되도록 구성해야 한다(예: 1일/1주/1달마다 1회). 작업을 시작해야 하는 해당 간격 내 특정 시점을 정의할 수 있다.
예시
이 크론잡 매니페스트 예제는 현재 시간과 hello 메시지를 1분마다 출력한다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
(크론잡으로 자동화된 작업 실행하기는 이 예시를 더 자세히 설명한다.)
크론 스케줄 문법
# ┌───────────── 분 (0 - 59)
# │ ┌───────────── 시 (0 - 23)
# │ │ ┌───────────── 일 (1 - 31)
# │ │ │ ┌───────────── 월 (1 - 12)
# │ │ │ │ ┌───────────── 요일 (0 - 6) (일요일부터 토요일까지;
# │ │ │ │ │ 특정 시스템에서는 7도 일요일)
# │ │ │ │ │ 또는 sun, mon, tue, wed, thu, fri, sat
# │ │ │ │ │
# * * * * *
| 항목 | 설명 | 상응 표현 |
|---|---|---|
| @yearly (or @annually) | 매년 1월 1일 자정에 실행 | 0 0 1 1 * |
| @monthly | 매월 1일 자정에 실행 | 0 0 1 * * |
| @weekly | 매주 일요일 자정에 실행 | 0 0 * * 0 |
| @daily (or @midnight) | 매일 자정에 실행 | 0 0 * * * |
| @hourly | 매시 0분에 시작 | 0 * * * * |
예를 들면, 다음은 해당 작업이 매주 금요일 자정에 시작되어야 하고, 매월 13일 자정에도 시작되어야 한다는 뜻이다.
0 0 13 * 5
크론잡 스케줄 표현을 생성하기 위해서 crontab.guru와 같은 웹 도구를 사용할 수도 있다.
타임 존
크론잡에 타임 존이 명시되어 있지 않으면, kube-controller-manager는 로컬 타임 존을 기준으로 스케줄을 해석한다.
기능 상태:
Kubernetes v1.25 [beta]
CronJobTimeZone 기능 게이트를 활성화하면,
크론잡에 대해 타임 존을 명시할 수 있다(기능 게이트를 활성화하지 않거나,
타임 존에 대한 실험적 지원을 제공하지 않는 쿠버네티스 버전을 사용 중인 경우,
클러스터의 모든 크론잡은 타임 존이 명시되지 않은 것으로 동작한다).
이 기능을 활성화하면, spec.timeZone을 유효한 타임 존으로 지정할 수 있다.
예를 들어, spec.timeZone: "Etc/UTC"와 같이 설정하면 쿠버네티스는 협정 세계시를 기준으로 스케줄을 해석한다.
Go 표준 라이브러리의 타임 존 데이터베이스가 바이너리로 인클루드되며, 시스템에서 외부 데이터베이스를 사용할 수 없을 때 폴백(fallback)으로 사용된다.
크론잡의 한계
크론잡은 일정의 실행시간 마다 약 한 번의 잡 오브젝트를 생성한다. "약" 이라고 하는 이유는 특정 환경에서는 두 개의 잡이 만들어지거나, 잡이 생성되지 않기도 하기 때문이다. 보통 이렇게 하지 않도록 해야겠지만, 완벽히 그럴 수는 없다. 따라서 잡은 멱등원 이 된다.
만약 startingDeadlineSeconds 가 큰 값으로 설정되거나, 설정되지 않고(디폴트 값),
concurrencyPolicy 가 Allow 로 설정될 경우, 잡은 항상 적어도 한 번은
실행될 것이다.
주의:
startingDeadlineSeconds 가 10초 미만의 값으로 설정되면, 크론잡이 스케줄되지 않을 수 있다. 이는 크론잡 컨트롤러가 10초마다 항목을 확인하기 때문이다.모든 크론잡에 대해 크론잡 컨트롤러 는 마지막 일정부터 지금까지 얼마나 많은 일정이 누락되었는지 확인한다. 만약 100회 이상의 일정이 누락되었다면, 잡을 실행하지 않고 아래와 같은 에러 로그를 남긴다.
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
중요한 것은 만약 startingDeadlineSeconds 필드가 설정이 되면(nil 이 아닌 값으로), 컨트롤러는 마지막 일정부터 지금까지 대신 startingDeadlineSeconds 값에서 몇 개의 잡이 누락되었는지 카운팅한다. 예를 들면, startingDeadlineSeconds 가 200 이면, 컨트롤러는 최근 200초 내 몇 개의 잡이 누락되었는지 카운팅한다.
크론잡은 정해진 시간에 생성되는데 실패하면 누락(missed)된 것으로 집계된다. 예를 들어 concurrencyPolicy가 Forbid 로 설정되어 있고 이전 크론잡이 여전히 실행 중인 상태라면, 크론잡은 일정에 따라 시도되었다가 생성을 실패하고 누락된 것으로 집계될 것이다.
즉, 크론잡이 08:30:00 에 시작하여 매 분마다 새로운 잡을 실행하도록 설정이 되었고,
startingDeadlineSeconds 값이 설정되어 있지 않는다고 가정해보자. 만약 크론잡 컨트롤러가
08:29:00 부터 10:21:00 까지 고장이 나면, 일정을 놓친 작업 수가 100개를 초과하여 잡이 실행되지 않을 것이다.
이 개념을 더 자세히 설명하자면, 크론잡이 08:30:00 부터 매 분 실행되는 일정으로 설정되고,
startingDeadlineSeconds 이 200이라고 가정한다. 크론잡 컨트롤러가
전의 예시와 같이 고장났다고 하면 (08:29:00 부터 10:21:00 까지), 잡은 10:22:00 부터 시작될 것이다. 이 경우, 컨트롤러가 마지막 일정부터 지금까지가 아니라, 최근 200초 안에 얼마나 놓쳤는지 체크하기 때문이다. (여기서는 3번 놓쳤다고 체크함)
크론잡은 오직 그 일정에 맞는 잡 생성에 책임이 있고, 잡은 그 잡이 대표하는 파드 관리에 책임이 있다.
컨트롤러 버전
쿠버네티스 v1.21부터 크론잡 컨트롤러의 두 번째 버전이
기본 구현이다. 기본 크론잡 컨트롤러를 비활성화하고
대신 원래 크론잡 컨트롤러를 사용하려면, CronJobControllerV2
기능 게이트
플래그를 kube-controller-manager에 전달하고,
이 플래그를 false 로 설정한다. 예를 들면, 다음과 같다.
--feature-gates="CronJobControllerV2=false"
다음 내용
- 크론잡이 의존하고 있는 파드와 잡 두 개념에 대해 배운다.
- 크론잡
.spec.schedule필드의 형식에 대해서 읽는다. - 크론잡을 생성하고 다루기 위한 지침 및 크론잡 매니페스트의 예제로 크론잡으로 자동화된 작업 실행를 읽는다.
- 실패했거나 완료된 잡을 자동으로 정리하도록 하려면, 완료된 잡을 자동으로 정리를 확인한다.
CronJob은 쿠버네티스 REST API의 일부이다. CronJob 오브젝트 정의를 읽고 쿠버네티스 크론잡 API에 대해 이해한다.
5.2.8 - 레플리케이션 컨트롤러
레플리케이션컨트롤러 는 언제든지 지정된 수의 파드 레플리카가 실행 중임을 보장한다. 다시 말하면, 레플리케이션 컨트롤러는 파드 또는 동일 종류의 파드의 셋이 항상 기동되고 사용 가능한지 확인한다.
레플리케이션 컨트롤러의 동작방식
파드가 너무 많으면 레플리케이션 컨트롤러가 추가적인 파드를 제거한다. 너무 적으면 레플리케이션 컨트롤러는 더 많은 파드를 시작한다. 수동으로 생성된 파드와 달리 레플리케이션 컨트롤러가 유지 관리하는 파드는 실패하거나 삭제되거나 종료되는 경우 자동으로 교체된다. 예를 들어, 커널 업그레이드와 같이 파괴적인 유지 보수 작업을 하고 난 이후의 노드에서 파드가 다시 생성된다. 따라서 애플리케이션에 하나의 파드만 필요한 경우에도 레플리케이션 컨트롤러를 사용해야 한다. 레플리케이션 컨트롤러는 프로세스 감시자(supervisor)와 유사하지만 단일 노드에서 개별 프로세스를 감시하는 대신 레플리케이션 컨트롤러는 여러 노드에서 여러 파드를 감시한다.
레플리케이션 컨트롤러는 디스커션에서 종종 "rc"로 축약되며 kubectl 명령에서 숏컷으로 사용된다.
간단한 경우는 하나의 레플리케이션 컨트롤러 오브젝트를 생성하여 한 개의 파드 인스턴스를 영구히 안정적으로 실행하는 것이다. 보다 복잡한 사용 사례는 웹 서버와 같이 복제된 서비스의 동일한 레플리카를 여러 개 실행하는 것이다.
레플리케이션 컨트롤러 예제 실행
레플리케이션 컨트롤러 예제의 config는 nginx 웹서버의 복사본 세 개를 실행한다.
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
예제 파일을 다운로드한 후 다음 명령을 실행하여 예제 작업을 실행하라.
kubectl apply -f https://k8s.io/examples/controllers/replication.yaml
출력 결과는 다음과 같다.
replicationcontroller/nginx created
다음 명령을 사용하여 레플리케이션 컨트롤러의 상태를 확인하자.
kubectl describe replicationcontrollers/nginx
출력 결과는 다음과 같다.
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
이제 세 개의 파드가 생성되었으나 아직 이미지가 풀(pull)되지 않아서 어떤 파드도 시작되지 않았다. 조금 지난 후에 같은 명령이 다음과 같이 보일 것이다.
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
레플리케이션 컨트롤러에 속한 모든 파드를 머신이 읽을 수 있는 형식으로 나열하기 위해 다음과 같은 명령을 사용할 수 있다.
pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $pods
출력 결과는 다음과 같다.
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
여기서 셀렉터는 레플리케이션컨트롤러(kubectl describe 의 출력에서 보인)의 셀렉터와 같고,
다른 형식의 파일인 replication.yaml 의 것과 동일하다. --output=jsonpath 은
반환된 목록의 각 파드의 이름을 출력하도록 하는 옵션이다.
레플리케이션 컨트롤러의 Spec 작성
다른 모든 쿠버네티스 컨피그와 마찬가지로 레플리케이션 컨트롤러는 apiVersion, kind, metadata 와 같은 필드가 필요하다.
레플리케이션 컨트롤러 오브젝트의 이름은 유효한
DNS 서브도메인 이름이어야 한다.
환경설정 파일의 동작에 관련된 일반적인 정보는 쿠버네티스 오브젝트 관리를 참고한다.
레플리케이션 컨트롤러는 또한 .spec section도 필요하다.
파드 템플릿
.spec.template 는 오직 .spec 필드에서 요구되는 것이다.
.spec.template 는 파드 템플릿이다. 정확하게 파드 스키마와 동일하나, 중첩되어 있고 apiVersion 혹은 kind를 갖지 않는다.
파드에 필요한 필드 외에도 레플리케이션 컨트롤러의 파드 템플릿은 적절한 레이블과 적절한 재시작 정책을 지정해야 한다. 레이블의 경우 다른 컨트롤러와 중첩되지 않도록 하라. 파드 셀렉터를 참조하라.
오직 Always 와 동일한 .spec.template.spec.restartPolicy만 허용되며, 특별히 지정되지 않으면 기본값이다.
로컬 컨테이너의 재시작의 경우, 레플리케이션 컨트롤러는 노드의 에이전트에게 위임한다. 예를 들어 Kubelet이다.
레플리케이션 컨트롤러에서 레이블
레플리케이션 컨트롤러 자체는 레이블 (.metadata.labels) 을 가질 수 있다. 일반적으로 이것을 .spec.template.metadata.labels 와 동일하게 설정할 것이다. .metadata.labels 가 지정되어 있지 않은 경우,
기본은 .spec.template.metadata.labels 이다. 하지만 레이블은
다른 것이 허용되며, .metadata.labels 라벨은 레플리케이션 컨트롤러의
동작에 영향을 미치지 않는다.
파드 셀렉터
.spec.selector 필드는 레이블 셀렉터이다. 레플리케이션 컨트롤러는 셀렉터와 일치하는 레이블이 있는 모든 파드를 관리한다.
직접 생성하거나 삭제된 파드와 다른 사람이나 프로세스가 생성하거나
삭제한 파드를 구분하지 않는다. 이렇게 하면 실행중인 파드에 영향을 주지 않고
레플리케이션 컨트롤러를 교체할 수 있다.
지정된 경우 .spec.template.metadata.labels 은
.spec.selector 와 동일해야 하며 그렇지 않으면 API에 의해 거부된다. .spec.selector 가 지정되지 않은 경우 기본값은
.spec.template.metadata.labels 이다.
또한 일반적으로 이 셀렉터와 레이블이 일치하는 파드를 직접 다른 레플리케이션 컨트롤러 또는 잡과 같은 다른 컨트롤러로 작성해서는 안된다. 그렇게 하면 레플리케이션 컨트롤러는 다른 파드를 생성했다고 생각한다. 쿠버네티스는 이런 작업을 중단해 주지 않는다.
중첩된 셀렉터들을 갖는 다수의 컨트롤러들을 종료하게 되면, 삭제된 것들은 스스로 관리를 해야 한다 (아래를 참조).
다수의 레플리카
.spec.replicas 를 동시에 실행하고 싶은 파드의 수로 설정함으로써
실행할 파드의 수를 지정할 수 있다. 레플리카가 증가 또는 감소한 경우 또는
파드가 정상적으로 종료되고 교체가 일찍 시작되는 경우라면
언제든지 실행중인 수가 더 높거나 낮을 수 있다.
.spec.replicas 를 지정하지 않으면 기본값은 1이다.
레플리케이션 컨트롤러 사용하기
레플리케이션 컨트롤러와 레플리케이션 컨트롤러의 파드 삭제
레플리케이션 컨트롤러와 레플리케이션의 모든 파드를 삭제하려면 kubectl delete 를 사용하라.
Kubectl은 레플리케이션 컨트롤러를 0으로 스케일하고 레플리케이션 컨트롤러 자체를
삭제하기 전에 각 파드를 삭제하기를 기다린다. 이 kubectl 명령이 인터럽트되면 다시 시작할 수 있다.
REST API나 클라이언트 라이브러리를 사용하는 경우 명시적으로 단계를 수행해야 한다(레플리카를 0으로 스케일하고 파드의 삭제를 기다린 이후, 레플리케이션 컨트롤러를 삭제).
레플리케이션 컨트롤러만 삭제
해당 파드에 영향을 주지 않고 레플리케이션 컨트롤러를 삭제할 수 있다.
kubectl을 사용하여, kubectl delete에 옵션으로 --cascade=orphan을 지정하라.
REST API나 클라이언트 라이브러리를 사용하는 경우 레플리케이션 컨트롤러 오브젝트를 삭제하라.
원본이 삭제되면 대체할 새로운 레플리케이션 컨트롤러를 생성하여 교체할 수 있다. 오래된 파드와 새로운 파드의 .spec.selector 가 동일하다면,
새로운 레플리케이션 컨트롤러는 오래된 파드를 채택할 것이다. 그러나 기존 파드를
새로운 파드 템플릿과 일치시키려는 노력은 하지 않을 것이다.
새로운 spec에 대한 파드를 제어된 방법으로 업데이트하려면 롤링 업데이트를 사용하라.
레플리케이션 컨트롤러에서 파드 격리
파드는 레이블을 변경하여 레플리케이션 컨트롤러의 대상 셋에서 제거될 수 있다. 이 기술은 디버깅과 데이터 복구를 위해 서비스에서 파드를 제거하는 데 사용될 수 있다. 이 방법으로 제거된 파드는 자동으로 교체된다 (레플리카 수가 변경되지 않는다고 가정).
일반적인 사용법 패턴
다시 스케줄하기
위에서 언급했듯이, 실행하려는 파드가 한 개 혹은 1000개이든 관계없이 레플리케이션 컨트롤러는 노드 실패 또는 파드 종료시 지정된 수의 파드가 존재하도록 보장한다 (예 : 다른 제어 에이전트에 의한 동작으로 인해).
스케일링
레플리케이션컨트롤러는 replicas 필드를 업데이트하여, 수동으로 또는 오토 스케일링 제어 에이전트를 통해, 레플리카의 수를 늘리거나 줄일 수 있다.
롤링 업데이트
레플리케이션 컨트롤러는 파드를 하나씩 교체함으로써 서비스에 대한 롤링 업데이트를 쉽게 하도록 설계되었다.
#1353에서 설명한 것처럼, 권장되는 접근법은 1 개의 레플리카를 가진 새로운 레플리케이션 컨트롤러를 생성하고 새로운 (+1) 컨트롤러 및 이전 (-1) 컨트롤러를 차례대로 스케일한 후 0개의 레플리카가 되면 이전 컨트롤러를 삭제하는 것이다. 예상치 못한 오류와 상관없이 파드 세트를 예측 가능하게 업데이트한다.
이상적으로 롤링 업데이트 컨트롤러는 애플리케이션 준비 상태를 고려하며 주어진 시간에 충분한 수의 파드가 생산적으로 제공되도록 보장할 것이다.
두 레플리케이션 컨트롤러는 일반적으로 롤링 업데이트를 동기화 하는 이미지 업데이트이기 때문에 파드의 기본 컨테이너 이미지 태그와 같이 적어도 하나의 차별화된 레이블로 파드를 생성해야 한다.
다수의 릴리스 트랙
롤링 업데이트가 진행되는 동안 다수의 애플리케이션 릴리스를 실행하는 것 외에도 다수의 릴리스 트랙을 사용하여 장기간에 걸쳐 또는 연속적으로 실행하는 것이 일반적이다. 트랙은 레이블 별로 구분된다.
예를 들어, 서비스는 tier in (frontend), environment in (prod) 이 있는 모든 파드를 대상으로 할 수 있다. 이제 이 계층을 구성하는 10 개의 복제된 파드가 있다고 가정해 보자. 하지만 이 구성 요소의 새로운 버전을 '카나리' 하기를 원한다. 대량의 레플리카에 대해 replicas 를 9로 설정하고 tier=frontend, environment=prod, track=stable 레이블을 설정한 레플리케이션 컨트롤러와, 카나리에 replicas 가 1로 설정된 다른 레플리케이션 컨트롤러에 tier=frontend, environment=prod, track=canary 라는 레이블을 설정할 수 있다. 이제 이 서비스는 카나리와 카나리 이외의 파드 모두를 포함한다. 그러나 레플리케이션 컨트롤러를 별도로 조작하여 테스트하고 결과를 모니터링하는 등의 작업이 혼란스러울 수 있다.
서비스와 레플리케이션컨트롤러 사용
하나의 서비스 뒤에 여러 개의 레플리케이션컨트롤러가 있을 수 있다. 예를 들어 일부 트래픽은 이전 버전으로 이동하고 일부는 새 버전으로 이동한다.
레플리케이션컨트롤러는 자체적으로 종료되지 않지만, 서비스만큼 오래 지속될 것으로 기대되지는 않는다. 서비스는 여러 레플리케이션컨트롤러에 의해 제어되는 파드로 구성될 수 있으며, 서비스 라이프사이클 동안(예를 들어, 서비스를 실행하는 파드 업데이트 수행을 위해) 많은 레플리케이션컨트롤러가 생성 및 제거될 것으로 예상된다. 서비스 자체와 클라이언트 모두 파드를 유지하는 레플리케이션컨트롤러를 의식하지 않는 상태로 남아 있어야 한다.
레플리케이션을 위한 프로그램 작성
레플리케이션 컨트롤러에 의해 생성된 파드는 해당 구성이 시간이 지남에 따라 이질적이 될 수 있지만 균일하고 의미상 동일하도록 설계되었다. 이는 레플리카된 상태 스테이트리스 서버에 적합하지만 레플리케이션 컨트롤러를 사용하여 마스터 선출, 샤드 및 워크-풀 애플리케이션의 가용성을 유지할 수도 있다. RabbitMQ work queues와 같은 애플리케이션은 안티패턴으로 간주되는 각 파드의 구성에 대한 정적/일회성 사용자 정의와 반대로 동적 작업 할당 메커니즘을 사용해야 한다. 리소스의 수직 자동 크기 조정 (예 : CPU 또는 메모리)과 같은 수행된 모든 파드 사용자 정의는 레플리케이션 컨트롤러 자체와 달리 다른 온라인 컨트롤러 프로세스에 의해 수행되어야 한다.
레플리케이션 컨트롤러의 책임
레플리케이션 컨트롤러는 의도한 수의 파드가 해당 레이블 셀렉터와 일치하고 동작하는지를 확인한다. 현재, 종료된 파드만 해당 파드의 수에서 제외된다. 향후 시스템에서 사용할 수 있는 readiness 및 기타 정보가 고려될 수 있으며 교체 정책에 대한 통제를 더 추가 할 수 있고 외부 클라이언트가 임의로 정교한 교체 또는 스케일 다운 정책을 구현하기 위해 사용할 수 있는 이벤트를 내보낼 계획이다.
레플리케이션 컨트롤러는 이 좁은 책임에 영원히 제약을 받는다. 그 자체로는 준비성 또는 활성 프로브를 실행하지 않을 것이다. 오토 스케일링을 수행하는 대신, 외부 오토 스케일러 (#492에서 논의된)가 레플리케이션 컨트롤러의 replicas 필드를 변경함으로써 제어되도록 의도되었다. 레플리케이션 컨트롤러에 스케줄링 정책 (예를 들어 spreading)을 추가하지 않을 것이다. 오토사이징 및 기타 자동화 된 프로세스를 방해할 수 있으므로 제어된 파드가 현재 지정된 템플릿과 일치하는지 확인해야 한다. 마찬가지로 기한 완료, 순서 종속성, 구성 확장 및 기타 기능은 다른 곳에 속한다. 대량의 파드 생성 메커니즘 (#170)까지도 고려해야 한다.
레플리케이션 컨트롤러는 조합 가능한 빌딩-블록 프리미티브가 되도록 고안되었다. 향후 사용자의 편의를 위해 더 상위 수준의 API 및/또는 도구와 그리고 다른 보완적인 기본 요소가 그 위에 구축 될 것으로 기대한다. 현재 kubectl이 지원하는 "매크로" 작업 (실행, 스케일)은 개념 증명의 예시이다. 예를 들어 Asgard와 같이 레플리케이션 컨트롤러, 오토 스케일러, 서비스, 정책 스케줄링, 카나리 등을 관리할 수 있다.
API 오브젝트
레플리케이션 컨트롤러는 쿠버네티스 REST API의 최상위 수준의 리소스이다. API 오브젝트에 대한 더 자세한 것은 ReplicationController API object 에서 찾을 수 있다.
레플리케이션 컨트롤러의 대안
레플리카셋
ReplicaSet은 새로운 집합성 기준 레이블 셀렉터이다.
이것은 주로 디플로이먼트에 의해 파드의 생성, 삭제 및 업데이트를 오케스트레이션 하는 메커니즘으로 사용된다.
사용자 지정 업데이트 조정이 필요하거나 업데이트가 필요하지 않은 경우가 아니면 레플리카셋을 직접 사용하는 대신 디플로이먼트를 사용하는 것이 좋다.
디플로이먼트 (권장됨)
Deployment는 기본 레플리카셋과 그 파드를 업데이트하는 상위 수준의 API 오브젝트이다. 선언적이며, 서버 사이드이고, 추가 기능이 있기 때문에 롤링 업데이트 기능을 원한다면 디플로이먼트를 권장한다.
베어 파드
사용자가 직접 파드를 만든 경우와 달리 레플리케이션 컨트롤러는 노드 오류 또는 커널 업그레이드와 같은 장애가 발생하는 노드 유지 관리의 경우와 같이 어떤 이유로든 삭제되거나 종료된 파드를 대체한다. 따라서 애플리케이션에 하나의 파드만 필요한 경우에도 레플리케이션 컨트롤러를 사용하는 것이 좋다. 프로세스 관리자와 비슷하게 생각하면, 단지 단일 노드의 개별 프로세스가 아닌 여러 노드에서 여러 파드를 감독하는 것이다. 레플리케이션 컨트롤러는 로컬 컨테이너가 kubelet과 같은 노드의 에이전트로 재시작하도록 위임한다.
잡
자체적으로 제거될 것으로 예상되는 파드 (즉, 배치 잡)의 경우
레플리케이션 컨트롤러 대신 Job을 사용하라.
데몬셋
머신 모니터링이나 머신 로깅과 같은 머신 레벨 기능을 제공하는 파드에는 레플리케이션 컨트롤러 대신
DaemonSet을 사용하라. 이런 파드들의 수명은 머신의 수명에 달려 있다.
다른 파드가 시작되기 전에 파드가 머신에서 실행되어야 하며,
머신이 재부팅/종료 준비가 되어 있을 때 안전하게 종료된다.
다음 내용
- 파드에 대해 배운다.
- 레플리케이션 컨트롤러를 대신하는 디플로이먼트에 대해 배운다.
ReplicationController는 쿠버네티스 REST API의 일부이다. 레플리케이션 컨트롤러 API에 대해 이해하기 위해 ReplicationController 오브젝트 정의를 읽는다.
6 - 서비스, 로드밸런싱, 네트워킹
쿠버네티스의 네트워킹에 대한 개념과 리소스에 대해 설명한다.
쿠버네티스 네트워크 모델
클러스터의 모든 파드는 고유한 IP 주소를 갖는다.
이는 즉 파드간 연결을 명시적으로 만들 필요가 없으며
또한 컨테이너 포트를 호스트 포트에 매핑할 필요가 거의 없음을 의미한다.
이로 인해 포트 할당, 네이밍, 서비스 디스커버리,
로드 밸런싱,
애플리케이션 구성, 마이그레이션 관점에서 파드를 VM 또는 물리 호스트처럼 다룰 수 있는 깔끔하고
하위 호환성을 갖는 모델이 제시된다.
쿠버네티스는 모든 네트워킹 구현에 대해 다음과 같은 근본적인 요구사항을 만족할 것을 요구한다. (이를 통해, 의도적인 네트워크 분할 정책을 방지)
- 파드는 NAT 없이 노드 상의 모든 파드와 통신할 수 있다.
- 노드 상의 에이전트(예: 시스템 데몬, kubelet)는 해당 노드의 모든 파드와 통신할 수 있다.
참고: 파드를 호스트 네트워크에서 구동하는 것도 지원하는 플랫폼(예:
리눅스)에 대해서는, 파드가 노드의 호스트 네트워크에 연결되어 있을 때에도 파드는 여전히
NAT 없이 모든 노드의 모든 파드와 통신할 수 있다.
이 모델은 전반적으로 덜 복잡할 뿐만 아니라, 무엇보다도 VM에 있던 앱을 컨테이너로 손쉽게 포팅하려는 쿠버네티스 요구사항을 만족시킬 수 있다. 작업을 기존에는 VM에서 실행했었다면, VM은 IP주소를 가지며 프로젝트 내의 다른 VM과 통신할 수 있었을 것이다. 이는 동일한 기본 모델이다.
쿠버네티스 IP 주소는 파드 범주에 존재하며,
파드 내의 컨테이너들은 IP 주소, MAC 주소를 포함하는 네트워크 네임스페이스를 공유한다.
이는 곧 파드 내의 컨테이너들이 각자의 포트에 localhost로 접근할 수 있음을 의미한다.
또한 파드 내의 컨테이너들이 포트 사용에 있어 서로 협조해야 하는데,
이는 VM 내 프로세스 간에도 마찬가지이다.
이러한 모델은 "파드 별 IP" 모델로 불린다.
이것이 어떻게 구현되는지는 사용하는 컨테이너 런타임의 상세사항이다.
노드 자체의 포트를 파드로 포워드하도록 요청하는 것도 가능하지만(호스트 포트라고 불림),
이는 매우 비주류적인(niche) 동작이다.
포워딩이 어떻게 구현되는지도 컨테이너 런타임의 상세사항이다.
파드 자체는 호스트 포트 존재 유무를 인지할 수 없다.
쿠버네티스 네트워킹은 다음의 네 가지 문제를 해결한다.
-
파드 내의 컨테이너는 루프백(loopback)을 통한 네트워킹을 사용하여 통신한다.
-
클러스터 네트워킹은 서로 다른 파드 간의 통신을 제공한다.
-
서비스 API를 사용하면 파드에서 실행 중인 애플리케이션을 클러스터 외부에서 접근 할 수 있다.
- 인그레스는 특히 HTTP 애플리케이션, 웹사이트 그리고 API를 노출하기 위한 추가 기능을 제공한다.
-
또한 서비스를 사용하여 서비스를 클러스터 내부에서만 사용할 수 있도록 게시할 수 있다.
-
서비스와 애플리케이션 연결하기 튜토리얼에서는 실습 예제를 통해 서비스와 쿠버네티스 네트워킹에 대해 배울 수 있다.
클러스터 네트워킹은 클러스터에 네트워킹을 설정하는 방법과 관련된 기술에 대한 개요도 제공한다.
6.1 - 서비스
외부와 접하는 단일 엔드포인트 뒤에 있는 클러스터에서 실행되는 애플리케이션을 노출시키며, 이는 워크로드가 여러 백엔드로 나뉘어 있는 경우에도 가능하다.
파드 집합에서 실행중인 애플리케이션을 네트워크 서비스로 노출하는 추상화 방법
쿠버네티스를 사용하면 익숙하지 않은 서비스 디스커버리 메커니즘을 사용하기 위해 애플리케이션을 수정할 필요가 없다. 쿠버네티스는 파드에게 고유한 IP 주소와 파드 집합에 대한 단일 DNS 명을 부여하고, 그것들 간에 로드-밸런스를 수행할 수 있다.
동기
쿠버네티스 파드는 클러스터 목표 상태(desired state)와 일치하도록 생성되고 삭제된다. 파드는 비영구적 리소스이다. 만약 앱을 실행하기 위해 디플로이먼트를 사용한다면, 동적으로 파드를 생성하고 제거할 수 있다.
각 파드는 고유한 IP 주소를 갖지만, 디플로이먼트에서는 한 시점에 실행되는 파드 집합이 잠시 후 실행되는 해당 파드 집합과 다를 수 있다.
이는 다음과 같은 문제를 야기한다. ("백엔드"라 불리는) 일부 파드 집합이 클러스터의 ("프론트엔드"라 불리는) 다른 파드에 기능을 제공하는 경우, 프론트엔드가 워크로드의 백엔드를 사용하기 위해, 프론트엔드가 어떻게 연결할 IP 주소를 찾아서 추적할 수 있는가?
서비스 로 들어가보자.
서비스 리소스
쿠버네티스에서 서비스는 파드의 논리적 집합과 그것들에 접근할 수 있는 정책을 정의하는 추상적 개념이다. (때로는 이 패턴을 마이크로-서비스라고 한다.) 서비스가 대상으로 하는 파드 집합은 일반적으로 셀렉터가 결정한다. 서비스 엔드포인트를 정의하는 다른 방법에 대한 자세한 내용은 셀렉터가 없는 서비스를 참고한다.
예를 들어, 3개의 레플리카로 실행되는 스테이트리스 이미지-처리 백엔드를 생각해보자. 이러한 레플리카는 대체 가능하다. 즉, 프론트엔드는 그것들이 사용하는 백엔드를 신경쓰지 않는다. 백엔드 세트를 구성하는 실제 파드는 변경될 수 있지만, 프론트엔드 클라이언트는 이를 인식할 필요가 없으며, 백엔드 세트 자체를 추적해야 할 필요도 없다.
서비스 추상화는 이러한 디커플링을 가능하게 한다.
클라우드-네이티브 서비스 디스커버리
애플리케이션에서 서비스 디스커버리를 위해 쿠버네티스 API를 사용할 수 있는 경우, 매치되는 엔드포인트슬라이스를 API 서버에 질의할 수 있다. 쿠버네티스는 서비스의 파드가 변경될 때마다 서비스의 엔드포인트슬라이스를 업데이트한다.
네이티브 애플리케이션이 아닌 (non-native applications) 경우, 쿠버네티스는 애플리케이션과 백엔드 파드 사이에 네트워크 포트 또는 로드 밸런서를 배치할 수 있는 방법을 제공한다.
서비스 정의
쿠버네티스의 서비스는 파드와 비슷한 REST 오브젝트이다. 모든 REST 오브젝트와
마찬가지로, 서비스 정의를 API 서버에 POST하여
새 인스턴스를 생성할 수 있다.
서비스 오브젝트의 이름은 유효한
RFC 1035 레이블 이름이어야 한다.
예를 들어, 각각 TCP 포트 9376에서 수신하고
app.kubernetes.io/name=MyApp 레이블을 가지고 있는 파드 세트가 있다고 가정해 보자.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
이 명세는 "my-service"라는 새로운 서비스 오브젝트를 생성하고,
app.kubernetes.io/name=MyApp 레이블을 가진 파드의 TCP 9376 포트를 대상으로 한다.
쿠버네티스는 이 서비스에 서비스 프록시가 사용하는 IP 주소 ("cluster IP"라고도 함) 를 할당한다. (이하 가상 IP와 서비스 프록시 참고)
서비스 셀렉터의 컨트롤러는 셀렉터와 일치하는 파드를 지속적으로 검색하고, "my-service"라는 엔드포인트 오브젝트에 대한 모든 업데이트를 POST한다.
참고:
서비스는 모든 수신port를 targetPort에 매핑할 수 있다. 기본적으로 그리고
편의상, targetPort는 port
필드와 같은 값으로 설정된다.파드의 포트 정의에 이름이 있으므로,
서비스의 targetPort 속성에서 이 이름을 참조할 수 있다.
예를 들어, 다음과 같은 방법으로 서비스의 targetPort를 파드 포트에 바인딩할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
이것은 서로 다른 포트 번호를 통해 가용한 동일 네트워크 프로토콜이 있고, 단일 구성 이름을 사용하는 서비스 내에 혼합된 파드가 존재해도 가능하다. 이를 통해 서비스를 배포하고 진전시키는 데 많은 유연성을 제공한다. 예를 들어, 클라이언트를 망가뜨리지 않고, 백엔드 소프트웨어의 다음 버전에서 파드가 노출시키는 포트 번호를 변경할 수 있다.
서비스의 기본 프로토콜은 TCP이다. 다른 지원되는 프로토콜을 사용할 수도 있다.
많은 서비스가 하나 이상의 포트를 노출해야 하기 때문에, 쿠버네티스는 서비스 오브젝트에서 다중
포트 정의를 지원한다.
각 포트는 동일한 프로토콜 또는 다른 프로토콜로 정의될 수 있다.
셀렉터가 없는 서비스
서비스는 일반적으로 셀렉터를 이용하여 쿠버네티스 파드에 대한 접근을 추상화하지만, 셀렉터 대신 매칭되는(corresponding) 엔드포인트슬라이스 오브젝트와 함께 사용되면 다른 종류의 백엔드도 추상화할 수 있으며, 여기에는 클러스터 외부에서 실행되는 것도 포함된다.
예시는 다음과 같다.
- 프로덕션 환경에서는 외부 데이터베이스 클러스터를 사용하려고 하지만, 테스트 환경에서는 자체 데이터베이스를 사용한다.
- 한 서비스에서 다른 네임스페이스 또는 다른 클러스터의 서비스를 지정하려고 한다.
- 워크로드를 쿠버네티스로 마이그레이션하고 있다. 해당 방식을 평가하는 동안, 쿠버네티스에서는 백엔드의 일부만 실행한다.
이러한 시나리오에서는 파드 셀렉터 없이 서비스를 정의 할 수 있다. 예를 들면
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
이 서비스에는 셀렉터가 없으므로, 매칭되는 엔드포인트슬라이스 (및 레거시 엔드포인트) 오브젝트가 자동으로 생성되지 않는다. 엔드포인트슬라이스 오브젝트를 수동으로 추가하여, 서비스를 실행 중인 네트워크 주소 및 포트에 서비스를 수동으로 매핑할 수 있다. 예시는 다음과 같다.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: my-service-1 # 관행적으로, 서비스의 이름을
# 엔드포인트슬라이스 이름의 접두어로 사용한다.
labels:
# "kubernetes.io/service-name" 레이블을 설정해야 한다.
# 이 레이블의 값은 서비스의 이름과 일치하도록 지정한다.
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: '' # 9376 포트는 (IANA에 의해) 잘 알려진 포트로 할당되어 있지 않으므로
# 이 칸은 비워 둔다.
appProtocol: http
protocol: TCP
port: 9376
endpoints:
- addresses:
- "10.4.5.6" # 이 목록에 IP 주소를 기재할 때 순서는 상관하지 않는다.
- "10.1.2.3"
커스텀 엔드포인트슬라이스
서비스를 위한 엔드포인트슬라이스 오브젝트를 생성할 때,
엔드포인트슬라이스 이름으로는 원하는 어떤 이름도 사용할 수 있다.
네임스페이스 내의 각 엔드포인트슬라이스 이름은 고유해야 한다.
해당 엔드포인트슬라이스에 kubernetes.io/service-name 레이블을 설정하여
엔드포인트슬라이스를 서비스와 연결할 수 있다.
참고:
엔드포인트 IP는 루프백(loopback) (IPv4의 경우 127.0.0.0/8, IPv6의 경우 ::1/128), 또는 링크-로컬 (IPv4의 경우 169.254.0.0/16와 224.0.0.0/24, IPv6의 경우 fe80::/64)이 되어서는 안된다.
엔드포인트 IP 주소는 다른 쿠버네티스 서비스의 클러스터 IP일 수 없는데, kube-proxy는 가상 IP를 목적지(destination)로 지원하지 않기 때문이다.
직접 생성했거나 직접 작성한 코드에 의해 생성된 엔드포인트슬라이스를 위해,
endpointslice.kubernetes.io/managed-by
레이블에 사용할 값을 골라야 한다.
엔드포인트슬라이스를 관리하는 컨트롤러 코드를 직접 작성하는 경우,
"my-domain.example/name-of-controller"와 같은 값을 사용할 수 있다.
써드파티 도구를 사용하는 경우, 도구의 이름에서 대문자는 모두 소문자로 바꾸고
공백 및 다른 문장 부호는 하이픈(-)으로 대체한 문자열을 사용한다.
kubectl과 같은 도구를 사용하여 직접 엔드포인트슬라이스를 관리하는 경우,
"staff" 또는 "cluster-admins"와 같이 이러한 수동 관리를 명시하는 이름을 사용한다.
쿠버네티스 자체 컨트롤 플레인이 관리하는 엔드포인트슬라이스를 가리키는
"controller"라는 예약된 값은 사용하지 말아야 한다.
셀렉터가 없는 서비스에 접근하기
셀렉터가 없는 서비스에 접근하는 것은 셀렉터가 있는 서비스에 접근하는 것과 동일하게 동작한다. 셀렉터가 없는 서비스 예시에서, 트래픽은 엔드포인트슬라이스 매니페스트에 정의된 두 엔드포인트 중 하나로 라우트된다(10.1.2.3:9376 또는 10.4.5.6:9376으로의 TCP 연결).
ExternalName 서비스는 셀렉터가 없고 대신 DNS 이름을 사용하는 특이 케이스 서비스이다. 자세한 내용은 이 문서 뒷부분의 ExternalName 섹션을 참조한다.
엔드포인트슬라이스
기능 상태:
Kubernetes v1.21 [stable]
엔드포인트슬라이스는 특정 서비스의 하위(backing) 네트워크 엔드포인트 부분집합(슬라이스)을 나타내는 오브젝트이다.
쿠버네티스 클러스터는 각 엔드포인트슬라이스가 얼마나 많은 엔드포인트를 나타내는지를 추적한다. 한 서비스의 엔드포인트가 너무 많아 역치에 도달하면, 쿠버네티스는 빈 엔드포인트슬라이스를 생성하고 여기에 새로운 엔드포인트 정보를 저장한다. 기본적으로, 쿠버네티스는 기존의 모든 엔드포인트슬라이스가 엔드포인트를 최소 100개 이상 갖게 되면 새 엔드포인트슬라이스를 생성한다. 쿠버네티스는 새 엔드포인트가 추가되어야 하는 상황이 아니라면 새 엔드포인트슬라이스를 생성하지 않는다.
이 API에 대한 더 많은 정보는 엔드포인트슬라이스를 참고한다.
엔드포인트
쿠버네티스 API에서, 엔드포인트(Endpoints)(리소스 명칭이 복수형임)는 네트워크 엔드포인트의 목록을 정의하며, 일반적으로 트래픽이 어떤 파드에 보내질 수 있는지를 정의하기 위해 서비스가 참조한다.
엔드포인트 대신 엔드포인트슬라이스 API를 사용하는 것을 권장한다.
용량 한계를 넘어선 엔드포인트
쿠버네티스는 단일 엔드포인트(Endpoints) 오브젝트에 포함될 수 있는 엔드포인트(endpoints)의 수를 제한한다. 단일 서비스에 1000개 이상의 하위(backing) 엔드포인트가 있으면, 쿠버네티스는 엔드포인트 오브젝트의 데이터를 덜어낸다(truncate). 서비스는 하나 이상의 엔드포인트슬라이스와 연결될 수 있기 때문에, 하위 엔드포인트 1000개 제한은 기존(legacy) 엔드포인트 API에만 적용된다.
이러한 경우, 쿠버네티스는 엔드포인트(Endpoints) 오브젝트에 저장될 수 있는
백엔드 엔드포인트(endpoints)를 최대 1000개 선정하고,
엔드포인트 오브젝트에 endpoints.kubernetes.io/over-capacity: truncated
어노테이션을 설정한다.
컨트롤 플레인은 또한 백엔드 파드 수가 1000 미만으로 내려가면
해당 어노테이션을 제거한다.
트래픽은 여전히 백엔드로 전송되지만, 기존(legacy) 엔드포인트 API에 의존하는 모든 로드 밸런싱 메커니즘은 사용 가능한 하위(backing) 엔드포인트 중에서 최대 1000개까지에만 트래픽을 전송한다.
동일한 API 상한은 곧 하나의 엔드포인트(Endpoints) 객체가 1000개 이상의 엔드포인트(endpoints)를 갖도록 수동으로 업데이트할 수는 없음을 의미한다.
애플리케이션 프로토콜
기능 상태:
Kubernetes v1.20 [stable]
appProtocol 필드는 각 서비스 포트에 대한 애플리케이션 프로토콜을 지정하는 방법을 제공한다.
이 필드의 값은 상응하는 엔드포인트와 엔드포인트슬라이스
오브젝트에 의해 미러링된다.
이 필드는 표준 쿠버네티스 레이블 구문을 따른다. 값은
IANA 표준 서비스 이름 또는
mycompany.com/my-custom-protocol과 같은 도메인 접두사 이름 중 하나여야 한다.
멀티-포트 서비스
일부 서비스의 경우, 둘 이상의 포트를 노출해야 한다. 쿠버네티스는 서비스 오브젝트에서 멀티 포트 정의를 구성할 수 있도록 지원한다. 서비스에 멀티 포트를 사용하는 경우, 모든 포트 이름을 명확하게 지정해야 한다. 예를 들면 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
참고:
쿠버네티스의 일반적인 이름과 마찬가지로, 포트 이름은
소문자 영숫자와 - 만 포함해야 한다. 포트 이름은
영숫자로 시작하고 끝나야 한다.
예를 들어, 123-abc 와 web 은 유효하지만, 123_abc 와 -web 은 유효하지 않다.
자신의 IP 주소 선택
서비스 생성 요청시 고유한 클러스터 IP 주소를 지정할 수
있다. 이를 위해, .spec.clusterIP 필드를 설정한다. 예를 들어,
재사용하려는 기존 DNS 항목이 있거나, 특정 IP 주소로 구성되어
재구성이 어려운 레거시 시스템인 경우이다.
선택한 IP 주소는 API 서버에 대해 구성된 service-cluster-ip-range
CIDR 범위 내의 유효한 IPv4 또는 IPv6 주소여야 한다.
유효하지 않은 clusterIP 주소 값으로 서비스를 생성하려고 하면, API 서버는
422 HTTP 상태 코드를 리턴하여 문제점이 있음을 알린다.
서비스 디스커버리하기
쿠버네티스는 서비스를 찾는 두 가지 기본 모드를 지원한다. - 환경 변수와 DNS
환경 변수
파드가 노드에서 실행될 때, kubelet은 각 활성화된 서비스에 대해 환경 변수 세트를 추가한다.
{SVCNAME}_SERVICE_HOST 및 {SVCNAME}_SERVICE_PORT 환경 변수가 추가되는데,
이 때 서비스 이름은 대문자로, 하이픈(-)은 언더스코어(_)로 변환하여 사용한다.
또한 도커 엔진의 "레거시 컨테이너 연결" 기능과
호환되는 변수(makeLinkVariables 참조)도
지원한다.
예를 들어, TCP 포트 6379를 개방하고
클러스터 IP 주소 10.0.0.11이 할당된 서비스 redis-primary는,
다음 환경 변수를 생성한다.
REDIS_PRIMARY_SERVICE_HOST=10.0.0.11
REDIS_PRIMARY_SERVICE_PORT=6379
REDIS_PRIMARY_PORT=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO=tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT=6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR=10.0.0.11
참고:
서비스에 접근이 필요한 파드가 있고, 환경 변수를 사용해 포트 및 클러스터 IP를 클라이언트 파드에 부여하는 경우, 클라이언트 파드가 생성되기 전에 서비스를 만들어야 한다. 그렇지 않으면, 해당 클라이언트 파드는 환경 변수를 생성할 수 없다.
DNS 만 사용하여 서비스의 클러스터 IP를 검색하는 경우, 이 순서 이슈에 대해 신경 쓸 필요가 없다.
DNS
애드-온을 사용하여 쿠버네티스 클러스터의 DNS 서비스를 설정할 수(대개는 필수적임) 있다.
CoreDNS와 같은, 클러스터-인식 DNS 서버는 새로운 서비스를 위해 쿠버네티스 API를 감시하고 각각에 대한 DNS 레코드 세트를 생성한다. 클러스터 전체에서 DNS가 활성화된 경우 모든 파드는 DNS 이름으로 서비스를 자동으로 확인할 수 있어야 한다.
예를 들면, 쿠버네티스 네임스페이스 my-ns에 my-service라는
서비스가 있는 경우, 컨트롤 플레인과 DNS 서비스가 함께 작동하여
my-service.my-ns에 대한 DNS 레코드를 만든다. my-ns 네임 스페이스의 파드들은
my-service(my-service.my-ns 역시 동작함)에 대한 이름 조회를
수행하여 서비스를 찾을 수 있어야 한다.
다른 네임스페이스의 파드들은 이름을 my-service.my-ns으로 사용해야 한다. 이 이름은
서비스에 할당된 클러스터 IP로 변환된다.
쿠버네티스는 또한 알려진 포트에 대한 DNS SRV (서비스) 레코드를 지원한다.
my-service.my-ns 서비스에 프로토콜이 TCP로 설정된 http라는 포트가 있는 경우,
IP 주소와 http에 대한 포트 번호를 검색하기 위해 _http._tcp.my-service.my-ns 에 대한
DNS SRV 쿼리를 수행할 수 있다.
쿠버네티스 DNS 서버는 ExternalName 서비스에 접근할 수 있는 유일한 방법이다.
DNS 파드와 서비스에서
ExternalName 검색에 대한 자세한 정보를 찾을 수 있다.
헤드리스(Headless) 서비스
때때로 로드-밸런싱과 단일 서비스 IP는 필요치 않다. 이 경우,
"헤드리스" 서비스라는 것을 만들 수 있는데, 명시적으로
클러스터 IP (.spec.clusterIP)에 "None"을 지정한다.
쿠버네티스의 구현에 묶이지 않고, 헤드리스 서비스를 사용하여 다른 서비스 디스커버리 메커니즘과 인터페이스할 수 있다.
헤드리스 서비스의 경우, 클러스터 IP가 할당되지 않고, kube-proxy가
이러한 서비스를 처리하지 않으며, 플랫폼에 의해 로드 밸런싱 또는 프록시를
하지 않는다. DNS가 자동으로 구성되는 방법은 서비스에 셀렉터가 정의되어 있는지
여부에 달려있다.
셀렉터가 있는 경우
셀렉터를 정의하는 헤드리스 서비스의 경우, 쿠버네티스 컨트롤 플레인은 쿠버네티스 API 내에서 엔드포인트슬라이스 오브젝트를 생성하고, 서비스 하위(backing) 파드들을 직접 가리키는 A 또는 AAAA 레코드(IPv4 또는 IPv6 주소)를 반환하도록 DNS 구성을 변경한다.
셀렉터가 없는 경우
셀렉터를 정의하지 않는 헤드리스 서비스의 경우, 쿠버네티스 컨트롤 플레인은 엔드포인트슬라이스 오브젝트를 생성하지 않는다. 하지만, DNS 시스템은 다음 중 하나를 탐색한 뒤 구성한다.
type: ExternalName서비스에 대한 DNS CNAME 레코드ExternalName이외의 모든 서비스 타입에 대해, 서비스의 활성(ready) 엔드포인트의 모든 IP 주소에 대한 DNS A / AAAA 레코드- IPv4 엔드포인트에 대해, DNS 시스템은 A 레코드를 생성한다.
- IPv6 엔드포인트에 대해, DNS 시스템은 AAAA 레코드를 생성한다.
서비스 퍼블리싱 (ServiceTypes)
애플리케이션 중 일부(예: 프론트엔드)는 서비스를 클러스터 밖에 위치한 외부 IP 주소에 노출하고 싶은 경우가 있을 것이다.
쿠버네티스 ServiceTypes는 원하는 서비스 종류를 지정할 수 있도록 해 준다.
Type 값과 그 동작은 다음과 같다.
ClusterIP: 서비스를 클러스터-내부 IP에 노출시킨다. 이 값을 선택하면 클러스터 내에서만 서비스에 도달할 수 있다. 이것은 서비스의type을 명시적으로 지정하지 않았을 때의 기본값이다.NodePort: 고정 포트 (NodePort)로 각 노드의 IP에 서비스를 노출시킨다. 노드 포트를 사용할 수 있도록 하기 위해, 쿠버네티스는type: ClusterIP인 서비스를 요청했을 때와 마찬가지로 클러스터 IP 주소를 구성한다.LoadBalancer: 클라우드 공급자의 로드 밸런서를 사용하여 서비스를 외부에 노출시킨다.ExternalName: 값과 함께 CNAME 레코드를 리턴하여, 서비스를externalName필드의 내용(예:foo.bar.example.com)에 매핑한다. 어떠한 종류의 프록시도 설정되지 않는다.참고:
ExternalName유형을 사용하려면kube-dns버전 1.7 또는 CoreDNS 버전 0.0.8 이상이 필요하다.
type 필드는 중첩(nested) 기능으로 설계되어, 각 단계는 이전 단계에 더해지는 형태이다.
이는 모든 클라우드 공급자에 대해 엄격히 요구되는 사항은 아니다(예:
Google Compute Engine에서는 type: LoadBalancer가 동작하기 위해 노드 포트를 할당할 필요가 없지만,
다른 클라우드 공급자 통합 시에는 필요할 수 있음).
엄격한 중첩이 필수 사항은 아니지만, 서비스에 대한 쿠버네티스 API 디자인은 이와 상관없이 엄격한 중첩 구조를 가정한다.
인그레스를 사용하여 서비스를 노출시킬 수도 있다. 인그레스는 서비스 유형은 아니지만, 클러스터의 진입점 역할을 한다. 동일한 IP 주소로 여러 서비스를 노출시킬 수 있기 때문에 라우팅 규칙을 단일 리소스로 통합할 수 있다.
NodePort 유형
type 필드를 NodePort로 설정하면, 쿠버네티스 컨트롤 플레인은
--service-node-port-range 플래그로 지정된 범위에서 포트를 할당한다 (기본값 : 30000-32767).
각 노드는 해당 포트 (모든 노드에서 동일한 포트 번호)를 서비스로 프록시한다.
서비스는 할당된 포트를 .spec.ports[*].nodePort 필드에 나타낸다.
NodePort를 사용하면 자유롭게 자체 로드 밸런싱 솔루션을 설정하거나, 쿠버네티스가 완벽하게 지원하지 않는 환경을 구성하거나, 하나 이상의 노드 IP를 직접 노출시킬 수 있다.
NodePort 서비스에 대해, 쿠버네티스는 포트를 추가로
할당한다(서비스의 프로토콜에 매치되도록 TCP, UDP, SCTP 중 하나).
클러스터의 모든 노드는 할당된 해당 포트를 리슨하고
해당 서비스에 연결된 활성(ready) 엔드포인트 중 하나로 트래픽을 전달하도록 자기 자신을 구성한다.
적절한 프로토콜(예: TCP) 및 적절한 포트(해당 서비스에 할당된 대로)로
클러스터 외부에서 클러스터의 아무 노드에 연결하여 type: NodePort 서비스로 접근할 수 있다.
포트 직접 선택하기
특정 포트 번호를 원한다면, nodePort 필드에 값을 명시할 수 있다.
컨트롤 플레인은 해당 포트를 할당해 주거나 또는
해당 API 트랜젝션이 실패했다고 알려줄 것이다.
이는 사용자 스스로 포트 충돌의 가능성을 고려해야 한다는 의미이다.
또한 유효한(NodePort용으로 사용할 수 있도록 구성된 범위 내의)
포트 번호를 사용해야 한다.
다음은 NodePort 값을 명시하는(이 예시에서는 30007)
type: NodePort 서비스에 대한 예시 매니페스트이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app.kubernetes.io/name: MyApp
ports:
# 기본적으로 그리고 편의상 `targetPort` 는 `port` 필드와 동일한 값으로 설정된다.
- port: 80
targetPort: 80
# 선택적 필드
# 기본적으로 그리고 편의상 쿠버네티스 컨트롤 플레인은 포트 범위에서 할당한다(기본값: 30000-32767)
nodePort: 30007
type: NodePort 서비스를 위한 커스텀 IP 주소 구성
NodePort 서비스 노출에 특정 IP 주소를 사용하도록 클러스터의 노드를 설정할 수 있다. 각 노드가 여러 네트워크(예: 애플리케이션 트래픽용 네트워크 및 노드/컨트롤 플레인 간 트래픽용 네트워크)에 연결되어 있는 경우에 이러한 구성을 고려할 수 있다.
포트를 프록시하기 위해 특정 IP를 지정하려면, kube-proxy에 대한
--nodeport-addresses 플래그 또는
kube-proxy 구성 파일의
동등한 nodePortAddresses 필드를
특정 IP 블록으로 설정할 수 있다.
이 플래그는 쉼표로 구분된 IP 블록 목록(예: 10.0.0.0/8, 192.0.2.0/25)을 사용하여
kube-proxy가 로컬 노드로 고려해야 하는 IP 주소 범위를 지정한다.
예를 들어, --nodeport-addresses=127.0.0.0/8 플래그로 kube-proxy를 시작하면,
kube-proxy는 NodePort 서비스에 대하여 루프백(loopback) 인터페이스만 선택한다.
--nodeport-addresses의 기본 값은 비어있는 목록이다.
이것은 kube-proxy가 NodePort에 대해 사용 가능한 모든 네트워크 인터페이스를 고려해야 한다는 것을 의미한다.
(이는 이전 쿠버네티스 릴리스와도 호환된다).
참고:
이 서비스는<NodeIP>:spec.ports[*].nodePort와 .spec.clusterIP:spec.ports[*].port로 표기된다.
kube-proxy에 대한 --nodeport-addresses 플래그 또는 kube-proxy 구성 파일의 동등한 필드가 설정된 경우,
<NodeIP> 는 노드 IP를 필터링한다.로드밸런서 유형
외부 로드 밸런서를 지원하는 클라우드 공급자 상에서, type
필드를 LoadBalancer로 설정하면 서비스에 대한 로드 밸런서를 프로비저닝한다.
로드 밸런서의 실제 생성은 비동기적으로 수행되고,
프로비저닝된 밸런서에 대한 정보는 서비스의
.status.loadBalancer 필드에 발행된다.
예를 들면 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.127
외부 로드 밸런서의 트래픽은 백엔드 파드로 전달된다. 클라우드 공급자는 로드 밸런싱 방식을 결정한다.
일부 클라우드 공급자는 loadBalancerIP를 지정할 수 있도록 허용한다. 이 경우, 로드 밸런서는
사용자 지정 loadBalancerIP로 생성된다. loadBalancerIP 필드가 지정되지 않으면,
임시 IP 주소로 loadBalancer가 설정된다. loadBalancerIP를 지정했지만
클라우드 공급자가 이 기능을 지원하지 않는 경우, 설정한 loadbalancerIP 필드는
무시된다.
type: LoadBalancer인 서비스를 구현하기 위해,
쿠버네티스는 일반적으로 type: NodePort 서비스를 요청했을 때와 동일한 변경사항을 적용하면서 시작한다.
그런 다음 cloud-controller-manager 컴포넌트는
할당된 해당 NodePort로 트래픽을 전달하도록 외부 로드 밸런서를 구성한다.
알파 기능으로서, 로드 밸런스된 서비스가 NodePort 할당을 생략하도록 구성할 수 있는데, 이는 클라우드 공급자의 구현이 이를 지원할 때에만 가능하다.
참고:
Azure 에서 사용자 지정 공개(public) 유형 loadBalancerIP를 사용하려면, 먼저
정적 유형 공개 IP 주소 리소스를 생성해야 한다. 이 공개 IP 주소 리소스는
클러스터에서 자동으로 생성된 다른 리소스와 동일한 리소스 그룹에 있어야 한다.
예를 들면, MC_myResourceGroup_myAKSCluster_eastus이다.
할당된 IP 주소를 loadBalancerIP로 지정한다. 클라우드 공급자 구성 파일에서
securityGroupName을 업데이트했는지 확인한다.
CreatingLoadBalancerFailed 권한 문제 해결에 대한 자세한 내용은
Azure Kubernetes Service (AKS) 로드 밸런서에서 고정 IP 주소 사용
또는 고급 네트워킹 AKS 클러스터에서 CreateLoadBalancerFailed를 참고한다.
프로토콜 유형이 혼합된 로드밸런서
기능 상태:
Kubernetes v1.24 [beta]
기본적으로 로드밸런서 서비스 유형의 경우 둘 이상의 포트가 정의되어 있을 때 모든 포트는 동일한 프로토콜을 가져야 하며 프로토콜은 클라우드 공급자가 지원하는 프로토콜이어야 한다.
MixedProtocolLBService 기능 게이트(v1.24에서 kube-apiserver에 대해 기본적으로 활성화되어 있음)는
둘 이상의 포트가 정의되어 있는 경우에 로드밸런서 타입의 서비스에 대해 서로 다른 프로토콜을 사용할 수 있도록 해 준다.
참고:
로드밸런서 서비스 유형에 사용할 수 있는 프로토콜 세트는 여전히 클라우드 제공 업체에서 정의한다. 클라우드 제공자가 혼합 프로토콜을 지원하지 않는다면 이는 단일 프로토콜만을 제공한다는 것을 의미한다.로드밸런서 NodePort 할당 비활성화
기능 상태:
Kubernetes v1.24 [stable]
type=LoadBalancer 서비스에 대한 노드 포트 할당을 선택적으로 비활성화할 수 있으며,
이는 spec.allocateLoadBalancerNodePorts 필드를 false로 설정하면 된다.
노드 포트를 사용하지 않고 트래픽을 파드로 직접 라우팅하는 로드 밸런서 구현에만 사용해야 한다.
기본적으로 spec.allocateLoadBalancerNodePorts는 true이며 로드밸런서 서비스 유형은 계속해서 노드 포트를 할당할 것이다.
노드 포트가 할당된 기존 서비스에서 spec.allocateLoadBalancerNodePorts가 false로 설정된 경우 해당 노드 포트는 자동으로 할당 해제되지 않는다.
이러한 노드 포트를 할당 해제하려면 모든 서비스 포트에서 nodePorts 항목을 명시적으로 제거해야 한다.
로드 밸런서 구현 클래스 지정
기능 상태:
Kubernetes v1.24 [stable]
spec.loadBalancerClass 필드를 설정하여 클라우드 제공자가 설정한 기본값 이외의 로드 밸런서 구현을 사용할 수 있다.
기본적으로, spec.loadBalancerClass 는 nil 이고,
클러스터가 클라우드 제공자의 로드밸런서를 이용하도록 --cloud-provider 컴포넌트 플래그를 이용하여 설정되어 있으면
LoadBalancer 유형의 서비스는 클라우드 공급자의 기본 로드 밸런서 구현을 사용한다.
spec.loadBalancerClass 가 지정되면, 지정된 클래스와 일치하는 로드 밸런서
구현이 서비스를 감시하고 있다고 가정한다.
모든 기본 로드 밸런서 구현(예: 클라우드 공급자가 제공하는
로드 밸런서 구현)은 이 필드가 설정된 서비스를 무시한다.
spec.loadBalancerClass 는 LoadBalancer 유형의 서비스에서만 설정할 수 있다.
한 번 설정하면 변경할 수 없다.
spec.loadBalancerClass 의 값은 "internal-vip" 또는
"example.com/internal-vip" 와 같은 선택적 접두사가 있는 레이블 스타일 식별자여야 한다.
접두사가 없는 이름은 최종 사용자를 위해 예약되어 있다.
내부 로드 밸런서
혼재된 환경에서는 서비스의 트래픽을 동일한 (가상) 네트워크 주소 블록 내로 라우팅해야 하는 경우가 있다.
수평 분할 DNS 환경에서는 외부와 내부 트래픽을 엔드포인트로 라우팅 할 수 있는 두 개의 서비스가 필요하다.
내부 로드 밸런서를 설정하려면, 사용 중인 클라우드 서비스 공급자에 따라 다음의 어노테이션 중 하나를 서비스에 추가한다.
탭 중 하나를 선택
[...]
metadata:
name: my-service
annotations:
cloud.google.com/load-balancer-type: "Internal"
[...]
[...]
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
[...]
[...]
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
[...]
[...]
metadata:
name: my-service
annotations:
service.kubernetes.io/ibm-load-balancer-cloud-provider-ip-type: "private"
[...]
[...]
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
[...]
[...]
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
[...]
[...]
metadata:
annotations:
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid: subnet-xxxxx
[...]
[...]
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet"
[...]
[...]
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/oci-load-balancer-internal: true
[...]
AWS에서 TLS 지원
AWS에서 실행되는 클러스터에서 부분적으로 TLS / SSL을 지원하기 위해, LoadBalancer 서비스에 세 가지
어노테이션을 추가할 수 있다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: arn:aws:acm:us-east-1:123456789012:certificate/12345678-1234-1234-1234-123456789012
첫 번째는 사용할 인증서의 ARN을 지정한다. IAM에 업로드된 써드파티 발급자의 인증서이거나 AWS Certificate Manager에서 생성된 인증서일 수 있다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: (https|http|ssl|tcp)
두 번째 어노테이션은 파드가 알려주는 프로토콜을 지정한다. HTTPS와 SSL의 경우, ELB는 인증서를 사용하여 암호화된 연결을 통해 파드가 스스로를 인증할 것으로 예상한다.
HTTP와 HTTPS는 7 계층 프록시를 선택한다. ELB는 요청을 전달할 때
사용자와의 연결을 종료하고, 헤더를 파싱하고 사용자의 IP 주소로 X-Forwarded-For
헤더를 삽입한다. (파드는 해당 연결의 다른 종단에서의
ELB의 IP 주소만 참조)
TCP 및 SSL은 4 계층 프록시를 선택한다. ELB는 헤더를 수정하지 않고 트래픽을 전달한다.
일부 포트는 보안성을 갖추고 다른 포트는 암호화되지 않은 혼재된 사용 환경에서는 다음 어노테이션을 사용할 수 있다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http
service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "443,8443"
위의 예에서, 서비스에 80, 443, 8443의 3개 포트가 포함된 경우,
443, 8443은 SSL 인증서를 사용하지만, 80은 프록시하는 HTTP이다.
쿠버네티스 v1.9부터는 서비스에 대한
HTTPS 또는 SSL 리스너와 함께
사전에 정의된 AWS SSL 정책을 사용할 수 있다.
사용 가능한 정책을 확인하려면, aws 커맨드라인 툴을 사용한다.
aws elb describe-load-balancer-policies --query 'PolicyDescriptions[].PolicyName'
그리고
"service.beta.kubernetes.io/aws-load-balancer-ssl-negotiation-policy"
어노테이션을 사용하여 이러한 정책 중 하나를 지정할 수 있다. 예를 들면
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-negotiation-policy: "ELBSecurityPolicy-TLS-1-2-2017-01"
AWS에서 지원하는 프록시 프로토콜
AWS에서 실행되는 클러스터에 대한 프록시 프로토콜 지원을 활성화하려면, 다음의 서비스 어노테이션을 사용할 수 있다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: "*"
버전 1.3.0 부터, 이 어노테이션의 사용은 ELB에 의해 프록시되는 모든 포트에 적용되며 다르게 구성할 수 없다.
AWS의 ELB 접근 로그
AWS ELB 서비스의 접근 로그를 관리하기 위한 몇 가지 어노테이션이 있다.
service.beta.kubernetes.io/aws-load-balancer-access-log-enabled 어노테이션은
접근 로그의 활성화 여부를 제어한다.
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval 어노테이션은
접근 로그를 게시하는 간격을 분 단위로 제어한다. 5분 또는 60분의
간격으로 지정할 수 있다.
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name 어노테이션은
로드 밸런서 접근 로그가 저장되는 Amazon S3 버킷의 이름을
제어한다.
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix 어노테이션은
Amazon S3 버킷을 생성한 논리적 계층을 지정한다.
metadata:
name: my-service
annotations:
# 로드 밸런서의 접근 로그 활성화 여부를 명시.
service.beta.kubernetes.io/aws-load-balancer-access-log-enabled: "true"
# 접근 로그를 게시하는 간격을 분 단위로 제어. 5분 또는 60분의 간격을 지정.
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval: "60"
# 로드 밸런서 접근 로그가 저장되는 Amazon S3 버킷의 이름 명시.
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name: "my-bucket"
# Amazon S3 버킷을 생성한 논리적 계층을 지정. 예: `my-bucket-prefix/prod`
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix: "my-bucket-prefix/prod"
AWS의 연결 드레이닝(Draining)
Classic ELB의 연결 드레이닝은
service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled 어노테이션을
"true"값으로 설정하여 관리할 수 있다. service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout 어노테이션을
사용하여 인스턴스를 해제하기 전에,
기존 연결을 열어 두는 목적으로 최대 시간을 초 단위로
설정할 수도 있다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled: "true"
service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout: "60"
다른 ELB 어노테이션
이하는 클래식 엘라스틱 로드 밸런서(Classic Elastic Load Balancers)를 관리하기 위한 다른 어노테이션이다.
metadata:
name: my-service
annotations:
# 로드 밸런서가 연결을 닫기 전에, 유휴 상태(연결을 통해 전송 된
# 데이터가 없음)의 연결을 허용하는 초단위 시간
service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "60"
# 로드 밸런서에 교차-영역(cross-zone) 로드 밸런싱을 사용할 지 여부를 지정
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true"
# 쉼표로 구분된 key-value 목록은 ELB에
# 추가 태그로 기록됨
service.beta.kubernetes.io/aws-load-balancer-additional-resource-tags: "environment=prod,owner=devops"
# 백엔드가 정상인 것으로 간주되는데 필요한 연속적인
# 헬스 체크 성공 횟수이다. 기본값은 2이며, 2와 10 사이여야 한다.
service.beta.kubernetes.io/aws-load-balancer-healthcheck-healthy-threshold: ""
# 백엔드가 비정상인 것으로 간주되는데 필요한
# 헬스 체크 실패 횟수이다. 기본값은 6이며, 2와 10 사이여야 한다.
service.beta.kubernetes.io/aws-load-balancer-healthcheck-unhealthy-threshold: "3"
# 개별 인스턴스의 상태 점검 사이의
# 대략적인 간격 (초 단위). 기본값은 10이며, 5와 300 사이여야 한다.
service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval: "20"
# 헬스 체크 실패를 의미하는 무 응답의 총 시간 (초 단위)
# 이 값은 service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval
# 값 보다 작아야한다. 기본값은 5이며, 2와 60 사이여야 한다.
service.beta.kubernetes.io/aws-load-balancer-healthcheck-timeout: "5"
# 생성된 ELB에 설정할 기존 보안 그룹(security group) 목록.
# service.beta.kubernetes.io/aws-load-balancer-extra-security-groups 어노테이션과 달리,
# 이는 이전에 ELB에 할당된 다른 모든 보안 그룹을 대체하며,
# '해당 ELB를 위한 고유 보안 그룹 생성'을 오버라이드한다.
# 목록의 첫 번째 보안 그룹 ID는 인바운드 트래픽(서비스 트래픽과 헬스 체크)이
# 워커 노드로 향하도록 하는 규칙으로 사용된다.
# 여러 ELB가 하나의 보안 그룹 ID와 연결되면, 1줄의 허가 규칙만이
# 워커 노드 보안 그룹에 추가된다.
# 즉, 만약 여러 ELB 중 하나를 지우면, 1줄의 허가 규칙이 삭제되어, 같은 보안 그룹 ID와 연결된 모든 ELB에 대한 접속이 막힌다.
# 적절하게 사용되지 않으면 이는 다수의 서비스가 중단되는 상황을 유발할 수 있다.
service.beta.kubernetes.io/aws-load-balancer-security-groups: "sg-53fae93f"
# 생성된 ELB에 추가할 추가 보안 그룹 목록
# 이 방법을 사용하면 이전에 생성된 고유 보안 그룹이 그대로 유지되므로,
# 각 ELB가 고유 보안 그룹 ID와 그에 매칭되는 허가 규칙 라인을 소유하여
# 트래픽(서비스 트래픽과 헬스 체크)이 워커 노드로 향할 수 있도록 한다.
# 여기에 기재되는 보안 그룹은 여러 서비스 간 공유될 수 있다.
service.beta.kubernetes.io/aws-load-balancer-extra-security-groups: "sg-53fae93f,sg-42efd82e"
# 로드 밸런서의 대상 노드를 선택하는 데
# 사용되는 키-값 쌍의 쉼표로 구분된 목록
service.beta.kubernetes.io/aws-load-balancer-target-node-labels: "ingress-gw,gw-name=public-api"
AWS의 네트워크 로드 밸런서 지원
기능 상태:
Kubernetes v1.15 [beta]
AWS에서 네트워크 로드 밸런서를 사용하려면, nlb 값이 설정된 service.beta.kubernetes.io/aws-load-balancer-type 어노테이션을 사용한다.
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
참고:
NLB는 특정 인스턴스 클래스에서만 작동한다. 지원되는 인스턴스 유형 목록은 엘라스틱 로드 밸런싱에 대한 AWS 문서 를 참고한다.클래식 엘라스틱 로드 밸런서와 달리, 네트워크 로드 밸런서 (NLB)는
클라이언트의 IP 주소를 노드로 전달한다. 서비스의 .spec.externalTrafficPolicy가
Cluster로 설정되어 있으면, 클라이언트의 IP 주소가 종단 파드로
전파되지 않는다.
.spec.externalTrafficPolicy를 Local로 설정하면, 클라이언트 IP 주소가
종단 파드로 전파되지만, 트래픽이 고르지 않게
분배될 수 있다. 특정 로드밸런서 서비스를 위한 파드가 없는 노드는 자동 할당된
.spec.healthCheckNodePort에 의해서 NLB 대상 그룹의
헬스 체크에 실패하고 트래픽을 수신하지 못하게 된다.
트래픽을 균일하게 하려면, DaemonSet을 사용하거나, 파드 안티어피니티(pod anti-affinity) 를 지정하여 동일한 노드에 위치하지 않도록 한다.
내부 로드 밸런서 어노테이션과 함께 NLB 서비스를 사용할 수도 있다.
클라이언트 트래픽이 NLB 뒤의 인스턴스에 도달하기 위해, 노드 보안 그룹은 다음 IP 규칙으로 수정된다.
| 규칙 | 프로토콜 | 포트 | IP 범위 | IP 범위 설명 |
|---|---|---|---|---|
| 헬스 체크 | TCP | NodePort(s) (.spec.healthCheckNodePort for .spec.externalTrafficPolicy = Local) |
Subnet CIDR | kubernetes.io/rule/nlb/health=<loadBalancerName> |
| 클라이언트 트래픽 | TCP | NodePort(s) | .spec.loadBalancerSourceRanges (defaults to 0.0.0.0/0) |
kubernetes.io/rule/nlb/client=<loadBalancerName> |
| MTU 탐색 | ICMP | 3,4 | .spec.loadBalancerSourceRanges (defaults to 0.0.0.0/0) |
kubernetes.io/rule/nlb/mtu=<loadBalancerName> |
네트워크 로드 밸런서에 접근할 수 있는 클라이언트 IP를 제한하려면,
loadBalancerSourceRanges를 지정한다.
spec:
loadBalancerSourceRanges:
- "143.231.0.0/16"
참고:
.spec.loadBalancerSourceRanges가 설정되어 있지 않으면, 쿠버네티스는
0.0.0.0/0에서 노드 보안 그룹으로의 트래픽을 허용한다. 노드에 퍼블릭 IP 주소가
있는 경우, 비(non)-NLB 트래픽도 해당 수정된 보안 그룹의
모든 인스턴스에 도달할 수 있다.엘라스틱 IP에 대한 설명 문서와 기타 일반적 사용 사례를 AWS 로드 밸런서 컨트롤러 문서에서 볼 수 있다.
Tencent Kubernetes Engine (TKE)의 다른 CLB 어노테이션
아래 표시된 것처럼 TKE에서 클라우드 로드 밸런서를 관리하기 위한 다른 어노테이션이 있다.
metadata:
name: my-service
annotations:
# 지정된 노드로 로드 밸런서 바인드
service.kubernetes.io/qcloud-loadbalancer-backends-label: key in (value1, value2)
# 기존 로드 밸런서의 ID
service.kubernetes.io/tke-existed-lbid:lb-6swtxxxx
# 로드 밸런서 (LB)에 대한 사용자 지정 매개 변수는 아직 LB 유형 수정을 지원하지 않음
service.kubernetes.io/service.extensiveParameters: ""
# LB 리스너의 사용자 정의 매개 변수
service.kubernetes.io/service.listenerParameters: ""
# 로드 밸런서 유형 지정
# 유효 값 : 클래식 (클래식 클라우드 로드 밸런서) 또는 애플리케이션 (애플리케이션 클라우드 로드 밸런서)
service.kubernetes.io/loadbalance-type: xxxxx
# 퍼블릭 네트워크 대역폭 청구 방법 지정
# 유효 값: TRAFFIC_POSTPAID_BY_HOUR (트래픽 별) 및 BANDWIDTH_POSTPAID_BY_HOUR (대역폭 별)
service.kubernetes.io/qcloud-loadbalancer-internet-charge-type: xxxxxx
# 대역폭 값 지정 (값 범위 : [1,2000] Mbps).
service.kubernetes.io/qcloud-loadbalancer-internet-max-bandwidth-out: "10"
# 이 어느테이션이 설정되면, 로드 밸런서는 파드가
# 실행중인 노드만 등록하고, 그렇지 않으면 모든 노드가 등록됨
service.kubernetes.io/local-svc-only-bind-node-with-pod: true
ExternalName 유형
ExternalName 유형의 서비스는 my-service 또는 cassandra와 같은 일반적인 셀렉터에 대한 서비스가 아닌,
DNS 이름에 대한 서비스에 매핑한다. spec.externalName 파라미터를 사용하여 이러한 서비스를 지정한다.
예를 들면, 이 서비스 정의는 prod 네임 스페이스의
my-service 서비스를 my.database.example.com에 매핑한다.
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
참고:
ExternalName은 IPv4 주소 문자열을 허용하지만, IP 주소가 아닌 숫자로 구성된 DNS 이름을 허용한다. IPv4 주소와 유사한 ExternalName은 CoreDNS 또는 ingress-nginx에 의해 확인되지 않는데, ExternalName은 정식(canonical) DNS 이름을 지정하기 때문이다. IP 주소를 하드 코딩하려면, 헤드리스(headless) 서비스 사용을 고려한다.my-service.prod.svc.cluster.local 호스트를 검색하면, 클러스터 DNS 서비스는
my.database.example.com 값의 CNAME 레코드를 반환한다. my-service에 접근하는 것은
다른 서비스와 같은 방식으로 작동하지만, 리다이렉션은 프록시 또는
포워딩을 통하지 않고 DNS 수준에서 발생한다는 중요한
차이점이 있다. 나중에 데이터베이스를 클러스터로 이동하기로 결정한 경우, 해당
파드를 시작하고 적절한 셀렉터 또는 엔드포인트를 추가하고,
서비스의 유형(type)을 변경할 수 있다.
경고:
HTTP 및 HTTPS를 포함한, 몇몇 일반적인 프로토콜에 ExternalName을 사용하는 것은 문제가 있을 수 있다. ExternalName을 사용하는 경우, 클러스터 내부의 클라이언트가 사용하는 호스트 이름(hostname)이 ExternalName이 참조하는 이름과 다르다.
호스트 이름을 사용하는 프로토콜의 경우, 이러한 차이로 인해 오류가 발생하거나 예기치 않은 응답이 발생할 수 있다.
HTTP 요청에는 오리진(origin) 서버가 인식하지 못하는 Host : 헤더가 있다.
TLS 서버는 클라이언트가 연결된 호스트 이름과 일치하는 인증서를 제공할 수 없다.
외부 IP
하나 이상의 클러스터 노드로 라우팅되는 외부 IP가 있는 경우, 쿠버네티스 서비스는 이러한
externalIPs에 노출될 수 있다. 서비스 포트에서 외부 IP (목적지 IP)를 사용하여 클러스터로 들어오는 트래픽은
서비스 엔드포인트 중 하나로 라우팅된다. externalIPs는 쿠버네티스에 의해 관리되지 않으며
클러스터 관리자에게 책임이 있다.
서비스 명세에서, externalIPs는 모든 ServiceTypes와 함께 지정할 수 있다.
아래 예에서, 클라이언트는 "80.11.12.10:80"(외부 IP:포트)로 "my-service"에 접근할 수 있다.
apiVersion: v1
kind: Service
metadata:
app.kubernetes.io/name: MyApp
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
세션 스티킹(stickiness)
특정 클라이언트로부터의 연결이 매번 동일한 파드로 전달되도록 하고 싶다면, 클라이언트의 IP 주소 기반으로 세션 어피니티를 구성할 수 있다. 더 자세한 정보는 세션 어피니티를 참고한다.
API 오브젝트
서비스는 쿠버네티스 REST API의 최상위 리소스이다. 서비스 API 오브젝트에 대한 자세한 내용을 참고할 수 있다.
가상 IP 주소 메커니즘
가상 IP 및 서비스 프록시에서 가상 IP 주소를 갖는 서비스를 노출하기 위해 쿠버네티스가 제공하는 메커니즘에 대해 알아본다.
다음 내용
- 서비스와 애플리케이션 연결 알아보기
- 인그레스에 대해 알아보기
- 엔드포인트슬라이스에 대해 알아보기
추가적으로,
- 가상 IP 및 서비스 프록시를 살펴보기
- 서비스(Service) API에 대한 API 레퍼런스 살펴보기
- 엔드포인트(Endpoints) API에 대한 API 레퍼런스 살펴보기
- 엔드포인트슬라이스 API에 대한 API 레퍼런스 살펴보기
6.2 - 인그레스(Ingress)
URI, 호스트네임, 경로 등과 같은 웹 개념을 이해하는 프로토콜-인지형(protocol-aware configuration) 설정 메커니즘을 이용하여 HTTP (혹은 HTTPS) 네트워크 서비스를 사용 가능하게 한다. 인그레스 개념은 쿠버네티스 API를 통해 정의한 규칙에 기반하여 트래픽을 다른 백엔드에 매핑할 수 있게 해준다.
기능 상태:
Kubernetes v1.19 [stable]
클러스터 내의 서비스에 대한 외부 접근을 관리하는 API 오브젝트이며, 일반적으로 HTTP를 관리함.
인그레스는 부하 분산, SSL 종료, 명칭 기반의 가상 호스팅을 제공할 수 있다.
용어
이 가이드는 용어의 명확성을 위해 다음과 같이 정의한다.
- 노드(Node): 클러스터의 일부이며, 쿠버네티스에 속한 워커 머신.
- 클러스터(Cluster): 쿠버네티스에서 관리되는 컨테이너화 된 애플리케이션을 실행하는 노드 집합. 이 예시와 대부분의 일반적인 쿠버네티스 배포에서 클러스터에 속한 노드는 퍼블릭 인터넷의 일부가 아니다.
- 에지 라우터(Edge router): 클러스터에 방화벽 정책을 적용하는 라우터. 이것은 클라우드 공급자 또는 물리적 하드웨어의 일부에서 관리하는 게이트웨이일 수 있다.
- 클러스터 네트워크(Cluster network): 쿠버네티스 네트워킹 모델에 따라 클러스터 내부에서 통신을 용이하게 하는 논리적 또는 물리적 링크 집합.
- 서비스: 레이블 셀렉터를 사용해서 파드 집합을 식별하는 쿠버네티스 서비스. 달리 언급하지 않으면 서비스는 클러스터 네트워크 내에서만 라우팅 가능한 가상 IP를 가지고 있다고 가정한다.
인그레스란?
인그레스는 클러스터 외부에서 클러스터 내부 서비스로 HTTP와 HTTPS 경로를 노출한다. 트래픽 라우팅은 인그레스 리소스에 정의된 규칙에 의해 컨트롤된다.
다음은 인그레스가 모든 트래픽을 하나의 서비스로 보내는 간단한 예시이다.

그림. 인그레스
인그레스는 외부에서 서비스로 접속이 가능한 URL, 로드 밸런스 트래픽, SSL / TLS 종료 그리고 이름-기반의 가상 호스팅을 제공하도록 구성할 수 있다. 인그레스 컨트롤러는 일반적으로 로드 밸런서를 사용해서 인그레스를 수행할 책임이 있으며, 트래픽을 처리하는데 도움이 되도록 에지 라우터 또는 추가 프런트 엔드를 구성할 수도 있다.
인그레스는 임의의 포트 또는 프로토콜을 노출시키지 않는다. HTTP와 HTTPS 이외의 서비스를 인터넷에 노출하려면 보통 Service.Type=NodePort 또는 Service.Type=LoadBalancer 유형의 서비스를 사용한다.
전제 조건들
인그레스 컨트롤러가 있어야 인그레스를 충족할 수 있다. 인그레스 리소스만 생성한다면 효과가 없다.
ingress-nginx와 같은 인그레스 컨트롤러를 배포해야 할 수도 있다. 여러 인그레스 컨트롤러 중에서 선택할 수도 있다.
이상적으로, 모든 인그레스 컨트롤러는 참조 사양이 맞아야 한다. 실제로, 다양한 인그레스 컨트롤러는 조금 다르게 작동한다.
참고:
인그레스 컨트롤러의 설명서를 검토하여 선택 시 주의 사항을 이해해야 한다.인그레스 리소스
최소한의 인그레스 리소스 예제:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
인그레스에는 apiVersion, kind, metadata 및 spec 필드가 명시되어야 한다.
인그레스 오브젝트의 이름은 유효한
DNS 서브도메인 이름이어야 한다.
설정 파일의 작성에 대한 일반적인 내용은 애플리케이션 배포하기, 컨테이너 구성하기, 리소스 관리하기를 참조한다.
인그레스는 종종 어노테이션을 이용해서 인그레스 컨트롤러에 따라 몇 가지 옵션을 구성하는데,
그 예시는 재작성-타겟 어노테이션이다.
서로 다른 인그레스 컨트롤러는 서로 다른 어노테이션을 지원한다.
지원되는 어노테이션을 확인하려면 선택한 인그레스 컨트롤러의 설명서를 검토한다.
인그레스 사양 에는 로드 밸런서 또는 프록시 서버를 구성하는데 필요한 모든 정보가 있다. 가장 중요한 것은, 들어오는 요청과 일치하는 규칙 목록을 포함하는 것이다. 인그레스 리소스는 HTTP(S) 트래픽을 지시하는 규칙만 지원한다.
ingressClassName을 생략하려면, 기본 인그레스 클래스가
정의되어 있어야 한다.
몇몇 인그레스 컨트롤러는 기본 IngressClass가 정의되어 있지 않아도 동작한다.
예를 들어, Ingress-NGINX 컨트롤러는 --watch-ingress-without-class
플래그를 이용하여 구성될 수 있다.
하지만 아래에 나와 있는 것과 같이 기본 IngressClass를 명시하는 것을
권장한다.
인그레스 규칙
각 HTTP 규칙에는 다음의 정보가 포함된다.
- 선택적 호스트. 이 예시에서는, 호스트가 지정되지 않기에 지정된 IP 주소를 통해 모든 인바운드 HTTP 트래픽에 규칙이 적용 된다. 만약 호스트가 제공되면(예, foo.bar.com), 규칙이 해당 호스트에 적용된다.
- 경로 목록 (예,
/testpath)에는 각각service.name과service.port.name또는service.port.number가 정의되어 있는 관련 백엔드를 가지고 있다. 로드 밸런서가 트래픽을 참조된 서비스로 보내기 전에 호스트와 경로가 모두 수신 요청의 내용과 일치해야 한다. - 백엔드는 서비스 문서 또는 사용자 정의 리소스 백엔드에 설명된 바와 같이 서비스와 포트 이름의 조합이다. 규칙의 호스트와 경로가 일치하는 인그레스에 대한 HTTP(와 HTTPS) 요청은 백엔드 목록으로 전송된다.
defaultBackend 는 종종 사양의 경로와 일치하지 않는 서비스에 대한 모든 요청을 처리하도록 인그레스
컨트롤러에 구성되는 경우가 많다.
DefaultBackend
규칙이 없는 인그레스는 모든 트래픽을 단일 기본 백엔드로 전송하며,
.spec.defaultBackend는 이와 같은 경우에 요청을 처리할 백엔드를 지정한다.
defaultBackend 는 일반적으로 인그레스 컨트롤러의 구성 옵션이며,
인그레스 리소스에 지정되어 있지 않다.
.spec.rules 가 명시되어 있지 않으면,
.spec.defaultBackend 는 반드시 명시되어 있어야 한다.
defaultBackend 가 설정되어 있지 않으면, 어느 규칙에도 해당되지 않는 요청의 처리는 인그레스 컨트롤러의 구현을 따른다(이러한
경우를 어떻게 처리하는지 알아보려면 해당 인그레스 컨트롤러 문서를 참고한다).
만약 인그레스 오브젝트의 HTTP 요청과 일치하는 호스트 또는 경로가 없으면, 트래픽은 기본 백엔드로 라우팅 된다.
리소스 백엔드
Resource 백엔드는 인그레스 오브젝트와 동일한 네임스페이스 내에 있는
다른 쿠버네티스 리소스에 대한 ObjectRef이다. Resource 는 서비스와
상호 배타적인 설정이며, 둘 다 지정하면 유효성 검사에 실패한다. Resource
백엔드의 일반적인 용도는 정적 자산이 있는 오브젝트 스토리지 백엔드로 데이터를
수신하는 것이다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
위의 인그레스를 생성한 후, 다음의 명령으로 확인할 수 있다.
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
경로 유형
인그레스의 각 경로에는 해당 경로 유형이 있어야 한다. 명시적
pathType 을 포함하지 않는 경로는 유효성 검사에 실패한다. 지원되는
경로 유형은 세 가지이다.
-
ImplementationSpecific: 이 경로 유형의 일치 여부는 IngressClass에 따라 달라진다. 이를 구현할 때 별도pathType으로 처리하거나,Prefix또는Exact경로 유형과 같이 동일하게 처리할 수 있다. -
Exact: URL 경로의 대소문자를 엄격하게 일치시킨다. -
Prefix: URL 경로의 접두사를/를 기준으로 분리한 값과 일치시킨다. 일치는 대소문자를 구분하고, 요소별로 경로 요소에 대해 수행한다. 모든 p 가 요청 경로의 요소별 접두사가 p 인 경우 요청은 p 경로에 일치한다.참고:
경로의 마지막 요소가 요청 경로에 있는 마지막 요소의 하위 문자열인 경우에는 일치하지 않는다(예시:/foo/bar는/foo/bar/baz와 일치하지만,/foo/barbaz와는 일치하지 않는다).
예제
| 종류 | 경로 | 요청 경로 | 일치 여부 |
|---|---|---|---|
| Prefix | / |
(모든 경로) | 예 |
| Exact | /foo |
/foo |
예 |
| Exact | /foo |
/bar |
아니오 |
| Exact | /foo |
/foo/ |
아니오 |
| Exact | /foo/ |
/foo |
아니오 |
| Prefix | /foo |
/foo, /foo/ |
예 |
| Prefix | /foo/ |
/foo, /foo/ |
예 |
| Prefix | /aaa/bb |
/aaa/bbb |
아니오 |
| Prefix | /aaa/bbb |
/aaa/bbb |
예 |
| Prefix | /aaa/bbb/ |
/aaa/bbb |
예, 마지막 슬래시 무시함 |
| Prefix | /aaa/bbb |
/aaa/bbb/ |
예, 마지막 슬래시 일치함 |
| Prefix | /aaa/bbb |
/aaa/bbb/ccc |
예, 하위 경로 일치함 |
| Prefix | /aaa/bbb |
/aaa/bbbxyz |
아니오, 문자열 접두사 일치하지 않음 |
| Prefix | /, /aaa |
/aaa/ccc |
예, /aaa 접두사 일치함 |
| Prefix | /, /aaa, /aaa/bbb |
/aaa/bbb |
예, /aaa/bbb 접두사 일치함 |
| Prefix | /, /aaa, /aaa/bbb |
/ccc |
예, / 접두사 일치함 |
| Prefix | /aaa |
/ccc |
아니오, 기본 백엔드 사용함 |
| Mixed | /foo (Prefix), /foo (Exact) |
/foo |
예, Exact 선호함 |
다중 일치
경우에 따라 인그레스의 여러 경로가 요청과 일치할 수 있다. 이 경우 가장 긴 일치하는 경로가 우선하게 된다. 두 개의 경로가 여전히 동일하게 일치하는 경우 접두사(prefix) 경로 유형보다 정확한(exact) 경로 유형을 가진 경로가 사용 된다.
호스트네임 와일드카드
호스트는 정확한 일치(예: "foo.bar.com") 또는 와일드카드(예:
"* .foo.com")일 수 있다. 정확한 일치를 위해서는 HTTP host 헤더가
host 필드와 일치해야 한다. 와일드카드 일치를 위해서는 HTTP host 헤더가
와일드카드 규칙의 접미사와 동일해야 한다.
| 호스트 | 호스트 헤더 | 일치 여부 |
|---|---|---|
*.foo.com |
bar.foo.com |
공유 접미사를 기반으로 일치함 |
*.foo.com |
baz.bar.foo.com |
일치하지 않음, 와일드카드는 단일 DNS 레이블만 포함함 |
*.foo.com |
foo.com |
일치하지 않음, 와일드카드는 단일 DNS 레이블만 포함함 |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
인그레스 클래스
인그레스는 서로 다른 컨트롤러에 의해 구현될 수 있으며, 종종 다른 구성으로 구현될 수 있다. 각 인그레스에서는 클래스를 구현해야하는 컨트롤러 이름을 포함하여 추가 구성이 포함된 IngressClass 리소스에 대한 참조 클래스를 지정해야 한다.
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
인그레스클래스의 .spec.parameters 필드를 사용하여
해당 인그레스클래스와 연관있는 환경 설정을 제공하는 다른 리소스를 참조할 수 있다.
사용 가능한 파라미터의 상세한 타입은
인그레스클래스의 .spec.parameters 필드에 명시한 인그레스 컨트롤러의 종류에 따라 다르다.
인그레스클래스 범위
인그레스 컨트롤러의 종류에 따라, 클러스터 범위로 설정한 파라미터의 사용이 가능할 수도 있고, 또는 한 네임스페이스에서만 사용 가능할 수도 있다.
인그레스클래스 파라미터의 기본 범위는 클러스터 범위이다.
.spec.parameters 필드만 설정하고 .spec.parameters.scope 필드는 지정하지 않거나,
.spec.parameters.scope 필드를 Cluster로 지정하면,
인그레스클래스는 클러스터 범위의 리소스를 참조한다.
파라미터의 kind(+apiGroup)는
클러스터 범위의 API (커스텀 리소스일 수도 있음) 를 참조하며,
파라미터의 name은
해당 API에 대한 특정 클러스터 범위 리소스를 가리킨다.
예시는 다음과 같다.
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-1
spec:
controller: example.com/ingress-controller
parameters:
# 이 인그레스클래스에 대한 파라미터는 "external-config-1" 라는
# ClusterIngressParameter(API 그룹 k8s.example.net)에 기재되어 있다.
# 이 정의는 쿠버네티스가
# 클러스터 범위의 파라미터 리소스를 검색하도록 한다.
scope: Cluster
apiGroup: k8s.example.net
kind: ClusterIngressParameter
name: external-config-1
기능 상태:
Kubernetes v1.23 [stable]
.spec.parameters 필드를 설정하고
.spec.parameters.scope 필드를 Namespace로 지정하면,
인그레스클래스는 네임스페이스 범위의 리소스를 참조한다.
사용하고자 하는 파라미터가 속한 네임스페이스를
.spec.parameters 의 namespace 필드에 설정해야 한다.
파라미터의 kind(+apiGroup)는
네임스페이스 범위의 API (예: 컨피그맵) 를 참조하며,
파라미터의 name은
namespace에 명시한 네임스페이스의 특정 리소스를 가리킨다.
네임스페이스 범위의 파라미터를 이용하여, 클러스터 운영자가 워크로드에 사용되는 환경 설정(예: 로드 밸런서 설정, API 게이트웨이 정의)에 대한 제어를 위임할 수 있다. 클러스터 범위의 파라미터를 사용했다면 다음 중 하나에 해당된다.
- 다른 팀의 새로운 환경 설정 변경을 적용하려고 할 때마다 클러스터 운영 팀이 매번 승인을 해야 한다. 또는,
- 애플리케이션 팀이 클러스터 범위 파라미터 리소스를 변경할 수 있게 하는 RBAC 롤, 바인딩 등의 특별 접근 제어를 클러스터 운영자가 정의해야 한다.
인그레스클래스 API 자신은 항상 클러스터 범위이다.
네임스페이스 범위의 파라미터를 참조하는 인그레스클래스 예시가 다음과 같다.
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-2
spec:
controller: example.com/ingress-controller
parameters:
# 이 인그레스클래스에 대한 파라미터는
# "external-configuration" 네임스페이스에 있는
# "external-config" 라는 IngressParameter(API 그룹 k8s.example.com)에 기재되어 있다.
scope: Namespace
apiGroup: k8s.example.com
kind: IngressParameter
namespace: external-configuration
name: external-config
사용중단(Deprecated) 어노테이션
쿠버네티스 1.18에 IngressClass 리소스 및 ingressClassName 필드가 추가되기
전에 인그레스 클래스는 인그레스에서
kubernetes.io/ingress.class 어노테이션으로 지정되었다. 이 어노테이션은
공식적으로 정의된 것은 아니지만, 인그레스 컨트롤러에서 널리 지원되었었다.
인그레스의 최신 ingressClassName 필드는 해당 어노테이션을
대체하지만, 직접적으로 해당하는 것은 아니다. 어노테이션은 일반적으로
인그레스를 구현해야 하는 인그레스 컨트롤러의 이름을 참조하는 데 사용되었지만,
이 필드는 인그레스 컨트롤러의 이름을 포함하는 추가 인그레스 구성이
포함된 인그레스 클래스 리소스에 대한 참조이다.
기본 IngressClass
특정 IngressClass를 클러스터의 기본 값으로 표시할 수 있다. IngressClass
리소스에서 ingressclass.kubernetes.io/is-default-class 를 true 로
설정하면 ingressClassName 필드가 지정되지 않은
새 인그레스에게 기본 IngressClass가 할당된다.
주의:
클러스터의 기본값으로 표시된 IngressClass가 두 개 이상 있는 경우 어드미션 컨트롤러에서ingressClassName 이 지정되지 않은
새 인그레스 오브젝트를 생성할 수 없다. 클러스터에서 최대 1개의 IngressClass가
기본값으로 표시하도록 해서 이 문제를 해결할 수 있다.몇몇 인그레스 컨트롤러는 기본 IngressClass가 정의되어 있지 않아도 동작한다.
예를 들어, Ingress-NGINX 컨트롤러는 --watch-ingress-without-class
플래그를 이용하여 구성될 수 있다.
하지만 다음과 같이 기본 IngressClass를 명시하는 것을
권장한다.
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
name: nginx-example
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
spec:
controller: k8s.io/ingress-nginx
인그레스 유형들
단일 서비스로 지원되는 인그레스
단일 서비스를 노출할 수 있는 기존 쿠버네티스 개념이 있다 (대안을 본다). 인그레스에 규칙 없이 기본 백엔드 를 지정해서 이를 수행할 수 있다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
spec:
defaultBackend:
service:
name: test
port:
number: 80
만약 kubectl apply -f 를 사용해서 생성한다면 추가한 인그레스의
상태를 볼 수 있어야 한다.
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
여기서 203.0.113.123 는 인그레스 컨트롤러가 인그레스를 충족시키기 위해
할당한 IP 이다.
참고:
인그레스 컨트롤러와 로드 밸런서는 IP 주소를 할당하는데 1~2분이 걸릴 수 있다. 할당될 때 까지는 주소는 종종<pending> 으로 표시된다.간단한 팬아웃(fanout)
팬아웃 구성은 HTTP URI에서 요청된 것을 기반으로 단일 IP 주소에서 1개 이상의 서비스로 트래픽을 라우팅 한다. 인그레스를 사용하면 로드 밸런서의 수를 최소로 유지할 수 있다. 예를 들어 다음과 같은 설정을 한다.

그림. 인그레스 팬아웃
다음과 같은 인그레스가 필요하다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
kubectl apply -f 를 사용해서 인그레스를 생성 할 때 다음과 같다.
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
인그레스 컨트롤러는 서비스(service1, service2)가 존재하는 한,
인그레스를 만족시키는 특정한 로드 밸런서를 프로비저닝한다.
이렇게 하면, 주소 필드에서 로드 밸런서의 주소를
볼 수 있다.
이름 기반의 가상 호스팅
이름 기반의 가상 호스트는 동일한 IP 주소에서 여러 호스트 이름으로 HTTP 트래픽을 라우팅하는 것을 지원한다.

그림. 이름 기반의 가상 호스팅 인그레스
다음 인그레스는 호스트 헤더에 기반한 요청을 라우팅 하기 위해 뒷단의 로드 밸런서를 알려준다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
만약 규칙에 정의된 호스트 없이 인그레스 리소스를 생성하는 경우, 이름 기반 가상 호스트가 없어도 인그레스 컨트롤러의 IP 주소에 대한 웹 트래픽을 일치 시킬 수 있다.
예를 들어, 다음 인그레스는 first.bar.com에 요청된 트래픽을
service1로, second.bar.com는 service2로, 그리고 요청 헤더가 first.bar.com 또는 second.bar.com에 해당되지 않는 모든 트래픽을 service3로 라우팅한다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress-no-third-host
spec:
rules:
- host: first.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: second.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service3
port:
number: 80
TLS
TLS 개인 키 및 인증서가 포함된 시크릿(Secret)을
지정해서 인그레스를 보호할 수 있다. 인그레스 리소스는
단일 TLS 포트인 443만 지원하고 인그레스 지점에서 TLS 종료를
가정한다(서비스 및 해당 파드에 대한 트래픽은 일반 텍스트임).
인그레스의 TLS 구성 섹션에서 다른 호스트를 지정하면, SNI TLS 확장을 통해
지정된 호스트이름에 따라 동일한 포트에서 멀티플렉싱
된다(인그레스 컨트롤러가 SNI를 지원하는 경우). TLS secret에는
tls.crt 와 tls.key 라는 이름의 키가 있어야 하고, 여기에는 TLS에 사용할 인증서와
개인 키가 있다. 예를 들어 다음과 같다.
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 encoded cert
tls.key: base64 encoded key
type: kubernetes.io/tls
인그레스에서 시크릿을 참조하면 인그레스 컨트롤러가 TLS를 사용하여
클라이언트에서 로드 밸런서로 채널을 보호하도록 지시한다. 생성한
TLS 시크릿이 https-example.foo.com 의 정규화 된 도메인 이름(FQDN)이라고
하는 일반 이름(CN)을 포함하는 인증서에서 온 것인지 확인해야 한다.
참고:
가능한 모든 하위 도메인에 대해 인증서가 발급되어야 하기 때문에 TLS는 기본 규칙에서 작동하지 않는다. 따라서tls 섹션의 hosts는 rules섹션의 host와 명시적으로 일치해야
한다.apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
참고:
TLS 기능을 제공하는 다양한 인그레스 컨트롤러간의 기능 차이가 있다. 사용자 환경에서의 TLS의 작동 방식을 이해하려면 nginx, GCE 또는 기타 플랫폼의 특정 인그레스 컨트롤러에 대한 설명서를 참조한다.로드 밸런싱
인그레스 컨트롤러는 로드 밸런싱 알고리즘, 백엔드 가중치 구성표 등 모든 인그레스에 적용되는 일부 로드 밸런싱 정책 설정으로 부트스트랩된다. 보다 진보된 로드 밸런싱 개념 (예: 지속적인 세션, 동적 가중치)은 아직 인그레스를 통해 노출되지 않는다. 대신 서비스에 사용되는 로드 밸런서를 통해 이러한 기능을 얻을 수 있다.
또한, 헬스 체크를 인그레스를 통해 직접 노출되지 않더라도, 쿠버네티스에는 준비 상태 프로브와 같은 동일한 최종 결과를 얻을 수 있는 병렬 개념이 있다는 점도 주목할 가치가 있다. 컨트롤러 별 설명서를 검토하여 헬스 체크를 처리하는 방법을 확인한다(예: nginx, 또는 GCE).
인그레스 업데이트
기존 인그레스를 업데이트해서 새 호스트를 추가하려면, 리소스를 편집해서 호스트를 업데이트 할 수 있다.
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
YAML 형식의 기존 구성이 있는 편집기가 나타난다. 새 호스트를 포함하도록 수정한다.
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
service:
name: service1
port:
number: 80
path: /foo
pathType: Prefix
- host: bar.baz.com
http:
paths:
- backend:
service:
name: service2
port:
number: 80
path: /foo
pathType: Prefix
..
변경사항을 저장한 후, kubectl은 API 서버의 리소스를 업데이트하며, 인그레스 컨트롤러에게도 로드 밸런서를 재구성하도록 지시한다.
이것을 확인한다.
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
수정된 인그레스 YAML 파일을 kubectl replace -f 를 호출해서 동일한 결과를 얻을 수 있다.
가용성 영역에 전체에서의 실패
장애 도메인에 트래픽을 분산시키는 기술은 클라우드 공급자마다 다르다. 자세한 내용은 인그레스 컨트롤러 설명서를 확인한다.
대안
사용자는 인그레스 리소스를 직접적으로 포함하지 않는 여러가지 방법으로 서비스를 노출할 수 있다.
다음 내용
- 인그레스 API에 대해 배우기
- 인그레스 컨트롤러에 대해 배우기
- NGINX 컨트롤러로 Minikube에서 인그레스 구성하기
6.3 - 인그레스 컨트롤러
클러스터 내의 인그레스가 작동하려면, 인그레스 컨트롤러가 실행되고 있어야 한다. 적어도 하나의 인그레스 컨트롤러를 선택하고 이를 클러스터 내에 설치한다. 이 페이지는 배포할 수 있는 일반적인 인그레스 컨트롤러를 나열한다.
인그레스 리소스가 작동하려면, 클러스터는 실행 중인 인그레스 컨트롤러가 반드시 필요하다.
kube-controller-manager 바이너리의 일부로 실행되는 컨트롤러의 다른 타입과 달리 인그레스 컨트롤러는
클러스터와 함께 자동으로 실행되지 않는다.
클러스터에 가장 적합한 인그레스 컨트롤러 구현을 선택하는데 이 페이지를 사용한다.
프로젝트로서 쿠버네티스는 AWS, GCE와 nginx 인그레스 컨트롤러를 지원하고 유지한다.
추가 컨트롤러
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
- AKS 애플리케이션 게이트웨이 인그레스 컨트롤러는 Azure 애플리케이션 게이트웨이를 구성하는 인그레스 컨트롤러다.
- Ambassador API 게이트웨이는 Envoy 기반 인그레스 컨트롤러다.
- Apache APISIX 인그레스 컨트롤러는 Apache APISIX 기반의 인그레스 컨트롤러이다.
- Avi 쿠버네티스 오퍼레이터는 VMware NSX Advanced Load Balancer을 사용하는 L4-L7 로드 밸런싱을 제공한다.
- BFE Ingress Controller는 BFE 기반 인그레스 컨트롤러다.
- Citrix 인그레스 컨트롤러는 Citrix 애플리케이션 딜리버리 컨트롤러에서 작동한다.
- Contour는 Envoy 기반 인그레스 컨트롤러다.
- EnRoute는 인그레스 컨트롤러로 실행할 수 있는 Envoy 기반 API 게이트웨이다.
- Easegress IngressController는 인그레스 컨트롤러로서 실행할 수 있는 Easegress 기반 API 게이트웨이다.
- F5 BIG-IP 쿠버네티스 용 컨테이너 인그레스 서비스를 이용하면 인그레스를 사용하여 F5 BIG-IP 가상 서버를 구성할 수 있다.
- Gloo는 API 게이트웨이 기능을 제공하는 Envoy 기반의 오픈소스 인그레스 컨트롤러다.
- HAProxy 인그레스는 HAProxy의 인그레스 컨트롤러다.
- 쿠버네티스 용 HAProxy 인그레스 컨트롤러는 HAProxy 용 인그레스 컨트롤러이기도 하다.
- Istio 인그레스는 Istio 기반 인그레스 컨트롤러다.
- 쿠버네티스 용 Kong 인그레스 컨트롤러는 Kong 게이트웨이를 구동하는 인그레스 컨트롤러다.
- Kusk 게이트웨이는 OpenAPI 중심의 Envoy 기반 인그레스 컨트롤러다.
- 쿠버네티스 용 NGINX 인그레스 컨트롤러는 NGINX 웹서버(프록시로 사용)와 함께 작동한다.
- Pomerium 인그레스 컨트롤러는 Pomerium 기반 인그레스 컨트롤러이며, 상황 인지 접근 정책을 제공한다.
- Skipper는 사용자의 커스텀 프록시를 구축하기 위한 라이브러리로 설계된 쿠버네티스 인그레스와 같은 유스케이스를 포함한 서비스 구성을 위한 HTTP 라우터 및 역방향 프록시다.
- Traefik 쿠버네티스 인그레스 제공자는 Traefik 프록시 용 인그레스 컨트롤러다.
- Tyk 오퍼레이터는 사용자 지정 리소스로 인그레스를 확장하여 API 관리 기능을 인그레스로 가져온다. Tyk 오퍼레이터는 오픈 소스 Tyk 게이트웨이 및 Tyk 클라우드 컨트롤 플레인과 함께 작동한다.
- Voyager는 HAProxy의 인그레스 컨트롤러다.
여러 인그레스 컨트롤러 사용
하나의 클러스터 내에 인그레스 클래스를 이용하여 여러 개의 인그레스 컨트롤러를 배포할 수 있다.
.metadata.name 필드를 확인해둔다. 인그레스를 생성할 때 인그레스 오브젝트(IngressSpec v1 참고)의 ingressClassName 필드에 해당 이름을 명시해야 한다. ingressClassName은 이전 어노테이션 방식의 대체 수단이다.
인그레스에 대한 인그레스 클래스를 설정하지 않았고, 클러스터에 기본으로 설정된 인그레스 클래스가 정확히 하나만 존재하는 경우, 쿠버네티스는 클러스터의 기본 인그레스 클래스를 인그레스에 적용한다.
인그레스 클래스에 ingressclass.kubernetes.io/is-default-class 어노테이션을 문자열 값 "true"로 설정하여, 해당 인그레스 클래스를 기본으로 설정할 수 있다.
이상적으로는 모든 인그레스 컨트롤러가 이 사양을 충족해야 하지만, 다양한 인그레스 컨트롤러는 약간 다르게 작동한다.
참고:
인그레스 컨트롤러의 설명서를 검토하여 선택 시 주의 사항을 이해해야 한다.다음 내용
- 인그레스에 대해 자세히 알아보기.
- NGINX 컨트롤러로 Minikube에서 인그레스를 설정하기.
6.4 - 엔드포인트슬라이스
엔드포인트슬라이스 API는 서비스가 대규모 백엔드를 처리할 수 있도록 확장할 수 있게 해주고, 클러스터가 정상적인 백엔드의 리스트를 효율적으로 업데이트 할 수 있도록 쿠버네티스가 사용하는 메커니즘이다.
기능 상태:
Kubernetes v1.21 [stable]
쿠버네티스의 엔드포인트슬라이스 API 는 쿠버네티스 클러스터 내의 네트워크 엔드포인트를 추적하는 방법을 제공한다. 엔드포인트슬라이스는 엔드포인트보다 더 유동적이고, 확장 가능한 대안을 제안한다.
엔드포인트슬라이스 API
쿠버네티스에서 엔드포인트슬라이스는 일련의 네트워크 엔드포인트에 대한 참조를 포함한다. 쿠버네티스 서비스에 셀렉터가 지정되면 컨트롤 플레인은 자동으로 엔드포인트슬라이스를 생성한다. 이 엔드포인트슬라이스는 서비스 셀렉터와 매치되는 모든 파드들을 포함하고 참조한다. 엔드포인트슬라이스는 프로토콜, 포트 번호 및 서비스 이름의 고유한 조합을 통해 네트워크 엔드포인트를 그룹화한다. 엔드포인트슬라이스 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
예를 들어, 여기에 example 쿠버네티스 서비스가 소유하는 엔드포인트슬라이스
객체 샘플이 있다.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
기본적으로, 컨트롤 플레인은 각각 100개 이하의 엔드포인트를
갖도록 엔드포인트슬라이스를
생성하고 관리한다. --max-endpoints-per-slice
kube-controller-manager
플래그를 사용하여, 최대 1000개까지 구성할 수 있다.
엔드포인트슬라이스는 내부 트래픽을 라우트하는 방법에 대해 kube-proxy에 신뢰할 수 있는 소스로 역할을 할 수 있다.
주소 유형
엔드포인트슬라이스는 다음 주소 유형을 지원한다.
- IPv4
- IPv6
- FQDN (전체 주소 도메인 이름)
각 엔드포인트슬라이스 객체는 특정한 IP 주소 유형을 나타낸다. IPv4와 IPv6를 사용할 수 있는 서비스가 있을 경우, 최소 두개의 엔드포인트슬라이스 객체가 존재한다(IPv4를 위해 하나, IPv6를 위해 하나).
컨디션
엔드포인트슬라이스 API는 컨슈머에게 유용한 엔드포인트에 대한 조건을 저장한다.
조건은 ready, serving 및 Terminating 세 가지가 있다.
Ready
ready는 파드의 Ready 조건에 매핑되는 조건이다. Ready 조건이 True로 설정된 실행 중인 파드는
이 엔드포인트슬라이스 조건도 true로 설정되어야 한다. 호환성의
이유로, 파드가 종료될 때 ready는 절대 true가 되면 안 된다. 컨슈머는 serving 조건을 참조하여
파드 종료 준비 상태(readiness)를 검사해야 한다.
이 규칙의 유일한 예외는 spec.publishNotReadyAddresses가 true로 설정된 서비스이다.
이러한 서비스의 엔드 포인트는 항상 ready조건이 true로 설정된다.
Serving
기능 상태:
Kubernetes v1.22 [beta]
serving은 종료 상태를 고려하지 않는다는 점을 제외하면 ready 조건과 동일하다.
엔드포인트슬라이스 API 컨슈머는 파드가 종료되는 동안 파드 준비 상태에 관심이 있다면
이 조건을 확인해야 한다.
참고:
serving은 ready와 거의 동일하지만 ready의 기존 의미가 깨지는 것을 방지하기 위해 추가되었다.
엔드포인트를 종료하기 위해 ready가 true 일 수 있다면 기존 클라이언트에게는 예상치 못한 일이 될 수 있다.
역사적으로 종료된 엔드포인트는 처음부터 엔드포인트 또는 엔드포인트슬라이스 API에 포함되지 않았기 때문이다.
이러한 이유로 ready는 엔드포인트 종료를 위해 always false이며,
클라이언트가 ready에 대한 기존 의미와 관계없이 파드 종료 준비 상태를
추적 할 수 있도록 v1.20에 새로운 조건 serving이 추가되었다.Terminating
기능 상태:
Kubernetes v1.22 [beta]
종료(Terminating)는 엔드포인트가 종료되는지 여부를 나타내는 조건이다.
파드의 경우 삭제 타임 스탬프가 설정된 모든 파드이다.
토폴로지 정보
엔드포인트슬라이스 내의 각 엔드 포인트는 관련 토폴로지 정보를 포함할 수 있다. 토폴로지 정보에는 엔드 포인트의 위치와 해당 노드 및 영역에 대한 정보가 포함된다. 엔드포인트슬라이스의 다음의 엔드 포인트별 필드에서 사용할 수 있다.
*nodeName - 이 엔드 포인트가 있는 노드의 이름이다.
*zone - 이 엔드 포인트가 있는 영역이다.
참고:
v1 API에서는, 전용 필드 nodeName 및 zone 을 위해 엔드 포인트별
topology 가 효과적으로 제거되었다.
EndpointSlice 리소스의 endpoint 필드에 임의의 토폴로지 필드를 설정하는 것은
더 이상 사용되지 않으며 v1 API에서 지원되지 않는다.
대신, v1 API는 개별 nodeName 및 zone 필드 설정을 지원한다.
이러한 필드는 API 버전 간에 자동으로 번역된다.
예를 들어, v1beta1 API의 topology 필드에 있는 "topology.kubernetes.io/zone" 키 값은
v1 API의 zone 필드로 접근할 수 있다.
관리
대부분의 경우, 컨트롤 플레인(특히, 엔드포인트슬라이스 컨트롤러)는 엔드포인트슬라이스 오브젝트를 생성하고 관리한다. 다른 엔티티나 컨트롤러가 추가 엔드포인트슬라이스 집합을 관리하게 할 수 있는 서비스 메시 구현과 같이 엔드포인트슬라이스에 대한 다양한 다른 유스케이스가 있다.
여러 엔티티가 서로 간섭하지 않고 엔드포인트슬라이스를
관리할 수 있도록 쿠버네티스는 엔드포인트슬라이스를 관리하는
엔티티를 나타내는 endpointslice.kubernetes.io/managed-by
레이블을
정의한다.
엔드포인트슬라이스 컨트롤러는 관리하는 모든 엔드포인트슬라이스에 레이블의 값으로
endpointslice-controller.k8s.io 를 설정한다. 엔드포인트슬라이스를
관리하는 다른 엔티티도 이 레이블에 고유한 값을 설정해야 한다.
소유권
대부분의 유스케이스에서, 엔드포인트슬라이스 오브젝트가 엔드포인트를
추적하는 서비스가 엔드포인트슬라이스를 소유한다. 이 소유권은 각 엔드포인트슬라이스의 소유자
참조와 서비스에 속한 모든 엔드포인트슬라이스의 간단한 조회를 가능하게 하는
kubernetes.io/service-name 레이블로 표시된다.
엔드포인트슬라이스 미러링
경우에 따라, 애플리케이션이 사용자 지정 엔드포인트 리소스를 생성한다. 이러한 애플리케이션이 엔드포인트와 엔드포인트슬라이스 리소스에 동시에 쓸 필요가 없도록 클러스터의 컨트롤 플레인은 대부분의 엔드포인트 리소스를 해당 엔드포인트슬라이스에 미러링한다.
컨트롤 플레인은 다음을 제외하고 엔드포인트 리소스를 미러링한다.
- 엔드포인트 리소스에는
endpointslice.kubernetes.io/skip-mirror레이블이true로 설정되어 있다. - 엔드포인트 리소스에는
control-plane.alpha.kubernetes.io/leader어노테이션이 있다. - 해당 서비스 리소스가 존재하지 않는다.
- 해당 서비스 리소스에 nil이 아닌 셀렉터가 있다.
개별 엔드포인트 리소스는 여러 엔드포인트슬라이스로 변환될 수 있다. 엔드포인트 리소스에 여러 하위 집합이 있거나 여러 IP 제품군(IPv4 및 IPv6)이 있는 엔드포인트가 포함된 경우 변환이 일어난다. 하위 집합 당 최대 1000개의 주소가 엔드포인트슬라이스에 미러링된다.
엔드포인트슬라이스의 배포
각 엔드포인트슬라이스에는 리소스 내에 모든 엔드포인트가 적용되는 포트 집합이 있다. 서비스에 알려진 포트를 사용하는 경우 파드는 동일하게 알려진 포트에 대해 다른 대상 포트 번호로 끝날 수 있으며 다른 엔드포인트슬라이스가 필요하다. 이는 하위 집합이 엔드포인트와 그룹화하는 방식의 논리와 유사하다.
컨트롤 플레인은 엔드포인트슬라이스를 최대한 채우려고 노력하지만, 적극적으로 재조정하지는 않는다. 로직은 매우 직관적이다.
- 기존 엔드포인트슬라이스에 대해 반복적으로, 더 이상 필요하지 않는 엔드포인트를 제거하고 변경에 의해 일치하는 엔드포인트를 업데이트 한다.
- 첫 번째 단계에서 수정된 엔드포인트슬라이스를 반복해서 필요한 새 엔드포인트로 채운다.
- 추가할 새 엔드포인트가 여전히 남아있으면, 이전에 변경되지 않은 슬라이스에 엔드포인트를 맞추거나 새로운 것을 생성한다.
중요한 것은, 세 번째 단계는 엔드포인트슬라이스를 완벽하게 전부 배포하는 것보다 엔드포인트슬라이스 업데이트 제한을 우선시한다. 예를 들어, 추가할 새 엔드포인트가 10개이고 각각 5개의 공간을 사용할 수 있는 엔드포인트 공간이 있는 2개의 엔드포인트슬라이스가 있는 경우, 이 방법은 기존 엔드포인트슬라이스 2개를 채우는 대신에 새 엔드포인트슬라이스를 생성한다. 다른 말로, 단일 엔드포인트슬라이스를 생성하는 것이 여러 엔드포인트슬라이스를 업데이트하는 것 보다 더 선호된다.
각 노드에서 kube-proxy를 실행하고 엔드포인트슬라이스를 관찰하면, 엔드포인트슬라이스에 대한 모든 변경 사항이 클러스터의 모든 노드로 전송되기 때문에 상대적으로 비용이 많이 소요된다. 이 방법은 여러 엔드포인트슬라이스가 가득 차지 않은 결과가 발생할지라도, 모든 노드에 전송해야 하는 변경 횟수를 의도적으로 제한하기 위한 것이다.
실제로는, 이러한 이상적이지 않은 분배는 드물 것이다. 엔드포인트슬라이스 컨트롤러에서 처리하는 대부분의 변경 내용은 기존 엔드포인트슬라이스에 적합할 정도로 적고, 그렇지 않은 경우 새 엔드포인트슬라이스가 필요할 수 있다. 디플로이먼트의 롤링 업데이트도 모든 파드와 해당 교체되는 엔드포인트에 대해서 엔드포인트슬라이스를 자연스럽게 재포장한다.
중복 엔드포인트
엔드포인트슬라이스 변경의 특성으로 인해, 엔드포인트는 동시에 둘 이상의 엔드포인트슬라이스에 표시될 수 있다. 이는 다른 엔드포인트슬라이스 오브젝트에 대한 변경 사항이 다른 시간에서의 쿠버네티스 클라이언트 워치(watch)/캐시에 도착할 수 있기 때문에 자연스럽게 발생한다.
참고:
엔드포인트슬라이스 API의 클라이언트는 반드시 서비스에 연관된 모든 존재하는 엔드포인트슬라이스에 대해 반복하고, 고유한 각 네트워크 엔드포인트들의 완전한 리스트를 구성해야 한다. 엔드포인트는 다른 엔드포인트슬라이스에서 중복될 수 있음에 유의한다.
엔드포인트 집계와 중복 제거 방법에 대한 레퍼런스 구현은 kube-proxy 의
EndpointSliceCache 구현에서 찾을 수 있다.
엔드포인트와 비교
기존 엔드포인트 API는 쿠버네티스에서 네트워크 엔드포인트를 추적하는 간단하고 직접적인 방법을 제공했다. 쿠버네티스 클러스터와 서비스가 더 많은 수의 백엔드 파드로 더 많은 트래픽을 처리하고 전송하는 방향으로 성장함에 따라, 이 API의 한계가 더욱 눈에 띄게 되었다. 특히나, 많은 수의 네트워크 엔드포인트로 확장하는 것에 어려움이 있었다.
서비스에 대한 모든 네트워크 엔드포인트가 단일 엔드포인트 객체에 저장되기 때문에 이러한 엔드포인트 객체들이 상당히 커지는 경우도 있었다. 안정적인 서비스(오랜 기간 동안 같은 엔드포인트 세트)의 경우 영향은 비교적 덜 눈에 띄지만, 여전히 쿠버네티스의 일부 사용 사례들은 잘 처리되지 않았다.
서비스가 많은 백엔드 엔드포인트를 가지고 워크로드가 자주 증가하거나, 새로운 변경사항이 자주 롤 아웃 될 경우, 해당 서비스의 단일 엔드포인트 객체에 대한 각 업데이트는 쿠버네티스 클러스터 컴포넌트 사이(컨트롤 플레인 내, 그리고 노드와 API 서버 사이)에 상당한 네트워크 트래픽이 발생할 것임을 의미했다. 이러한 추가 트래픽은 또한 CPU 사용 관점에서도 굉장한 비용을 발생시켰다.
엔드포인트슬라이스 사용 시, 단일 파드를 추가하거나 삭제하는 작업은 (다수의 파드를 추가/삭제하는 작업과 비교했을 때) 해당 변경을 감시하고 있는 클라이언트에 동일한 _수_의 업데이트를 트리거한다. 하지만, 파드 대규모 추가/삭제의 경우 업데이트 메시지의 크기는 훨씬 작다.
엔드포인트슬라이스는 듀얼 스택 네트워킹과 토폴로지 인식 라우팅과 같은 새로운 기능에 대한 혁신을 가능하게 했다.
다음 내용
- 서비스와 애플리케이션 연결하기 튜토리얼을 따라하기
- 엔드포인트슬라이스 API 레퍼런스 를 읽어보기
- 엔드포인트 API 레퍼런스 를 읽어보기
6.5 - 네트워크 정책
IP 주소 또는 포트 수준(OSI 계층 3 또는 4)에서 트래픽 흐름을 제어하려는 경우, 네트워크 정책은 클러스터 내의 트래픽 흐름뿐만 아니라 파드와 외부 간의 규칙을 정의할 수 있도록 해준다. 클러스터는 반드시 네트워크 정책을 지원하는 네트워크 플러그인을 사용해야 한다.
IP 주소 또는 포트 수준(OSI 계층 3 또는 4)에서 트래픽 흐름을 제어하려는 경우, 클러스터의 특정 애플리케이션에 대해 쿠버네티스 네트워크폴리시(NetworkPolicy) 사용을 고려할 수 있다. 네트워크폴리시는 파드가 네트워크 상의 다양한 네트워크 "엔티티"(여기서는 "엔티티"를 사용하여 쿠버네티스에서 특별한 의미로 사용되는 "엔드포인트" 및 "서비스"와 같은 일반적인 용어가 중의적으로 표현되는 것을 방지함)와 통신할 수 있도록 허용하는 방법을 지정할 수 있는 애플리케이션 중심 구조이다. 네트워크폴리시는 한쪽 또는 양쪽 종단이 파드인 연결에만 적용되며, 다른 연결에는 관여하지 않는다.
파드가 통신할 수 있는 엔티티는 다음 3개의 식별자 조합을 통해 식별된다.
- 허용되는 다른 파드(예외: 파드는 자신에 대한 접근을 차단할 수 없음)
- 허용되는 네임스페이스
- IP 블록(예외: 파드 또는 노드의 IP 주소와 관계없이 파드가 실행 중인 노드와의 트래픽은 항상 허용됨)
pod- 또는 namespace- 기반의 네트워크폴리시를 정의할 때, 셀렉터를 사용하여 셀렉터와 일치하는 파드와 주고받는 트래픽을 지정한다.
한편, IP 기반의 네트워크폴리시가 생성되면, IP 블록(CIDR 범위)을 기반으로 정책을 정의한다.
전제 조건
네트워크 정책은 네트워크 플러그인으로 구현된다. 네트워크 정책을 사용하려면 네트워크폴리시를 지원하는 네트워킹 솔루션을 사용해야만 한다. 이를 구현하는 컨트롤러 없이 네트워크폴리시 리소스를 생성해도 아무런 효과가 없기 때문이다.
파드 격리의 두 가지 종류
파드 격리에는 이그레스에 대한 격리와 인그레스에 대한 격리의 두 가지 종류가 있다. 이들은 어떤 연결이 성립될지에 대해 관여한다. 여기서 "격리"는 절대적인 것이 아니라, "일부 제한이 적용됨"을 의미한다. 반대말인 "이그레스/인그레스에 대한 비격리"는 각 방향에 대해 제한이 적용되지 않음을 의미한다. 두 종류의 격리(또는 비격리)는 독립적으로 선언되며, 두 종류 모두 파드 간 연결과 연관된다.
기본적으로, 파드는 이그레스에 대해 비격리되어 있다. 즉, 모든 아웃바운드 연결이 허용된다. 해당 파드에 적용되면서 policyTypes에 "Egress"가 있는 NetworkPolicy가 존재하는 경우, 파드가 이그레스에 대해 격리된다. 이러한 정책은 파드의 이그레스에 적용된다고 말한다. 파드가 이그레스에 대해 격리되면, 파드에서 나가는 연결 중에서 파드의 이그레스에 적용된 NetworkPolicy의 egress 리스트에 허용된 연결만이 허용된다. egress 리스트 각 항목의 효과는 합산되어 적용된다.
기본적으로, 파드는 인그레스에 대해 비격리되어 있다. 즉, 모든 인바운드 연결이 허용된다. 해당 파드에 적용되면서 policyTypes에 "Ingress"가 있는 NetworkPolicy가 존재하는 경우, 파드가 인그레스에 대해 격리된다. 이러한 정책은 파드의 인그레스에 적용된다고 말한다. 파드가 인그레스에 대해 격리되면, 파드로 들어오는 연결 중에서 파드의 인그레스에 적용된 NetworkPolicy의 ingress 리스트에 허용된 연결만이 허용된다. ingress 리스트 각 항목의 효과는 합산되어 적용된다.
네트워크 폴리시가 충돌하는 경우는 없다. 네트워크 폴리시는 합산되어 적용된다. 특정 파드의 특정 방향에 대해 하나 또는 여러 개의 폴리시가 적용되면, 해당 파드의 해당 방향에 대해 허용된 연결은 모든 폴리시가 허용하는 연결의 합집합이다. 따라서, 판별 순서는 폴리시 결과에 영향을 미치지 않는다.
송신 파드에서 수신 파드로의 연결이 허용되기 위해서는, 송신 파드의 이그레스 폴리시와 수신 파드의 인그레스 폴리시가 해당 연결을 허용해야 한다. 만약 어느 한 쪽이라도 해당 연결을 허용하지 않으면, 연결이 되지 않을 것이다.
네트워크폴리시 리소스
리소스에 대한 전체 정의에 대한 참조는 네트워크폴리시 를 본다.
네트워크폴리시 의 예시는 다음과 같다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
참고:
선택한 네트워킹 솔루션이 네트워킹 정책을 지원하지 않으면 클러스터의 API 서버에 이를 POST 하더라도 효과가 없다.필수 필드들: 다른 모든 쿠버네티스 설정과 마찬가지로 네트워크폴리시 에는
apiVersion, kind, 그리고 metadata 필드가 필요하다. 구성 파일
작업에 대한 일반적인 정보는
컨피그맵을 사용하도록 파드 구성하기,
그리고 오브젝트 관리 를 본다.
spec: 네트워크폴리시 사양에는 지정된 네임스페이스에서 특정 네트워크 정책을 정의하는데 필요한 모든 정보가 있다.
podSelector: 각 네트워크폴리시에는 정책이 적용되는 파드 그룹을 선택하는 podSelector 가 포함된다. 예시 정책은 "role=db" 레이블이 있는 파드를 선택한다. 비어있는 podSelector 는 네임스페이스의 모든 파드를 선택한다.
policyTypes: 각 네트워크폴리시에는 Ingress, Egress 또는 두 가지 모두를 포함할 수 있는 policyTypes 목록이 포함된다. policyTypes 필드는 선택한 파드에 대한 인그레스 트래픽 정책, 선택한 파드에 대한 이그레스 트래픽 정책 또는 두 가지 모두에 지정된 정책의 적용 여부를 나타낸다. 만약 네트워크폴리시에 policyTypes 가 지정되어 있지 않으면 기본적으로 Ingress 가 항상 설정되고, 네트워크폴리시에 Egress 가 있으면 이그레스 규칙이 설정된다.
ingress: 각 네트워크폴리시에는 화이트리스트 ingress 규칙 목록이 포함될 수 있다. 각 규칙은 from 과 ports 부분과 모두 일치하는 트래픽을 허용한다. 예시 정책에는 단일 규칙이 포함되어 있는데 첫 번째 포트는 ipBlock 을 통해 지정되고, 두 번째는 namespaceSelector 를 통해 그리고 세 번째는 podSelector 를 통해 세 가지 소스 중 하나의 단일 포트에서 발생하는 트래픽과 일치 시킨다.
egress: 각 네트워크폴리시에는 화이트리스트 egress 규칙이 포함될 수 있다. 각 규칙은 to 와 ports 부분과 모두 일치하는 트래픽을 허용한다. 예시 정책에는 단일 포트의 트래픽을 10.0.0.0/24 의 모든 대상과 일치시키는 단일 규칙을 포함하고 있다.
따라서 예시의 네트워크폴리시는 다음과 같이 동작한다.
-
인그레스 및 이그레스 트래픽에 대해 "default" 네임스페이스에서 "role=db"인 파드를 격리한다(아직 격리되지 않은 경우).
-
(인그레스 규칙)은 "role=db" 레이블을 사용하는 "default" 네임스페이스의 모든 파드에 대해서 TCP 포트 6379로의 연결을 허용한다. 인그레스을 허용 할 대상은 다음과 같다.
- "role=frontend" 레이블이 있는 "default" 네임스페이스의 모든 파드
- 네임스페이스와 "project=myproject" 를 레이블로 가지는 모든 파드
- 172.17.0.0–172.17.0.255 와 172.17.2.0–172.17.255.255 의 범위를 가지는 IP 주소(예: 172.17.0.0/16 전체에서 172.17.1.0/24 를 제외)
-
(이그레스 규칙)은 "role=db" 레이블이 있는 "default" 네임스페이스의 모든 파드에서 TCP 포트 5978의 CIDR 10.0.0.0/24 로의 연결을 허용한다.
자세한 설명과 추가 예시는 네트워크 정책 선언을 본다.
to 및 from 셀럭터의 동작
ingress from 부분 또는 egress to 부분에 지정할 수 있는 네 종류의 셀렉터가 있다.
podSelector: 네트워크폴리시를 통해서, 인그레스 소스 또는 이그레스 목적지로 허용되야 하는 동일한 네임스페이스에 있는 특정 파드들을 선택한다.
namespaceSelector: 모든 파드가 인그레스 소스 또는 이그레스를 대상으로 허용되어야 하는 특정 네임스페이스를 선택한다.
namespaceSelector 와 podSelector: namespaceSelector 와 podSelector 를 모두 지정하는 단일 to/from 항목은 특정 네임스페이스 내에서 특정 파드를 선택한다. 올바른 YAML 구문을 사용하도록 주의해야 한다. 이 정책:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
...
네임스페이스에서 레이블이 role=client 인 것과 레이블이 user=alice 인 파드의 연결을 허용하는 단일 from 요소가 포함되어 있다. 그러나 이 정책:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
- podSelector:
matchLabels:
role: client
...
from 배열에 두 개의 요소가 포함되어 있으며, 로컬 네임스페이스에 레이블을 role=client 로 가지는 파드 또는 네임스페이스에 레이블을 user=alice 로 가지는 파드의 연결을 허용한다.
의심스러운 경우, kubectl describe 를 사용해서 쿠버네티스가 정책을 어떻게 해석하는지 확인해본다.
ipBlock: 인그레스 소스 또는 이그레스 대상으로 허용할 IP CIDR 범위를 선택한다. 파드 IP는 임시적이고 예측할 수 없기에 클러스터 외부 IP이어야 한다.
클러스터 인그레스 및 이그레스 매커니즘은 종종 패킷의 소스 또는 대상 IP의 재작성을
필요로 한다. 이러한 상황이 발생하는 경우, 네트워크폴리시의 처리 전 또는 후에
발생한 것인지 정의되지 않으며, 네트워크 플러그인, 클라우드 공급자,
서비스 구현 등의 조합에 따라 동작이 다를 수 있다.
인그레스 사례에서의 의미는 실제 원본 소스 IP를 기준으로 들어오는 패킷을
필터링할 수 있는 반면에 다른 경우에는 네트워크폴리시가 작동하는
"소스 IP"는 LoadBalancer 또는 파드가 속한 노드 등의 IP일 수 있다.
이그레스의 경우 파드에서 클러스터 외부 IP로 다시 작성된 서비스 IP로의 연결은
ipBlock 기반의 정책의 적용을 받거나 받지 않을 수 있다는 것을 의미한다.
기본 정책
기본적으로 네임스페이스 정책이 없으면 해당 네임스페이스의 파드에 대한 모든 인그레스와 이그레스 트래픽이 허용된다. 다음 예시에서는 해당 네임스페이스의 기본 동작을 변경할 수 있다.
기본적으로 모든 인그레스 트래픽 거부
모든 파드를 선택하지만 해당 파드에 대한 인그레스 트래픽은 허용하지 않는 네트워크폴리시를 생성해서 네임스페이스에 대한 "기본" 인그레스 격리 정책을 생성할 수 있다.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
이렇게 하면 다른 네트워크폴리시에서 선택하지 않은 파드도 인그레스에 대해 여전히 격리된다. 이 정책은 다른 파드로부터의 이그레스 격리에는 영향을 미치지 않는다.
모든 인그레스 트래픽 허용
한 네임스페이스의 모든 파드로의 인입(incoming) 연결을 허용하려면, 이를 명시적으로 허용하는 정책을 만들 수 있다.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
이 정책이 존재하면, 해당 파드로의 인입 연결을 막는 다른 정책은 효력이 없다. 이 정책은 모든 파드로부터의 이그레스 격리에는 영향을 미치지 않는다.
기본적으로 모든 이그레스 트래픽 거부
모든 파드를 선택하지만, 해당 파드의 이그레스 트래픽을 허용하지 않는 네트워크폴리시를 생성해서 네임스페이스에 대한 "기본" 이그레스 격리 정책을 생성할 수 있다.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
이렇게 하면 다른 네트워크폴리시에서 선택하지 않은 파드조차도 이그레스 트래픽을 허용하지 않는다. 이 정책은 모든 파드의 인그레스 격리 정책을 변경하지 않는다.
모든 이그레스 트래픽 허용
한 네임스페이스의 모든 파드로부터의 모든 연결을 허용하려면, 해당 네임스페이스의 파드로부터 나가는(outgoing) 모든 연결을 명시적으로 허용하는 정책을 생성할 수 있다.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
이 정책이 존재하면, 해당 파드에서 나가는 연결을 막는 다른 정책은 효력이 없다. 이 정책은 모든 파드로의 인그레스 격리에는 영향을 미치지 않는다.
기본적으로 모든 인그레스와 모든 이그레스 트래픽 거부
해당 네임스페이스에 아래의 네트워크폴리시를 만들어 모든 인그레스와 이그레스 트래픽을 방지하는 네임스페이스에 대한 "기본" 정책을 만들 수 있다.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
이렇게 하면 다른 네트워크폴리시에서 선택하지 않은 파드도 인그레스 또는 이그레스 트래픽을 허용하지 않는다.
SCTP 지원
기능 상태:
Kubernetes v1.20 [stable]
안정된 기능으로, 기본 활성화되어 있다. 클러스터 수준에서 SCTP를 비활성화하려면, 사용자(또는 클러스터 관리자)가 API 서버에 --feature-gates=SCTPSupport=false,… 를 사용해서 SCTPSupport 기능 게이트를 비활성화해야 한다.
해당 기능 게이트가 활성화되어 있는 경우, 네트워크폴리시의 protocol 필드를 SCTP로 지정할 수 있다.
참고:
SCTP 프로토콜 네트워크폴리시를 지원하는 CNI 플러그인을 사용하고 있어야 한다.포트 범위 지정
기능 상태:
Kubernetes v1.25 [stable]
네트워크폴리시를 작성할 때, 단일 포트 대신 포트 범위를 대상으로 지정할 수 있다.
다음 예와 같이 endPort 필드를 사용하면, 이 작업을 수행할 수 있다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: multi-port-egress
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 32000
endPort: 32768
위 규칙은 대상 포트가 32000에서 32768 사이에 있는 경우,
네임스페이스 default 에 레이블이 role=db 인 모든 파드가
TCP를 통해 10.0.0.0/24 범위 내의 모든 IP와 통신하도록 허용한다.
이 필드를 사용할 때 다음의 제한 사항이 적용된다.
endPort필드는port필드보다 크거나 같아야 한다.endPort는port도 정의된 경우에만 정의할 수 있다.- 두 포트 모두 숫자여야 한다.
참고:
클러스터가 네트워크폴리시 명세의endPort 필드를 지원하는
CNI 플러그인을 사용해야 한다.
만약 네트워크 플러그인이
endPort 필드를 지원하지 않는데 네트워크폴리시의 해당 필드에 명시를 하면,
그 정책은 port 필드에만 적용될 것이다.이름으로 네임스페이스 지정
기능 상태:
Kubernetes 1.22 [stable]
쿠버네티스 컨트롤 플레인은 NamespaceDefaultLabelName
기능 게이트가 활성화된 경우
모든 네임스페이스에 변경할 수 없는(immutable) 레이블 kubernetes.io/metadata.name 을 설정한다.
레이블의 값은 네임스페이스 이름이다.
네트워크폴리시는 일부 오브젝트 필드가 있는 이름으로 네임스페이스를 대상으로 지정할 수 없지만, 표준화된 레이블을 사용하여 특정 네임스페이스를 대상으로 지정할 수 있다.
네트워크 정책으로 할 수 없는 것(적어도 아직은 할 수 없는)
쿠버네티스 1.31부터 다음의 기능은 네트워크폴리시 API에 존재하지 않지만, 운영 체제 컴포넌트(예: SELinux, OpenVSwitch, IPTables 등) 또는 Layer 7 기술(인그레스 컨트롤러, 서비스 메시 구현) 또는 어드미션 컨트롤러를 사용하여 제2의 해결책을 구현할 수 있다. 쿠버네티스의 네트워크 보안을 처음 사용하는 경우, 네트워크폴리시 API를 사용하여 다음의 사용자 스토리를 (아직) 구현할 수 없다는 점에 유의할 필요가 있다.
- 내부 클러스터 트래픽이 공통 게이트웨이를 통과하도록 강제한다(서비스 메시나 기타 프록시와 함께 제공하는 것이 가장 좋을 수 있음).
- TLS와 관련된 모든 것(이를 위해 서비스 메시나 인그레스 컨트롤러 사용).
- 노드별 정책(이에 대해 CIDR 표기법을 사용할 수 있지만, 특히 쿠버네티스 ID로 노드를 대상으로 지정할 수 없음).
- 이름으로 서비스를 타겟팅한다(그러나, 레이블로 파드나 네임스페이스를 타겟팅할 수 있으며, 이는 종종 실행할 수 있는 해결 방법임).
- 타사 공급사가 이행한 "정책 요청"의 생성 또는 관리.
- 모든 네임스페이스나 파드에 적용되는 기본 정책(이를 수행할 수 있는 타사 공급사의 쿠버네티스 배포본 및 프로젝트가 있음).
- 고급 정책 쿼리 및 도달 가능성 도구.
- 네트워크 보안 이벤트를 기록하는 기능(예: 차단되거나 수락된 연결).
- 명시적으로 정책을 거부하는 기능(현재 네트워크폴리시 모델은 기본적으로 거부하며, 허용 규칙을 추가하는 기능만 있음).
- 루프백 또는 들어오는 호스트 트래픽을 방지하는 기능(파드는 현재 로컬 호스트 접근을 차단할 수 없으며, 상주 노드의 접근을 차단할 수 있는 기능도 없음).
다음 내용
- 자세한 설명과 추가 예시는 네트워크 정책 선언을 본다.
- 네트워크폴리시 리소스에서 사용되는 일반적인 시나리오는 레시피를 본다.
6.6 - 서비스 및 파드용 DNS
워크로드는 DNS를 사용하여 클러스터 내의 서비스들을 발견할 수 있다; 이 페이지는 이것이 어떻게 동작하는지를 설명한다.
쿠버네티스는 파드와 서비스를 위한 DNS 레코드를 생성한다. 사용자는 IP 주소 대신에 일관된 DNS 네임을 통해서 서비스에 접속할 수 있다.
쿠버네티스는 DNS를 설정 하기 위해 사용되는 파드와 서비스에 대한 정보를 발행한다. Kubelet은 실행 중인 컨테이너가 IP가 아닌 이름으로 서비스를 검색할 수 있도록 파드의 DNS를 설정한다.
클러스터 내의 서비스에는 DNS 네임이 할당된다. 기본적으로 클라이언트 파드의 DNS 검색 리스트는 파드 자체의 네임스페이스와 클러스터의 기본 도메인을 포함한다.
서비스의 네임스페이스
DNS 쿼리는 그것을 생성하는 파드의 네임스페이스에 따라 다른 결과를 반환할 수 있다. 네임스페이스를 지정하지 않은 DNS 쿼리는 파드의 네임스페이스에 국한된다. DNS 쿼리에 네임스페이스를 명시하여 다른 네임스페이스에 있는 서비스에 접속한다.
예를 들어, test 네임스페이스에 있는 파드를 생각해보자. data 서비스는
prod 네임스페이스에 있다.
이 경우, data 에 대한 쿼리는 파드의 test 네임스페이스를 사용하기 때문에 결과를 반환하지 않을 것이다.
data.prod 로 쿼리하면 의도한 결과를 반환할 것이다. 왜냐하면
네임스페이스가 명시되어 있기 때문이다.
DNS 쿼리는 파드의 /etc/resolv.conf 를 사용하여 확장될 수 있을 것이다. Kubelet은
각 파드에 대해서 파일을 설정한다. 예를 들어, data 만을 위한 쿼리는
data.test.svc.cluster.local 로 확장된다. search 옵션의 값은
쿼리를 확장하기 위해서 사용된다. DNS 쿼리에 대해 더 자세히 알고 싶은 경우,
resolv.conf 설명 페이지.를 참고한다.
nameserver 10.32.0.10
search <namespace>.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
요약하면, test 네임스페이스에 있는 파드는, prod 네임스페이스에 있는 data 파드를 가리키는 도메인 이름인
data.prod 또는 data.prod.svc.cluster.local 을 성공적으로 해석할 수 있다.
DNS 레코드
어떤 오브젝트가 DNS 레코드를 가지는가?
- 서비스
- 파드
다음 섹션은 지원되는 DNS 레코드의 종류 및 레이아웃에 대한 상세 내용이다. 혹시 동작시킬 필요가 있는 다른 레이아웃, 네임, 또는 쿼리는 구현 세부 사항으로 간주되며 경고 없이 변경될 수 있다. 최신 명세 확인을 위해서는, 쿠버네티스 DNS-기반 서비스 디스커버리를 본다.
서비스
A/AAAA 레코드
"노멀"(헤드리스가 아닌) 서비스는 서비스의 IP family 혹은 IP families 에 따라
my-svc.my-namespace.svc.cluster-domain.example
형식의 이름을 가진 DNS A 또는 AAAA 레코드가 할당된다. 이는 서비스의 클러스터
IP로 해석된다.
헤드리스 서비스
(클러스터 IP가 없는) 또한 my-svc.my-namespace.svc.cluster-domain.example
형식의 이름을 가진 DNS A 또는 AAAA 레코드가 할당된다. 노멀 서비스와는 달리
이는 서비스에 의해 선택된 파드들의 IP 집합으로 해석된다.
클라이언트는 해석된 IP 집합에서 IP를 직접 선택하거나 표준 라운드로빈을
통해 선택할 수 있다.
SRV 레코드
SRV 레코드는 노멀 서비스 또는 헤드리스 서비스에 속하는 네임드 포트를 위해 만들어졌다.
각각의 네임드 포트에 대해서 SRV 레코드는 다음과 같은 형식을 갖는다.
_port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.example.
정규 서비스의 경우, 이는 포트 번호와 도메인 네임으로 해석된다:
my-svc.my-namespace.svc.cluster-domain.example.
헤드리스 서비스의 경우, 서비스를 지원하는 각 파드에 대해 하나씩 복수 응답으로 해석되며 이 응답은 파드의
포트 번호와 도메인 이름을 포함한다.
hostname.my-svc.my-namespace.svc.cluster-domain.example.
파드
A/AAAA 레코드
일반적으로 파드에는 다음과 같은 DNS 주소를 갖는다.
pod-ip-address.my-namespace.pod.cluster-domain.example.
예를 들어, default 네임스페이스의 파드에 IP 주소 172.17.0.3이 있고,
클러스터의 도메인 이름이 cluster.local 이면, 파드는 다음과 같은 DNS 주소를 갖는다.
172-17-0-3.default.pod.cluster.local.
서비스에 의해 노출된 모든 파드는 다음과 같은 DNS 주소를 갖는다.
pod-ip-address.service-name.my-namespace.svc.cluster-domain.example.
파드의 hostname 및 subdomain 필드
파드가 생성되면 hostname(파드 내부에서 확인된 것 처럼)은
해당 파드의 metadata.name 값이 된다.
파드 스펙(Pod spec)에는 선택적 필드인 hostname이 있다. 이 필드는
다른 호스트네임을 지정할 수 있다. hostname 필드가 지정되면, 파드의 이름보다
파드의 호스트네임이 우선시된다.(역시 파드 내에서 확인된 것 처럼) 예를 들어,
spec.hostname 필드가 "my-host"로 설정된 파드는
호스트네임이 "my-host"로 설정된다.
또한, 파드 스펙에는 선택적 필드인 subdomain이 있다. 이 필드는 파드가 네임스페이스의
서브 그룹의 일부임을 나타낼 수 있다. 예를 들어 "my-namespace" 네임스페이스에서, spec.hostname 필드가
"foo"로 설정되고, spec.subdomain 필드가 "bar"로 설정된 파드는
전체 주소 도메인 네임(FQDN)을 가지게 된다.
"foo.bar.my-namespace.svc.cluster-domain.example" (다시 한 번, 파드 내부 에서
확인된 것 처럼).
파드와 동일한 네임스페이스 내에 같은 서브도메인 이름을 가진 헤드리스 서비스가 있다면, 클러스터의 DNS 서버는 파드의 전체 주소 호스트네임(fully qualified hostname)인 A 또는 AAAA 레코드를 반환한다.
예시:
apiVersion: v1
kind: Service
metadata:
name: busybox-subdomain
spec:
selector:
name: busybox
clusterIP: None
ports:
- name: foo # 단일 포트 서비스에 이름은 필수사항이 아니다.
port: 1234
---
apiVersion: v1
kind: Pod
metadata:
name: busybox1
labels:
name: busybox
spec:
hostname: busybox-1
subdomain: busy-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
---
apiVersion: v1
kind: Pod
metadata:
name: busybox2
labels:
name: busybox
spec:
hostname: busybox-2
subdomain: busy-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
위의 주어진 서비스 "busybox-subdomain"과 spec.subdomain이
"busybox-subdomain"으로 설정된 파드에서, 첫번째 파드는 다음과 같은 자기 자신의 FQDN을 확인하게 된다.
"busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example". DNS는
위 FQDN에 대해 파드의 IP를 가리키는 A 또는 AAAA 레코드를 제공한다. "busybox1"와
"busybox2" 파드 모두 각 파드의 주소 레코드를 갖게 된다.
엔드포인트슬라이스(EndpointSlice)는 임의의 엔드포인트 주소에 대해 해당 IP와 함께 DNS 호스트 네임을 지정할 수 있다.
참고:
A 와 AAAA 레코드는 파드의 이름으로 생성되지 않기 때문에 파드의 A 또는 AAAA 레코드를 생성하기 위해서는hostname 필드를 작성해야 한다.
hostname 필드는 없고 subdomain 필드만 있는 파드는 파드의 IP 주소를 가리키는 헤드리스 서비스의
A 또는 AAAA 레코드만 생성할 수 있다. (busybox-subdomain.my-namespace.svc.cluster-domain.example)
또한 서비스에서 publishNotReadyAddresses=True 를 설정하지 않았다면, 파드가 준비 상태가 되어야 레코드를 가질 수 있다.파드의 setHostnameAsFQDN 필드
기능 상태:
Kubernetes v1.22 [stable]
파드가 전체 주소 도메인 이름(FQDN)을 갖도록 구성된 경우,
해당 호스트네임은 짧은 호스트네임이다.
예를 들어, 전체 주소 도메인 이름이 busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example 인 파드가 있는 경우,
기본적으로 해당 파드 내부의 hostname 명령어는 busybox-1 을 반환하고
hostname --fqdn 명령은 FQDN을 반환한다.
파드 명세에서 setHostnameAsFQDN: true 를 설정하면, kubelet은 파드의 FQDN을 해당 파드 네임스페이스의 호스트네임에 기록한다. 이 경우, hostname 과 hostname --fqdn 은 모두 파드의 FQDN을 반환한다.
참고:
리눅스에서, 커널의 호스트네임 필드(struct utsname 의 nodename 필드)는 64자로 제한된다.
파드에서 이 기능을 사용하도록 설정하고 FQDN이 64자보다 길면, 시작되지 않는다. 파드는 파드 호스트네임과 클러스터 도메인에서 FQDN을 구성하지 못한다거나, FQDN long-FDQN 이 너무 길다(최대 64자, 70자 요청인 경우)와 같은 오류 이벤트를 생성하는 Pending 상태(kubectl 에서 표시하는 ContainerCreating)로 유지된다. 이 시나리오에서 사용자 경험을 개선하는 한 가지 방법은 사용자가 최상위 레벨을 오브젝트(예를 들어, 디플로이먼트)를 생성할 때 FQDN 크기를 제어하기 위해 어드미션 웹훅 컨트롤러를 생성하는 것이다.
파드의 DNS 정책
DNS 정책은 파드별로 설정할 수 있다.
현재 쿠버네티스는 다음과 같은 파드별 DNS 정책을 지원한다.
이 정책들은 파드 스펙의 dnsPolicy 필드에서 지정할 수 있다.
- "
Default": 파드는 파드가 실행되고 있는 노드로부터 네임 해석 설정(the name resolution configuration)을 상속받는다. 자세한 내용은 관련 논의에서 확인할 수 있다. - "
ClusterFirst": "www.kubernetes.io"와 같이 클러스터 도메인 suffix 구성과 일치하지 않는 DNS 쿼리는 DNS 서버에 의해 업스트림 네임서버로 전달된다. 클러스터 관리자는 추가 스텁-도메인(stub-domain)과 업스트림 DNS 서버를 구축할 수 있다. 그러한 경우 DNS 쿼리를 어떻게 처리하는지에 대한 자세한 내용은 관련 논의에서 확인할 수 있다. - "
ClusterFirstWithHostNet": hostNetwork에서 running 상태인 파드의 경우 DNS 정책인 "ClusterFirstWithHostNet"을 명시적으로 설정해야 한다. 그렇지 않으면, hostNetwork와"ClusterFirst"로 실행되고 있는 파드는"Default"정책으로 동작한다.- 참고: 윈도우에서는 지원되지 않는다.상세 정보는 아래에서 확인한다.
- "
None": 이 정책은 파드가 쿠버네티스 환경의 DNS 설정을 무시하도록 한다. 모든 DNS 설정은 파드 스펙 내에dnsConfig필드를 사용하여 제공해야 한다. 아래 절인 파드의 DNS 설정에서 자세한 내용을 확인할 수 있다.
참고:
"Default"는 기본 DNS 정책이 아니다.dnsPolicy가 명시적으로 지정되어 있지 않다면
"ClusterFirst"가 기본값으로 사용된다.아래 예시는 hostNetwork필드가 true로 설정되어 있어서
DNS 정책이 "ClusterFirstWithHostNet"으로 설정된 파드를 보여준다.
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
파드의 DNS 설정
기능 상태:
Kubernetes v1.14 [stable]
사용자들은 파드의 DNS 설정을 통해서 직접 파드의 DNS를 세팅할 수 있다.
dnsConfig 필드는 선택적이고, dnsPolicy 세팅과 함께 동작한다.
이때, 파드의 dnsPolicy의 값이 "None"으로 설정되어 있어야
dnsConfig 필드를 지정할 수 있다.
사용자는 dnsConfig 필드에서 다음과 같은 속성들을 지정할 수 있다.
nameservers: 파드의 DNS 서버가 사용할 IP 주소들의 목록이다. 파드의dnsPolicy가 "None" 으로 설정된 경우에는 적어도 하나의 IP 주소가 포함되어야 하며, 그렇지 않으면 이 속성은 생략할 수 있다.nameservers에 나열된 서버는 지정된 DNS 정책을 통해 생성된 기본 네임 서버와 합쳐지며 중복되는 주소는 제거된다.searches: 파드의 호스트네임을 찾기 위한 DNS 검색 도메인의 목록이다. 이 속성은 생략이 가능하며, 값을 지정한 경우 나열된 검색 도메인은 지정된 DNS 정책을 통해 생성된 기본 검색 도메인에 합쳐진다. 병합 시 중복되는 도메인은 제거되며, 쿠버네티스는 최대 6개의 검색 도메인을 허용하고 있다.options:name속성(필수)과value속성(선택)을 가질 수 있는 오브젝트들의 선택적 목록이다. 이 속성의 내용은 지정된 DNS 정책에서 생성된 옵션으로 병합된다. 이 속성의 내용은 지정된 DNS 정책을 통해 생성된 옵션으로 합쳐지며, 병합 시 중복되는 항목은 제거된다.
다음은 커스텀 DNS 세팅을 한 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 1.2.3.4
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
위에서 파드가 생성되면,
컨테이너 test의 /etc/resolv.conf 파일에는 다음과 같은 내용이 추가된다.
nameserver 1.2.3.4
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0
IPv6 셋업을 위해서 검색 경로와 네임 서버 셋업은 다음과 같아야 한다:
kubectl exec -it dns-example -- cat /etc/resolv.conf
출력은 다음과 같은 형식일 것이다.
nameserver 2001:db8:30::a
search default.svc.cluster-domain.example svc.cluster-domain.example cluster-domain.example
options ndots:5
DNS 탐색 도메인 리스트 제한
기능 상태:
Kubernetes 1.26 [beta]
쿠버네티스는 탐색 도메인 리스트가 32개를 넘거나 모든 탐색 도메인의 길이가 2048자를 초과할 때까지 DNS Config에 자체적인 제한을 하지 않는다. 이 제한은 노드의 resolver 설정 파일, 파드의 DNS Config, 그리고 합쳐진 DNS Config에 각각 적용된다.
참고:
이전 버전의 일부 컨테이너 런타임은 DNS 탐색 도메인 수에 대해 자체적인 제한을 가지고 있을 수 있다. 컨테이너 런타임 환경에 따라 많은 수의 DNS 검색 도메인을 갖는 파드는 pending 상태로 고착될 수 있다.
containerd v1.5.5 혹은 그 이전 그리고 CRI-O v1.21 혹은 그 이전에서 이러한 문제가 발생하는 것으로 알려졌다.
윈도우 노드에서 DNS 해석(resolution)
- ClusterFirstWithHostNet은 윈도우 노드에서 구동 중인 파드에는 지원되지 않는다.
윈도우는
.를 포함한 모든 네임(주소)을 FQDN으로 취급하여 FQDN 해석을 생략한다. - 윈도우에는 여러 DNS 해석기가 사용될 수 있다. 이러한 해석기는
각자 조금씩 다르게 동작하므로, 네임 쿼리 해석을 위해서
Resolve-DNSName파워쉘(powershell) cmdlet을 사용하는 것을 추천한다. - 리눅스에는 DNS 접미사 목록이 있는데, 이는 네임이 완전한 주소가 아니어서 주소
해석에 실패한 경우 사용한다.
윈도우에서는 파드의 네임스페이스(예:
mydns.svc.cluster.local)와 연계된 하나의 DNS 접미사만 가질 수 있다. 윈도우는 이러한 단일 접미사 통해 해석될 수 있는 FQDNs, 서비스, 또는 네트워크 네임을 해석할 수 있다. 예를 들어,default에 소속된 파드는 DNS 접미사default.svc.cluster.local를 가진다. 윈도우 파드 내부에서는kubernetes.default.svc.cluster.local와kubernetes를 모두 해석할 수 있다. 그러나, 일부에만 해당(partially qualified)하는 네임(kubernetes.default또는kubernetes.default.svc)은 해석할 수 없다.
다음 내용
DNS 구성 관리에 대한 지침은 DNS 서비스 구성에서 확인할 수 있다.
6.7 - IPv4/IPv6 이중 스택
쿠버네티스는 단일 스택 IPv4 네트워킹, 단일 스택 IPv6 네트워킹 혹은 두 네트워크 패밀리를 활성화한 이중 스택 네트워킹 설정할 수 있도록 해준다. 이 페이지는 이 방법을 설명한다.
기능 상태:
Kubernetes v1.23 [stable]
IPv4/IPv6 이중 스택 네트워킹을 사용하면 파드와 서비스에 IPv4와 IPv6 주소를 모두 할당할 수 있다.
IPv4/IPv6 이중 스택 네트워킹은 1.21부터 쿠버네티스 클러스터에 기본적으로 활성화되어 있고, IPv4 및 IPv6 주소를 동시에 할당할 수 있다.
지원되는 기능
쿠버네티스 클러스터의 IPv4/IPv6 이중 스택은 다음의 기능을 제공한다.
- 이중 스택 파드 네트워킹(파드 당 단일 IPv4와 IPv6 주소 할당)
- IPv4와 IPv6 지원 서비스
- IPv4와 IPv6 인터페이스를 통한 파드 오프(off) 클러스터 이그레스 라우팅(예: 인터넷)
필수 구성 요소
IPv4/IPv6 이중 스택 쿠버네티스 클러스터를 활용하려면 다음의 필수 구성 요소가 필요하다.
-
쿠버네티스 1.20 및 이후 버전
예전 버전 쿠버네티스에서 이중 스택 서비스를 사용하는 방법에 대한 정보는 해당 버전의 쿠버네티스에 대한 문서를 참조한다.
-
이중 스택 네트워킹을 위한 공급자의 지원. (클라우드 공급자 또는 다른 방식으로 쿠버네티스 노드에 라우팅 가능한 IPv4/IPv6 네트워크 인터페이스를 제공할 수 있어야 함.)
-
이중 스택 네트워킹을 지원하는 네트워크 플러그인.
IPv4/IPv6 이중 스택 구성
IPv4/IPv6 이중 스택을 구성하려면, 이중 스택 클러스터 네트워크 할당을 설정한다.
- kube-apiserver:
--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
- kube-controller-manager:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6IPv4의 기본값은 /24 이고 IPv6의 기본값은 /64 이다.
- kube-proxy:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>
- kubelet:
--cloud-provider가 명시되지 않았다면 관리자는 해당 노드에 듀얼 스택.status.addresses를 수동으로 설정하기 위해 쉼표로 구분된 IP 주소 쌍을--node-ip플래그로 전달할 수 있다. 해당 노드의 파드가 HostNetwork 모드로 실행된다면, 파드는 이 IP 주소들을 자신의.status.podIPs필드에 보고한다. 노드의 모든podIPs는 해당 노드의.status.addresses필드에 의해 정의된 IP 패밀리 선호사항을 만족한다.
참고:
IPv4 CIDR의 예: 10.244.0.0/16 (자신의 주소 범위를 제공하더라도)
IPv6 CIDR의 예: fdXY:IJKL:MNOP:15::/64 (이 형식으로 표시되지만, 유효한
주소는 아니다. RFC 4193을 확인한다.)
서비스
IPv4, IPv6 또는 둘 다를 사용할 수 있는 서비스를 생성할 수 있다.
서비스의 주소 계열은 기본적으로 첫 번째 서비스 클러스터 IP 범위의 주소 계열로 설정된다.
(--service-cluster-ip-range 플래그를 통해 kube-apiserver에 구성)
서비스를 정의할 때 선택적으로 이중 스택으로 구성할 수 있다. 원하는 동작을 지정하려면 .spec.ipFamilyPolicy 필드를
다음 값 중 하나로 설정한다.
SingleStack: 단일 스택 서비스. 컨트롤 플레인은 첫 번째로 구성된 서비스 클러스터 IP 범위를 사용하여 서비스에 대한 클러스터 IP를 할당한다.PreferDualStack:- 서비스에 IPv4 및 IPv6 클러스터 IP를 할당한다.
RequireDualStack: IPv4 및 IPv6 주소 범위 모두에서 서비스.spec.ClusterIPs를 할당한다..spec.ipFamilies배열의 첫 번째 요소의 주소 계열을 기반으로.spec.ClusterIPs목록에서.spec.ClusterIP를 선택한다.
단일 스택에 사용할 IP 계열을 정의하거나 이중 스택에 대한 IP 군의
순서를 정의하려는 경우, 서비스에서 옵션 필드
.spec.ipFamilies를 설정하여 주소 군을 선택할 수 있다.
참고:
.spec.ipFamilies 필드는 이미 존재하는 서비스에 .spec.ClusterIP를
재할당할 수 없기 때문에 변경할 수 없다. .spec.ipFamilies를 변경하려면
서비스를 삭제하고 다시 생성한다..spec.ipFamilies를 다음 배열 값 중 하나로 설정할 수 있다.
["IPv4"]["IPv6"]["IPv4","IPv6"](이중 스택)["IPv6","IPv4"](이중 스택)
나열한 첫 번째 군은 레거시.spec.ClusterIP 필드에 사용된다.
이중 스택 서비스 구성 시나리오
이 예제는 다양한 이중 스택 서비스 구성 시나리오의 동작을 보여준다.
새로운 서비스에 대한 이중 스택 옵션
- 이 서비스 사양은
.spec.ipFamilyPolicy를 명시적으로 정의하지 않는다. 이 서비스를 만들 때 쿠버네티스는 처음 구성된service-cluster-ip-range에서 서비스에 대한 클러스터 IP를 할당하고.spec.ipFamilyPolicy를SingleStack으로 설정한다. (셀렉터가 없는 서비스 및 헤드리스 서비스와 같은 방식으로 동작한다.)
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
-
이 서비스 사양은
.spec.ipFamilyPolicy에PreferDualStack을 명시적으로 정의한다. 이중 스택 클러스터에서 이 서비스를 생성하면 쿠버네티스는 서비스에 대해 IPv4 및 IPv6 주소를 모두 할당한다. 컨트롤 플레인은 서비스의.spec을 업데이트하여 IP 주소 할당을 기록한다. 필드.spec.ClusterIPs는 기본 필드이며 할당된 IP 주소를 모두 포함한다..spec.ClusterIP는 값이.spec.ClusterIPs에서 계산된 보조 필드이다..spec.ClusterIP필드의 경우 컨트롤 플레인은 첫 번째 서비스 클러스터 IP 범위와 동일한 주소 계열의 IP 주소를 기록한다.- 단일 스택 클러스터에서
.spec.ClusterIPs및.spec.ClusterIP필드는 모두 하나의 주소만 나열한다. - 이중 스택이 활성화된 클러스터에서
.spec.ipFamilyPolicy에RequireDualStack을 지정하면PreferDualStack과 동일하게 작동한다.
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
ipFamilyPolicy: PreferDualStack
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
- 이 서비스 사양은
.spec.ipFamilies에IPv6과IPv4를 명시적으로 정의하고.spec.ipFamilyPolicy에PreferDualStack을 정의한다. 쿠버네티스가.spec.ClusterIPs에 IPv6 및 IPv4 주소를 할당할 때.spec.ClusterIP는.spec.ClusterIPs배열의 첫 번째 요소이므로 IPv6 주소로 설정되어 기본값을 재정의한다.
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
ipFamilyPolicy: PreferDualStack
ipFamilies:
- IPv6
- IPv4
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
기존 서비스의 이중 스택 기본값
이 예제는 서비스가 이미 있는 클러스터에서 이중 스택이 새로 활성화된 경우의 기본 동작을 보여준다. (기존 클러스터를 1.21 이상으로 업그레이드하면 이중 스택이 활성화된다.)
-
클러스터에서 이중 스택이 활성화된 경우 기존 서비스 (
IPv4또는IPv6)는 컨트롤 플레인이.spec.ipFamilyPolicy를SingleStack으로 지정하고.spec.ipFamilies를 기존 서비스의 주소 계열로 설정한다. 기존 서비스 클러스터 IP는.spec.ClusterIPs에 저장한다.apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80kubectl을 사용하여 기존 서비스를 검사하여 이 동작을 검증할 수 있다.
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: 10.0.197.123 clusterIPs: - 10.0.197.123 ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp type: ClusterIP status: loadBalancer: {} -
클러스터에서 이중 스택이 활성화된 경우, 셀렉터가 있는 기존 헤드리스 서비스는
.spec.ClusterIP가None이라도 컨트롤 플레인이.spec.ipFamilyPolicy을SingleStack으로 지정하고.spec.ipFamilies는 첫 번째 서비스 클러스터 IP 범위(kube-apiserver에 대한--service-cluster-ip-range플래그를 통해 구성)의 주소 계열으로 지정한다.apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80kubectl을 사용하여 셀렉터로 기존 헤드리스 서비스를 검사하여 이 동작의 유효성을 검사 할 수 있다.
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: None clusterIPs: - None ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp
단일 스택과 이중 스택 간 서비스 전환
서비스는 단일 스택에서 이중 스택으로, 이중 스택에서 단일 스택으로 변경할 수 있다.
-
서비스를 단일 스택에서 이중 스택으로 변경하려면 원하는 대로
.spec.ipFamilyPolicy를SingleStack에서PreferDualStack또는RequireDualStack으로 변경한다. 이 서비스를 단일 스택에서 이중 스택으로 변경하면 쿠버네티스는 누락된 주소 계열의 것을 배정하므로 해당 서비스는 이제 IPv4와 IPv6 주소를 갖는다..spec.ipFamilyPolicy를SingleStack에서PreferDualStack으로 업데이트하는 서비스 사양을 편집한다.이전:
spec: ipFamilyPolicy: SingleStack이후:
spec: ipFamilyPolicy: PreferDualStack -
서비스를 이중 스택에서 단일 스택으로 변경하려면
.spec.ipFamilyPolicy를PreferDualStack에서 또는RequireDualStack을SingleStack으로 변경한다. 이 서비스를 이중 스택에서 단일 스택으로 변경하면 쿠버네티스는.spec.ClusterIPs배열의 첫 번째 요소 만 유지하고.spec.ClusterIP를 해당 IP 주소로 설정하고.spec.ipFamilies를.spec.ClusterIPs의 주소 계열로 설정한다.
셀렉터가 없는 헤드리스 서비스
셀렉터가 없는 서비스 및 .spec.ipFamilyPolicy가
명시적으로 설정되지 않은 경우 .spec.ipFamilyPolicy 필드의 기본값은
RequireDualStack 이다.
로드밸런서 서비스 유형
서비스에 이중 스택 로드밸런서를 프로비저닝하려면
.spec.type필드를LoadBalancer로 설정.spec.ipFamilyPolicy필드를PreferDualStack또는RequireDualStack으로 설정
참고:
이중 스택LoadBalancer 유형 서비스를 사용하려면 클라우드 공급자가
IPv4 및 IPv6로드 밸런서를 지원해야 한다.이그레스(Egress) 트래픽
비공개로 라우팅할 수 있는 IPv6 주소를 사용하는 파드에서 클러스터 외부 대상 (예: 공용 인터넷)에 도달하기 위해 이그레스 트래픽을 활성화하려면 투명 프록시 또는 IP 위장과 같은 메커니즘을 통해 공개적으로 라우팅한 IPv6 주소를 사용하도록 파드를 활성화해야 한다. ip-masq-agent 프로젝트는 이중 스택 클러스터에서 IP 위장을 지원한다.
참고:
CNI 공급자가 IPv6를 지원하는지 확인한다.윈도우 지원
윈도우에 있는 쿠버네티스는 싱글 스택(single-stack) "IPv6-only" 네트워킹을 지원하지 않는다. 그러나, 싱글 패밀리(single-family) 서비스로 되어 있는 파드와 노드에 대해서는 듀얼 스택(dual-stack) IPv4/IPv6 네트워킹을 지원한다.
l2bridge 네트워크로 IPv4/IPv6 듀얼 스택 네트워킹을 사용할 수 있다.
참고:
윈도우에서 오버레이 (VXLAN) 네트워크은 듀얼 스택 네트워킹을 지원하지 않는다.윈도우의 다른 네트워크 모델에 대한 내용은 윈도우에서의 네트워킹을 살펴본다.
다음 내용
6.8 - 토폴로지 인지 힌트
토폴로지 인지 힌트 는 트래픽이 발생한 존 내에서 네트워크 트래픽을 유지하도록 처리하는 메커니즘을 제공한다. 클러스터의 파드간 동일한 존의 트래픽을 선호하는 것은 안전성, 성능(네트워크 지연 및 처리량) 혹은 비용 측면에 도움이 될 수 있다.
기능 상태:
Kubernetes v1.23 [beta]
토폴로지 인지 힌트(Topology Aware Hints) 는 클라이언트가 엔드포인트(endpoint)를 어떻게 사용해야 하는지에 대한 제안을 포함시킴으로써 토폴로지 인지 라우팅을 가능하게 한다. 이러한 접근은 엔드포인트슬라이스(EndpointSlice) 또는 엔드포인트(Endpoints) 오브젝트의 소비자(consumer)가 이용할 수 있는 메타데이터를 추가하며, 이를 통해 해당 네트워크 엔드포인트로의 트래픽이 근원지에 더 가깝게 라우트될 수 있다.
예를 들어, 비용을 줄이거나 네트워크 성능을 높이기 위해, 인접성을 고려하여 트래픽을 라우트할 수 있다.
동기(motivation)
쿠버네티스 클러스터가 멀티-존(multi-zone) 환경에 배포되는 일이 점점 많아지고 있다. 토폴로지 인지 힌트 는 트래픽이 발생한 존 내에서 트래픽을 유지하도록 처리하는 메커니즘을 제공한다. 이러한 개념은 보통 "토폴로지 인지 라우팅"이라고 부른다. 서비스의 엔드포인트를 계산할 때, 엔드포인트슬라이스 컨트롤러는 각 엔드포인트의 토폴로지(지역(region) 및 존)를 고려하여, 엔드포인트가 특정 존에 할당되도록 힌트 필드를 채운다. 그러면 kube-proxy와 같은 클러스터 구성 요소는 해당 힌트를 인식하고, (토폴로지 상 가까운 엔드포인트를 사용하도록) 트래픽 라우팅 구성에 활용한다.
토폴로지 인지 힌트 사용하기
service.kubernetes.io/topology-aware-hints 어노테이션을 auto로 설정하여
서비스에 대한 토폴로지 인지 힌트를 활성화할 수 있다.
이는 엔드포인트슬라이스 컨트롤러가 안전하다고 판단되는 경우 토폴로지 힌트를 설정하도록 지시하는 것이다.
명심할 점은, 이를 수행한다고 해서 힌트가 항상 설정되는 것은 아니라는 것이다.
동작 방법
이 기능을 동작시키는 요소는 엔드포인트슬라이스 컨트롤러와 kube-proxy 두 구성요소로 나눠져 있다. 이 섹션에서는 각 구성요소가 어떻게 이 기능을 동작시키는지에 대한 고차원 개요를 제공한다.
엔드포인트슬라이스 컨트롤러
엔드포인트슬라이스 컨트롤러는 이 기능이 활성화되어 있을 때 엔드포인트슬라이스에 힌트를 설정하는 일을 담당한다. 컨트롤러는 각 존에 일정 비율의 엔드포인트를 할당한다. 이 비율은 해당 존에 있는 노드의 할당 가능한(allocatable) CPU 코어에 의해 결정된다. 예를 들어, 한 존에 2 CPU 코어가 있고 다른 존에 1 CPU 코어만 있는 경우, 컨트롤러는 2 CPU 코어가 있는 존에 엔드포인트를 2배 할당할 것이다.
다음 예시는 엔드포인트슬라이스에 힌트가 채워졌을 때에 대한 예시이다.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
labels:
kubernetes.io/service-name: example-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
kube-proxy
kube-proxy 구성요소는 엔드포인트슬라이스 컨트롤러가 설정한 힌트를 기반으로 자신이 라우팅하는 엔드포인트를 필터링한다. 대부분의 경우, 이는 kube-proxy가 동일 존 내에서 트래픽을 엔드포인트로 라우팅할 수 있음을 뜻한다. 때때로 컨트롤러는 존 사이에 보다 균등한 엔드포인트 분배를 위해 다른 존으로부터 엔드포인트를 할당하기도 한다. 이러한 경우 일부 트래픽은 다른 존으로 라우팅될 것이다.
보호 규칙
쿠버네티스 컨트롤 플레인과 각 노드의 kube-proxy는 토폴로지 인지 힌트를 사용하기 전에 몇 가지 보호 규칙을 적용한다. 이들이 만족되지 않으면, kube-proxy는 존에 상관없이 클러스터의 모든 곳으로부터 엔드포인트를 선택한다.
-
엔드포인트 수가 충분하지 않음: 존의 숫자보다 엔드포인트의 숫자가 적으면, 컨트롤러는 어떤 힌트도 할당하지 않을 것이다.
-
균형잡힌 할당이 불가능함: 일부 경우에, 존 간 균형잡힌 엔드포인트 할당이 불가능할 수 있다. 예를 들어, zone-a가 zone-b보다 2배 큰 상황에서, 엔드포인트가 2개 뿐이라면, zone-a에 할당된 엔드포인트는 zone-b에 할당된 엔드포인트보다 2배의 트래픽을 수신할 것이다. 컨트롤러는 이 "예상 과부하" 값을 각 존에 대해 허용 가능한 임계값보다 작게 낮출 수 없는 경우에는 힌트를 할당하지 않는다. 명심할 점은, 이것이 실시간 피드백 기반이 아니라는 것이다. 개별 엔드포인트가 과부하 상태로 바뀔 가능성도 여전히 있다.
-
하나 이상의 노드에 대한 정보가 불충분함:
topology.kubernetes.io/zone레이블이 없는 노드가 있거나 할당 가능한 CPU 값을 보고하지 않는 노드가 있으면, 컨트롤 플레인은 토폴로지 인지 엔드포인트를 설정하지 않으며 이로 인해 kube-proxy는 존 별로 엔드포인트를 필터링하지 않는다. -
하나 이상의 엔드포인트에 존 힌트가 없음: 이러한 상황이 발생하면, kube-proxy는 토폴로지 인지 힌트로부터의 또는 토폴로지 인지 힌트로의 전환이 진행 중이라고 가정한다. 이 상태에서 서비스의 엔드포인트를 필터링하는 것은 위험할 수 있으므로 kube-proxy는 모든 엔드포인트를 사용하는 모드로 전환된다.
-
힌트에 존이 기재되지 않음: kube-proxy가 실행되고 있는 존을 향하는 힌트를 갖는 엔드포인트를 하나도 찾지 못했다면, 모든 존에서 오는 엔드포인트를 사용하는 모드로 전환된다. 이러한 경우는 기존에 있던 클러스터에 새로운 존을 추가하는 경우에 발생할 가능성이 가장 높다.
제약사항
-
토폴로지 인지 힌트는 서비스의
externalTrafficPolicy또는internalTrafficPolicy가Local로 설정된 경우에는 사용되지 않는다. 동일 클러스터의 서로 다른 서비스들에 대해 두 기능 중 하나를 사용하는 것은 가능하며, 하나의 서비스에 두 기능 모두를 사용하는 것은 불가능하다. -
이러한 접근 방법은 존의 일부분에서 많은 트래픽이 발생하는 서비스에는 잘 작동하지 않을 것이다. 대신, 들어오는 트래픽이 각 존 내 노드 용량에 대략 비례한다고 가정한다.
-
엔드포인트슬라이스 컨트롤러는 각 존 내의 비율을 계산할 때 준비되지 않은(unready) 노드는 무시한다. 이 때문에 많은 노드가 준비되지 않은 상태에서는 의도하지 않은 결과가 나타날 수도 있다.
-
엔드포인트슬라이스 컨트롤러는 각 존 내의 비율을 배포하거나 계산할 때 톨러레이션은 고려하지 않는다. 서비스를 구성하는 파드가 클러스터의 일부 노드에만 배치되어 있는 경우, 이러한 상황은 고려되지 않을 것이다.
-
오토스케일링 기능과는 잘 동작하지 않을 수 있다. 예를 들어, 하나의 존에서 많은 트래픽이 발생하는 경우, 해당 존에 할당된 엔드포인트만 트래픽을 처리하고 있을 것이다. 이로 인해 Horizontal Pod Autoscaler가 이 이벤트를 감지하지 못하거나, 또는 새롭게 추가되는 파드가 다른 존에 추가될 수 있다.
다음 내용
- 서비스와 애플리케이션 연결하기를 따라하기.
6.9 - 윈도우에서의 네트워킹
쿠버네티스는 리눅스 및 윈도우 노드를 지원한다. 단일 클러스터 내에 두 종류의 노드를 혼합할 수 있다. 이 페이지에서는 윈도우 운영 체제에서의 네트워킹에 대한 개요를 제공한다.
윈도우에서의 컨테이너 네트워킹
윈도우 컨테이너에 대한 네트워킹은 CNI 플러그인을 통해 노출된다. 윈도우 컨테이너는 네트워킹과 관련하여 가상 머신과 유사하게 작동한다. 각 컨테이너에는 Hyper-V 가상 스위치(vSwitch)에 연결된 가상 네트워크 어댑터(vNIC)가 있다. 호스트 네트워킹 서비스(HNS)와 호스트 컴퓨팅 서비스(HCS)는 함께 작동하여 컨테이너를 만들고 컨테이너 vNIC을 네트워크에 연결한다. HCS는 컨테이너 관리를 담당하는 반면 HNS는 다음과 같은 네트워킹 리소스 관리를 담당한다.
- 가상 네트워크(vSwitch 생성 포함)
- 엔드포인트 / vNIC
- 네임스페이스
- 정책(패킷 캡슐화, 로드 밸런싱 규칙, ACL, NAT 규칙 등)
윈도우 HNS(호스트 네트워킹 서비스)와 가상 스위치는
네임스페이스를 구현하고 파드 또는 컨테이너에 필요한 가상 NIC을 만들 수 있다.
그러나 DNS, 라우트, 메트릭과 같은 많은 구성은
리눅스에서와 같이 /etc/ 내의 파일이 아닌 윈도우 레지스트리 데이터베이스에 저장된다.
컨테이너의 윈도우 레지스트리는 호스트 레지스트리와 별개이므로
호스트에서 컨테이너로 /etc/resolv.conf를 매핑하는 것과 같은 개념은 리눅스에서와 동일한 효과를 갖지 않는다.
해당 컨테이너의 컨텍스트에서 실행되는 윈도우 API를 사용하여 구성해야 한다.
따라서 CNI 구현에서는 파일 매핑에 의존하는 대신
HNS를 호출하여 네트워크 세부 정보를 파드 또는 컨테이너로 전달해야 한다.
네트워크 모드
윈도우는 L2bridge, L2tunnel, Overlay, Transparent 및 NAT의 다섯 가지 네트워킹 드라이버/모드를 지원한다. 윈도우와 리눅스 워커 노드가 있는 이기종 클러스터에서는 윈도우와 리눅스 모두에서 호환되는 네트워킹 솔루션을 선택해야 한다. 윈도우에서 다음과 같은 out-of-tree 플러그인이 지원되며, 어떠한 경우에 각 CNI를 사용하면 좋은지도 소개한다.
| 네트워크 드라이버 | 설명 | 컨테이너 패킷 수정 | 네트워크 플러그인 | 네트워크 플러그인 특성 |
|---|---|---|---|---|
| L2bridge | 컨테이너는 외부 vSwitch에 연결된다. 컨테이너는 언더레이 네트워크에 연결된다. 하지만 인그레스/이그레스시에 재작성되기 때문에 물리적 네트워크가 컨테이너 MAC을 학습할 필요가 없다. | MAC은 호스트 MAC에 다시 쓰여지고, IP는 HNS OutboundNAT 정책을 사용하여 호스트 IP에 다시 쓰여질 수 있다. | win-bridge, Azure-CNI, Flannel 호스트-게이트웨이는 win-bridge를 사용한다. | win-bridge는 L2bridge 네트워크 모드를 사용하고, 컨테이너를 호스트의 언더레이에 연결하여 최상의 성능을 제공한다. 노드 간 연결을 위해 사용자 정의 경로(user-defined routes, UDR)가 필요하다. |
| L2Tunnel | 이것은 Azure에서만 사용되는 l2bridge의 특별 케이스다. 모든 패킷은 SDN 정책이 적용되는 가상화 호스트로 전송된다. | MAC 재작성되고, 언더레이 네트워크 상에서 IP가 보인다. | Azure-CNI | Azure-CNI를 사용하면 컨테이너를 Azure vNET과 통합할 수 있으며, Azure Virtual Network에서 제공하는 기능 집합을 활용할 수 있다. 예를 들어, Azure 서비스에 안전하게 연결하거나 Azure NSG를 사용한다. azure-cni 예제를 참고한다. |
| Overlay | 컨테이너에는 외부 vSwitch에 연결된 vNIC이 제공된다. 각 오버레이 네트워크는 사용자 지정 IP 접두사로 정의된 자체 IP 서브넷을 가져온다. 오버레이 네트워크 드라이버는 VXLAN 캡슐화를 사용한다. | 외부 헤더로 캡슐화된다. | win-overlay, Flannel VXLAN (win-overlay 사용) | win-overlay는 가상 컨테이너 네트워크를 호스트의 언더레이에서 격리하려는 경우(예: 보안 상의 이유로) 사용해야 한다. 데이터 센터의 IP에 제한이 있는 경우, (다른 VNID 태그가 있는) 다른 오버레이 네트워크에 IP를 재사용할 수 있다. 이 옵션을 사용하려면 Windows Server 2019에서 KB4489899가 필요하다. |
| Transparent (ovn-kubernetes의 특수한 유스케이스) | 외부 vSwitch가 필요하다. 컨테이너는 논리적 네트워크(논리적 스위치 및 라우터)를 통해 파드 내 통신을 가능하게 하는 외부 vSwitch에 연결된다. | 패킷은 GENEVE 또는 STT 터널링을 통해 캡슐화되는데, 동일한 호스트에 있지 않은 파드에 도달하기 위한 터널링을 한다. 패킷은 ovn 네트워크 컨트롤러에서 제공하는 터널 메타데이터 정보를 통해 전달되거나 삭제된다. NAT는 north-south 통신(데이터 센터와 클라이언트, 네트워크 상의 데이터 센터 외부와의 통신)을 위해 수행된다. |
ovn-kubernetes | Ansible을 통해 배포한다. 분산 ACL은 쿠버네티스 정책을 통해 적용할 수 있다. IPAM을 지원한다. kube-proxy 없이 로드 밸런싱을 수행할 수 있다. NAT를 수행할 때 iptables/netsh를 사용하지 않고 수행된다. |
| NAT (쿠버네티스에서 사용되지 않음) | 컨테이너에는 내부 vSwitch에 연결된 vNIC이 제공된다. DNS/DHCP는 WinNAT라는 내부 컴포넌트를 사용하여 제공된다. | MAC 및 IP는 호스트 MAC/IP에 다시 작성된다. | nat | 완전성을 위해 여기에 포함되었다. |
위에서 설명한 대로, 플란넬(Flannel) CNI 플러그인은 VXLAN 네트워크 백엔드(베타 지원, win-overlay에 위임) 및 host-gateway network backend(안정적인 지원, win-bridge에 위임)를 통해 윈도우에서도 지원한다.
이 플러그인은 자동 노드 서브넷 임대 할당과 HNS 네트워크 생성을 위해
윈도우의 Flannel 데몬(Flanneld)과 함께 작동할 수 있도록
참조 CNI 플러그인(win-overlay, win-bridge) 중 하나에 대한 위임을 지원한다.
이 플러그인은 자체 구성 파일 (cni.conf)을 읽고,
이를 FlannelD가 생성한 subnet.env 파일의 환경 변수와 결합한다.
이후 이를 네트워크 연결을 위한 참조 CNI 플러그인 중 하나에 위임하고,
노드-할당 서브넷을 포함하는 올바른 구성을 IPAM 플러그인(예: host-local)으로 보낸다.
노드, 파드 및 서비스 오브젝트의 경우, TCP/UDP 트래픽에 대해 다음 네트워크 흐름이 지원된다.
- 파드 → 파드(IP)
- 파드 → 파드(이름)
- 파드 → 서비스(Cluster IP)
- 파드 → 서비스(PQDN, 단 "."이 없는 경우에만)
- 파드 → 서비스(FQDN)
- 파드 → External(IP)
- 파드 → External(DNS)
- 노드 → 파드
- 파드 → 노드
IP 주소 관리 (IPAM)
The following IPAM options are supported on Windows:
- host-local
- azure-vnet-ipam(azure-cni 전용)
- Windows Server IPAM (IPAM이 설정되지 않은 경우에 대한 폴백(fallback) 옵션)
Load balancing and Services
쿠버네티스 서비스는 논리적 파드 집합 및 네트워크에서 해당 파드로 접근할 수 있는 수단을 정의하는 추상화이다. 윈도우 노드가 포함된 클러스터에서, 다음과 같은 종류의 서비스를 사용할 수 있다.
NodePortClusterIPLoadBalancerExternalName
윈도우 컨테이너 네트워킹은 리눅스 네트워킹과 몇 가지 중요한 차이점을 갖는다. 윈도우 컨테이너 네트워킹에 대한 마이크로소프트 문서에서 상세 사항과 배경 지식을 제공한다.
윈도우에서는 다음 설정을 사용하여 서비스 및 로드 밸런싱 동작을 구성할 수 있다.
| 기능 | 설명 | 지원하는 최소 윈도우 OS 빌드 | 활성화하는 방법 |
|---|---|---|---|
| 세션 어피니티 | 특정 클라이언트의 연결이 매번 동일한 파드로 전달되도록 한다. | Windows Server 2022 | service.spec.sessionAffinity를 "ClientIP"로 설정 |
| 서버 직접 반환 (DSR, Direct Server Return) | IP 주소 수정 및 LBNAT가 컨테이너 vSwitch 포트에서 직접 발생하는 로드 밸런싱 모드. 서비스 트래픽은 소스 IP가 원래 파드 IP로 설정된 상태로 도착한다. | Windows Server 2019 | kube-proxy에 --feature-gates="WinDSR=true" --enable-dsr=true 플래그를 설정한다. |
| 목적지 보존(Preserve-Destination) | 서비스 트래픽의 DNAT를 스킵하여, 백엔드 파드에 도달하는 패킷에서 목적지 서비스의 가상 IP를 보존한다. 또한 노드-노드 전달을 비활성화한다. | Windows Server, version 1903 | 서비스 어노테이션에 "preserve-destination": "true"를 설정하고 kube-proxy에 DSR을 활성화한다. |
| IPv4/IPv6 이중 스택 네트워킹 | 클러스터 내/외부에 네이티브 IPv4-to-IPv4 통신 및 IPv6-to-IPv6 통신 활성화 | Windows Server 2019 | IPv4/IPv6 이중 스택을 참고한다. |
| 클라이언트 IP 보존 | 인그레스 트래픽의 소스 IP가 유지되도록 한다. 또한 노드-노드 전달을 비활성화한다. | Windows Server 2019 | Set service.spec.externalTrafficPolicy를 "Local"로 설정하고 kube-proxy에 DSR을 활성화한다. |
경고:
목적지 노드가 Windows Server 2022를 실행 중인 경우, 오버레이 네트워킹에서 NodePort 서비스에 문제가 있음이 알려져 있다.
이 이슈를 완전히 피하려면, 서비스에 externalTrafficPolicy: Local를 설정한다.
KB5005619 또는 그 이상이 설치된 Windows Server 2022의 경우, l2bridge 네트워크에서 파드 간 연결성에 문제가 있음이 알려져 있다. 이 이슈를 우회하고 파드 간 연결성을 복구하기 위해, kube-proxy의 WinDSR 기능을 비활성화할 수 있다.
이 이슈들을 해결하기 위해서는 운영 체제를 패치해야 한다. 이와 관련해서는 https://github.com/microsoft/Windows-Containers/issues/204 를 참고한다.
제한
다음 네트워킹 기능은 윈도우 노드에서 지원되지 않는다.
- 호스트 네트워킹 모드
- 노드 자체에서 로컬 NodePort로의 접근(다른 노드 또는 외부 클라이언트에서는 가능)
- 단일 서비스에 대해 64개를 초과하는 백엔드 파드 (또는 고유한 목적지 주소)
- 오버레이 네트워크에 연결된 윈도우 파드 간의 IPv6 통신
- non-DSR 모드에서의 로컬 트래픽 정책(Local Traffic Policy)
- win-overlay, win-bridge, Azure-CNI 플러그인을 통해 ICMP 프로토콜을 사용하는 아웃바운드 통신.
특히, 윈도우 데이터 플레인(VFP)은
ICMP 패킷 치환을 지원하지 않는다. 이것은 다음을 의미한다.
- 동일한 네트워크 내의 목적지로 전달되는 ICMP 패킷(예: ping을 통한 파드 간 통신)은 예상대로 제한 없이 작동한다.
- TCP/UDP 패킷은 예상대로 제한 없이 작동한다.
- 원격 네트워크를 통과하도록 지정된 ICMP 패킷(예: ping을 통한 파드에서 외부 인터넷으로의 통신)은 치환될 수 없으므로 소스로 다시 라우팅되지 않는다.
- TCP/UDP 패킷은 여전히 치환될 수 있기 때문에
ping <destination>을curl <destination>으로 대체하여 외부와의 연결을 디버깅할 수 있다.
다른 제한도 존재한다.
- 윈도우 참조 네트워크 플러그인 win-bridge와 win-overlay는
현재
CHECK구현 누락으로 인해 CNI 사양 v0.4.0을 구현하지 않는다. - Flannel VXLAN CNI는 윈도우에서 다음과 같은 제한이 있다.
- 노드-파드 연결은 Flannel v0.12.0(또는 그 이상) 상의 로컬 파드에서만 가능하다.
- Flannel은 VNI 4096 및 UDP 4789 포트만 사용하도록 제한된다. 이 파라미터에 대한 더 자세한 사항은 공식 Flannel VXLAN 백엔드 문서를 참조한다.
6.10 - 서비스 내부 트래픽 정책
클러스터 내의 두 파드가 통신을 하려고 하고 두 파드가 동일한 노드에서 실행되는 경우, _서비스 내부 트래픽 정책_을 사용하여 네트워크 트래픽을 해당 노드 안에서 유지할 수 있다. 클러스터 네트워크를 통한 왕복 이동을 피하면 안전성, 성능 (네트워크 지연 및 처리량) 혹은 비용 측면에 도움이 될 수 있다.
기능 상태:
Kubernetes v1.26 [stable]
서비스 내부 트래픽 정책 을 사용하면 내부 트래픽 제한이 트래픽이 시작된 노드 내의 엔드포인트로만 내부 트래픽을 라우팅하도록 한다. 여기서 "내부" 트래픽은 현재 클러스터의 파드로부터 시작된 트래픽을 지칭한다. 이를 통해 비용을 절감하고 성능을 개선할 수 있다.
서비스 내부 트래픽 정책 사용
서비스의
.spec.internalTrafficPolicy를 Local로 설정하여 내부 전용 트래픽 정책을 활성화 할 수 있다.
이것은 kube-proxy가 클러스터 내부 트래픽을 위해 노드 내부 엔드포인트로만 사용하도록 한다.
참고:
지정된 서비스에 대한 엔드포인트가 없는 노드의 파드인 경우에 서비스는 다른 노드에 엔드포인트가 있더라도 엔드포인트가 없는 것처럼 작동한다. (이 노드의 파드에 대해서)다음 예제는 서비스의 .spec.internalTrafficPolicy를 Local로
설정하는 것을 보여 준다:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
internalTrafficPolicy: Local
작동 방식
kube-proxy는 spec.internalTrafficPolicy 의 설정에 따라서 라우팅되는
엔드포인트를 필터링한다.
이것을 Local로 설정하면, 노드 내부 엔드포인트만 고려한다.
이 설정이 Cluster(기본)이거나 설정되지 않았다면 모든 엔드포인트를 고려한다.
다음 내용
- 토폴로지 인지 힌트에 대해서 읽기
- 서비스 외부 트래픽 정책에 대해서 읽기
- 서비스와 애플리케이션 연결하기 를 따라하기
6.11 - 서비스 클러스터IP 할당
쿠버네티스에서 서비스는 파드 집합에서
실행되는 애플리케이션을 노출하는 추상적인 방법이다. 서비스는
(type: ClusterIP인 서비스를 통해) 클러스터-범위의 가상 IP 주소를 가진다.
클라이언트는 해당 가상 IP 주소로 접속할 수 있으며, 쿠버네티스는 해당 서비스를 거치는 트래픽을
서비스 뒷단의 파드들에게 로드 밸런싱한다.
어떻게 서비스 클러스터IP가 할당되는가?
쿠버네티스가 서비스에 가상 IP를 할당해야 할 때, 해당 요청분에는 두가지 방법 중 하나가 수행된다.
- 동적 할당
- 클러스터의 컨트롤 플레인이 자동으로
type: ClusterIP서비스의 설정된 IP 범위 내에서 가용 IP 주소를 선택한다. - 정적 할당
- 서비스용으로 설정된 IP 범위 내에서 사용자가 IP 주소를 선택한다.
클러스터 전체에 걸쳐, 모든 서비스의 ClusterIP는 항상 고유해야 한다.
이미 할당된 특정 ClusterIP로 서비스를 생성하려고 하면
에러가 발생한다.
왜 서비스 클러스터 IP를 예약해야 하는가?
때로는 클러스터의 다른 컴포넌트들이나 사용자들이 사용할 수 있도록 이미 알려진 IP 주소를 통해 서비스를 실행하고 싶을 것이다.
가장 좋은 방법은 클러스터의 DNS 서비스이다. 가벼운 관례로 일부 쿠버네티스 설치 관리자들은 DNS 서비스의 10번째 주소를 서비스 IP 범위로 지정한다. 클러스터의 서비스 IP 범위가 10.96.0.0/16 인 상황에서 DNS 서비스 IP를 10.96.0.10 으로 지정하고 싶다면, 아래와 같이 서비스를 생성해야 할 것이다.
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
spec:
clusterIP: 10.96.0.10
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
type: ClusterIP
하지만 이전에도 설명했듯이, IP 주소 10.96.0.10는 예약된 상태가 아니다. 만약 다른 서비스들이 그 전에 동적 할당으로 생성되었거나, 동시에 생성되었다면, 해당 서비스들이 IP를 할당받았을 수도 있다. 따라서, 충돌 에러로 인해 DNS 서비스를 생성하지 못할 것이다.
어떻게 하면 서비스 클러스터IP 충돌을 피할 수 있는가?
쿠버네티스에 구현된 할당 전략은 서비스에 클러스터IP 할당의 충돌 위험을 줄여준다.
ClusterIP 범위는 16 이상 256 미만의 단계적인 차수를 나타내는
min(max(16, cidrSize / 16), 256) 공식을 기반으로 나누어져 있다.
동적 IP 할당은 기본값으로 위쪽 밴드를 사용한다. 위쪽 범위가 모두 소진되었다면 아래쪽 밴드를 사용할 것이다. 이것은 사용자로 하여금 아래쪽 밴드의 정적 할당을 낮은 충돌 확률로 수행할 수 있게 해준다.
예시
예시 1
아래 예시는 서비스 IP 주소들로 10.96.0.0/24 (CIDR 표기법) IP 주소 범위를 사용한다.
범위 크기: 28 - 2 = 254
밴드 오프셋: min(max(16, 256/16), 256) = min(16, 256) = 16
정적 밴드 시작점: 10.96.0.1
정적 밴드 끝점: 10.96.0.16
범위 끝점: 10.96.0.254
pie showData
title 10.96.0.0/24
"정적" : 16
"동적" : 238
예시 2
아래 예시는 서비스 IP 주소들로 10.96.0.0/20 (CIDR 표기법) IP 주소 범위를 사용한다.
범위 크기: 212 - 2 = 4094
밴드 오프셋: min(max(16, 4096/16), 256) = min(256, 256) = 256
정적 밴드 시작점: 10.96.0.1
정적 밴드 끝점: 10.96.1.0
범위 끝점: 10.96.15.254
pie showData
title 10.96.0.0/20
"정적" : 256
"동적" : 3838
예시 3
아래 예시는 서비스 IP 주소들로 10.96.0.0/16 (CIDR 표기법) IP 주소 범위를 사용한다.
범위 크기: 216 - 2 = 65534
밴드 오프셋: min(max(16, 65536/16), 256) = min(4096, 256) = 256
정적 밴드 시작점: 10.96.0.1
정적 밴드 끝점: 10.96.1.0
범위 끝점: 10.96.255.254
pie showData
title 10.96.0.0/16
"정적" : 256
"동적" : 65278
다음 내용
- 클라이언트 소스 IP 보존하기에 대해 알아보기
- 서비스와 애플리케이션 연결하기에 대해 알아보기
- 서비스에 대해 알아보기
6.12 - 토폴로지 키를 사용하여 토폴로지-인지 트래픽 라우팅
기능 상태:
Kubernetes v1.21 [deprecated]
참고:
이 기능, 특히 알파topologyKeys API는 쿠버네티스 v1.21부터
더 이상 사용되지 않는다.
쿠버네티스 v1.21에 도입된 토폴로지 인지 힌트는
유사한 기능을 제공한다.서비스 토폴로지 를 활성화 하면 서비스는 클러스터의 노드 토폴로지를 기반으로 트래픽을 라우팅한다. 예를 들어, 서비스는 트래픽을 클라이언트와 동일한 노드이거나 동일한 가용성 영역에 있는 엔드포인트로 우선적으로 라우팅되도록 지정할 수 있다.
소개
기본적으로 ClusterIP 또는 NodePort 서비스로 전송된 트래픽은 서비스의
모든 백엔드 주소로 라우팅될 수 있다. 쿠버네티스 1.7을 사용하면 트래픽을 수신한
동일한 노드에서 실행 중인 파드로 "외부(external)" 트래픽을 라우팅할 수
있다. ClusterIP 서비스의 경우, 라우팅에 대한 동일한 노드 기본 설정이
불가능했다. 또한 동일한 영역 내의 엔드 포인트에 대한 라우팅을 선호하도록
클러스터를 구성할 수도 없다.
서비스에 topologyKeys 를 설정하면, 출발 및 대상 노드에 대한
노드 레이블을 기반으로 트래픽을 라우팅하는 정책을 정의할 수 있다.
소스와 목적지 사이의 레이블 일치를 통해 클러스터 운영자는 서로 "근접(closer)"하거나 "먼(father)" 노드 그룹을 지정할 수 있다. 자신의 요구 사항에 맞는 메트릭을 나타내는 레이블을 정의할 수 있다. 예를 들어, 퍼블릭 클라우드에서는 지역 간의 트래픽에는 관련 비용이 발생(지역 내 트래픽은 일반적으로 그렇지 않다)하기 때문에, 네트워크 트래픽을 동일한 지역 내에 유지하는 것을 선호할 수 있다. 다른 일반적인 필요성으로는 데몬셋(DaemonSet)이 관리하는 로컬 파드로 트래픽을 라우팅하거나, 대기 시간을 최소화하기 위해 동일한 랙 상단(top-of-rack) 스위치에 연결된 노드로 트래픽을 유지하는 것이 있다.
서비스 토폴로지 사용하기
만약 클러스터에서 ServiceTopology 기능 게이트가 활성화된 경우, 서비스 사양에서
topologyKeys 필드를 지정해서 서비스 트래픽 라우팅을 제어할 수 있다. 이 필드는
이 서비스에 접근할 때 엔드포인트를 정렬하는데 사용되는 노드
레이블의 우선 순위 목록이다. 트래픽은 첫 번째 레이블 값이 해당 레이블의
발신 노드 값과 일치하는 노드로 보내진다. 만약 노드에 서비스와 일치하는
백엔드가 없는 경우, 두 번째 레이블을 그리고 더 이상의
레이블이 남지 않을 때까지 고려한다.
만약 일치하는 것을 못찾는 경우에는, 서비스에 대한 백엔드가 없었던 것처럼
트래픽이 거부될 것이다. 즉, 엔드포인트는 사용 가능한 백엔드가 있는 첫 번째
토폴로지 키를 기반으로 선택된다. 만약 이 필드가 지정되고 모든 항목에
클라이언트의 토폴로지와 일치하는 백엔드가 없는 경우, 서비스에는 해당 클라이언트에
대한 백엔드가 없기에 연결에 실패해야 한다. 특수한 값인 "*" 은 "모든 토폴로지"를
의미하는데 사용될 수 있다. 이 캐치 올(catch-all) 값을 사용하는 경우
목록의 마지막 값으로만 타당하다.
만약 topologyKeys 가 지정되지 않거나 비어있는 경우 토폴로지 제약 조건이 적용되지 않는다.
호스트 이름, 영역 이름 그리고 지역 이름으로 레이블이 지정된 노드가 있는
클러스터가 있다고 생각해 보자. 그러고 나면, 서비스의 topologyKeys 값을 설정해서 다음과 같이 트래픽을
전달할 수 있다.
- 동일한 노드의 엔드포인트에만 해당하고, 엔드포인트가 노드에 없으면 실패한다:
["kubernetes.io/hostname"]. - 동일한 노드의 엔드포인트를 선호하지만, 동일한 영역의 엔드포인트로 대체
한 후 동일한 지역으로 대체되고, 그렇지 않으면 실패한다:
["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]. 예를 들어 데이터 위치가 중요한 경우에 유용할 수 있다. - 동일한 영역이 선호되지만, 이 영역 내에 사용할 수 있는 항목이 없는 경우에는
사용가능한 엔드포인트로 대체된다:
["topology.kubernetes.io/zone", "*"].
제약들
-
서비스 토폴로지는
externalTrafficPolicy=Local와 호환되지 않으므로 서비스는 이 두 가지 기능을 함께 사용할 수 없다. 동일한 서비스가 아닌 같은 클러스터의 다른 서비스라면 이 기능을 함께 사용할 수 있다. -
유효한 토폴로지 키는 현재
kubernetes.io/hostname,topology.kubernetes.io/zone그리고topology.kubernetes.io/region로 제한되어 있지만, 앞으로 다른 노드 레이블로 일반화 될 것이다. -
토폴로지 키는 유효한 레이블 키이어야 하며 최대 16개의 키를 지정할 수 있다.
-
만약 캐치 올(catch-all) 값인
"*"를 사용한다면 토폴로지 키들의 마지막 값이어야 한다.
예시들
다음은 서비스 토폴로지 기능을 사용하는 일반적인 예시이다.
노드 로컬 엔드포인트만
노드 로컬 엔드포인트로만 라우팅하는 서비스이다. 만약 노드에 엔드포인트가 없으면 트레픽이 드롭된다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
노드 로컬 엔드포인트 선호
노드 로컬 엔드포인트를 선호하지만, 노드 로컬 엔드포인트가 없는 경우 클러스터 전체 엔드포인트로 폴백 하는 서비스이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "*"
영역 또는 지리적 엔드포인트만
영역보다는 지리적 엔드포인트를 선호하는 서비스이다. 만약 엔드포인트가 없다면, 트래픽은 드롭된다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
노드 로컬, 영역 및 지역 엔드포인트 선호
노드 로컬, 영역 및 지역 엔드포인트를 선호하지만, 클러스터 전체 엔드포인트로 폴백하는 서비스이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"
다음 내용
- 토폴로지 인지 힌트를 읽어보기.
- 서비스와 애플리케이션 연결하기를 읽어보기.
7 - 스토리지
클러스터의 파드에 장기(long-term) 및 임시 스토리지를 모두 제공하는 방법
7.1 - 볼륨
컨테이너 내의 디스크에 있는 파일은 임시적이며, 컨테이너에서 실행될 때
애플리케이션에 적지 않은 몇 가지 문제가 발생한다. 한 가지 문제는
컨테이너가 크래시될 때 파일이 손실된다는 것이다. kubelet은 컨테이너를 다시 시작하지만
초기화된 상태이다. 두 번째 문제는 Pod에서 같이 실행되는 컨테이너간에
파일을 공유할 때 발생한다.
쿠버네티스 볼륨 추상화는
이러한 문제를 모두 해결한다.
파드에 대해 익숙해지는 것을 추천한다.
배경
도커는 다소 느슨하고, 덜 관리되지만 볼륨이라는 개념을 가지고 있다. 도커 볼륨은 디스크에 있는 디렉터리이거나 다른 컨테이너에 있다. 도커는 볼륨 드라이버를 제공하지만, 기능이 다소 제한된다.
쿠버네티스는 다양한 유형의 볼륨을 지원한다. 파드는 여러 볼륨 유형을 동시에 사용할 수 있다. 임시 볼륨 유형은 파드의 수명을 갖지만, 퍼시스턴트 볼륨은 파드의 수명을 넘어 존재한다. 파드가 더 이상 존재하지 않으면, 쿠버네티스는 임시(ephemeral) 볼륨을 삭제하지만, 퍼시스턴트(persistent) 볼륨은 삭제하지 않는다. 볼륨의 종류와 상관없이, 파드 내의 컨테이너가 재시작되어도 데이터는 보존된다.
기본적으로 볼륨은 디렉터리이며, 일부 데이터가 있을 수 있으며, 파드 내 컨테이너에서 접근할 수 있다. 디렉터리의 생성 방식, 이를 지원하는 매체와 내용은 사용된 특정 볼륨의 유형에 따라 결정된다.
볼륨을 사용하려면, .spec.volumes 에서 파드에 제공할 볼륨을 지정하고
.spec.containers[*].volumeMounts 의 컨테이너에 해당 볼륨을 마운트할 위치를 선언한다.
컨테이너의 프로세스는
컨테이너 이미지의 최초 내용물과
컨테이너 안에 마운트된 볼륨(정의된 경우에 한함)으로 구성된 파일시스템을 보게 된다.
프로세스는 컨테이너 이미지의 최초 내용물에 해당되는 루트 파일시스템을
보게 된다.
쓰기가 허용된 경우, 해당 파일시스템에 쓰기 작업을 하면
추후 파일시스템에 접근할 때 변경된 내용을 보게 될 것이다.
볼륨은 이미지의 특정 경로에
마운트된다.
파드에 정의된 각 컨테이너에 대해,
컨테이너가 사용할 각 볼륨을 어디에 마운트할지 명시해야 한다.
볼륨은 다른 볼륨 안에 마운트될 수 없다 (하지만, 서브패스 사용에서 관련 메커니즘을 확인한다). 또한, 볼륨은 다른 볼륨에 있는 내용물을 가리키는 하드 링크를 포함할 수 없다.
볼륨 유형들
쿠버네티스는 여러 유형의 볼륨을 지원한다.
awsElasticBlockStore (사용 중단됨)
기능 상태:
Kubernetes v1.17 [deprecated]
awsElasticBlockStore 볼륨은 아마존 웹 서비스 (AWS)
EBS 볼륨을 파드에 마운트 한다. 파드를
제거할 때 지워지는 emptyDir 와는 다르게 EBS 볼륨의
내용은 유지되고, 볼륨은 마운트 해제만 된다. 이 의미는 EBS 볼륨에
데이터를 미리 채울 수 있으며, 파드 간에 데이터를 "전달(handed off)"할 수 있다.
참고:
이를 사용하려면 먼저aws ec2 create-volume 또는 AWS API를 사용해서 EBS 볼륨을 생성해야 한다.awsElasticBlockStore 볼륨을 사용할 때 몇 가지 제한이 있다.
- 파드가 실행 중인 노드는 AWS EC2 인스턴스여야 함
- 이러한 인스턴스는 EBS 볼륨과 동일한 지역과 가용성 영역에 있어야 함
- EBS는 볼륨을 마운트하는 단일 EC2 인스턴스만 지원함
AWS EBS 볼륨 생성하기
파드와 함께 EBS 볼륨을 사용하려면, 먼저 EBS 볼륨을 생성해야 한다.
aws ec2 create-volume --availability-zone=eu-west-1a --size=10 --volume-type=gp2
클러스터를 띄운 영역과 생성하는 영역이 일치하는지 확인한다. 크기와 EBS 볼륨 유형이 사용에 적합한지 확인한다.
AWS EBS 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-ebs
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-ebs
name: test-volume
volumes:
- name: test-volume
# 이 AWS EBS 볼륨은 이미 존재해야 한다.
awsElasticBlockStore:
volumeID: "<volume-id>"
fsType: ext4
EBS 볼륨이 파티션된 경우, 선택적 필드인 partition: "<partition number>" 를 제공하여 마운트할 파티션을 지정할 수 있다.
AWS EBS CSI 마이그레이션
기능 상태:
Kubernetes v1.25 [stable]
awsElasticBlockStore 의 CSIMigration 기능이 활성화된 경우, 기존 인-트리 플러그인의
모든 플러그인 작업을 ebs.csi.aws.com 컨테이너 스토리지 인터페이스(CSI)
드라이버로 리디렉션한다. 이 기능을 사용하려면, 클러스터에 AWS EBS CSI
드라이버를
설치해야 한다.
AWS EBS CSI 마이그레이션 완료
기능 상태:
Kubernetes v1.17 [alpha]
컨트롤러 관리자와 kubelet에 의해 로드되지 않도록 awsElasticBlockStore 스토리지
플러그인을 끄려면, InTreePluginAWSUnregister 플래그를 true 로 설정한다.
azureDisk (사용 중단됨)
기능 상태:
Kubernetes v1.19 [deprecated]
azureDisk 볼륨 유형은 Microsoft Azure 데이터 디스크를 파드에 마운트한다.
더 자세한 내용은 azureDisk 볼륨 플러그인을 참고한다.
azureDisk CSI 마이그레이션
기능 상태:
Kubernetes v1.24 [stable]
azureDisk 의 CSIMigration 기능이 활성화된 경우,
기존 인-트리 플러그인의 모든 플러그인 작업을
disk.csi.azure.com 컨테이너 스토리지 인터페이스(CSI) 드라이버로 리다이렉트한다.
이 기능을 사용하려면, 클러스터에 Azure 디스크 CSI 드라이버 를
설치해야 한다.
azureDisk CSI 마이그레이션 완료
기능 상태:
Kubernetes v1.21 [alpha]
컨트롤러 매니저 및 kubelet이 azureDisk 스토리지 플러그인을 로드하지 않도록 하려면,
InTreePluginAzureDiskUnregister 플래그를 true로 설정한다.
azureFile (사용 중단됨)
기능 상태:
Kubernetes v1.21 [deprecated]
azureFile 볼륨 유형은 Microsoft Azure 파일 볼륨(SMB 2.1과 3.0)을 파드에
마운트한다.
더 자세한 내용은 azureFile 볼륨 플러그인을 참고한다.
azureFile CSI 마이그레이션
기능 상태:
Kubernetes v1.26 [stable]
azureFile 의 CSIMigration 기능이 활성화된 경우, 기존 트리 내 플러그인에서
file.csi.azure.com 컨테이너 스토리지 인터페이스(CSI)
드라이버로 모든 플러그인 작업을 수행한다. 이 기능을 사용하려면, 클러스터에 Azure 파일 CSI
드라이버
를 설치하고 CSIMigrationAzureFile
기능 게이트를 활성화해야 한다.
Azure File CSI 드라이버는 동일한 볼륨을 다른 fsgroup에서 사용하는 것을 지원하지 않는다. Azurefile CSI 마이그레이션이 활성화된 경우, 다른 fsgroup에서 동일한 볼륨을 사용하는 것은 전혀 지원되지 않는다.
azureFile CSI 마이그레이션 완료
기능 상태:
Kubernetes v1.21 [alpha]
컨트롤러 매니저 및 kubelet이 azureFile 스토리지 플러그인을 로드하지 않도록 하려면,
InTreePluginAzureFileUnregister 플래그를 true로 설정한다.
cephfs
cephfs 볼륨은 기존 CephFS 볼륨을
파드에 마운트 할 수 있다. 파드를 제거할 때 지워지는 emptyDir
와는 다르게 cephfs 볼륨의 내용은 유지되고, 볼륨은 그저 마운트
해제만 된다. 이 의미는 cephfs 볼륨에 데이터를 미리 채울 수 있으며,
해당 데이터는 파드 간에 공유될 수 있다. cephfs 볼륨은 여러 작성자가
동시에 마운트할 수 있다.
참고:
CephFS를 사용하기 위해선 먼저 Ceph 서버를 실행하고 공유를 내보내야 한다.더 자세한 내용은 CephFS 예시를 참조한다.
cinder (사용 중단됨)
기능 상태:
Kubernetes v1.18 [deprecated]
참고:
쿠버네티스는 오픈스택 클라우드 공급자로 구성되어야 한다.cinder 볼륨 유형은 오픈스택 Cinder 볼륨을 파드에 마운트하는데 사용된다.
Cinder 볼륨 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-cinder
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-cinder-container
volumeMounts:
- mountPath: /test-cinder
name: test-volume
volumes:
- name: test-volume
# 이 오픈스택 볼륨은 이미 존재해야 한다.
cinder:
volumeID: "<volume id>"
fsType: ext4
오픈스택 CSI 마이그레이션
기능 상태:
Kubernetes v1.24 [stable]
Cinder의CSIMigration 기능은 Kubernetes 1.21부터 기본적으로 활성화되어 있다.
기존 트리 내 플러그인에서 cinder.csi.openstack.org 컨테이너 스토리지 인터페이스(CSI)
드라이버로 모든 플러그인 작업을 수행한다.
오픈스택 Cinder CSI 드라이버가
클러스터에 설치되어 있어야 한다.
컨트롤러 매니저 및 kubelet이 인-트리 Cinder 플러그인을 로드하지 않도록 하려면,
InTreePluginOpenStackUnregister
기능 게이트를 활성화한다.
컨피그맵(configMap)
컨피그맵은
구성 데이터를 파드에 주입하는 방법을 제공한다.
컨피그맵에 저장된 데이터는 configMap 유형의 볼륨에서 참조되고
그런 다음에 파드에서 실행되는 컨테이너화된 애플리케이션이 소비한다.
컨피그맵을 참조할 때, 볼륨에 컨피그맵의 이름을
제공한다. 컨피그맵의 특정 항목에 사용할 경로를
사용자 정의할 수 있다. 다음 구성은 log-config 컨피그맵을
configmap-pod 라 부르는 파드에 마운트하는 방법을 보여준다.
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: test
image: busybox:1.28
volumeMounts:
- name: config-vol
mountPath: /etc/config
volumes:
- name: config-vol
configMap:
name: log-config
items:
- key: log_level
path: log_level
log-config 컨피그맵은 볼륨으로 마운트되며, log_level 항목에
저장된 모든 컨텐츠는 파드의 /etc/config/log_level 경로에 마운트된다.
이 경로는 볼륨의 mountPath 와 log_level 로 키가 지정된
path 에서 파생된다.
참고:
downwardAPI
downwardAPI 볼륨은 애플리케이션에서 다운워드(downward) API
데이터를 사용할 수 있도록 한다. 볼륨 내에서 노출된 데이터를
일반 텍스트 형식의 읽기 전용 파일로 찾을 수 있다.
참고:
다운워드 API를subPath 볼륨 마운트로 사용하는 컨테이너는 다운워드 API
업데이트를 수신하지 않는다.더 자세한 내용은 다운워드 API 예시 를 참고한다.
emptyDir
emptyDir 볼륨은 파드가 노드에 할당될 때 처음 생성되며,
해당 노드에서 파드가 실행되는 동안에만 존재한다. 이름에서 알 수 있듯이
emptyDir 볼륨은 처음에는 비어있다. 파드 내 모든 컨테이너는 emptyDir 볼륨에서 동일한
파일을 읽고 쓸 수 있지만, 해당 볼륨은 각각의 컨테이너에서 동일하거나
다른 경로에 마운트될 수 있다. 어떤 이유로든 노드에서 파드가 제거되면
emptyDir 의 데이터가 영구적으로 삭제된다.
참고:
컨테이너가 크래시되는 것은 노드에서 파드를 제거하지 않는다.emptyDir 볼륨의 데이터는
컨테이너 크래시로부터 안전하다.emptyDir 의 일부 용도는 다음과 같다.
- 디스크 기반의 병합 종류와 같은 스크레치 공간
- 충돌로부터 복구하기위해 긴 계산을 검사점으로 지정
- 웹 서버 컨테이너가 데이터를 처리하는 동안 컨텐츠 매니저 컨테이너가 가져오는 파일을 보관
emptyDir.medium 필드는 emptyDir 볼륨이 저장되는 곳을 제어한다.
기본 emptyDir 볼륨은 환경에 따라
디스크, SSD 또는 네트워크 스토리지와 같이 노드를 지원하는 모든 매체에 저장된다.
emptyDir.medium 필드를 "Memory"로 설정하면, 쿠버네티스는 tmpfs(RAM 기반 파일시스템)를 대신
마운트한다. tmpfs는 매우 빠르지만, 디스크와 다르게
노드 재부팅시 tmpfs는 마운트 해제되고, 작성하는 모든 파일이
컨테이너 메모리 제한에 포함된다.
emptyDir 볼륨의 용량을 제한하는 기본 medium을 위해,
크기 제한을 명시할 수 있다. 스토리지는 노드 임시
스토리지로부터 할당된다.
만약 해당 공간이 다른 소스(예를 들어, 로그 파일이나 이미지 오버레이)에 의해
채워져있다면, emptyDir는 지정된 제한 이전에 용량을 다 쓰게 될 수 있다.
참고:
SizeMemoryBackedVolumes 기능 게이트가 활성화된 경우,
메모리 기반 볼륨의 크기를 지정할 수 있다. 크기를 지정하지 않으면, 메모리
기반 볼륨의 크기는 리눅스 호스트 메모리의 50%로 조정된다.emptyDir 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
fc (파이버 채널)
fc 볼륨 유형은 기존 파이버 채널 블록 스토리지 볼륨을
파드에 마운트할 수 있게 한다. 볼륨 구성에서 targetWWNs 파라미터를 사용하여
단일 또는 다중 대상 월드 와이드 이름(WWN)을 지정할 수 있다. 만약 여러 WWN이 지정된 경우,
targetWWN은 해당 WWN이 다중 경로 연결에서 온 것으로 예상한다.
참고:
이러한 LUN (볼륨)을 할당하고 대상 WWN에 마스킹하도록 FC SAN Zoning을 구성해야만 쿠버네티스 호스트가 해당 LUN에 접근할 수 있다.더 자세한 내용은 파이버 채널 예시를 참고한다.
gcePersistentDisk (사용 중단됨)
기능 상태:
Kubernetes v1.17 [deprecated]
gcePersistentDisk 볼륨은 구글 컴퓨트 엔진(GCE)
영구 디스크(PD)를 파드에 마운트한다.
파드를 제거할 때 지워지는 emptyDir 와는 다르게, PD의 내용은 유지되고,
볼륨은 마운트 해제만 된다. 이는 PD에 데이터를
미리 채울 수 있으며, 파드 간에 데이터를 공유할 수 있다는 것을 의미한다.
참고:
gcePersistentDisk 를 사용하려면 먼저 PD를 gcloud, GCE API 또는 UI를 사용해서 생성해야 한다.gcePersistentDisk 를 사용할 때 몇 가지 제한이 있다.
- 파드가 실행 중인 노드는 GCE VM이어야 함
- 이러한 VM은 영구 디스크와 동일한 GCE 프로젝트와 영역에 있어야 함
GCE 영구 디스크의 한 가지 기능은 영구 디스크에 대한 동시 읽기 전용 접근이다.
gcePersistentDisk 볼륨을 사용하면 여러 사용자가 영구 디스크를 읽기 전용으로
동시에 마운트할 수 있다. 즉, PD를 데이터 세트로 미리 채운 다음
필요한 만큼 많은 파드에서 병렬로 제공할 수 있다. 불행히도,
PD는 읽기-쓰기 모드에서 단일 사용자만 마운트할 수 있다. 동시
쓰기는 허용되지 않는다.
PD가 읽기 전용이거나 레플리카의 수가 0 또는 1이 아니라면 레플리카셋(ReplicaSet)으로 제어되는 파드가 있는 GCE 영구 디스크를 사용할 수 없다.
GCE 영구 디스크 생성하기
GCE 영구 디스크를 파드와 함께 사용하려면, 디스크를 먼저 생성해야 한다.
gcloud compute disks create --size=500GB --zone=us-central1-a my-data-disk
GCE 영구 디스크 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
# 이 GCE PD는 이미 존재해야 한다.
gcePersistentDisk:
pdName: my-data-disk
fsType: ext4
리전 영구 디스크
리전 영구 디스크 기능을 사용하면 동일한 영역 내의 두 영역에서 사용할 수 있는 영구 디스크를 생성할 수 있다. 이 기능을 사용하려면 볼륨을 퍼시스턴트볼륨(PersistentVolume)으로 프로비저닝해야 한다. 파드에서 직접 볼륨을 참조하는 것은 지원되지 않는다.
리전 PD 퍼시스턴트볼륨을 수동으로 프로비저닝하기
GCE PD용 스토리지클래스를 사용해서 동적 프로비저닝이 가능하다. 퍼시스턴트볼륨을 생성하기 전에 영구 디스크를 생성해야만 한다.
gcloud compute disks create --size=500GB my-data-disk
--region us-central1
--replica-zones us-central1-a,us-central1-b
리전 영구 디스크 구성 예시
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-volume
spec:
capacity:
storage: 400Gi
accessModes:
- ReadWriteOnce
gcePersistentDisk:
pdName: my-data-disk
fsType: ext4
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
# 1.21 이전 버전에서는 failure-domain.beta.kubernetes.io/zone 키를 사용해야 한다.
- key: topology.kubernetes.io/zone
operator: In
values:
- us-central1-a
- us-central1-b
GCE CSI 마이그레이션
기능 상태:
Kubernetes v1.25 [stable]
GCE PD의 CSIMigration 기능이 활성화된 경우 기존 인-트리 플러그인에서
pd.csi.storage.gke.io 컨테이너 스토리지 인터페이스(CSI)
드라이버로 모든 플러그인 작업을 리디렉션한다. 이 기능을 사용하려면, 클러스터에 GCE PD CSI
드라이버
를 설치해야 한다.
GCE CSI 마이그레이션 완료
기능 상태:
Kubernetes v1.21 [alpha]
컨트롤러 매니저와 kubelet이 gcePersistentDisk 스토리지 플러그인을 로드하는 것을 방지하려면,
InTreePluginGCEUnregister 플래그를 true로 설정한다.
gitRepo (사용 중단됨)
경고:
gitRepo 볼륨 유형은 사용 중단되었다. git repo가 있는 컨테이너를 프로비전 하려면 초기화 컨테이너(InitContainer)에 EmptyDir을 마운트하고, 여기에 git을 사용해서 repo를 복제하고, EmptyDir을 파드 컨테이너에 마운트 한다.gitRepo 볼륨은 볼륨 플러그인의 예시이다. 이 플러그인은
빈 디렉터리를 마운트하고 파드가 사용할 수 있도록 이 디렉터리에 git 리포지터리를
복제한다.
여기 gitRepo 볼륨의 예시가 있다.
apiVersion: v1
kind: Pod
metadata:
name: server
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /mypath
name: git-volume
volumes:
- name: git-volume
gitRepo:
repository: "git@somewhere:me/my-git-repository.git"
revision: "22f1d8406d464b0c0874075539c1f2e96c253775"
glusterfs (제거됨)
쿠버네티스 1.31 는 glusterfs 볼륨 타입을 포함하지 않는다.
GlusterFS 인-트리 스토리지 드라이버는 쿠버네티스 1.25에서 사용 중단되었고 v1.26 릴리즈에서 완전히 제거되었다.
hostPath
경고:
HostPath 볼륨에는 많은 보안 위험이 있으며, 가능하면 HostPath를 사용하지 않는 것이 좋다. HostPath 볼륨을 사용해야 하는 경우, 필요한 파일 또는 디렉터리로만 범위를 지정하고 ReadOnly로 마운트해야 한다.
AdmissionPolicy를 사용하여 특정 디렉터리로의 HostPath 액세스를 제한하는 경우,
readOnly 마운트를 사용하는 정책이 유효하려면 volumeMounts 가 반드시 지정되어야 한다.
hostPath 볼륨은 호스트 노드의 파일시스템에 있는 파일이나 디렉터리를
파드에 마운트 한다. 이것은 대부분의 파드들이 필요한 것은 아니지만, 일부
애플리케이션에 강력한 탈출구를 제공한다.
예를 들어, hostPath 의 일부 용도는 다음과 같다.
- 도커 내부에 접근할 필요가 있는 실행중인 컨테이너.
/var/lib/docker를hostPath로 이용함 - 컨테이너에서 cAdvisor의 실행.
/sys를hostPath로 이용함 - 파드는 주어진
hostPath를 파드가 실행되기 이전에 있어야 하거나, 생성해야 하는지 그리고 존재해야 하는 대상을 지정할 수 있도록 허용함
필요한 path 속성 외에도, hostPath 볼륨에 대한 type 을 마음대로 지정할 수 있다.
필드가 type 에 지원되는 값은 다음과 같다.
| 값 | 행동 |
|---|---|
| 빈 문자열 (기본값)은 이전 버전과의 호환성을 위한 것으로, hostPath 볼륨은 마운트 하기 전에 아무런 검사도 수행되지 않는다. | |
DirectoryOrCreate |
만약 주어진 경로에 아무것도 없다면, 필요에 따라 Kubelet이 가지고 있는 동일한 그룹과 소유권, 권한을 0755로 설정한 빈 디렉터리를 생성한다. |
Directory |
주어진 경로에 디렉터리가 있어야 함 |
FileOrCreate |
만약 주어진 경로에 아무것도 없다면, 필요에 따라 Kubelet이 가지고 있는 동일한 그룹과 소유권, 권한을 0644로 설정한 빈 파일을 생성한다. |
File |
주어진 경로에 파일이 있어야 함 |
Socket |
주어진 경로에 UNIX 소캣이 있어야 함 |
CharDevice |
주어진 경로에 문자 디바이스가 있어야 함 |
BlockDevice |
주어진 경로에 블록 디바이스가 있어야 함 |
다음과 같은 이유로 이 유형의 볼륨 사용시 주의해야 한다.
- HostPath는 권한있는 시스템 자격 증명 (예 : Kubelet 용) 또는 권한있는 API (예 : 컨테이너 런타임 소켓)를 노출 할 수 있으며, 이는 컨테이너 이스케이프 또는 클러스터의 다른 부분을 공격하는 데 사용될 수 있다.
- 동일한 구성(파드템플릿으로 생성한 것과 같은)을 가진 파드는 노드에 있는 파일이 다르기 때문에 노드마다 다르게 동작할 수 있다.
- 기본 호스트에 생성된 파일 또는 디렉터리는 root만 쓸 수 있다.
프로세스를 특권을 가진(privileged) 컨테이너에서
루트로 실행하거나
hostPath볼륨에 쓸 수 있도록 호스트의 파일 권한을 수정해야 한다.
hostPath 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# 호스트의 디렉터리 위치
path: /data
# 이 필드는 선택 사항이다
type: Directory
주의:
FileOrCreate 모드는 파일의 상위 디렉터리를 생성하지 않는다. 마운트된 파일의 상위 디렉터리가
없으면 파드가 시작되지 않는다. 이 모드가 작동하는지 확인하려면,
FileOrCreate 구성에 표시된대로
디렉터리와 파일을 별도로 마운트할 수 있다.hostPath FileOrCreate 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: test-webserver
spec:
containers:
- name: test-webserver
image: registry.k8s.io/test-webserver:latest
volumeMounts:
- mountPath: /var/local/aaa
name: mydir
- mountPath: /var/local/aaa/1.txt
name: myfile
volumes:
- name: mydir
hostPath:
# 파일 디렉터리가 생성되었는지 확인한다.
path: /var/local/aaa
type: DirectoryOrCreate
- name: myfile
hostPath:
path: /var/local/aaa/1.txt
type: FileOrCreate
iscsi
iscsi 볼륨을 사용하면 기존 iSCSI (SCSI over IP) 볼륨을 파드에 마운트
할수 있다. 파드를 제거할 때 지워지는 emptyDir 와는
다르게 iscsi 볼륨의 내용은 유지되고, 볼륨은 그저 마운트
해제만 된다. 이 의미는 iscsi 볼륨에 데이터를 미리 채울 수 있으며,
파드간에 데이터를 공유할 수 있다는 것이다.
참고:
사용하려면 먼저 iSCSI 서버를 실행하고 볼륨을 생성해야 한다.iSCSI 특징은 여러 고객이 읽기 전용으로 마운트할 수 있다는 것이다. 즉, 데이터셋으로 사전에 볼륨을 채운다음, 필요한 만큼 많은 파드에서 병렬로 제공할 수 있다. 불행하게도, iSCSI 볼륨은 읽기-쓰기 모드에서는 단일 고객만 마운트할 수 있다. 동시 쓰기는 허용되지 않는다.
더 자세한 내용은 iSCSI 예시를 본다.
local
local 볼륨은 디스크, 파티션 또는 디렉터리 같은 마운트된 로컬 스토리지
장치를 나타낸다.
로컬 볼륨은 정적으로 생성된 퍼시스턴트볼륨으로만 사용할 수 있다. 동적으로 프로비저닝된 것은 지원되지 않는다.
hostPath 볼륨에 비해 local 볼륨은 수동으로 파드를 노드에 예약하지 않고도
내구성과 휴대성을 갖춘 방식으로 사용된다. 시스템은
퍼시스턴트볼륨의 노드 어피니티를 확인하여 볼륨의 노드 제약 조건을 인식한다.
그러나 local 볼륨은 여전히 기본 노드의 가용성을 따르며
모든 애플리케이션에 적합하지는 않는다. 만약 노드가 비정상 상태가
되면 local 볼륨도 접근할 수 없게 되고, 파드를 실행할 수
없게 된다. local 볼륨을 사용하는 애플리케이션은 기본 디스크의
내구 특성에 따라 이러한 감소되는 가용성과 데이터
손실 가능성도 허용할 수 있어야 한다.
다음의 예시는 local 볼륨과 nodeAffinity 를 사용하는 퍼시스턴트볼륨을
보여준다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- example-node
local 볼륨을 사용하는 경우 퍼시스턴트볼륨 nodeAffinity 를 설정해야 합니다.
쿠버네티스 스케줄러는 퍼시스턴트볼륨 nodeAffinity 를 사용하여
파드를 올바른 노드로 스케줄한다.
퍼시스턴트볼륨의 volumeMode 을 "Block" (기본값인 "Filesystem"을
대신해서)으로 설정하면 로컬 볼륨을 원시 블록 장치로 노출할 수 있다.
로컬 볼륨을 사용할 때는 volumeBindingMode 가 WaitForFirstConsumer 로 설정된
스토리지클래스(StorageClass)를 생성하는 것을 권장한다. 자세한 내용은
local 스토리지클래스(StorageClas) 예제를 참고한다.
볼륨 바인딩을 지연시키는 것은 퍼시스턴트볼륨클래임 바인딩 결정도
노드 리소스 요구사항, 노드 셀렉터, 파드 어피니티 그리고 파드 안티 어피니티와
같이 파드가 가질 수 있는 다른 노드 제약 조건으로 평가되도록 만든다.
로컬 볼륨 라이프사이클의 향상된 관리를 위해 외부 정적 프로비저너를 별도로 실행할 수 있다. 이 프로비저너는 아직 동적 프로비저닝을 지원하지 않는 것을 참고한다. 외부 로컬 프로비저너를 실행하는 방법에 대한 예시는 로컬 볼륨 프로비저너 사용자 가이드를 본다.
참고:
로컬 정적 프로비저너를 사용해서 볼륨 라이프사이클을 관리하지 않는 경우 로컬 퍼시스턴트볼륨을 수동으로 정리하고 삭제하는 것이 필요하다.nfs
nfs 볼륨을 사용하면 기존 NFS (네트워크 파일 시스템) 볼륨을 파드에 마운트
할수 있다. 파드를 제거할 때 지워지는 emptyDir 와는
다르게 nfs 볼륨의 내용은 유지되고, 볼륨은 그저 마운트
해제만 된다. 이 의미는 NFS 볼륨에 데이터를 미리 채울 수 있으며,
파드 간에 데이터를 공유할 수 있다는 뜻이다. NFS는 여러 작성자가
동시에 마운트할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /my-nfs-data
name: test-volume
volumes:
- name: test-volume
nfs:
server: my-nfs-server.example.com
path: /my-nfs-volume
readOnly: true
참고:
사용하려면 먼저 NFS 서버를 실행하고 공유를 내보내야 한다.
또한 파드 스펙에 NFS 마운트 옵션을 명시할 수 없음을 기억하라. 마운트 옵션을 서버에서 설정하거나, /etc/nfsmount.conf를 사용해야 한다. 마운트 옵션을 설정할 수 있게 허용하는 퍼시스턴트볼륨을 통해 NFS 볼륨을 마운트할 수도 있다.
퍼시스턴트볼륨을 사용하여 NFS 볼륨을 마운트하는 예제는 NFS 예시를 본다.
persistentVolumeClaim
persistentVolumeClaim 볼륨은
퍼시스턴트볼륨을 파드에 마운트하는데 사용한다. 퍼시스턴트볼륨클레임은
사용자가 특정 클라우드 환경의 세부 내용을 몰라도 내구성이있는 스토리지 (GCE 퍼시스턴트디스크 또는
iSCSI 볼륨와 같은)를 "클레임" 할 수 있는 방법이다.
더 자세한 내용은 퍼시스턴트볼륨 예시를 본다.
portworxVolume (사용 중단됨)
기능 상태:
Kubernetes v1.25 [deprecated]
portworxVolume 은 쿠버네티스와 하이퍼컨버지드(hyperconverged)를 실행하는 탄력적인 블록 스토리지
계층이다. Portworx는 서버의
스토리지를 핑거프린팅하고(fingerprints), 기능에 기반하여 계층화하고, 그리고 여러 서버에 걸쳐 용량을 집계한다.
Portworx는 가상 머신 내 게스트 또는 베어 메탈 리눅스 노드 위에서 실행된다.
portworxVolume 은 쿠버네티스를 통해 동적으로 생성되거나
사전에 프로비전할 수 있으며 쿠버네티스 파드 내에서 참조할 수 있다.
다음은 사전에 프로비저닝된 Portworx 볼륨을 참조하는 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: test-portworx-volume-pod
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /mnt
name: pxvol
volumes:
- name: pxvol
# 이 Portworx 볼륨은 이미 존재해야 한다.
portworxVolume:
volumeID: "pxvol"
fsType: "<fs-type>"
참고:
파드에서 사용하기 이전에 먼저 이름이pxvol 인 PortworxVolume이
있는지 확인한다.자세한 내용은 Portworx 볼륨 예제를 참고한다.
Portworx CSI 마이그레이션
기능 상태:
Kubernetes v1.25 [beta]
Portworx를 위한 CSIMigration 기능이 쿠버네티스 1.23에 추가되었지만 알파 상태이기 때문에 기본적으로는 비활성화되어 있었다.
v1.25 이후 이 기능은 베타 상태가 되었지만 여전히 기본적으로는 비활성화되어 있다.
이 기능은 사용 중인 트리 내(in-tree) 플러그인의 모든 동작을
pxd.portworx.com CSI 드라이버로 리다이렉트한다.
이 기능을 사용하려면, 클러스터에 Portworx CSI 드라이버가
설치되어 있어야 한다.
이 기능을 활성화시키기 위해서는 kube-controller-manager와 kubelet에 CSIMigrationPortworx=true를 설정해야 한다.
projected
Projected 볼륨은 여러 기존 볼륨 소스를 동일한 디렉터리에 매핑한다.
더 자세한 사항은 projected volumes를 참고한다.
rbd
rbd 볼륨을 사용하면
Rados Block Device(RBD) 볼륨을 파드에 마운트할 수
있다. 파드를 제거할 때 지워지는 emptyDir 와는 다르게 rbd 볼륨의
내용은 유지되고, 볼륨은 마운트 해제만 된다. 이
의미는 RBD 볼륨에 데이터를 미리 채울 수 있으며, 데이터를
공유할 수 있다는 것이다.
참고:
RBD를 사용하기 위해선 먼저 Ceph를 설치하고 실행해야 한다.RBD의 특징은 여러 고객이 동시에 읽기 전용으로 마운트할 수 있다는 것이다. 즉, 데이터셋으로 볼륨을 미리 채운 다음, 필요한 만큼 많은 파드에서 병렬로 제공할수 있다. 불행하게도, RBD는 읽기-쓰기 모드에서 단일 고객만 마운트할 수 있다. 동시 쓰기는 허용되지 않는다.
더 자세한 내용은 RBD 예시를 참고한다.
RBD CSI 마이그레이션
기능 상태:
Kubernetes v1.23 [alpha]
RBD를 위한 CSIMigration 기능이 활성화되어 있으면,
사용 중이 트리 내(in-tree) 플러그인의 모든 플러그인 동작을
rbd.csi.ceph.com CSI
드라이버로 리다이렉트한다.
이 기능을 사용하려면, 클러스터에
Ceph CSI 드라이버가 설치되어 있고
csiMigrationRBD 기능 게이트가
활성화되어 있어야 한다. (v1.24 릴리즈에서 csiMigrationRBD 플래그는 삭제되었으며
CSIMigrationRBD로 대체되었음에 주의한다.)
참고:
스토리지를 관리하는 쿠버네티스 클러스터 관리자는, RBD CSI 드라이버로의 마이그레이션을 시도하기 전에 다음의 선행 사항을 완료해야 한다.
- 쿠버네티스 클러스터에 Ceph CSI 드라이버 (
rbd.csi.ceph.com) v3.5.0 이상을 설치해야 한다. - CSI 드라이버가 동작하기 위해
clusterID필드가 필수이지만 트리 내(in-tree) 스토리지클래스는monitors필드가 필수임을 감안하여, 쿠버네티스 저장소 관리자는 monitors 값의 해시(예:#echo -n '<monitors_string>' | md5sum) 기반으로 clusterID를 CSI 컨피그맵 내에 만들고 이 clusterID 환경 설정 아래에 monitors 필드를 유지해야 한다. - 또한, 트리 내(in-tree) 스토리지클래스의
adminId값이admin이 아니면, 트리 내(in-tree) 스토리지클래스의adminSecretName값이adminId파라미터 값의 base64 값으로 패치되어야 하며, 아니면 이 단계를 건너뛸 수 있다.
secret
secret 볼륨은 암호와 같은 민감한 정보를 파드에 전달하는데
사용된다. 쿠버네티스 API에 시크릿을 저장하고 쿠버네티스에 직접적으로 연결하지 않고도
파드에서 사용할 수 있도록 파일로 마운트 할 수 있다. secret 볼륨은
tmpfs(RAM 기반 파일시스템)로 지원되기 때문에 비 휘발성 스토리지에 절대
기록되지 않는다.
참고:
사용하기 위해선 먼저 쿠버네티스 API에서 시크릿을 생성해야 한다.참고:
시크릿을subPath 볼륨 마운트로 사용하는 컨테이너는 시크릿
업데이트를 수신하지 못한다.더 자세한 내용은 시크릿 구성하기를 참고한다.
vsphereVolume (사용 중단됨)
참고:
이 드라이버 대신 외부(out-of-tree) vSphere CSI 드라이버를 사용하는 것을 권장한다.vsphereVolume 은 vSphere VMDK 볼륨을 파드에 마운트하는데 사용된다. 볼륨을
마운트 해제해도 볼륨의 내용이 유지된다. VMFS와 VSAM 데이터스토어를 모두 지원한다.
더 자세한 내용은 vSphere 볼륨 예제를 참고한다.
vSphere CSI 마이그레이션
기능 상태:
Kubernetes v1.26 [stable]
쿠버네티스 1.31에서, 인-트리 vsphereVolume 타입을 위한 모든 작업은
csi.vsphere.vmware.com CSI 드라이버로 리다이렉트된다.
vSphere CSI 드라이버가
클러스터에 설치되어 있어야 한다. 인-트리 vsphereVolume 마이그레이션에 대한 추가 조언은 VMware의 문서 페이지
인-트리 vSphere 볼륨을 vSphere 컨테이너 스토리지 플러그인으로 마이그레이션하기를 참고한다.
vSphere CSI 드라이버가 설치되어있지 않다면 볼륨 작업은 인-트리 vsphereVolume 타입으로 생성된 PV에서 수행될 수 없다.
vSphere CSI 드라이버로 마이그레이션하기 위해서는 vSphere 7.0u2 이상을 사용해야 한다.
v1.31 외의 쿠버네티스 버전을 사용 중인 경우, 해당 쿠버네티스 버전의 문서를 참고한다.
참고:
빌트인 vsphereVolume 플러그인의 다음 스토리지클래스 파라미터는 vSphere CSI 드라이버에서 지원되지 않는다.
diskformathostfailurestotolerateforceprovisioningcachereservationdiskstripesobjectspacereservationiopslimit
이러한 파라미터를 사용하여 생성된 기존 볼륨은 vSphere CSI 드라이버로 마이그레이션되지만, vSphere CSI 드라이버에서 생성된 새 볼륨은 이러한 파라미터를 따르지 않는다.
vSphere CSI 마이그레이션 완료
기능 상태:
Kubernetes v1.19 [beta]
vsphereVolume 플러그인이 컨트롤러 관리자와 kubelet에 의해 로드되지 않도록 기능을 비활성화하려면, InTreePluginvSphereUnregister 기능 플래그를 true 로 설정해야 한다. 이를 위해서는 모든 워커 노드에 csi.vsphere.vmware.com CSI 드라이버를 설치해야 한다.
subPath 사용하기
때로는 단일 파드에서 여러 용도의 한 볼륨을 공유하는 것이 유용하다.
volumeMounts[*].subPath 속성을 사용해서 root 대신 참조하는 볼륨 내의 하위 경로를
지정할 수 있다.
다음의 예시는 단일 공유 볼륨을 사용하여 LAMP 스택(리눅스 Apache MySQL PHP)이
있는 파드를 구성하는 방법을 보여준다. 이 샘플 subPath 구성은 프로덕션 용도로
권장되지 않는다.
PHP 애플리케이션의 코드와 자산은 볼륨의 html 폴더에 매핑되고
MySQL 데이터베이스는 볼륨의 mysql 폴더에 저장된다. 예를 들면 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
name: my-lamp-site
spec:
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "rootpasswd"
volumeMounts:
- mountPath: /var/lib/mysql
name: site-data
subPath: mysql
- name: php
image: php:7.0-apache
volumeMounts:
- mountPath: /var/www/html
name: site-data
subPath: html
volumes:
- name: site-data
persistentVolumeClaim:
claimName: my-lamp-site-data
subPath를 확장된 환경 변수와 함께 사용하기
기능 상태:
Kubernetes v1.17 [stable]
subPathExpr 필드를 사용해서 다운워드 API 환경 변수로부터
subPath 디렉터리 이름을 구성한다.
subPath 와 subPathExpr 속성은 상호 배타적이다.
이 예제는 Pod 가 subPathExpr 을 사용해서 hostPath 볼륨
/var/log/pods 내에 pod1 디렉터리를 만든다.
hostPath 볼륨은 downwardAPI 에서 Pod 이름을 사용한다.
호스트 디렉토리 /var/log/pods/pod1 은 컨테이너의 /logs 에 마운트된다.
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: container1
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
image: busybox:1.28
command: [ "sh", "-c", "while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt" ]
volumeMounts:
- name: workdir1
mountPath: /logs
# 변수 확장에는 괄호를 사용한다(중괄호 아님).
subPathExpr: $(POD_NAME)
restartPolicy: Never
volumes:
- name: workdir1
hostPath:
path: /var/log/pods
리소스
emptyDir 볼륨의 스토리지 매체(디스크나 SSD와 같은)는 kubelet root
디렉터리(보통 /var/lib/kubelet)를 보유한 파일시스템의
매체에 의해 결정 된다. emptyDir 또는 hostPath 볼륨이
사용할 수 있는 공간의 크기는 제한이 없으며, 컨테이너 간 또는 파드 간 격리는
없다.
리소스 사양을 사용한 공간 요청에 대한 자세한 내용은 리소스 관리 방법을 참고한다.
아웃-오브-트리(out-of-tree) 볼륨 플러그인
아웃-오브-트리 볼륨 플러그인에는 컨테이너 스토리지 인터페이스(CSI) 그리고 FlexVolume(사용 중단됨)이 포함된다. 이러한 플러그인을 사용하면 스토리지 벤더들은 플러그인 소스 코드를 쿠버네티스 리포지터리에 추가하지 않고도 사용자 정의 스토리지 플러그인을 만들 수 있다.
이전에는 모든 볼륨 플러그인이 "인-트리(in-tree)"에 있었다. "인-트리" 플러그인은 쿠버네티스 핵심 바이너리와 함께 빌드, 링크, 컴파일 및 배포되었다. 즉, 쿠버네티스(볼륨 플러그인)에 새로운 스토리지 시스템을 추가하려면 쿠버네티스 핵심 코드 리포지터리의 코드 확인이 필요했음을 의미한다.
CSI와 FlexVolume을 통해 쿠버네티스 코드 베이스와는 독립적으로 볼륨 플러그인을 개발하고, 쿠버네티스 클러스터의 확장으로 배포(설치) 할 수 있다.
아웃 오브 트리(out-of-tree) 볼륨 플러그인을 생성하려는 스토리지 벤더는 볼륨 플러그인 FAQ를 참조한다.
csi
컨테이너 스토리지 인터페이스(CSI)는 컨테이너 오케스트레이션 시스템(쿠버네티스와 같은)을 위한 표준 인터페이스를 정의하여 임의의 스토리지 시스템을 컨테이너 워크로드에 노출시킨다.
더 자세한 정보는 CSI 디자인 제안을 읽어본다.
참고:
CSI 규격 버전 0.2와 0.3에 대한 지원은 쿠버네티스 v1.13에서 사용중단(deprecated) 되었고, 향후 릴리스에서 제거될 예정이다.참고:
CSI 드라이버는 일부 쿠버네티스 릴리스에서 호환되지 않을 수 있다. 각각의 쿠버네티스 릴리스와 호환성 매트릭스에 대해 지원되는 배포 단계는 특정 CSI 드라이버 문서를 참조한다.CSI 호환 볼륨 드라이버가 쿠버네티스 클러스터에 배포되면
사용자는 csi 볼륨 유형을 사용해서 CSI 드라이버에 의해 노출된 볼륨에 연결하거나
마운트할 수 있다.
csi 볼륨은 세 가지 방법으로 파드에서 사용할 수 있다.
- 퍼시스턴트볼륨클레임에 대한 참조를 통해서
- 일반 임시 볼륨과 함께
- 드라이버가 지원하는 경우 CSI 임시 볼륨과 함께
스토리지 관리자가 다음 필드를 사용해서 CSI 퍼시스턴트 볼륨을 구성할 수 있다.
driver: 사용할 볼륨 드라이버의 이름을 지정하는 문자열 값. 이 값은 CSI 사양에 정의된 CSI 드라이버가GetPluginInfoResponse에 반환하는 값과 일치해야 한다. 쿠버네티스에서 호출할 CSI 드라이버를 식별하고, CSI 드라이버 컴포넌트에서 CSI 드라이버에 속하는 PV 오브젝트를 식별하는데 사용한다.volumeHandle: 볼륨을 식별하게 하는 고유한 문자열 값. 이 값은 CSI 사양에 정의된 CSI 드라이버가CreateVolumeResponse의volume.id필드에 반환하는 값과 일치해야 한다. 이 값은 볼륨을 참조할 때 CSI 볼륨 드라이버에 대한 모든 호출에volume_id값을 전달한다.readOnly: 볼륨을 읽기 전용으로 "ControllerPublished" (연결)할지 여부를 나타내는 선택적인 불리언(boolean) 값. 기본적으로 false 이다. 이 값은ControllerPublishVolumeRequest의readonly필드를 통해 CSI 드라이버로 전달된다.fsType: 만약 PV의VolumeMode가Filesystem인 경우에 이 필드는 볼륨을 마운트하는 데 사용해야 하는 파일시스템을 지정하는 데 사용될 수 있다. 만약 볼륨이 포맷되지 않았고 포맷이 지원되는 경우, 이 값은 볼륨을 포맷하는데 사용된다. 이 값은ControllerPublishVolumeRequest,NodeStageVolumeRequest그리고NodePublishVolumeRequest의VolumeCapability필드를 통해 CSI 드라이버로 전달된다.volumeAttributes: 볼륨의 정적 속성을 지정하는 문자열과 문자열을 매핑한다. 이 매핑은 CSI 사양에 정의된 대로 CSI 드라이버의CreateVolumeResponse와volume.attributes필드에서 반환되는 매핑과 일치해야 한다. 이 매핑은ControllerPublishVolumeRequest,NodeStageVolumeRequest, 그리고NodePublishVolumeRequest의volume_context필드를 통해 CSI 드라이버로 전달된다.controllerPublishSecretRef: CSI의ControllerPublishVolume그리고ControllerUnpublishVolume호출을 완료하기 위해 CSI 드라이버에 전달하려는 민감한 정보가 포함된 시크릿 오브젝트에 대한 참조이다. 이 필드는 선택 사항이며, 시크릿이 필요하지 않은 경우 비어있을 수 있다. 만약 시크릿에 둘 이상의 시크릿이 포함된 경우에도 모든 시크릿이 전달된다.nodeExpandSecretRef: CSINodeExpandVolume호출을 완료하기 위해 CSI 드라이버에 전달하려는 민감한 정보를 포함하고 있는 시크릿에 대한 참조이다. 이 필드는 선택 사항이며, 시크릿이 필요하지 않은 경우 비어있을 수 있다. 오브젝트에 둘 이상의 시크릿이 포함된 경우에도, 모든 시크릿이 전달된다. 노드에 의해 시작된 볼륨 확장을 위한 시크릿 정보를 설정하면, kubelet은NodeExpandVolume()호출을 통해 CSI 드라이버에 해당 데이터를 전달한다.nodeExpandSecretRef필드를 사용하기 위해, 클러스터는 쿠버네티스 버전 1.25 이상을 실행 중이어야 하며 모든 노드의 모든 kube-apiserver와 kubelet을 대상으로CSINodeExpandSecret기능 게이트를 활성화해야 한다. 또한 노드에 의해 시작된 스토리지 크기 조정 작업 시 시크릿 정보를 지원하거나 필요로 하는 CSI 드라이버를 사용해야 한다.nodePublishSecretRef: CSI의NodePublishVolume호출을 완료하기 위해 CSI 드라이버에 전달하려는 민감한 정보가 포함 된 시크릿 오브젝트에 대한 참조이다. 이 필드는 선택 사항이며, 시크릿이 필요하지 않은 경우 비어있을 수 있다. 만약 시크릿 오브젝트에 둘 이상의 시크릿이 포함된 경우에도 모든 시크릿이 전달된다.nodeStageSecretRef: CSI의NodeStageVolume호출을 완료하기위해 CSI 드라이버에 전달하려는 민감한 정보가 포함 된 시크릿 오브젝트에 대한 참조이다. 이 필드는 선택 사항이며, 시크릿이 필요하지 않은 경우 비어있을 수 있다. 만약 시크릿에 둘 이상의 시크릿이 포함된 경우에도 모든 시크릿이 전달된다.
CSI 원시(raw) 블록 볼륨 지원
기능 상태:
Kubernetes v1.18 [stable]
외부 CSI 드라이버가 있는 벤더들은 쿠버네티스 워크로드에서 원시(raw) 블록 볼륨 지원을 구현할 수 있다.
CSI 설정 변경 없이 평소와 같이 원시 블록 볼륨 지원으로 퍼시스턴트볼륨/퍼시스턴트볼륨클레임 설정을 할 수 있다.
CSI 임시(ephemeral) 볼륨
기능 상태:
Kubernetes v1.25 [stable]
파드 명세 내에서 CSI 볼륨을 직접 구성할 수 있다. 이 방식으로 지정된 볼륨은 임시 볼륨이며 파드가 다시 시작할 때 지속되지 않는다. 자세한 내용은 임시 볼륨을 참고한다.
CSI 드라이버의 개발 방법에 대한 더 자세한 정보는 쿠버네티스-csi 문서를 참조한다.
윈도우 CSI 프록시
기능 상태:
Kubernetes v1.22 [stable]
CSI 노드 플러그인은 디스크 장치 검색 및 파일 시스템 마운트 같은 다양한 권한이 부여된 작업을 수행해야 한다. 이러한 작업은 호스트 운영 체제마다 다르다. 리눅스 워커 노드의 경우, 일반적으로 컨테이너형 CSI 노드 플러그인은 권한 있는 컨테이너로 배포된다. 윈도우 워커 노드의 경우, 각 윈도우 노드에 미리 설치해야 하는 커뮤니티판 스탠드얼론(stand-alone) 바이너리인 csi-proxy를 이용하여 컨테이너형 CSI 노드 플러그인에 대한 권한 있는 작업을 지원한다.
자세한 내용은 배포할 CSI 플러그인의 배포 가이드를 참고한다.
인-트리 플러그인으로부터 CSI 드라이버로 마이그레이션하기
기능 상태:
Kubernetes v1.25 [stable]
CSIMigration 기능은 기존의 인-트리 플러그인에
대한 작업을 해당 CSI 플러그인(설치와 구성이 될 것으로 예상한)으로 유도한다.
결과적으로, 운영자는 인-트리 플러그인을 대체하는
CSI 드라이버로 전환할 때 기존 스토리지 클래스, 퍼시스턴트볼륨 또는 퍼시스턴트볼륨클레임(인-트리 플러그인 참조)에
대한 구성 변경을 수행할 필요가 없다.
지원되는 작업 및 기능은 프로비저닝/삭제, 연결/분리, 마운트/마운트 해제 그리고 볼륨 크기 재조정이 포함된다.
CSIMigration 을 지원하고 해당 CSI 드라이버가 구현된 인-트리 플러그인은
볼륨 유형들에 나열되어 있다.
다음 인-트리 플러그인은 윈도우 노드에서 퍼시스턴트볼륨을 지원한다.
flexVolume (사용 중단됨)
기능 상태:
Kubernetes v1.23 [deprecated]
FlexVolume은 스토리지 드라이버와 인터페이싱하기 위해 exec 기반 모델을 사용하는 아웃-오브-트리 플러그인 인터페이스이다. FlexVolume 드라이버 바이너리 파일은 각 노드의 미리 정의된 볼륨 플러그인 경로에 설치되어야 하며, 일부 경우에는 컨트롤 플레인 노드에도 설치되어야 한다.
파드는 flexvolume 인-트리 볼륨 플러그인을 통해 FlexVolume 드라이버와 상호 작용한다.
더 자세한 내용은 FlexVolume README 문서를 참고한다.
호스트에 PowerShell 스크립트로 배포된 다음과 같은 FlexVolume 플러그인은 윈도우 노드를 지원한다.
참고:
FlexVolume은 사용 중단되었다. 쿠버네티스에 외부 스토리지를 연결하려면 아웃-오브-트리 CSI 드라이버를 사용하는 것을 권장한다.
FlexVolume 드라이버 메인테이너는 CSI 드라이버를 구현하고 사용자들이 FlexVolume 드라이버에서 CSI로 마이그레이트할 수 있도록 지원해야 한다. FlexVolume 사용자는 워크로드가 동등한 CSI 드라이버를 사용하도록 이전해야 한다.
마운트 전파(propagation)
마운트 전파를 통해 컨테이너가 마운트한 볼륨을 동일한 파드의 다른 컨테이너 또는 동일한 노드의 다른 파드로 공유할 수 있다.
볼륨 마운트 전파는 containers[*].volumeMounts 의 mountPropagation 필드에
의해 제어된다. 그 값은 다음과 같다.
-
None- 이 볼륨 마운트는 호스트의 볼륨 또는 해당 서브디렉터리에 마운트된 것을 마운트 이후에 수신하지 않는다. 비슷한 방식으로, 컨테이너가 생성한 마운트는 호스트에서 볼 수 없다. 이것이 기본 모드이다.이 모드는 리눅스 커널 문서에 설명된
rshared마운트 전파와 같다. -
HostToContainer- 이 볼륨 마운트는 볼륨 또는 해당 서브디렉터리를 마운트한 정보를 수신한다.다시 말하면, 만약 호스트가 볼륨 마운트 내부에 다른 것을 마운트 하더라도 컨테이너가 마운트된 것을 볼 수 있다.
마찬가지로
Bidirectional마운트 전파가 있는 파드가 동일한 마운트가 된 경우에 파드에HostToContainer마운트 전파가 있는 컨테이너가 이를 볼 수 있다.이 모드는 리눅스 커널 문서에 설명된
rshared마운트 전파와 같다. -
Bidirectional- 이 볼륨 마운트는HostToContainer마운트와 동일하게 작동한다. 추가로 컨테이너에서 생성된 모든 볼륨 마운트는 동일한 볼륨을 사용하는 모든 파드의 모든 컨테이너와 호스트로 다시 전파된다.이 모드의 일반적인 유스 케이스로는 FlexVolume 또는 CSI 드라이버를 사용하는 파드 또는
hostPath볼륨을 사용하는 호스트에 무언가를 마운트해야 하는 파드이다.이 모드는 리눅스 커널 문서에 설명된
rshared마운트 전파와 같다.
경고:
Bidirectional 마운트 전파는 위험할 수 있다. 이것은
호스트 운영체제를 손상시킬 수 있기에 권한이 있는 컨테이너에서만
허용된다. 리눅스 커널 동작을 숙지하는 것을 권장한다.
또한 파드 내 컨테이너에 의해 생성된 볼륨 마운트는 종료 시
컨테이너에 의해 파괴(마운트 해제)되어야 한다.구성
일부 배포판(CoreOS, RedHat/Centos, Ubuntu)에서 마운트 전파가 제대로 작동하려면 아래와 같이 도커에서의 마운트 공유를 올바르게 구성해야 한다.
도커의 systemd 서비스 파일을 편집한다. MountFlags 를 다음과 같이 설정한다.
MountFlags=shared
또는 MountFlags=slave 가 있으면 제거한다. 이후 도커 데몬을 재시작 한다.
sudo systemctl daemon-reload
sudo systemctl restart docker
다음 내용
퍼시스턴트 볼륨과 함께 워드프레스와 MySQL 배포하기의 예시를 따른다.
7.2 - 퍼시스턴트 볼륨
이 페이지에서는 쿠버네티스의 퍼시스턴트 볼륨 에 대해 설명한다. 볼륨에 대해 익숙해지는 것을 추천한다.
소개
스토리지 관리는 컴퓨트 인스턴스 관리와는 별개의 문제다. 퍼시스턴트볼륨 서브시스템은 사용자 및 관리자에게 스토리지 사용 방법에서부터 스토리지가 제공되는 방법에 대한 세부 사항을 추상화하는 API를 제공한다. 이를 위해 퍼시스턴트볼륨 및 퍼시스턴트볼륨클레임이라는 두 가지 새로운 API 리소스를 소개한다.
퍼시스턴트볼륨 (PV)은 관리자가 프로비저닝하거나 스토리지 클래스를 사용하여 동적으로 프로비저닝한 클러스터의 스토리지이다. 노드가 클러스터 리소스인 것처럼 PV는 클러스터 리소스이다. PV는 Volumes와 같은 볼륨 플러그인이지만, PV를 사용하는 개별 파드와는 별개의 라이프사이클을 가진다. 이 API 오브젝트는 NFS, iSCSI 또는 클라우드 공급자별 스토리지 시스템 등 스토리지 구현에 대한 세부 정보를 담아낸다.
퍼시스턴트볼륨클레임 (PVC)은 사용자의 스토리지에 대한 요청이다. 파드와 비슷하다. 파드는 노드 리소스를 사용하고 PVC는 PV 리소스를 사용한다. 파드는 특정 수준의 리소스(CPU 및 메모리)를 요청할 수 있다. 클레임은 특정 크기 및 접근 모드를 요청할 수 있다(예: ReadWriteOnce, ReadOnlyMany 또는 ReadWriteMany로 마운트 할 수 있음. AccessModes 참고).
퍼시스턴트볼륨클레임을 사용하면 사용자가 추상화된 스토리지 리소스를 사용할 수 있지만, 다른 문제들 때문에 성능과 같은 다양한 속성을 가진 퍼시스턴트볼륨이 필요한 경우가 일반적이다. 클러스터 관리자는 사용자에게 해당 볼륨의 구현 방법에 대한 세부 정보를 제공하지 않고 크기와 접근 모드와는 다른 방식으로 다양한 퍼시스턴트볼륨을 제공할 수 있어야 한다. 이러한 요구에는 스토리지클래스 리소스가 있다.
실습 예제와 함께 상세한 내용을 참고하길 바란다.
볼륨과 클레임 라이프사이클
PV는 클러스터 리소스이다. PVC는 해당 리소스에 대한 요청이며 리소스에 대한 클레임 검사 역할을 한다. PV와 PVC 간의 상호 작용은 다음 라이프사이클을 따른다.
프로비저닝
PV를 프로비저닝 할 수 있는 두 가지 방법이 있다: 정적(static) 프로비저닝과 동적(dynamic) 프로비저닝
정적 프로비저닝
클러스터 관리자는 여러 PV를 만든다. 클러스터 사용자가 사용할 수 있는 실제 스토리지의 세부 사항을 제공한다. 이 PV들은 쿠버네티스 API에 존재하며 사용할 수 있다.
동적 프로비저닝
관리자가 생성한 정적 PV가 사용자의 퍼시스턴트볼륨클레임과 일치하지 않으면
클러스터는 PVC를 위해 특별히 볼륨을 동적으로 프로비저닝 하려고 시도할 수 있다.
이 프로비저닝은 스토리지클래스를 기반으로 한다. PVC는
스토리지 클래스를
요청해야 하며 관리자는 동적 프로비저닝이 발생하도록 해당 클래스를 생성하고 구성해야 한다.
"" 클래스를 요청하는 클레임은 동적 프로비저닝을 효과적으로
비활성화한다.
스토리지 클래스를 기반으로 동적 스토리지 프로비저닝을 사용하려면 클러스터 관리자가 API 서버에서
DefaultStorageClass 어드미션 컨트롤러를 사용하도록 설정해야 한다.
예를 들어 API 서버 컴포넌트의 --enable-admission-plugins 플래그에 대한 쉼표로 구분되어
정렬된 값들의 목록 중에 DefaultStorageClass가 포함되어 있는지 확인하여 설정할 수 있다.
API 서버 커맨드라인 플래그에 대한 자세한 정보는
kube-apiserver 문서를 확인하면 된다.
바인딩
사용자는 원하는 특정 용량의 스토리지와 특정 접근 모드로 퍼시스턴트볼륨클레임을 생성하거나 동적 프로비저닝의 경우 이미 생성한 상태다. 마스터의 컨트롤 루프는 새로운 PVC를 감시하고 일치하는 PV(가능한 경우)를 찾아 서로 바인딩한다. PV가 새 PVC에 대해 동적으로 프로비저닝된 경우 루프는 항상 해당 PV를 PVC에 바인딩한다. 그렇지 않으면 사용자는 항상 최소한 그들이 요청한 것을 얻지만 볼륨은 요청된 것을 초과할 수 있다. 일단 바인딩되면 퍼시스턴트볼륨클레임은 어떻게 바인딩되었는지 상관없이 배타적으로 바인딩된다. PVC 대 PV 바인딩은 일대일 매핑으로, 퍼시스턴트볼륨과 퍼시스턴트볼륨클레임 사이의 양방향 바인딩인 ClaimRef를 사용한다.
일치하는 볼륨이 없는 경우 클레임은 무한정 바인딩되지 않은 상태로 남아 있다. 일치하는 볼륨이 제공되면 클레임이 바인딩된다. 예를 들어 많은 수의 50Gi PV로 프로비저닝된 클러스터는 100Gi를 요청하는 PVC와 일치하지 않는다. 100Gi PV가 클러스터에 추가되면 PVC를 바인딩할 수 있다.
사용 중
파드는 클레임을 볼륨으로 사용한다. 클러스터는 클레임을 검사하여 바인딩된 볼륨을 찾고 해당 볼륨을 파드에 마운트한다. 여러 접근 모드를 지원하는 볼륨의 경우 사용자는 자신의 클레임을 파드에서 볼륨으로 사용할 때 원하는 접근 모드를 지정한다.
일단 사용자에게 클레임이 있고 그 클레임이 바인딩되면, 바인딩된 PV는 사용자가 필요로 하는 한 사용자에게 속한다. 사용자는 파드의 volumes 블록에 persistentVolumeClaim을 포함하여 파드를 스케줄링하고 클레임한 PV에 접근한다. 이에 대한 자세한 내용은 볼륨으로 클레임하기를 참고하길 바란다.
사용 중인 스토리지 오브젝트 보호
사용 중인 스토리지 오브젝트 보호 기능의 목적은 PVC에 바인딩된 파드와 퍼시스턴트볼륨(PV)이 사용 중인 퍼시스턴트볼륨클레임(PVC)을 시스템에서 삭제되지 않도록 하는 것이다. 삭제되면 이로 인해 데이터의 손실이 발생할 수 있기 때문이다.
참고:
PVC를 사용하는 파드 오브젝트가 존재하면 파드가 PVC를 사용하고 있는 상태이다.사용자가 파드에서 활발하게 사용 중인 PVC를 삭제하면 PVC는 즉시 삭제되지 않는다. PVC가 더 이상 파드에서 적극적으로 사용되지 않을 때까지 PVC 삭제가 연기된다. 또한 관리자가 PVC에 바인딩된 PV를 삭제하면 PV는 즉시 삭제되지 않는다. PV가 더 이상 PVC에 바인딩되지 않을 때까지 PV 삭제가 연기된다.
PVC의 상태가 Terminating이고 Finalizers 목록에 kubernetes.io/pvc-protection이 포함되어 있으면 PVC가 보호된 것으로 볼 수 있다.
kubectl describe pvc hostpath
Name: hostpath
Namespace: default
StorageClass: example-hostpath
Status: Terminating
Volume:
Labels: <none>
Annotations: volume.beta.kubernetes.io/storage-class=example-hostpath
volume.beta.kubernetes.io/storage-provisioner=example.com/hostpath
Finalizers: [kubernetes.io/pvc-protection]
...
마찬가지로 PV 상태가 Terminating이고 Finalizers 목록에 kubernetes.io/pv-protection이 포함되어 있으면 PV가 보호된 것으로 볼 수 있다.
kubectl describe pv task-pv-volume
Name: task-pv-volume
Labels: type=local
Annotations: <none>
Finalizers: [kubernetes.io/pv-protection]
StorageClass: standard
Status: Terminating
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: HostPath (bare host directory volume)
Path: /tmp/data
HostPathType:
Events: <none>
반환(Reclaiming)
사용자가 볼륨을 다 사용하고나면 리소스를 반환할 수 있는 API를 사용하여 PVC 오브젝트를 삭제할 수 있다. 퍼시스턴트볼륨의 반환 정책은 볼륨에서 클레임을 해제한 후 볼륨에 수행할 작업을 클러스터에 알려준다. 현재 볼륨에 대한 반환 정책은 Retain, Recycle, 그리고 Delete가 있다.
Retain(보존)
Retain 반환 정책은 리소스를 수동으로 반환할 수 있게 한다. 퍼시스턴트볼륨클레임이 삭제되면 퍼시스턴트볼륨은 여전히 존재하며 볼륨은 "릴리스 된" 것으로 간주된다. 그러나 이전 요청자의 데이터가 여전히 볼륨에 남아 있기 때문에 다른 요청에 대해서는 아직 사용할 수 없다. 관리자는 다음 단계에 따라 볼륨을 수동으로 반환할 수 있다.
- 퍼시스턴트볼륨을 삭제한다. PV가 삭제된 후에도 외부 인프라(예: AWS EBS, GCE PD, Azure Disk 또는 Cinder 볼륨)의 관련 스토리지 자산이 존재한다.
- 관련 스토리지 자산의 데이터를 수동으로 삭제한다.
- 연결된 스토리지 자산을 수동으로 삭제한다.
동일한 스토리지 자산을 재사용하려는 경우, 동일한 스토리지 자산 정의로 새 퍼시스턴트볼륨을 생성한다.
Delete(삭제)
Delete 반환 정책을 지원하는 볼륨 플러그인의 경우, 삭제는 쿠버네티스에서 퍼시스턴트볼륨 오브젝트와 외부 인프라(예: AWS EBS, GCE PD, Azure Disk 또는 Cinder 볼륨)의 관련 스토리지 자산을 모두 삭제한다. 동적으로 프로비저닝된 볼륨은 스토리지클래스의 반환 정책을 상속하며 기본값은 Delete이다. 관리자는 사용자의 기대에 따라 스토리지클래스를 구성해야 한다. 그렇지 않으면 PV를 생성한 후 PV를 수정하거나 패치해야 한다. 퍼시스턴트볼륨의 반환 정책 변경을 참고하길 바란다.
Recycle(재활용)
경고:
Recycle 반환 정책은 더 이상 사용하지 않는다. 대신 권장되는 방식은 동적 프로비저닝을 사용하는 것이다.기본 볼륨 플러그인에서 지원하는 경우 Recycle 반환 정책은 볼륨에서 기본 스크럽(rm -rf /thevolume/*)을 수행하고 새 클레임에 다시 사용할 수 있도록 한다.
그러나 관리자는 레퍼런스에
설명된 대로 쿠버네티스 컨트롤러 관리자 커맨드라인 인자(command line arguments)를
사용하여 사용자 정의 재활용 파드 템플릿을 구성할 수 있다.
사용자 정의 재활용 파드 템플릿에는 아래 예와 같이 volumes 명세가
포함되어야 한다.
apiVersion: v1
kind: Pod
metadata:
name: pv-recycler
namespace: default
spec:
restartPolicy: Never
volumes:
- name: vol
hostPath:
path: /any/path/it/will/be/replaced
containers:
- name: pv-recycler
image: "registry.k8s.io/busybox"
command: ["/bin/sh", "-c", "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1"]
volumeMounts:
- name: vol
mountPath: /scrub
그러나 volumes 부분의 사용자 정의 재활용 파드 템플릿에 지정된 특정 경로는 재활용되는 볼륨의 특정 경로로 바뀐다.
퍼시스턴트볼륨 삭제 보호 파이널라이저(finalizer)
기능 상태:
Kubernetes v1.23 [alpha]
퍼시스턴트볼륨에 파이널라이저를 추가하여, Delete 반환 정책을 갖는 퍼시스턴트볼륨이
기반 스토리지(backing storage)가 삭제된 이후에만 삭제되도록 할 수 있다.
새롭게 도입된 kubernetes.io/pv-controller 및 external-provisioner.volume.kubernetes.io/finalizer 파이널라이저는
동적으로 프로비전된 볼륨에만 추가된다.
kubernetes.io/pv-controller 파이널라이저는 인-트리 플러그인 볼륨에 추가된다. 다음은 이에 대한 예시이다.
kubectl describe pv pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Name: pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Labels: <none>
Annotations: kubernetes.io/createdby: vsphere-volume-dynamic-provisioner
pv.kubernetes.io/bound-by-controller: yes
pv.kubernetes.io/provisioned-by: kubernetes.io/vsphere-volume
Finalizers: [kubernetes.io/pv-protection kubernetes.io/pv-controller]
StorageClass: vcp-sc
Status: Bound
Claim: default/vcp-pvc-1
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 1Gi
Node Affinity: <none>
Message:
Source:
Type: vSphereVolume (a Persistent Disk resource in vSphere)
VolumePath: [vsanDatastore] d49c4a62-166f-ce12-c464-020077ba5d46/kubernetes-dynamic-pvc-74a498d6-3929-47e8-8c02-078c1ece4d78.vmdk
FSType: ext4
StoragePolicyName: vSAN Default Storage Policy
Events: <none>
external-provisioner.volume.kubernetes.io/finalizer 파이널라이저는 CSI 볼륨에 추가된다.
다음은 이에 대한 예시이다.
Name: pvc-2f0bab97-85a8-4552-8044-eb8be45cf48d
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: csi.vsphere.vmware.com
Finalizers: [kubernetes.io/pv-protection external-provisioner.volume.kubernetes.io/finalizer]
StorageClass: fast
Status: Bound
Claim: demo-app/nginx-logs
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 200Mi
Node Affinity: <none>
Message:
Source:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: csi.vsphere.vmware.com
FSType: ext4
VolumeHandle: 44830fa8-79b4-406b-8b58-621ba25353fd
ReadOnly: false
VolumeAttributes: storage.kubernetes.io/csiProvisionerIdentity=1648442357185-8081-csi.vsphere.vmware.com
type=vSphere CNS Block Volume
Events: <none>
특정 인-트리 볼륨 플러그인에 대해 CSIMigration{provider} 기능 플래그가 활성화되어 있을 때,
kubernetes.io/pv-controller 파이널라이저는
external-provisioner.volume.kubernetes.io/finalizer 파이널라이저로 대체된다.
퍼시스턴트볼륨 예약
컨트롤 플레인은 클러스터에서 퍼시스턴트볼륨클레임을 일치하는 퍼시스턴트볼륨에 바인딩할 수 있다. 그러나, PVC를 특정 PV에 바인딩하려면, 미리 바인딩해야 한다.
퍼시스턴트볼륨클레임에서 퍼시스턴트볼륨을 지정하여, 특정 PV와 PVC 간의 바인딩을 선언한다.
퍼시스턴트볼륨이 존재하고 claimRef 필드를 통해 퍼시스턴트볼륨클레임을 예약하지 않은 경우, 퍼시스턴트볼륨 및 퍼시스턴트볼륨클레임이 바인딩된다.
바인딩은 노드 선호도(affinity)를 포함하여 일부 볼륨 일치(matching) 기준과 관계없이 발생한다. 컨트롤 플레인은 여전히 스토리지 클래스, 접근 모드 및 요청된 스토리지 크기가 유효한지 확인한다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: foo
spec:
storageClassName: "" # 빈 문자열은 명시적으로 설정해야 하며 그렇지 않으면 기본 스토리지클래스가 설정됨
volumeName: foo-pv
...
이 메서드는 퍼시스턴트볼륨에 대한 바인딩 권한을 보장하지 않는다. 다른 퍼시스턴트볼륨클레임에서 지정한 PV를 사용할 수 있는 경우, 먼저 해당 스토리지 볼륨을 예약해야 한다. PV의 claimRef 필드에 관련 퍼시스턴트볼륨클레임을 지정하여 다른 PVC가 바인딩할 수 없도록 한다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
spec:
storageClassName: ""
claimRef:
name: foo-pvc
namespace: foo
...
이는 기존 PV를 재사용하는 경우를 포함하여 claimPolicy 가
Retain 으로 설정된 퍼시스턴트볼륨을 사용하려는 경우에 유용하다.
퍼시스턴트 볼륨 클레임 확장
기능 상태:
Kubernetes v1.24 [stable]
퍼시스턴트볼륨클레임(PVC) 확장 지원은 기본적으로 활성화되어 있다. 다음 유형의 볼륨을 확장할 수 있다.
- azureDisk
- azureFile
- awsElasticBlockStore
- cinder (deprecated)
- csi
- flexVolume (deprecated)
- gcePersistentDisk
- rbd
- portworxVolume
스토리지 클래스의 allowVolumeExpansion 필드가 true로 설정된 경우에만 PVC를 확장할 수 있다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-vol-default
provisioner: vendor-name.example/magicstorage
parameters:
resturl: "http://192.168.10.100:8080"
restuser: ""
secretNamespace: ""
secretName: ""
allowVolumeExpansion: true
PVC에 대해 더 큰 볼륨을 요청하려면 PVC 오브젝트를 수정하여 더 큰 용량을 지정한다. 이는 기본 퍼시스턴트볼륨을 지원하는 볼륨의 확장을 트리거한다. 클레임을 만족시키기 위해 새로운 퍼시스턴트볼륨이 생성되지 않고 기존 볼륨의 크기가 조정된다.
경고:
퍼시스턴트볼륨의 크기를 직접 변경하면 자동 볼륨 리사이즈 기능을 이용할 수 없게 된다. 퍼시스턴트볼륨의 크기를 변경하고, 퍼시스턴트볼륨에 해당되는 퍼시스턴트볼륨클레임의.spec에 적혀 있는 크기를 동일하게 변경하면,
스토리지 리사이즈가 발생하지 않는다.
쿠버네티스 컨트롤 플레인은
두 리소스의 목표 상태(desired state)가 일치하는 것을 확인하고,
배후(backing) 볼륨 크기가 수동으로 증가되어 리사이즈가 필요하지 않다고 판단할 것이다.CSI 볼륨 확장
기능 상태:
Kubernetes v1.24 [stable]
CSI 볼륨 확장 지원은 기본적으로 활성화되어 있지만 볼륨 확장을 지원하려면 특정 CSI 드라이버도 필요하다. 자세한 내용은 특정 CSI 드라이버 문서를 참고한다.
파일시스템을 포함하는 볼륨 크기 조정
파일시스템이 XFS, Ext3 또는 Ext4 인 경우에만 파일시스템을 포함하는 볼륨의 크기를 조정할 수 있다.
볼륨에 파일시스템이 포함된 경우 새 파드가 ReadWrite 모드에서 퍼시스턴트볼륨클레임을 사용하는
경우에만 파일시스템의 크기가 조정된다. 파일시스템 확장은 파드가 시작되거나
파드가 실행 중이고 기본 파일시스템이 온라인 확장을 지원할 때 수행된다.
FlexVolumes(쿠버네티스 v1.23부터 사용 중단됨)는 드라이버의 RequiresFSResize 기능이 true로 설정된 경우 크기 조정을 허용한다.
FlexVolume은 파드 재시작 시 크기를 조정할 수 있다.
사용 중인 퍼시스턴트볼륨클레임 크기 조정
기능 상태:
Kubernetes v1.24 [stable]
이 경우 기존 PVC를 사용하는 파드 또는 디플로이먼트를 삭제하고 다시 만들 필요가 없다. 파일시스템이 확장되자마자 사용 중인 PVC가 파드에서 자동으로 사용 가능하다. 이 기능은 파드나 디플로이먼트에서 사용하지 않는 PVC에는 영향을 미치지 않는다. 확장을 완료하기 전에 PVC를 사용하는 파드를 만들어야 한다.
다른 볼륨 유형과 비슷하게 FlexVolume 볼륨도 파드에서 사용 중인 경우 확장할 수 있다.
참고:
FlexVolume의 크기 조정은 기본 드라이버가 크기 조정을 지원하는 경우에만 가능하다.참고:
EBS 볼륨 확장은 시간이 많이 걸리는 작업이다. 또한 6시간마다 한 번의 수정을 할 수 있는 볼륨별 쿼터가 있다.볼륨 확장 시 오류 복구
사용자가 기반 스토리지 시스템이 제공할 수 있는 것보다 더 큰 사이즈를 지정하면, 사용자 또는 클러스터 관리자가 조치를 취하기 전까지 PVC 확장을 계속 시도한다. 이는 바람직하지 않으며 따라서 쿠버네티스는 이러한 오류 상황에서 벗어나기 위해 다음과 같은 방법을 제공한다.
기본 스토리지 확장에 실패하면, 클러스터 관리자가 수동으로 퍼시스턴트 볼륨 클레임(PVC) 상태를 복구하고 크기 조정 요청을 취소할 수 있다. 그렇지 않으면, 컨트롤러가 관리자 개입 없이 크기 조정 요청을 계속해서 재시도한다.
- 퍼시스턴트볼륨클레임(PVC)에 바인딩된 퍼시스턴트볼륨(PV)을
Retain반환 정책으로 표시한다. - PVC를 삭제한다. PV에는
Retain반환 정책이 있으므로 PVC를 재생성할 때 데이터가 손실되지 않는다. - 새 PVC를 바인딩할 수 있도록 PV 명세에서
claimRef항목을 삭제한다. 그러면 PV가Available상태가 된다. - PV 보다 작은 크기로 PVC를 다시 만들고 PVC의
volumeName필드를 PV 이름으로 설정한다. 이것은 새 PVC를 기존 PV에 바인딩해야 한다. - PV의 반환 정책을 복원하는 것을 잊지 않는다.
기능 상태:
Kubernetes v1.23 [alpha]
참고:
PVC 확장 실패의 사용자에 의한 복구는 쿠버네티스 1.23부터 제공되는 알파 기능이다. 이 기능이 작동하려면RecoverVolumeExpansionFailure 기능이 활성화되어 있어야 한다. 더 많은 정보는 기능 게이트 문서를 참조한다.클러스터에 RecoverVolumeExpansionFailure
기능 게이트가 활성화되어 있는 상태에서 PVC 확장이 실패하면
이전에 요청했던 값보다 작은 크기로의 확장을 재시도할 수 있다.
더 작은 크기를 지정하여 확장 시도를 요청하려면,
이전에 요청했던 값보다 작은 크기로 PVC의 .spec.resources 값을 수정한다.
이는 총 용량 제한(capacity constraint)으로 인해 큰 값으로의 확장이 실패한 경우에 유용하다.
만약 확장이 실패했다면, 또는 실패한 것 같다면, 기반 스토리지 공급자의 용량 제한보다 작은 값으로 확장을 재시도할 수 있다.
.status.resizeStatus와 PVC의 이벤트를 감시하여 리사이즈 작업의 상태를 모니터할 수 있다.
참고:
이전에 요청했던 값보다 작은 크기를 요청했더라도,
새로운 값이 여전히 .status.capacity보다 클 수 있다.
쿠버네티스는 PVC를 현재 크기보다 더 작게 축소하는 것은 지원하지 않는다.
퍼시스턴트 볼륨의 유형
퍼시스턴트볼륨 유형은 플러그인으로 구현된다. 쿠버네티스는 현재 다음의 플러그인을 지원한다.
cephfs- CephFS 볼륨csi- 컨테이너 스토리지 인터페이스 (CSI)fc- Fibre Channel (FC) 스토리지hostPath- HostPath 볼륨 (단일 노드 테스트 전용. 다중-노드 클러스터에서 작동하지 않음. 대신로컬볼륨 사용 고려)iscsi- iSCSI (SCSI over IP) 스토리지local- 노드에 마운트된 로컬 스토리지 디바이스nfs- 네트워크 파일 시스템 (NFS) 스토리지rbd- Rados Block Device (RBD) 볼륨
아래의 PersistentVolume 타입은 사용 중단되었다. 이 말인 즉슨, 지원은 여전히 제공되지만 추후 쿠버네티스 릴리스에서는 삭제될 예정이라는 것이다.
awsElasticBlockStore- AWS Elastic Block Store (EBS) (v1.17에서 사용 중단)azureDisk- Azure Disk (v1.19에서 사용 중단)azureFile- Azure File (v1.21에서 사용 중단)cinder- Cinder (오픈스택 블록 스토리지) (v1.18에서 사용 중단)flexVolume- FlexVolume (v1.23에서 사용 중단)gcePersistentDisk- GCE Persistent Disk (v1.17에서 사용 중단)portworxVolume- Portworx 볼륨 (v1.25에서 사용 중단)vsphereVolume- vSphere VMDK 볼륨 (v1.19에서 사용 중단)
이전 쿠버네티스 버전은 아래의 인-트리 PersistentVolume 타입도 지원했었다.
photonPersistentDisk- Photon 컨트롤러 퍼시스턴트 디스크. (v1.15부터 사용 불가)scaleIO- ScaleIO 볼륨 (v1.21부터 사용 불가)flocker- Flocker 스토리지 (v1.25부터 사용 불가)quobyte- Quobyte 볼륨 (v1.25부터 사용 불가)storageos- StorageOS 볼륨 (v1.25부터 사용 불가)
퍼시스턴트 볼륨
각 PV에는 스펙과 상태(볼륨의 명세와 상태)가 포함된다. 퍼시스턴트볼륨 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
참고:
클러스터 내에서 퍼시스턴트볼륨을 사용하려면 볼륨 유형과 관련된 헬퍼(Helper) 프로그램이 필요할 수 있다. 이 예에서 퍼시스턴트볼륨은 NFS 유형이며 NFS 파일시스템 마운트를 지원하려면 헬퍼 프로그램인 /sbin/mount.nfs가 필요하다.용량
일반적으로 PV는 특정 저장 용량을 가진다. 이것은 PV의 capacity 속성을 사용하여 설정된다. capacity가 사용하는 단위를 이해하려면 용어집에 있는 수량 항목을 참고한다.
현재 스토리지 용량 크기는 설정하거나 요청할 수 있는 유일한 리소스이다. 향후 속성에 IOPS, 처리량 등이 포함될 수 있다.
볼륨 모드
기능 상태:
Kubernetes v1.18 [stable]
쿠버네티스는 퍼시스턴트볼륨의 두 가지 volumeModes인 Filesystem과 Block을 지원한다.
volumeMode는 선택적 API 파라미터이다.
Filesystem은 volumeMode 파라미터가 생략될 때 사용되는 기본 모드이다.
volumeMode: Filesystem이 있는 볼륨은 파드의 디렉터리에 마운트 된다. 볼륨이 장치에
의해 지원되고 그 장치가 비어 있으면 쿠버네티스는 장치를
처음 마운트하기 전에 장치에 파일시스템을 만든다.
볼륨을 원시 블록 장치로 사용하려면 volumeMode의 값을 Block으로 설정할 수 있다.
이러한 볼륨은 파일시스템이 없는 블록 장치로 파드에 제공된다.
이 모드는 파드와 볼륨 사이에 파일시스템 계층 없이도 볼륨에 액세스하는
가장 빠른 방법을 파드에 제공하는 데 유용하다. 반면에 파드에서 실행되는 애플리케이션은
원시 블록 장치를 처리하는 방법을 알아야 한다.
파드에서 volumeMode: Block으로 볼륨을 사용하는 방법에 대한 예는
원시 블록 볼륨 지원를 참조하십시오.
접근 모드
리소스 제공자가 지원하는 방식으로 호스트에 퍼시스턴트볼륨을 마운트할 수 있다. 아래 표에서 볼 수 있듯이 제공자들은 서로 다른 기능을 가지며 각 PV의 접근 모드는 해당 볼륨에서 지원하는 특정 모드로 설정된다. 예를 들어 NFS는 다중 읽기/쓰기 클라이언트를 지원할 수 있지만 특정 NFS PV는 서버에서 읽기 전용으로 export할 수 있다. 각 PV는 특정 PV의 기능을 설명하는 자체 접근 모드 셋을 갖는다.
접근 모드는 다음과 같다.
ReadWriteOnce- 하나의 노드에서 해당 볼륨이 읽기-쓰기로 마운트 될 수 있다. ReadWriteOnce 접근 모드에서도 파드가 동일 노드에서 구동되는 경우에는 복수의 파드에서 볼륨에 접근할 수 있다.
ReadOnlyMany- 볼륨이 다수의 노드에서 읽기 전용으로 마운트 될 수 있다.
ReadWriteMany- 볼륨이 다수의 노드에서 읽기-쓰기로 마운트 될 수 있다.
ReadWriteOncePod- 볼륨이 단일 파드에서 읽기-쓰기로 마운트될 수 있다. 전체 클러스터에서 단 하나의 파드만 해당 PVC를 읽거나 쓸 수 있어야하는 경우 ReadWriteOncePod 접근 모드를 사용한다. 이 기능은 CSI 볼륨과 쿠버네티스 버전 1.22+ 에서만 지원된다.
퍼시스턴트 볼륨에 대한 단일 파드 접근 모드 소개 블로그 기사에서 이에 대해 보다 자세한 내용을 다룬다.
CLI에서 접근 모드는 다음과 같이 약어로 표시된다.
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- RWX - ReadWriteMany
- RWOP - ReadWriteOncePod
참고:
쿠버네티스는 볼륨 접근 모드를 이용해 퍼시스턴트볼륨클레임과 퍼시스턴트볼륨을 연결한다. 경우에 따라 볼륨 접근 모드는 퍼시스턴트볼륨을 탑재할 수 있는 위치도 제한한다. 볼륨 접근 모드는 스토리지를 마운트 한 후에는 쓰기 보호를 적용하지 않는다. 접근 모드가 ReadWriteOnce, ReadOnlyMany 혹은 ReadWriteMany로 지정된 경우에도 접근 모드는 볼륨에 제약 조건을 설정하지 않는다. 예를 들어 퍼시스턴트볼륨이 ReadOnlyMany로 생성되었다 하더라도, 해당 퍼시스턴트 볼륨이 읽기 전용이라는 것을 보장하지 않는다. 만약 접근 모드가 ReadWriteOncePod로 지정된 경우, 볼륨에 제한이 설정되어 단일 파드에만 마운트 할 수 있게 된다.중요! 볼륨이 여러 접근 모드를 지원하더라도 한 번에 하나의 접근 모드를 사용하여 마운트할 수 있다. 예를 들어 GCEPersistentDisk는 하나의 노드가 ReadWriteOnce로 마운트하거나 여러 노드가 ReadOnlyMany로 마운트할 수 있지만 동시에는 불가능하다.
| Volume Plugin | ReadWriteOnce | ReadOnlyMany | ReadWriteMany | ReadWriteOncePod |
|---|---|---|---|---|
| AWSElasticBlockStore | ✓ | - | - | - |
| AzureFile | ✓ | ✓ | ✓ | - |
| AzureDisk | ✓ | - | - | - |
| CephFS | ✓ | ✓ | ✓ | - |
| Cinder | ✓ | - | (다중 부착(multi-attached)이 가능한 볼륨이라면) | - |
| CSI | 드라이버에 의존 | 드라이버에 의존 | 드라이버에 의존 | 드라이버에 의존 |
| FC | ✓ | ✓ | - | - |
| FlexVolume | ✓ | ✓ | 드라이버에 의존 | - |
| GCEPersistentDisk | ✓ | ✓ | - | - |
| Glusterfs | ✓ | ✓ | ✓ | - |
| HostPath | ✓ | - | - | - |
| iSCSI | ✓ | ✓ | - | - |
| NFS | ✓ | ✓ | ✓ | - |
| RBD | ✓ | ✓ | - | - |
| VsphereVolume | ✓ | - | - (파드를 배치할(collocated) 때 동작한다) | - |
| PortworxVolume | ✓ | - | ✓ | - |
클래스
PV는 storageClassName 속성을
스토리지클래스의
이름으로 설정하여 지정하는 클래스를 가질 수 있다.
특정 클래스의 PV는 해당 클래스를 요청하는 PVC에만 바인딩될 수 있다.
storageClassName이 없는 PV에는 클래스가 없으며 특정 클래스를 요청하지 않는 PVC에만
바인딩할 수 있다.
이전에는 volume.beta.kubernetes.io/storage-class 어노테이션이
storageClassName 속성 대신 사용되었다. 이 어노테이션은 아직까지는 사용할 수 있지만,
향후 쿠버네티스 릴리스에서 완전히 사용 중단(deprecated)이 될 예정이다.
반환 정책
현재 반환 정책은 다음과 같다.
- Retain(보존) -- 수동 반환
- Recycle(재활용) -- 기본 스크럽 (
rm -rf /thevolume/*) - Delete(삭제) -- AWS EBS, GCE PD, Azure Disk 또는 OpenStack Cinder 볼륨과 같은 관련 스토리지 자산이 삭제됨
현재 NFS 및 HostPath만 재활용을 지원한다. AWS EBS, GCE PD, Azure Disk 및 Cinder 볼륨은 삭제를 지원한다.
마운트 옵션
쿠버네티스 관리자는 퍼시스턴트 볼륨이 노드에 마운트될 때 추가 마운트 옵션을 지정할 수 있다.
참고:
모든 퍼시스턴트 볼륨 유형이 마운트 옵션을 지원하는 것은 아니다.다음 볼륨 유형은 마운트 옵션을 지원한다.
awsElasticBlockStoreazureDiskazureFilecephfscinder(v1.18에서 사용 중단됨)gcePersistentDiskiscsinfsrbdvsphereVolume
마운트 옵션의 유효성이 검사되지 않는다. 마운트 옵션이 유효하지 않으면, 마운트가 실패한다.
이전에는 mountOptions 속성 대신 volume.beta.kubernetes.io/mount-options 어노테이션이
사용되었다. 이 어노테이션은 아직까지는 사용할 수 있지만,
향후 쿠버네티스 릴리스에서 완전히 사용 중단(deprecated)이 될 예정이다.
노드 어피니티(affinity)
참고:
대부분의 볼륨 유형의 경우 이 필드를 설정할 필요가 없다. AWS EBS, GCE PD 및 Azure Disk 볼륨 블록 유형에 자동으로 채워진다. 로컬 볼륨에 대해서는 이를 명시적으로 설정해야 한다.PV는 노드 어피니티를 지정하여 이 볼륨에 접근할 수 있는 노드를 제한하는 제약 조건을 정의할 수 있다. PV를 사용하는 파드는 노드 어피니티에 의해 선택된 노드로만 스케줄링된다. 노드 어피니티를 명기하기 위해서는, PV의 .spec에 nodeAffinity를 설정한다. 퍼시스턴트볼륨 API 레퍼런스에 해당 필드에 대해 보다 자세한 내용이 있다.
단계(Phase)
볼륨은 다음 단계 중 하나이다.
- Available(사용 가능) -– 아직 클레임에 바인딩되지 않은 사용할 수 있는 리소스
- Bound(바인딩) –- 볼륨이 클레임에 바인딩됨
- Released(릴리스) –- 클레임이 삭제되었지만 클러스터에서 아직 리소스를 반환하지 않음
- Failed(실패) –- 볼륨이 자동 반환에 실패함
CLI는 PV에 바인딩된 PVC의 이름을 표시한다.
퍼시스턴트볼륨클레임
각 PVC에는 스펙과 상태(클레임의 명세와 상태)가 포함된다. 퍼시스턴트볼륨클레임 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
접근 모드
클레임은 특정 접근 모드로 저장소를 요청할 때 볼륨과 동일한 규칙을 사용한다.
볼륨 모드
클레임은 볼륨과 동일한 규칙을 사용하여 파일시스템 또는 블록 장치로 볼륨을 사용함을 나타낸다.
리소스
파드처럼 클레임은 특정 수량의 리소스를 요청할 수 있다. 이 경우는 스토리지에 대한 요청이다. 동일한 리소스 모델이 볼륨과 클레임 모두에 적용된다.
셀렉터
클레임은 볼륨 셋을 추가로 필터링하기 위해 레이블 셀렉터를 지정할 수 있다. 레이블이 셀렉터와 일치하는 볼륨만 클레임에 바인딩할 수 있다. 셀렉터는 두 개의 필드로 구성될 수 있다.
matchLabels- 볼륨에 이 값의 레이블이 있어야함matchExpressions- 키, 값의 목록, 그리고 키와 값에 관련된 연산자를 지정하여 만든 요구 사항 목록. 유효한 연산자에는 In, NotIn, Exists 및 DoesNotExist가 있다.
matchLabels 및 matchExpressions의 모든 요구 사항이 AND 조건이다. 일치하려면 모두 충족해야 한다.
클래스
클레임은 storageClassName 속성을 사용하여
스토리지클래스의 이름을 지정하여
특정 클래스를 요청할 수 있다.
요청된 클래스의 PV(PVC와 동일한 storageClassName을 갖는 PV)만 PVC에
바인딩될 수 있다.
PVC는 반드시 클래스를 요청할 필요는 없다. storageClassName이 ""로 설정된
PVC는 항상 클래스가 없는 PV를 요청하는 것으로 해석되므로
클래스가 없는 PV(어노테이션이 없거나 ""와 같은 하나의 셋)에만 바인딩될 수
있다. storageClassName이 없는 PVC는
DefaultStorageClass 어드미션 플러그인이
켜져 있는지 여부에 따라 동일하지 않으며
클러스터에 따라 다르게 처리된다.
- 어드미션 플러그인이 켜져 있으면 관리자가 기본 스토리지클래스를 지정할 수 있다.
storageClassName이 없는 모든 PVC는 해당 기본값의 PV에만 바인딩할 수 있다. 기본 스토리지클래스 지정은 스토리지클래스 오브젝트에서 어노테이션storageclass.kubernetes.io/is-default-class를true로 설정하여 수행된다. 관리자가 기본값을 지정하지 않으면 어드미션 플러그인이 꺼져 있는 것처럼 클러스터가 PVC 생성에 응답한다. 둘 이상의 기본값이 지정된 경우 어드미션 플러그인은 모든 PVC 생성을 금지한다. - 어드미션 플러그인이 꺼져 있으면 기본 스토리지클래스에 대한 기본값 자체가 없다.
storageClassName이""으로 설정된 모든 PVC는storageClassName이 마찬가지로""로 설정된 PV에만 바인딩할 수 있다. 하지만,storageClassName이 없는 PVC는 기본 스토리지클래스가 사용 가능해지면 갱신될 수 있다. PVC가 갱신되면 해당 PVC는 더 이상storageClassName이""로 설정된 PV와 바인딩되어있지 않게 된다.
더 자세한 정보는 retroactive default StorageClass assignment를 참조한다.
설치 방법에 따라 설치 중에 애드온 관리자가 기본 스토리지클래스를 쿠버네티스 클러스터에 배포할 수 있다.
PVC가 스토리지클래스를 요청하는 것 외에도 selector를 지정하면 요구 사항들이
AND 조건으로 동작한다. 요청된 클래스와 요청된 레이블이 있는 PV만 PVC에
바인딩될 수 있다.
참고:
현재 비어 있지 않은selector가 있는 PVC에는 PV를 동적으로 프로비저닝할 수 없다.이전에는 volume.beta.kubernetes.io/storage-class 어노테이션이 storageClassName
속성 대신 사용되었다. 이 어노테이션은 아직까지는 사용할 수 있지만,
향후 쿠버네티스 릴리스에서는 지원되지 않는다.
기본 스토리지클래스 할당 소급 적용하기
기능 상태:
Kubernetes v1.26 [beta]
새로운 PVC를 위한 storageClassName을 설정하지 않고 퍼시스턴트볼륨클레임을 생성할 수 있으며, 이는 클러스터에 기본 스토리지클래스가 존재하지 않을 때에도 가능하다. 이 경우, 새로운 PVC는 정의된 대로 생성되며, 해당 PVC의 storageClassName은 기본값이 사용 가능해질 때까지 미설정 상태로 남는다.
기본 스토리지클래스가 사용 가능해지면, 컨트롤플레인은 storageClassName가 없는 PVC를 찾는다. storageClassName의 값이 비어있거나 해당 키 자체가 없는 PVC라면, 컨트롤플레인은 해당 PVC의 storageClassName가 새로운 기본 스토리지클래스와 일치하도록 설정하여 갱신한다. storageClassName가 ""인 PVC가 있고, 기본 스토리지클래스를 설정한다면, 해당 PVC는 갱신되지 않는다.
기본 스토리지클래스가 존재할 때 storageClassName가 ""로 설정된 PV와의 바인딩을 유지하고싶다면, 연결된 PVC의 storageClassName를 ""로 설정해야 한다.
이 행동은 관리자가 오래된 기본 스토리지클래스를 삭제하고 새로운 기본 스토리지클래스를 생성하거나 설정하여 기본 스토리지클래스를 변경하는 데 도움이 된다. 기본값이 설정되어있지 않을 때의 이 작은 틈새로 인해 이 때 생성된 storageClassName가 없는 PVC는 아무런 기본값도 없이 생성될 수 있지만, 기본 스토리지클래스 할당 소급 적용에 의해 이러한 방식으로 기본값을 변경하는 것은 안전하다.
볼륨으로 클레임하기
클레임을 볼륨으로 사용해서 파드가 스토리지에 접근한다. 클레임은 클레임을 사용하는 파드와 동일한 네임스페이스에 있어야 한다. 클러스터는 파드의 네임스페이스에서 클레임을 찾고 이를 사용하여 클레임과 관련된 퍼시스턴트볼륨을 얻는다. 그런 다음 볼륨이 호스트와 파드에 마운트된다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
네임스페이스에 대한 참고 사항
퍼시스턴트볼륨 바인딩은 배타적이며, 퍼시스턴트볼륨클레임은 네임스페이스 오브젝트이므로 "다중" 모드(ROX, RWX)를 사용한 클레임은 하나의 네임스페이스 내에서만 가능하다.
hostPath 유형의 퍼시스턴트볼륨
hostPath 퍼시스턴트볼륨은 노드의 파일이나 디렉터리를 사용하여 네트워크 연결 스토리지를 에뮬레이션한다.
hostPath 유형 볼륨의 예를 참고한다.
원시 블록 볼륨 지원
기능 상태:
Kubernetes v1.18 [stable]
다음 볼륨 플러그인에 해당되는 경우 동적 프로비저닝을 포함하여 원시 블록 볼륨을 지원한다.
- AWSElasticBlockStore
- AzureDisk
- CSI
- FC (파이버 채널)
- GCEPersistentDisk
- iSCSI
- Local volume
- OpenStack Cinder
- RBD (Ceph Block Device)
- VsphereVolume
원시 블록 볼륨을 사용하는 퍼시스턴트볼륨
apiVersion: v1
kind: PersistentVolume
metadata:
name: block-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
volumeMode: Block
persistentVolumeReclaimPolicy: Retain
fc:
targetWWNs: ["50060e801049cfd1"]
lun: 0
readOnly: false
원시 블록 볼륨을 요청하는 퍼시스턴트볼륨클레임
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 10Gi
컨테이너에 원시 블록 장치 경로를 추가하는 파드 명세
apiVersion: v1
kind: Pod
metadata:
name: pod-with-block-volume
spec:
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: [ "tail -f /dev/null" ]
volumeDevices:
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: block-pvc
참고:
파드에 대한 원시 블록 장치를 추가할 때 마운트 경로 대신 컨테이너에 장치 경로를 지정한다.블록 볼륨 바인딩
사용자가 퍼시스턴트볼륨클레임 스펙에서 volumeMode 필드를 사용하여 이를 나타내는 원시 블록 볼륨을 요청하는 경우 바인딩 규칙은 스펙의 일부분으로 이 모드를 고려하지 않은 이전 릴리스에 비해 약간 다르다.
사용자와 관리자가 원시 블록 장치를 요청하기 위해 지정할 수 있는 가능한 조합의 표가 아래 나열되어 있다. 이 테이블은 볼륨이 바인딩되는지 여부를 나타낸다.
정적 프로비저닝된 볼륨에 대한 볼륨 바인딩 매트릭스이다.
| PV volumeMode | PVC volumeMode | Result |
|---|---|---|
| 지정되지 않음 | 지정되지 않음 | BIND |
| 지정되지 않음 | Block | NO BIND |
| 지정되지 않음 | Filesystem | BIND |
| Block | 지정되지 않음 | NO BIND |
| Block | Block | BIND |
| Block | Filesystem | NO BIND |
| Filesystem | Filesystem | BIND |
| Filesystem | Block | NO BIND |
| Filesystem | 지정되지 않음 | BIND |
참고:
알파 릴리스에서는 정적으로 프로비저닝된 볼륨만 지원된다. 관리자는 원시 블록 장치로 작업할 때 이러한 값을 고려해야 한다.볼륨 스냅샷 및 스냅샷 지원에서 볼륨 복원
기능 상태:
Kubernetes v1.20 [stable]
볼륨 스냅 샷은 아웃-오브-트리 CSI 볼륨 플러그인만 지원한다. 자세한 내용은 볼륨 스냅샷을 참조한다. 인-트리 볼륨 플러그인은 사용 중단 되었다. 볼륨 플러그인 FAQ에서 사용 중단된 볼륨 플러그인에 대해 확인할 수 있다.
볼륨 스냅샷에서 퍼시스턴트볼륨클레임 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: restore-pvc
spec:
storageClassName: csi-hostpath-sc
dataSource:
name: new-snapshot-test
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
볼륨 복제
볼륨 복제는 CSI 볼륨 플러그인만 사용할 수 있다.
기존 pvc에서 퍼시스턴트볼륨클레임 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cloned-pvc
spec:
storageClassName: my-csi-plugin
dataSource:
name: existing-src-pvc-name
kind: PersistentVolumeClaim
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
볼륨 파퓰레이터(Volume populator)와 데이터 소스
기능 상태:
Kubernetes v1.24 [beta]
쿠버네티스는 커스텀 볼륨 파퓰레이터를 지원한다.
커스텀 볼륨 파퓰레이터를 사용하려면,
kube-apiserver와 kube-controller-manager에 대해 AnyVolumeDataSource
기능 게이트를 활성화해야 한다.
볼륨 파퓰레이터는 dataSourceRef라는 PVC 스펙 필드를 활용한다.
다른 PersistentVolumeClaim 또는 VolumeSnapshot을 가리키는 참조만 명시할 수 있는
dataSource 필드와는 다르게, dataSourceRef 필드는 동일 네임스페이스에 있는
어떠한 오브젝트에 대한 참조도 명시할 수 있다(단, PVC 외의 다른 코어 오브젝트는 제외).
기능 게이트가 활성화된 클러스터에서는 dataSource보다 dataSourceRef를 사용하는 것을 권장한다.
네임스페이스를 교차하는 데이터 소스
기능 상태:
Kubernetes v1.26 [alpha]
쿠버네티스는 네임스페이스를 교차하는 볼륨 데이터 소스를 지원한다.
네임스페이스를 교차하는 볼륨 데이터 소스를 사용하기 위해서는, kube-apiserver, kube-controller-manager에 대해서 AnyVolumeDataSource와 CrossNamespaceVolumeDataSource
기능 게이트를
활성화해야 한다.
또한, csi-provisioner에 대한 CrossNamespaceVolumeDataSource 기능 게이트도 활성화해야 한다.
CrossNamespaceVolumeDataSource 기능 게이트를 활성화하면 dataSourceRef 필드에 네임스페이스를 명시할 수 있다.
참고:
볼륨 데이터 소스의 네임스페이스를 명시하면, 쿠버네티스는 참조를 받아들이기 전에 다른 네임스페이스의 레퍼런스그랜트를 확인한다. 레퍼런스그랜트는gateway.networking.k8s.io 확장 API에 속한다.
자세한 정보는 게이트웨이 API 문서의 레퍼런스그랜트를 참고하라.
즉 이 방법을 사용하려면 우선 게이트웨이 API에서 최소한 레퍼런스그랜트 이상을 사용하여
쿠버네티스 클러스터를 확장해야 한다는 것을 의미한다.데이터 소스 참조
dataSourceRef 필드는 dataSource 필드와 거의 동일하게 동작한다.
둘 중 하나만 명시되어 있으면, API 서버는 두 필드에 같은 값을 할당할 것이다.
두 필드 모두 생성 이후에는 변경될 수 없으며,
두 필드에 다른 값을 넣으려고 시도하면 검증 에러가 발생할 것이다.
따라서 두 필드는 항상 같은 값을 갖게 된다.
dataSourceRef 필드와 dataSource 필드 사이에는
사용자가 알고 있어야 할 두 가지 차이점이 있다.
dataSource필드는 유효하지 않은 값(예를 들면, 빈 값)을 무시하지만,dataSourceRef필드는 어떠한 값도 무시하지 않으며 유효하지 않은 값이 들어오면 에러를 발생할 것이다. 유효하지 않은 값은 PVC를 제외한 모든 코어 오브젝트(apiGroup이 없는 오브젝트)이다.dataSourceRef필드는 여러 타입의 오브젝트를 포함할 수 있지만,dataSource필드는 PVC와 VolumeSnapshot만 포함할 수 있다.
CrossNamespaceVolumeDataSource 기능이 활성화되어 있을 때, 추가적인 차이점이 존재한다:
dataSource필드는 로컬 오브젝트만을 허용하지만,dataSourceRef필드는 모든 네임스페이스의 오브젝트를 허용한다.- 네임스페이스가 명시되어 있을 때,
dataSource와dataSourceRef는 동기화되지 않는다.
기능 게이트가 활성화된 클러스터에서는 dataSourceRef를 사용해야 하고, 그렇지 않은
클러스터에서는 dataSource를 사용해야 한다. 어떤 경우에서든 두 필드 모두를 확인해야
할 필요는 없다. 이렇게 약간의 차이만 있는 중복된 값은 이전 버전 호환성을 위해서만
존재하는 것이다. 상세히 설명하면, 이전 버전과 새로운 버전의 컨트롤러가 함께 동작할
수 있는데, 이는 두 필드가 동일하기 때문이다.
볼륨 파퓰레이터 사용하기
볼륨 파퓰레이터는 비어 있지 않은 볼륨(non-empty volume)을 생성할 수 있는 컨트롤러이며,
이 볼륨의 내용물은 커스텀 리소스(Custom Resource)에 의해 결정된다.
파퓰레이티드 볼륨(populated volume)을 생성하려면 dataSourceRef 필드에 커스텀 리소스를 기재한다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: populated-pvc
spec:
dataSourceRef:
name: example-name
kind: ExampleDataSource
apiGroup: example.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
볼륨 파퓰레이터는 외부 컴포넌트이기 때문에, 만약 적합한 컴포넌트가 설치되어 있지 않다면 볼륨 파퓰레이터를 사용하는 PVC에 대한 생성 요청이 실패할 수 있다. 외부 컨트롤러는 '컴포넌트가 없어서 PVC를 생성할 수 없음' 경고와 같은 PVC 생성 상태에 대한 피드백을 제공하기 위해, PVC에 대한 이벤트를 생성해야 한다.
알파 버전의 볼륨 데이터 소스 검증기를 클러스터에 설치할 수 있다. 해당 데이터 소스를 다루는 파퓰레이터가 등록되어 있지 않다면 이 컨트롤러가 PVC에 경고 이벤트를 생성한다. PVC를 위한 적절한 파퓰레이터가 설치되어 있다면, 볼륨 생성과 그 과정에서 발생하는 이슈에 대한 이벤트를 생성하는 것은 파퓰레이터 컨트롤러의 몫이다.
네임스페이스를 교차하는 볼륨 데이터 소스 사용하기
기능 상태:
Kubernetes v1.26 [alpha]
네임스페이스 소유자가 참조를 받아들일 수 있도록 레퍼런스그랜트를 생성한다.
dataSourceRef 필드를 사용하여 네임스페이스를 교차하는 볼륨 데이터 소스를 명시해서 파퓰레이트된 볼륨을 정의한다. 이 때, 원천 네임스페이스에 유효한 레퍼런스그랜트를 보유하고 있어야 한다:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-ns1-pvc
namespace: default
spec:
from:
- group: ""
kind: PersistentVolumeClaim
namespace: ns1
to:
- group: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: ns1
spec:
storageClassName: example
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
dataSourceRef:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
namespace: default
volumeMode: Filesystem
포터블 구성 작성
광범위한 클러스터에서 실행되고 퍼시스턴트 스토리지가 필요한 구성 템플릿 또는 예제를 작성하는 경우 다음 패턴을 사용하는 것이 좋다.
- 구성 번들(디플로이먼트, 컨피그맵 등)에 퍼시스턴트볼륨클레임 오브젝트를 포함시킨다.
- 구성을 인스턴스화 하는 사용자에게 퍼시스턴트볼륨을 생성할 권한이 없을 수 있으므로 퍼시스턴트볼륨 오브젝트를 구성에 포함하지 않는다.
- 템플릿을 인스턴스화 할 때 스토리지 클래스 이름을 제공하는 옵션을
사용자에게 제공한다.
- 사용자가 스토리지 클래스 이름을 제공하는 경우 해당 값을
permanentVolumeClaim.storageClassName필드에 입력한다. 클러스터에서 관리자가 스토리지클래스를 활성화한 경우 PVC가 올바른 스토리지 클래스와 일치하게 된다. - 사용자가 스토리지 클래스 이름을 제공하지 않으면
permanentVolumeClaim.storageClassName필드를 nil로 남겨둔다. 그러면 클러스터에 기본 스토리지클래스가 있는 사용자에 대해 PV가 자동으로 프로비저닝된다. 많은 클러스터 환경에 기본 스토리지클래스가 설치되어 있거나 관리자가 고유한 기본 스토리지클래스를 생성할 수 있다.
- 사용자가 스토리지 클래스 이름을 제공하는 경우 해당 값을
- 도구(tooling)에서 일정 시간이 지나도 바인딩되지 않는 PVC를 관찰하여 사용자에게 노출시킨다. 이는 클러스터가 동적 스토리지를 지원하지 않거나(이 경우 사용자가 일치하는 PV를 생성해야 함), 클러스터에 스토리지 시스템이 없음을 나타낸다(이 경우 사용자는 PVC가 필요한 구성을 배포할 수 없음).
다음 내용
- 퍼시스턴트볼륨 생성에 대해 자세히 알아보기
- 퍼시스턴트볼륨클레임 생성에 대해 자세히 알아보기
- 퍼시스턴트 스토리지 설계 문서 읽어보기
API 레퍼런스
본 페이지에 기술된 API에 대해서 다음을 읽어본다.
7.3 - 프로젝티드 볼륨
이 페이지에서는 쿠버네티스의 프로젝티드 볼륨(projected volume) 에 대해 설명한다. 볼륨에 대해 익숙해지는 것을 추천한다.
들어가며
프로젝티드 볼륨은 여러 기존 볼륨 소스(sources)를 동일한 디렉토리에 매핑한다.
현재, 아래와 같은 볼륨 유형 소스를 프로젝트(project)할 수 있다.
모든 소스는 파드와 같은 네임스페이스에 있어야 한다. 자세한 내용은 올인원(all-in-one) 볼륨 문서를 참고한다.
시크릿, downwardAPI, 컨피그맵 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
기본 권한이 아닌 모드 설정의 시크릿 구성 예시
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- secret:
name: mysecret2
items:
- key: password
path: my-group/my-password
mode: 511
각 프로젝티드 볼륨 소스는 sources 아래의 스펙에 나열된다.
파라미터는 두 가지 예외를 제외하고 동일하다.
- 시크릿의 경우 컨피그맵 명명법과 동일하도록
secretName필드가name으로 변경되었다. defaultMode의 경우 볼륨 소스별 각각 명시할 수 없고 프로젝티드 수준에서만 명시할 수 있다. 그러나 위의 그림처럼 각 개별 프로젝션에 대해mode를 명시적으로 지정할 수 있다.
서비스어카운트토큰 프로젝티드 볼륨
파드의 지정된 경로에 서비스어카운트토큰을 주입할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: sa-token-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: token-vol
mountPath: "/service-account"
readOnly: true
serviceAccountName: default
volumes:
- name: token-vol
projected:
sources:
- serviceAccountToken:
audience: api
expirationSeconds: 3600
path: token
위 예시에는 파드에 주입된 서비스어카운트토큰이 포함된 프로젝티드 볼륨이 있다.
이 파드의 컨테이너는 서비스어카운트토큰을 사용하여 쿠버네티스 API 서버에 접근하고,
파드의 서비스어카운트로 인증할 수 있다.
audience 필드는 토큰의 의도된 대상을 포함한다.
토큰 수신자는 토큰의 대상으로 지정된 식별자로 자신을 식별해야 하며,
그렇지 않으면 토큰을 거부해야 한다.
이 필드는 선택 사항으로, API 서버의 식별자로 기본 설정된다.
expirationSeconds는 서비스어카운트토큰의 예상 유효 기간이다.
기본값은 1시간이며 최소 10분 (600초) 이상이어야 한다.
관리자는 API 서버 옵션 --service-account-max-token-expiration으로
값을 지정하여 최대값을 제한할 수 있다.
path 필드는 프로젝티드 볼륨의 마운트 지점에 대한 상대 경로를 지정한다.
참고:
하위 경로 볼륨 마운트로 프로젝티드 볼륨 소스를 사용하는 컨테이너는
해당 볼륨 소스에 대한 업데이트를 수신하지 않는다.시큐리티컨텍스트(SecurityContext) 상호작용
프로젝티드 서비스 어카운트 볼륨 내에서의 파일 퍼미션 처리에 대한 개선 제안을 통해, 프로젝티드 파일의 소유자 및 퍼미션이 올바르게 설정되도록 변경되었다.
리눅스
프로젝티드 볼륨과 파드
보안 컨텍스트에
RunAsUser가 설정된 리눅스 파드에서는
프로젝티드파일이 컨테이너 사용자 소유권을 포함한 올바른 소유권 집합을 가진다.
파드의 모든 컨테이너의
PodSecurityContext나
컨테이너
SecurityContext의 runAsUser 설정이 동일하다면,
kubelet은 serviceAccountToken 볼륨의 내용이 해당 사용자의 소유이며,
토큰 파일의 권한 모드는 0600로 설정됨을 보장한다.
참고:
생성된 후 파드에 추가되는 임시 컨테이너는 파드 생성 시 설정된 볼륨 권한을 변경하지 않는다.
파드 내 그 외의 모든 컨테이너의 runAsUser가 동일하여
파드의 serviceAccountToken 볼륨 권한이 0600으로 설정되어 있다면, 임시
컨테이너는 토큰을 읽을 수 있도록 동일한 runAsUser를 사용해야 한다.
윈도우
윈도우 파드에서 프로젝티드 볼륨과 파드 SecurityContext에 RunAsUsername이 설정된 경우,
윈도우에서 사용자 계정을 관리하는 방법으로 인하여 소유권이 적용되지 않는다.
윈도우는 보안 계정 관리자 (Security Account Manager)라는 데이터베이스 파일에
로컬 사용자 및 그룹 계정을 저장하고 관리한다.
컨테이너가 실행되는 동안 각 컨테이너는
호스트가 볼 수 없는 SAM 데이터베이스의 자체 인스턴스를 유지한다.
윈도우 컨테이너는 OS의 사용자 모드 부분을 호스트와 분리하여 실행하도록 설계되어 가상 SAM 데이터베이스를 유지 관리한다.
따라서 호스트에서 실행 중인 kubelet은 가상화된 컨테이너 계정에 대한
호스트 파일 소유권을 동적으로 구성할 수 없다.
호스트 머신의 파일을 컨테이너와 공유하려는 경우
C:\ 외부에 있는 자체 볼륨 마운트에 배치하는 것을
권장한다.
기본적으로, 프로젝티드 파일은 예제의 프로젝티드 볼륨 파일처럼 아래와 같은 소유권을 가진다.
PS C:\> Get-Acl C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt | Format-List
Path : Microsoft.PowerShell.Core\FileSystem::C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt
Owner : BUILTIN\Administrators
Group : NT AUTHORITY\SYSTEM
Access : NT AUTHORITY\SYSTEM Allow FullControl
BUILTIN\Administrators Allow FullControl
BUILTIN\Users Allow ReadAndExecute, Synchronize
Audit :
Sddl : O:BAG:SYD:AI(A;ID;FA;;;SY)(A;ID;FA;;;BA)(A;ID;0x1200a9;;;BU)
ContainerAdministrator와 같은
모든 관리자인 사용자는 읽기, 쓰기 그리고 실행 권한을 갖게 되지만
관리자가 아닌 사용자는 읽기 및 실행 권한을 갖게 된다는 것을 의미한다.
참고:
일반적으로 호스트에게 컨테이너 액세스를 승인하는 것은 잠재적인 보안 악용에 대한 문을 열 수 있기 때문에 권장되지 않는다.
윈도우 파드에서 SecurityContext를 RunAsUser로 생성하면,
파드는 영원히 ContainerCreating 상태에 머물게 된다.
따라서 리눅스 전용 RunAsUser 옵션은 윈도우 파드와 함께 사용하지 않는 것이 좋다.
7.4 - 임시 볼륨
이 문서는 쿠버네티스의 임시(ephemeral) 볼륨 에 대해 설명한다. 쿠버네티스 볼륨, 특히 퍼시스턴트볼륨클레임(PersistentVolumeClaim) 및 퍼시스턴트볼륨(PersistentVolume)에 대해 잘 알고 있는 것이 좋다.
일부 애플리케이션은 추가적인 저장소를 필요로 하면서도 재시작 시 데이터의 영구적 보존 여부는 신경쓰지 않을 수도 있다. 예를 들어, 캐싱 서비스는 종종 메모리 사이즈에 제약을 받으며 이에 따라 전반적인 성능에 적은 영향을 미치면서도 사용 데이터를 메모리보다는 느린 저장소에 간헐적으로 옮길 수도 있다.
또 다른 애플리케이션은 읽기 전용 입력 데이터를 파일에서 읽도록 되어 있으며, 이러한 데이터의 예시로는 구성 데이터 또는 비밀 키 등이 있다.
임시 볼륨 은 이러한 사용 사례를 위해 설계되었다. 임시 볼륨은 파드의 수명을 따르며 파드와 함께 생성 및 삭제되기 때문에, 일부 퍼시스턴트 볼륨이 어디에서 사용 가능한지에 제약되는 일 없이 파드가 중지 및 재시작될 수 있다.
임시 볼륨은 파드 명세에 인라인 으로 명시되며, 이로 인해 애플리케이션 배포 및 관리가 간편해진다.
임시 볼륨의 종류
쿠버네티스는 각 목적에 맞는 몇 가지의 임시 볼륨을 지원한다.
- emptyDir: 파드가 시작될 때 빈 상태로 시작되며, 저장소는 로컬의 kubelet 베이스 디렉터리(보통 루트 디스크) 또는 램에서 제공된다
- configMap, downwardAPI, secret: 각 종류의 쿠버네티스 데이터를 파드에 주입한다
- CSI 임시 볼륨: 앞의 볼륨 종류와 비슷하지만, 특히 이 기능을 지원하는 특수한 CSI 드라이버에 의해 제공된다
- 일반(generic) 임시 볼륨: 퍼시스턴트 볼륨도 지원하는 모든 스토리지 드라이버에 의해 제공될 수 있다
emptyDir, configMap, downwardAPI, secret은
로컬 임시 스토리지로서
제공된다.
이들은 각 노드의 kubelet에 의해 관리된다.
CSI 임시 볼륨은 써드파티 CSI 스토리지 드라이버에 의해 제공 되어야 한다.
일반 임시 볼륨은 써드파티 CSI 스토리지 드라이버에 의해 제공 될 수 있지만, 동적 프로비저닝을 지원하는 다른 스토리지 드라이버에 의해서도 제공될 수 있다. 일부 CSI 드라이버는 특히 CSI 임시 볼륨을 위해 만들어져서 동적 프로비저닝을 지원하지 않는데, 이러한 경우에는 일반 임시 볼륨 용으로는 사용할 수 없다.
써드파티 드라이버 사용의 장점은 쿠버네티스 자체적으로는 지원하지 않는 기능(예: kubelet에서 관리하는 디스크와 성능 특성이 다른 스토리지, 또는 다른 데이터 주입)을 제공할 수 있다는 것이다.
CSI 임시 볼륨
기능 상태:
Kubernetes v1.25 [stable]
참고:
CSI 드라이버 중 일부만 CSI 임시 볼륨을 지원한다. 쿠버네티스 CSI 드라이버 목록에서 어떤 드라이버가 임시 볼륨을 지원하는지 보여 준다.개념적으로, CSI 임시 볼륨은 configMap, downwardAPI, secret 볼륨 유형과 비슷하다.
즉, 스토리지는 각 노드에서 로컬하게 관리되며,
파드가 노드에 스케줄링된 이후에 다른 로컬 리소스와 함께 생성된다.
쿠버네티스에는 지금 단계에서는 파드를 재스케줄링하는 개념이 없다.
볼륨 생성은 실패하는 일이 거의 없어야 하며,
만약 실패할 경우 파드 시작 과정이 중단될 것이다.
특히, 스토리지 용량 인지 파드 스케줄링은
이러한 볼륨에 대해서는 지원되지 않는다.
또한 이러한 볼륨은 파드의 스토리지 자원 사용 상한에 제한받지 않는데,
이는 kubelet 자신이 관리하는 스토리지에만 강제할 수 있는 것이기 때문이다.
다음은 CSI 임시 스토리지를 사용하는 파드에 대한 예시 매니페스트이다.
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/data"
name: my-csi-inline-vol
command: [ "sleep", "1000000" ]
volumes:
- name: my-csi-inline-vol
csi:
driver: inline.storage.kubernetes.io
volumeAttributes:
foo: bar
volumeAttributes은 드라이버에 의해 어떤 볼륨이 준비되는지를 결정한다.
이러한 속성은 각 드라이버별로 다르며 표준화되지 않았다.
더 자세한 사항은 각 CSI 드라이버 문서를
참고한다.
CSI 드라이버 제한 사항
CSI 임시 볼륨은 사용자로 하여금 volumeAttributes를
파드 스펙의 일부로서 CSI 드라이버에 직접 제공할 수 있도록 한다.
보통은 관리자만 사용할 수 있는 volumeAttributes를 허용하는 CSI 드라이버는
내장(inline) 임시 볼륨 내에서 사용하는 것이 적합하지 않다.
예를 들어, 일반적으로 스토리지클래스 내에 정의되어 있는 파라미터들은
내장 임시 볼륨 사용을 통해 사용자에게 노출되어서는 안 된다.
클러스터 관리자가 이처럼 파드 스펙 내장 임시 볼륨 사용이 가능한 CSI 드라이버를 제한하려면 다음을 수행할 수 있다.
- CSIDriver 스펙의
volumeLifecycleModes에서Ephemeral을 제거하여, 해당 드라이버가 내장 임시 볼륨으로 사용되는 것을 막는다. - 어드미션 웹훅을 사용하여 드라이버를 활용하는 방법을 제한한다.
일반 임시 볼륨
기능 상태:
Kubernetes v1.23 [stable]
일반 임시 볼륨은
프로비저닝 후 일반적으로 비어 있는 스크래치 데이터에 대해 파드 별 디렉터리를 제공한다는 점에서
emptyDir 볼륨과 유사하다.
하지만 다음과 같은 추가 기능도 제공한다.
- 스토리지는 로컬이거나 네트워크 연결형(network-attached)일 수 있다.
- 볼륨의 크기를 고정할 수 있으며 파드는 이 크기를 초과할 수 없다.
- 드라이버와 파라미터에 따라 볼륨이 초기 데이터를 가질 수도 있다.
- 볼륨에 대한 일반적인 작업은 드라이버가 지원하는 범위 내에서 지원된다. 이와 같은 작업은 다음을 포함한다. 스냅샷, 복제, 크기 조정, 및 스토리지 용량 추적.
다음은 예시이다.
kind: Pod
apiVersion: v1
metadata:
name: my-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/scratch"
name: scratch-volume
command: [ "sleep", "1000000" ]
volumes:
- name: scratch-volume
ephemeral:
volumeClaimTemplate:
metadata:
labels:
type: my-frontend-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "scratch-storage-class"
resources:
requests:
storage: 1Gi
라이프사이클 및 퍼시스턴트볼륨클레임
핵심 설계 아이디어는 볼륨 클레임을 위한 파라미터는 파드의 볼륨 소스 내부에서 허용된다는 점이다. 레이블, 어노테이션 및 퍼시스턴트볼륨클레임을 위한 모든 필드가 지원된다. 이러한 파드가 생성되면, 임시 볼륨 컨트롤러는 파드가 속한 동일한 네임스페이스에 퍼시스턴트볼륨클레임 오브젝트를 생성하고 파드가 삭제될 때에는 퍼시스턴트볼륨클레임도 삭제되도록 만든다.
이는 볼륨 바인딩 및/또는 프로비저닝을 유발하는데,
스토리지클래스가
즉각적인(immediate) 볼륨 바인딩을 사용하는 경우에는 즉시,
또는 파드가 노드에 잠정적으로 스케줄링되었을 때 발생한다(WaitForFirstConsumer 볼륨 바인딩 모드).
일반 임시 볼륨에는 후자가 추천되는데, 이 경우 스케줄러가 파드를 할당하기에 적합한 노드를 선택하기가 쉬워지기 때문이다.
즉각적인 바인딩을 사용하는 경우,
스케줄러는 볼륨이 사용 가능해지는 즉시 해당 볼륨에 접근 가능한 노드를 선택하도록 강요받는다.
리소스 소유권 관점에서,
일반 임시 스토리지를 갖는 파드는
해당 임시 스토리지를 제공하는 퍼시스턴트볼륨클레임의 소유자이다.
파드가 삭제되면, 쿠버네티스 가비지 콜렉터는 해당 PVC를 삭제하는데,
스토리지 클래스의 기본 회수 정책이 볼륨을 삭제하는 것이기 때문에 PVC의 삭제는 보통 볼륨의 삭제를 유발한다.
회수 정책을 retain으로 설정한 스토리지클래스를 사용하여 준 임시(quasi-ephemeral) 로컬 스토리지를 생성할 수도 있는데,
이렇게 하면 스토리지의 수명이 파드의 수명보다 길어지며,
이러한 경우 볼륨 정리를 별도로 수행해야 함을 명심해야 한다.
이러한 PVC가 존재하는 동안은, 다른 PVC와 동일하게 사용될 수 있다. 특히, 볼륨 복제 또는 스냅샷 시에 데이터 소스로 참조될 수 있다. 또한 해당 PVC 오브젝트는 해당 볼륨의 현재 상태도 가지고 있다.
퍼시스턴트볼륨클레임 이름 정하기
자동으로 생성된 PVC의 이름은 규칙에 따라 정해진다.
PVC의 이름은 파드 이름과 볼륨 이름의 사이를 하이픈(-)으로 결합한 형태이다.
위의 예시에서, PVC 이름은 my-app-scratch-volume가 된다.
이렇게 규칙에 의해 정해진 이름은 PVC와의 상호작용을 더 쉽게 만드는데,
이는 파드 이름과 볼륨 이름을 알면
PVC 이름을 별도로 검색할 필요가 없기 때문이다.
PVC 이름 규칙에 따라 서로 다른 파드 간 이름 충돌이 발생할 수 있으며("pod-a" 파드 + "scratch" 볼륨 vs. "pod" 파드 + "a-scratch" 볼륨 - 두 경우 모두 PVC 이름은 "pod-a-scratch") 또한 파드와 수동으로 생성한 PVC 간에도 이름 충돌이 발생할 수 있다.
이러한 충돌은 감지될 수 있는데, 이는 PVC가 파드를 위해 생성된 경우에만 임시 볼륨으로 사용되기 때문이다. 이러한 체크는 소유권 관계를 기반으로 한다. 기존에 존재하던 PVC는 덮어써지거나 수정되지 않는다. 대신에 충돌을 해결해주지는 않는데, 이는 적합한 PVC가 없이는 파드가 시작될 수 없기 때문이다.
주의:
이러한 충돌이 발생하지 않도록 동일한 네임스페이스 내에서는 파드와 볼륨의 이름을 정할 때 주의해야 한다.보안
GenericEphemeralVolume 기능을 활성화하면 사용자가 파드를 생성할 수 있는 경우 PVC를 간접적으로 생성할 수 있도록 허용하며, 심지어 사용자가 PVC를 직접적으로 만들 수 있는 권한이 없는 경우에도 이를 허용한다. 클러스터 관리자는 이를 명심해야 한다. 이것이 보안 모델에 부합하지 않는다면, 어드미션 웹훅을 사용하여 일반 임시 볼륨을 갖는 파드와 같은 오브젝트를 거부해야 한다.
일반적인 PVC의 네임스페이스 쿼터는 여전히 적용되므로, 사용자가 이 새로운 메카니즘을 사용할 수 있도록 허용되었어도, 다른 정책을 우회하는 데에는 사용할 수 없다.
다음 내용
kubelet이 관리하는 임시 볼륨
로컬 임시 스토리지를 참고한다.
CSI 임시 볼륨
- 설계에 대한 더 자세한 정보는 임시 인라인 CSI 볼륨 KEP를 참고한다.
- 이 기능의 추가 개발에 대한 자세한 정보는 enhancement 저장소의 이슈 #596을 참고한다.
일반 임시 볼륨
- 설계에 대한 더 자세한 정보는 일반 임시 인라인 볼륨 KEP를 참고한다.
7.5 - 스토리지 클래스
이 문서는 쿠버네티스의 스토리지클래스의 개념을 설명한다. 볼륨과 퍼시스턴트 볼륨에 익숙해지는 것을 권장한다.
소개
스토리지클래스는 관리자가 제공하는 스토리지의 "classes"를 설명할 수 있는 방법을 제공한다. 다른 클래스는 서비스의 품질 수준 또는 백업 정책, 클러스터 관리자가 정한 임의의 정책에 매핑될 수 있다. 쿠버네티스 자체는 클래스가 무엇을 나타내는지에 대해 상관하지 않는다. 다른 스토리지 시스템에서는 이 개념을 "프로파일"이라고도 한다.
스토리지클래스 리소스
각 스토리지클래스에는 해당 스토리지클래스에 속하는 퍼시스턴트볼륨을 동적으로 프로비저닝
할 때 사용되는 provisioner, parameters 와
reclaimPolicy 필드가 포함된다.
스토리지클래스 오브젝트의 이름은 중요하며, 사용자가 특정 클래스를 요청할 수 있는 방법이다. 관리자는 스토리지클래스 오브젝트를 처음 생성할 때 클래스의 이름과 기타 파라미터를 설정하며, 일단 생성된 오브젝트는 업데이트할 수 없다.
관리자는 특정 클래스에 바인딩을 요청하지 않는 PVC에 대해서만 기본 스토리지클래스를 지정할 수 있다. 자세한 내용은 퍼시스턴트볼륨클레임 섹션을 본다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
프로비저너
각 스토리지클래스에는 PV 프로비저닝에 사용되는 볼륨 플러그인을 결정하는 프로비저너가 있다. 이 필드는 반드시 지정해야 한다.
| 볼륨 플러그인 | 내부 프로비저너 | 설정 예시 |
|---|---|---|
| AWSElasticBlockStore | ✓ | AWS EBS |
| AzureFile | ✓ | Azure 파일 |
| AzureDisk | ✓ | Azure 디스크 |
| CephFS | - | - |
| Cinder | ✓ | OpenStack Cinder |
| FC | - | - |
| FlexVolume | - | - |
| GCEPersistentDisk | ✓ | GCE PD |
| iSCSI | - | - |
| NFS | - | NFS |
| RBD | ✓ | Ceph RBD |
| VsphereVolume | ✓ | vSphere |
| PortworxVolume | ✓ | Portworx 볼륨 |
| Local | - | Local |
여기 목록에서 "내부" 프로비저너를 지정할 수 있다(이 이름은 "kubernetes.io" 가 접두사로 시작하고, 쿠버네티스와 함께 제공된다). 또한, 쿠버네티스에서 정의한 사양을 따르는 독립적인 프로그램인 외부 프로비저너를 실행하고 지정할 수 있다. 외부 프로비저너의 작성자는 코드의 수명, 프로비저너의 배송 방법, 실행 방법, (Flex를 포함한)볼륨 플러그인 등에 대한 완전한 재량권을 가진다. kubernetes-sigs/sig-storage-lib-external-provisioner 리포지터리에는 대량의 사양을 구현하는 외부 프로비저너를 작성하기 위한 라이브러리가 있다. 일부 외부 프로비저너의 목록은 kubernetes-sigs/sig-storage-lib-external-provisioner 리포지터리에 있다.
예를 들어, NFS는 내부 프로비저너를 제공하지 않지만, 외부 프로비저너를 사용할 수 있다. 타사 스토리지 업체가 자체 외부 프로비저너를 제공하는 경우도 있다.
리클레임 정책
스토리지클래스에 의해 동적으로 생성된 퍼시스턴트볼륨은 클래스의
reclaimPolicy 필드에 지정된 리클레임 정책을 가지는데,
이는 Delete 또는 Retain 이 될 수 있다. 스토리지클래스 오브젝트가
생성될 때 reclaimPolicy 가 지정되지 않으면 기본값은 Delete 이다.
수동으로 생성되고 스토리지클래스를 통해 관리되는 퍼시스턴트볼륨에는 생성 시 할당된 리클레임 정책이 있다.
볼륨 확장 허용
기능 상태:
Kubernetes v1.11 [beta]
퍼시스턴트볼륨은 확장이 가능하도록 구성할 수 있다. 이 기능을 true 로 설정하면
해당 PVC 오브젝트를 편집하여 볼륨 크기를 조정할 수 있다.
다음 볼륨 유형은 기본 스토리지클래스에서 allowVolumeExpansion 필드가
true로 설정된 경우 볼륨 확장을 지원한다.
| 볼륨 유형 | 요구되는 쿠버네티스 버전 |
|---|---|
| gcePersistentDisk | 1.11 |
| awsElasticBlockStore | 1.11 |
| Cinder | 1.11 |
| rbd | 1.11 |
| Azure File | 1.11 |
| Azure Disk | 1.11 |
| Portworx | 1.11 |
| FlexVolume | 1.13 |
| CSI | 1.14 (alpha), 1.16 (beta) |
참고:
볼륨 확장 기능을 사용해서 볼륨을 확장할 수 있지만, 볼륨을 축소할 수는 없다.마운트 옵션
스토리지클래스에 의해 동적으로 생성된 퍼시스턴트볼륨은
클래스의 mountOptions 필드에 지정된 마운트 옵션을 가진다.
만약 볼륨 플러그인이 마운트 옵션을 지원하지 않는데, 마운트 옵션을 지정하면 프로비저닝은 실패한다. 마운트 옵션은 클래스 또는 PV에서 검증되지 않는다. PV 마운트가 유효하지 않으면, 마운트가 실패하게 된다.
볼륨 바인딩 모드
volumeBindingMode 필드는 볼륨 바인딩과 동적
프로비저닝의 시작 시기를 제어한다. 설정되어 있지 않으면, Immediate 모드가 기본으로 사용된다.
Immediate 모드는 퍼시스턴트볼륨클레임이 생성되면 볼륨
바인딩과 동적 프로비저닝이 즉시 발생하는 것을 나타낸다. 토폴로지 제약이
있고 클러스터의 모든 노드에서 전역적으로 접근할 수 없는 스토리지
백엔드의 경우, 파드의 스케줄링 요구 사항에 대한 지식 없이 퍼시스턴트볼륨이
바인딩되거나 프로비저닝된다. 이로 인해 스케줄되지 않은 파드가 발생할 수 있다.
클러스터 관리자는 WaitForFirstConsumer 모드를 지정해서 이 문제를 해결할 수 있는데
이 모드는 퍼시스턴트볼륨클레임을 사용하는 파드가 생성될 때까지 퍼시스턴트볼륨의 바인딩과 프로비저닝을 지연시킨다.
퍼시스턴트볼륨은 파드의 스케줄링 제약 조건에 의해 지정된 토폴로지에
따라 선택되거나 프로비전된다. 여기에는
리소스 요구 사항,
노드 셀렉터,
파드 어피니티(affinity)와
안티-어피니티(anti-affinity)
그리고 테인트(taint)와 톨러레이션(toleration)이 포함된다.
다음 플러그인은 동적 프로비저닝과 WaitForFirstConsumer 를 지원한다.
다음 플러그인은 사전에 생성된 퍼시스턴트볼륨 바인딩으로 WaitForFirstConsumer 를 지원한다.
- 위에서 언급한 모든 플러그인
- Local
기능 상태:
CSI 볼륨은 동적 프로비저닝과
사전에 생성된 PV에서도 지원되지만, 지원되는 토폴로지 키와 예시를 보려면 해당
CSI 드라이버에 대한 문서를 본다.
Kubernetes v1.17 [stable]
참고:
WaitForFirstConsumer를 사용한다면, 노드 어피니티를 지정하기 위해서 파드 스펙에 nodeName을 사용하지는 않아야 한다.
만약 nodeName을 사용한다면, 스케줄러가 바이패스되고 PVC가 pending 상태로 있을 것이다.
대신, 아래와 같이 호스트네임을 이용하는 노드셀렉터를 사용할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
nodeSelector:
kubernetes.io/hostname: kube-01
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
허용된 토폴로지
클러스터 운영자가 WaitForFirstConsumer 볼륨 바인딩 모드를 지정하면, 대부분의 상황에서
더 이상 특정 토폴로지로 프로비저닝을 제한할 필요가 없다. 그러나
여전히 필요한 경우에는 allowedTopologies 를 지정할 수 있다.
이 예시는 프로비전된 볼륨의 토폴로지를 특정 영역으로 제한하는 방법을
보여 주며 지원되는 플러그인의 zone 과 zones 파라미터를 대체하는
데 사용해야 한다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
volumeBindingMode: WaitForFirstConsumer
allowedTopologies:
- matchLabelExpressions:
- key: failure-domain.beta.kubernetes.io/zone
values:
- us-central-1a
- us-central-1b
파라미터
스토리지 클래스에는 스토리지 클래스에 속하는 볼륨을 설명하는 파라미터가
있다. provisioner 에 따라 다른 파라미터를 사용할 수 있다. 예를 들어,
파라미터 type 에 대한 값 io1 과 파라미터 iopsPerGB 는
EBS에만 사용할 수 있다. 파라미터 생략 시 일부 기본값이
사용된다.
스토리지클래스에 대해 최대 512개의 파라미터를 정의할 수 있다. 키와 값을 포함하여 파라미터 오브젝터의 총 길이는 256 KiB를 초과할 수 없다.
AWS EBS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "10"
fsType: ext4
type:io1,gp2,sc1,st1. 자세한 내용은 AWS 문서를 본다. 기본값:gp2.zone(사용 중단(deprecated)): AWS 영역.zone과zones를 지정하지 않으면, 일반적으로 쿠버네티스 클러스터의 노드가 있는 모든 활성화된 영역에 걸쳐 볼륨이 라운드 로빈으로 조정된다.zone과zones파라미터를 동시에 사용해서는 안된다.zones(사용 중단): 쉼표로 구분된 AWS 영역의 목록.zone과zones를 지정하지 않으면, 일반적으로 쿠버네티스 클러스터의 노드가 있는 모든 활성화된 영역에 걸쳐 볼륨이 라운드 로빈으로 조정된다.zone과zones파라미터를 동시에 사용해서는 안된다.iopsPerGB:io1볼륨 전용이다. 1초당 GiB에 대한 I/O 작업 수이다. AWS 볼륨 플러그인은 요청된 볼륨 크기에 곱셈하여 볼륨의 IOPS를 계산하고 이를 20,000 IOPS로 제한한다(AWS에서 지원하는 최대값으로, AWS 문서를 본다). 여기에는 문자열, 즉10이 아닌,"10"이 필요하다.fsType: fsType은 쿠버네티스에서 지원된다. 기본값:"ext4".encrypted: EBS 볼륨의 암호화 여부를 나타낸다. 유효한 값은"ture"또는"false"이다. 여기에는 문자열, 즉true가 아닌,"true"가 필요하다.kmsKeyId: 선택 사항. 볼륨을 암호화할 때 사용할 키의 전체 Amazon 리소스 이름이다. 아무것도 제공되지 않지만,encrypted가 true라면 AWS에 의해 키가 생성된다. 유효한 ARN 값은 AWS 문서를 본다.
GCE PD
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
fstype: ext4
replication-type: none
-
type:pd-standard또는pd-ssd. 기본값:pd-standard -
zone(사용 중단): GCE 영역.zone과zones를 모두 지정하지 않으면, 쿠버네티스 클러스터의 노드가 있는 모든 활성화된 영역에 걸쳐 볼륨이 라운드 로빈으로 조정된다.zone과zones파라미터를 동시에 사용해서는 안된다. -
zones(사용 중단): 쉼표로 구분되는 GCE 영역의 목록.zone과zones를 모두 지정하지 않으면, 쿠버네티스 클러스터의 노드가 있는 모든 활성화된 영역에 걸쳐 볼륨이 라운드 로빈으로 조정된다.zone과zones파라미터를 동시에 사용해서는 안된다. -
fstype:ext4또는xfs. 기본값:ext4. 정의된 파일시스템 유형은 호스트 운영체제에서 지원되어야 한다. -
replication-type:none또는regional-pd. 기본값:none.
replication-type 을 none 으로 설정하면 (영역) PD가 프로비전된다.
replication-type 이 regional-pd 로 설정되면,
지역 퍼시스턴트 디스크
가 프로비전된다. 이는 퍼시스턴트볼륨클레임과 스토리지클래스를 소모하는 파드를
생성할 때 지역 퍼시스턴트 디스크는 두개의 영역으로
프로비전되기에 volumeBindingMode: WaitForFirstConsumer 를
설정하는 것을 강력히 권장한다. 하나의 영역은 파드가 스케줄된
영역과 동일하다. 다른 영역은 클러스터에서 사용할 수
있는 영역에서 임의로 선택된다. 디스크 영역은 allowedTopologies 를
사용하면 더 제한할 수 있다.
NFS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-nfs
provisioner: example.com/external-nfs
parameters:
server: nfs-server.example.com
path: /share
readOnly: "false"
server: NFS 서버의 호스트네임 또는 IP 주소.path: NFS 서버가 익스포트(export)한 경로.readOnly: 스토리지를 읽기 전용으로 마운트할지 나타내는 플래그(기본값: false).
쿠버네티스에는 내장 NFS 프로비저너가 없다. NFS를 위한 스토리지클래스를 생성하려면 외부 프로비저너를 사용해야 한다. 예시는 다음과 같다.
OpenStack Cinder
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gold
provisioner: kubernetes.io/cinder
parameters:
availability: nova
availability: 가용성 영역. 지정하지 않으면, 일반적으로 쿠버네티스 클러스터의 노드가 있는 모든 활성화된 영역에 걸쳐 볼륨이 라운드 로빈으로 조정된다.
참고:
기능 상태:
Kubernetes v1.11 [deprecated]
이 OpenStack 내부 프로비저너는 사용 중단 되었다. OpenStack용 외부 클라우드 공급자를 사용한다.
vSphere
vSphere 스토리지 클래스에는 두 가지 유형의 프로비저닝 도구가 있다.
- CSI 프로비저닝 도구:
csi.vsphere.vmware.com - vCP 프로비저닝 도구:
kubernetes.io/vsphere-volume
인-트리 프로비저닝 도구는 사용 중단되었다. CSI 프로비저닝 도구에 대한 자세한 내용은 쿠버네티스 vSphere CSI 드라이버 및 vSphereVolume CSI 마이그레이션을 참고한다.
CSI 프로비저닝 도구
vSphere CSI 스토리지클래스 프로비저닝 도구는 Tanzu 쿠버네티스 클러스터에서 작동한다. 예시는 vSphere CSI 리포지터리를 참조한다.
vCP 프로비저닝 도구
다음 예시에서는 VMware 클라우드 공급자(vCP) 스토리지클래스 프로비저닝 도구를 사용한다.
-
사용자 지정 디스크 형식으로 스토리지클래스를 생성한다.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthickdiskformat:thin,zeroedthick와eagerzeroedthick. 기본값:"thin". -
사용자 지정 데이터스토어에 디스크 형식으로 스토리지클래스를 생성한다.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthick datastore: VSANDatastoredatastore: 또한, 사용자는 스토리지클래스에서 데이터스토어를 지정할 수 있다. 볼륨은 스토리지클래스에 지정된 데이터스토어에 생성되며, 이 경우VSANDatastore이다. 이 필드는 선택 사항이다. 데이터스토어를 지정하지 않으면, vSphere 클라우드 공급자를 초기화하는데 사용되는 vSphere 설정 파일에 지정된 데이터스토어에 볼륨이 생성된다. -
쿠버네티스 내부 스토리지 정책을 관리한다.
-
기존 vCenter SPBM 정책을 사용한다.
vSphere 스토리지 관리의 가장 중요한 기능 중 하나는 정책 기반 관리이다. 스토리지 정책 기반 관리(Storage Policy Based Management (SPBM))는 광범위한 데이터 서비스와 스토리지 솔루션에서 단일 통합 컨트롤 플레인을 제공하는 스토리지 정책 프레임워크이다. SPBM을 통해 vSphere 관리자는 용량 계획, 차별화된 서비스 수준과 용량의 헤드룸(headroom) 관리와 같은 선행 스토리지 프로비저닝 문제를 극복할 수 있다.
SPBM 정책은
storagePolicyName파라미터를 사용하면 스토리지클래스에서 지정할 수 있다. -
쿠버네티스 내부의 가상 SAN 정책 지원
Vsphere 인프라스트럭처(Vsphere Infrastructure (VI)) 관리자는 동적 볼륨 프로비저닝 중에 사용자 정의 가상 SAN 스토리지 기능을 지정할 수 있다. 이제 동적 볼륨 프로비저닝 중에 스토리지 기능의 형태로 성능 및 가용성과 같은 스토리지 요구 사항을 정의할 수 있다. 스토리지 기능 요구 사항은 가상 SAN 정책으로 변환된 퍼시스턴트 볼륨(가상 디스크)을 생성할 때 가상 SAN 계층으로 푸시된다. 가상 디스크는 가상 SAN 데이터 스토어에 분산되어 요구 사항을 충족시키게 된다.
퍼시스턴트 볼륨 관리에 스토리지 정책을 사용하는 방법에 대한 자세한 내용은 볼륨의 동적 프로비저닝을 위한 스토리지 정책 기반 관리(SPBM)를 참조한다.
-
vSphere용 쿠버네티스 내에서 퍼시스턴트 볼륨 관리를 시도하는 vSphere 예시는 거의 없다.
Ceph RBD
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: kube
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
userSecretNamespace: default
fsType: ext4
imageFormat: "2"
imageFeatures: "layering"
-
monitors: 쉼표로 구분된 Ceph 모니터. 이 파라미터는 필수이다. -
adminId: 풀에 이미지를 생성할 수 있는 Ceph 클라이언트 ID. 기본값은 "admin". -
adminSecretName:adminId의 시크릿 이름. 이 파라미터는 필수이다. 제공된 시크릿은 "kubernetes.io/rbd" 유형이어야 한다. -
adminSecretNamespace:adminSecretName의 네임스페이스. 기본값은 "default". -
pool: Ceph RBD 풀. 기본값은 "rbd". -
userId: RBD 이미지를 매핑하는 데 사용하는 Ceph 클라이언트 ID. 기본값은adminId와 동일하다. -
userSecretName: RDB 이미지를 매핑하기 위한userId에 대한 Ceph 시크릿 이름. PVC와 동일한 네임스페이스에 존재해야 한다. 이 파라미터는 필수이다. 제공된 시크릿은 "kubernetes.io/rbd" 유형이어야 하며, 다음의 예시와 같이 생성되어야 한다.kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \ --from-literal=key='QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \ --namespace=kube-system -
userSecretNamespace:userSecretName의 네임스페이스. -
fsType: 쿠버네티스가 지원하는 fsType. 기본값:"ext4". -
imageFormat: Ceph RBD 이미지 형식, "1" 또는 "2". 기본값은 "2". -
imageFeatures: 이 파라미터는 선택 사항이며,imageFormat을 "2"로 설정한 경우에만 사용해야 한다. 현재layering에서만 기능이 지원된다. 기본값은 ""이며, 기능이 설정되어 있지 않다.
Azure 디스크
Azure 비관리 디스크 스토리지 클래스
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
skuName: Standard_LRS
location: eastus
storageAccount: azure_storage_account_name
skuName: Azure 스토리지 계정 Sku 계층. 기본값은 없음.location: Azure 스토리지 계정 지역. 기본값은 없음.storageAccount: Azure 스토리지 계정 이름. 스토리지 계정이 제공되면, 클러스터와 동일한 리소스 그룹에 있어야 하며,location은 무시된다. 스토리지 계정이 제공되지 않으면, 클러스터와 동일한 리소스 그룹에 새 스토리지 계정이 생성된다.
Azure 디스크 스토리지 클래스(v1.7.2부터 제공)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
storageaccounttype: Standard_LRS
kind: managed
storageaccounttype: Azure 스토리지 계정 Sku 계층. 기본값은 없음.kind: 가능한 값은shared,dedicated, 그리고managed(기본값) 이다.kind가shared인 경우, 모든 비관리 디스크는 클러스터와 동일한 리소스 그룹에 있는 몇 개의 공유 스토리지 계정에 생성된다.kind가dedicated인 경우, 클러스터와 동일한 리소스 그룹에서 새로운 비관리 디스크에 대해 새로운 전용 스토리지 계정이 생성된다.kind가managed인 경우, 모든 관리 디스크는 클러스터와 동일한 리소스 그룹에 생성된다.resourceGroup: Azure 디스크를 만들 리소스 그룹을 지정한다. 기존에 있는 리소스 그룹 이름이어야 한다. 지정되지 않는 경우, 디스크는 현재 쿠버네티스 클러스터와 동일한 리소스 그룹에 배치된다.
- 프리미엄 VM은 표준 LRS(Standard_LRS)와 프리미엄 LRS(Premium_LRS) 디스크를 모두 연결할 수 있는 반면에, 표준 VM은 표준 LRS(Standard_LRS) 디스크만 연결할 수 있다.
- 관리되는 VM은 관리되는 디스크만 연결할 수 있고, 비관리 VM은 비관리 디스크만 연결할 수 있다.
Azure 파일
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
parameters:
skuName: Standard_LRS
location: eastus
storageAccount: azure_storage_account_name
skuName: Azure 스토리지 계정 Sku 계층. 기본값은 없음.location: Azure 스토리지 계정 지역. 기본값은 없음.storageAccount: Azure 스토리지 계정 이름. 기본값은 없음. 스토리지 계정이 제공되지 않으면, 리소스 그룹과 관련된 모든 스토리지 계정이 검색되어skuName과location이 일치하는 것을 찾는다. 스토리지 계정이 제공되면, 클러스터와 동일한 리소스 그룹에 있어야 하며skuName과location은 무시된다.secretNamespace: Azure 스토리지 계정 이름과 키가 포함된 시크릿 네임스페이스. 기본값은 파드와 동일하다.secretName: Azure 스토리지 계정 이름과 키가 포함된 시크릿 이름. 기본값은azure-storage-account-<accountName>-secretreadOnly: 스토리지가 읽기 전용으로 마운트되어야 하는지 여부를 나타내는 플래그. 읽기/쓰기 마운트를 의미하는 기본값은 false. 이 설정은 볼륨마운트(VolumeMounts)의ReadOnly설정에도 영향을 준다.
스토리지 프로비저닝 중에 마운트 자격증명에 대해 secretName
이라는 시크릿이 생성된다. 클러스터에
RBAC과
컨트롤러의 롤(role)들을
모두 활성화한 경우, clusterrole system:controller:persistent-volume-binder
에 대한 secret 리소스에 create 권한을 추가한다.
다중 테넌시 컨텍스트에서 secretNamespace 의 값을 명시적으로 설정하는
것을 권장하며, 그렇지 않으면 다른 사용자가 스토리지 계정 자격증명을
읽을 수 있기 때문이다.
Portworx 볼륨
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: portworx-io-priority-high
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "1"
snap_interval: "70"
priority_io: "high"
fs: 배치할 파일 시스템:none/xfs/ext4(기본값:ext4)block_size: Kbytes 단위의 블록 크기(기본값:32).repl: 레플리케이션 팩터1..3(기본값:1)의 형태로 제공될 동기 레플리카의 수. 여기에는 문자열, 즉0이 아닌,"0"이 필요하다.priority_io: 볼륨이 고성능 또는 우선 순위가 낮은 스토리지에서 생성될 것인지를 결정한다high/medium/low(기본값:low).snap_interval: 스냅샷을 트리거할 때의 시각/시간 간격(분). 스냅샷은 이전 스냅샷과의 차이에 따라 증분되며, 0은 스냅을 비활성화 한다(기본값:0). 여기에는 문자열, 즉70이 아닌,"70"이 필요하다.aggregation_level: 볼륨이 분배될 청크 수를 지정하며, 0은 집계되지 않은 볼륨을 나타낸다(기본값:0). 여기에는 문자열, 즉0이 아닌,"0"이 필요하다.ephemeral: 마운트 해제 후 볼륨을 정리해야 하는지 혹은 지속적이어야 하는지를 지정한다.emptyDir에 대한 유스케이스는 이 값을 true로 설정할 수 있으며,persistent volumes에 대한 유스케이스인 카산드라와 같은 데이터베이스는 false로 설정해야 한다.true/false(기본값false) 여기에는 문자열, 즉true가 아닌,"true"가 필요하다.
Local
기능 상태:
Kubernetes v1.14 [stable]
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
로컬 볼륨은 현재 동적 프로비저닝을 지원하지 않지만, 파드 스케줄링까지
볼륨 바인딩을 지연시키기 위해서는 스토리지클래스가 여전히 생성되어야 한다. 이것은
WaitForFirstConsumer 볼륨 바인딩 모드에 의해 지정된다.
볼륨 바인딩을 지연시키면 스케줄러가 퍼시스턴트볼륨클레임에 적절한 퍼시스턴트볼륨을 선택할 때 파드의 모든 스케줄링 제약 조건을 고려할 수 있다.
7.6 - 동적 볼륨 프로비저닝
동적 볼륨 프로비저닝을 통해 온-디맨드 방식으로 스토리지 볼륨을 생성할 수 있다.
동적 프로비저닝이 없으면 클러스터 관리자는 클라우드 또는 스토리지
공급자에게 수동으로 요청해서 새 스토리지 볼륨을 생성한 다음, 쿠버네티스에
표시하기 위해 PersistentVolume 오브젝트를
생성해야 한다. 동적 프로비저닝 기능을 사용하면 클러스터 관리자가
스토리지를 사전 프로비저닝 할 필요가 없다. 대신 사용자가
스토리지를 요청하면 자동으로 프로비저닝 한다.
배경
동적 볼륨 프로비저닝의 구현은 storage.k8s.io API 그룹의 StorageClass
API 오브젝트를 기반으로 한다. 클러스터 관리자는 볼륨을 프로비전하는
볼륨 플러그인 (프로비저너라고도 알려짐)과 프로비저닝시에 프로비저너에게
전달할 파라미터 집합을 지정하는 StorageClass
오브젝트를 필요한 만큼 정의할 수 있다.
클러스터 관리자는 클러스터 내에서 사용자 정의 파라미터 집합을
사용해서 여러 가지 유형의 스토리지 (같거나 다른 스토리지 시스템들)를
정의하고 노출시킬 수 있다. 또한 이 디자인을 통해 최종 사용자는
스토리지 프로비전 방식의 복잡성과 뉘앙스에 대해 걱정할 필요가 없다. 하지만,
여전히 여러 스토리지 옵션들을 선택할 수 있다.
스토리지 클래스에 대한 자세한 정보는 여기에서 찾을 수 있다.
동적 프로비저닝 활성화하기
동적 프로비저닝을 활성화하려면 클러스터 관리자가 사용자를 위해 하나 이상의 스토리지클래스(StorageClass) 오브젝트를 사전 생성해야 한다. 스토리지클래스 오브젝트는 동적 프로비저닝이 호출될 때 사용할 프로비저너와 해당 프로비저너에게 전달할 파라미터를 정의한다. 스토리지클래스 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
다음 매니페스트는 표준 디스크와 같은 퍼시스턴트 디스크를 프로비전하는 스토리지 클래스 "slow"를 만든다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
다음 매니페스트는 SSD와 같은 퍼시스턴트 디스크를 프로비전하는 스토리지 클래스 "fast"를 만든다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
동적 프로비저닝 사용하기
사용자는 PersistentVolumeClaim 에 스토리지 클래스를 포함시켜 동적으로 프로비전된
스토리지를 요청한다. 쿠버네티스 v1.6 이전에는 volume.beta.kubernetes.io/storage-class
어노테이션을 통해 수행되었다. 그러나 이 어노테이션은
v1.9부터는 더 이상 사용하지 않는다. 사용자는 이제 PersistentVolumeClaim 오브젝트의
storageClassName 필드를 사용해야 한다. 이 필드의 값은
관리자가 구성한 StorageClass 의 이름과
일치해야 한다. (아래를 참고)
예를 들어 "fast" 스토리지 클래스를 선택하려면 다음과
같은 PersistentVolumeClaim 을 생성한다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast
resources:
requests:
storage: 30Gi
이 클레임의 결과로 SSD와 같은 퍼시스턴트 디스크가 자동으로 프로비전 된다. 클레임이 삭제되면 볼륨이 삭제된다.
기본 동작
스토리지 클래스가 지정되지 않은 경우 모든 클레임이 동적으로 프로비전이 되도록 클러스터에서 동적 프로비저닝을 활성화 할 수 있다. 클러스터 관리자는 이 방법으로 활성화 할 수 있다.
- 하나의
StorageClass오브젝트를 default 로 표시한다. - API 서버에서
DefaultStorageClass어드미션 컨트롤러를 사용하도록 설정한다.
관리자는 storageclass.kubernetes.io/is-default-class 어노테이션을
추가하여 특정 StorageClass 를 기본으로 표시할 수 있다.
기본 StorageClass 가 클러스터에 존재하고 사용자가
storageClassName 를 지정하지 않은 PersistentVolumeClaim 을
작성하면, DefaultStorageClass 어드미션 컨트롤러가 디폴트
스토리지 클래스를 가리키는 storageClassName 필드를 자동으로 추가한다.
클러스터에는 최대 하나의 default 스토리지 클래스가 있을 수 있다. 그렇지 않은 경우
storageClassName 을 명시적으로 지정하지 않은 PersistentVolumeClaim 을
생성할 수 없다.
토폴로지 인식
다중 영역 클러스터에서 파드는 한 지역 내 여러 영역에 걸쳐 분산될 수 있다. 파드가 예약된 영역에서 단일 영역 스토리지 백엔드를 프로비전해야 한다. 볼륨 바인딩 모드를 설정해서 수행할 수 있다.
7.7 - 볼륨 스냅샷
쿠버네티스에서 VolumeSnapshot 은 스토리지 시스템 볼륨 스냅샷을 나타낸다. 이 문서는 이미 쿠버네티스 퍼시스턴트 볼륨에 대해 잘 알고 있다고 가정한다.
소개
API 리소스 PersistentVolume 및 PersistentVolumeClaim 가
사용자와 관리자를 위해 볼륨을 프로비전할 때 사용되는 것과 유사하게, VolumeSnapshotContent
및 VolumeSnapshot API 리소스는 사용자와 관리자를 위한 볼륨 스냅샷을 생성하기 위해
제공된다.
VolumeSnapshotContent 는 관리자가
프로비져닝한 클러스터 내 볼륨의 스냅샷이다. 퍼시스턴트볼륨이
클러스터 리소스인 것처럼 이것 또한 클러스터 리소스이다.
VolumeSnapshot 은 사용자가 볼륨의 스냅샷을 요청할 수 있는 방법이다. 이는
퍼시스턴트볼륨클레임과 유사하다.
VolumeSnapshotClass 을 사용하면
VolumeSnapshot 에 속한 다른 속성을 지정할 수 있다. 이러한 속성은 스토리지 시스템에의 동일한
볼륨에서 가져온 스냅샷마다 다를 수 있으므로
PersistentVolumeClaim 의 동일한 StorageClass 를 사용하여 표현할 수는 없다.
볼륨 스냅샷은 쿠버네티스 사용자에게 완전히 새로운 볼륨을 생성하지 않고도 특정 시점에 볼륨의 콘텐츠를 복사하는 표준화된 방법을 제공한다. 예를 들어, 데이터베이스 관리자는 이 기능을 사용하여 수정 사항을 편집 또는 삭제하기 전에 데이터베이스를 백업할 수 있다.
사용자는 이 기능을 사용할 때 다음 사항을 알고 있어야 한다.
- API 오브젝트인
VolumeSnapshot,VolumeSnapshotContent,VolumeSnapshotClass는 핵심 API가 아닌, CRDs 이다. VolumeSnapshot은 CSI 드라이버에서만 사용할 수 있다.- 쿠버네티스 팀은
VolumeSnapshot의 배포 프로세스 일부로써, 컨트롤 플레인에 배포할 스냅샷 컨트롤러와 CSI 드라이버와 함께 배포할 csi-snapshotter라는 사이드카 헬퍼(helper) 컨테이너를 제공한다. 스냅샷 컨트롤러는VolumeSnapshot및VolumeSnapshotContent오브젝트를 관찰하고VolumeSnapshotContent오브젝트의 생성 및 삭제에 대한 책임을 진다. 사이드카 csi-snapshotter는VolumeSnapshotContent오브젝트를 관찰하고 CSI 엔드포인트에 대해CreateSnapshot및DeleteSnapshot을 트리거(trigger)한다. - 스냅샷 오브젝트에 대한 강화된 검증을 제공하는 검증 웹훅 서버도 있다. 이는 CSI 드라이버가 아닌 스냅샷 컨트롤러 및 CRD와 함께 쿠버네티스 배포판에 의해 설치되어야 한다. 스냅샷 기능이 활성화된 모든 쿠버네티스 클러스터에 설치해야 한다.
- CSI 드라이버에서의 볼륨 스냅샷 기능 유무는 확실하지 않다. 볼륨 스냅샷 서포트를 제공하는 CSI 드라이버는 csi-snapshotter를 사용할 가능성이 높다. 자세한 사항은 CSI 드라이버 문서를 확인하면 된다.
- CRDs 및 스냅샷 컨트롤러는 쿠버네티스 배포 시 설치된다.
볼륨 스냅샷 및 볼륨 스냅샷 컨텐츠의 라이프사이클
VolumeSnapshotContents 은 클러스터 리소스이다. VolumeSnapshots 은
이러한 리소스의 요청이다. VolumeSnapshotContents 과 VolumeSnapshots의 상호 작용은
다음과 같은 라이프사이클을 따른다.
프로비저닝 볼륨 스냅샷
스냅샷을 프로비저닝할 수 있는 방법에는 사전 프로비저닝 혹은 동적 프로비저닝의 두 가지가 있다: .
사전 프로비전
클러스터 관리자는 많은 VolumeSnapshotContents 을 생성한다. 그들은
클러스터 사용자들이 사용 가능한 스토리지 시스템의 실제 볼륨 스냅샷 세부 정보를 제공한다.
이것은 쿠버네티스 API에 있고 사용 가능하다.
동적
사전 프로비저닝을 사용하는 대신 퍼시스턴트볼륨클레임에서 스냅샷을 동적으로 가져오도록 요청할 수 있다. 볼륨스냅샷클래스는 스냅샷 실행 시 스토리지 제공자의 특정 파라미터를 명세한다.
바인딩
스냅샷 컨트롤러는 사전 프로비저닝과 동적 프로비저닝된 시나리오에서 VolumeSnapshot 오브젝트와 적절한
VolumeSnapshotContent 오브젝트와의 바인딩을 처리한다.
바인딩은 1:1 매핑이다.
사전 프로비저닝된 경우, 볼륨스냅샷은 요청된 볼륨스냅샷컨텐츠 오브젝트가 생성될 때까지 바인드되지 않은 상태로 유지된다.
스냅샷 소스 보호로서의 퍼시스턴트 볼륨 클레임
이 보호의 목적은 스냅샷이 생성되는 동안 사용 중인 퍼시스턴트볼륨클레임 API 오브젝트가 시스템에서 지워지지 않게 하는 것이다 (데이터 손실이 발생할 수 있기 때문에).
퍼시스턴트볼륨클레임이 스냅샷을 생성할 동안에는 해당 퍼시스턴트볼륨클레임은 사용 중인 상태이다. 스냅샷 소스로 사용 중인 퍼시스턴트볼륨클레임 API 오브젝트를 삭제한다면, 퍼시스턴트볼륨클레임 오브젝트는 즉시 삭제되지 않는다. 대신, 퍼시스턴트볼륨클레임 오브젝트 삭제는 스냅샷이 준비(readyToUse) 혹은 중단(aborted) 상태가 될 때까지 연기된다.
삭제
VolumeSnapshot 를 삭제하면 삭제 과정이 트리거되고, DeletionPolicy 가
이어서 실행된다. DeletionPolicy 가 Delete 라면, 기본 스토리지 스냅샷이
VolumeSnapshotContent 오브젝트와 함께 삭제될 것이다. DeletionPolicy 가
Retain 이라면, 기본 스트리지 스냅샷과 VolumeSnapshotContent 둘 다 유지된다.
볼륨 스냅샷
각각의 볼륨 스냅샷은 스펙과 상태를 포함한다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-test
persistentVolumeClaimName 은 스냅샷을 위한 퍼시스턴트볼륨클레임 데이터 소스의
이름이다. 이 필드는 동적 프로비저닝 스냅샷이 필요하다.
볼륨 스냅샷은 volumeSnapshotClassName 속성을 사용하여
볼륨스냅샷클래스의 이름을 지정하여
특정 클래스를 요청할 수 있다. 아무것도 설정하지 않으면, 사용 가능한 경우
기본 클래스가 사용될 것이다.
사전 프로비저닝된 스냅샷의 경우, 다음 예와 같이 volumeSnapshotContentName을
스냅샷 소스로 지정해야 한다. 사전 프로비저닝된 스냅샷에는
volumeSnapshotContentName 소스 필드가 필요하다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
spec:
source:
volumeSnapshotContentName: test-content
볼륨 스냅샷 컨텐츠
각각의 볼륨스냅샷컨텐츠는 스펙과 상태를 포함한다. 동적 프로비저닝에서는,
스냅샷 공통 컨트롤러는 VolumeSnapshotContent 오브젝트를 생성한다. 예시는 다음과 같다.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotContent
metadata:
name: snapcontent-72d9a349-aacd-42d2-a240-d775650d2455
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
volumeHandle: ee0cfb94-f8d4-11e9-b2d8-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotClassName: csi-hostpath-snapclass
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
uid: 72d9a349-aacd-42d2-a240-d775650d2455
volumeHandle 은 스토리지 백엔드에서 생성되고
볼륨 생성 중에 CSI 드라이버가 반환하는 볼륨의 고유 식별자이다. 이 필드는
스냅샷을 동적 프로비저닝하는 데 필요하다.
이것은 스냅샷의 볼륨 소스를 지정한다.
사전 프로비저닝된 스냅샷의 경우, (클러스터 관리자로서) 다음과 같이
VolumeSnapshotContent 오브젝트를 생성해야 한다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
snapshotHandle 은 스토리지 백엔드에서 생성된 볼륨 스냅샷의
고유 식별자이다. 이 필드는 사전 프로비저닝된 스냅샷에 필요하다.
VolumeSnapshotContent 가 나타내는 스토리지 시스템의 CSI 스냅샷 id를
지정한다.
sourceVolumeMode 은 스냅샷이 생성된 볼륨의 모드를 나타낸다.
sourceVolumeMode 필드의 값은 Filesystem 또는 Block 일 수 있다.
소스 볼륨 모드가 명시되어 있지 않으면,
쿠버네티스는 해당 스냅샷의 소스 볼륨 모드를 알려지지 않은 상태(unknown)로 간주하여 스냅샷을 처리한다.
volumeSnapshotRef은 상응하는 VolumeSnapshot의 참조이다.
VolumeSnapshotContent이 이전에 프로비전된 스냅샷으로 생성된 경우,
volumeSnapshotRef에서 참조하는 VolumeSnapshot은 아직 존재하지 않을 수도 있음에 주의한다.
스냅샷의 볼륨 모드 변환하기
클러스터에 설치된 VolumeSnapshots API가 sourceVolumeMode 필드를 지원한다면,
인증되지 않은 사용자가 볼륨의 모드를 변경하는 것을 금지하는 기능이
API에 있는 것이다.
클러스터가 이 기능을 지원하는지 확인하려면, 다음 명령어를 실행한다.
$ kubectl get crd volumesnapshotcontent -o yaml
사용자가 기존 VolumeSnapshot으로부터 PersistentVolumeClaim을 생성할 때
기존 소스와 다른 볼륨 모드를 지정할 수 있도록 하려면,
VolumeSnapshot와 연관된 VolumeSnapshotContent에
snapshot.storage.kubernetes.io/allowVolumeModeChange: "true" 어노테이션을 추가해야 한다.
이전에 프로비전된 스냅샷의 경우에는, 클러스터 관리자가 spec.sourceVolumeMode를
추가해야 한다.
이 기능이 활성화된 예시 VolumeSnapshotContent 리소스는 다음과 같을 것이다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
annotations:
- snapshot.storage.kubernetes.io/allowVolumeModeChange: "true"
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
스냅샷을 위한 프로비저닝 볼륨
PersistentVolumeClaim 오브젝트의 dataSource 필드를 사용하여
스냅샷 데이터로 미리 채워진 새 볼륨을 프로비저닝할 수 있다.
보다 자세한 사항은 볼륨 스냅샷 및 스냅샷에서 볼륨 복원에서 확인할 수 있다.
7.8 - 볼륨 스냅샷 클래스
이 문서는 쿠버네티스의 볼륨스냅샷클래스(VolumeSnapshotClass) 개요를 설명한다. 볼륨 스냅샷과 스토리지 클래스의 숙지를 추천한다.
소개
스토리지클래스(StorageClass)는 관리자가 볼륨을 프로비저닝할 때 제공하는 스토리지의 "클래스"를 설명하는 방법을 제공하는 것처럼, 볼륨스냅샷클래스는 볼륨 스냅샷을 프로비저닝할 때 스토리지의 "클래스"를 설명하는 방법을 제공한다.
VolumeSnapshotClass 리소스
각 볼륨스냅샷클래스에는 클래스에 속하는 볼륨스냅샷을
동적으로 프로비전 할 때 사용되는 driver, deletionPolicy 그리고 parameters
필드를 포함한다.
볼륨스냅샷클래스 오브젝트의 이름은 중요하며, 사용자가 특정 클래스를 요청할 수 있는 방법이다. 관리자는 볼륨스냅샷클래스 오브젝트를 처음 생성할 때 클래스의 이름과 기타 파라미터를 설정하고, 오브젝트가 생성된 이후에는 업데이트할 수 없다.
참고:
CRD의 설치는 쿠버네티스 배포판의 책임이다. 필요한 CRD가 존재하지 않는다면, 볼륨스냅샷클래스 생성이 실패할 것이다.apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
관리자는snapshot.storage.kubernetes.io/is-default-class: "true" 어노테이션을 추가하여
바인딩할 특정 클래스를 요청하지 않는 볼륨스냅샷에 대한
기본 볼륨스냅샷클래스를 지정할 수 있다.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
드라이버
볼륨 스냅샷 클래스에는 볼륨스냅샷의 프로비저닝에 사용되는 CSI 볼륨 플러그인을 결정하는 드라이버를 가지고 있다. 이 필드는 반드시 지정해야 한다.
삭제정책(DeletionPolicy)
볼륨 스냅샷 클래스는 삭제정책을 가지고 있다. 바인딩된 볼륨스냅샷 오브젝트를 삭제할 때 VolumeSnapshotContent의 상황을 구성할 수 있다. 볼륨 스냅샷 클래스의 삭제정책은 Retain 또는 Delete 일 수 있다. 이 필드는 반드시 지정해야 한다.
삭제정책이 Delete 인 경우 기본 스토리지 스냅샷이 VolumeSnapshotContent 오브젝트와 함께 삭제된다. 삭제정책이 Retain 인 경우 기본 스냅샷과 VolumeSnapshotContent 모두 유지된다.
파라미터
볼륨 스냅샷 클래스에는 볼륨 스냅샷 클래스에 속하는 볼륨 스냅샷을
설명하는 파라미터를 가지고 있다. driver 에 따라 다른 파라미터를 사용할
수 있다.
7.9 - CSI 볼륨 복제하기
이 문서에서는 쿠버네티스의 기존 CSI 볼륨 복제의 개념을 설명한다. 볼륨을 숙지하는 것을 추천한다.
소개
CSI 볼륨 복제 기능은 dataSource 필드에 기존 PVC를 지정하는 지원을 추가해서 사용자가 볼륨(Volume)을 복제하려는 것을 나타낸다.
복제는 표준 볼륨처럼 소비할 수 있는 쿠버네티스 볼륨의 복제본으로 정의된다. 유일한 차이점은 프로비저닝할 때 "새" 빈 볼륨을 생성하는 대신에 백엔드 장치가 지정된 볼륨의 정확한 복제본을 생성한다는 것이다.
쿠버네티스 API의 관점에서 복제를 구현하면 새로운 PVC 생성 중에 기존 PVC를 데이터 소스로 지정할 수 있는 기능이 추가된다. 소스 PVC는 바인딩되어 있고, 사용 가능해야 한다(사용 중이 아니어야 함).
사용자는 이 기능을 사용할 때 다음 사항을 알고 있어야 한다.
- 복제 지원(
VolumePVCDataSource)은 CSI 드라이버에서만 사용할 수 있다. - 복제 지원은 동적 프로비저너만 사용할 수 있다.
- CSI 드라이버는 볼륨 복제 기능을 구현했거나 구현하지 않았을 수 있다.
- PVC는 대상 PVC와 동일한 네임스페이스에 있는 경우에만 복제할 수 있다(소스와 대상은 동일한 네임스페이스에 있어야 함).
- 복제는 서로 다른 스토리지 클래스에 대해서도 지원된다.
- 대상 볼륨은 소스와 동일하거나 다른 스토리지 클래스여도 된다.
- 기본 스토리지 클래스를 사용할 수 있으며, 사양에 storageClassName을 생략할 수 있다.
- 동일한 VolumeMode 설정을 사용하는 두 볼륨에만 복제를 수행할 수 있다(블록 모드 볼륨을 요청하는 경우에는 반드시 소스도 블록 모드여야 한다).
프로비저닝
동일한 네임스페이스에서 기존 PVC를 참조하는 dataSource를 추가하는 것을 제외하고는 다른 PVC와 마찬가지로 복제가 프로비전된다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: clone-of-pvc-1
namespace: myns
spec:
accessModes:
- ReadWriteOnce
storageClassName: cloning
resources:
requests:
storage: 5Gi
dataSource:
kind: PersistentVolumeClaim
name: pvc-1
참고:
spec.resources.requests.storage 에 용량 값을 지정해야 하며, 지정한 값은 소스 볼륨의 용량과 같거나 또는 더 커야 한다.그 결과로 지정된 소스 pvc-1 과 동일한 내용을 가진 clone-of-pvc-1 이라는 이름을 가지는 새로운 PVC가 생겨난다.
사용
새 PVC를 사용할 수 있게 되면, 복제된 PVC는 다른 PVC와 동일하게 소비된다. 또한, 이 시점에서 새롭게 생성된 PVC는 독립된 오브젝트이다. 원본 dataSource PVC와는 무관하게 독립적으로 소비하고, 복제하고, 스냅샷의 생성 또는 삭제를 할 수 있다. 이는 소스가 새롭게 생성된 복제본에 어떤 방식으로든 연결되어 있지 않으며, 새롭게 생성된 복제본에 영향 없이 수정하거나, 삭제할 수도 있는 것을 의미한다.
7.10 - 스토리지 용량
스토리지 용량은 제한이 있으며, 파드가 실행되는 노드의 상황에 따라 달라질 수 있다. 예를 들어, 일부 노드에서 NAS(Network Attached Storage)에 접근할 수 없는 경우가 있을 수 있으며, 또는 각 노드에 종속적인 로컬 스토리지를 사용하는 경우일 수도 있다.
기능 상태:
Kubernetes v1.24 [stable]
이 페이지에서는 쿠버네티스가 어떻게 스토리지 용량을 추적하고 스케줄러가 남아 있는 볼륨을 제공하기 위해 스토리지 용량이 충분한 노드에 파드를 스케줄링하기 위해 이 정보를 어떻게 사용하는지 설명한다. 스토리지 용량을 추적하지 않으면, 스케줄러는 볼륨을 제공할 충분한 용량이 없는 노드를 선정할 수 있으며, 스케줄링을 여러 번 다시 시도해야 한다.
시작하기 전에
쿠버네티스 v1.31 버전은 스토리지 용량 추적을 위한 클러스터-수준 API를 지원한다. 이를 사용하려면, 스토리지 용량 추적을 지원하는 CSI 드라이버를 사용하고 있어야 한다. 사용 중인 CSI 드라이버가 이를 지원하는지, 지원한다면 어떻게 사용하는지를 알아보려면 해당 CSI 드라이버의 문서를 참고한다. 쿠버네티스 v1.31 버전을 사용하고 있지 않다면, 해당 버전 쿠버네티스 문서를 참고한다.
API
이 기능에는 다음 두 가지 API 확장이 있다.
- CSIStorageCapacity 오브젝트: CSI 드라이버가 설치된 네임스페이스에 CSI 드라이버가 이 오브젝트를 생성한다. 각 오브젝트는 하나의 스토리지 클래스에 대한 용량 정보를 담고 있으며, 어떤 노드가 해당 스토리지에 접근할 수 있는지를 정의한다.
CSIDriverSpec.StorageCapacity필드:true로 설정하면, 쿠버네티스 스케줄러가 CSI 드라이버를 사용하는 볼륨의 스토리지 용량을 고려하게 된다.
스케줄링
다음과 같은 경우 쿠버네티스 스케줄러에서 스토리지 용량 정보를 사용한다.
- 파드가 아직 생성되지 않은 볼륨을 사용하고,
- 해당 볼륨은 CSI 드라이버를 참조하고
WaitForFirstConsumer볼륨 바인딩 모드를 사용하는 스토리지클래스(StorageClass)를 사용하고, - 드라이버의
CSIDriver오브젝트에StorageCapacity속성이 true로 설정되어 있다.
이 경우 스케줄러는 파드에 제공할
충분한 스토리지가 있는 노드만 고려한다.
이 검사는 아주 간단한데,
볼륨의 크기를 노드를 포함하는 토폴로지를 가진 CSIStorageCapacity 오브젝트에
나열된 용량과 비교한다.
볼륨 바인딩 모드가 Immediate 인 볼륨의 경우에는 스토리지 드라이버는
볼륨을 사용하는 파드와 관계없이 볼륨을 생성할 위치를 정한다.
볼륨을 생성한 후에, 스케줄러는
볼륨을 사용할 수 있는 노드에 파드를 스케줄링한다.
CSI 임시 볼륨의 경우에는 볼륨 유형이 로컬 볼륨이고 큰 자원이 필요하지 않은 특정 CSI 드라이버에서만 사용된다는 가정하에, 항상 스토리지 용량을 고려하지 않고 스케줄링한다.
리스케줄링
WaitForFirstConsumer 볼륨을 가진 파드에 대해
노드가 선정되었더라도 아직은 잠정적인 결정이다. 다음 단계에서
선정한 노드에서 볼륨을 사용할 수 있어야 한다는 힌트를 주고
CSI 스토리지 드라이버에 볼륨 생성을 요청한다
쿠버네티스는 시간이 지난 스토리지 용량 정보를 기반으로 노드를 선정할 수도 있으므로, 볼륨을 실제로 생성하지 않을 수도 있다. 그런 다음 노드 선정이 재설정되고 쿠버네티스 스케줄러가 파드를 위한 노드를 찾는 것을 재시도한다.
제한사항
스토리지 용량 추적은 첫 시도에 스케줄링이 성공할 가능성을 높이지만, 스케줄러가 시간이 지난 정보를 기반으로 결정해야 할 수도 있기 때문에 이를 보장하지는 않는다. 일반적으로 스토리지 용량 정보가 없는 스케줄링과 동일한 재시도 메커니즘으로 스케줄링 실패를 처리한다.
스케줄링이 영구적으로 실패할 수 있는 한 가지 상황은 파드가 여러 볼륨을 사용하는 경우이다. 토폴로지 세그먼트에 하나의 볼륨이 이미 생성되어 다른 볼륨에 충분한 용량이 남아 있지 않을 수 있다. 이러한 상황을 복구하려면 용량을 늘리거나 이미 생성된 볼륨을 삭제하는 등의 수작업이 필요하다.
다음 내용
- 설계에 대한 자세한 내용은 파드 스케줄링 스토리지 용량 제약 조건을 참조한다.
7.11 - 노드 별 볼륨 한도
이 페이지는 다양한 클라우드 공급자들이 제공하는 노드에 연결할 수 있는 최대 볼륨 수를 설명한다.
Google, Amazon 그리고 Microsoft와 같은 클라우드 공급자는 일반적으로 노드에 연결할 수 있는 볼륨 수에 제한이 있다. 쿠버네티스가 이러한 제한을 준수하는 것은 중요하다. 그렇지 않으면, 노드에서 예약된 파드가 볼륨이 연결될 때까지 멈추고 기다릴 수 있다.
쿠버네티스 기본 한도
쿠버네티스 스케줄러에는 노드에 연결될 수 있는 볼륨 수에 대한 기본 한도가 있다.
| 클라우드 서비스 | 노드 당 최대 볼륨 |
|---|---|
| Amazon Elastic Block Store (EBS) | 39 |
| Google Persistent Disk | 16 |
| Microsoft Azure Disk Storage | 16 |
사용자 정의 한도
KUBE_MAX_PD_VOLS 환경 변수의 값을 설정한 후,
스케줄러를 시작하여 이러한 한도를 변경할 수 있다.
CSI 드라이버는 절차가 다를 수 있으므로, 한도를 사용자 정의하는
방법에 대한 문서를 참고한다.
기본 한도보다 높은 한도를 설정한 경우 주의한다. 클라우드 공급자의 문서를 참조하여 노드가 실제로 사용자가 설정한 한도를 지원할 수 있는지 확인한다.
한도는 전체 클러스터에 적용되므로, 모든 노드에 영향을 준다.
동적 볼륨 한도
기능 상태:
Kubernetes v1.17 [stable]
다음 볼륨 유형에 대해 동적 볼륨 한도가 지원된다.
- Amazon EBS
- Google Persistent Disk
- Azure Disk
- CSI
인-트리(in-tree) 볼륨 플러그인으로 관리되는 볼륨의 경우, 쿠버네티스는 자동으로 노드 유형을 결정하고 노드에 적절한 최대 볼륨 수를 적용한다. 예를 들면, 다음과 같다.
-
Google Compute Engine에서는, 노드 유형에 따라 최대 127개의 볼륨까지 노드에 연결할 수 있다.
-
M5, C5, R5, T3와 Z1D 인스턴스 유형의 Amazon EBS 디스크의 경우, 쿠버네티스는 25개의 볼륨만 노드에 연결할 수 있도록 허용한다. Amazon Elastic Compute Cloud (EC2)의 다른 인스턴스 유형의 경우, 쿠버네티스는 노드에 39개의 볼륨을 연결할 수 있도록 허용한다.
-
Azure에서는, 노드 유형에 따라 최대 64개의 디스크를 노드에 연결할 수 있다. 더 자세한 내용은 Azure의 가상 머신 크기를 참고한다.
-
CSI 스토리지 드라이버가
NodeGetInfo를 사용해서 노드에 대한 최대 볼륨 수를 알린다면, kube-scheduler는 그 한도를 따른다.
자세한 내용은 CSI 명세를 참고한다.
- CSI 드라이버로 마이그레이션된 인-트리 플러그인으로 관리되는 볼륨의 경우, 최대 볼륨 수는 CSI 드라이버가 보고한 개수이다.
7.12 - 볼륨 헬스 모니터링
기능 상태:
Kubernetes v1.21 [alpha]
CSI 볼륨 헬스 모니터링을 통해 CSI 드라이버는 기본 스토리지 시스템에서 비정상적인 볼륨 상태를 감지하고 이를 PVC 또는 파드의 이벤트로 보고한다.
볼륨 헬스 모니터링
쿠버네티스 볼륨 헬스 모니터링 은 쿠버네티스가 CSI(Container Storage Interface)를 구현하는 방법의 일부다. 볼륨 헬스 모니터링 기능은 외부 헬스 모니터 컨트롤러와 kubelet, 2가지 컴포넌트로 구현된다.
CSI 드라이버가 컨트롤러 측의 볼륨 헬스 모니터링 기능을 지원하는 경우, CSI 볼륨에서 비정상적인 볼륨 상태가 감지될 때 관련 퍼시스턴트볼륨클레임(PersistentVolumeClaim, PVC) 이벤트가 보고된다.
외부 헬스 모니터 컨트롤러는 노드 장애 이벤트도 감시한다. enable-node-watcher 플래그를 true로 설정하여 노드 장애 모니터링을 활성화할 수 있다. 외부 헬스 모니터가 노드 장애 이벤트를 감지하면, 컨트롤러는 이 PVC를 사용하는 파드가 장애 상태인 노드에 있음을 나타내는 이벤트가 PVC에 보고된다고 알린다.
CSI 드라이버가 노드 측에서 볼륨 헬스 모니터링 기능을 지원하는 경우, CSI 볼륨에서 비정상적인 볼륨 상태가 감지되면 PVC를 사용하는 모든 파드에서 이벤트가 보고된다. 그리고, 볼륨 헬스 정보는 kubelet VolumeStats 메트릭 형태로 노출된다. 새로운 kubelet_volume_stats_health_status_abnormal 메트릭이 추가되었다. 이 메트릭은 namespace 및 persistentvolumeclaim 2개의 레이블을 포함한다. 카운터는 1 또는 0이다. 카운터가 1이면 볼륨이 정상적이지 않음을, 0이면 정상적임을 의미한다. 더 많은 정보는 KEP를 참고한다.
다음 내용
이 기능을 구현한 CSI 드라이버를 확인하려면 CSI 드라이버 문서를 참고한다.
7.13 - 윈도우 스토리지
이 페이지는 윈도우 운영 체제에서의 스토리지 개요를 제공한다.
퍼시스턴트 스토리지
윈도우는 계층 구조의 파일시스템 드라이버를 사용하여 컨테이너 레이어를 마운트하고 NTFS 기반 파일시스템의 복제본을 생성한다. 컨테이너 내의 모든 파일 경로는 해당 컨테이너 컨텍스트 내에서만 인식 가능하다.
- 도커를 사용할 때, 볼륨 마운트는 컨테이너 내의 디렉토리로만 지정할 수 있으며, 개별 파일로는 지정할 수 없다. 이 제약 사항은 containerd에는 적용되지 않는다.
- 볼륨 마운트는 파일 또는 디렉토리를 호스트 파일시스템으로 투영(project)할 수 없다.
- 윈도우 레지스트리와 SAM 데이터케이스에 쓰기 권한이 항상 필요하기 때문에, 읽기 전용 파일시스템은 지원되지 않는다. 다만, 읽기 전용 볼륨은 지원된다.
- 볼륨 사용자-마스크 및 퍼미션은 사용할 수 있다. 호스트와 컨테이너 간에 SAM이 공유되지 않기 때문에, 둘 간의 매핑이 존재하지 않는다. 모든 퍼미션은 해당 컨테이너 컨텍스트 내에서만 처리된다.
결과적으로, 윈도우 노드에서는 다음 스토리지 기능이 지원되지 않는다.
- 볼륨 서브패스(subpath) 마운트: 윈도우 컨테이너에는 전체 볼륨만 마운트할 수 있다.
- 시크릿을 위한 서브패스 볼륨 마운팅
- 호스트 마운트 투영(projection)
- 읽기 전용 루트 파일시스템 (매핑된 볼륨은 여전히
readOnly를 지원한다) - 블록 디바이스 매핑
- 메모리를 스토리지 미디어로 사용하기 (예를 들어,
emptyDir.medium를Memory로 설정하는 경우) - uid/gid, 사용자 별 리눅스 파일시스템 권한과 같은 파일시스템 기능
- DefaultMode을 이용하여 시크릿 퍼미션 설정하기 (UID/GID 의존성 때문에)
- NFS 기반 스토리지/볼륨 지원
- 마운트된 볼륨 확장하기 (resizefs)
쿠버네티스 볼륨을 사용하여 데이터 지속성(persistence) 및 파드 볼륨 공유 요구 사항이 있는 복잡한 애플리케이션을 쿠버네티스에 배포할 수 있다. 특정 스토리지 백엔드 또는 프로토콜과 연관된 퍼시스턴트 볼륨의 관리는 볼륨 프로비저닝/디프로비저닝/리사이징, 쿠버네티스 노드로의 볼륨 연결(attaching) 및 해제(detaching), 데이터를 보존해야 하는 파드 내 개별 컨테이너로의 볼륨 마운트 및 해제 같은 동작을 포함한다.
볼륨 관리 구성 요소는 쿠버네티스 볼륨 플러그인 형태로 제공된다. 윈도우는 다음의 광역 쿠버네티스 볼륨 플러그인 클래스를 지원한다.
FlexVolume플러그인- FlexVolume은 1.23부터 사용 중단되었음에 유의한다.
CSI플러그인
인-트리(In-tree) 볼륨 플러그인
다음의 인-트리 플러그인은 윈도우 노드에서의 퍼시스턴트 스토리지를 지원한다.
8 - 구성
쿠버네티스가 파드 구성을 위해 제공하는 리소스
8.1 - 구성 모범 사례
이 문서는 사용자 가이드, 시작하기 문서 및 예제들에 걸쳐 소개된 구성 모범 사례를 강조하고 통합한다.
이 문서는 지속적으로 변경 가능하다. 이 목록에 없지만 다른 사람들에게 유용할 것 같은 무엇인가를 생각하고 있다면, 새로운 이슈를 생성하거나 풀 리퀘스트를 제출하는 것을 망설이지 말기를 바란다.
일반적인 구성 팁
-
구성을 정의할 때, 안정된 최신 API 버전을 명시한다.
-
구성 파일들은 클러스터에 적용되기 전에 버전 컨트롤에 저장되어 있어야 한다. 이는 만약 필요하다면 구성의 변경 사항을 빠르게 되돌릴 수 있도록 해준다. 이는 또한 클러스터의 재-생성과 복원을 도와준다.
-
JSON보다는 YAML을 사용해 구성 파일을 작성한다. 비록 이러한 포맷들은 대부분의 모든 상황에서 통용되어 사용될 수 있지만, YAML이 좀 더 사용자 친화적인 성향을 가진다.
-
의미상 맞다면 가능한 연관된 오브젝트들을 하나의 파일에 모아 놓는다. 때로는 여러 개의 파일보다 하나의 파일이 더 관리하기 쉽다. 이 문법의 예시로서 guestbook-all-in-one.yaml 파일을 참고한다.
-
많은
kubectl커맨드들은 디렉터리에 대해 호출될 수 있다. 예를 들어, 구성 파일들의 디렉터리에 대해kubectl apply를 호출할 수 있다. -
불필요하게 기본 값을 명시하지 않는다. 간단하고 최소한의 설정은 에러를 덜 발생시킨다.
-
더 나은 인트로스펙션(introspection)을 위해서, 어노테이션에 오브젝트의 설명을 넣는다.
"단독(Naked)" 파드 vs 레플리카셋(ReplicaSet), 디플로이먼트(Deployment), 그리고 잡(Job)
-
가능하다면 단독 파드(즉, 레플리카셋이나 디플로이먼트에 연결되지 않은 파드)를 사용하지 않는다. 단독 파드는 노드 장애 이벤트가 발생해도 다시 스케줄링되지 않는다.
명시적으로
restartPolicy: Never를 사용하는 상황을 제외한다면, 의도한 파드의 수가 항상 사용 가능한 상태를 유지하는 레플리카셋을 생성하고, (롤링 업데이트와 같이) 파드를 교체하는 전략을 명시하는 디플로이먼트는 파드를 직접 생성하기 위해 항상 선호되는 방법이다. 잡 또한 적절할 수 있다.
서비스
-
서비스에 대응하는 백엔드 워크로드(디플로이먼트 또는 레플리카셋) 또는 서비스 접근이 필요한 어떠한 워크로드를 생성하기 전에 서비스를 미리 생성한다. 쿠버네티스가 컨테이너를 시작할 때, 쿠버네티스는 컨테이너 시작 당시에 생성되어 있는 모든 서비스를 가리키는 환경 변수를 컨테이너에 제공한다. 예를 들어,
foo라는 이름의 서비스가 존재한다면, 모든 컨테이너들은 초기 환경에서 다음의 변수들을 얻을 것이다.FOO_SERVICE_HOST=<서비스가 동작 중인 호스트> FOO_SERVICE_PORT=<서비스가 동작 중인 포트>이는 순서를 정하는 일이 요구됨을 암시한다 -
파드가 접근하기를 원하는 어떠한서비스는파드스스로가 생성되기 전에 미리 생성되어 있어야 하며, 그렇지 않으면 환경 변수가 설정되지 않을 것이다. DNS는 이러한 제한을 가지고 있지 않다. -
선택적인(그렇지만 매우 권장되는) 클러스터 애드온은 DNS 서버이다. DNS 서버는 새로운
서비스를 위한 쿠버네티스 API를 Watch하며, 각 서비스를 위한 DNS 레코드 셋을 생성한다. 만약 DNS가 클러스터에 걸쳐 활성화되어 있다면, 모든파드는서비스의 이름을 자동으로 해석할 수 있어야 한다. -
반드시 필요한 것이 아니라면 파드에
hostPort를 명시하지 않는다. <hostIP,hostPort,protocol> 조합은 유일해야 하기 때문에,hostPort로 바인드하는 것은 파드가 스케줄링될 수 있는 위치의 개수를 제한한다. 만약hostIP와protocol을 뚜렷히 명시하지 않으면, 쿠버네티스는hostIP의 기본 값으로0.0.0.0를,protocol의 기본 값으로TCP를 사용한다.만약 오직 디버깅의 목적으로 포트에 접근해야 한다면, apiserver proxy 또는
kubectl port-forward를 사용할 수 있다.만약 파드의 포트를 노드에서 명시적으로 노출해야 한다면,
hostPort에 의존하기 전에 NodePort 서비스를 사용하는 것을 고려할 수 있다. -
hostPort와 같은 이유로,hostNetwork를 사용하는 것을 피한다. -
kube-proxy로드 밸런싱이 필요하지 않을 때, 서비스 발견을 위해 헤드리스 서비스(ClusterIP의 값을None으로 가지는)를 사용한다.
레이블 사용하기
{ app.kubernetes.io/name: MyApp, tier: frontend, phase: test, deployment: v3 }처럼 애플리케이션이나 디플로이먼트의 속성에 대한 의미 를 식별하는 레이블을 정의해 사용한다. 다른 리소스를 위해 적절한 파드를 선택하는 용도로 이러한 레이블을 이용할 수 있다. 예를 들어, 모든tier: frontend파드를 선택하거나,app.kubernetes.io/name: MyApp의 모든phase: test컴포넌트를 선택하는 서비스를 생각해 볼 수 있다. 이 접근 방법의 예시는 방명록 앱을 참고한다.
릴리스에 특정되는 레이블을 서비스의 셀렉터에서 생략함으로써 여러 개의 디플로이먼트에 걸치는 서비스를 생성할 수 있다. 동작 중인 서비스를 다운타임 없이 갱신하려면, 디플로이먼트를 사용한다.
오브젝트의 의도한 상태는 디플로이먼트에 의해 기술되며, 만약 그 스펙에 대한 변화가 적용될 경우, 디플로이먼트 컨트롤러는 일정한 비율로 실제 상태를 의도한 상태로 변화시킨다.
-
일반적인 활용 사례인 경우 쿠버네티스 공통 레이블을 사용한다. 이 표준화된 레이블은
kubectl및 대시보드와 같은 도구들이 상호 운용이 가능한 방식으로 동작할 수 있도록 메타데이터를 향상시킨다. -
디버깅을 위해 레이블을 조작할 수 있다. (레플리카셋과 같은) 쿠버네티스 컨트롤러와 서비스는 셀렉터 레이블을 사용해 파드를 선택하기 때문에, 관련된 레이블을 파드에서 삭제하는 것은 컨트롤러로부터 관리되거나 서비스로부터 트래픽을 전달받는 것을 중단시킨다. 만약 이미 존재하는 파드의 레이블을 삭제한다면, 파드의 컨트롤러는 그 자리를 대신할 새로운 파드를 생성한다. 이것은 이전에 "살아 있는" 파드를 "격리된" 환경에서 디버그할 수 있는 유용한 방법이다. 레이블을 상호적으로 추가하고 삭제하기 위해서,
kubectl label를 사용할 수 있다.
kubectl 사용하기
-
kubectl apply -f <디렉터리>를 사용한다. 이 명령어는<디렉터리>내부의 모든.yaml,.yml, 그리고.json쿠버네티스 구성 파일을 찾아apply에 전달한다. -
get과delete동작을 위해 특정 오브젝트의 이름 대신 레이블 셀렉터를 사용한다. 레이블 셀렉터와 효율적으로 레이블 사용하기를 참고할 수 있다. -
단일 컨테이너로 구성된 디플로이먼트와 서비스를 빠르게 생성하기 위해
kubectl create deployment와kubectl expose를 사용한다. 클러스터 내부의 애플리케이션에 접근하기 위한 서비스 사용에서 예시를 확인할 수 있다.
8.2 - 컨피그맵(ConfigMap)
컨피그맵은 키-값 쌍으로 기밀이 아닌 데이터를 저장하는 데 사용하는 API 오브젝트이다. 파드는 볼륨에서 환경 변수, 커맨드-라인 인수 또는 구성 파일로 컨피그맵을 사용할 수 있다.
컨피그맵을 사용하면 컨테이너 이미지에서 환경별 구성을 분리하여, 애플리케이션을 쉽게 이식할 수 있다.
주의:
컨피그맵은 보안 또는 암호화를 제공하지 않는다. 저장하려는 데이터가 기밀인 경우, 컨피그맵 대신 시크릿(Secret) 또는 추가(써드파티) 도구를 사용하여 데이터를 비공개로 유지하자.사용 동기
애플리케이션 코드와 별도로 구성 데이터를 설정하려면 컨피그맵을 사용하자.
예를 들어, 자신의 컴퓨터(개발용)와 클라우드(실제 트래픽 처리)에서
실행할 수 있는 애플리케이션을 개발한다고 가정해보자.
DATABASE_HOST 라는 환경 변수를 찾기 위해 코드를 작성한다.
로컬에서는 해당 변수를 localhost 로 설정한다. 클라우드에서는, 데이터베이스
컴포넌트를 클러스터에 노출하는 쿠버네티스 서비스를
참조하도록 설정한다.
이를 통해 클라우드에서 실행 중인 컨테이너 이미지를 가져와
필요한 경우 정확히 동일한 코드를 로컬에서 디버깅할 수 있다.
컨피그맵은 많은 양의 데이터를 보유하도록 설계되지 않았다. 컨피그맵에 저장된 데이터는 1MiB를 초과할 수 없다. 이 제한보다 큰 설정을 저장해야 하는 경우, 볼륨을 마운트하는 것을 고려하거나 별도의 데이터베이스 또는 파일 서비스를 사용할 수 있다.
컨피그맵 오브젝트
컨피그맵은 다른 오브젝트가 사용할 구성을 저장할 수 있는
API 오브젝트이다.
spec 이 있는 대부분의 쿠버네티스 오브젝트와 달리, 컨피그맵에는 data 및 binaryData
필드가 있다. 이러한 필드는 키-값 쌍을 값으로 허용한다. data 필드와
binaryData 는 모두 선택 사항이다. data 필드는
UTF-8 문자열을 포함하도록 설계되었으며 binaryData 필드는 바이너리
데이터를 base64로 인코딩된 문자열로 포함하도록 설계되었다.
컨피그맵의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
data 또는 binaryData 필드 아래의 각 키는
영숫자 문자, -, _ 또는 . 으로 구성되어야 한다. data 에 저장된 키는
binaryData 필드의 키와 겹치지 않아야 한다.
v1.19부터 컨피그맵 정의에 immutable 필드를 추가하여
변경할 수 없는 컨피그맵을 만들 수 있다.
컨피그맵과 파드
컨피그맵을 참조하는 파드 spec 을 작성하고 컨피그맵의 데이터를
기반으로 해당 파드의 컨테이너를 구성할 수 있다. 파드와 컨피그맵은
동일한 네임스페이스에 있어야 한다.
다음은 단일 값을 가진 키와, 값이 구성 형식의 일부처럼 보이는 키를 가진 컨피그맵의 예시이다.
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 속성과 비슷한 키; 각 키는 간단한 값으로 매핑됨
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# 파일과 비슷한 키
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
컨피그맵을 사용하여 파드 내부에 컨테이너를 구성할 수 있는 네 가지 방법이 있다.
- 컨테이너 커맨드와 인수 내에서
- 컨테이너에 대한 환경 변수
- 애플리케이션이 읽을 수 있도록 읽기 전용 볼륨에 파일 추가
- 쿠버네티스 API를 사용하여 컨피그맵을 읽는 파드 내에서 실행할 코드 작성
이러한 방법들은 소비되는 데이터를 모델링하는 방식에 따라 다르게 쓰인다. 처음 세 가지 방법의 경우, kubelet은 파드의 컨테이너를 시작할 때 컨피그맵의 데이터를 사용한다.
네 번째 방법은 컨피그맵과 데이터를 읽기 위해 코드를 작성해야 한다는 것을 의미한다. 그러나, 쿠버네티스 API를 직접 사용하기 때문에, 애플리케이션은 컨피그맵이 변경될 때마다 업데이트를 받기 위해 구독할 수 있고, 업데이트가 있으면 반응한다. 쿠버네티스 API에 직접 접근하면, 이 기술을 사용하여 다른 네임스페이스의 컨피그맵에 접근할 수도 있다.
다음은 game-demo 의 값을 사용하여 파드를 구성하는 파드 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# 환경 변수 정의
- name: PLAYER_INITIAL_LIVES # 참고로 여기서는 컨피그맵의 키 이름과
# 대소문자가 다르다.
valueFrom:
configMapKeyRef:
name: game-demo # 이 값의 컨피그맵.
key: player_initial_lives # 가져올 키.
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# 파드 레벨에서 볼륨을 설정한 다음, 해당 파드 내의 컨테이너에 마운트한다.
- name: config
configMap:
# 마운트하려는 컨피그맵의 이름을 제공한다.
name: game-demo
# 컨피그맵에서 파일로 생성할 키 배열
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"
컨피그맵은 단일 라인 속성(single line property) 값과 멀티 라인의 파일과 비슷한(multi-line file-like) 값을 구분하지 않는다. 더 중요한 것은 파드와 다른 오브젝트가 이러한 값을 소비하는 방식이다.
이 예제에서, 볼륨을 정의하고 demo 컨테이너에
/config 로 마운트하면 컨피그맵에 4개의 키가 있더라도
/config/game.properties 와 /config/user-interface.properties
2개의 파일이 생성된다. 이것은 파드 정의가
volume 섹션에서 items 배열을 지정하기 때문이다.
items 배열을 완전히 생략하면, 컨피그맵의 모든 키가
키와 이름이 같은 파일이 되고, 4개의 파일을 얻게 된다.
컨피그맵 사용하기
컨피그맵은 데이터 볼륨으로 마운트할 수 있다. 컨피그맵은 파드에 직접적으로 노출되지 않고, 시스템의 다른 부분에서도 사용할 수 있다. 예를 들어, 컨피그맵은 시스템의 다른 부분이 구성을 위해 사용해야 하는 데이터를 보유할 수 있다.
컨피그맵을 사용하는 가장 일반적인 방법은 동일한 네임스페이스의 파드에서 실행되는 컨테이너에 대한 설정을 구성하는 것이다. 컨피그맵을 별도로 사용할 수도 있다.
예를 들어, 컨피그맵에 기반한 동작을 조정하는 애드온이나 오퍼레이터를 사용할 수도 있다.
파드에서 컨피그맵을 파일로 사용하기
파드의 볼륨에서 컨피그맵을 사용하려면 다음을 수행한다.
- 컨피그맵을 생성하거나 기존 컨피그맵을 사용한다. 여러 파드가 동일한 컨피그맵을 참조할 수 있다.
- 파드 정의를 수정해서
.spec.volumes[]아래에 볼륨을 추가한다. 볼륨 이름은 원하는 대로 정하고, 컨피그맵 오브젝트를 참조하도록.spec.volumes[].configMap.name필드를 설정한다. - 컨피그맵이 필요한 각 컨테이너에
.spec.containers[].volumeMounts[]를 추가한다..spec.containers[].volumeMounts[].readOnly = true를 설정하고 컨피그맵이 연결되기를 원하는 곳에 사용하지 않은 디렉터리 이름으로.spec.containers[].volumeMounts[].mountPath를 지정한다. - 프로그램이 해당 디렉터리에서 파일을 찾도록 이미지 또는 커맨드 라인을
수정한다. 컨피그맵의
data맵 각 키는mountPath아래의 파일 이름이 된다.
다음은 볼륨에 컨피그맵을 마운트하는 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
configmap:
name: myconfigmap
사용하려는 각 컨피그맵은 .spec.volumes 에서 참조해야 한다.
파드에 여러 컨테이너가 있는 경우 각 컨테이너에는 자체 volumeMounts 블록이 필요하지만,
컨피그맵은 각 컨피그맵 당 하나의 .spec.volumes 만 필요하다.
마운트된 컨피그맵이 자동으로 업데이트
현재 볼륨에서 사용된 컨피그맵이 업데이트되면, 프로젝션된 키도 마찬가지로 업데이트된다.
kubelet은 모든 주기적인 동기화에서 마운트된 컨피그맵이 최신 상태인지 확인한다.
그러나, kubelet은 로컬 캐시를 사용해서 컨피그맵의 현재 값을 가져온다.
캐시 유형은 KubeletConfiguration 구조체의
ConfigMapAndSecretChangeDetectionStrategy 필드를 사용해서 구성할 수 있다.
컨피그맵은 watch(기본값), ttl 기반 또는 API 서버로 직접
모든 요청을 리디렉션할 수 있다.
따라서 컨피그맵이 업데이트되는 순간부터 새 키가 파드에 업데이트되는 순간까지의
총 지연시간은 kubelet 동기화 기간 + 캐시 전파 지연만큼 길 수 있다. 여기서 캐시
전파 지연은 선택한 캐시 유형에 따라 달라질 수 있다(전파
지연을 지켜보거나, 캐시의 ttl 또는 0에 상응함).
환경 변수로 사용되는 컨피그맵은 자동으로 업데이트되지 않으며 파드를 다시 시작해야 한다.
참고:
컨피그맵을 subPath 볼륨 마운트로 사용하는 컨테이너는 컨피그맵 업데이트를 받지 못할 것이다.변경할 수 없는(immutable) 컨피그맵
기능 상태:
Kubernetes v1.21 [stable]
쿠버네티스 기능인 변경할 수 없는 시크릿과 컨피그맵 은 개별 시크릿과 컨피그맵을 변경할 수 없는 것으로 설정하는 옵션을 제공한다. 컨피그맵을 광범위하게 사용하는 클러스터(최소 수만 개의 고유한 컨피그맵이 파드에 마운트)의 경우 데이터 변경을 방지하면 다음과 같은 이점이 있다.
- 애플리케이션 중단을 일으킬 수 있는 우발적(또는 원하지 않는) 업데이트로부터 보호
- immutable로 표시된 컨피그맵에 대한 감시를 중단하여, kube-apiserver의 부하를 크게 줄임으로써 클러스터의 성능을 향상시킴
이 기능은 ImmutableEphemeralVolumes
기능 게이트에 의해 제어된다.
immutable 필드를 true 로 설정하여 변경할 수 없는 컨피그맵을 생성할 수 있다.
다음은 예시이다.
apiVersion: v1
kind: ConfigMap
metadata:
...
data:
...
immutable: true
컨피그맵을 immutable로 표시하면, 이 변경 사항을 되돌리거나
data 또는 binaryData 필드 내용을 변경할 수 없다. 컨피그맵만
삭제하고 다시 작성할 수 있다. 기존 파드는 삭제된 컨피그맵에 대한 마운트 지점을
유지하므로, 이러한 파드를 다시 작성하는 것을 권장한다.
다음 내용
- 시크릿에 대해 읽어본다.
- 컨피그맵을 사용하도록 파드 구성하기를 읽어본다.
- 컨피그맵 (또는 어떠한 쿠버네티스 오브젝트) 변경하기를 읽어본다.
- 코드를 구성에서 분리하려는 동기를 이해하려면 Twelve-Factor 앱을 읽어본다.
8.3 - 시크릿(Secret)
시크릿은 암호, 토큰 또는 키와 같은 소량의 중요한 데이터를 포함하는 오브젝트이다. 이를 사용하지 않으면 중요한 정보가 파드 명세나 컨테이너 이미지에 포함될 수 있다. 시크릿을 사용한다는 것은 사용자의 기밀 데이터를 애플리케이션 코드에 넣을 필요가 없음을 뜻한다.
시크릿은 시크릿을 사용하는 파드와 독립적으로 생성될 수 있기 때문에, 파드를 생성하고, 확인하고, 수정하는 워크플로우 동안 시크릿(그리고 데이터)이 노출되는 것에 대한 위험을 경감시킬 수 있다. 쿠버네티스 및 클러스터에서 실행되는 애플리케이션은 비밀 데이터를 비휘발성 저장소에 쓰는 것을 피하는 것과 같이, 시크릿에 대해 추가 예방 조치를 취할 수도 있다.
시크릿은 컨피그맵과 유사하지만 특별히 기밀 데이터를 보관하기 위한 것이다.
주의:
쿠버네티스 시크릿은 기본적으로 API 서버의 기본 데이터 저장소(etcd)에 암호화되지 않은 상태로 저장된다. API 접근(access) 권한이 있는 모든 사용자 또는 etcd에 접근할 수 있는 모든 사용자는 시크릿을 조회하거나 수정할 수 있다. 또한 네임스페이스에서 파드를 생성할 권한이 있는 사람은 누구나 해당 접근을 사용하여 해당 네임스페이스의 모든 시크릿을 읽을 수 있다. 여기에는 디플로이먼트 생성 기능과 같은 간접 접근이 포함된다.
시크릿을 안전하게 사용하려면 최소한 다음의 단계를 따르는 것이 좋다.
- 시크릿에 대해 저장된 데이터 암호화(Encryption at Rest)를 활성화한다.
- 시크릿에 대한 최소한의 접근 권한을 지니도록 RBAC 규칙을 활성화 또는 구성한다.
- 특정 컨테이너에서만 시크릿에 접근하도록 한다.
- 외부 시크릿 저장소 제공 서비스를 사용하는 것을 고려한다.
시크릿의 보안성을 높이고 관리하는 데에 관한 가이드라인은 쿠버네티스 시크릿에 관한 좋은 관행를 참고한다.
더 자세한 것은 시크릿을 위한 정보 보안(Information security)을 참고한다.
시크릿의 사용
파드가 시크릿을 사용하는 주요한 방법으로 다음의 세 가지가 있다.
- 하나 이상의 컨테이너에 마운트된 볼륨 내의 파일로써 사용.
- 컨테이너 환경 변수로써 사용.
- 파드의 이미지를 가져올 때 kubelet에 의해 사용.
쿠버네티스 컨트롤 플레인 또한 시크릿을 사용한다. 예를 들어, 부트스트랩 토큰 시크릿은 노드 등록을 자동화하는 데 도움을 주는 메커니즘이다.
시크릿의 대체품
기밀 데이터를 보호하기 위해 시크릿 대신 다음의 대안 중 하나를 고를 수 있다.
다음과 같은 대안이 존재한다.
- 클라우드 네이티브 구성 요소가 동일 쿠버네티스 클러스터 안에 있는 다른 애플리케이션에 인증해야 하는 경우, 서비스어카운트(ServiceAccount) 및 그의 토큰을 이용하여 클라이언트를 식별할 수 있다.
- 비밀 정보 관리 기능을 제공하는 써드파티 도구를 클러스터 내부 또는 외부에 실행할 수 있다. 예를 들어, 클라이언트가 올바르게 인증했을 때에만(예: 서비스어카운트 토큰으로 인증) 비밀 정보를 공개하고, 파드가 HTTPS를 통해서만 접근하도록 처리하는 서비스가 있을 수 있다.
- 인증을 위해, X.509 인증서를 위한 커스텀 인증자(signer)를 구현하고, CertificateSigningRequests를 사용하여 해당 커스텀 인증자가 인증서를 필요로 하는 파드에 인증서를 발급하도록 할 수 있다.
- 장치 플러그인을 사용하여 노드에 있는 암호화 하드웨어를 특정 파드에 노출할 수 있다. 예를 들어, 신뢰할 수 있는 파드를 별도로 구성된 TPM(Trusted Platform Module, 신뢰할 수 있는 플랫폼 모듈)을 제공하는 노드에 스케줄링할 수 있다.
위의 옵션들 및 시크릿 오브젝트 자체를 이용하는 옵션 중 2가지 이상을 조합하여 사용할 수도 있다.
예시: 외부 서비스에서 단기 유효(short-lived) 세션 토큰을 가져오는 오퍼레이터를 구현(또는 배포)한 다음, 이 단기 유효 세션 토큰을 기반으로 시크릿을 생성할 수 있다. 클러스터의 파드는 이 세션 토큰을 활용할 수 있으며, 오퍼레이터는 토큰이 유효한지 검증해 준다. 이러한 분리 구조는 곧 파드가 이러한 세션 토큰의 발급 및 갱신에 대한 정확한 메커니즘을 모르게 하면서도 파드를 실행할 수 있음을 의미한다.
시크릿 다루기
시크릿 생성하기
시크릿 생성에는 다음과 같은 방법이 있다.
시크릿 이름 및 데이터에 대한 제약 사항
시크릿 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
사용자는 시크릿을 위한 파일을 구성할 때 data 및 (또는) stringData 필드를
명시할 수 있다. 해당 data 와 stringData 필드는 선택적으로 명시할 수 있다.
data 필드의 모든 키(key)에 해당하는 값(value)은 base64로 인코딩된 문자열이어야 한다.
만약 사용자에게 base64로의 문자열 변환이 적합하지 않다면,
임의의 문자열을 값으로 받는 stringData 필드를 대신 사용할 수 있다.
data 및 stringData의 키는 영숫자 문자,
-, _, 또는 . 으로 구성되어야 한다. stringData 필드의 모든 키-값 쌍은 의도적으로
data 필드로 합쳐진다. 만약 키가 data 와 stringData 필드 모두에 정의되어
있으면, stringData 필드에 지정된 값이
우선적으로 사용된다.
크기 제한
개별 시크릿의 크기는 1 MiB로 제한된다. 이는 API 서버 및 kubelet 메모리를 고갈시킬 수 있는 매우 큰 시크릿의 생성을 방지하기 위함이다. 그러나, 작은 크기의 시크릿을 많이 만드는 것도 메모리를 고갈시킬 수 있다. 리소스 쿼터를 사용하여 한 네임스페이스의 시크릿 (또는 다른 리소스) 수를 제한할 수 있다.
시크릿 수정하기
만들어진 시크릿은 불변(immutable)만 아니라면 수정될 수 있다. 시크릿 수정 방식은 다음과 같다.
Kustomize 도구로
시크릿 내부의 데이터를 수정하는 것도 가능하지만, 이 경우 수정된 데이터를 지닌 새로운 Secret 오브젝트가 생성된다.
시크릿을 생성한 방법이나 파드에서 시크릿이 어떻게 사용되는지에 따라,
존재하는 Secret 오브젝트에 대한 수정은 해당 데이터를 사용하는 파드들에 자동으로 전파된다.
자세한 정보는 마운트된 시크릿의 자동 업데이트를 참고하라.
시크릿 사용하기
시크릿은 데이터 볼륨으로 마운트되거나 파드의 컨테이너에서 사용할 환경 변수로 노출될 수 있다. 또한, 시크릿은 파드에 직접 노출되지 않고, 시스템의 다른 부분에서도 사용할 수 있다. 예를 들어, 시크릿은 시스템의 다른 부분이 사용자를 대신해서 외부 시스템과 상호 작용하는 데 사용해야 하는 자격 증명을 보유할 수 있다.
특정된 오브젝트 참조(reference)가 실제로 시크릿 유형의 오브젝트를 가리키는지 확인하기 위해, 시크릿 볼륨 소스의 유효성이 검사된다. 따라서, 시크릿은 자신에 의존하는 파드보다 먼저 생성되어야 한다.
시크릿을 가져올 수 없는 경우 (아마도 시크릿이 존재하지 않거나, 또는 API 서버에 대한 일시적인 연결 불가로 인해) kubelet은 해당 파드 실행을 주기적으로 재시도한다. kubelet은 또한 시크릿을 가져올 수 없는 문제에 대한 세부 정보를 포함하여 해당 파드에 대한 이벤트를 보고한다.
선택적 시크릿
시크릿을 기반으로 컨테이너 환경 변수를 정의하는 경우, 이 환경 변수를 선택 사항 으로 표시할 수 있다. 기본적으로는 시크릿은 필수 사항이다.
모든 필수 시크릿이 사용 가능해지기 전에는 파드의 컨테이너가 시작되지 않을 것이다.
파드가 시크릿의 특정 키를 참조하고, 해당 시크릿이 존재하지만 해당 키가 존재하지 않는 경우, 파드는 시작 과정에서 실패한다.
파드에서 시크릿을 파일처럼 사용하기
파드 안에서 시크릿의 데이터에 접근하고 싶다면, 한 가지 방법은 쿠버네티스로 하여금 해당 시크릿의 값을 파드의 하나 이상의 컨테이너의 파일시스템 내에 파일 형태로 표시하도록 만드는 것이다.
이렇게 구성하려면, 다음을 수행한다.
- 시크릿을 생성하거나 기존 시크릿을 사용한다. 여러 파드가 동일한 시크릿을 참조할 수 있다.
.spec.volumes[].아래에 볼륨을 추가하려면 파드 정의를 수정한다. 볼륨의 이름을 뭐든지 지정하고, 시크릿 오브젝트의 이름과 동일한.spec.volumes[].secret.secretName필드를 생성한다.- 시크릿이 필요한 각 컨테이너에
.spec.containers[].volumeMounts[]를 추가한다. 시크릿을 표시하려는 사용되지 않은 디렉터리 이름에.spec.containers[].volumeMounts[].readOnly = true와.spec.containers[].volumeMounts[].mountPath를 지정한다. - 프로그램이 해당 디렉터리에서 파일을 찾도록 이미지 또는 커맨드 라인을 수정한다. 시크릿
data맵의 각 키는mountPath아래의 파일명이 된다.
다음은 볼륨에 mysecret이라는 시크릿을 마운트하는 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
optional: false # 기본값임; "mysecret" 은 반드시 존재해야 함
사용하려는 각 시크릿은 .spec.volumes 에서 참조해야 한다.
파드에 여러 컨테이너가 있는 경우, 모든 컨테이너는
자체 volumeMounts 블록이 필요하지만, 시크릿에 대해서는 시크릿당 하나의 .spec.volumes 만 필요하다.
참고:
쿠버네티스 v1.22 이전 버전은 쿠버네티스 API에 접근하기 위한 크리덴셜을 자동으로 생성했다. 이러한 예전 메커니즘은 토큰 시크릿 생성 및 이를 실행 중인 파드에 마운트하는 절차에 기반했다. 쿠버네티스 v1.31 버전을 포함한 최근 버전에서는, API 크리덴셜이 TokenRequest API를 사용하여 직접 얻어지고, 프로젝티드 볼륨을 사용하여 파드 내에 마운트된다. 이러한 방법을 사용하여 얻은 토큰은 수명이 제한되어 있으며, 토큰이 탑재된 파드가 삭제되면 자동으로 무효화된다.
여전히 서비스 어카운트 토큰 시크릿을 수동으로 생성할 수도 있다.
예를 들어, 영원히 만료되지 않는 토큰이 필요한 경우에 활용할 수 있다.
그러나, 이렇게 하기보다는 API 접근에 필요한 토큰을 얻기 위해
TokenRequest 서브리소스를 사용하는 것을 권장한다.
TokenRequest API로부터 토큰을 얻기 위해
kubectl create token 커맨드를 사용할 수 있다.
특정 경로에 대한 시크릿 키 투영하기
시크릿 키가 투영되는 볼륨 내 경로를 제어할 수도 있다.
.spec.volumes[].secret.items 필드를 사용하여 각 키의 대상 경로를 변경할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
다음과 같은 일들이 일어날 것이다.
mysecret의username키는 컨테이너의/etc/foo/username경로 대신/etc/foo/my-group/my-username경로에서 사용 가능하다.- 시크릿 오브젝트의
password키는 투영되지 않는다.
.spec.volumes[].secret.items 를 사용하면, items 에 지정된 키만 투영된다.
시크릿의 모든 키를 사용하려면, 모든 키가 items 필드에 나열되어야 한다.
키를 명시적으로 나열했다면, 나열된 모든 키가 해당 시크릿에 존재해야 한다. 그렇지 않으면, 볼륨이 생성되지 않는다.
시크릿 파일 퍼미션
단일 시크릿 키에 대한 POSIX 파일 접근 퍼미션 비트를 설정할 수 있다.
만약 사용자가 퍼미션을 지정하지 않는다면, 기본적으로 0644 가 사용된다.
전체 시크릿 볼륨에 대한 기본 모드를 설정하고 필요한 경우 키별로 오버라이드할 수도 있다.
예를 들어, 다음과 같은 기본 모드를 지정할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 0400
시크릿이 /etc/foo 에 마운트되고,
시크릿 볼륨 마운트로 생성된 모든 파일의 퍼미션은 0400 이다.
참고:
JSON을 사용하여 파드 또는 파드 템플릿을 정의하는 경우, JSON 스펙은 8진수 표기법을 지원하지 않음에 유의한다.defaultMode 값으로 대신 10진수를 사용할 수 있다(예를 들어, 8진수 0400은 10진수로는 256이다).
YAML로 작성하는 경우, defaultMode 값을 8진수로 표기할 수 있다.볼륨으로부터 시크릿 값 사용하기
시크릿 볼륨을 마운트하는 컨테이너 내부에서, 시크릿 키는 파일 형태로 나타난다. 시크릿 값은 base64로 디코딩되어 이러한 파일 내에 저장된다.
다음은 위 예시의 컨테이너 내부에서 실행된 명령의 결과이다.
ls /etc/foo/
출력 결과는 다음과 비슷하다.
username
password
cat /etc/foo/username
출력 결과는 다음과 비슷하다.
admin
cat /etc/foo/password
출력 결과는 다음과 비슷하다.
1f2d1e2e67df
컨테이너의 프로그램은 필요에 따라 이러한 파일에서 시크릿 데이터를 읽는다.
마운트된 시크릿의 자동 업데이트
볼륨이 시크릿의 데이터를 포함하고 있는 상태에서 시크릿이 업데이트되면, 쿠버네티스는 이를 추적하고 최종적으로 일관된(eventually-consistent) 접근 방식을 사용하여 볼륨 안의 데이터를 업데이트한다.
참고:
시크릿을 subPath 볼륨 마운트로 사용하는 컨테이너는 자동 시크릿 업데이트를 받지 못한다.kubelet은 해당 노드의 파드의 볼륨에서 사용되는 시크릿의 현재 키 및 값 캐시를 유지한다.
kubelet이 캐시된 값에서 변경 사항을 감지하는 방식을 변경할 수 있다.
kubelet 환경 설정의 configMapAndSecretChangeDetectionStrategy 필드는
kubelet이 사용하는 전략을 제어한다. 기본 전략은 Watch이다.
시크릿 업데이트는 TTL(time-to-live)이 설정된 캐시 기반의 API 감시(watch) 메커니즘에 의해 전파되거나 (기본값임), 각 kubelet 동기화 때마다 클러스터 API 서버로부터의 폴링으로 달성될 수 있다.
결과적으로 시크릿이 업데이트되는 순간부터 새 키가 파드에 투영되는 순간까지의 총 지연은 kubelet 동기화 기간 + 캐시 전파 지연만큼 길어질 수 있다. 여기서 캐시 전파 지연은 선택한 캐시 유형에 따라 다르다(이전 단락과 동일한 순서로 나열하면, 감시(watch) 전파 지연, 설정된 캐시 TTL, 또는 직접 폴링의 경우 0임).
시크릿을 환경 변수 형태로 사용하기
파드에서 환경 변수 형태로 시크릿을 사용하려면 다음과 같이 한다.
- 시크릿을 생성(하거나 기존 시크릿을 사용)한다. 여러 파드가 동일한 시크릿을 참조할 수 있다.
- 사용하려는 각 시크릿 키에 대한 환경 변수를 추가하려면
시크릿 키 값을 사용하려는 각 컨테이너에서 파드 정의를 수정한다.
시크릿 키를 사용하는 환경 변수는 시크릿의 이름과 키를
env[].valueFrom.secretKeyRef에 채워야 한다. - 프로그램이 지정된 환경 변수에서 값을 찾도록 이미지 및/또는 커맨드 라인을 수정한다.
다음은 환경 변수를 통해 시크릿을 사용하는 파드의 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
optional: false # 기본값과 동일하다
# "mysecret"이 존재하고 "username"라는 키를 포함해야 한다
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
optional: false # 기본값과 동일하다
# "mysecret"이 존재하고 "password"라는 키를 포함해야 한다
restartPolicy: Never
올바르지 않은 환경 변수
유효하지 않은 환경 변수 이름으로 간주되는 키가 있는 envFrom 필드로
환경 변수를 채우는 데 사용되는 시크릿은 해당 키를 건너뛴다.
하지만 파드를 시작할 수는 있다.
유효하지 않은 변수 이름이 파드 정의에 포함되어 있으면,
reason이 InvalidVariableNames로 설정된 이벤트와
유효하지 않은 스킵된 키 목록 메시지가 파드 시작 실패 정보에 추가된다.
다음 예시는 2개의 유효하지 않은 키 1badkey 및 2alsobad를 포함하는 mysecret 시크릿을 참조하는 파드를 보여준다.
kubectl get events
출력은 다음과 같다.
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variable names.
환경 변수로부터 시크릿 값 사용하기
환경 변수 형태로 시크릿을 사용하는 컨테이너 내부에서, 시크릿 키는 일반적인 환경 변수로 보인다. 이러한 환경 변수의 값은 시크릿 데이터를 base64 디코드한 값이다.
다음은 위 예시 컨테이너 내부에서 실행된 명령의 결과이다.
echo "$SECRET_USERNAME"
출력 결과는 다음과 비슷하다.
admin
echo "$SECRET_PASSWORD"
출력 결과는 다음과 비슷하다.
1f2d1e2e67df
참고:
컨테이너가 이미 환경 변수 형태로 시크릿을 사용하는 경우, 컨테이너가 다시 시작되기 전에는 시크릿 업데이트를 볼 수 없다. 시크릿이 변경되면 컨테이너 재시작을 트리거하는 써드파티 솔루션이 존재한다.컨테이너 이미지 풀 시크릿
비공개 저장소에서 컨테이너 이미지를 가져오고 싶다면, 각 노드의 kubelet이 해당 저장소에 인증을 수행하는 방법을 마련해야 한다. 이를 위해 이미지 풀 시크릿 을 구성할 수 있다. 이러한 시크릿은 파드 수준에 설정된다.
파드의 imagePullSecrets 필드는 파드가 속한 네임스페이스에 있는 시크릿들에 대한 참조 목록이다.
imagePullSecrets를 사용하여 이미지 저장소 접근 크리덴셜을 kubelet에 전달할 수 있다.
kubelet은 이 정보를 사용하여 파드 대신 비공개 이미지를 가져온다.
imagePullSecrets 필드에 대한 더 많은 정보는
파드 API 레퍼런스의
PodSpec 부분을 확인한다.
imagePullSecrets 사용하기
imagePullSecrets 필드는 동일한 네임스페이스의 시크릿에 대한 참조 목록이다.
imagePullSecrets 를 사용하여 도커(또는 다른 컨테이너) 이미지 레지스트리 비밀번호가 포함된 시크릿을 kubelet에 전달할 수 있다.
kubelet은 이 정보를 사용해서 파드를 대신하여 프라이빗 이미지를 가져온다.
imagePullSecrets 필드에 대한 자세한 정보는 PodSpec API를 참고한다.
imagePullSecret 수동으로 지정하기
컨테이너 이미지 문서에서
imagePullSecrets를 지정하는 방법을 배울 수 있다.
imagePullSecrets가 자동으로 연결되도록 준비하기
수동으로 imagePullSecrets 를 생성하고,
서비스어카운트(ServiceAccount)에서 이들을 참조할 수 있다.
해당 서비스어카운트로 생성되거나 기본적인 서비스어카운트로 생성된 모든 파드는
파드의 imagePullSecrets 필드를 가져오고 서비스 어카운트의 필드로 설정한다.
해당 프로세스에 대한 자세한 설명은
서비스 어카운트에 ImagePullSecrets 추가하기를 참고한다.
스태틱 파드에서의 시크릿 사용
스태틱(static) 파드에서는 컨피그맵이나 시크릿을 사용할 수 없다.
사용 사례
사용 사례: 컨테이너 환경 변수로 사용하기
시크릿 정의를 작성한다.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
USER_NAME: YWRtaW4=
PASSWORD: MWYyZDFlMmU2N2Rm
시크릿을 생성한다.
kubectl apply -f mysecret.yaml
모든 시크릿 데이터를 컨테이너 환경 변수로 정의하는 데 envFrom 을 사용한다. 시크릿의 키는 파드의 환경 변수 이름이 된다.
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- secretRef:
name: mysecret
restartPolicy: Never
사용 사례: SSH 키를 사용하는 파드
몇 가지 SSH 키를 포함하는 시크릿을 생성한다.
kubectl create secret generic ssh-key-secret --from-file=ssh-privatekey=/path/to/.ssh/id_rsa --from-file=ssh-publickey=/path/to/.ssh/id_rsa.pub
출력 결과는 다음과 비슷하다.
secret "ssh-key-secret" created
SSH 키를 포함하는 secretGenerator 필드가 있는 kustomization.yaml 를 만들 수도 있다.
주의:
사용자 자신의 SSH 키를 보내기 전에 신중하게 생각한다. 클러스터의 다른 사용자가 시크릿에 접근할 수 있게 될 수도 있기 때문이다.
대신, 쿠버네티스 클러스터를 공유하는 모든 사용자가 접근할 수 있으면서도, 크리덴셜이 유출된 경우 폐기가 가능한 서비스 아이덴티티를 가리키는 SSH 프라이빗 키를 만들 수 있다.
이제 SSH 키를 가진 시크릿을 참조하고 볼륨에서 시크릿을 사용하는 파드를 만들 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
labels:
name: secret-test
spec:
volumes:
- name: secret-volume
secret:
secretName: ssh-key-secret
containers:
- name: ssh-test-container
image: mySshImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
컨테이너의 명령이 실행될 때, 다음 위치에서 키 부분을 사용할 수 있다.
/etc/secret-volume/ssh-publickey
/etc/secret-volume/ssh-privatekey
그러면 컨테이너는 SSH 연결을 맺기 위해 시크릿 데이터를 자유롭게 사용할 수 있다.
사용 사례: 운영 / 테스트 자격 증명을 사용하는 파드
이 예제에서는 운영 환경의 자격 증명이 포함된 시크릿을 사용하는 파드와 테스트 환경의 자격 증명이 있는 시크릿을 사용하는 다른 파드를 보여준다.
사용자는 secretGenerator 필드가 있는 kustomization.yaml 을 만들거나
kubectl create secret 을 실행할 수 있다.
kubectl create secret generic prod-db-secret --from-literal=username=produser --from-literal=password=Y4nys7f11
출력 결과는 다음과 비슷하다.
secret "prod-db-secret" created
테스트 환경의 자격 증명에 대한 시크릿을 만들 수도 있다.
kubectl create secret generic test-db-secret --from-literal=username=testuser --from-literal=password=iluvtests
출력 결과는 다음과 비슷하다.
secret "test-db-secret" created
참고:
$, \, *, = 그리고 ! 와 같은 특수 문자는 사용자의 셸에 의해 해석되고 이스케이핑이 필요하다.
대부분의 셸에서 비밀번호를 이스케이프하는 가장 쉬운 방법은 작은 따옴표(')로 묶는 것이다.
예를 들어, 실제 비밀번호가 S!B\*d$zDsb= 이면, 다음과 같은 명령을 실행해야 한다.
kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password='S!B\*d$zDsb='
파일(--from-file)에서는 비밀번호의 특수 문자를 이스케이프할 필요가 없다.
이제 파드를 생성한다.
cat <<EOF > pod.yaml
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
EOF
동일한 kustomization.yaml에 파드를 추가한다.
cat <<EOF >> kustomization.yaml
resources:
- pod.yaml
EOF
다음을 실행하여 API 서버에 이러한 모든 오브젝트를 적용한다.
kubectl apply -k .
두 컨테이너 모두 각 컨테이너의 환경에 대한 값을 가진 파일시스템에 다음의 파일이 존재한다.
/etc/secret-volume/username
/etc/secret-volume/password
두 파드의 사양이 한 필드에서만 어떻게 다른지 확인한다. 이를 통해 공통 파드 템플릿에서 다양한 기능을 가진 파드를 생성할 수 있다.
두 개의 서비스 어카운트를 사용하여 기본 파드 명세를 더욱 단순화할 수 있다.
prod-db-secret을 가진prod-usertest-db-secret을 가진test-user
파드 명세는 다음과 같이 단축된다.
apiVersion: v1
kind: Pod
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
serviceAccount: prod-db-client
containers:
- name: db-client-container
image: myClientImage
사용 사례: 시크릿 볼륨의 도트 파일(dotfile)
점으로 시작하는 키를 정의하여 데이터를 "숨김"으로 만들 수 있다.
이 키는 도트 파일 또는 "숨겨진" 파일을 나타낸다.
예를 들어, 다음 시크릿이 secret-volume 볼륨에 마운트되면 아래와 같다.
apiVersion: v1
kind: Secret
metadata:
name: dotfile-secret
data:
.secret-file: dmFsdWUtMg0KDQo=
---
apiVersion: v1
kind: Pod
metadata:
name: secret-dotfiles-pod
spec:
volumes:
- name: secret-volume
secret:
secretName: dotfile-secret
containers:
- name: dotfile-test-container
image: registry.k8s.io/busybox
command:
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
볼륨은 .secret-file 이라는 하나의 파일을 포함하고,
dotfile-test-container 는 /etc/secret-volume/.secret-file 경로에
이 파일을 가지게 된다.
참고:
ls -l 명령의 결과에서 숨겨진 점으로 시작하는 파일들은
디렉터리 내용을 나열할 때 ls -la 를 사용해야 이 파일들을 볼 수 있다.사용 사례: 파드의 한 컨테이너에 표시되는 시크릿
HTTP 요청을 처리하고, 복잡한 비즈니스 로직을 수행한 다음, HMAC이 있는 일부 메시지에 서명해야 하는 프로그램을 고려한다. 애플리케이션 로직이 복잡하기 때문에, 서버에서 눈에 띄지 않는 원격 파일 읽기 공격이 있을 수 있으며, 이로 인해 개인 키가 공격자에게 노출될 수 있다.
이는 두 개의 컨테이너의 두 개 프로세스로 나눌 수 있다. 사용자 상호 작용과 비즈니스 로직을 처리하지만, 개인 키를 볼 수 없는 프론트엔드 컨테이너와 개인 키를 볼 수 있고, 프론트엔드의 간단한 서명 요청(예를 들어, localhost 네트워킹을 통해)에 응답하는 서명자 컨테이너로 나눌 수 있다.
이 분할된 접근 방식을 사용하면, 공격자는 이제 애플리케이션 서버를 속여서 파일을 읽는 것보다 다소 어려운 임의적인 어떤 작업을 수행해야 한다.
시크릿 타입
시크릿을 생성할 때, Secret
리소스의 type 필드를 사용하거나, (활용 가능하다면) kubectl 의
유사한 특정 커맨드라인 플래그를 사용하여 시크릿의 타입을 명시할 수 있다.
시크릿 타입은 여러 종류의 기밀 데이터를 프로그래밍 방식으로 용이하게 처리하기 위해 사용된다.
쿠버네티스는 일반적인 사용 시나리오를 위해 몇 가지 빌트인 타입을 제공한다. 이 타입은 쿠버네티스가 부과하여 수행되는 검증 및 제약에 따라 달라진다.
| 빌트인 타입 | 사용처 |
|---|---|
Opaque |
임의의 사용자 정의 데이터 |
kubernetes.io/service-account-token |
서비스 어카운트 토큰 |
kubernetes.io/dockercfg |
직렬화 된(serialized) ~/.dockercfg 파일 |
kubernetes.io/dockerconfigjson |
직렬화 된 ~/.docker/config.json 파일 |
kubernetes.io/basic-auth |
기본 인증을 위한 자격 증명(credential) |
kubernetes.io/ssh-auth |
SSH를 위한 자격 증명 |
kubernetes.io/tls |
TLS 클라이언트나 서버를 위한 데이터 |
bootstrap.kubernetes.io/token |
부트스트랩 토큰 데이터 |
사용자는 시크릿 오브젝트의 type 값에 비어 있지 않은 문자열을 할당하여 자신만의 시크릿 타입을 정의하고 사용할 수 있다
(비어 있는 문자열은 Opaque 타입으로 인식된다).
쿠버네티스는 타입 명칭에 제약을 부과하지는 않는다. 그러나 만약 빌트인 타입 중 하나를 사용한다면, 해당 타입에 정의된 모든 요구 사항을 만족시켜야 한다.
공개 사용을 위한 시크릿 타입을 정의하는 경우, 규칙에 따라
cloud-hosting.example.net/cloud-api-credentials와 같이 시크릿 타입 이름 앞에 도메인 이름 및 /를 추가하여
전체 시크릿 타입 이름을 구성한다.
불투명(Opaque) 시크릿
Opaque 은 시크릿 구성 파일에서 시크릿 타입을 지정하지 않았을 경우의 기본 시크릿 타입이다.
kubectl 을 사용하여 시크릿을 생성할 때 Opaque 시크릿 타입을 나타내기
위해서는 generic 하위 커맨드를 사용할 것이다. 예를 들어, 다음 커맨드는
타입 Opaque 의 비어 있는 시크릿을 생성한다.
kubectl create secret generic empty-secret
kubectl get secret empty-secret
출력은 다음과 같다.
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
해당 DATA 열은 시크릿에 저장된 데이터 아이템의 수를 보여준다.
이 경우, 0 은 비어 있는 시크릿을 생성하였다는 것을 의미한다.
서비스 어카운트 토큰 시크릿
kubernetes.io/service-account-token 시크릿 타입은
서비스 어카운트를 확인하는
토큰 자격증명을 저장하기 위해서 사용한다.
1.22 버전 이후로는 이러한 타입의 시크릿은 더 이상 파드에 자격증명을 마운트하는 데 사용되지 않으며,
서비스 어카운트 토큰 시크릿 오브젝트를 사용하는 대신
TokenRequest API를 통해 토큰을 얻는 것이 추천된다.
TokenRequest API에서 얻은 토큰은 제한된 수명을 가지며 다른 API 클라이언트에서 읽을 수 없기 때문에
시크릿 오브젝트에 저장된 토큰보다 더 안전하다.
TokenRequest API에서 토큰을 얻기 위해서
kubectl create token 커맨드를 사용할 수 있다.
토큰을 얻기 위한 TokenRequest API를 사용할 수 없는 경우에는
서비스 어카운트 토큰 시크릿 오브젝트를 생성할 수 밖에 없으나,
이는 만료되지 않는 토큰 자격증명을 읽기 가능한 API 오브젝트로
지속되는 보안 노출 상황을 감수할 수 있는 경우에만 생성해야 한다.
이 시크릿 타입을 사용할 때는,
kubernetes.io/service-account.name 어노테이션이 존재하는
서비스 어카운트 이름으로 설정되도록 해야 한다. 만약 서비스 어카운트와
시크릿 오브젝트를 모두 생성하는 경우, 서비스 어카운트를 먼저 생성해야만 한다.
시크릿이 생성된 후, 쿠버네티스 컨트롤러는
kubernetes.io/service-account.uid 어노테이션 및
인증 토큰을 보관하고 있는 data 필드의 token 키와 같은 몇 가지 다른 필드들을 채운다.
다음은 서비스 어카운트 토큰 시크릿의 구성 예시이다.
apiVersion: v1
kind: Secret
metadata:
name: secret-sa-sample
annotations:
kubernetes.io/service-account.name: "sa-name"
type: kubernetes.io/service-account-token
data:
# 사용자는 불투명 시크릿을 사용하므로 추가적인 키 값 쌍을 포함할 수 있다.
extra: YmFyCg==
시크릿을 만든 후, 쿠버네티스가 data 필드에 token 키를 채울 때까지 기다린다.
서비스 어카운트 문서를 보면
서비스 어카운트가 동작하는 방법에 대한 더 자세한 정보를 얻을 수 있다.
또한 파드에서 서비스 어카운트 자격증명을 참조하는 방법에 대한 정보는
Pod의
automountServiceAccountToken 필드와 serviceAccountName
필드를 통해 확인할 수 있다.
도커 컨피그 시크릿
이미지에 대한 도커 레지스트리 접속 자격 증명을 저장하기 위한
시크릿을 생성하기 위해서 다음의 type 값 중 하나를 사용할 수 있다.
kubernetes.io/dockercfgkubernetes.io/dockerconfigjson
kubernetes.io/dockercfg 는 직렬화된 도커 커맨드라인 구성을
위한 기존(legacy) 포맷 ~/.dockercfg 를 저장하기 위해 할당된 타입이다.
시크릿 타입을 사용할 때는, data 필드가 base64 포맷으로
인코딩된 ~/.dockercfg 파일의 콘텐츠를 값으로 가지는 .dockercfg 키를 포함하고 있는지
확실히 확인해야 한다.
kubernetes.io/dockerconfigjson 타입은 ~/.dockercfg 의
새로운 포맷인 ~/.docker/config.json 파일과 동일한 포맷 법칙을
따르는 직렬화 된 JSON의 저장을 위해 디자인되었다.
이 시크릿 타입을 사용할 때는, 시크릿 오브젝트의 data 필드가 .dockerconfigjson 키를
꼭 포함해야 한다. ~/.docker/config.json 파일을 위한 콘텐츠는
base64로 인코딩된 문자열으로 제공되어야 한다.
아래는 시크릿의 kubernetes.io/dockercfg 타입 예시이다.
apiVersion: v1
kind: Secret
metadata:
name: secret-dockercfg
type: kubernetes.io/dockercfg
data:
.dockercfg: |
"<base64 encoded ~/.dockercfg file>"
참고:
만약 base64 인코딩 수행을 원하지 않는다면, 그 대신stringData 필드를 사용할 수 있다.이러한 타입들을 매니페스트를 사용하여 생성하는 경우, API
서버는 해당 data 필드에 기대하는 키가 존재하는지 확인하고,
제공된 값이 유효한 JSON으로 파싱될 수 있는지 검증한다. API
서버가 해당 JSON이 실제 도커 컨피그 파일인지를 검증하지는 않는다.
도커 컨피그 파일을 가지고 있지 않거나 도커 레지스트리 시크릿을 생성하기
위해 kubectl 을 사용하고 싶은 경우, 다음과 같이 처리할 수 있다.
kubectl create secret docker-registry secret-tiger-docker \
--docker-email=tiger@acme.example \
--docker-username=tiger \
--docker-password=pass1234 \
--docker-server=my-registry.example:5000
이 커맨드는 kubernetes.io/dockerconfigjson 타입의 시크릿을 생성한다.
다음 명령으로 이 새 시크릿에서 .data.dockerconfigjson 필드를 덤프하고
base64로 디코드하면,
kubectl get secret secret-tiger-docker -o jsonpath='{.data.*}' | base64 -d
출력은 다음과 같은 JSON 문서이다(그리고 이는 또한 유효한 도커 구성 파일이다).
{
"auths": {
"my-registry.example:5000": {
"username": "tiger",
"password": "pass1234",
"email": "tiger@acme.example",
"auth": "dGlnZXI6cGFzczEyMzQ="
}
}
}
참고:
위의auth 값은 base64 인코딩되어 있다. 이는 난독화된 것이지 암호화된 것이 아니다.
이 시크릿을 읽을 수 있는 사람은 레지스트리 접근 베어러 토큰을 알 수 있는 것이다.기본 인증(Basic authentication) 시크릿
kubernetes.io/basic-auth 타입은 기본 인증을 위한 자격 증명을 저장하기
위해 제공된다. 이 시크릿 타입을 사용할 때는 시크릿의 data 필드가
다음의 두 키 중 하나를 포함해야 한다.
username: 인증을 위한 사용자 이름password: 인증을 위한 암호나 토큰
위의 두 키에 대한 두 값은 모두 base64로 인코딩된 문자열이다. 물론,
시크릿 생성 시 stringData 를 사용하여 평문 텍스트 콘텐츠(clear text content)를 제공할
수도 있다.
다음의 YAML은 기본 인증 시크릿을 위한 구성 예시이다.
apiVersion: v1
kind: Secret
metadata:
name: secret-basic-auth
type: kubernetes.io/basic-auth
stringData:
username: admin # kubernetes.io/basic-auth 에서 요구하는 필드
password: t0p-Secret # kubernetes.io/basic-auth 에서 요구하는 필드
이 기본 인증 시크릿 타입은 오직 사용자 편의를 위해 제공되는 것이다.
사용자는 기본 인증에서 사용할 자격 증명을 위해 Opaque 타입의 시크릿을 생성할 수도 있다.
그러나, 미리 정의되어 공개된 시크릿 타입(kubernetes.io/basic-auth)을 사용하면
다른 사람이 이 시크릿의 목적을 이해하는 데 도움이 되며,
예상되는 키 이름에 대한 규칙이 설정된다.
쿠버네티스 API는 이 유형의 시크릿에 대해
필수 키가 설정되었는지 확인한다.
SSH 인증 시크릿
이 빌트인 타입 kubernetes.io/ssh-auth 는 SSH 인증에 사용되는 데이터를
저장하기 위해서 제공된다. 이 시크릿 타입을 사용할 때는 ssh-privatekey
키-값 쌍을 사용할 SSH 자격 증명으로 data (또는 stringData)
필드에 명시해야 할 것이다.
다음 매니페스트는 SSH 공개/개인 키 인증에 사용되는 시크릿 예시이다.
apiVersion: v1
kind: Secret
metadata:
name: secret-ssh-auth
type: kubernetes.io/ssh-auth
data:
# 본 예시를 위해 축약된 데이터임
ssh-privatekey: |
MIIEpQIBAAKCAQEAulqb/Y ...
SSH 인증 시크릿 타입은 오직 사용자 편의를 위해 제공되는 것이다.
사용자는 SSH 인증에서 사용할 자격 증명을 위해 Opaque 타입의 시크릿을 생성할 수도 있다.
그러나, 미리 정의되어 공개된 시크릿 타입(kubernetes.io/ssh-auth)을 사용하면
다른 사람이 이 시크릿의 목적을 이해하는 데 도움이 되며,
예상되는 키 이름에 대한 규칙이 설정된다.
그리고 API 서버가
시크릿 정의에 필수 키가 명시되었는지 확인한다.
주의:
SSH 개인 키는 자체적으로 SSH 클라이언트와 호스트 서버 간에 신뢰할 수 있는 통신을 설정하지 않는다. 컨피그맵(ConfigMap)에 추가된known_hosts 파일과 같은
"중간자(man in the middle)" 공격을 완화하려면 신뢰를 설정하는
2차 수단이 필요하다.TLS 시크릿
쿠버네티스는 일반적으로 TLS를 위해 사용되는 인증서 및 관련된 키를 저장하기 위한
빌트인 시크릿 타입 kubernetes.io/tls 를 제공한다.
TLS 시크릿의 일반적인 용도 중 하나는 인그레스에 대한
전송 암호화(encryption in transit)를 구성하는 것이지만,
다른 리소스와 함께 사용하거나 워크로드에서 직접 사용할 수도 있다.
이 타입의 시크릿을 사용할 때는 tls.key 와 tls.crt 키가
시크릿 구성의 data (또는 stringData) 필드에서 제공되어야 한다.
그러나, API 서버가 각 키에 대한 값이 유효한지 실제로 검증하지는 않는다.
다음 YAML은 TLS 시크릿을 위한 구성 예시를 포함한다.
apiVersion: v1
kind: Secret
metadata:
name: secret-tls
type: kubernetes.io/tls
data:
# 본 예시를 위해 축약된 데이터임
tls.crt: |
MIIC2DCCAcCgAwIBAgIBATANBgkqh ...
tls.key: |
MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
TLS 시크릿 타입은 사용자 편의만을 위해서 제공된다. 사용자는 TLS 서버 및/또는
클라이언트를 위해 사용되는 자격 증명을 위한 Opaque 를 생성할 수도 있다. 그러나, 빌트인
시크릿 타입을 사용하는 것은 사용자의 자격 증명들의 포맷을 통합하는 데 도움이 되고,
API 서버는 요구되는 키가 시크릿 구성에서 제공되고 있는지 검증도 한다.
kubectl 를 사용하여 TLS 시크릿을 생성할 때, tls 하위 커맨드를
다음 예시와 같이 사용할 수 있다.
kubectl create secret tls my-tls-secret \
--cert=path/to/cert/file \
--key=path/to/key/file
공개/개인 키 쌍은 사전에 준비되어야 한다.
--cert 에 들어가는 공개 키 인증서는
RFC 7468의 섹션 5.1에 있는 DER 형식이어야 하고,
--key 에 들어가는 개인 키 인증서는
RFC 7468의 섹션 11에 있는 DER 형식 PKCS #8 을 따라야 한다.
참고:
kubernetes.io/tls 시크릿은
키 및 인증서에 Base64 인코드된 DER 데이터를 보관한다.
개인 키 및 인증서에 사용되는 PEM 형식에 익숙하다면,
이 base64 데이터는 PEM 형식에서 맨 윗줄과 아랫줄을 제거한 것과 동일하다.
예를 들어, 인증서의 경우,
--------BEGIN CERTIFICATE----- 및 -------END CERTIFICATE---- 줄은 포함되면 안 된다.
부트스트랩 토큰 시크릿
부트스트랩 토큰 시크릿은 시크릿 type 을 bootstrap.kubernetes.io/token 으로
명확하게 지정하면 생성할 수 있다. 이 타입의 시크릿은 노드 부트스트랩 과정 중에 사용되는
토큰을 위해 디자인되었다. 이것은 잘 알려진 컨피그맵에 서명하는 데 사용되는
토큰을 저장한다.
부트스트랩 토큰 시크릿은 보통 kube-system 네임스페이스에 생성되며
<token-id> 가 해당 토큰 ID의 6개 문자의 문자열으로 구성된 bootstrap-token-<token-id> 형태로
이름이 지정된다.
쿠버네티스 매니페스트로서, 부트스트렙 토큰 시크릿은 다음과 유사할 것이다.
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-5emitj
namespace: kube-system
type: bootstrap.kubernetes.io/token
data:
auth-extra-groups: c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
expiration: MjAyMC0wOS0xM1QwNDozOToxMFo=
token-id: NWVtaXRq
token-secret: a3E0Z2lodnN6emduMXAwcg==
usage-bootstrap-authentication: dHJ1ZQ==
usage-bootstrap-signing: dHJ1ZQ==
부트스트랩 타입 시크릿은 data 아래 명시된 다음의 키들을 가진다.
token-id: 토큰 식별자로 임의의 6개 문자의 문자열. 필수 사항.token-secret: 실제 토큰 시크릿으로 임의의 16개 문자의 문자열. 필수 사항.description: 토큰의 사용처를 설명하는 사람이 읽을 수 있는 문자열. 선택 사항.expiration: 토큰이 만료되어야 하는 시기를 명시한 RFC3339를 사용하는 절대 UTC 시간. 선택 사항.usage-bootstrap-<usage>: 부트스트랩 토큰의 추가적인 사용처를 나타내는 불리언(boolean) 플래그.auth-extra-groups:system:bootstrappers그룹에 추가로 인증될 쉼표로 구분된 그룹 이름 목록.
위의 YAML은 모두 base64로 인코딩된 문자열 값이므로 혼란스러워 보일 수 있다. 사실은 다음 YAML을 사용하여 동일한 시크릿을 생성할 수 있다.
apiVersion: v1
kind: Secret
metadata:
# 시크릿 이름이 어떻게 지정되었는지 확인
name: bootstrap-token-5emitj
# 부트스트랩 토큰 시크릿은 일반적으로 kube-system 네임스페이스에 포함
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
auth-extra-groups: "system:bootstrappers:kubeadm:default-node-token"
expiration: "2020-09-13T04:39:10Z"
# 이 토큰 ID는 이름에 사용됨
token-id: "5emitj"
token-secret: "kq4gihvszzgn1p0r"
# 이 토큰은 인증을 위해서 사용될 수 있음
usage-bootstrap-authentication: "true"
# 또한 서명(signing)에도 사용될 수 있음
usage-bootstrap-signing: "true"
불변(immutable) 시크릿
기능 상태:
Kubernetes v1.21 [stable]
쿠버네티스에서 특정 시크릿(및 컨피그맵)을 불변 으로 표시할 수 있다. 기존 시크릿 데이터의 변경을 금지시키면 다음과 같은 이점을 가진다.
- 잘못된(또는 원치 않은) 업데이트를 차단하여 애플리케이션 중단을 방지
- (수만 개 이상의 시크릿-파드 마운트와 같이 시크릿을 대규모로 사용하는 클러스터의 경우,) 불변 시크릿으로 전환하면 kube-apiserver의 부하를 크게 줄여 클러스터의 성능을 향상시킬 수 있다. kubelet은 불변으로 지정된 시크릿에 대해서는 [감시(watch)]를 유지할 필요가 없기 때문이다.
시크릿을 불변으로 지정하기
다음과 같이 시크릿의 immutable 필드를 true로 설정하여 불변 시크릿을 만들 수 있다.
apiVersion: v1
kind: Secret
metadata:
...
data:
...
immutable: true
또한 기존의 수정 가능한 시크릿을 변경하여 불변 시크릿으로 바꿀 수도 있다.
참고:
시크릿 또는 컨피그맵이 불변으로 지정되면, 이 변경을 취소하거나data 필드의 내용을 바꿀 수 없다.
시크릿을 삭제하고 다시 만드는 것만 가능하다.
기존의 파드는 삭제된 시크릿으로의 마운트 포인트를 유지하기 때문에,
이러한 파드는 재생성하는 것을 추천한다.시크릿을 위한 정보 보안(Information security)
컨피그맵과 시크릿은 비슷하게 동작하지만, 쿠버네티스는 시크릿 오브젝트에 대해 약간의 추가적인 보호 조치를 적용한다.
시크릿은 종종 다양한 중요도에 걸친 값을 보유하며, 이 중 많은 부분이 쿠버네티스(예: 서비스 어카운트 토큰)와 외부 시스템으로 단계적으로 확대될 수 있다. 개별 앱이 상호 작용할 것으로 예상되는 시크릿의 힘에 대해 추론할 수 있더라도 동일한 네임스페이스 내의 다른 앱이 이러한 가정을 무효화할 수 있다.
해당 노드의 파드가 필요로 하는 경우에만 시크릿이 노드로 전송된다.
시크릿을 파드 내부로 마운트할 때, 기밀 데이터가 보존적인(durable) 저장소에 기록되지 않도록 하기 위해
kubelet이 데이터 복제본을 tmpfs에 저장한다.
해당 시크릿을 사용하는 파드가 삭제되면,
kubelet은 시크릿에 있던 기밀 데이터의 로컬 복사본을 삭제한다.
파드에는 여러 개의 컨테이너가 있을 수 있다. 기본적으로, 사용자가 정의한 컨테이너는 기본 서비스어카운트 및 이에 연관된 시크릿에만 접근할 수 있다. 다른 시크릿에 접근할 수 있도록 하려면 명시적으로 환경 변수를 정의하거나 컨테이너 내에 볼륨을 맵핑해야 한다.
동일한 노드의 여러 파드에 대한 시크릿이 있을 수 있다. 그러나 잠재적으로는 파드가 요청한 시크릿만 해당 파드의 컨테이너 내에서 볼 수 있다. 따라서, 하나의 파드는 다른 파드의 시크릿에 접근할 수 없다.
경고:
특정 노드에 대해privileged: true가 설정되어 실행 중인 컨테이너들은 전부
해당 노드에서 사용 중인 모든 시크릿에 접근할 수 있다.다음 내용
- 시크릿의 보안성을 높이고 관리하는 데에 관한 가이드라인을 원한다면 쿠버네티스 시크릿을 다루는 좋은 관행들을 참고하라.
kubectl을 사용하여 시크릿 관리하는 방법 배우기- 구성 파일을 사용하여 시크릿 관리하는 방법 배우기
- kustomize를 사용하여 시크릿 관리하는 방법 배우기
- API 레퍼런스에서
Secret에 대해 읽기
8.4 - 파드 및 컨테이너 리소스 관리
파드를 지정할 때, 컨테이너에 필요한 각 리소스의 양을 선택적으로 지정할 수 있다. 지정할 가장 일반적인 리소스는 CPU와 메모리(RAM) 그리고 다른 것들이 있다.
파드에서 컨테이너에 대한 리소스 요청(request) 을 지정하면, kube-scheduler는 이 정보를 사용하여 파드가 배치될 노드를 결정한다. 컨테이너에 대한 리소스 제한(limit) 을 지정하면, kubelet은 실행 중인 컨테이너가 설정한 제한보다 많은 리소스를 사용할 수 없도록 해당 제한을 적용한다. 또한 kubelet은 컨테이너가 사용할 수 있도록 해당 시스템 리소스의 최소 요청 량을 예약한다.
요청 및 제한
파드가 실행 중인 노드에 사용 가능한 리소스가 충분하면, 컨테이너가 해당
리소스에 지정한 request 보다 더 많은 리소스를 사용할 수 있도록 허용된다.
그러나, 컨테이너는 리소스 limit 보다 더 많은 리소스를 사용할 수는 없다.
예를 들어, 컨테이너에 대해 256MiB의 memory 요청을 설정하고, 해당 컨테이너가
8GiB의 메모리를 가진 노드로 스케줄된 파드에 있고 다른 파드는 없는 경우, 컨테이너는 더 많은 RAM을
사용할 수 있다.
해당 컨테이너에 대해 4GiB의 memory 제한을 설정하면, kubelet(그리고
컨테이너 런타임)이 제한을 적용한다.
런타임은 컨테이너가 구성된 리소스 제한을 초과하여 사용하지 못하게 한다. 예를 들어,
컨테이너의 프로세스가 허용된 양보다 많은 메모리를 사용하려고 하면,
시스템 커널은 메모리 부족(out of memory, OOM) 오류와 함께 할당을 시도한 프로세스를
종료한다.
제한은 반응적(시스템이 위반을 감지한 후에 개입)으로 또는 강제적(시스템이 컨테이너가 제한을 초과하지 않도록 방지)으로 구현할 수 있다. 런타임마다 다른 방식으로 동일한 제약을 구현할 수 있다.
참고:
리소스에 대해 제한은 지정하지만 요청은 지정하지 않고, 해당 리소스에 대한 요청 기본값을 지정하는 승인-시점 메커니즘(admission-time mechanism)이 없는 경우, 쿠버네티스는 당신이 지정한 제한을 복사하여 해당 리소스의 요청 값으로 사용한다.리소스 타입
CPU 와 메모리 는 각각 리소스 타입 이다. 리소스 타입에는 기본 단위가 있다. CPU는 컴퓨팅 처리를 나타내며 쿠버네티스 CPU 단위로 지정된다. 메모리는 바이트 단위로 지정된다. 리눅스 워크로드에 대해서는, huge page 리소스를 지정할 수 있다. Huge page는 노드 커널이 기본 페이지 크기보다 훨씬 큰 메모리 블록을 할당하는 리눅스 관련 기능이다.
예를 들어, 기본 페이지 크기가 4KiB인 시스템에서, hugepages-2Mi: 80Mi 제한을
지정할 수 있다. 컨테이너가 40개 이상의 2MiB huge page(총 80MiB)를
할당하려고 하면 해당 할당이 실패한다.
참고:
hugepages-* 리소스를 오버커밋할 수 없다.
이것은 memory 및 cpu 리소스와는 다르다.CPU와 메모리를 통칭하여 컴퓨트 리소스 또는 리소스 라고 한다. 컴퓨트 리소스는 요청, 할당 및 소비될 수 있는 측정 가능한 수량이다. 이것은 API 리소스와는 다르다. 파드 및 서비스와 같은 API 리소스는 쿠버네티스 API 서버를 통해 읽고 수정할 수 있는 오브젝트이다.
파드와 컨테이너의 리소스 요청 및 제한
각 컨테이너에 대해, 다음과 같은 리소스 제한(limit) 및 요청(request)을 지정할 수 있다.
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>
요청 및 제한은 개별 컨테이너에 대해서만 지정할 수 있지만, 한 파드의 총 리소스 요청 및 제한에 대해 생각해 보는 것도 유용할 수 있다. 특정 리소스 종류에 대해, 파드 리소스 요청/제한 은 파드의 각 컨테이너에 대한 해당 타입의 리소스 요청/제한의 합이다.
쿠버네티스의 리소스 단위
CPU 리소스 단위
CPU 리소스에 대한 제한 및 요청은 cpu 단위로 측정된다. 쿠버네티스에서, 1 CPU 단위는 노드가 물리 호스트인지 아니면 물리 호스트 내에서 실행되는 가상 머신인지에 따라 1 물리 CPU 코어 또는 1 가상 코어 에 해당한다.
요청량을 소수점 형태로 명시할 수도 있다. 컨테이너의
spec.containers[].resources.requests.cpu를 0.5로 설정한다는 것은,
1.0 CPU를 요청했을 때와 비교하여 절반의 CPU 타임을 요청한다는 의미이다.
CPU 자원의 단위와 관련하여, 0.1 이라는 수량 표현은
"백 밀리cpu"로 읽을 수 있는 100m 표현과 동일하다. 어떤 사람들은
"백 밀리코어"라고 말하는데, 같은 것을 의미하는 것으로 이해된다.
CPU 리소스는 항상 리소스의 절대량으로 표시되며, 상대량으로 표시되지 않는다.
예를 들어, 컨테이너가 싱글 코어, 듀얼 코어, 또는 48 코어 머신 중 어디에서 실행되는지와 상관없이
500m CPU는 거의 같은 양의 컴퓨팅 파워를 가리킨다.
참고:
쿠버네티스에서 CPU 리소스를1m보다 더 정밀한 단위로 표기할 수 없다.
이 때문에, CPU 단위를 1.0 또는 1000m보다 작은 밀리CPU 형태로 표기하는 것이 유용하다.
예를 들어, 0.005 보다는 5m으로 표기하는 것이 좋다.메모리 리소스 단위
memory 에 대한 제한 및 요청은 바이트 단위로 측정된다.
E, P, T, G, M, k 와 같은
수량 접미사 중 하나를 사용하여 메모리를
일반 정수 또는 고정 소수점 숫자로 표현할 수 있다. Ei, Pi, Ti, Gi, Mi, Ki와
같은 2의 거듭제곱을 사용할 수도 있다. 예를 들어, 다음은 대략 동일한 값을 나타낸다.
128974848, 129e6, 129M, 128974848000m, 123Mi
접미사의 대소문자에 유의한다.
400m의 메모리를 요청하면, 이는 0.4 바이트를 요청한 것이다.
이 사람은 아마도 400 메비바이트(mebibytes) (400Mi) 또는 400 메가바이트 (400M) 를 요청하고 싶었을 것이다.
컨테이너 리소스 예제
다음 파드는 두 컨테이너로 구성된다. 각 컨테이너는 0.25 CPU와 64 MiB(226 바이트) 메모리 요청을 갖도록 정의되어 있다. 또한 각 컨테이너는 0.5 CPU와 128 MiB 메모리 제한을 갖는다. 이 경우 파드는 0.5 CPU와 128 MiB 메모리 요청을 가지며, 1 CPU와 256 MiB 메모리 제한을 갖는다.
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
리소스 요청이 포함된 파드를 스케줄링하는 방법
파드를 생성할 때, 쿠버네티스 스케줄러는 파드를 실행할 노드를 선택한다. 각 노드는 파드에 제공할 수 있는 CPU와 메모리 양과 같은 각 리소스 타입에 대해 최대 용량을 갖는다. 스케줄러는 각 리소스 타입마다 스케줄된 컨테이너의 리소스 요청 합계가 노드 용량보다 작도록 한다. 참고로 노드의 실제 메모리나 CPU 리소스 사용량은 매우 적지만, 용량 확인에 실패한 경우 스케줄러는 여전히 노드에 파드를 배치하지 않는다. 이는 리소스 사용량이 나중에 증가할 때, 예를 들어, 일일 요청 비율이 최대일 때 노드의 리소스 부족을 방지한다.
쿠버네티스가 리소스 요청 및 제한을 적용하는 방법
kubelet이 파드의 컨테이너를 시작할 때, kubelet은 해당 컨테이너의 메모리/CPU 요청 및 제한을 컨테이너 런타임에 전달한다.
리눅스에서, 일반적으로 컨테이너 런타임은 적용될 커널 cgroup을 설정하고, 명시한 제한을 적용한다.
- CPU 제한은 해당 컨테이너가 사용할 수 있는 CPU 시간에 대한 강한 상한(hard ceiling)을 정의한다. 각 스케줄링 간격(시간 조각)마다, 리눅스 커널은 이 제한이 초과되었는지를 확인하고, 만약 초과되었다면 cgroup의 실행 재개를 허가하지 않고 기다린다.
- CPU 요청은 일반적으로 가중치 설정(weighting)을 정의한다. 현재 부하율이 높은 시스템에서 여러 개의 컨테이너(cgroup)가 실행되어야 하는 경우, 큰 CPU 요청값을 갖는 워크로드가 작은 CPU 요청값을 갖는 워크로드보다 더 많은 CPU 시간을 할당받는다.
- 메모리 요청은 주로 (쿠버네티스) 파드 스케줄링 과정에서 사용된다.
cgroup v2를 사용하는 노드에서, 컨테이너 런타임은 메모리 요청을 힌트로 사용하여
memory.min및memory.low을 설정할 수 있다. - 메모리 제한은 해당 cgroup에 대한 메모리 사용량 상한을 정의한다. 컨테이너가 제한보다 더 많은 메모리를 할당받으려고 시도하면, 리눅스 커널의 메모리 부족(out-of-memory) 서브시스템이 활성화되고 (일반적으로) 개입하여 메모리를 할당받으려고 했던 컨테이너의 프로세스 중 하나를 종료한다. 해당 프로세스의 PID가 1이고, 컨테이너가 재시작 가능(restartable)으로 표시되어 있으면, 쿠버네티스가 해당 컨테이너를 재시작한다.
- 파드 또는 컨테이너의 메모리 제한은 메모리 기반 볼륨(예:
emptyDir)의 페이지에도 적용될 수 있다. kubelet은tmpfsemptyDir 볼륨을 로컬 임시(ephemeral) 스토리지가 아닌 컨테이너 메모리 사용으로 간주하여 추적한다.
한 컨테이너가 메모리 요청을 초과하고 해당 노드의 메모리가 부족하지면, 해당 컨테이너가 속한 파드가 축출될 수 있다.
컨테이너가 비교적 긴 시간 동안 CPU 제한을 초과하는 것이 허용될 수도, 허용되지 않을 수도 있다. 그러나, 컨테이너 런타임은 과도한 CPU 사용률을 이유로 파드 또는 컨테이너를 종료시키지는 않는다.
리소스 제한으로 인해 컨테이너를 스케줄할 수 없는지 또는 종료 중인지 확인하려면, 문제 해결 섹션을 참조한다.
컴퓨트 및 메모리 리소스 사용량 모니터링
kubelet은 파드의 리소스 사용량을 파드
status에 포함하여 보고한다.
클러스터에서 선택적인 모니터링 도구를 사용할 수 있다면, 메트릭 API에서 직접 또는 모니터링 도구에서 파드 리소스 사용량을 검색할 수 있다.
로컬 임시(ephemeral) 스토리지
기능 상태:
Kubernetes v1.25 [stable]
노드에는 로컬에 연결된 쓰기 가능 장치 또는, 때로는 RAM에 의해 지원되는 로컬 임시 스토리지가 있다. "임시"는 내구성에 대한 장기간의 보증이 없음을 의미한다.
파드는 스크래치 공간, 캐싱 및 로그에 대해 임시 로컬 스토리지를 사용한다.
kubelet은 로컬 임시 스토리지를 사용하여 컨테이너에
emptyDir
볼륨을 마운트하기 위해 파드에 스크래치 공간을 제공할 수 있다.
kubelet은 이러한 종류의 스토리지를 사용하여 노드-레벨 컨테이너 로그, 컨테이너 이미지 및 실행 중인 컨테이너의 쓰기 가능 계층을 보유한다.
주의:
노드가 실패하면, 임시 스토리지의 데이터가 손실될 수 있다. 애플리케이션은 로컬 임시 스토리지에서 성능에 대한 SLA(예: 디스크 IOPS)를 기대할 수 없다.베타 기능에서, 쿠버네티스는 파드가 사용할 수 있는 임시 로컬 스토리지의 양을 추적, 예약 및 제한할 수 있도록 해준다.
로컬 임시 스토리지 구성
쿠버네티스는 노드에서 로컬 임시 스토리지를 구성하는 두 가지 방법을 지원한다.
이 구성에서, 모든 종류의 임시 로컬 데이터(emptyDir 볼륨,
쓰기 가능 계층, 컨테이너 이미지, 로그)를 하나의 파일시스템에 배치한다.
kubelet을 구성하는 가장 효과적인 방법은 이 파일시스템을 쿠버네티스(kubelet) 데이터 전용으로
하는 것이다.
kubelet은 또한 노드-레벨 컨테이너 로그를 작성하고 임시 로컬 스토리지와 유사하게 처리한다.
kubelet은 구성된 로그 디렉터리 내의 파일에 로그를 기록한다(기본적으로
/var/log). 그리고 로컬에 저장된 다른 데이터에 대한 기본 디렉터리가 있다(기본적으로
/var/lib/kubelet).
일반적으로, /var/lib/kubelet 와 /var/log 모두 시스템 루트 파일시스템에 위치하고,
그리고 kubelet은 이런 레이아웃을 염두에 두고 설계되었다.
노드는 쿠버네티스에서 사용하지 않는 다른 많은 파일시스템을 가질 수 있다.
사용하고 있는 노드에 실행 중인 파드에서 발생하는 임시 데이터를
위한 파일시스템을 가진다(로그와 emptyDir 볼륨). 이 파일시스템을
다른 데이터(예를 들어, 쿠버네티스와 관련없는 시스템 로그)를 위해 사용할 수 있다. 이 파일시스템은
루트 파일시스템일 수도 있다.
kubelet은 또한 노드-레벨 컨테이너 로그를 첫 번째 파일시스템에 기록하고, 임시 로컬 스토리지와 유사하게 처리한다.
또한 다른 논리 스토리지 장치가 지원하는 별도의 파일시스템을 사용한다. 이 구성에서, 컨테이너 이미지 계층과 쓰기 가능한 계층을 배치하도록 kubelet에 지시하는 디렉터리는 이 두 번째 파일시스템에 있다.
첫 번째 파일시스템에는 이미지 계층이나 쓰기 가능한 계층이 없다.
노드는 쿠버네티스에서 사용하지 않는 다른 많은 파일시스템을 가질 수 있다.
kubelet은 사용 중인 로컬 스토리지 양을 측정할 수 있다. 임시 볼륨(ephemeral storage)을 설정하기 위해 지원되는 구성 중 하나를 사용하여 노드를 설정한 경우 제공된다.
다른 구성을 사용하는 경우, kubelet은 임시 로컬 스토리지에 대한 리소스 제한을 적용하지 않는다.
참고:
kubelet은 로컬 임시 스토리지가 아닌 컨테이너 메모리 사용으로tmpfs emptyDir 볼륨을 추적한다.참고:
kubelet은 임시 스토리지을 위해 오직 루트 파일시스템만을 추적한다./var/lib/kubelet 혹은 /var/lib/containers에 대해 별도의 디스크를 마운트하는 OS 레이아웃은 임시 스토리지를 정확하게 보고하지 않을 것이다.로컬 임시 스토리지에 대한 요청 및 제한 설정
ephemeral-storage를 명시하여 로컬 임시 저장소를 관리할 수 있다.
파드의 각 컨테이너는 다음 중 하나 또는 모두를 명시할 수 있다.
spec.containers[].resources.limits.ephemeral-storagespec.containers[].resources.requests.ephemeral-storage
ephemeral-storage 에 대한 제한 및 요청은 바이트 단위로 측정된다.
E, P, T, G, M, k와 같은 접미사 중 하나를 사용하여 스토리지를 일반 정수 또는 고정 소수점 숫자로 표현할 수 있다.
Ei, Pi, Ti, Gi, Mi, Ki와 같은 2의 거듭제곱을 사용할 수도 있다.
예를 들어, 다음은 거의 동일한 값을 나타낸다.
128974848129e6129M123Mi
접미사의 대소문자에 유의한다.
400m의 메모리를 요청하면, 이는 0.4 바이트를 요청한 것이다.
이 사람은 아마도 400 메비바이트(mebibytes) (400Mi) 또는 400 메가바이트 (400M) 를 요청하고 싶었을 것이다.
다음 예에서, 파드에 두 개의 컨테이너가 있다.
각 컨테이너에는 2GiB의 로컬 임시 스토리지 요청이 있다.
각 컨테이너에는 4GiB의 로컬 임시 스토리지 제한이 있다.
따라서, 파드는 4GiB의 로컬 임시 스토리지 요청과 8GiB 로컬 임시 스토리지 제한을 가진다.
이 제한 중 500Mi까지는 emptyDir 볼륨에 의해 소진될 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
volumes:
- name: ephemeral
emptyDir:
sizeLimit: 500Mi
ephemeral-storage 요청이 있는 파드의 스케줄링 방법
파드를 생성할 때, 쿠버네티스 스케줄러는 파드를 실행할 노드를 선택한다. 각 노드에는 파드에 제공할 수 있는 최대 임시 스토리지 공간이 있다. 자세한 정보는, 노드 할당 가능을 참조한다.
스케줄러는 스케줄된 컨테이너의 리소스 요청 합계가 노드 용량보다 작도록 한다.
임시 스토리지 소비 관리
kubelet이 로컬 임시 스토리지를 리소스로 관리하는 경우, kubelet은 다음에서 스토리지 사용을 측정한다.
- tmpfs
emptyDir볼륨을 제외한emptyDir볼륨 - 노드-레벨 로그가 있는 디렉터리
- 쓰기 가능한 컨테이너 계층
허용하는 것보다 더 많은 임시 스토리지를 파드가 사용하는 경우, kubelet은 파드 축출을 트리거하는 축출 신호를 설정한다.
컨테이너-레벨 격리의 경우, 컨테이너의 쓰기 가능한 계층과 로그 사용량이 스토리지 제한을 초과하면, kubelet은 파드를 축출하도록 표시한다.
파드-레벨 격리에 대해 kubelet은 해당 파드의 컨테이너에 대한 제한을 합하여
전체 파드 스토리지 제한을 해결한다. 이 경우, 모든
컨테이너와 파드의 emptyDir 볼륨의 로컬 임시 스토리지 사용량 합계가
전체 파드 스토리지 제한을 초과하면, kubelet은 파드를 축출 대상으로
표시한다.
주의:
kubelet이 로컬 임시 스토리지를 측정하지 않는 경우, 로컬 스토리지 제한을 초과하는 파드는 로컬 스토리지 리소스 제한을 위반해도 축출되지 않는다.
그러나, 쓰기 가능한 컨테이너 계층, 노드-레벨 로그
또는 emptyDir 볼륨의 파일 시스템 공간이 부족하면, 로컬
스토리지가 부족하다고 노드 자체에 테인트되고
이로인해 특별히 이 테인트를 허용하지 않는 모든 파드를 축출하도록 트리거한다.
임시 로컬 스토리지에 대해 지원되는 구성을 참조한다.
kubelet은 파드 스토리지 사용을 측정하는 다양한 방법을 지원한다.
kubelet은 각 emptyDir 볼륨, 컨테이너 로그 디렉터리 및 쓰기 가능한 컨테이너 계층을
스캔하는 정기적인 스케줄 검사를 수행한다.
스캔은 사용된 공간의 양을 측정한다.
참고:
이 모드에서, kubelet은 삭제된 파일의 열린 파일 디스크립터를 추적하지 않는다.
여러분(또는 컨테이너)이 emptyDir 볼륨 안에 파일을 생성하면,
그 파일이 열리고, 파일이 열려있는 동안 파일을
삭제하면, 삭제된 파일의 inode는 해당 파일을 닫을 때까지
유지되지만 kubelet은 사용 중인 공간으로 분류하지 않는다.
기능 상태:
Kubernetes v1.15 [alpha]
프로젝트 쿼터는 파일시스템에서 스토리지 사용을 관리하기 위한 운영체제 레벨의 기능이다. 쿠버네티스를 사용하면, 스토리지 사용을 모니터링하기 위해 프로젝트 쿼터를 사용할 수 있다. 노드에서 'emptyDir' 볼륨을 지원하는 파일시스템이 프로젝트 쿼터 지원을 제공하는지 확인한다. 예를 들어, XFS와 ext4fs는 프로젝트 쿼터를 지원한다.
참고:
프로젝트 쿼터를 통해 스토리지 사용을 모니터링할 수 있다. 이는 제한을 강제하지 않는다.쿠버네티스는 1048576 부터 프로젝트 ID를 사용한다. 사용 중인 ID는
/etc/projects 와 /etc/projid 에 등록되어 있다. 이 범위의 프로젝트 ID가
시스템에서 다른 목적으로 사용되는 경우, 쿠버네티스가
이를 사용하지 않도록 해당 프로젝트 ID를 /etc/projects 와 /etc/projid 에
등록해야 한다.
쿼터는 디렉터리 검색보다 빠르고 정확하다. 디렉터리가 프로젝트에 할당되면, 디렉터리 아래에 생성된 모든 파일이 해당 프로젝트에 생성되며, 커널은 해당 프로젝트의 파일에서 사용 중인 블록 수를 추적하기만 하면 된다. 파일이 생성되고 삭제되었지만, 열린 파일 디스크립터가 있으면, 계속 공간을 소비한다. 쿼터 추적은 공간을 정확하게 기록하는 반면 디렉터리 스캔은 삭제된 파일이 사용한 스토리지를 간과한다.
프로젝트 쿼터를 사용하려면, 다음을 수행해야 한다.
-
kubelet 구성의
featureGates필드 또는--feature-gates커맨드 라인 플래그를 사용하여LocalStorageCapacityIsolationFSQuotaMonitoring=true기능 게이트를 활성화한다. -
루트 파일시스템(또는 선택적인 런타임 파일시스템)에 프로젝트 쿼터가 활성화되어 있는지 확인한다. 모든 XFS 파일시스템은 프로젝트 쿼터를 지원한다. ext4 파일시스템의 경우, 파일시스템이 마운트되지 않은 상태에서 프로젝트 쿼터 추적 기능을 활성화해야 한다.
# ext4인 /dev/block-device가 마운트되지 않은 경우 sudo tune2fs -O project -Q prjquota /dev/block-device -
루트 파일시스템(또는 선택적인 런타임 파일시스템)은 프로젝트 쿼터를 활성화한 상태에서 마운트해야 힌다. XFS와 ext4fs 모두에서, 마운트 옵션의 이름은
prjquota이다.
확장된 리소스
확장된 리소스는 kubernetes.io 도메인 외부의 전체 주소(fully-qualified)
리소스 이름이다. 쿠버네티스에 내장되지 않은 리소스를 클러스터 운영자가 알리고
사용자는 사용할 수 있다.
확장된 리소스를 사용하려면 두 단계가 필요한다. 먼저, 클러스터 운영자는 확장된 리소스를 알려야 한다. 둘째, 사용자는 파드의 확장된 리소스를 요청해야 한다.
확장된 리소스 관리
노드-레벨의 확장된 리소스
노드-레벨의 확장된 리소스는 노드에 연결된다.
장치 플러그인 관리 리소스
각 노드에서 장치 플러그인 관리 리소스를 알리는 방법은 장치 플러그인을 참조한다.
기타 리소스
새로운 노드-레벨의 확장된 리소스를 알리기 위해, 클러스터 운영자는
API 서버에 PATCH HTTP 요청을 제출하여 클러스터의
노드에 대해 status.capacity 에서 사용할 수 있는 수량을 지정할 수 있다. 이 작업
후에는, 노드의 status.capacity 에 새로운 리소스가 포함된다. 이
status.allocatable 필드는 kubelet에 의해 비동기적으로 새로운
리소스로 자동 업데이트된다.
스케줄러가 파드 적합성을 평가할 때 노드의 status.allocatable 값을 사용하므로,
스케줄러는 해당 비동기 업데이트 이후의 새로운 값만을 고려한다.
따라서 노드 용량을 새 리소스로 패치하는 시점과
해당 자원을 요청하는 첫 파드가 해당 노드에 스케줄될 수 있는 시점 사이에
약간의 지연이 있을 수 있다.
예제:
다음은 curl 을 사용하여 마스터가 k8s-master 인 노드 k8s-node-1 에
5개의 "example.com/foo" 리소스를 알리는 HTTP 요청을 구성하는 방법을
보여주는 예이다.
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/status
참고:
앞의 요청에서,~1 은 패치 경로에서 문자 / 의
인코딩이다. JSON-Patch의 작업 경로 값은
JSON-Pointer로 해석된다. 더 자세한 내용은,
IETF RFC 6901, 섹션 3을 참조한다.클러스터-레벨의 확장된 리소스
클러스터-레벨의 확장된 리소스는 노드에 연결되지 않는다. 이들은 일반적으로 리소스 소비와 리소스 쿼터를 처리하는 스케줄러 익스텐더(extender)에 의해 관리된다.
스케줄러 구성에서 스케줄러 익스텐더가 처리하는 확장된 리소스를 지정할 수 있다.
예제:
스케줄러 정책에 대한 다음의 구성은 클러스터-레벨의 확장된 리소스 "example.com/foo"가 스케줄러 익스텐더에 의해 처리됨을 나타낸다.
- 파드가 "example.com/foo"를 요청하는 경우에만 스케줄러가 파드를 스케줄러 익스텐더로 보낸다.
- 이
ignoredByScheduler필드는 스케줄러가PodFitsResources속성에서 "example.com/foo" 리소스를 확인하지 않도록 지정한다.
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix":"<extender-endpoint>",
"bindVerb": "bind",
"managedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}
확장된 리소스 소비
사용자는 CPU와 메모리 같은 파드 스펙의 확장된 리소스를 사용할 수 있다. 스케줄러는 리소스 어카운팅(resource accounting)을 관리하여 사용 가능한 양보다 많은 양의 리소스가 여러 파드에 동시에 할당되지 않도록 한다.
API 서버는 확장된 리소스의 수량을 정수로 제한한다.
유효한 수량의 예로는 3, 3000m 그리고 3Ki 를 들 수 있다. 유효하지 않은
수량의 예는 0.5 와 1500m 이다.
참고:
확장된 리소스는 불명확한 정수 리소스를 대체한다. 사용자는 예약된kubernetes.io 이외의 모든 도메인 이름 접두사를 사용할 수 있다.파드에서 확장된 리소스를 사용하려면, 컨테이너 사양에서 spec.containers[].resources.limits
맵에 리소스 이름을 키로 포함한다.
참고:
확장된 리소스는 오버커밋할 수 없으므로, 컨테이너 사양에 둘 다 있으면 요청과 제한이 동일해야 한다.파드는 CPU, 메모리 및 확장된 리소스를 포함하여 모든 리소스 요청이
충족되는 경우에만 예약된다. 리소스 요청을 충족할 수 없다면
파드는 PENDING 상태를 유지한다.
예제:
아래의 파드는 2개의 CPU와 1개의 "example.com/foo"(확장된 리소스)를 요청한다.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: myimage
resources:
requests:
cpu: 2
example.com/foo: 1
limits:
example.com/foo: 1
PID 제한
프로세스 ID(PID) 제한은 kubelet의 구성에 대해 주어진 파드가 사용할 수 있는 PID 수를 제한할 수 있도록 허용한다. 자세한 내용은 PID 제한을 참고한다.
문제 해결
내 파드가 FailedScheduling 이벤트 메시지로 보류 중이다
파드가 배치될 수 있는 노드를 스케줄러가 찾을 수 없으면,
노드를 찾을 수 있을 때까지 파드는 스케줄되지 않은 상태로 유지한다.
파드가 할당될 곳을 스케줄러가 찾지 못하면
Event가 생성된다.
다음과 같이 kubectl을 사용하여 파드의 이벤트를 볼 수 있다.
kubectl describe pod frontend | grep -A 9999999999 Events
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 23s default-scheduler 0/42 nodes available: insufficient cpu
위의 예에서, 모든 노드의 CPU 리소스가 충분하지 않아 이름이 "frontend"인 파드를 스케줄하지 못했다. 비슷한 메시지로 메모리 부족(PodExceedsFreeMemory)으로 인한 장애도 알릴 수 있다. 일반적으로, 파드가 이 타입의 메시지로 보류 중인 경우, 몇 가지 시도해 볼 것들이 있다.
- 클러스터에 더 많은 노드를 추가한다.
- 불필요한 파드를 종료하여 보류 중인 파드를 위한 공간을 확보한다.
- 파드가 모든 노드보다 크지 않은지 확인한다. 예를 들어, 모든
노드의 용량이
cpu: 1인 경우,cpu: 1.1요청이 있는 파드는 절대 스케줄되지 않는다. - 노드 테인트를 확인한다. 대부분의 노드에 테인트가 걸려 있고, 신규 파드가 해당 테인트에 배척된다면, 스케줄러는 해당 테인트가 걸려 있지 않은 나머지 노드에만 배치를 고려할 것이다.
kubectl describe nodes 명령으로 노드 용량과 할당된 양을
확인할 수 있다. 예를 들면, 다음과 같다.
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... 명확하게 하기 위해 라인들을 제거함 ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... 명확하게 하기 위해 라인들을 제거함 ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi (0%) 100Mi (1%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (11%) 1070Mi (13%)
위의 출력에서, 1.120 이상의 CPU 또는 6.23 Gi 이상의 메모리를 요청하는 파드는 노드에 할당될 수 없음을 확인할 수 있다.
"Pods" 섹션을 살펴보면, 어떤 파드가 노드에서 공간을 차지하고 있는지를 볼 수 있다.
사용 가능한 리소스의 일부를 시스템 데몬이 사용하기 때문에,
파드에 사용 가능한 리소스의 양은 노드 총 용량보다 적다.
쿠버네티스 API에서, 각 노드는 .status.allocatable 필드(상세 사항은
NodeStatus 참조)를
갖는다.
.status.allocatable 필드는 해당 노드에서 파드가 사용할 수 있는
리소스의 양을 표시한다(예: 15 vCPUs 및 7538 MiB 메모리).
쿠버네티스의 노드 할당 가능 리소스에 대한 상세 사항은
시스템 데몬을 위한 컴퓨트 자원 예약하기를 참고한다.
리소스 쿼터를 설정하여, 한 네임스페이스가 사용할 수 있는 리소스 총량을 제한할 수 있다. 특정 네임스페이스 내에 ResourceQuota가 설정되어 있으면 쿠버네티스는 오브젝트에 대해 해당 쿼터를 적용한다. 예를 들어, 각 팀에 네임스페이스를 할당한다면, 각 네임스페이스에 ResourceQuota를 설정할 수 있다. 리소스 쿼터를 설정함으로써 한 팀이 지나치게 많은 리소스를 사용하여 다른 팀에 영향을 주는 것을 막을 수 있다.
해당 네임스페이스에 어떤 접근을 허용할지도 고려해야 한다. 네임스페이스에 대한 완전한 쓰기 권한을 가진 사람은 어떠한 리소스(네임스페이스에 설정된 ResourceQuota 포함)라도 삭제할 수 있다.
내 컨테이너가 종료되었다
리소스가 부족하여 컨테이너가 종료될 수 있다. 리소스
제한에 도달하여 컨테이너가 종료되고 있는지 확인하려면,
관심있는 파드에 대해 kubectl describe pod 를 호출한다.
kubectl describe pod simmemleak-hra99
출력은 다음과 같다.
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Containers:
simmemleak:
Image: saadali/simmemleak:latest
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2019 12:54:41 -0700
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 07 Jul 2019 12:54:30 -0700
Finished: Fri, 07 Jul 2019 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 42s default-scheduler Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Normal Pulled 41s kubelet Container image "saadali/simmemleak:latest" already present on machine
Normal Created 41s kubelet Created container simmemleak
Normal Started 40s kubelet Started container simmemleak
Normal Killing 32s kubelet Killing container with id ead3fb35-5cf5-44ed-9ae1-488115be66c6: Need to kill Pod
앞의 예제에서, Restart Count: 5 표시는 파드의 simmemleak
컨테이너가 종료되고 (지금까지) 5번 다시 시작되었음을 나타낸다.
Reason: OOMKilled를 통해 컨테이너가 제한보다 많은 양의 메모리를 사용하려고 했다는 것을 확인할 수 있다.
다음 단계로 메모리 누수가 있는지 애플리케이션 코드를 확인해 볼 수 있다. 애플리케이션이 예상한 대로 동작하는 것을 확인했다면, 해당 컨테이너의 메모리 제한(및 요청)을 더 높게 설정해 본다.
다음 내용
- 컨테이너와 파드에 메모리 리소스를 할당하는 핸즈온 경험을 해보자.
- 컨테이너와 파드에 CPU 리소스를 할당하는 핸즈온 경험을 해보자.
- API 레퍼런스에 컨테이너와 컨테이너 리소스 요구사항이 어떻게 정의되어 있는지 확인한다.
- XFS의 프로젝트 쿼터에 대해 읽어보기
- kube-scheduler 정책 레퍼런스 (v1beta3)에 대해 더 읽어보기
8.5 - kubeconfig 파일을 사용하여 클러스터 접근 구성하기
kubeconfig 파일들을 사용하여 클러스터, 사용자, 네임스페이스 및 인증 메커니즘에 대한 정보를 관리하자.
kubectl 커맨드라인 툴은 kubeconfig 파일을 사용하여
클러스터의 선택과
클러스터의 API 서버와의 통신에 필요한 정보를 찾는다.
참고:
클러스터에 대한 접근을 구성하는 데 사용되는 파일을 kubeconfig 파일 이라 한다. 이는 구성 파일을 참조하는 일반적인 방법을 의미한다.kubeconfig라는 이름의 파일이 있다는 의미는 아니다.경고:
신뢰할 수 있는 소스의 kubeconfig 파일만 사용한다. 특수 제작된 kubeconfig 파일을 사용하면 악성 코드가 실행되거나 파일이 노출될 수 있다. 신뢰할 수 없는 kubeconfig 파일을 사용해야 하는 경우 셸 스크립트를 사용하는 경우처럼 먼저 신중하게 검사한다.기본적으로 kubectl은 $HOME/.kube 디렉터리에서 config라는 이름의 파일을 찾는다.
KUBECONFIG 환경 변수를 설정하거나
--kubeconfig 플래그를 지정해서
다른 kubeconfig 파일을 사용할 수 있다.
kubeconfig 파일을 생성하고 지정하는 단계별 지시사항은 다중 클러스터로 접근 구성하기를 참조한다.
다중 클러스터, 사용자와 인증 메커니즘 지원
여러 클러스터가 있고, 사용자와 구성 요소가 다양한 방식으로 인증한다고 가정하자. 예를 들면 다음과 같다.
- 실행 중인 kubelet은 인증서를 이용하여 인증할 수 있다.
- 사용자는 토큰으로 인증할 수 있다.
- 관리자는 개별 사용자에게 제공하는 인증서 집합을 가지고 있다.
kubeconfig 파일을 사용하면 클러스터와 사용자와 네임스페이스를 구성할 수 있다. 또한 컨텍스트를 정의하여 빠르고 쉽게 클러스터와 네임스페이스 간에 전환할 수 있다.
컨텍스트
kubeconfig에서 컨텍스트 요소는 편리한 이름으로 접속 매개 변수를 묶는데 사용한다.
각 컨텍스트는 클러스터, 네임스페이스와 사용자라는 세 가지 매개 변수를 가진다.
기본적으로 kubectl 커맨드라인 툴은 현재 컨텍스트 의 매개 변수를
사용하여 클러스터와 통신한다.
현재 컨택스트를 선택하려면 다음을 실행한다.
kubectl config use-context
KUBECONFIG 환경 변수
KUBECONFIG 환경 변수는 kubeconfig 파일 목록을 보유한다.
리눅스 및 Mac의 경우 이는 콜론(:)으로 구분된 목록이다.
윈도우는 세미콜론(;)으로 구분한다. KUBECONFIG 환경 변수가 필수는 아니다.
KUBECONFIG 환경 변수가 없으면,
kubectl은 기본 kubeconfig 파일인 $HOME/.kube/config를 사용한다.
KUBECONFIG 환경 변수가 존재하면, kubectl은
KUBECONFIG 환경 변수에 나열된 파일을 병합한 결과 형태의
효과적 구성을 이용한다.
kubeconfig 파일 병합
구성을 보려면, 다음 커맨드를 입력한다.
kubectl config view
앞서 설명한 것처럼, 이 출력 내용은 단일 kubeconfig 파일이나 여러 kubeconfig 파일을 병합한 결과 일 수 있다.
다음은 kubeconfig 파일을 병합할 때에 kubectl에서 사용하는 규칙이다.
-
--kubeconfig플래그를 설정했으면, 지정한 파일만 사용한다. 병합하지 않는다. 이 플래그는 오직 한 개 인스턴스만 허용한다.그렇지 않고,
KUBECONFIG환경 변수를 설정하였다면 병합해야 하는 파일의 목록으로 사용한다.KUBECONFIG환경 변수의 나열된 파일은 다음 규칙에 따라 병합한다.- 빈 파일명은 무시한다.
- 역 직렬화 불가한 파일 내용에 대해서 오류를 일으킨다.
- 특정 값이나 맵 키를 설정한 첫 번째 파일을 우선한다.
- 값이나 맵 키를 변경하지 않는다.
예:
현재 컨텍스트를 설정할 첫 번째 파일의 컨택스트를 유지한다. 예: 두 파일이red-user를 지정했다면, 첫 번째 파일의red-user값만을 사용한다. 두 번째 파일의red-user하위에 충돌하지 않는 항목이 있어도 버린다.
KUBECONFIG환경 변수 설정의 예로, KUBECONFIG 환경 변수 설정를 참조한다.그렇지 않다면, 병합하지 않고 기본 kubeconfig 파일인
$HOME/.kube/config를 사용한다. -
이 체인에서 첫 번째를 기반으로 사용할 컨텍스트를 결정한다.
- 커맨드라인 플래그의
--context를 사용한다. - 병합된 kubeconfig 파일에서
current-context를 사용한다.
이 시점에서는 빈 컨텍스트도 허용한다.
- 커맨드라인 플래그의
-
클러스터와 사용자를 결정한다. 이 시점에서는 컨텍스트가 있을 수도 있고 없을 수도 있다. 사용자에 대해 한 번, 클러스터에 대해 한 번 총 두 번에 걸친 이 체인에서 첫 번째 것을 기반으로 클러스터와 사용자를 결정한다.
- 커맨드라인 플래그가 존재하면,
--user또는--cluster를 사용한다. - 컨텍스트가 비어있지 않다면, 컨텍스트에서 사용자 또는 클러스터를 가져온다.
이 시점에서는 사용자와 클러스터는 비워둘 수 있다.
- 커맨드라인 플래그가 존재하면,
-
사용할 실제 클러스터 정보를 결정한다. 이 시점에서 클러스터 정보가 있을 수 있고 없을 수도 있다. 이 체인을 기반으로 클러스터 정보를 구축한다. 첫 번째 것을 사용한다.
- 커맨드라인 플래그가 존재하면,
--server,--certificate-authority,--insecure-skip-tls-verify를 사용한다. - 병합된 kubeconfig 파일에서 클러스터 정보 속성이 있다면 사용한다.
- 서버 위치가 없다면 실패한다.
- 커맨드라인 플래그가 존재하면,
-
사용할 실제 사용자 정보를 결정한다. 사용자 당 하나의 인증 기법만 허용하는 것을 제외하고는 클러스터 정보와 동일한 규칙을 사용하여 사용자 정보를 작성한다.
- 커맨드라인 플래그가 존재하면,
--client-certificate,--client-key,--username,--password,--token을 사용한다. - 병합된 kubeconfig 파일에서
user필드를 사용한다. - 충돌하는 두 가지 기법이 있다면 실패한다.
- 커맨드라인 플래그가 존재하면,
-
여전히 누락된 정보는 기본 값을 사용하고 인증 정보를 묻는 메시지가 표시될 수 있다.
파일 참조
kubeconfig 파일에서 파일과 경로 참조는 kubeconfig 파일의 위치와 관련 있다.
커맨드라인 상에 파일 참조는 현재 디렉터리를 기준으로 한다.
$HOME/.kube/config에서 상대 경로는 상대적으로, 절대 경로는
절대적으로 저장한다.
프록시
다음과 같이 kubeconfig 파일에서 proxy-url를 사용하여 kubectl이 각 클러스터마다 프록시를 거치도록 설정할 수 있다.
apiVersion: v1
kind: Config
clusters:
- cluster:
proxy-url: http://proxy.example.org:3128
server: https://k8s.example.org/k8s/clusters/c-xxyyzz
name: development
users:
- name: developer
contexts:
- context:
name: development
다음 내용
8.6 - 윈도우 노드의 자원 관리
이 페이지는 리눅스와 윈도우 간에 리소스를 관리하는 방법의 차이점을 간략하게 설명한다.
리눅스 노드에서, cgroup이 리소스 제어를 위한 파드 경계로서 사용된다. 컨테이너는 네트워크, 프로세스 및 파일시스템 격리를 위해 해당 경계 내에 생성된다. cpu/io/memory 통계를 수집하기 위해 cgroup API를 사용할 수 있다.
반대로, 윈도우는 시스템 네임스페이스 필터와 함께 컨테이너별로 잡(job) 오브젝트를 사용하여 모든 프로세스를 컨테이너 안에 포함시키고 호스트와의 논리적 격리를 제공한다. (잡 오브젝트는 윈도우의 프로세스 격리 메커니즘이며 쿠버네티스의 잡(Job)과는 다른 것이다.)
네임스페이스 필터링 없이 윈도우 컨테이너를 실행할 수 있는 방법은 없다. 이는 곧 시스템 권한은 호스트 입장에서 주장할(assert) 수 없고, 이로 인해 특권을 가진(privileged) 컨테이너는 윈도우에서 사용할 수 없음을 의미한다. 또한 보안 계정 매니저(Security Account Manager, SAM)가 분리되어 있으므로 컨테이너는 호스트의 ID를 가정(assume)할 수 없다.
메모리 관리
윈도우에는 리눅스에는 있는 메모리 부족 프로세스 킬러가 없다. 윈도우는 모든 사용자 모드 메모리 할당을 항상 가상 메모리처럼 처리하며, 페이지파일(pagefile)이 필수이다.
윈도우 노드는 프로세스를 위해 메모리를 오버커밋(overcommit)하지 않는다. 이로 인해 윈도우는 메모리 컨디션에 도달하는 방식이 리눅스와 다르며, 프로세스는 메모리 부족(OOM, out of memory) 종료를 겪는 대신 디스크에 페이징을 수행한다. 메모리가 오버프로비저닝(over-provision)되고 전체 물리 메모리가 고갈되면, 페이징으로 인해 성능이 저하될 수 있다.
CPU 관리
윈도우는 각 프로세스에 할당되는 CPU 시간의 양을 제한할 수는 있지만, CPU 시간의 최소량을 보장하지는 않는다.
윈도우에서, kubelet은 kubelet 프로세스의
스케줄링 우선 순위를 설정하기 위한 명령줄 플래그인
--windows-priorityclass를 지원한다.
이 플래그를 사용하면 윈도우 호스트에서 실행되는 kubelet 프로세스가 다른 프로세스보다 더 많은 CPU 시간 슬라이스를 할당받는다.
할당 가능한 값 및 각각의 의미에 대한 자세한 정보는
윈도우 프라이어리티 클래스에서 확인할 수 있다.
실행 중인 파드가 kubelet의 CPU 사이클을 빼앗지 않도록 하려면, 이 플래그를 ABOVE_NORMAL_PRIORITY_CLASS 이상으로 설정한다.
리소스 예약
운영 체제, 컨테이너 런타임, 그리고 kubelet과 같은 쿠버네티스 호스트 프로세스가 사용하는 메모리 및 CPU를 고려하기 위해,
kubelet 플래그 --kube-reserved 및 --system-reserved를 사용하여
메모리 및 CPU 리소스의 예약이 가능하다 (그리고 필요하다).
윈도우에서 이들 값은 노드의
할당 가능(allocatable) 리소스의 계산에만 사용된다.
주의:
워크로드를 배포할 때, 컨테이너에 메모리 및 CPU 리소스 제한을 걸자. 이 또한 NodeAllocatable에서 차감되며, 클러스터 수준 스케줄러가 각 파드를 어떤 노드에 할당할지 결정하는 데 도움을 준다.
제한을 설정하지 않은 파드를 스케줄링하면 윈도우 노드가 오버프로비전될 수 있으며, 극단적인 경우 노드가 비정상 상태(unhealthy)로 될 수도 있다.
윈도우에서는, 메모리를 최소 2GB 이상 예약하는 것이 좋다.
얼마나 많은 양의 CPU를 예약할지 결정하기 위해, 각 노드의 최대 파드 수를 확인하고 해당 노드의 시스템 서비스의 CPU 사용량을 모니터링한 뒤, 워크로드 요구사항을 충족하는 값을 선택한다.
9 - 보안
클라우드 네이티브 워크로드를 안전하게 유지하기 위한 개념
9.1 - 클라우드 네이티브 보안 개요
클라우드 네이티브 보안 관점에서 쿠버네티스 보안을 생각해보기 위한 모델
이 개요는 클라우드 네이티브 보안의 맥락에서 쿠버네티스 보안에 대한 생각의 모델을 정의한다.
경고:
이 컨테이너 보안 모델은 입증된 정보 보안 정책이 아닌 제안 사항을 제공한다.클라우드 네이티브 보안의 4C
보안은 계층으로 생각할 수 있다. 클라우드 네이티브 보안의 4C는 클라우드(Cloud), 클러스터(Cluster), 컨테이너(Container)와 코드(Code)이다.
참고:
이 계층화된 접근 방식은 보안에 대한 심층 방어 컴퓨팅 접근 방식을 강화하며, 소프트웨어 시스템의 보안을 위한 모범 사례로 널리 알려져 있다.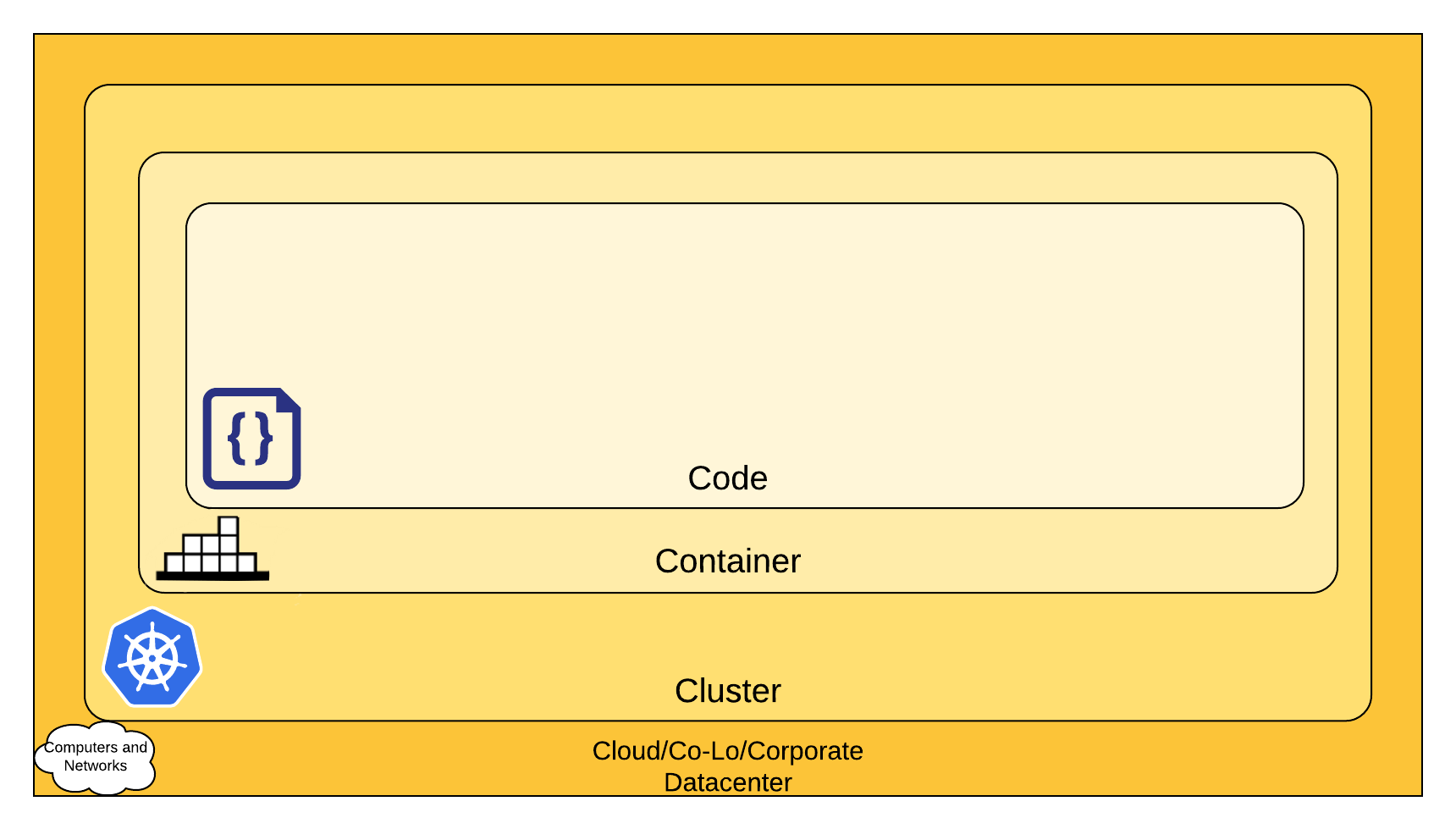
클라우드 네이티브 보안의 4C
클라우드 네이티브 보안 모델의 각 계층은 다음의 가장 바깥쪽 계층을 기반으로 한다. 코드 계층은 강력한 기본(클라우드, 클러스터, 컨테이너) 보안 계층의 이점을 제공한다. 코드 수준에서 보안을 처리하여 기본 계층의 열악한 보안 표준을 보호할 수 없다.
클라우드
여러 면에서 클라우드(또는 공동 위치 서버, 또는 기업의 데이터 센터)는 쿠버네티스 클러스터 구성을 위한 신뢰 컴퓨팅 기반(trusted computing base) 이다. 클라우드 계층이 취약하거나 취약한 방식으로 구성된 경우 이 기반 위에서 구축된 구성 요소가 안전하다는 보장은 없다. 각 클라우드 공급자는 해당 환경에서 워크로드를 안전하게 실행하기 위한 보안 권장 사항을 제시한다.
클라우드 공급자 보안
자신의 하드웨어 또는 다른 클라우드 공급자에서 쿠버네티스 클러스터를 실행 중인 경우, 보안 모범 사례는 설명서를 참고한다. 다음은 인기있는 클라우드 공급자의 보안 문서 중 일부에 대한 링크이다.
| IaaS 공급자 | 링크 |
|---|---|
| Alibaba Cloud | https://www.alibabacloud.com/trust-center |
| Amazon Web Services | https://aws.amazon.com/security |
| Google Cloud Platform | https://cloud.google.com/security |
| Huawei Cloud | https://www.huaweicloud.com/securecenter/overallsafety |
| IBM Cloud | https://www.ibm.com/cloud/security |
| Microsoft Azure | https://docs.microsoft.com/en-us/azure/security/azure-security |
| Oracle Cloud Infrastructure | https://www.oracle.com/security |
| VMware vSphere | https://www.vmware.com/security/hardening-guides.html |
인프라스트럭처 보안
쿠버네티스 클러스터에서 인프라 보안을 위한 제안은 다음과 같다.
| 쿠버네티스 인프라에서 고려할 영역 | 추천 |
|---|---|
| API 서버에 대한 네트워크 접근(컨트롤 플레인) | 쿠버네티스 컨트롤 플레인에 대한 모든 접근은 인터넷에서 공개적으로 허용되지 않으며 클러스터 관리에 필요한 IP 주소 집합으로 제한된 네트워크 접근 제어 목록에 의해 제어된다. |
| 노드에 대한 네트워크 접근(노드) | 지정된 포트의 컨트롤 플레인에서 만 (네트워크 접근 제어 목록을 통한) 연결을 허용하고 NodePort와 LoadBalancer 유형의 쿠버네티스 서비스에 대한 연결을 허용하도록 노드를 구성해야 한다. 가능하면 이러한 노드가 공용 인터넷에 완전히 노출되어서는 안된다. |
| 클라우드 공급자 API에 대한 쿠버네티스 접근 | 각 클라우드 공급자는 쿠버네티스 컨트롤 플레인 및 노드에 서로 다른 권한 집합을 부여해야 한다. 관리해야하는 리소스에 대해 최소 권한의 원칙을 따르는 클라우드 공급자의 접근 권한을 클러스터에 구성하는 것이 가장 좋다. Kops 설명서는 IAM 정책 및 역할에 대한 정보를 제공한다. |
| etcd에 대한 접근 | etcd(쿠버네티스의 데이터 저장소)에 대한 접근은 컨트롤 플레인으로만 제한되어야 한다. 구성에 따라 TLS를 통해 etcd를 사용해야 한다. 자세한 내용은 etcd 문서에서 확인할 수 있다. |
| etcd 암호화 | 가능한 한 모든 스토리지를 암호화하는 것이 좋은 방법이며, etcd는 전체 클러스터(시크릿 포함)의 상태를 유지하고 있기에 특히 디스크는 암호화되어 있어야 한다. |
클러스터
쿠버네티스 보안에는 다음의 두 가지 영역이 있다.
- 설정 가능한 클러스터 컴포넌트의 보안
- 클러스터에서 실행되는 애플리케이션의 보안
클러스터의 컴포넌트
우발적이거나 악의적인 접근으로부터 클러스터를 보호하고, 모범 사례에 대한 정보를 채택하기 위해서는 클러스터 보안에 대한 조언을 읽고 따른다.
클러스터 내 컴포넌트(애플리케이션)
애플리케이션의 공격 영역에 따라, 보안의 특정 측면에 중점을 둘 수 있다. 예를 들어, 다른 리소스 체인에 중요한 서비스(서비스 A)와 리소스 소진 공격에 취약한 별도의 작업 부하(서비스 B)를 실행하는 경우, 서비스 B의 리소스를 제한하지 않으면 서비스 A가 손상될 위험이 높다. 다음은 쿠버네티스에서 실행되는 워크로드를 보호하기 위한 보안 문제 및 권장 사항이 나와 있는 표이다.
| 워크로드 보안에서 고려할 영역 | 추천 |
|---|---|
| RBAC 인증(쿠버네티스 API에 대한 접근) | https://kubernetes.io/docs/reference/access-authn-authz/rbac/ |
| 인증 | https://kubernetes.io/ko/docs/concepts/security/controlling-access/ |
| 애플리케이션 시크릿 관리(및 유휴 상태에서의 etcd 암호화 등) | https://kubernetes.io/ko/docs/concepts/configuration/secret/ https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/ |
| 파드가 파드 시큐리티 폴리시를 만족하는지 확인하기 | https://kubernetes.io/docs/concepts/security/pod-security-standards/#policy-instantiation |
| 서비스 품질(및 클러스터 리소스 관리) | https://kubernetes.io/ko/docs/tasks/configure-pod-container/quality-service-pod/ |
| 네트워크 정책 | https://kubernetes.io/ko/docs/concepts/services-networking/network-policies/ |
| 쿠버네티스 인그레스를 위한 TLS | https://kubernetes.io/ko/docs/concepts/services-networking/ingress/#tls |
컨테이너
컨테이너 보안은 이 가이드의 범위를 벗어난다. 다음은 일반적인 권장사항과 이 주제에 대한 링크이다.
| 컨테이너에서 고려할 영역 | 추천 |
|---|---|
| 컨테이너 취약점 스캔 및 OS에 종속적인 보안 | 이미지 빌드 단계의 일부로 컨테이너에 알려진 취약점이 있는지 검사해야 한다. |
| 이미지 서명 및 시행 | 컨테이너 이미지에 서명하여 컨테이너의 내용에 대한 신뢰 시스템을 유지한다. |
| 권한있는 사용자의 비허용 | 컨테이너를 구성할 때 컨테이너의 목적을 수행하는데 필요한 최소 권한을 가진 사용자를 컨테이너 내에 만드는 방법에 대해서는 설명서를 참조한다. |
| 더 강력한 격리로 컨테이너 런타임 사용 | 더 강력한 격리를 제공하는 컨테이너 런타임 클래스를 선택한다. |
코드
애플리케이션 코드는 가장 많은 제어를 할 수 있는 주요 공격 영역 중 하나이다. 애플리케이션 코드 보안은 쿠버네티스 보안 주제를 벗어나지만, 애플리케이션 코드를 보호하기 위한 권장 사항은 다음과 같다.
코드 보안
| 코드에서 고려할 영역 | 추천 |
|---|---|
| TLS를 통한 접근 | 코드가 TCP를 통해 통신해야 한다면, 미리 클라이언트와 TLS 핸드 셰이크를 수행한다. 몇 가지 경우를 제외하고, 전송 중인 모든 것을 암호화한다. 한 걸음 더 나아가, 서비스 간 네트워크 트래픽을 암호화하는 것이 좋다. 이것은 인증서를 가지고 있는 두 서비스의 양방향 검증을 실행하는 mTLS(상호 TLS 인증)를 통해 수행할 수 있다. |
| 통신 포트 범위 제한 | 이 권장사항은 당연할 수도 있지만, 가능하면 통신이나 메트릭 수집에 꼭 필요한 서비스의 포트만 노출시켜야 한다. |
| 타사 종속성 보안 | 애플리케이션의 타사 라이브러리를 정기적으로 스캔하여 현재 알려진 취약점이 없는지 확인하는 것이 좋다. 각 언어에는 이런 검사를 자동으로 수행하는 도구를 가지고 있다. |
| 정적 코드 분석 | 대부분 언어에는 잠재적으로 안전하지 않은 코딩 방법에 대해 코드 스니펫을 분석할 수 있는 방법을 제공한다. 가능한 언제든지 일반적인 보안 오류에 대해 코드베이스를 스캔할 수 있는 자동화된 도구를 사용하여 검사를 한다. 도구는 다음에서 찾을 수 있다. https://owasp.org/www-community/Source_Code_Analysis_Tools |
| 동적 탐지 공격 | 잘 알려진 공격 중 일부를 서비스에 테스트할 수 있는 자동화된 몇 가지 도구가 있다. 여기에는 SQL 인젝션, CSRF 및 XSS가 포함된다. 가장 널리 사용되는 동적 분석 도구는 OWASP Zed Attack 프록시이다. |
다음 내용
쿠버네티스 보안 주제에 관련한 내용들을 배워보자.
9.2 - 파드 시큐리티 스탠다드
파드 시큐리티 스탠다드에 정의된 여러 가지 정책 레벨에 대한 세부사항
파드 시큐리티 스탠다드에서는 보안 범위를 넓게 다루기 위해 세 가지 정책을 정의한다. 이러한 정책은 점증적이며 매우 허용적인 것부터 매우 제한적인 것까지 있다. 이 가이드는 각 정책의 요구사항을 간략히 설명한다.
| 프로필 | 설명 |
|---|---|
| 특권(Privileged) | 무제한 정책으로, 가장 넓은 범위의 권한 수준을 제공한다. 이 정책은 알려진 권한 상승(privilege escalations)을 허용한다. |
| 기본(Baseline) | 알려진 권한 상승을 방지하는 최소한의 제한 정책이다. 기본(최소로 명시된) 파드 구성을 허용한다. |
| 제한(Restricted) | 엄격히 제한된 정책으로 현재 파드 하드닝 모범 사례를 따른다. |
프로필 세부사항
특권(Privileged)
특권 정책은 의도적으로 열려있으며 전적으로 제한이 없다. 이러한 종류의 정책은 권한이 있고 신뢰할 수 있는 사용자가 관리하는 시스템 및 인프라 수준의 워크로드를 대상으로 한다.
특권 정책은 제한 사항이 없는 것으로 정의한다. 기본으로 허용하는 메커니즘(예를 들면, gatekeeper)은 당연히 특권 정책일 수 있다. 반대로, 기본적으로 거부하는 메커니즘(예를 들면, 파드 시큐리티 폴리시)의 경우 특권 정책은 모든 제한 사항을 비활성화해야 한다.
기본(Baseline)
기본 정책은 알려진 권한 상승을 방지하면서 일반적인 컨테이너 워크로드에 대해 정책 채택을 쉽게 하는 것을 목표로 한다. 이 정책은 일반적인(non-critical) 애플리케이션의 운영자 및 개발자를 대상으로 한다. 아래 명시한 제어 방식은 다음과 같이 강행되거나 금지되어야 한다.
참고:
다음 표에서 와일드카드(*)는 리스트에 포함된 모든 요소들을 가리킨다.
예를 들어, spec.containers[*].securityContext는 시큐리티 컨텍스트 오브젝트에 정의되어 있는 모든 컨테이너를 가리킨다.
정의된 컨테이너 중 하나라도 요구사항을 충족시키지 못한다면, 파드 전체가
검증 과정에서 실패한다.| 제어 | 정책 |
|---|---|
| 호스트 프로세스 |
윈도우 파드는 호스트 프로세스 컨테이너를 실행할 권한을 제공하며, 이는 윈도우 노드에 대한 특권 접근을 가능하게 한다. 기본 정책에서의 호스트에 대한 특권 접근은 허용되지 않는다.
기능 상태:
Kubernetes v1.23 [beta]
제한된 필드
허용된 값
|
| 호스트 네임스페이스 |
호스트 네임스페이스 공유는 금지된다. 제한된 필드
허용된 값
|
| 특권 컨테이너 |
특권 파드(Privileged Pods)는 대부분의 보안 메커니즘을 비활성화하므로 금지된다. 제한된 필드
허용된 값
|
| 기능(Capabilities) |
아래 명시되지 않은 부가 기능을 추가하는 작업은 금지된다. 제한된 필드
허용된 값
|
| 호스트 경로(hostPath) 볼륨 |
호스트 경로 볼륨은 금지된다. 제한된 필드
허용된 값
|
| 호스트 포트 |
호스트 포트는 허용되지 않아야 하며, 또는 적어도 알려진 목록 범위내로 제한되어야 한다. 제한된 필드
허용된 값
|
| AppArmor |
지원되는 호스트에서는, 제한된 필드
허용된 값
|
| SELinux |
SELinux 타입을 설정하는 것은 제한되며, 맞춤 SELinux 사용자 및 역할 옵션을 설정하는 것은 금지되어 있다. 제한된 필드
허용된 값
제한된 필드
허용된 값
|
/proc 마운트 타입 |
기본 제한된 필드
허용된 값
|
| Seccomp |
Seccomp 프로필은 제한된 필드
허용된 값
|
| Sysctls |
Sysctls는 보안 메커니즘을 비활성화 시키거나 호스트에 위치한 모든 컨테이너에 영향을 미칠 수 있으며, 허용된 "안전한" 서브넷을 제외한 곳에서는 허용되지 않아야 한다. 컨테이너 또는 파드 네임스페이스에 속해 있거나, 같은 노드 내의 다른 파드 및 프로세스와 격리된 상황에서만 sysctl 사용이 안전하다고 간주한다. 제한된 필드
허용된 값
|
제한(Restricted)
제한 정책은 일부 호환성을 희생하면서 현재 사용되고 있는 파드 하드닝 모범 사례 시행하는 것을 목표로 한다. 보안이 중요한 애플리케이션의 운영자 및 개발자는 물론 신뢰도가 낮은 사용자도 대상으로 한다. 아래에 나열된 제어 방식은 강제되거나 금지되어야 한다.
참고:
다음 표에서 와일드카드(*)는 리스트에 포함된 모든 요소들을 가리킨다.
예를 들어, spec.containers[*].securityContext는 시큐리티 컨텍스트 오브젝트에 정의되어 있는 모든 컨테이너를 가리킨다.
나열된 컨테이너 중 하나라도 요구사항을 충족시키지 못한다면, 파드 전체가
검증에 실패한다.| 제어 | 정책 |
| 기본 프로필에 해당하는 모든 요소 | |
| 볼륨 타입 |
제한 정책은 다음과 같은 볼륨 타입만 허용한다. 제한된 필드
허용된 값 spec.volumes[*] 목록에 속한 모든 아이템은 다음 필드 중 하나를 null이 아닌 값으로 설정해야 한다.
|
| 권한 상승(v1.8+) |
권한 상승(예를 들어, set-user-ID 또는 set-group-ID 파일 모드를 통한)은 허용되지 않아야 한다. v1.25+에서는 리눅스 전용 정책이다. 제한된 필드
허용된 값
|
| 루트가 아닌 권한으로 실행 |
컨테이너는 루트가 아닌 사용자 권한으로 실행되어야 한다. 제한된 필드
허용된 값
spec.securityContext.runAsNonRoot가 true로 설정되면
컨테이너 필드는 undefined/nil로 설정될 수 있다.
|
| 루트가 아닌 사용자로 실행(v1.23+) |
컨테이너에서는 runAsUser 값을 0으로 설정하지 않아야 한다. 제한된 필드
허용된 값
|
| Seccomp(v1.19+) |
Seccomp 프로필은 다음과 같은 값으로 설정되어야 한다. 제한된 필드
허용된 값
spec.securityContext.seccompProfile.type 필드가 적절하게 설정되면,
컨테이너 필드는 undefined/nil로 설정될 수 있다.
모든 컨테이너 레벨 필드가 설정되어 있다면,
pod-level 필드는 undefined/nil로 설정될 수 있다.
|
| 능력(Capabilities) (v1.22+) |
컨테이너는 제한된 필드
허용된 값
제한된 필드
허용된 값
|
정책 초기화
정책 초기화에서의 디커플링(Decoupling) 정책 정의는, 내재되어 있는 시행 메커니즘과 별개로 클러스터 사이의 공통된 이해와 일관된 정책 언어 사용을 가능하게끔 한다.
메커니즘이 발달함에 따라, 아래와 같이 정책별로 정의가 될 것이다. 개별 정책에 대한 시행 방식은 여기서 정의하고 있지 않는다.
대안
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
쿠버네티스 환경에서 정책을 시행하기 위한 대안이 개발되고 있으며 다음은 몇 가지 예시이다.
파드 OS 필드
쿠버네티스에서는 리눅스 또는 윈도우를 실행하는 노드를 사용할 수 있다.
하나의 클러스터에 두 종류의 노드를 혼합하여 사용할 수 있다.
윈도우 환경 쿠버네티스는 리눅스 기반 워크로드와 비교하였을 때 몇 가지 제한사항 및 차별점이 있다.
구체적으로 말하자면, 대부분의 파드 securityContext 필드는
윈도우 환경에서 효과가 없다.
참고:
v1.24 이전 Kubelet은 파드 OS 필드를 필수로 요구하지 않으며, 만일 클러스터 내에 v1.24 이전에 해당하는 노드가 있다면 v1.25 이전 버전의 제한 정책을 적용해야 한다.제한 파드의 시큐리티 스탠다드 변화
쿠버네티스 v1.25에서 나타난 또 다른 중요 변화는, 제한 파드 시큐리티가 pod.spec.os.name 필드를 사용하도록 업데이트 되었다는 것이다.
특정 OS에 특화된 일부 정책은 OS 이름에 근거하여
다른 OS에 대해서는 완화될 수 있다
특정 OS 정책 제어
spec.os.name의 값이 windows가 아닐 시에만 다음 제어 항목에 대한 제한 사항이 요구된다.
- 권한 상승
- Seccomp
- Linux 기능
FAQ
왜 특권 프로필과 기본 프로필 사이의 프로필은 없는 것인가?
여기서 정의된 세 가지 프로필은 가장 높은 보안에서(제한 프로필) 가장 낮은 보안까지(특권 프로필) 명백한 선형 관계를 가지며 넓은 범위의 워크로드를 다룬다. 기본 정책을 넘는 요청 권한은 일반적으로 애플리케이션 전용에 속하므로 이러한 틈새시장에 대해서는 표준 프로필을 제공하지 않는다. 이 경우에는 항상 특권 프로필을 사용해야 한다는 주장은 아니지만, 해당 영역의 정책은 케이스 별로 정의되어야 한다는 것이다.
이외 프로필이 분명히 필요하다면 SIG Auth는 향후에 이러한 입장을 재고할 수 있다.
시큐리티 컨텍스트와 시큐리티 프로필의 차이점은 무엇인가?
시큐리티 컨텍스트는 파드 및 컨테이너를 런타임에 설정한다. 시큐리티 컨텍스트는 파드 매니페스트 내 파드 및 컨테이너 명세의 일부로 정의되고 컨테이너 런타임에 파라미터로 제공한다.
시큐리티 프로필은 컨트롤 플레인 메커니즘으로, 시큐리티 컨텍스트의 상세 설정을 비롯하여 시큐리티 컨텍스트 외부의 다른 관련된 파라미터도 적용한다. 2021년 7월부로, 파드 시큐리티 폴리시는 내장된 파드 시큐리티 어드미션 컨트롤러에 의해 대체되어 사용이 중단되었다.
샌드박스 파드는 어떠한가?
현재로서는, 파드가 샌드박스 특성을 가지는지 제어할 수 있는 API 표준이 존재하지 않는다. 샌드박스 파드는 샌드박스 런타임(예를 들면, gVisor 혹은 Kata 컨테이너)을 통해 식별할 수 있지만, 샌드박스 런타임이 무엇인지에 대한 표준 정의는 없는 상태이다.
샌드박스 워크로드가 필요로하는 보호물은 다른 워크로드와 다를 수 있다. 예를 들어, 내재된 커널과 분리된 워크로드에서는 제한된 특수 권한의 필요성이 적어진다. 이는 높아진 권한을 요구하는 워크로드가 분리될 수 있도록 허용한다.
추가적으로, 샌드박스 방식에 따라 샌드박스 워크로드에 대한 보호가 달라진다. 이와 같은 경우에는, 하나의 프로필만을 모든 샌드박스 워크로드에 대해 권장할 수 없다.
9.3 - 파드 시큐리티 어드미션
파드 보안을 적용할 수 있는 파드 시큐리티 어드미션 컨트롤러에 대한 개요
기능 상태:
Kubernetes v1.25 [stable]
쿠버네티스 파드 시큐리티 스탠다드는 파드에 대해 서로 다른 격리 수준을 정의한다. 이러한 표준을 사용하면 파드의 동작을 명확하고 일관된 방식으로 제한하는 방법을 정의할 수 있다.
쿠버네티스는 파드 시큐리티 스탠다드를 적용하기 위해 내장된 파드 시큐리티 어드미션 컨트롤러를 제공한다. 파드 시큐리티의 제한은 파드가 생성될 때 네임스페이스 수준에서 적용된다.
내장된 파드 시큐리티 어드미션 적용
이 페이지는 쿠버네티스 v1.31에 대한 문서 일부이다. 다른 버전의 쿠버네티스를 실행 중인 경우, 해당 릴리즈에 대한 문서를 참고한다.
파드 시큐리티 수준
파드 시큐리티 어드미션은 파드의
시큐리티 컨텍스트 및 기타 관련 필드인
파드 시큐리티 스탠다드에 정의된 세가지 수준에 따라 요구사항을 적용한다:
특권(privileged), 기본(baseline) 그리고 제한(restricted).
이러한 요구사항에 대한 자세한 내용은
파드 시큐리티 스탠다드 페이지를 참고한다.
네임스페이스에 대한 파드 시큐리티 어드미션 레이블
이 기능이 활성화되거나 웹훅이 설치되면, 네임스페이스를 구성하여 각 네임스페이스에서 파드 보안에 사용할 어드미션 제어 모드를 정의할 수 있다. 쿠버네티스는 미리 정의된 파드 시큐리티 스탠다드 수준을 사용자가 네임스페이스에 정의하여 사용할 수 있도록 레이블 집합을 정의한다. 선택한 레이블은 잠재적인 위반이 감지될 경우 컨트롤 플레인이 취하는 조치를 정의한다.
| 모드 | 설명 |
|---|---|
| 강제(enforce) | 정책 위반 시 파드가 거부된다. |
| 감사(audit) | 정책 위반이 감사 로그에 감사 어노테이션 이벤트로 추가되지만, 허용은 된다. |
| 경고(warn) | 정책 위반이 사용자에게 드러나도록 경고를 트리거하지만, 허용은 된다. |
네임스페이스는 일부 또는 모든 모드를 구성하거나, 모드마다 다른 수준을 설정할 수 있다.
각 모드에는, 사용되는 정책을 결정하는 두 개의 레이블이 존재한다.
# 모드별 단계 레이블은 모드에 적용할 정책 수준을 나타낸다.
#
# 모드(MODE)는 반드시 `강제(enforce)`, `감사(audit)` 혹은 `경고(warn)`중 하나여야 한다.
# 단계(LEVEL)는 반드시 `특권(privileged)`, `기본(baseline)`, or `제한(restricted)` 중 하나여야 한다.
pod-security.kubernetes.io/<MODE>: <LEVEL>
# 선택 사항: 특정 쿠버네티스 마이너 버전(예를 들어, v1.31)과 함께
# 제공된 버전에 정책을 고정하는 데 사용할 수 있는 모드별 버전 레이블
#
# 모드(MODE)는 반드시 `강제(enforce)`, `감사(audit)` 혹은 `경고(warn)`중 하나여야 한다.
# 버전(VERSION)은 반드시 올바른 쿠버네티스의 마이너(minor) 버전 혹은 '최신(latest)'하나여야 한다.
pod-security.kubernetes.io/<MODE>-version: <VERSION>
네임스페이스 레이블로 파드 시큐리티 스탠다드 적용하기 문서를 확인하여 사용 예시를 확인한다.
워크로드 리소스 및 파드 템플릿
파드는 디플로이먼트(Deployment)나 잡(Job)과 같은 워크로드 오브젝트 생성을 통해 간접적으로 생성되는 경우가 많다. 워크로드 오브젝트는 _파드 템플릿_을 정의하고 워크로드 리소스에 대한 컨트롤러는 해당 템플릿을 기반으로 파드를 생성한다. 위반을 조기에 발견할 수 있도록 감사 모드와 경고 모드가 모두 워크로드 리소스에 적용된다. 그러나 강제 모드에서는 워크로드 리소스에 적용되지 않으며, 결과가 되는 파드 오브젝트에만 적용된다.
면제 (exemptions)
지정된 네임스페이스와 관련된 정책으로 인해 금지된 파드 생성을 허용하기 위해 파드 보안 강제에서 면제 를 정의할 수 있다. 면제는 어드미션 컨트롤러 구성하기 에서 정적으로 구성할 수 있다.
면제는 명시적으로 열거해야 한다. 면제 기준을 충족하는 요청은 어드미션 컨트롤러에 의해 무시 된다. 면제 기준은 다음과 같다.
- 사용자 이름(Usernames): 면제 인증된(혹은 사칭한) 사용자 이름을 가진 사용자의 요청은 무시된다.
- 런타임 클래스 이름(RuntimeClassNames): 면제 런타임 클래스 이름을 지정하는 파드 및 워크로드 리소스는 무시된다.
- 네임스페이스(Namespaces): 파드 및 워크로드 리소스는 면제 네임스페이스에서 무시된다.
주의:
대부분의 파드는 컨트롤러가 워크로드 리소스 에 대한 응답으로 생성되므로, 최종 사용자가 파드를 직접 생성할 때만 적용을 면제하고 워크로드 리소스를 생성할 때는 적용이 면제하지 않는다. 컨트롤러 서비스 어카운트(예로system:serviceaccount:kube-system:replicaset-controller)
는 일반적으로 해당 워크로드 리소스를 생성할 수 있는 모든 사용자를 암시적으로
면제할 수 있으므로 면제해서는 안 된다.다음 파드 필드에 대한 업데이트는 정책 검사에서 제외되므로, 파드 업데이트 요청이 이러한 필드만 변경하는 경우, 파드가 현재 정책 수준을 위반하더라도 거부되지 않는다.
- seccomp 또는 AppArmor 어노테이션에 대한 변경 사항을 제외한 모든 메타데이터 업데이트.
seccomp.security.alpha.kubernetes.io/pod(사용 중단)container.seccomp.security.alpha.kubernetes.io/*(사용 중단)container.apparmor.security.beta.kubernetes.io/*
.spec.activeDeadlineSeconds에 대해 유효한 업데이트.spec.tolerations에 대해 유효한 업데이트
다음 내용
9.4 - 파드 시큐리티 폴리시
제거된 기능
파드시큐리티폴리시(PodSecurityPolicy)는 쿠버네티스 1.21 버전부터 사용 중단(deprecated)되었으며, v1.25 버전 때 쿠버네티스에서 제거되었다.파드시큐리티폴리시를 사용하는 것 대신, 다음 중 하나를 사용하거나 둘 다 사용하여 파드에 유사한 제한을 적용할 수 있다.
- 파드 시큐리티 어드미션
- 직접 배포하고 구성할 수 있는 서드파티 어드미션 플러그인
마이그레이션에 관한 설명이 필요하다면 파드시큐리티폴리시(PodSecurityPolicy)에서 빌트인 파드시큐리티어드미션컨트롤러(PodSecurity Admission Controller)로 마이그레이션을 참고한다. 이 API 제거에 대해 더 많은 정보가 필요하다면, 파드시큐리티폴리시(PodSecurityPolicy) 사용 중단: 과거, 현재, 미래를 참고한다.
쿠버네티스 v1.31 이외의 버전을 실행 중이라면, 해당 쿠버네티스 버전에 대한 문서를 확인한다.
9.5 - 윈도우 노드에서의 보안
이 페이지에서는 윈도우 운영 체제에서의 보안 고려 사항 및 추천 사례에 대해 기술한다.
노드의 시크릿 데이터 보호
윈도우에서는 시크릿 데이터가 노드의 로컬 스토리지에 평문으로 기록된다(리눅스는 tmpfs 또는 인메모리 파일시스템에 기록). 클러스터 운영자로서, 다음 2 가지의 추가 사항을 고려해야 한다.
- 파일 ACL을 사용하여 시크릿의 파일 위치를 보호한다.
- BitLocker를 사용하여 볼륨 수준의 암호화를 적용한다.
컨테이너 사용자
윈도우 파드 또는 컨테이너에 RunAsUsername을 설정하여 해당 컨테이너 프로세스를 실행할 사용자를 지정할 수 있다. 이는 RunAsUser와 대략적으로 동등하다.
윈도우 컨테이너는 ContainerUser와 ContainerAdministrator라는 기본 사용자 계정을 2개 제공한다. 이 두 사용자 계정이 어떻게 다른지는 마이크로소프트의 안전한 윈도우 컨테이너 문서 내의 언제 ContainerAdmin 및 ContainerUser 사용자 계정을 사용해야 하는가를 참고한다.
컨테이너 빌드 과정에서 컨테이너 이미지에 로컬 사용자를 추가할 수 있다.
참고:
- Nano Server 기반 이미지는
기본적으로
ContainerUser로 실행된다 - Server Core 기반 이미지는
기본적으로
ContainerAdministrator로 실행된다
그룹 관리 서비스 어카운트를 활용하여 윈도우 컨테이너를 Active Directory 사용자로 실행할 수도 있다.
파드-수준 보안 격리
리눅스 특유의 파드 보안 컨텍스트 메커니즘(예: SELinux, AppArmor, Seccomp, 또는 커스텀 POSIX 기능)은 윈도우 노드에서 지원되지 않는다.
특권을 가진(Privileged) 컨테이너는 윈도우에서 지원되지 않는다. 대신, 리눅스에서 권한 있는 컨테이너가 할 수 있는 작업 중 많은 부분을 윈도우에서 수행하기 위해 HostProcess 컨테이너를 사용할 수 있다.
9.6 - 쿠버네티스 API 접근 제어하기
이 페이지는 쿠버네티스 API에 대한 접근 제어의 개요를 제공한다.
사용자는 kubectl, 클라이언트 라이브러리
또는 REST 요청을 통해
API에 접근한다.
사용자와 쿠버네티스 서비스 어카운트 모두 API에 접근할 수 있다.
요청이 API에 도달하면,
다음 다이어그램에 설명된 몇 가지 단계를 거친다.

전송 보안
기본적으로 쿠버네티스 API 서버는 TLS에 의해 보호되는 첫번째 non-localhost 네트워크 인터페이스의 6443번 포트에서 수신을 대기한다. 일반적인 쿠버네티스 클러스터에서 API는 443번 포트에서 서비스한다. 포트번호는 --secure-port 플래그를 통해, 수신 대기 IP 주소는 --bind-address 플래그를 통해 변경될 수 있다.
API 서버는 인증서를 제시한다.
이러한 인증서는 사설 인증 기관(CA)에 기반하여 서명되거나, 혹은 공인 CA와 연결된 공개키 인프라스트럭처에 기반한다.
인증서와 그에 해당하는 개인키는 각각 --tls-cert-file과 --tls-private-key-file 플래그를 통해 지정한다.
만약 클러스터가 사설 인증 기관을 사용한다면,
해당 CA 인증서를 복사하여 클라이언트의 ~/.kube/config 안에 구성함으로써
연결을 신뢰하고 누군가 중간에 가로채지 않았음을 보장해야 한다.
클라이언트는 이 단계에서 TLS 클라이언트 인증서를 제시할 수 있다.
인증
TLS가 설정되면 HTTP 요청이 인증 단계로 넘어간다. 이는 다이어그램에 1단계로 표시되어 있다. 클러스터 생성 스크립트 또는 클러스터 관리자는 API 서버가 하나 이상의 인증기 모듈을 실행하도록 구성한다. 인증기에 대해서는 인증에서 더 자세히 서술한다.
인증 단계로 들어가는 것은 온전한 HTTP 요청이지만 일반적으로 헤더 그리고/또는 클라이언트 인증서를 검사한다.
인증 모듈은 클라이언트 인증서, 암호 및 일반 토큰, 부트스트랩 토큰, JWT 토큰(서비스 어카운트에 사용됨)을 포함한다.
여러 개의 인증 모듈을 지정할 수 있으며, 이 경우 하나의 인증 모듈이 성공할 때까지 각 모듈을 순차적으로 시도한다.
요청을 인증할 수 없는 경우 HTTP 상태 코드 401과 함께 거부된다.
이 외에는 사용자가 특정 username으로 인증되며,
이 username은 다음 단계에서 사용자의 결정에 사용할 수 있다.
일부 인증기는 사용자 그룹 관리 기능을 제공하는 반면,
이외의 인증기는 그렇지 않다.
쿠버네티스는 접근 제어 결정과 요청 기록 시 usernames를 사용하지만,
user 오브젝트를 가지고 있지 않고 usernames 나 기타 사용자 정보를
오브젝트 저장소에 저장하지도 않는다.
인가
특정 사용자로부터 온 요청이 인증된 후에는 인가되어야 한다. 이는 다이어그램에 2단계로 표시되어 있다.
요청은 요청자의 username, 요청된 작업 및 해당 작업이 영향을 주는 오브젝트를 포함해야 한다. 기존 정책이 요청된 작업을 완료할 수 있는 권한이 해당 사용자에게 있다고 선언하는 경우 요청이 인가된다.
예를 들어 Bob이 아래와 같은 정책을 가지고 있다면 projectCaribou 네임스페이스에서만 파드를 읽을 수 있다.
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
Bob이 다음과 같은 요청을 하면 'projectCaribou' 네임스페이스의 오브젝트를 읽을 수 있기 때문에 요청이 인가된다.
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
Bob이 projectCaribou 네임스페이스에 있는 오브젝트에 쓰기(create 또는 update) 요청을 하면 그의 인가는 거부된다. 만약 Bob이 projectFish처럼 다른 네임스페이스의 오브젝트 읽기(get) 요청을 하면 그의 인가는 거부된다.
쿠버네티스 인가는 공통 REST 속성을 사용하여 기존 조직 전체 또는 클라우드 제공자 전체의 접근 제어 시스템과 상호 작용할 것을 요구한다. 이러한 제어 시스템은 쿠버네티스 API 이외의 다른 API와 상호작용할 수 있으므로 REST 형식을 사용하는 것이 중요하다.
쿠버네티스는 ABAC 모드, RBAC 모드, 웹훅 모드와 같은 여러 개의 인가 모듈을 지원한다. 관리자가 클러스터를 생성할 때 API 서버에서 사용해야 하는 인가 모듈을 구성했다. 인가 모듈이 2개 이상 구성되면 쿠버네티스가 각 모듈을 확인하고, 어느 모듈이 요청을 승인하면 요청을 진행할 수 있다. 모든 모듈이 요청을 거부하면 요청이 거부된다(HTTP 상태 코드 403).
인가 모듈을 사용한 정책 생성을 포함해 쿠버네티스 인가에 대해 더 배우려면 인가 개요를 참조한다.
어드미션 제어
어드미션 제어 모듈은 요청을 수정하거나 거부할 수 있는 소프트웨어 모듈이다. 인가 모듈에서 사용할 수 있는 속성 외에도 어드미션 제어 모듈은 생성되거나 수정된 오브젝트 내용에 접근할 수 있다.
어드미션 컨트롤러는 오브젝트를 생성, 수정, 삭제 또는 (프록시에) 연결하는 요청에 따라 작동한다. 어드미션 컨트롤러는 단순히 오브젝트를 읽는 요청에는 작동하지 않는다. 여러 개의 어드미션 컨트롤러가 구성되면 순서대로 호출된다.
이는 다이어그램에 3단계로 표시되어 있다.
인증 및 인가 모듈과 달리, 어드미션 제어 모듈이 거부되면 요청은 즉시 거부된다.
어드미션 제어 모듈은 오브젝트를 거부하는 것 외에도 필드의 복잡한 기본값을 설정할 수 있다.
사용 가능한 어드미션 제어 모듈은 여기에 서술되어 있다.
요청이 모든 어드미션 제어 모듈을 통과하면 유효성 검사 루틴을 사용하여 해당 API 오브젝트를 검증한 후 오브젝트 저장소에 기록(4단계)된다.
감사(Auditing)
쿠버네티스 감사는 클러스터에서 발생하는 일들의 순서를 문서로 기록하여, 보안과 관련되어 있고 시간 순서로 정리된 기록을 제공한다. 클러스터는 사용자, 쿠버네티스 API를 사용하는 애플리케이션, 그리고 컨트롤 플레인 자신이 생성한 활동을 감사한다.
더 많은 정보는 감사를 참고한다.
다음 내용
인증 및 인가 그리고 API 접근 제어에 대한 추가적인 문서는 아래에서 찾을 수 있다.
또한, 다음 사항을 익힐 수 있다.
- 파드가 API 크리덴셜(credential)을 얻기 위해 시크릿(Secret) 을 사용하는 방법.
9.7 - 역할 기반 접근 제어 (RBAC) 모범 사례
클러스터 운영자를 위한 모범 RBAC 설정 규칙 및 사례
쿠버네티스 RBAC는 클러스터 사용자 및 워크로드가 자신의 역할을 수행하기 위해 필요한 자원에 대해서만 접근 권한을 가지도록 보장하는 핵심 보안 제어 방식이다. 클러스터 관리자가 클러스터 사용자 권한을 설정할 시에는, 보안 사고로 이어지는 과도한 접근 권한 부여의 위험을 줄이기 위해 권한 에스컬레이션 발생 가능성에 대해 이해하는 것이 중요하다.
여기서 제공하는 모범 사례는 RBAC 문서 와 함께 읽는 것을 권장한다.
보편적인 모범 사례
최소 권한
이상적으로는, 최소의 RBAC 권한만이 사용자 및 서비스 어카운트에 부여되어야 한다. 작업에 명시적으로 필요한 권한만 사용되어야 한다. 각 클러스터마다 경우가 다르겠지만, 여기서 적용해 볼 수 있는 보편적 규칙은 다음과 같다.
- 권한은 가능하면 네임스페이스 레벨에서 부여한다. 클러스터롤바인딩 대신 롤바인딩을 사용하여 특정 네임스페이스 내에서만 사용자에게 권한을 부여한다.
- 와일드카드(wildcard)를 사용한 권한 지정을 할 시에는, 특히 모든 리소스에 대해서는 가능하면 지양한다. 쿠버네티스는 확장성을 지니는 시스템이기 때문에, 와일드카드를 이용한 권한 지정은 현재 클러스터에 있는 모든 오브젝트 타입뿐만 아니라 모든 오브젝트 타입에 대해서도 권한을 부여하게 된다.
- 운영자는
cluster-admin계정이 필수로 요구되지 않을시에는 사용을 지양한다. 적은 권한을 가진 계정과 가장 (impersonation) 권한을 혼합하여 사용하면 클러스터 자원을 실수로 수정하는 일을 방지할 수 있다. system:masters그룹에 사용자 추가를 지양한다. 해당 그룹의 멤버는 누구나 모든 RBAC 권한 체크를 우회할 수 있으며 롤바인딩과 클러스터 롤바인딩을 통한 권한 회수가 불가능한 슈퍼유저 (superuser) 권한을 가지게 된다. 추가적으로 클러스터가 권한 웹훅을 사용할 시에는, 그룹의 멤버가 해당 웹훅도 우회할 수 있다. (그룹의 멤버인 사용자가 전송하는 요청은 웹훅에 전달되지 않는다.)
특권 토큰 분배 최소화
이상적인 상황에서는, 강력한 권한이 부여된 서비스 어카운트를 파드에게 지정해서는 안된다. (예를 들어, 권한 에스컬레이션 위험에 명시된 모든 권한) 워크로드가 강력한 권한을 요구하는 상황에서는 다음과 같은 사례를 고려해 보자.
- 강력한 권한을 가진 파드를 실행하는 노드의 수를 제한한다. 컨테이너 이스케이프의 영향 범위를 최소화하기 위해, 실행되고 있는 모든 데몬셋은 최소의 권한만을 가지도록 한다.
- 강력한 권한을 가진 파드를 신뢰되지 못하거나 외부로 노출된 파드와 함께 실행하는 것을 지양한다. 신뢰되지 못하거나 신뢰성이 적은 파드와 함께 실행되는 것을 방지하기 위해 테인트와 톨러레이션, 노드 어피니티, 혹은 파드 안티-어피니티를 사용해 보는 것도 고려해 보자. 신뢰성이 적은 파드가 제한된 파드 시큐리티 스탠다드에 부합하지 않을 시에는 더욱 조심해야 한다.
하드닝 (Hardening)
모든 클러스터에서 요구되지 않더라도, 쿠버네티스에서는 기본으로 제공하는 권한이 있다.
기본으로 부여되는 RBAC 권리에 대한 검토를 통해 보안 하드닝을 할 수 있다.
보편적으로는 system: 계정에 부여되는 권한을 수정하는 것은 지양한다.
클러스터 권한을 하드닝할 수 있는 방법은 다음과 같다.
system:unauthenticated그룹의 바인딩은 누구에게나 네트워크 레벨에서 API 서버와 통신할 수 있는 권한을 부여하므로, 바인딩을 검토해 보고 가능하면 제거한다.automountServiceAccountToken: false를 설정함으로써, 서비스 어카운트 토큰의 자동 마운트 사용을 지양한다. 더 자세한 내용은 기본 서비스 어카운트 토큰 사용법을 참고한다. 파드에서 위와 같은 설정을 하게 된다면, 서비스 어카운트 설정을 덮어쓰게 되며 서비스 어카운트 토큰을 요구하는 워크로드는 여전히 마운트가 가능하다.
주기적 검토
중복된 항목 및 권한 에스컬레이션에 대비하여, 쿠버네티스 RBAC 설정을 주기적으로 검토하는 일은 중요하다. 만일 공격자가 삭제된 사용자와 같은 이름으로 사용자 계정을 생성할 수 있다면, 삭제된 사용자의 모든 권한, 특히 해당 사용자에게 부여되었던 권한까지도 자동으로 상속받을 수 있게 된다.
쿠버네티스 RBAC - 권한 에스컬레이션 위험
쿠버네티스 RBAC 중, 부여받을 시 사용자 또는 서비스 어카운트가 권한 에스컬레이션을 통해 클러스터 밖의 시스템까지 영향을 미칠 수 있게끔 하는 권한이 몇 가지 존재한다.
해당 섹션은 클러스터 운영자가 실수로 클러스터에 의도되지 않은 접근 권한을 부여하지 않도록 하기 위해 신경 써야 할 부분에 대한 시야를 제공하는 것이 목적이다.
시크릿 나열
시크릿에 대해 get 권한을 부여하는 행위는 사용자에게 해당 내용에 대한 열람을 허용하는 일이라는 것은 명확히 알려져 있다.
list 및 watch 권한 또한 사용자가 시크릿의 내용을 열람할 수 있는 권한을 부여한다는 것을 알고 지나가는 것이 중요하다.
예를 들어 리스트 응답이 반환되면 (예를 들어, kubectl get secrets -A -o yaml을 통해),
해당 응답에는 모든 시크릿의 내용이 포함되어 있다.
워크로드 생성
네임스페이스에 워크로드(파드 혹은 파드를 관리하는 워크로드 리소스)를 생성할 수 있는 권한은 파드에 마운트할 수 있는 시크릿, 컨피그맵 그리고 퍼시스턴트볼륨(PersistentVolume)과 같은 해당 네임스페이스의 다른 많은 리소스에 대한 액세스 권한을 암묵적으로 부여한다. 또한 파드는 모든 서비스어카운트로 실행할 수 있기 때문에, 워크로드 생성 권한을 부여하면 해당 네임스페이스에 있는 모든 서비스어카운트의 API 액세스 수준도 암묵적으로 부여된다.
특권 파드 실행 권한을 가지는 사용자는 해당 노드에 대한 권한을 부여받을 수 있으며, 더 나아가 권한을 상승시킬 수 있는 가능성도 존재한다. 특정 사용자 혹은, 적절히 안정 및 격리 된 파드를 생성할 수 있는 자격을 가진 다른 주체를 완전히 신뢰하지 못하는 상황이라면, 베이스라인 혹은 제한된 파드 시큐리티 스탠다드를 사용해야 한다. 이는 파드 시큐리티 어드미션 또는 다른 (서드 파티) 매커니즘을 통해 시행할 수 있다.
이러한 이유로, 네임스페이스는 서로 다른 수준의 보안 또는 테넌시가 필요한 리소스들을 분리하는 데 사용해야 한다. 최소 권한 원칙을 따르고 권한을 가장 적게 할당하는 것이 바람직하지만, 네임스페이스 내의 경계는 약한 것으로 간주되어야 한다.
퍼시스턴트 볼륨 생성
파드시큐리티폴리시 문서에서도 언급이 되었듯이, 퍼시스턴트볼륨 생성 권한은 해당 호스트에 대한 권한 에스컬레이션으로 이어질 수 있다. 퍼시스턴트 스토리지에 대한 권한이 필요할 시에는 신뢰 가능한 관리자를 통해 퍼시스턴트볼륨을 생성하고, 제한된 권한을 가진 사용자는 퍼시스턴트볼륨클레임을 통해 해당 스토리지에 접근하는 것이 바람직하다.
노드의 proxy 하위 리소스에 대한 접근
노드 오브젝트의 하위 리소스인 프록시에 대한 접근 권한을 가지는 사용자는 Kubelet API에 대한 권한도 가지며, 이는 권한을 가지고 있는 노드에 위치한 모든 파드에서 명령어 실행 권한이 주어짐을 의미한다. 이러한 접근 권한을 통해 감시 로깅 및 어드미션 컨트롤에 대한 우회가 가능해짐으로, 해당 리소스에 대한 권한을 부여할 시에는 주의가 필요하다.
에스컬레이트 동사
사용자가 자신이 보유한 권한보다 더 많은 권한을 가진 클러스터롤을 생성하고자 할때, RBAC 시스템이 이를 막는 것이 보편적이다.
이와 관련하여, escalate 동사가 예외에 해당한다. RBAC 문서에서도 언급이 되었듯이,
해당 권한을 가진 사용자는 권한 에스컬레이션을 할 수 있다.
바인드 동사
해당 권한을 사용자에게 부여함으로써 escalate 동사와 유사하게
권한 에스컬레이션에 대한 쿠버네티스에 내장된 보호 기능을 우회할 수 있게 되며,
이는 사용자가 부여받지 않은 권한을 가진 롤에 대한 바인딩을 생성할 수 있게끔 한다.
가장 (Impersonate) 동사
사용자는 해당 동사를 통해 클러스터 내에서 다른 사용자를 가장하여 권한을 부여받을 수 있게 된다. 가장된 계정을 통해 필요 이상의 권한이 부여되지 않도록 해당 동사 부여시 주의를 기울일 필요가 있다.
CSR 및 증명서 발급
CSR API를 통해 CSR에 대한 create 권한 및 certificatesigningrequests/approval에 대한 update 권한을 가진 사용자가,
서명자가 kubernetes.io/kube-apiserver-client인 새로운 클라이언트 증명서를 생성할 수 있게 되며 이를 통해 사용자는 클러스터를 인증할 수 있게 된다.
해당 클라이언트 증명서는 임의의 이름을 가지게 되며, 이에 중복된 쿠버네티스 시스템 구성 요소도 포함 된다.
이는 권한 에스컬레이션 발생 가능성을 열어두게 된다.
토큰 요청
serviceaccounts/token에 대해 create 권한을 가지는 사용자는
기존의 서비스 어카운트에 토큰을 발급할 수 있는 토큰리퀘스트를 생성할 수 있다.
컨트롤 어드미션 웹훅
validatingwebhookconfigurations 혹은 mutatingwebhookconfigurations에 대한 제어권을 가지는 사용자는
클러스터가 승인한 모든 오브젝트를 열람할 수 있는 웹훅을 제어할 수 있으며,
변화하는 웹훅의 경우에는 승인된 오브젝트를 변화시킬 수도 있다.
쿠버네티스 RBAC - 서비스 거부 위험
객체 생성 서비스 거부
클러스터 내 오브젝트 생성 권한을 가지는 사용자는 쿠버네티스가 사용하는 etcd는 OOM 공격에 취약에서 언급 되었듯이, 서비스 거부 현상을 초래할 정도 규모의 오브젝트를 생성할 수 있다. 다중 테넌트 클러스터에서 신뢰되지 못하거나 신뢰성이 적은 사용자에게 시스템에 대해 제한된 권한이 부여된다면 해당 현상이 나타날 수 있다.
해당 문제의 완화 방안 중 하나로는, 리소스 쿼터를 사용하여 생성할 수 있는 오브젝트의 수량을 제한하는 방법이 있다.
다음 내용
- RBAC에 대한 추가적인 정보를 얻기 위해서는 RBAC 문서를 참고한다.
9.8 - 쿠버네티스 시크릿 모범 사례
클러스터 운영자와 애플리케이션 개발자를 위한 모범 시크릿 관리 규칙 및 사례.
쿠버네티스에서 시크릿은 비밀번호, OAuth 토큰 및 SSH 키와 같은 민감한 정보를 저장한다.
시크릿을 사용하면 민감한 정보가 사용되는 방법을 더 잘 통제할 수 있으며, 실수로 외부에 노출되는 위험도 줄일 수 있다. 시크릿 값은 base64 문자열로 인코딩되며 기본적으로는 평문으로 저장되지만, 암호화하여 저장하도록 설정할 수도 있다.
파드는 볼륨을 마운트하거나 혹은 환경 변수를 통하는 등 다양한 방식으로 시크릿을 참조할 수 있다. 시크릿은 기밀 데이터를 다루는 용도로 적합하며, 컨피그맵은 기밀이 아닌 데이터를 다루는 용도로 적합하다.
다음 모범 사례는 클러스터 관리자와 애플리케이션 개발자 모두를 위한 것이다. 이 가이드라인을 사용하여 시크릿 오브젝트에 있는 민감한 정보의 보안을 개선하고 시크릿을 보다 효과적으로 관리할 수 있다.
클러스터 관리자
이 섹션에서는 클러스터 관리자가 클러스터의 기밀 정보 보안을 개선하는 데 사용할 수 있는 모범 사례를 제공한다.
저장된 데이터(at rest)에 암호화 구성
기본적으로 시크릿 오브젝트는 etcd에
암호화되지 않은 상태로 저장된다. 따라서 etcd의 시크릿 데이터에 암호화를 구성해야 한다.
자세한 내용은
Encrypt Secret Data at Rest를 참고한다.
시크릿에 대한 최소 권한 접근 구성
쿠버네티스 역할 기반 접근 제어 (RBAC)
(RBAC)와 같은 접근 제어 메커니즘을 계획할 때,
Secret 오브젝트에 대한 접근에 대해 다음 가이드라인을 고려한다. 또한
역할 기반 접근 제어 (RBAC) 모범 사례의
다른 가이드라인도 따라야 한다.
- 컴포넌트: 가장 권한이 높은 시스템 수준의 구성 요소에 대해서만
watch나list액세스를 제한한다. 컴포넌트의 정상 동작에 필요한 경우에만 시크릿에 대한get액세스를 허용한다. - 사람: 시크릿에
get,watch또는list액세스를 제한한다. 클러스터 관리자에게만etcd에 대한 액세스를 허용한다. 여기에는 읽기 전용 액세스가 포함된다. 특정 어노테이션을 사용하여 시크릿에 대한 액세스를 제한하는 등의 더 복잡한 액세스 제어를 수행하려면 써드파티(third-party) 권한 부여 메커니즘을 사용하는 것을 고려한다.
주의:
시크릿에 대한list 액세스 권한을 부여하면 주체가 암시적으로
시크릿의 내용을 가져갈 수 있다.시크릿을 사용하는 파드를 생성할 수 있는 사용자는 해당 시크릿의 값도 볼 수 있다. 클러스터 정책에서 사용자가 시크릿을 직접 읽는 것을 허용하지 않더라도, 동일한 사용자가 시크릿을 노출하는 파드를 실행할 수 있다. 이 액세스 권한을 가진 사용자가 의도적이든 의도적이지 않든 시크릿 데이터를 노출시켜 발생할 수 있는 영향을 감지하거나 제한할 수 있다. 몇 가지 권장 사항은 다음과 같다.
- 수명이 짧은 시크릿 사용
- 한 사용자가 여러 비밀을 동시에 읽는 것과 같은 특정 이벤트에 대해 경고하는 감사 규칙 구현
etcd 관리 정책 개선
더 이상 사용하지 않는다면 etcd에서 사용하는 내구성 스토리지를
지우거나 파쇄하는 것을 고려한다.
여러 개의 etcd 인스턴스가 있는 경우, 인스턴스 간에 암호화된 SSL/TLS 통신을 구성하여
전송 중(in transit)인 시크릿 데이터를 보호한다.
외부 시크릿에 대한 액세스 구성
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
써드파티 시크릿 저장소 공급자를 사용하여 기밀 데이터를 클러스터 외부에 보관한 다음 해당 정보에 액세스하도록 파드를 구성할 수 있다. 쿠버네티스 시크릿 스토어 CSI 드라이버는 kubelet이 외부 스토어에서 시크릿을 검색하고 접근 권한을 부여한 특정 파드에 시크릿을 볼륨으로 마운트할 수 있도록 하는 데몬셋(DaemonSet)이다.
지원되는 제공자 목록은 다음을 참고한다. 시크릿 스토어 CSI 드라이버 제공자.
개발자
이 섹션은 개발자가 쿠버네티스 리소스를 구축하고 배포할 때 기밀 데이터의 보안을 개선하기 위해 사용할 수 있는 모범 사례를 제공한다.
특정 컨테이너에 시크릿 액세스 제한
파드에 여러 개의 컨테이너를 정의하고 있고 그 중 하나만 시크릿에 접근해야 하는 경우, 볼륨 마운트 또는 환경 변수 구성을 정의하여 다른 컨테이너가 해당 시크릿에 액세스하지 못하도록 한다.
읽기 후 시크릿 데이터 보호
애플리케이션은 환경 변수나 볼륨에서 기밀 정보를 읽은 후에도 그 값을 보호해야 한다. 예를 들어, 애플리케이션은 시크릿 데이터를 로그에 남기거나 신뢰할 수 없는 상대에게 전송하지 않아야 한다.
시크릿 매니페스트 공유 방지
시크릿 데이터가 base64로 인코딩된 매니페스트를 통해 시크릿을 구성하는 경우, 이 파일을 공유하거나 소스 리포지토리에 체크인하면 매니페스트를 읽을 수 있는 모든 사람이 시크릿을 사용할 수 있다는 것을 의미한다.
주의:
Base64 인코딩은 암호화 방식이 아니며, 일반 텍스트에 비해 추가적인 기밀성을 제공하지 않는다.9.9 - 멀티 테넌시(multi-tenancy)
이 페이지는 클러스터 멀티 테넌시를 구현하기 위해 유효한 구성 옵션과 모범 사례에 대한 개요를 제공한다.
클러스터 공유를 통해 비용 절감 및 운영을 간편화할 수 있다. 그러나 클러스터를 공유하게 되면 보안, 공평성, 소란스러운 이웃(noisy neighbors) 관리와 같이 여러 문제 상황이 발생할 수 있다.
클러스터는 다양한 방법을 통해 공유될 수 있다. 특정 경우에는 같은 클러스터 내 서로 다른 애플리케이션이 실행될 수 있다. 또 다른 경우에는 하나의 애플리케이션에서 각 엔드유저에 대한 인스턴스가 모여 여러 인스턴스가 같은 클러스터 내에서 실행될 수 있다. 이러한 모든 종류의 공유 방법은 주로 멀티 테넌시 라는 포괄적 용어로 통칭한다.
쿠버네티스에서는 엔드 유저 또는 테넌트에 대한 정형화된 개념을 정해놓고 있지는 않지만, 다양한 테넌시 요구사항을 관리하기 위한 몇 가지 기능을 제공한다. 이에 대한 내용은 밑에서 다룬다.
유스케이스
클러스터를 공유하기 위해 고려해야 하는 첫 번째 단계는, 사용 가능한 패턴과 툴을 산정하기 위해 유스케이스를 이해하는 것이다. 일반적으로 쿠버네티스에서의 멀티 테넌시는 다양한 형태로 변형 또는 혼합이 가능하지만, 넓게는 두 가지 범주로 분류된다.
다수의 팀
흔히 사용하는 멀티 테넌시의 형태는 하나 또는 그 이상의 워크로드를 운영하는 한 조직 소속의 여러 팀이 하나의 클러스터를 공유하는 형태이다. 이러한 워크로드는 같은 클러스터 내외의 다른 워크로드와 잦은 통신이 필요하다.
이러한 시나리오에서 팀에 속한 멤버는 보통 kubectl과 같은 툴을 통해 쿠버네티스 리소스에 직접적으로 접근하거나,
GitOps 컨트롤러 혹은 다른 종류의 배포 자동화 툴을 통해 간접적으로 접근한다.
대개는 다른 팀 멤버 간에 일정량의 신뢰가 형성되어 있지만,
안전하고 공평한 클러스터 공유를 위해서는
RBAC, 쿼터(quota), 네트워크 정책과 같은 쿠버네티스 정책이 필수이다.
다수의 고객
다른 주요 멀티 테넌시 형태로는 서비스형소프트웨어(SaaS) 사업자가 여러 고객의 워크로드 인스턴스를 실행하는 것과 관련이 있다. 이러한 비즈니스 모델은 많은 이들이 "SaaS 테넌시"라고 부르는 배포 스타일과 밀접한 연관이 있다. 그러나 SaaS 사업자는 다른 배포 모델을 사용할 수 있기도 하며 SaaS가 아니어도 이러한 배포 모델의 적용이 가능하기 때문에, "다중 고객 테넌시(multi-customer tenancy)"를 더 적합한 용어로 볼 수 있다.
고객은 이러한 시나리오에서 클러스터에 대한 접근 권한을 가지지 않는다. 쿠버네티스는 그들의 관점에서는 보이지 않으며, 사업자가 워크로드를 관리하기 위해서만 사용된다. 비용 최적화는 주로 중대한 관심사가 되며, 워크로드 간의 확실한 격리를 보장하기 위해 쿠버네티스 정책이 사용된다.
용어
테넌트
쿠버네티스에서의 멀티 테넌시를 논할 때는, "테넌트(tenant)"를 하나의 의미로 해석할 수 없다. 오히려 다중 팀 혹은 다중 고객 테넌시의 여부에 따라 테넌트의 정의는 달라진다.
다중 팀 사용(multi-team usage)에서의 테넌트는 일반적으로 하나의 팀을 의미하며, 이 팀은 일반적으로 서비스의 복잡도에 따라 스케일 하는 작은 양의 워크로드를 다수 배포한다. 그러나 "팀" 자체에 대한 정의도 상위 조직으로 구성될 수 있기도 하고 작은 팀으로 세분화될 수 있기 때문에 정의가 모호할 수 있다.
반대로 각 팀이 새로운 고객에 대한 전용 워크로드를 배포하게 된다면, 다중 고객 테넌시 모델을 사용한다고 볼 수 있다. 이와 같은 경우에서는, "테넌트"는 하나의 워크로드를 공유하는 사용자의 집합을 의미한다. 이는 하나의 기업만큼 큰 규모일 수도 있고, 해당 기업의 한 팀 정도의 작은 규모일수도 있다.
같은 조직이 "테넌트"에 대한 두 개의 정의를 서로 다른 맥락에서 사용할 수 있는 경우가 많다.
예를 들어, 플랫폼 팀은 다수의 내부 "고객"을 위해 보안 툴 및 데이터베이스와 같은 공유된 서비스를 제공할 수 있고,
SaaS 사업자는 공유된 개발 클러스터를 다수의 팀에게 제공할 수 있다.
마지막으로, SaaS 제공자는 민감한 데이터를 다루는 고객별 워크로드와
공유된 서비스를 다루는 멀티 테넌트를 혼합하여 제공하는 하이브리드 구조도
사용이 가능하다.
공존하는 테넌시 모델을 나타내고 있는 클러스터
격리
쿠버네티스에서 멀티 테넌트 솔루션을 설계하고 빌드 하는 방법은 몇 가지가 있다. 각 방법은 격리 수준, 구현 비용, 운영 복잡도, 서비스 비용에 영향을 미치는 각자만의 상충 요소를 가지고 있다.
각 쿠버네티스 클러스터는 쿠버네티스 소프트웨어를 실행하는 컨트롤 플레인과 테넌트의 워크로드가 파드의 형태로 실행되고 있는 워커 노드로 구성된 데이터 플레인으로 구성되어 있다. 테넌트 격리는 조직의 요구사항에 따라 컨트롤 플레인 및 데이터 플레인 모두에 대해 적용할 수 있다.
제공되는 격리의 수준은 강한 격리를 의미하는 "하드(hard)" 멀티 테넌시와 약한 격리를 의미하는 "소프트(soft)" 멀티 테넌시와 같은 용어를 통해 정의한다. 특히 "하드" 멀티 테넌시는 주로 보안이나 리소스 공유 관점(예를 들어, 데이터 유출 및 DoS 공격에 대한 방어)에서 테넌트가 서로 신뢰하지 않는 상황을 설명할 때 주로 사용한다. 데이터 플레인은 일반적으로 더 큰 공격 영역을 가지고 있기 때문에, 컨트롤 플레인 격리 또한 중요하지만 데이터 플레인을 격리하는 데 있어서 "하드" 멀티 테넌시는 추가적인 주의를 요구한다.
그러나 모든 사용자에게 적용할 수 있는 하나의 정의가 없기 때문에, "하드"와 "소프트" 용어에 대한 혼동이 생길 수 있다. 오히려 요구사항에 따라 클러스터 내에서 다양한 종류의 격리를 유지할 수 있는 다양한 기법을 다루는 "하드한 정도" 혹은 "소프트한 정도"가 넓은 범위에서는 이해하기에 편하다.
극단적인 경우에는 클러스터 레벨의 공유를 모두 포기하고 각 테넌트에 대한 전용 클러스터를 할당하거나, 가상머신을 통한 보안 경계가 충분하지 않다고 판단될 시에는 전용 하드웨어에서 실행하는 것이 쉽고 적절한 방법일 수 있다. 클러스터를 생성하고 운영하는데 필요한 오버헤드를 클라우드 공급자가 맡게 되는 매니지드 쿠버네티스 클러스터에서는 이와 같은 방식을 사용하기에 더 쉬울 수 있다. 강한 테넌트 격리의 장점은 여러 클러스터를 관리하는데 필요한 비용과 복잡도와 비교하여 산정되어야 한다. 멀티 클러스터 SIG는 이러한 종류의 유스케이스를 다루는 작업을 담당한다.
이 페이지의 남은 부분에서는 공유 쿠버네티스 클러스터에서 사용되는 격리 기법을 중점적으로 다룬다. 그러나 전용 클러스터를 고려하고 있다 하더라도, 요구사항 혹은 기능에 대한 변화가 생겼을 때 공유 클러스터로 전환할 수 있는 유연성을 제공할 수 있기 때문에, 이러한 권고사항을 검토해 볼 가치가 있다.
컨트롤 플레인 격리
컨트롤 플레인 격리는 서로 다른 테넌트가 서로의 쿠버네티스 API 리소스에 대한 접근 및 영향을 미치지 못하도록 보장한다.
네임스페이스
쿠버네티스에서 네임스페이스는 하나의 클러스터 내에서 API 리소스 그룹을 격리하는 데 사용하는 기능이다. 이러한 격리는 두 가지 주요 특징을 지닌다.
-
네임스페이스 내의 오브젝트 이름은 폴더 내의 파일과 유사하게 다른 네임스페이스에 속한 이름과 중첩될 수 있다. 이를 통해 각 테넌트는 다른 테넌트의 활동과 무관하게 자신의 리소스에 대한 이름을 정할 수 있다.
-
많은 쿠버네티스 보안 정책은 네임스페이스 범위에서 사용한다. 예를 들어, RBAC 역할과 네트워크 정책은 네임스페이스 범위의 리소스이다. RBAC를 사용함으로써 사용자 및 서비스 어카운트는 하나의 네임스페이스에 대해 제한될 수 있다.
멀티 테넌트 환경에서의 각 네임스페이스는 테넌트의 워크로드를 논리적이고 구별되는 관리 단위로 분할할 수 있다. 실제로 일반적인 관습에서는 여러 워크로드가 하나의 테넌트에 의해 운영되더라도, 각 워크로드를 개별 네임스페이스로 격리한다. 이를 통해 각 워크로드는 개별 정체성을 가질 수 있으며 적절한 보안 정책을 적용 받을 수 있게끔 보장한다.
네임스페이스 격리 모델은 테넌트 워크로드를 제대로 격리 시키기 위해 몇 가지 다른 쿠버네티스 리소스, 네트워크 플러그인, 보안 모범 사례에 대한 준수가 필요하다. 이와 같이 고려해야 하는 사항은 아래에 명시되어 있다.
접근 제어
컨트롤 플레인에서의 가장 중요한 격리 방식은 인증이다. 만일 팀 또는 해당 팀의 워크로드가 서로 다른 API 리소스에 대한 접근 및 수정이 가능하다면, 다른 종류의 정책을 모두 바꾸거나 비활성화할 수 있게 되어 해당 정책이 제공하는 보호를 무효화한다. 따라서 각 테넌트가 필요로 하는 네임스페이스에 대한 적절한 최소의 권한만을 부여하는 것이 중요하다. 이는 "최소 권한의 원칙(Principle of Least Privilege)"이라고 부른다.
역할 기반 접근 제어(RBAC)는 흔히 쿠버네티스 컨트롤 플레인에서의 사용자와 워크로드에 (서비스 어카운트) 대한 인증을 시행하기 위해 사용된다. 롤(Roles)과 롤바인딩(RoleBindings)은 네임스페이스 레벨에서 애플리케이션의 접근 제어를 시행하기 위해 사용되는 쿠버네티스 오브젝트이다. 클러스터 레벨의 오브젝트에 대한 접근 권한을 인증하기 위해 사용되는 유사한 오브젝트도 존재하지만, 이는 멀티 테넌트 클러스터에서는 비교적 유용성이 떨어진다.
다중 팀 환경에서는, 클러스터 전범위 리소스에 대해 클러스터 운영자와 같이 특권을 가진 사용자에 의해서만 접근 또는 수정이 가능하도록 보장하기 위해 RBAC를 사용하여 테넌트의 접근을 적합한 네임스페이스로 제한해야 한다.
만일 사용자에게 필요 이상으로 권한을 부여하는 정책이 있다면, 이는 영향 받는 리소스를 포함하고 있는 네임스페이스가 더 세분화된 네임스페이스로 재구성 되어야 한다는 신호일 가능성이 높다. 네임스페이스 관리 툴을 통해 공통된 RBAC 정책을 서로 다른 네임스페이스에 적용하고 필요에 따라 세분화된 정책은 허용하며, 세분화된 네임스페이스를 간편하게 관리할 수 있다.
쿼터
쿠버네티스 워크로드는 CPU 및 메모리와 같은 노드 리소스를 소모한다. 멀티 테넌트 환경에서는, 테넌트 워크로드의 리소스 사용량을 관리하기 위해 리소스 쿼터를 사용할 수 있다. 테넌트가 쿠버네티스 API에 대한 접근 권한을 가지는 다수 팀 유스케이스의 경우에는, 테넌트가 생성할 수 있는 API 리소스(예를 들어, 파드의 개수 혹은 컨피그맵의 개수)의 개수를 리소스 쿼터를 사용하여 제한할 수 있다. 오브젝트 개수에 대한 제한은 공평성을 보장하고 같은 컨트롤 플레인을 공유하는 테넌트 간 침범이 발생하는 소란스러운 이웃 문제를 예방하기 위한 목적을 가지고 있다.
리소스 쿼터는 네임스페이스 오브젝트이다. 테넌트를 네임스페이스에 대해 매핑함으로써, 클러스터 운영자는 쿼터를 사용하여 하나의 테넌트가 클러스터의 리소스를 독점하거나 컨트롤 플레인을 압도하지 못하도록 보장할 수 있다. 네임스페이스 관리 툴은 쿼터 운영을 간편화해준다. 이에 더해 쿠버네티스 쿼터는 하나의 네임스페이스 내에서만 적용이 가능하지만, 특정 네임스페이스 관리 툴은 네임스페이스 그룹이 쿼터를 공유할 수 있도록 허용함으로써 운영자에게 내장된 쿼터에 비해 적은 수고로 더 많은 유연성을 제공한다.
쿼터는 하나의 테넌트가 자신에게 할당된 몫의 리소스 보다 많이 사용하는 것을 방지하며, 이를 통해 하나의 테넌트가 다른 테넌트의 워크로드 성능에 부정적 영향을 미치는 "소란스러운 이웃" 문제를 최소화할 수 있다.
쿠버네티스에서 네임스페이스에 대한 쿼터를 적용할 시에는 각 컨테이너에 대한 리소스 요청과 제한을 명시하도록 요구한다. 제한은 각 컨테이너가 소모할 수 있는 리소스의 양에 대한 상한선이다. 설정된 제한을 초과하여 리소스 소모를 시도하는 컨테이너는 리소스의 종류에 따라 스로틀(throttled)되거나 종료(killed)된다. 리소스 요청이 제한보다 낮게 설정되었을 시에는, 각 컨테이너가 요청한 리소스의 양은 보장되지만 워크로드 간의 영향이 있을 가능성은 존재한다.
쿼터는 네트워크 트래픽과 같이 모든 종류의 리소스 공유에 대한 보호는 할 수 없다. 노드 격리(아래에서 설명)가 이러한 문제에 대해서는 더 나은 해결책일 수 있다.
데이터 플레인 격리
데이터 플레인 격리는 다른 테넌트의 파드 및 워크로드와 충분히 격리가 이루어질 수 있도록 보장한다.
네트워크 격리
기본적으로 쿠버네티스 클러스터의 모든 파드는 서로 통신을 할 수 있도록 허용되어 있으며 모든 네트워크 트래픽은 암호화되어 있지 않다. 이는 트래픽이 실수 또는 악의적으로 의도되지 않은 목적지로 전송되거나 신뢰가 손상된(compromised) 노드 상의 워크로드에 의해 가로채지는 것과 같은 보안 취약점으로 이어질 수 있다.
파드에서 파드로의 통신은 네임스페이스 레이블 혹은 IP 주소 범위를 통해 파드 간의 통신을 제한하는 네트워크 정책에 의해 제어될 수 있다. 테넌트 간의 엄격한 네트워크 격리가 필요한 멀티 테넌트 환경에서는, 파드 간의 통신을 거부하는 기본 정책과 모든 파드가 네임 해석(name resolution)을 위해 DNS 서버를 쿼리하도록 하는 규칙을 시작에 설정하는 것을 권고한다. 이러한 기본 정책을 기반으로 하여, 네임스페이스 내에서 통신을 허용하는 관대한 규칙을 추가할 수 있다. 또한 네임스페이스 간에 트래픽을 허용해야 하는 경우 네트워크 정책 정의의 namespaceSelector 필드에 빈 레이블 셀렉터 '{}'를 사용하지 않는 것이 좋다. 이러한 방식은 요구에 따라 한 단계 더 정제할 수 있다. 이는 하나의 컨트롤 플레인 내의 파드에 대해서만 적용된다는 것을 알아두어야 한다. 서로 다른 가상의 컨트롤 플레인에 소속된 파드는 쿠버네티스 네트워킹을 통해 통신할 수 없다.
네임스페이스 관리 툴을 통해 기본 또는 공통 네트워크 정책을 간편하게 생성할 수 있다. 이에 더해, 몇 가지 툴은 클러스터 상에서 일관된 집합의 네임스페이스 레이블을 사용할 수 있게 함으로써 정책에 대한 신뢰 가능한 기반이 마련될 수 있도록 보장한다.
경고:
네트워크 정책은 구현 과정에서 지원되는 CNI 플러그인을 요구한다. 만일 그렇지 않으면, 네트워크폴리시 리소스는 무시된다.추가적으로, 서비스 메쉬(service mesh)는 워크로드 특징에 따른 OSI 7 계층 정책을 제공하므로 네임스페이스보다 더 고도의 네트워크 격리를 제공할 수 있다. 이러한 상위 정책은 특히 하나의 테넌트에 대한 여러 네임스페이스가 있는 경우와 같이, 네임스페이스 기반 멀티 테넌시를 더욱 쉽게 관리할 수 있도록 한다. 신뢰가 손상된(compromised) 노드가 발생했을 시에도 데이터를 보호할 수 있는 상호 간의 TLS을 통해 암호화도 제공하며 전용 또는 가상의 클러스터 사이에서도 동작한다. 그러나 관리하기에 더 복잡할 수 있으며 모든 사용자에게 적합한 방법이 아닐 수 있다.
스토리지 격리
쿠버네티스는 워크로드가 퍼시스턴트 스토리지로 사용할 수 있는 몇 가지 종류의 볼륨을 제공한다. 보안 및 데이터 격리를 위해서는 동적 볼륨 프로비저닝을 권고하며 노드 리소스를 사용하는 볼륨 타입은 피해야 한다.
스토리지 클래스는 클러스터에 제공하는 사용자 정의 "클래스"를 서비스 품질 수준(quality-of-service level), 백업 정책 혹은 클러스터 운영자에 의해 결정된 사용자 정의 정책을 기반으로 명시할 수 있도록 허용한다.
파드는 퍼시스턴트 볼륨 클레임을 통해 스토리지를 요청할 수 있다. 퍼시스턴트 볼륨 클레임은 공용 쿠버네티스 클러스터 내에서 스토리지 시스템의 부분 단위 격리를 가능하게끔 하는 네임스페이스 리소스이다. 그러나 퍼시스턴트 볼륨은 클러스터 전범위(cluster-wide)의 리소스이며 워크로드와 네임스페이스의 라이프사이클에 독립적이므로, 이를 염두에 둘 필요가 있다.
예를 들어, 각 테넌트에 대한 별도의 스토리지 클래스를 설정할 수 있으며 이를 통해 격리를 강화할 수 있다.
만일 스토리지 클래스가 공유된다면, Delete 리클레임(reclaim) 정책을 설정하여
퍼시스턴트 볼륨이 다른 네임스페이스에서 재사용되지 못하도록 보장해야 한다.
컨테이너 샌드박싱(sandboxing)
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
쿠버네티스 파드는 워커 노드 상에서 실행되는 하나 또는 그 이상의 컨테이너로 구성되어 있다. 컨테이너는 OS 레벨의 가상화를 활용하기 때문에 하드웨어 기반의 가상화를 활용하는 가상 머신에 비해 격리의 경계가 약하다.
공유 환경에서 애플리케이션 및 시스템 계층 상 패치되지 않은 취약점은 컨테이너 탈출(container breakout) 또는 원격 코드 실행과 같이 호스트 리소스에 대한 접근을 허용하여 공격자에 의해 악용될 수 있다. 컨텐츠 매니지먼트 시스템(CMS)과 같은 특정 애플리케이션에서는, 고객이 신뢰되지 않은 스크립트 및 코드를 업로드할 수 있는 기능이 허용될 수 있다. 어떤 경우이든, 강한 격리를 통해 워크로드를 한 단계 더 격리하고 보호하기 위한 기능은 필요하다.
샌드박싱은 공유 클러스터에서 실행되는 워크로드를 격리하는 방법을 제공한다. 일반적으로 각
파드를 가상 머신 또는 유저스페이스 커널(userspace kernel)과 같은 별도의 실행 환경에서 실행하는 것과 연관이
있다. 샌드박싱은 주로 워크로드가 악의적으로 판단되는 신뢰되지 않은 코드를 실행할 때
권고된다. 이러한 격리가 필요한 이유는 컨테이너가 공유된 커널에서 실행되기 때문이다.
컨테이너는 하위 호스트의 /sys 및 /proc 와 같은 파일 시스템을 마운트 하기 때문에,
개별 커널을 가지는 가상 머신에서 실행되는 애플리케이션과 비교하였을 때는 보안성이 낮다.
Seccomp, AppArmor, SELinux와 같은 제어를 통해 컨테이너의 보안을 강화할 수 있지만,
공유 클러스터에서 실행되고 있는 모든 워크로드에 대해 공통된 규칙을 적용하는 데는 어려움이
있다. 워크로드를 샌드박스 환경에서 실행함으로써, 공격자가 호스트의 취약점을 악용하여
호스트 시스템 및 해당 호스트에서 실행되고 있느 모든 프로세스와 파일 대한 권한을 얻을 수
있는 컨테이너 탈출로 부터 호스트를 보호할 수 있다.
가상 머신 및 유저스페이스 커널은 샌드박싱을 제공하는 대표적인 두 가지 방법이다. 다음과 같은 샌드박싱 구현이 가능하다.
- gVisor는 컨테이너로부터 시스템 호출을 가로채 Go로 작성된 유저스페이스 커널을 통해 실행하므로, 컨테이너가 호스트 내부(underlying host)에 대한 제한적인 접근 권한만 가진다.
- Kata 컨테이너는 OCI에 부합하는 런타임으로 가상 머신 내에서 컨테이너가 실행되도록 한다. Kata는 하드웨어 가상화를 통해, 신뢰되지 않은 코드를 실행하는 컨테이너에 대해 추가적인 보안 계층을 제공한다.
노드 격리
노드 격리는 테넌트 워크로드를 서로 격리시킬 수 있는 또 다른 기법이다. 노드 격리를 통해 하나의 노드 집합은 특정 테넌트의 파드를 전용으로 실행할 수 있으며 테넌트 파드 간의 혼합(co-mingling)은 금지되어 있다. 이러한 구성을 사용하게 되면 노드 상에서 실행되는 파드가 모두 하나의 테넌트 소유이기 때문에 소란스러운 테넌트 문제를 줄일 수 있다. 컨테이너 탈출에 성공한 공격자가 있다 하더라도, 해당 노드의 컨테이너 및 마운트 된 볼륨에 대해서만 접근 권한을 가지므로, 노드 격리를 통해 정보 유출의 위험도 비교적 감소한다.
다른 테넌트의 워크로드가 다른 노드에서 실행되고 있다 하더라도, Kubelet과 (가상 컨트롤 플레인을 사용하지 않는 한) API 서비스는 여전히 공유되고 있다는 사실을 이해하는 것은 중요하다. 능숙한 공격자는 Kubelet 또는 노드에서 실행되고 있는 다른 파드에 부여된 권한을 이용하여 클러스터 내에서 좌우로 이동하며 다른 노드에서 실행되고 있는 테넌트 워크로드에 대한 접근 권한을 얻을 수 있다. 만일 이러한 사항이 우려된다면, seccomp, AppArmor, SELinux와 같은 제어 방식을 이용하거나, 샌드박스 컨테이너 이용 또는 각 테넌트에 대한 개별 클러스터를 생성하는 방안을 검토해 보아야 한다.
노드 격리를 통해 파드가 아닌 노드 별 비용을 청구할 수 있으므로, 비용 관점에서는 샌드박스 컨테이너에 비해 이해 및 파악이 수월하다. 또한 호환성 및 성능 문제 발생 가능성이 낮으며 샌드박스 컨테이너 보다 구현도 더 쉬운 편이다. 예를 들어, 각 테넌트에 대한 노드는 대응하는 톨러레이션(toleration)을 가진 파드만 실행할 수 있도록 테인트(taint)를 통해 설정할 수 있다. 변화하는 웹훅을 통해 자동으로 톨러레이션과 노드 어피니티를 테넌트 네임스페이스에 배포된 파드에 추가하여, 해당 파드를 특정 테넌트를 위해 지정된 특정 노드의 집합에서 실행될 수 있도록 한다.
노드 격리는 파드 노드 셀렉터 또는 가상 Kubelet(Virtual Kubelet)을 통해 구현할 수 있다.
추가적인 고려 사항
해당 섹션에서는 멀티 테넌시와 연관 있는 이외의 쿠버네티스 구성 및 패턴에 대한 내용을 다룬다.
API 우선순위와 공평성
API 우선순위(priority)와 공평성(fairness)은 쿠버네티스의 기능 중 하나로, 클러스터 내 실행 중인 특정 파드에 대해 우선순위를 부여할 수 있다. 애플리케이션이 쿠버네티스 API를 호출하게 되면, API 서버는 해당 파드에 부여된 우선순위를 산정한다. 더 높은 우선순위를 가진 파드의 호출은 낮은 우선순위를 가진 파드의 호출보다 먼저 수행된다. 경합률(contention)이 높을 시에는 낮은 우선순위의 호출은 서버 리소스가 한가해질 때까지 대기하거나 해당 요청을 거부할 수 있다.
고객이 쿠버네티스 API와 상호작용하는 애플리케이션(예를 들어, 컨트롤러)을 실행하지 않은 한, SaaS 환경에서 API 우선순위와 공평성을 사용하는 일은 흔치 않을 것이다.
서비스 품질(QoS)
SaaS 애플리케이션을 실행할 시에는, 각 테넌트에게 다른 수준의 서비스 품질 티어(tier)를 제공하는 기능이 필요할 수 있다. 예를 들어, 낮은 성능 및 기능을 보장하는 무료 서비스와 특정 수준의 성능을 보장하는 유료 서비스를 제공할 수 있다. 다행히 쿠버네티스는 이러한 티어를 공유 클러스터 내에서 구현하기 위한 네트워크 QoS, 스토리지 클래스, 파드 우선순위 및 선점과 같은 몇 가지 구성들을 제공한다. 이는 각 테넌트가 지불한 비용에 적합한 서비스 품질을 제공하기 위한 목적이다. 우선 네트워크 QoS에 대해 먼저 살펴본다.
일반적으로 하나의 노드에 위치한 모든 파드는 네트워크 인터페이스를 공유한다. 네트워크 QoS 없이는, 몇 개의 파드가 가용 대역폭 중 다른 파드의 대역폭까지 소모하여 불공평한 공유를 야기할 수 있다. 쿠버네티스 대역폭 플러그인은 리눅스 tc 큐를 이용하여 파드에 비율 제한을 적용할 수 있는 쿠버네티스 리소스 구성(예를 들어, 요청/제한)을 사용 가능하게 하는 네트워킹 확장 리소스를 생성한다. 네트워크 플러그인 문서에 따르면 해당 플러그인은 아직은 실험 목적으로 사용되고 있다는 점에 대한 주의가 필요하며 프로덕션 환경에서 사용하기 전에는 철저한 테스트가 이루어져야 한다.
스토리지 서비스 품질과 같은 경우에는, 각 성능 특징을 나타내기 위해 서로 다른 스토리지 클래스 또는 프로필을 생성할 필요가 있다. 각 스토리지 프로필은 IO, 중복성, 처리량과 같이 서로 다른 워크로드에 최적화된 티어의 서비스와 묶을 수 있다. 테넌트가 자신의 워크로드에 적합한 스토리지 프로필을 적용하기 위해서는 추가적인 로직이 필요할 수 있다.
마지막으로, 파드에 우선순위 값을 부여할 수 있는 파드 우선순위와 선점이 있다. 파드 스케줄링 시에 우선순위가 높은 파드를 스케줄링하기 위한 리소스가 부족하다면, 스케줄러는 낮은 우선순위의 파드에 대한 축출을 시도한다. 공유 클러스터 내에서 다른 서비스 티어(예를 들어, 무료 및 유료)를 사용하는 테넌트를 가진 유스케이스가 있다면, 이러한 기능을 활용하여 특정 티어에 더 높은 우선순위를 부여할 수 있다.
DNS
쿠버네티스 클러스터는 네임과 IP 주소 간의 변환을 제공하기 위해 모든 서비스와 파드에서 도메인 네임 시스템(DNS) 서비스를 포함하고 있다. 기본적으로 쿠버네티스 DNS 서비스를 통해 클러스터 내 모든 네임스페이스를 조회할 수 있다.
테넌트가 파드 및 다른 쿠버네티스 리소스에 접근할 수 있거나, 더욱 강력한 격리가 필요한 멀티 테넌트 환경에서는 파드가 다른 네임스페이스의 서비스를 조회하는 것을 막는 것이 적절할 수 있다. 네임스페이스 교차 DNS 조회(cross-namespace DNS lookup)는 DNS 서비스의 보안 규칙 설정을 통해 제한할 수 있다. 예를 들어, CoreDNS(쿠버네티스 기본 DNS 서비스)는 쿠버네티스 메타데이터를 이용하여 네임스페이스 내의 파드 및 서비스에 대한 쿼리를 제한할 수 있다. 추가적인 정보는 CoreDNS 문서에 포함된 해당 사항을 설정하는 예시에서 확인할 수 있다.
테넌트 별 가상 컨트롤 플레인 모델이 사용될 시에는, 테넌트 별 DNS 서비스가 설정하거나 멀티 테넌트 DNS 서비스를 사용해야 한다. CoreDNS 사용자 맞춤 버전은 멀티 테넌트를 지원하는 하나의 예시이다.
오퍼레이터
오퍼레이터는 애플리케이션을 관리하는 쿠버네티스 컨트롤러이다. 오퍼레이터는 데이터베이스 서비스와 유사하게 애플리케이션의 여러 인스턴스를 간편하게 관리할 수 있어, 다중 소비자 (SaaS) 멀티 테넌시 유스케이스의 중요한 기반이 된다.
멀티 테넌트 환경에서 사용되는 오퍼레이터는 더욱 엄격한 가이드라인을 준수해야 한다. 다음은 오퍼레이터가 지켜야 할 사항이다.
- 오퍼레이터가 배포된 네임스페이스뿐만 아니라, 다른 테넌트 네임스페이스에서의 리소스 생성도 지원해야 한다.
- 스케줄링과 공평성을 보장하기 위해, 파드에 대한 리소스 요청 및 제한을 설정한다.
- 파드에서 노드 격리 및 샌드박스 컨테이너와 같은 데이터 플레인 격리 기법을 설정할 수 있도록 지원한다.
구현
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
멀티 테넌시를 위해 쿠버네티스 클러스터를 공유하는 대표적인 방법은 두 가지가 있으며, 이는 네임스페이스 사용 (테넌트 별 네임스페이스) 또는 컨트롤 플레인 가상화 (테넌트 별 가상 컨트롤 플레인)이다.
두 경우 모두 데이터 플레인 격리와 API 우선순위 및 공평성과 같은 추가적인 고려 사항에 대한 관리를 권고한다.
네임스페이스 격리는 쿠버네티스에서 지원이 잘 이루어지고 있으며, 아주 적은 리소스 비용을 소모하며 서비스 간의 통신과 같은 테넌트가 상호작용하기 위한 기능을 제공한다. 그러나 설정하는 과정이 복잡하며 커스텀 리소스 데피니션 정의, 스토리지 클래스, 웹훅과 같이 네임스페이스 적용을 받지 않은 쿠버네티스 리소스에 대해서는 적용되지 않는다.
컨트롤 플레인 가상화는 더 많은 리소스 사용량과 더 어려운 테넌트 교차 공유(cross-tenant sharing)를 대가로, 네임스페이스 되지 않은 리소스에 대한 격리 기능을 제공한다. 네임스페이스 격리로는 충분하지 않으며 높은 운영 비용 (특히 온 프레미스) 또는 큰 오버헤드와 리소스 공유의 부재로 인한 전용 클러스터는 사용하지 못할 때 좋은 선택지다. 그러나, 가상 컨트롤 플레인을 사용하더라도 네임스페이스를 같이 사용하면 이익을 볼 수 있다.
두 가지의 옵션은 다음 섹션에서 상세히 다룬다.
테넌트 별 네임스페이스
이전에 언급하였듯이, 전용 클러스터 또는 가상 컨트롤 플레인을 사용하더라도 각 워크로드를 개별 네임스페이스로 격리하는 것을 고려해 보아야 한다. 이를 통해 각 워크로드는 컨피그맵 및 시크릿과 같이 자신의 리소스에만 접근할 수 있으며 각 워크로드에 대한 전용 보안 정책을 조정할 수 있다. 추가적으로, 전용 및 공유 클러스터 간 전환 혹은 서비스 메쉬와 같은 멀티 클러스터 툴을 이용할 수 있는 유연성을 제공받기 위해 각 네임스페이스 이름을 전체 클러스터 무리 사이에서도 고유하게 짓는 것이 (즉, 서로 다른 클러스터에 위치하더라도) 모범 사례이다.
반대로 워크로드 레벨이 아닌, 하나의 테넌트가 소유한 모든 워크로드에 대해 적용되는 정책도 있기 때문에 테넌트 레벨에서의 네임스페이스 적용도 장점이 있다. 그러나 이는 또 다른 문제를 제기한다. 첫 번째로 개별 워크로드에 대한 맞춤 정책을 적용하는 것이 어렵거나 불가능해지며, 두 번째로는 네임스페이스를 적용받을 하나의 "테넌시" 레벨을 정하는 것이 어려울 수 있다. 예를 들어, 하나의 조직에 부서, 팀, 하위 팀이 있다고 하면 어떤 단위에 대해 네임스페이스를 적용해야 하는가?
이러한 문제의 해결책으로, 네임스페이스를 계층으로 정리하고 특정 정책 및 리소스를 사이에서 공유할 수 있는 계층적 네임스페이스 컨트롤러(HNC)를 쿠버네티스에서 제공하고 있다. 또한 네임스페이스 레이블 관리, 네임스페이스 라이프사이클, 관리 위임, 관련된 네임스페이스 사이에서 리소스 쿼터 공유와 같은 이점도 있다. 이러한 기능은 다중 팀 및 다중 고객 시나리오에서도 유용하다.
유사한 기능을 제공하며 네임스페이스 리소스 관리를 돕는 다른 프로젝트는 다음과 같다.
다중 팀 테넌시
다중 고객 테넌시
정책 엔진
정책 엔진은 테넌트 구성을 생성하고 검증하는 기능을 제공한다.
테넌트 별 가상 컨트롤 플레인
컨트롤 플레인 격리의 또 다른 형태로는 쿠버네티스 확장을 이용하여 클러스터 전범위의 API 리소스를 세분화할 수 있는, 각 테넌트에 가상 컨트롤 플레인을 제공하는 형태이다. 데이터 플레인 격리 기법을 이러한 모델과 함께 이용하여 테넌트 간의 워커 노드를 안전하게 관리할 수 있다.
가상 컨트롤 플레인 기반의 멀티 테넌시 모델은 각 테넌트에게 전용 컨트롤 플레인 요소를 제공하며 클러스터 전범위 리소스 및 애드온 서비스에 대한 완전한 제어를 부여하게 되어 네임스페이스 기반 멀티 테넌시를 확장한다. 워커 노드는 모든 테넌트 간 공유 되며, 일반적으로 테넌트에 의해 접근이 불가능한 쿠버네티스 클러스터에 의해 관리된다. 이러한 클러스터를 슈퍼 클러스터 (혹은 호스트 클러스터)라고 부른다. 테넌트의 컨트롤 플레인은 하위 컴퓨팅 리소스와 직접적으로 연결된 것이 아니기 때문에 가상 컨트롤 플레인 이라고 부른다.
가상 컨트롤 플레인은 일반적으로 쿠버네티스 API 서버, 컨트롤러 매니저, etcd 데이터 스토어로 구성되어 있다. 테넌트 컨트롤 플레인과 슈퍼 클러스터 컨트롤 플레인 간 변화를 조정하는 메타데이터 동기화 컨트롤러를 통해 슈퍼 클러스터와 상호작용한다.
하나의 API 서버를 사용하였을 때 나타나는 격리 문제는 테넌트 별 전용 컨트롤 플레인을 이용하면 해결된다. 몇 가지 예시로는, 컨트롤 플레인 내의 소란스러운 이웃 문제, 잘못된 정책 설정으로 인한 제어불능 영향 반경, 웹훅 및 CRD와 같은 클러스터 범위 오브젝트 간의 충돌이 있다. 그러므로 각 테넌트가 쿠버네티스 API 서버에 대한 접근 권한 및 완전한 클러스터 관리 기능이 필요한 경우, 가상 컨트롤 플레인 모델이 적합하다.
개선된 격리의 대가는 각 테넌트 별 가상 컨트롤 플레인을 운영하고 유지하는 비용에서 나타난다. 추가적으로, 각 테넌트 컨트롤 플레인은 노드 레벨에서의 소란스러운 이웃 문제 또는 보안 위협과 같은 데이터 플레인에서의 격리 문제를 해결하지 못한다. 이러한 문제에 대해서는 별도로 대응해야 한다.
쿠버네티스 클러스터 API - 네스티드(CAPN) 프로젝트는 가상 컨트롤 플레인 구현 방식을 제공한다.
이외의 구현 방식
10.1 - 리밋 레인지(Limit Range)
기본적으로 컨테이너는 쿠버네티스 클러스터에서 무제한 컴퓨팅 리소스로 실행된다. 쿠버네티스의 리소스 쿼터를 사용하면 클러스터 관리자(또는 클러스터 오퍼레이터 라고 함)는 네임스페이스별로 리소스(CPU 시간, 메모리 및 퍼시스턴트 스토리지) 사용과 생성을 제한할 수 있다. 네임스페이스 내에서 파드는 네임스페이스의 리소스 쿼터에 정의된 만큼의 CPU와 메모리를 사용할 수 있다. 클러스터 운영자 또는 네임스페이스 수준 관리자는 단일 오브젝트가 네임스페이스 내에서 사용 가능한 모든 리소스를 독점하지 못하도록 하는 것에 대해 우려할 수도 있다.
리밋레인지는 네임스페이스의 각 적용 가능한 오브젝트 종류(예: 파드 또는 퍼시스턴트볼륨클레임)에 대해 지정할 수 있는 리소스 할당(제한 및 요청)을 제한하는 정책이다.
리밋레인지 는 다음과 같은 제약 조건을 제공한다.
- 네임스페이스에서 파드 또는 컨테이너별 최소 및 최대 컴퓨팅 리소스 사용량을 지정한다.
- 네임스페이스에서 퍼시스턴트볼륨클레임별 최소 및 최대 스토리지 요청을 지정한다.
- 네임스페이스에서 리소스에 대한 요청과 제한 사이의 비율을 지정한다.
- 네임스페이스에서 컴퓨팅 리소스에 대한 기본 요청/제한을 설정하고 런타임에 있는 컨테이너에 자동으로 설정한다.
해당 네임스페이스에 리밋레인지 오브젝트가 있는 경우 특정 네임스페이스에 리밋레인지가 지정된다.
리밋레인지 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
리소스 제한 및 요청에 대한 제약
- 관리자는 네임스페이스에 리밋레인지를 생성한다.
- 사용자는 해당 네임스페이스에서 파드 또는 퍼시스턴트볼륨클레임과 같은 오브젝트를 생성하거나 생성하려고 시도한다.
- 첫째,
LimitRange어드미션 컨트롤러는 컴퓨팅 리소스 요구사항을 설정하지 않은 모든 파드(및 해당 컨테이너)에 대해 기본 요청 및 제한 값을 적용한다. - 둘째,
LimitRange는 사용량을 추적하여 네임스페이스에 존재하는LimitRange에 정의된 리소스 최소, 최대 및 비율을 초과하지 않는지 확인한다. - 리밋레인지 제약 조건을 위반하는 리소스(파드, 컨테이너, 퍼시스턴트볼륨클레임)를 생성하거나 업데이트하려고 하는 경우 HTTP 상태 코드
403 FORBIDDEN및 위반된 제약 조건을 설명하는 메시지와 함께 API 서버에 대한 요청이 실패한다. cpu,memory와 같은 컴퓨팅 리소스의 네임스페이스에서 리밋레인지를 추가한 경우 사용자는 해당 값에 대한 요청 또는 제한을 지정해야 한다. 그렇지 않으면 시스템에서 파드 생성이 거부될 수 있다.LimitRange유효성 검사는 실행 중인 파드가 아닌 파드 어드미션 단계에서만 수행된다. 리밋레인지가 추가되거나 수정되면, 해당 네임스페이스에 이미 존재하는 파드는 변경되지 않고 계속 유지된다.- 네임스페이스에 두 개 이상의
LimitRange오브젝트가 존재하는 경우, 어떤 기본값이 적용될지는 결정적이지 않다.
파드에 대한 리밋레인지 및 어드미션 확인
LimitRange는 적용하는 기본값의 일관성을 확인하지 않는다. 즉, LimitRange에 의해 설정된 limit 의 기본값이 클라이언트가 API 서버에 제출하는 스펙에서 컨테이너에 지정된 request 값보다 작을 수 있다. 이 경우, 최종 파드는 스케줄링할 수 없다.
예를 들어, 이 매니페스트에 LimitRange를 정의한다.
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 이 섹션에서는 기본 한도를 정의한다
cpu: 500m
defaultRequest: # 이 섹션에서는 기본 요청을 정의한다
cpu: 500m
max: # max와 min은 제한 범위를 정의한다
cpu: "1"
min:
cpu: 100m
이 때 CPU 리소스 요청을 700m로 선언하지만 제한은 선언하지 않는 파드를 포함한다.
apiVersion: v1
kind: Pod
metadata:
name: example-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: 700m
그러면 해당 파드는 스케줄링되지 않고 다음과 유사한 오류와 함께 실패한다.
Pod "example-conflict-with-limitrange-cpu" is invalid: spec.containers[0].resources.requests: Invalid value: "700m": must be less than or equal to cpu limit
request와 limit를 모두 설정하면, 동일한 LimitRange가 적용되어 있어도 새 파드는 성공적으로 스케줄링된다.
apiVersion: v1
kind: Pod
metadata:
name: example-no-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: 700m
limits:
cpu: 700m
리소스 제약 예시
LimitRange를 사용하여 생성할 수 있는 정책의 예는 다음과 같다.
- 용량이 8GiB RAM과 16 코어인 2 노드 클러스터에서 네임스페이스의 파드를 제한하여 CPU의 최대 제한이 500m인 CPU 100m를 요청하고 메모리의 최대 제한이 600M인 메모리 200Mi를 요청하라.
- 스펙에 CPU 및 메모리 요청없이 시작된 컨테이너에 대해 기본 CPU 제한 및 요청을 150m로, 메모리 기본 요청을 300Mi로 정의하라.
네임스페이스의 총 제한이 파드/컨테이너의 제한 합보다 작은 경우 리소스에 대한 경합이 있을 수 있다. 이 경우 컨테이너 또는 파드가 생성되지 않는다.
경합이나 리밋레인지 변경은 이미 생성된 리소스에 영향을 미치지 않는다.
다음 내용
제한의 사용에 대한 예시는 다음을 참조한다.
- 네임스페이스당 최소 및 최대 CPU 제약 조건을 설정하는 방법.
- 네임스페이스당 최소 및 최대 메모리 제약 조건을 설정하는 방법.
- 네임스페이스당 기본 CPU 요청과 제한을 설정하는 방법.
- 네임스페이스당 기본 메모리 요청과 제한을 설정하는 방법.
- 네임스페이스당 최소 및 최대 스토리지 사용량을 설정하는 방법.
- 네임스페이스당 할당량을 설정하는 자세한 예시.
컨텍스트 및 기록 정보는 LimitRanger 디자인 문서를 참조한다.
10.2 - 리소스 쿼터
여러 사용자나 팀이 정해진 수의 노드로 클러스터를 공유할 때 한 팀이 공정하게 분배된 리소스보다 많은 리소스를 사용할 수 있다는 우려가 있다.
리소스 쿼터는 관리자가 이 문제를 해결하기 위한 도구이다.
ResourceQuota 오브젝트로 정의된 리소스 쿼터는 네임스페이스별 총 리소스 사용을 제한하는
제약 조건을 제공한다. 유형별로 네임스페이스에서 만들 수 있는 오브젝트 수와
해당 네임스페이스의 리소스가 사용할 수 있는 총 컴퓨트 리소스의 양을
제한할 수 있다.
리소스 쿼터는 다음과 같이 작동한다.
-
다른 팀은 다른 네임스페이스에서 작업한다. 이것은 RBAC으로 설정할 수 있다.
-
관리자는 각 네임스페이스에 대해 하나의 리소스쿼터를 생성한다.
-
사용자는 네임스페이스에서 리소스(파드, 서비스 등)를 생성하고 쿼터 시스템은 사용량을 추적하여 리소스쿼터에 정의된 하드(hard) 리소스 제한을 초과하지 않도록 한다.
-
리소스를 생성하거나 업데이트할 때 쿼터 제약 조건을 위반하면 위반된 제약 조건을 설명하는 메시지와 함께 HTTP 상태 코드
403 FORBIDDEN으로 요청이 실패한다. -
cpu,memory와 같은 컴퓨트 리소스에 대해 네임스페이스에서 쿼터가 활성화된 경우 사용자는 해당값에 대한 요청 또는 제한을 지정해야 한다. 그렇지 않으면 쿼터 시스템이 파드 생성을 거부할 수 있다. 힌트: 컴퓨트 리소스 요구 사항이 없는 파드를 기본값으로 설정하려면LimitRanger어드미션 컨트롤러를 사용하자.이 문제를 회피하는 방법에 대한 예제는 연습을 참고하길 바란다.
참고:
- 리소스쿼터는
cpu및memory리소스의 경우, 해당 네임스페이스의 모든 (신규) 파드가 해당 리소스에 대한 제한을 설정하도록 강제한다. 네임스페이스에서cpu또는memory에 대해 리소스 할당량을 적용하는 경우, 사용자와 다른 클라이언트는 반드시 제출하는 모든 새 파드에 대해 해당 리소스에requests또는limits중 하나를 지정해야 한다. 그렇지 않으면 컨트롤 플레인이 해당 파드에 대한 어드미션을 거부할 수 있다. - 다른 리소스의 경우: 리소스쿼터는 작동하며 해당 리소스에 대한 제한이나 요청을 설정하지 않고 네임스페이스의 파드를 무시한다. 즉, 리소스 쿼터가 이 네임스페이스의 임시 스토리지를 제한하는 경우 임시 스토리지를 제한/요청하지 않고 새 파드를 생성할 수 있다. 리밋 레인지(Limit Range)를 사용하여 이러한 리소스에 대한 기본 요청을 자동으로 설정할 수 있다.
리소스쿼터 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
네임스페이스와 쿼터를 사용하여 만들 수 있는 정책의 예는 다음과 같다.
- 용량이 32GiB RAM, 16 코어인 클러스터에서 A 팀이 20GiB 및 10 코어를 사용하고 B 팀은 10GiB 및 4 코어를 사용하게 하고 2GiB 및 2 코어를 향후 할당을 위해 보유하도록 한다.
- "testing" 네임스페이스를 1 코어 및 1GiB RAM을 사용하도록 제한한다. "production" 네임스페이스에는 원하는 양을 사용하도록 한다.
클러스터의 총 용량이 네임스페이스의 쿼터 합보다 작은 경우 리소스에 대한 경합이 있을 수 있다. 이것은 선착순으로 처리된다.
경합이나 쿼터 변경은 이미 생성된 리소스에 영향을 미치지 않는다.
리소스 쿼터 활성화
많은 쿠버네티스 배포판에 기본적으로 리소스 쿼터 지원이 활성화되어 있다.
API 서버
--enable-admission-plugins= 플래그의 인수 중 하나로
ResourceQuota가 있는 경우 활성화된다.
해당 네임스페이스에 리소스쿼터가 있는 경우 특정 네임스페이스에 리소스 쿼터가 적용된다.
컴퓨트 리소스 쿼터
지정된 네임스페이스에서 요청할 수 있는 총 컴퓨트 리소스 합을 제한할 수 있다.
다음과 같은 리소스 유형이 지원된다.
| 리소스 이름 | 설명 |
|---|---|
limits.cpu |
터미널이 아닌 상태의 모든 파드에서 CPU 제한의 합은 이 값을 초과할 수 없음. |
limits.memory |
터미널이 아닌 상태의 모든 파드에서 메모리 제한의 합은 이 값을 초과할 수 없음. |
requests.cpu |
터미널이 아닌 상태의 모든 파드에서 CPU 요청의 합은 이 값을 초과할 수 없음. |
requests.memory |
터미널이 아닌 상태의 모든 파드에서 메모리 요청의 합은 이 값을 초과할 수 없음. |
hugepages-<size> |
터미널 상태가 아닌 모든 파드에 걸쳐서, 지정된 사이즈의 휴즈 페이지 요청은 이 값을 초과하지 못함. |
cpu |
requests.cpu 와 같음. |
memory |
requests.memory 와 같음. |
확장된 리소스에 대한 리소스 쿼터
위에서 언급한 리소스 외에도 릴리스 1.10에서는 확장된 리소스에 대한 쿼터 지원이 추가되었다.
확장된 리소스에는 오버커밋(overcommit)이 허용되지 않으므로 하나의 쿼터에서
동일한 확장된 리소스에 대한 requests와 limits을 모두 지정하는 것은 의미가 없다. 따라서 확장된
리소스의 경우 지금은 접두사 requests.이 있는 쿼터 항목만 허용된다.
예를 들어, 리소스 이름이 nvidia.com/gpu이고 네임스페이스에서 요청된 총 GPU 수를 4개로 제한하려는 경우,
GPU 리소스를 다음과 같이 쿼터를 정의할 수 있다.
requests.nvidia.com/gpu: 4
자세한 내용은 쿼터 보기 및 설정을 참고하길 바란다.
스토리지 리소스 쿼터
지정된 네임스페이스에서 요청할 수 있는 총 스토리지 리소스 합을 제한할 수 있다.
또한 연관된 스토리지 클래스를 기반으로 스토리지 리소스 사용을 제한할 수 있다.
| 리소스 이름 | 설명 |
|---|---|
requests.storage |
모든 퍼시스턴트 볼륨 클레임에서 스토리지 요청의 합은 이 값을 초과할 수 없음 |
persistentvolumeclaims |
네임스페이스에 존재할 수 있는 총 퍼시스턴트 볼륨 클레임 수 |
<storage-class-name>.storageclass.storage.k8s.io/requests.storage |
storage-class-name과 관련된 모든 퍼시스턴트 볼륨 클레임에서 스토리지 요청의 합은 이 값을 초과할 수 없음 |
<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims |
<storage-class-name> 과 관련된 모든 퍼시스턴트 볼륨 클레임에서 네임스페이스에 존재할 수 있는 총 퍼시스턴트 볼륨 클레임 수 |
예를 들어, 운영자가 bronze 스토리지 클래스와 별도로 gold 스토리지 클래스를 사용하여 스토리지에 쿼터를 지정하려는 경우 운영자는 다음과 같이
쿼터를 정의할 수 있다.
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
릴리스 1.8에서는 로컬 임시 스토리지에 대한 쿼터 지원이 알파 기능으로 추가되었다.
| 리소스 이름 | 설명 |
|---|---|
requests.ephemeral-storage |
네임스페이스의 모든 파드에서 로컬 임시 스토리지 요청의 합은 이 값을 초과할 수 없음. |
limits.ephemeral-storage |
네임스페이스의 모든 파드에서 로컬 임시 스토리지 제한의 합은 이 값을 초과할 수 없음. |
ephemeral-storage |
requests.ephemeral-storage 와 같음. |
참고:
CRI 컨테이너 런타임을 사용할 때, 컨테이너 로그는 임시 스토리지 쿼터에 포함된다. 이로 인해 스토리지 쿼터를 소진한 파드가 예기치 않게 축출될 수 있다. 자세한 내용은 로깅 아키텍처를 참조한다.오브젝트 수 쿼터
다음 구문을 사용하여 모든 표준 네임스페이스 처리된(namespaced) 리소스 유형에 대한 특정 리소스 전체 수에 대하여 쿼터를 지정할 수 있다.
- 코어 그룹이 아닌(non-core) 리소스를 위한
count/<resource>.<group> - 코어 그룹의 리소스를 위한
count/<resource>
다음은 사용자가 오브젝트 수 쿼터 아래에 배치하려는 리소스 셋의 예이다.
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
사용자 정의 리소스를 위해 동일한 구문을 사용할 수 있다.
예를 들어 example.com API 그룹에서 widgets 사용자 정의 리소스에 대한 쿼터를 생성하려면 count/widgets.example.com을 사용한다.
count/* 리소스 쿼터를 사용할 때 서버 스토리지 영역에 있다면 오브젝트는 쿼터에 대해 과금된다.
이러한 유형의 쿼터는 스토리지 리소스 고갈을 방지하는 데 유용하다. 예를 들어,
크기가 큰 서버에서 시크릿 수에 쿼터를 지정할 수 있다. 클러스터에 시크릿이 너무 많으면 실제로 서버와
컨트롤러가 시작되지 않을 수 있다. 잘못 구성된 크론 잡으로부터의 보호를 위해
잡의 쿼터를 설정할 수 있다. 네임스페이스 내에서 너무 많은 잡을 생성하는 크론 잡은 서비스 거부를 유발할 수 있다.
또한 제한된 리소스 셋에 대해서 일반 오브젝트 수(generic object count) 쿼터를 적용하는 것도 가능하다. 다음 유형이 지원된다.
| 리소스 이름 | 설명 |
|---|---|
configmaps |
네임스페이스에 존재할 수 있는 총 컨피그맵 수 |
persistentvolumeclaims |
네임스페이스에 존재할 수 있는 총 퍼시스턴트 볼륨 클레임 수 |
pods |
네임스페이스에 존재할 수 있는 터미널이 아닌 상태의 파드의 총 수. .status.phase in (Failed, Succeeded)가 true인 경우 파드는 터미널 상태임 |
replicationcontrollers |
네임스페이스에 존재할 수 있는 총 레플리케이션컨트롤러 수 |
resourcequotas |
네임스페이스에 존재할 수 있는 총 리소스쿼터 수 |
services |
네임스페이스에 존재할 수 있는 총 서비스 수 |
services.loadbalancers |
네임스페이스에 존재할 수 있는 LoadBalancer 유형의 총 서비스 수 |
services.nodeports |
네임스페이스에 존재할 수 있는 NodePort 유형의 총 서비스 수 |
secrets |
네임스페이스에 존재할 수 있는 총 시크릿 수 |
예를 들어, pods 쿼터는 터미널이 아닌 단일 네임스페이스에서 생성된 pods 수를
계산하고 최댓값을 적용한다. 사용자가 작은 파드를 많이 생성하여 클러스터의 파드 IP
공급이 고갈되는 경우를 피하기 위해 네임스페이스에
pods 쿼터를 설정할 수 있다.
쿼터 범위
각 쿼터에는 연결된 scopes 셋이 있을 수 있다. 쿼터는 열거된 범위의 교차 부분과 일치하는 경우에만
리소스 사용량을 측정한다.
범위가 쿼터에 추가되면 해당 범위와 관련된 리소스를 지원하는 리소스 수가 제한된다. 허용된 셋 이외의 쿼터에 지정된 리소스는 유효성 검사 오류가 발생한다.
| 범위 | 설명 |
|---|---|
Terminating |
.spec.activeDeadlineSeconds >= 0에 일치하는 파드 |
NotTerminating |
.spec.activeDeadlineSeconds is nil에 일치하는 파드 |
BestEffort |
최상의 서비스 품질을 제공하는 파드 |
NotBestEffort |
서비스 품질이 나쁜 파드 |
PriorityClass |
지정된 프라이어리티클래스를 참조하여 일치하는 파드. |
CrossNamespacePodAffinity |
크로스-네임스페이스 파드 [(안티)어피니티 용어]가 있는 파드 |
BestEffort 범위는 다음의 리소스를 추적하도록 쿼터를 제한한다.
pods
Terminating, NotTerminating, NotBestEffort 및 PriorityClass
범위는 쿼터를 제한하여 다음의 리소스를 추적한다.
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory
Terminating 과 NotTerminating 범위를 동일한 쿼터 내에 모두
명시하지는 못하며, 마찬가지로 BestEffort 와
NotBestEffort 범위도 동일한 쿼터 내에서 모두 명시하지는 못한다.
scopeSelector 는 operator 필드에 다음의 값을 지원한다.
InNotInExistsDoesNotExist
scopeSelector 를 정의할 때, scopeName 으로 다음의 값 중 하나를 사용하는
경우, operator 는 Exists 이어야 한다.
TerminatingNotTerminatingBestEffortNotBestEffort
만약 operator 가 In 또는 NotIn 인 경우, values 필드는 적어도 하나의 값은
가져야 한다. 예를 들면 다음과 같다.
scopeSelector:
matchExpressions:
- scopeName: PriorityClass
operator: In
values:
- middle
만약 operator 가 Exists 또는 DoesNotExist 이라면, values 필드는 명시되면
안된다.
PriorityClass별 리소스 쿼터
기능 상태:
Kubernetes v1.17 [stable]
특정 우선 순위로 파드를 생성할 수 있다.
쿼터 스펙의 scopeSelector 필드를 사용하여 파드의 우선 순위에 따라 파드의 시스템 리소스 사용을
제어할 수 있다.
쿼터 스펙의 scopeSelector가 파드를 선택한 경우에만 쿼터가 일치하고 사용된다.
scopeSelector 필드를 사용하여 우선 순위 클래스의 쿼터 범위를 지정하면,
쿼터 오브젝트는 다음의 리소스만 추적하도록 제한된다.
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
이 예에서는 쿼터 오브젝트를 생성하여 특정 우선 순위의 파드와 일치시킨다. 예제는 다음과 같이 작동한다.
- 클러스터의 파드는 "low(낮음)", "medium(중간)", "high(높음)"의 세 가지 우선 순위 클래스 중 하나를 가진다.
- 각 우선 순위마다 하나의 쿼터 오브젝트가 생성된다.
다음 YAML을 quota.yml 파일에 저장한다.
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["low"]
kubectl create를 사용하여 YAML을 적용한다.
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
kubectl describe quota를 사용하여 Used 쿼터가 0인지 확인하자.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
우선 순위가 "high"인 파드를 생성한다. 다음 YAML을
high-priority-pod.yml 파일에 저장한다.
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "10Gi"
cpu: "500m"
limits:
memory: "10Gi"
cpu: "500m"
priorityClassName: high
kubectl create로 적용하자.
kubectl create -f ./high-priority-pod.yml
"high" 우선 순위 쿼터가 적용된 pods-high에 대한 "Used" 통계가 변경되었고
다른 두 쿼터는 변경되지 않았는지 확인한다.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
네임스페이스 간 파드 어피니티 쿼터
기능 상태:
Kubernetes v1.24 [stable]
오퍼레이터는 네임스페이스를 교차하는 어피니티가 있는 파드를 가질 수 있는 네임스페이스를
제한하기 위해 CrossNamespacePodAffinity 쿼터 범위를 사용할 수 있다. 특히, 파드 어피니티 용어의
namespaces 또는 namespaceSelector 필드를 설정할 수 있는 파드를 제어한다.
안티-어피니티 제약 조건이 있는 파드는 장애 도메인에서 다른 모든 네임스페이스의 파드가 예약되지 않도록 차단할 수 있으므로 사용자가 네임스페이스 간 어피니티 용어를 사용하지 못하도록 하는 것이 바람직할 수 있다.
이 범위 오퍼레이터를 사용하면 CrossNamespaceAffinity 범위와 하드(hard) 제한이 0인
네임스페이스에 리소스 쿼터 오브젝트를 생성하여 특정 네임스페이스(아래 예에서 foo-ns)가 네임스페이스 간 파드 어피니티를
사용하는 파드를 사용하지 못하도록 방지할 수 있다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: disable-cross-namespace-affinity
namespace: foo-ns
spec:
hard:
pods: "0"
scopeSelector:
matchExpressions:
- scopeName: CrossNamespaceAffinity
오퍼레이터가 기본적으로 namespaces 및 namespaceSelector 사용을 허용하지 않고,
특정 네임스페이스에만 허용하려는 경우, kube-apiserver 플래그 --admission-control-config-file를
다음의 구성 파일의 경로로 설정하여 CrossNamespaceAffinity 를
제한된 리소스로 구성할 수 있다.
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: CrossNamespaceAffinity
위의 구성을 사용하면, 파드는 생성된 네임스페이스에 CrossNamespaceAffinity 범위가 있는 리소스 쿼터 오브젝트가 있고,
해당 필드를 사용하는 파드 수보다 크거나 같은 하드 제한이 있는 경우에만
파드 어피니티에서 namespaces 및 namespaceSelector 를 사용할 수 있다.
요청과 제한의 비교
컴퓨트 리소스를 할당할 때 각 컨테이너는 CPU 또는 메모리에 대한 요청과 제한값을 지정할 수 있다. 쿼터는 값에 대한 쿼터를 지정하도록 구성할 수 있다.
쿼터에 requests.cpu나 requests.memory에 지정된 값이 있으면 들어오는 모든
컨테이너가 해당 리소스에 대한 명시적인 요청을 지정해야 한다. 쿼터에 limits.cpu나
limits.memory에 지정된 값이 있으면 들어오는 모든 컨테이너가 해당 리소스에 대한 명시적인 제한을 지정해야 한다.
쿼터 보기 및 설정
Kubectl은 쿼터 생성, 업데이트 및 보기를 지원한다.
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace=myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace=myspace
kubectl get quota --namespace=myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace=myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace=myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
Kubectl은 count/<resource>.<group> 구문을 사용하여 모든 표준 네임스페이스 리소스에 대한
오브젝트 수 쿼터를 지원한다.
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.apps=2,count/replicasets.apps=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl create deployment nginx --image=nginx --namespace=myspace --replicas=2
kubectl describe quota --namespace=myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
쿼터 및 클러스터 용량
리소스쿼터는 클러스터 용량과 무관하다. 그것들은 절대 단위로 표현된다. 따라서 클러스터에 노드를 추가해도 각 네임스페이스에 더 많은 리소스를 사용할 수 있는 기능이 자동으로 부여되지는 않는다.
가끔 다음과 같은 보다 복잡한 정책이 필요할 수 있다.
- 여러 팀으로 전체 클러스터 리소스를 비례적으로 나눈다.
- 각 테넌트가 필요에 따라 리소스 사용량을 늘릴 수 있지만, 실수로 리소스가 고갈되는 것을 막기 위한 충분한 제한이 있다.
- 하나의 네임스페이스에서 요구를 감지하고 노드를 추가하며 쿼터를 늘린다.
이러한 정책은 쿼터 사용을 감시하고 다른 신호에 따라 각 네임스페이스의 쿼터 하드 제한을
조정하는 "컨트롤러"를 작성하여 ResourceQuotas를 구성 요소로
사용하여 구현할 수 있다.
리소스 쿼터는 통합된 클러스터 리소스를 분할하지만 노드에 대한 제한은 없다. 여러 네임스페이스의 파드가 동일한 노드에서 실행될 수 있다.
기본적으로 우선 순위 클래스 소비 제한
파드가 특정 우선 순위, 예를 들어 일치하는 쿼터 오브젝트가 존재하는 경우에만 "cluster-services"가 네임스페이스에 허용되어야 한다.
이 메커니즘을 통해 운영자는 특정 우선 순위가 높은 클래스의 사용을 제한된 수의 네임스페이스로 제한할 수 있으며 모든 네임스페이스가 기본적으로 이러한 우선 순위 클래스를 사용할 수 있는 것은 아니다.
이를 적용하려면 kube-apiserver 플래그 --admission-control-config-file 을
사용하여 다음 구성 파일의 경로를 전달해야 한다.
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: PriorityClass
operator: In
values: ["cluster-services"]
그리고, kube-system 네임스페이스에 리소스 쿼터 오브젝트를 생성한다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-cluster-services
spec:
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["cluster-services"]kubectl apply -f https://k8s.io/examples/policy/priority-class-resourcequota.yaml -n kube-system
resourcequota/pods-cluster-services created
이 경우, 파드 생성은 다음의 조건을 만족해야 허용될 것이다.
- 파드의
priorityClassName가 명시되지 않음. - 파드의
priorityClassName가cluster-services이외의 다른 값으로 명시됨. - 파드의
priorityClassName가cluster-services로 설정되고, 파드가kube-system네임스페이스에 생성되었으며 리소스 쿼터 검증을 통과함.
파드 생성 요청은 priorityClassName 가 cluster-services 로 명시되고
kube-system 이외의 다른 네임스페이스에 생성되는 경우, 거절된다.
다음 내용
- 자세한 내용은 리소스쿼터 디자인 문서를 참고한다.
- 리소스 쿼터를 사용하는 방법에 대한 자세한 예를 참고한다.
- 우선 순위 클래스에 대한 쿼터 지원 디자인 문서를 읽는다.
- 제한된 자원을 참고한다.
10.3 - 프로세스 ID 제한 및 예약
기능 상태:
Kubernetes v1.20 [stable]
쿠버네티스에서 파드가 사용할 수 있는 프로세스 ID(PID)의 수를 제한할 수 있다. 또한 (파드가 아닌) 운영체제와 데몬이 사용할 용도로 각 노드에 대해 할당 가능한 PID의 수를 미리 예약할 수 있다.
프로세스 ID(PID)는 노드에서 기본이 되는 리소스이다. 다른 종류의 리소스 상한(limit)을 초과하지 않고도, 태스크의 상한을 초과하게 되는 상황은 일상적이며 사소해 보일 수 있다. 그러나, 이러한 상황은 호스트 머신의 불안정성을 야기할 수 있다.
클러스터 관리자는 클러스터에서 실행 중인 파드가 호스트 데몬(예를 들어, kubelet 또는 kube-proxy 그리고 잠재적 컨테이너 런타임)이 실행되는 것을 방해하는 PID 소진이 발생하지 않도록 하는 메커니즘이 필요하다. 추가적으로, PID가 동일한 노드의 다른 워크로드에 미치는 영향을 제한하려면 파드 간에 PID를 제한하는 것이 중요하다.
참고:
특정 리눅스 설치에서는, 운영 체제가 PID 제한을 '32768'과 같은 낮은 기본값으로 설정한다./proc/sys/kernel/pid_max의 값을 높이는 것을 고려하길 바란다.지정된 파드가 사용할 수 있는 PID 수를 제한하도록 kubelet을 구성할 수 있다. 예를 들어, 노드의 호스트 OS가 최대 '262144' PID를 사용하도록 설정되어 있고 '250' 미만의 파드를 호스팅할 것으로 예상되는 경우, 각 파드에 '1000' PID의 양을 할당하여 해당 노드의 가용 PID의 수를 전부 소비해버리지 않도록 방지할 수 있다. 관리자는 몇 가지 추가 위험을 감수하여 CPU 또는 메모리와 유사한 PID를 오버 커밋할 수 있다. 어느 쪽이든 간에, 하나의 파드가 전체 시스템을 중단시키지는 않을 것이다. 이러한 종류의 리소스 제한은 단순 포크 폭탄(fork bomb)이 전체 클러스터의 작동에 영향을 미치는 것을 방지하는 데 도움이 된다.
관리자는 파드별 PID 제한을 통해 각 파드를 서로에게서 보호할 수 있지만, 해당 호스트에 배정된 모든 파드가 노드 전체에 영향을 미치지 못함을 보장하진 않는다. 또한 파드별 제한은 노드 에이전트 자체를 PID 고갈로부터 보호하지 않는다.
또한 파드에 대한 할당과는 별도로, 노드 오버헤드를 위해 일정량의 PID를 예약할 수 있다. 이는 파드와 해당 컨테이너 외부의 운영 체제 및 기타 장비에서 사용하기 위해 CPU, 메모리 또는 기타 리소스를 예약하는 방식과 유사하다.
PID 제한은 컴퓨팅 리소스 요청 및 제한에서 중요한 개념이다. 하지만 다른 방식으로 명시한다. 파드의 '.spec'에 파드 리소스 제한을 정의하는 대신, kubelet 설정에서 제한을 구성한다. 파드에서 정의하는 PID 제한은 현재 지원되지 않는다.
주의:
파드가 배포된 위치에 따라 파드에 적용되는 제한이 다를 수 있다. 간단히 하자면, 모든 노드에서 동일한 PID 리소스 제한 및 예약을 사용하는 것이 가장 쉽다.노드 PID 제한
쿠버네티스를 사용하면 시스템 사용을 위해 여러 프로세스 ID를 예약할 수 있다.
예약을 구성하려면 --system-reserved 및 --kube-reserved 명령줄 옵션에서
pid=<number> 매개변수를 kubelet에 사용하면 된다.
지정한 값은 지정된 수의 프로세스 ID가
시스템 전체와 Kubernetes 시스템 데몬에 각각 예약됨을
선언한다.
참고:
쿠버네티스 1.20 버전 이전에서 노드 단위로 PID 리소스 제한을 예약하려면 'SupportNodePidsLimit' 기능 게이트가 작동하도록 설정해야 한다.파드 PID 제한
쿠버네티스를 사용하면 파드에서 실행되는 프로세스 수를 제한할 수 있다.
이 제한을 특정 파드에 대한 리소스 제한으로 구성하는 대신 노드 수준에서 지정한다.
각각의 노드는 다른 PID 제한을 가질 수 있다.
제한을 구성하려면 kubelet에 커맨드라인 매개변수 --pod-max-pids를
지정하거나, kubelet 구성 파일에서
PodPidsLimit을 설정하면 된다.
참고:
쿠버네티스 1.20 버전 이전에서 파드에 대한 PID 리소스를 제한하려면 기능 게이트 'SupportPodPidsLimit'이 작동하도록 설정해야 한다.PID 기반 축출(eviction)
파드가 오작동하고 비정상적인 양의 리소스를 사용할 때 파드를 종료하게끔 kubelet을 구성할 수 있다.
이 기능을 축출(eviction)이라고 한다. 다양한
축출 신호에 대한 리소스 부족 처리를 구성할
수 있다.
pid.available 축출 신호를 사용하여 파드에서 사용하는 PID 수에 대한 임계값을 구성한다.
소프트(soft) 및 하드(hard) 축출 정책을 설정할 수 있다.
그러나 하드 축출 정책을 사용하더라도 PID 수가 매우 빠르게 증가하면,
노드 PID 제한에 도달하여 노드가 여전히 불안정한 상태가 될 수 있다.
축출 신호 값은 주기적으로 계산되는 것이며 제한을 강제하지는 않는다.
PID 제한 - 각 파드와 각 노드는 하드 제한을 설정한다. 제한에 도달하게 되면, 새로운 PID를 가져오려고 할 때 워크로드에 오류가 발생할 것이다. 워크로드가 이러한 장애에 대응하는 방식과 파드에 대한 활성 및 준비성 프로브가 어떻게 구성되었는지에 따라, 파드가 재배포(rescheduling)될 수도 있고 그렇지 않을 수도 있다. 그러나 제한이 올바르게 설정되었다면, 하나의 파드가 오작동할 때 다른 파드 워크로드 및 시스템 프로세스에 PID가 부족하지 않도록 보장할 수 있다.
다음 내용
- 자세한 내용은 PID 제한 개선 문서를 참고한다.
- 역사적인 맥락을 원한다면, Kubernetes 1.14의 안정성 향상을 위한 프로세스 ID 제한을 참고한다.
- 컨테이너에 대한 리소스 관리를 읽는다.
- 리소스 부족 처리 구성을 배운다.
10.4 - 노드 리소스 매니저
쿠버네티스는 지연 시간에 민감하고 처리량이 많은 워크로드를 지원하기 위해 리소스 매니저 세트를 제공한다. 매니저는 CPU, 장치 및 메모리 (hugepages) 리소스와 같은 특정한 요구 사항으로 구성된 파드를 위해 노드의 리소스 할당을 조정하고 최적화하는 것을 목표로 한다.
주 매니저인 토폴로지 매니저는 정책을 통해 전체 리소스 관리 프로세스를 조정하는 Kubelet 컴포넌트이다.
개별 매니저의 구성은 다음의 문서에 자세히 기술되어 있다.
11 - 스케줄링, 선점(Preemption), 축출(Eviction)
쿠버네티스에서, 스케줄링은 kubelet이 파드를 실행할 수 있도록 파드를 노드에 할당하는 것을 말한다. 선점은 우선순위가 높은 파드가 노드에 스케줄될 수 있도록 우선순위가 낮은 파드를 종료시키는 과정을 말한다. 축출은 리소스가 부족한 노드에서 하나 이상의 파드를 사전에 종료시키는 프로세스이다.
쿠버네티스에서, 스케줄링은 kubelet이 파드를 실행할 수 있도록 파드를 노드에 할당하는 것을 말한다. 선점은 우선순위가 높은 파드가 노드에 스케줄될 수 있도록 우선순위가 낮은 파드를 종료시키는 과정을 말한다. 축출은 리소스가 부족한 노드에서 하나 이상의 파드를 사전에 종료시키는 프로세스이다.
스케줄링
- 쿠버네티스 스케줄러
- 노드에 파드 할당하기
- 파드 오버헤드
- 파드 토폴로지 분배 제약 조건
- 테인트(Taints)와 톨러레이션(Tolerations)
- 스케줄링 프레임워크
- 동적 리소스 할당
- 스케줄러 성능 튜닝
- 확장된 리소스를 위한 리소스 빈 패킹(bin packing)
- 파드 스케줄링 준비성(readiness)
파드 중단(disruption)
파드 중단은 노드에 있는 파드가 자발적 또는 비자발적으로 종료되는 절차이다.
자발적 중단은 애플리케이션 소유자 또는 클러스터 관리자가 의도적으로 시작한다. 비자발적 중단은 의도하지 않은 것이며, 노드의 리소스 부족과 같은 피할 수 없는 문제 또는 우발적인 삭제로 인해 트리거가 될 수 있다.
11.1 - 쿠버네티스 스케줄러
쿠버네티스에서 스케줄링 은 Kubelet이 파드를 실행할 수 있도록 파드가 노드에 적합한지 확인하는 것을 말한다.
스케줄링 개요
스케줄러는 노드가 할당되지 않은 새로 생성된 파드를 감시한다. 스케줄러가 발견한 모든 파드에 대해 스케줄러는 해당 파드가 실행될 최상의 노드를 찾는 책임을 진다. 스케줄러는 아래 설명된 스케줄링 원칙을 고려하여 이 배치 결정을 하게 된다.
파드가 특정 노드에 배치되는 이유를 이해하려고 하거나 사용자 정의된 스케줄러를 직접 구현하려는 경우 이 페이지를 통해서 스케줄링에 대해 배울 수 있을 것이다.
kube-scheduler
kube-scheduler는 쿠버네티스의 기본 스케줄러이며 컨트롤 플레인의 일부로 실행된다. kube-scheduler는 원하거나 필요에 따라 자체 스케줄링 컴포넌트를 만들고 대신 사용할 수 있도록 설계되었다.
kube-scheduler는 새로 생성되었거나 아직 예약되지 않은(스케줄링되지 않은) 파드를 실행할 최적의 노드를 선택한다. 파드의 컨테이너와 파드 자체는 서로 다른 요구사항을 가질 수 있으므로, 스케줄러는 파드의 특정 스케줄링 요구사항을 충족하지 않는 모든 노드를 필터링한다. 또는 API를 사용하면 파드를 생성할 때 노드를 지정할 수 있지만, 이는 드문 경우이며 특별한 경우에만 수행된다.
클러스터에서 파드에 대한 스케줄링 요구사항을 충족하는 노드를 실행 가능한(feasible) 노드라고 한다. 적합한 노드가 없으면 스케줄러가 배치할 수 있을 때까지 파드가 스케줄 되지 않은 상태로 유지된다.
스케줄러는 파드가 실행 가능한 노드를 찾은 다음 실행 가능한 노드의 점수를 측정하는 기능 셋을 수행하고 실행 가능한 노드 중에서 가장 높은 점수를 가진 노드를 선택하여 파드를 실행한다. 그런 다음 스케줄러는 바인딩 이라는 프로세스에서 이 결정에 대해 API 서버에 알린다.
스케줄링 결정을 위해 고려해야 할 요소에는 개별 및 집단 리소스 요구사항, 하드웨어 / 소프트웨어 / 정책 제한조건, 어피니티 및 안티-어피니티 명세, 데이터 지역성(data locality), 워크로드 간 간섭 등이 포함된다.
kube-scheduler에서 노드 선택
kube-scheduler는 2단계 작업에서 파드에 대한 노드를 선택한다.
- 필터링
- 스코어링(scoring)
필터링 단계는 파드를 스케줄링 할 수 있는 노드 셋을 찾는다. 예를 들어 PodFitsResources 필터는 후보 노드가 파드의 특정 리소스 요청을 충족시키기에 충분한 가용 리소스가 있는지 확인한다. 이 단계 다음에 노드 목록에는 적합한 노드들이 포함된다. 하나 이상의 노드가 포함된 경우가 종종 있을 것이다. 목록이 비어 있으면 해당 파드는 (아직) 스케줄링 될 수 없다.
스코어링 단계에서 스케줄러는 목록에 남아있는 노드의 순위를 지정하여 가장 적합한 파드 배치를 선택한다. 스케줄러는 사용 중인 스코어링 규칙에 따라 이 점수를 기준으로 필터링에서 통과된 각 노드에 대해 점수를 지정한다.
마지막으로 kube-scheduler는 파드를 순위가 가장 높은 노드에 할당한다. 점수가 같은 노드가 두 개 이상인 경우 kube-scheduler는 이들 중 하나를 임의로 선택한다.
스케줄러의 필터링 및 스코어링 동작을 구성하는 데 지원되는 두 가지 방법이 있다.
- 스케줄링 정책을 사용하면 필터링을 위한 단정(Predicates) 및 스코어링을 위한 우선순위(Priorities) 를 구성할 수 있다.
- 스케줄링 프로파일을 사용하면
QueueSort,Filter,Score,Bind,Reserve,Permit등의 다른 스케줄링 단계를 구현하는 플러그인을 구성할 수 있다. 다른 프로파일을 실행하도록 kube-scheduler를 구성할 수도 있다.
다음 내용
- 스케줄러 성능 튜닝에 대해 읽기
- 파드 토폴로지 분배 제약 조건에 대해 읽기
- kube-scheduler의 레퍼런스 문서 읽기
- kube-scheduler 구성(v1beta3) 레퍼런스 읽기
- 멀티 스케줄러 구성하기에 대해 배우기
- 토폴로지 관리 정책에 대해 배우기
- 파드 오버헤드에 대해 배우기
- 볼륨을 사용하는 파드의 스케줄링에 대해 배우기
11.2 - 노드에 파드 할당하기
특정한 노드(들) 집합에서만 동작하거나 특정한 노드 집합에서 동작하는 것을 선호하도록 파드를 제한할 수 있다. 이를 수행하는 방법에는 여러 가지가 있으며 권장되는 접근 방식은 모두 레이블 셀렉터를 사용하여 선택을 용이하게 한다. 보통은 스케줄러가 자동으로 합리적인 배치(예: 자원이 부족한 노드에 파드를 배치하지 않도록 노드 간에 파드를 분배)를 수행하기에 이러한 제약 조건을 설정할 필요는 없다. 그러나, 예를 들어 SSD가 장착된 머신에 파드가 배포되도록 하거나 또는 많은 통신을 하는 두 개의 서로 다른 서비스의 파드를 동일한 가용성 영역(availability zone)에 배치하는 경우와 같이, 파드가 어느 노드에 배포될지를 제어해야 하는 경우도 있다.
쿠버네티스가 특정 파드를 어느 노드에 스케줄링할지 고르는 다음의 방법 중 하나를 골라 사용할 수 있다.
- 노드 레이블에 매칭되는 nodeSelector 필드
- 어피니티 / 안티 어피니티
- nodeName 필드
- 파드 토폴로지 분배 제약 조건
노드 레이블
다른 쿠버네티스 오브젝트와 마찬가지로, 노드도 레이블을 가진다. 레이블을 수동으로 추가할 수 있다. 또한 쿠버네티스도 클러스터의 모든 노드에 표준화된 레이블 집합을 적용한다. 잘 알려진 레이블, 어노테이션, 테인트에서 널리 사용되는 노드 레이블의 목록을 확인한다.
참고:
이러한 레이블에 대한 값은 클라우드 제공자별로 다르며 정확하지 않을 수 있다. 예를 들어,kubernetes.io/hostname에 대한 값은 특정 환경에서는 노드 이름과 동일할 수 있지만
다른 환경에서는 다른 값일 수도 있다.노드 격리/제한
노드에 레이블을 추가하여 파드를 특정 노드 또는 노드 그룹에 스케줄링되도록 지정할 수 있다. 이 기능을 사용하여 특정 파드가 특정 격리/보안/규제 속성을 만족하는 노드에서만 실행되도록 할 수 있다.
노드 격리를 위해 레이블을 사용할 때, kubelet이 변경할 수 없는 레이블 키를 선택한다. 그렇지 않으면 kubelet이 해당 레이블을 변경하여 노드가 사용 불가능(compromised) 상태로 빠지고 스케줄러가 이 노드에 워크로드를 스케줄링하는 일이 발생할 수 있다.
NodeRestriction 어드미션 플러그인은
kubelet이 node-restriction.kubernetes.io/ 접두사를 갖는 레이블을
설정하거나 변경하지 못하도록 한다.
노드 격리를 위해 레이블 접두사를 사용하려면,
- 노드 인가자(authorizer)를 사용하고 있는지, 그리고
NodeRestriction어드미션 플러그인을 활성화 했는지 확인한다. - 노드에
node-restriction.kubernetes.io/접두사를 갖는 레이블을 추가하고, 노드 셀렉터에서 해당 레이블을 사용한다. 예:example.com.node-restriction.kubernetes.io/fips=true또는example.com.node-restriction.kubernetes.io/pci-dss=true
노드셀렉터(nodeSelector)
nodeSelector는 노드 선택 제약사항의 가장 간단하면서도 추천하는 형태이다.
파드 스펙에 nodeSelector 필드를 추가하고,
타겟으로 삼고 싶은 노드가 갖고 있는 노드 레이블을 명시한다.
쿠버네티스는 사용자가 명시한 레이블을 갖고 있는 노드에만
파드를 스케줄링한다.
노드에 파드 할당에서 더 많은 정보를 확인한다.
어피니티(affinity)와 안티-어피니티(anti-affinity)
nodeSelector 는 파드를 특정 레이블이 있는 노드로 제한하는 가장 간단한 방법이다.
어피니티/안티-어피니티 기능은 표현할 수 있는 제약 종류를 크게 확장한다.
주요 개선 사항은 다음과 같다.
- 어피니티/안티-어피니티 언어가 더 표현적이다.
nodeSelector로는 명시한 레이블이 있는 노드만 선택할 수 있다. 어피니티/안티-어피니티는 선택 로직에 대한 좀 더 많은 제어권을 제공한다. - 규칙이 "소프트(soft)" 또는 "선호사항(preference)" 임을 나타낼 수 있으며, 이 덕분에 스케줄러는 매치되는 노드를 찾지 못한 경우에도 파드를 스케줄링할 수 있다.
- 다른 노드 (또는 다른 토폴로지 도메인)에서 실행 중인 다른 파드의 레이블을 사용하여 파드를 제한할 수 있으며, 이를 통해 어떤 파드들이 노드에 함께 위치할 수 있는지에 대한 규칙을 정의할 수 있다.
어피니티 기능은 다음의 두 가지 종류로 구성된다.
- 노드 어피니티 기능은
nodeSelector필드와 비슷하지만 더 표현적이고 소프트(soft) 규칙을 지정할 수 있게 해 준다. - 파드 간 어피니티/안티-어피니티 는 다른 파드의 레이블을 이용하여 해당 파드를 제한할 수 있게 해 준다.
노드 어피니티
노드 어피니티는 개념적으로 nodeSelector 와 비슷하며,
노드의 레이블을 기반으로 파드가 스케줄링될 수 있는 노드를 제한할 수 있다.
노드 어피니티에는 다음의 두 종류가 있다.
requiredDuringSchedulingIgnoredDuringExecution: 규칙이 만족되지 않으면 스케줄러가 파드를 스케줄링할 수 없다. 이 기능은nodeSelector와 유사하지만, 좀 더 표현적인 문법을 제공한다.preferredDuringSchedulingIgnoredDuringExecution: 스케줄러는 조건을 만족하는 노드를 찾으려고 노력한다. 해당되는 노드가 없더라도, 스케줄러는 여전히 파드를 스케줄링한다.
참고:
앞의 두 유형에서,IgnoredDuringExecution는
쿠버네티스가 파드를 스케줄링한 뒤에 노드 레이블이 변경되어도 파드는 계속 해당 노드에서 실행됨을 의미한다.파드 스펙의 .spec.affinity.nodeAffinity 필드에
노드 어피니티를 명시할 수 있다.
예를 들어, 다음과 같은 파드 스펙이 있다고 하자.
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0이 예시에서는 다음의 규칙이 적용된다.
- 노드는 키가
topology.kubernetes.io/zone인 레이블을 갖고 있어야 하며, 레이블의 값이antarctica-east1혹은antarctica-west1여야 한다. - 키가
another-node-label-key이고 값이another-node-label-value인 레이블을 갖고 있는 노드를 선호한다 .
operator 필드를 사용하여
쿠버네티스가 규칙을 해석할 때 사용할 논리 연산자를 지정할 수 있다.
In, NotIn, Exists, DoesNotExist, Gt 및 Lt 연산자를 사용할 수 있다.
NotIn 및 DoesNotExist 연산자를 사용하여 노드 안티-어피니티 규칙을 정의할 수 있다.
또는, 특정 노드에서 파드를 쫓아내는
노드 테인트(taint)를 설정할 수 있다.
참고:
nodeSelector와 nodeAffinity를 모두 사용하는 경우,
파드가 노드에 스케줄링되려면 두 조건 모두 만족되어야 한다.
nodeAffinity의 nodeSelectorTerms에 여러 조건(term)을 명시한 경우,
노드가 명시된 조건 중 하나만 만족해도 파드가
해당 노드에 스케줄링될 수 있다. (조건들은 OR 연산자로 처리)
nodeSelectorTerms의 조건으로 단일 matchExpressions 필드에 여러 표현식(expression)을 명시한 경우,
모든 표현식을 동시에 만족하는 노드에만
파드가 스케줄링될 수 있다. (표현식들은 AND 연산자로 처리)
노드 어피니티를 사용해 노드에 파드 할당에서 더 많은 정보를 확인한다.
노드 어피니티 가중치(weight)
각 preferredDuringSchedulingIgnoredDuringExecution 어피니티 타입 인스턴스에 대해
1-100 범위의 weight를 명시할 수 있다.
스케줄러가 다른 모든 파드 스케줄링 요구 사항을 만족하는 노드를 찾으면,
스케줄러는 노드가 만족한 모든 선호하는(preferred) 규칙에 대해
합계 계산을 위한 weight 값을 각각 추가한다.
최종 합계는 해당 노드에 대한 다른 우선 순위 함수 점수에 더해진다. 스케줄러가 파드에 대한 스케줄링 판단을 할 때, 총 점수가 가장 높은 노드가 우선 순위를 갖는다.
예를 들어, 다음과 같은 파드 스펙이 있다고 하자.
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
preferredDuringSchedulingIgnoredDuringExecution 규칙을 만족하는 노드가 2개 있고,
하나에는 label-1:key-1 레이블이 있고 다른 하나에는 label-2:key-2 레이블이 있으면,
스케줄러는 각 노드의 weight를 확인한 뒤
해당 노드에 대한 다른 점수에 가중치를 더하고,
최종 점수가 가장 높은 노드에 해당 파드를 스케줄링한다.
참고:
이 예시에서 쿠버네티스가 정상적으로 파드를 스케줄링하려면, 보유하고 있는 노드에kubernetes.io/os=linux 레이블이 있어야 한다.스케줄링 프로파일당 노드 어피니티
기능 상태:
Kubernetes v1.20 [beta]
여러 스케줄링 프로파일을 구성할 때
노드 어피니티가 있는 프로파일을 연결할 수 있는데, 이는 프로파일이 특정 노드 집합에만 적용되는 경우 유용하다.
이렇게 하려면 다음과 같이 스케줄러 구성에 있는
NodeAffinity 플러그인의 args 필드에 addedAffinity를 추가한다.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
addedAffinity는 .spec.schedulerName을 foo-scheduler로 설정하는 모든 파드에 적용되며
PodSpec에 지정된 NodeAffinity도 적용된다.
즉, 파드를 매칭시키려면, 노드가 addedAffinity와
파드의 .spec.NodeAffinity를 충족해야 한다.
addedAffinity는 엔드 유저에게 표시되지 않으므로,
예상치 못한 동작이 일어날 수 있다.
스케줄러 프로파일 이름과 명확한 상관 관계가 있는 노드 레이블을 사용한다.
참고:
데몬셋 파드를 생성하는 데몬셋 컨트롤러는 스케줄링 프로파일을 지원하지 않는다. 데몬셋 컨트롤러가 파드를 생성할 때, 기본 쿠버네티스 스케줄러는 해당 파드를 배치하고 데몬셋 컨트롤러의 모든nodeAffinity 규칙을 준수한다.파드간 어피니티와 안티-어피니티
파드간 어피니티와 안티-어피니티를 사용하여, 노드 레이블 대신, 각 노드에 이미 실행 중인 다른 파드 의 레이블을 기반으로 파드가 스케줄링될 노드를 제한할 수 있다.
파드간 어피니티와 안티-어피니티 규칙은 "X가 규칙 Y를 충족하는 하나 이상의 파드를 이미 실행중인 경우 이 파드는 X에서 실행해야 한다(또는 안티-어피니티의 경우에는 "실행하면 안 된다")"의 형태이며, 여기서 X는 노드, 랙, 클라우드 제공자 존 또는 리전 등이며 Y는 쿠버네티스가 충족할 규칙이다.
이러한 규칙(Y)은 레이블 셀렉터 형태로 작성하며, 연관된 네임스페이스 목록을 선택적으로 명시할 수도 있다. 쿠버네티스에서 파드는 네임스페이스에 속하는(namespaced) 오브젝트이므로, 파드 레이블도 암묵적으로 특정 네임스페이스에 속하게 된다. 파드 레이블에 대한 모든 레이블 셀렉터는 쿠버네티스가 해당 레이블을 어떤 네임스페이스에서 탐색할지를 명시해야 한다.
topologyKey를 사용하여 토폴로지 도메인(X)를 나타낼 수 있으며,
이는 시스템이 도메인을 표시하기 위해 사용하는 노드 레이블의 키이다.
이에 대한 예시는 잘 알려진 레이블, 어노테이션, 테인트를 참고한다.
참고:
파드간 어피니티와 안티-어피니티에는 상당한 양의 프로세싱이 필요하기에 대규모 클러스터에서는 스케줄링 속도가 크게 느려질 수 있다. 수백 개의 노드를 넘어가는 클러스터에서 이를 사용하는 것은 추천하지 않는다.참고:
파드 안티-어피니티에서는 노드에 일관된 레이블을 지정해야 한다. 즉, 클러스터의 모든 노드는topologyKey 와 매칭되는 적절한 레이블을 가지고 있어야 한다.
일부 또는 모든 노드에 지정된 topologyKey 레이블이 없는 경우에는
의도하지 않은 동작이 발생할 수 있다.파드간 어피니티 및 안티-어피니티 종류
노드 어피니티와 마찬가지로 파드 어피니티 및 안티-어피니티에는 다음의 2 종류가 있다.
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
예를 들어, requiredDuringSchedulingIgnoredDuringExecution 어피니티를 사용하여
서로 통신을 많이 하는 두 서비스의 파드를
동일 클라우드 제공자 존에 배치하도록 스케줄러에게 지시할 수 있다.
비슷하게, preferredDuringSchedulingIgnoredDuringExecution 안티-어피니티를 사용하여
서비스의 파드를
여러 클라우드 제공자 존에 퍼뜨릴 수 있다.
파드간 어피니티를 사용하려면, 파드 스펙에 affinity.podAffinity 필드를 사용한다.
파드간 안티-어피니티를 사용하려면,
파드 스펙에 affinity.podAntiAffinity 필드를 사용한다.
파드 어피니티 예시
다음과 같은 파드 스펙을 가정한다.
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
이 예시는 하나의 파드 어피니티 규칙과
하나의 파드 안티-어피니티 규칙을 정의한다.
파드 어피니티 규칙은 "하드" requiredDuringSchedulingIgnoredDuringExecution을,
안티-어피니티 규칙은 "소프트" preferredDuringSchedulingIgnoredDuringExecution을 사용한다.
위의 어피니티 규칙은 security=S1 레이블이 있는 하나 이상의 기존 파드의 존와 동일한 존에 있는 노드에만
파드를 스케줄링하도록 스케줄러에 지시한다.
더 정확히 말하면, 만약 security=S1 파드 레이블이 있는 하나 이상의 기존 파드를 실행하고 있는 노드가
zone=V에 하나 이상 존재한다면,
스케줄러는 파드를 topology.kubernetes.io/zone=V 레이블이 있는 노드에 배치해야 한다.
위의 안티-어피니티 규칙은 security=S2 레이블이 있는 하나 이상의 기존 파드의 존와 동일한 존에 있는 노드에는
가급적 파드를 스케줄링하지 않도록 스케줄러에 지시한다.
더 정확히 말하면, 만약 security=S2 파드 레이블이 있는 파드가 실행되고 있는 zone=R에
다른 노드도 존재한다면,
스케줄러는 topology.kubernetes.io/zone=R 레이블이 있는 노드에는 가급적 해당 파드를 스케줄링하지 않야아 한다.
파드 어피니티와 안티-어피니티의 예시에 대해 익숙해지고 싶다면, 디자인 제안을 참조한다.
파드 어피니티와 안티-어피니티의 operator 필드에
In, NotIn, Exists 및 DoesNotExist 값을 사용할 수 있다.
원칙적으로, topologyKey 에는 성능과 보안상의 이유로 다음의 예외를 제외하면
어느 레이블 키도 사용할 수 있다.
- 파드 어피니티 및 안티-어피니티에 대해, 빈
topologyKey필드는requiredDuringSchedulingIgnoredDuringExecution및preferredDuringSchedulingIgnoredDuringExecution내에 허용되지 않는다. requiredDuringSchedulingIgnoredDuringExecution파드 안티-어피니티 규칙에 대해,LimitPodHardAntiAffinityTopology어드미션 컨트롤러는topologyKey를kubernetes.io/hostname으로 제한한다. 커스텀 토폴로지를 허용하고 싶다면 어드미션 컨트롤러를 수정하거나 비활성화할 수 있다.
labelSelector와 topologyKey에 더하여 선택적으로,
labelSelector가 비교해야 하는 네임스페이스의 목록을
labelSelector 및 topologyKey 필드와 동일한 계위의 namespaces 필드에 명시할 수 있다.
생략하거나 비워 두면,
해당 어피니티/안티-어피니티 정의가 있는 파드의 네임스페이스를 기본값으로 사용한다.
네임스페이스 셀렉터
기능 상태:
Kubernetes v1.24 [stable]
네임스페이스 집합에 대한 레이블 쿼리인 namespaceSelector 를 사용하여 일치하는 네임스페이스를 선택할 수도 있다.
namespaceSelector 또는 namespaces 필드에 의해 선택된 네임스페이스 모두에 적용된다.
빈 namespaceSelector ({})는 모든 네임스페이스와 일치하는 반면,
null 또는 빈 namespaces 목록과 null namespaceSelector 는 규칙이 적용된 파드의 네임스페이스에 매치된다.
더 실제적인 유스케이스
파드간 어피니티와 안티-어피니티는 레플리카셋, 스테이트풀셋, 디플로이먼트 등과 같은 상위 레벨 모음과 함께 사용할 때 더욱 유용할 수 있다. 이러한 규칙을 사용하면, 워크로드 집합이 예를 들면 서로 연관된 두 개의 파드를 동일한 노드에 배치하는 것과 같이 동일하게 정의된 토폴로지와 같은 위치에 배치되도록 쉽게 구성할 수 있다.
세 개의 노드로 구성된 클러스터를 상상해 보자. 이 클러스터에서 redis와 같은 인-메모리 캐시를 이용하는 웹 애플리케이션을 실행한다. 또한 이 예에서 웹 애플리케이션과 메모리 캐시 사이의 대기 시간은 될 수 있는 대로 짧아야 한다고 가정하자. 이 때 웹 서버를 가능한 한 캐시와 같은 위치에서 실행되도록 하기 위해 파드간 어피니티/안티-어피니티를 사용할 수 있다.
다음의 redis 캐시 디플로이먼트 예시에서, 레플리카는 app=store 레이블을 갖는다.
podAntiAffinity 규칙은 스케줄러로 하여금
app=store 레이블을 가진 복수 개의 레플리카를 단일 노드에 배치하지 않게 한다.
이렇게 하여 캐시 파드를 각 노드에 분산하여 생성한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
웹 서버를 위한 다음의 디플로이먼트는 app=web-store 레이블을 갖는 레플리카를 생성한다.
파드 어피니티 규칙은 스케줄러로 하여금 app=store 레이블이 있는 파드를 실행 중인 노드에 각 레플리카를 배치하도록 한다.
파드 안티-어피니티 규칙은 스케줄러로 하여금 app=web-store 레이블이 있는 서버 파드를
한 노드에 여러 개 배치하지 못하도록 한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
위의 두 디플로이먼트를 생성하면 다음과 같은 클러스터 형상이 나타나는데, 세 노드에 각 웹 서버가 캐시와 함께 있는 형상이다.
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
전체적인 효과는 각 캐시 인스턴스를 동일한 노드에서 실행 중인 단일 클라이언트가 액세스하게 될 것 같다는 것이다. 이 접근 방식은 차이(불균형 로드)와 대기 시간을 모두 최소화하는 것을 목표로 한다.
파드간 안티-어피니티를 사용해야 하는 다른 이유가 있을 수 있다. ZooKeeper 튜토리얼에서 위 예시와 동일한 기술을 사용해 고 가용성을 위한 안티-어피니티로 구성된 스테이트풀셋의 예시를 확인한다.
nodeName
nodeName은 어피니티 또는 nodeSelector보다 더 직접적인 형태의 노드 선택 방법이다.
nodeName은 파드 스펙의 필드 중 하나이다.
nodeName 필드가 비어 있지 않으면, 스케줄러는 파드를 무시하고,
명명된 노드의 kubelet이 해당 파드를 자기 노드에 배치하려고 시도한다.
nodeName은 nodeSelector 또는 어피니티/안티-어피니티 규칙보다 우선적으로 적용(overrule)된다.
nodeName 을 사용해서 노드를 선택할 때의 몇 가지 제한은 다음과 같다.
- 만약 명명된 노드가 없으면, 파드가 실행되지 않고 따라서 자동으로 삭제될 수 있다.
- 만약 명명된 노드에 파드를 수용할 수 있는 리소스가 없는 경우 파드가 실패하고, 그 이유는 다음과 같이 표시된다. 예: OutOfmemory 또는 OutOfcpu.
- 클라우드 환경의 노드 이름은 항상 예측 가능하거나 안정적인 것은 아니다.
다음은 nodeName 필드를 사용하는 파드 스펙 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
위 파드는 kube-01 노드에서만 실행될 것이다.
파드 토폴로지 분배 제약 조건
_토폴로지 분배 제약 조건_을 사용하여 지역(regions), 영역(zones), 노드 또는 사용자가 정의한 다른 토폴로지 도메인과 같은 장애 도메인 사이에서 파드가 클러스터 전체에 분산되는 방식을 제어할 수 있다. 성능, 예상 가용성 또는 전체 활용도를 개선하기 위해 이 작업을 수행할 수 있다.
파드 토폴로지 분배 제약 조건에서 작동 방식에 대해 더 자세히 알아볼 수 있다.
다음 내용
- 테인트 및 톨러레이션에 대해 더 읽어본다.
- 노드 어피니티와 파드간 어피니티/안티-어피니티에 대한 디자인 문서를 읽어본다.
- 토폴로지 매니저가 노드 수준 리소스 할당 결정에 어떻게 관여하는지 알아본다.
- 노드셀렉터(nodeSelector)를 어떻게 사용하는지 알아본다.
- 어피니티/안티-어피니티를 어떻게 사용하는지 알아본다.
11.3 - 파드 오버헤드
기능 상태:
Kubernetes v1.24 [stable]
노드 상에서 파드를 구동할 때, 파드는 그 자체적으로 많은 시스템 리소스를 사용한다. 이러한 리소스는 파드 내의 컨테이너들을 구동하기 위한 리소스 이외에 추가적으로 필요한 것이다. 쿠버네티스에서, 파드 오버헤드 는 리소스 요청 및 상한 외에도 파드의 인프라에 의해 소비되는 리소스를 계산하는 방법 중 하나이다.
쿠버네티스에서 파드의 오버헤드는 파드의 런타임클래스 와 관련된 오버헤드에 따라 어드미션 이 수행될 때 지정된다.
파드를 노드에 스케줄링할 때, 컨테이너 리소스 요청의 합 뿐만 아니라 파드의 오버헤드도 함께 고려된다. 마찬가지로, kubelet은 파드의 cgroups 크기를 변경하거나 파드의 축출 등급을 부여할 때에도 파드의 오버헤드를 포함하여 고려한다.
파드 오버헤드 환경 설정하기
overhead 필드를 정의하는 RuntimeClass 가 사용되고 있는지 확인해야 한다.
사용 예제
파드 오버헤드를 활용하려면, overhead 필드를 정의하는 런타임클래스가 필요하다.
예를 들어, 가상 머신 및 게스트 OS에 대하여 파드 당 120 MiB를 사용하는
가상화 컨테이너 런타임의 런타임클래스의 경우 다음과 같이 정의 할 수 있다.
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
kata-fc 런타임클래스 핸들러를 지정하는 워크로드는 리소스 쿼터 계산,
노드 스케줄링 및 파드 cgroup 크기 조정을 위하여 메모리와 CPU 오버헤드를 고려한다.
주어진 예제 워크로드 test-pod의 구동을 고려해보자.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox:1.28
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
어드미션 수행 시에, 어드미션 컨트롤러는
런타임클래스에 기술된 overhead 를 포함하기 위하여 워크로드의 PodSpec 항목을 갱신한다. 만약 PodSpec이 이미 해당 필드에 정의되어 있으면,
파드는 거부된다. 주어진 예제에서, 오직 런타임클래스의 이름만이 정의되어 있기 때문에, 어드미션 컨트롤러는 파드가
overhead 를 포함하도록 변경한다.
런타임클래스 어드미션 컨트롤러가 변경을 완료하면, 다음의 명령어로 업데이트된 파드 오버헤드 값을 확인할 수 있다.
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
명령 실행 결과는 다음과 같다.
map[cpu:250m memory:120Mi]
만약 리소스쿼터 항목이 정의되어 있다면, 컨테이너의 리소스 요청의 합에는
overhead 필드도 추가된다.
kube-scheduler 는 어떤 노드에 파드가 기동 되어야 할지를 정할 때, 파드의 overhead 와
해당 파드에 대한 컨테이너의 리소스 요청의 합을 고려한다. 이 예제에서, 스케줄러는
리소스 요청과 파드의 오버헤드를 더하고, 2.25 CPU와 320 MiB 메모리가 사용 가능한 노드를 찾는다.
일단 파드가 특정 노드에 스케줄링 되면, 해당 노드에 있는 kubelet 은 파드에 대한 새로운 cgroup을 생성한다. 기본 컨테이너 런타임이 만들어내는 컨테이너들은 이 파드 안에 존재한다.
만약 각 컨테이너에 대하여 리소스 상한 제한이 걸려있으면
(제한이 걸려있는 보장된(Guaranteed) Qos 또는 향상 가능한(Burstable) QoS),
kubelet 은 해당 리소스(CPU의 경우 cpu.cfs_quota_us, 메모리의 경우 memory.limit_in_bytes)와 연관된 파드의 cgroup 의 상한선을 설정한다.
이 상한선은 컨테이너 리소스 상한과 PodSpec에 정의된 overhead 의 합에 기반한다.
CPU의 경우, 만약 파드가 보장형 또는 버스트형 QoS로 설정되었으면,
kubelet은 PodSpec에 정의된 overhead 에 컨테이너의 리소스 요청의 합을 더한 값을 cpu.shares 로 설정한다.
다음의 예제를 참고하여, 워크로드에 대하여 컨테이너의 리소스 요청을 확인하자.
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
컨테이너 리소스 요청의 합은 각각 CPU 2000m 와 메모리 200MiB 이다.
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
노드에서 측정된 내용과 비교하여 확인해보자.
kubectl describe node | grep test-pod -B2
결과를 보면 2250 m의 CPU와 320 MiB의 메모리가 리소스로 요청되었다. 여기에는 파드 오버헤드가 포함되어 있다.
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
파드 cgroup 상한 확인하기
워크로드가 실행 중인 노드에서 파드의 메모리 cgroup들을 확인해 보자.
다음의 예제에서,
crictl은 노드에서 사용되며,
CRI-호환 컨테이너 런타임을 위해서 노드에서 사용할 수 있는 CLI 를 제공한다.
파드 오버헤드 동작을 보여주는 좋은 예이며, 사용자가 노드에서 직접 cgroup들을 확인하지 않아도 된다.
먼저 특정 노드에서 파드의 식별자를 확인해 보자.
# 파드가 스케줄 된 노드에서 이것을 실행
POD_ID="$(sudo crictl pods --name test-pod -q)"
여기에서, 파드의 cgroup 경로를 확인할 수 있다.
# 파드가 스케줄 된 노드에서 이것을 실행
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
명령의 결과로 나온 cgroup 경로는 파드의 pause 컨테이너를 포함한다. 파드 레벨의 cgroup은 하나의 디렉터리이다.
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
아래의 특정한 경우에, 파드 cgroup 경로는 kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2 이다.
메모리의 파드 레벨 cgroup 설정을 확인하자.
# 파드가 스케줄 된 노드에서 이것을 실행.
# 또한 사용자의 파드에 할당된 cgroup 이름에 맞춰 해당 이름을 수정.
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
예상한 것과 같이 320 MiB 이다.
335544320
관찰성
몇몇 kube_pod_overhead 메트릭은
kube-state-metrics 에서 사용할 수 있어,
파드 오버헤드가 사용되는 시기를 식별하고, 정의된 오버헤드로 실행되는 워크로드의 안정성을 관찰할 수 있다.
다음 내용
- 런타임클래스에 대해 알아본다.
- 더 자세한 문맥은 파드오버헤드 디자인 향상 제안을 확인한다.
11.4 - 파드 스케줄링 준비성(readiness)
기능 상태:
Kubernetes v1.26 [alpha]
파드는 생성되면 스케줄링 될 준비가 된 것으로 간주된다. 쿠버네티스 스케줄러는 모든 Pending 중인 파드를 배치할 노드를 찾기 위한 철저한 조사 과정을 수행한다. 그러나 일부 파드는 오랜 기간 동안 "필수 리소스 누락" 상태에 머물 수 있다. 이러한 파드는 실제로 스케줄러(그리고 클러스터 오토스케일러와 같은 다운스트림 통합자) 불필요한 방식으로 작동하게 만들 수 있다.
파드의 .spec.schedulingGates를 지정하거나 제거함으로써,
파드가 스케줄링 될 준비가 되는 시기를 제어할 수 있다.
파드 스케줄링게이트(schedulingGates) 구성하기
스케줄링게이트(schedulingGates) 필드는 문자열 목록을 포함하며, 각 문자열 리터럴은
파드가 스케줄링 가능한 것으로 간주되기 전에 충족해야 하는 기준으로 인식된다. 이 필드는
파드가 생성될 때만 초기화할 수 있다(클라이언트에 의해 생성되거나, 어드미션 중에 변경될 때).
생성 후 각 스케줄링게이트는 임의의 순서로 제거될 수 있지만, 새로운 스케줄링게이트의 추가는 허용되지 않는다.
stateDiagram-v2
s1: 파드 생성
s2: 파드 스케줄링 게이트됨
s3: 파드 스케줄링 준비됨
s4: 파드 실행
if: 스케줄링 게이트가 비어 있는가?
[*] --> s1
s1 --> if
s2 --> if: 스케줄링 게이트 제거됨
if --> s2: 아니오
if --> s3: 네
s3 --> s4
s4 --> [*]
사용 예시
파드가 스케줄링 될 준비가 되지 않았다고 표시하려면, 다음과 같이 하나 이상의 스케줄링 게이트를 생성하여 표시할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulingGates:
- name: foo
- name: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.6
파드가 생성된 후에는 다음 명령을 사용하여 상태를 확인할 수 있다.
kubectl get pod test-pod
출력은 파드가 SchedulingGated 상태임을 보여준다.
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
다음 명령을 실행하여 schedulingGates 필드를 확인할 수도 있다.
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
출력은 다음과 같다.
[{"name":"foo"},{"name":"bar"}]
스케줄러에게 이 파드가 스케줄링 될 준비가 되었음을 알리기 위해, 수정된 매니페스트를 다시 적용하여
schedulingGates를 완전히 제거할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: pause
image: registry.k8s.io/pause:3.6
schedulingGates가 지워졌는지 확인하려면 다음 명령을 실행하여 확인할 수 있다.
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
출력은 비어 있을 것이다. 그리고 다음 명령을 실행하여 최신 상태를 확인할 수 있다.
kubectl get pod test-pod -o wide
test-pod가 CPU/메모리 리소스를 요청하지 않았기 때문에, 이 파드의 상태는 이전의 SchedulingGated에서
Running으로 전환됐을 것이다.
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
가시성(Observability)
스케줄링을 시도했지만 스케줄링할 수 없다고 클레임되거나 스케줄링할 준비가 되지 않은 것으로 명시적으로 표시된 파드를
구분하기 위해 scheduler_pending_pods 메트릭은 ”gated"라는 새로운 레이블과 함께 제공된다.
scheduler_pending_pods{queue="gated"}를 사용하여 메트릭 결과를 확인할 수 있다.
다음 내용
- 자세한 내용은 PodSchedulingReadiness KEP를 참고한다.
11.5 - 파드 토폴로지 분배 제약 조건
사용자는 토폴로지 분배 제약 조건 을 사용하여 지역(region), 존(zone), 노드 및 기타 사용자 정의 토폴로지 도메인과 같이 장애 도메인으로 설정된 클러스터에 걸쳐 파드가 분배되는 방식을 제어할 수 있다. 이를 통해 고가용성뿐만 아니라 효율적인 리소스 활용의 목적을 이루는 데에도 도움이 된다.
클러스터-수준 제약을 기본값으로 설정하거나, 개별 워크로드마다 각각의 토폴로지 분배 제약 조건을 설정할 수 있다.
동기(motivation)
최대 20 노드로 이루어진 클러스터가 있고, 레플리카 수를 자동으로 조절하는 워크로드를 실행해야 하는 상황을 가정해 보자. 파드의 수는 2개 정도로 적을 수도 있고, 15개 정도로 많을 수도 있다. 파드가 2개만 있는 상황에서는, 해당 파드들이 동일 노드에서 실행되는 것은 원치 않을 것이다. 단일 노드 장애(single node failure)로 인해 전체 워크로드가 오프라인이 될 수 있기 때문이다.
이러한 기본적 사용 뿐만 아니라, 고가용성(high availability) 및 클러스터 활용(cluster utilization)으로부터 오는 장점을 워크로드가 누리도록 하는 고급 사용 예시도 존재한다.
워크로드를 스케일 업 하여 더 많은 파드를 실행함에 따라, 중요성이 부각되는 다른 요소도 존재한다. 3개의 노드가 각각 5개의 파드를 실행하는 경우를 가정하자. 각 노드는 5개의 레플리카를 실행하기에 충분한 성능을 갖고 있다. 하지만, 이 워크로드와 통신하는 클라이언트들은 3개의 서로 다른 데이터센터(또는 인프라스트럭처 존(zone))에 걸쳐 존재한다. 이제 단일 노드 장애에 대해서는 덜 걱정해도 되지만, 지연 시간(latency)이 증가하고, 서로 다른 존 간에 네트워크 트래픽을 전송하기 위해 네트워크 비용을 지불해야 한다.
정상적인 동작 중에는 각 인프라스트럭처 존에 비슷한 수의 레플리카가 스케줄되고, 클러스터에 문제가 있는 경우 스스로 치유하도록 설정할 수 있다.
파드 토폴로지 분배 제약 조건은 이러한 설정을 할 수 있도록 하는 선언적인 방법을 제공한다.
topologySpreadConstraints 필드
파드 API에 spec.topologySpreadConstraints 필드가 있다. 이 필드는 다음과 같이
쓰인다.
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 토폴로지 분배 제약 조건을 구성한다.
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # 선택 사항이며, v1.25에서 베타 기능으로 도입되었다.
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # 선택 사항이며, v1.25에서 알파 기능으로 도입되었다.
nodeAffinityPolicy: [Honor|Ignore] # 선택 사항이며, v1.26에서 베타 기능으로 도입되었다.
nodeTaintsPolicy: [Honor|Ignore] # 선택 사항이며, v1.26에서 베타 기능으로 도입되었다.
### 파드의 다른 필드가 이 아래에 오게 된다.
kubectl explain Pod.spec.topologySpreadConstraints 명령을 실행하거나 파드에 관한 API 레퍼런스의
스케줄링 섹션을 참조해서 이 필드에 대해 좀 더 알아볼 수 있다.
분배 제약 조건 정의
하나 또는 다중 topologySpreadConstraint 를 정의하여,
kube-scheduler가 어떻게 클러스터 내에서 기존 파드와의 관계를 고려하며
새로운 파드를 배치할지를 지시할 수 있다. 각 필드는 다음과 같다.
-
maxSkew 는 파드가 균등하지 않게 분산될 수 있는 정도를 나타낸다. 이 필드는 필수이며, 0 보다는 커야 한다. 이 필드 값의 의미는
whenUnsatisfiable의 값에 따라 다르다.whenUnsatisfiable: DoNotSchedule을 선택했다면,maxSkew는 대상 토폴로지에서 일치하는 파드 수와 전역 최솟값(global minimum) (적절한 도메인 내에서 일치하는 파드의 최소 수, 또는 적절한 도메인의 수가minDomains보다 작은 경우에는 0)
사이의 최대 허용 차이를 나타낸다. 예를 들어, 3개의 존에 각각 2, 2, 1개의 일치하는 파드가 있으면,maxSkew는 1로 설정되고 전역 최솟값은 1로 설정된다.whenUnsatisfiable: ScheduleAnyway를 선택하면, 스케줄러는 차이(skew)를 줄이는 데 도움이 되는 토폴로지에 더 높은 우선 순위를 부여한다.
-
minDomains 는 적합한(eligible) 도메인의 최소 수를 나타낸다. 이 필드는 선택 사항이다. 도메인은 토폴로지의 특정 인스턴스 중 하나이다. 도메인의 노드가 노드 셀렉터에 매치되면 그 도메인은 적합한 도메인이다.
참고:
minDomains필드는 1.25에서 기본적으로 사용하도록 설정된 베타 필드이다. 사용을 원하지 않을 경우MinDomainsInPodTopologySpread기능 게이트를 비활성화한다.minDomains값을 명시하는 경우, 이 값은 0보다 커야 한다.minDomains는whenUnsatisfiable: DoNotSchedule일 때에만 지정할 수 있다.- 매치되는 토폴로지 키의 적합한 도메인 수가
minDomains보다 적으면, 파드 토폴로지 스프레드는 전역 최솟값을 0으로 간주한 뒤,skew계산을 수행한다. 전역 최솟값은 적합한 도메인 내에 매치되는 파드의 최소 수이며, 적합한 도메인 수가minDomains보다 적은 경우에는 0이다. - 매치되는 토폴로지 키의 적합한 도메인 수가
minDomains보다 크거나 같으면, 이 값은 스케줄링에 영향을 미치지 않는다. minDomains를 명시하지 않으면, 분배 제약 조건은minDomains가 1이라고 가정하고 동작한다.
-
topologyKey 는 노드 레이블의 키(key)이다. 이 키와 동일한 값을 가진 레이블이 있는 노드는 동일한 토폴로지에 있는 것으로 간주된다.
토폴로지의 각 인스턴스(즉, <키, 값> 쌍)를 도메인이라고 한다. 스케줄러는 각 도메인에 균형잡힌 수의 파드를 배치하려고 시도할 것이다. 또한, 노드가 nodeAffinityPolicy 및 nodeTaintsPolicy의 요구 사항을 충족하는 도메인을 적절한 도메인이라고 정의한다. -
whenUnsatisfiable 는 분산 제약 조건을 만족하지 않을 경우에 파드를 처리하는 방법을 나타낸다.
DoNotSchedule(기본값)은 스케줄러에 스케줄링을 하지 말라고 알려준다.ScheduleAnyway는 스케줄러에게 차이(skew)를 최소화하는 노드에 높은 우선 순위를 부여하면서, 스케줄링을 계속하도록 지시한다.
-
labelSelector 는 일치하는 파드를 찾는 데 사용된다. 이 레이블 셀렉터와 일치하는 파드의 수를 계산하여 해당 토폴로지 도메인에 속할 파드의 수를 결정한다. 자세한 내용은 레이블 셀렉터를 참조한다.
-
matchLabelKeys 는 분배도(spreading)가 계산될 파드를 선택하기 위한 파드 레이블 키 목록이다. 키는 파드 레이블에서 값을 조회하는 데 사용되며, 이러한 키-값 레이블은
labelSelector와 AND 처리되어 들어오는 파드(incoming pod)에 대해 분배도가 계산될 기존 파드 그룹의 선택에 사용된다. 파드 레이블에 없는 키는 무시된다. null 또는 비어 있는 목록은labelSelector와만 일치함을 의미한다.matchLabelKeys를 사용하면, 사용자는 다른 리비전 간에pod.spec을 업데이트할 필요가 없다. 컨트롤러/오퍼레이터는 다른 리비전에 대해 동일한label키에 다른 값을 설정하기만 하면 된다. 스케줄러는matchLabelKeys를 기준으로 값을 자동으로 가정할 것이다. 예를 들어 사용자가 디플로이먼트를 사용하는 경우, 디플로이먼트 컨트롤러에 의해 자동으로 추가되는pod-template-hash로 키가 지정된 레이블을 사용함으로써 단일 디플로이먼트에서 서로 다른 리비전을 구별할 수 있다.topologySpreadConstraints: - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: DoNotSchedule matchLabelKeys: - app - pod-template-hash참고:
matchLabelKeys필드는 1.25에서 추가된 알파 필드이다. 이 필드를 사용하려면MatchLabelKeysInPodTopologySpread기능 게이트 를 활성화시켜야 한다. -
nodeAffinityPolicy는 파드 토폴로지의 스프레드 스큐(spread skew)를 계산할 때 파드의 nodeAffinity/nodeSelector를 다루는 방법을 나타낸다. 옵션은 다음과 같다.
- Honor: nodeAffinity/nodeSelector와 일치하는 노드만 계산에 포함된다.
- Ignore: nodeAffinity/nodeSelector는 무시된다. 모든 노드가 계산에 포함된다.
옵션의 값이 null일 경우, Honor 정책과 동일하게 동작한다.
참고:
nodeAffinityPolicy필드는 베타 필드이고 1.26에서 기본적으로 활성화되어 있다. 이 필드를 비활성화하려면NodeInclusionPolicyInPodTopologySpread기능 게이트 를 비활성화하면 된다. -
nodeTaintsPolicy는 파드 토폴로지의 스프레드 스큐(spread skew)를 계산할 때 노드 테인트(taint)를 다루는 방법을 나타낸다. 옵션은 다음과 같다.
- Honor: 테인트가 없는 노드, 그리고 노드가 톨러레이션이 있는 들어오는 파드(incoming pod)를 위한 테인트가 설정된 노드가 포함된다.
- Ignore: 노드 테인트는 무시된다. 모든 노드가 포함된다.
옵션의 값이 null일 경우, Ignore 정책과 동일하게 동작한다.
참고:
nodeTaintsPolicy필드는 베타 필드이고 1.26에서 기본적으로 활성화되어 있다. 이 필드를 비활성화하려면NodeInclusionPolicyInPodTopologySpread기능 게이트 를 비활성화하면 된다.
파드에 2개 이상의 topologySpreadConstraint가 정의되어 있으면,
각 제약 조건은 논리 AND 연산으로 조합되며,
kube-scheduler는 새로운 파드의 모든 제약 조건을 만족하는 노드를 찾는다.
노드 레이블
토폴로지 분배 제약 조건은 노드 레이블을 이용하여 각 노드가 속한 토폴로지 도메인(들)을 인식한다. 예를 들어, 노드가 다음과 같은 레이블을 가질 수 있다.
region: us-east-1
zone: us-east-1a
참고:
간결함을 위해, 이 예시에서는
잘 알려진 레이블 키인
topology.kubernetes.io/zone 및 topology.kubernetes.io/region을 사용하지 않는다.
그러나 그렇더라도, 아래에 등장하는 프라이빗(비공인된) 레이블 키인 region 및 zone보다는
위와 같은 공인된 레이블 키를 사용하는 것을 권장한다.
다양한 각 상황에 대해, 프라이빗 레이블 키의 의미가 모두 우리의 생각과 같을 것이라고 가정할 수는 없다.
각각 다음과 같은 레이블을 갖는 4개의 노드로 구성된 클러스터가 있다고 가정한다.
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
그러면 클러스터는 논리적으로 다음과 같이 보이게 된다.
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
일관성(consistency)
그룹 내의 모든 파드에는 동일한 파드 토폴로지 분배 제약 조건을 설정해야 한다.
일반적으로, 디플로이먼트와 같은 워크로드 컨트롤러를 사용하는 경우, 파드 템플릿이 이 사항을 담당한다. 여러 분배 제약 조건을 혼합하는 경우, 쿠버네티스는 해당 필드의 API 정의를 따르기는 하지만, 동작이 복잡해질 수 있고 트러블슈팅이 덜 직관적이게 된다.
동일한 토폴로지 도메인(예: 클라우드 공급자 리전)에 있는 모든 노드가
일관적으로 레이블되도록 하는 메카니즘이 필요하다.
각 노드를 수동으로 레이블하는 것을 피하기 위해,
대부분의 클러스터는 topology.kubernetes.io/hostname와 같은 잘 알려진 레이블을 자동으로 붙인다.
이용하려는 클러스터가 이를 지원하는지 확인해 본다.
토폴로지 분배 제약 조건 예시
예시: 단수 토폴로지 분배 제약 조건
foo:bar 가 레이블된 3개의 파드가 4개 노드를 가지는 클러스터의
node1, node2 및 node3에 각각 위치한다고 가정한다.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
신규 파드가 기존 파드와 함께 여러 존에 걸쳐 균등하게 분배되도록 하려면, 다음과 같은 매니페스트를 사용할 수 있다.
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1위의 매니페스트에서, topologyKey: zone이 의미하는 것은 zone: <any value>로 레이블된
노드에 대해서만 균등한 분배를 적용한다는 뜻이다(zone 레이블이 없는 노드는 무시된다).
whenUnsatisfiable: DoNotSchedule 필드는 만약 스케줄러가 신규 파드에 대해 제약 조건을
만족하는 스케줄링 방법을 찾지 못하면 이 신규 파드를 pending 상태로 유지하도록 한다.
만약 스케줄러가 이 신규 파드를 A 존에 배치하면 파드 분포는 [3, 1]이 된다.
이는 곧 실제 차이(skew)가 2(3-1)임을 나타내는데, 이는 maxSkew: 1을 위반하게 된다.
이 예시에서 제약 조건과 상황을 만족하려면,
신규 파드는 B 존의 노드에만 배치될 수 있다.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
또는
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
사용자는 파드 스펙을 조정하여 다음과 같은 다양한 요구사항을 충족할 수 있다.
maxSkew를 더 큰 값(예:2)으로 변경하여 신규 파드가A존에도 배치할 수 있도록 한다.topologyKey를node로 변경하여 파드가 존이 아닌 노드에 걸쳐 고르게 분산되도록 한다. 위의 예시에서, 만약maxSkew를1로 유지한다면, 신규 파드는 오직node4에만 배치될 수 있다.whenUnsatisfiable: DoNotSchedule를whenUnsatisfiable: ScheduleAnyway로 변경하면 신규 파드가 항상 스케줄링되도록 보장할 수 있다(다른 스케줄링 API를 충족한다는 가정 하에). 그러나, 매칭되는 파드의 수가 적은 토폴로지 도메인에 배치되는 것이 선호된다. (이 선호도는 리소스 사용 비율과 같은 다른 내부 스케줄링 우선순위와 함께 정규화된다는 것을 알아두자.)
예시: 다중 토폴로지 분배 제약 조건
이 예시는 위의 예시에 기반한다. foo:bar 가 레이블된 3개의 파드가
4개 노드를 가지는 클러스터의 node1, node2 그리고 node3에 각각 위치한다고 가정한다.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
사용자는 2개의 토폴로지 분배 제약 조건을 사용하여 노드 및 존 기반으로 파드가 분배되도록 제어할 수 있다.
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1이 경우에는, 첫 번째 제약 조건에 부합하려면, 신규 파드는 오직 B 존에만 배치될 수 있다.
한편 두 번째 제약 조건에 따르면 신규 파드는 오직 node4 노드에만 배치될 수 있다.
스케줄러는 모든 정의된 제약 조건을 만족하는 선택지만 고려하므로,
유효한 유일한 선택지는 신규 파드를 node4에 배치하는 것이다.
예시: 상충하는 토폴로지 분배 제약 조건
다중 제약 조건이 서로 충돌할 수 있다. 3개의 노드를 가지는 클러스터 하나가 2개의 존에 걸쳐 있다고 가정한다.
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
만약
two-constraints.yaml
(위 예시의 매니페스트)을
이 클러스터에 적용하면,
mypod 파드가 Pending 상태로 유지되는 것을 볼 수 있을 것이다.
이러한 이유는, 첫 번째 제약 조건을 충족하려면 mypod 파드는 B 존에만 배치될 수 있지만,
두 번째 제약 조건에 따르면 mypod 파드는 node2 노드에만 스케줄링될 수 있기 때문이다.
두 제약 조건의 교집합이 공집합이므로, 스케줄러는 파드를 배치할 수 없다.
이 상황을 극복하기 위해, maxSkew 값을 증가시키거나,
제약 조건 중 하나를 whenUnsatisfiable: ScheduleAnyway 를 사용하도록 수정할 수 있다.
상황에 따라, 기존 파드를 수동으로 삭제할 수도 있다.
예를 들어, 버그픽스 롤아웃이 왜 진행되지 않는지 트러블슈팅하는 상황에서 이 방법을 활용할 수 있다.
노드 어피니티(Affinity) 및 노드 셀렉터(Selector)와의 상호 작용
스케줄러는 신규 파드에 spec.nodeSelector 또는 spec.affinity.nodeAffinity가 정의되어 있는 경우,
부합하지 않는 노드들을 차이(skew) 계산에서 생략한다.
예시: 토폴로지 분배 제약조건과 노드 어피니티
5개의 노드를 가지는 클러스터가 A 존에서 C 존까지 걸쳐 있다고 가정한다.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
그리고 C 존은 파드 배포에서 제외해야 한다는 사실을 사용자가 알고 있다고 가정한다.
이 경우에, 다음과 같이 매니페스트를 작성하여, mypod 파드가 C 존 대신 B 존에 배치되도록 할 수 있다.
유사하게, 쿠버네티스는 spec.nodeSelector 필드도 고려한다.
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- zoneC
containers:
- name: pause
image: registry.k8s.io/pause:3.1암묵적 규칙
여기에 주목할만한 몇 가지 암묵적인 규칙이 있다.
-
신규 파드와 동일한 네임스페이스를 갖는 파드만이 매칭의 후보가 된다.
-
topologySpreadConstraints[*].topologyKey가 없는 노드는 무시된다. 이것은 다음을 의미한다.- 이러한 노드에 위치한 파드는
maxSkew계산에 영향을 미치지 않는다. 위의 예시에서,node1노드는 "zone" 레이블을 가지고 있지 않다고 가정하면, 파드 2개는 무시될 것이고, 이런 이유로 신규 파드는A존으로 스케줄된다. - 신규 파드는 이런 종류의 노드에 스케줄 될 기회가 없다.
위의 예시에서, 잘못 타이핑된
zone-typo: zoneC레이블을 갖는node5노드가 있다고 가정하자(zone레이블은 설정되지 않음).node5노드가 클러스터에 편입되면, 해당 노드는 무시되고 이 워크로드의 파드는 해당 노드에 스케줄링되지 않는다.
- 이러한 노드에 위치한 파드는
-
신규 파드의
topologySpreadConstraints[*].labelSelector가 자체 레이블과 일치하지 않을 경우 어떻게 되는지 알고 있어야 한다. 위의 예시에서, 신규 파드의 레이블을 제거해도, 제약 조건이 여전히 충족되기 때문에 이 파드는B존의 노드에 배치될 수 있다. 그러나, 배치 이후에도 클러스터의 불균형 정도는 변경되지 않는다. 여전히A존은foo: bar레이블을 가지는 2개의 파드를 가지고 있고,B존도foo: bar레이블을 가지는 1개의 파드를 가지고 있다. 만약 결과가 예상과 다르다면, 워크로드의topologySpreadConstraints[*].labelSelector를 파드 템플릿의 레이블과 일치하도록 업데이트한다.
클러스터 수준의 기본 제약 조건
클러스터에 대한 기본 토폴로지 분배 제약 조건을 설정할 수 있다. 기본 토폴로지 분배 제약 조건은 다음과 같은 경우에만 파드에 적용된다.
.spec.topologySpreadConstraints에 어떠한 제약 조건도 정의되어 있지 않는 경우.- 서비스, 레플리카셋(ReplicaSet), 스테이트풀셋(StatefulSet), 또는 레플리케이션컨트롤러(ReplicationController)에 속해있는 경우.
기본 제약 조건은
스케줄링 프로파일내의 플러그인 인자 중 하나로 설정할 수 있다.
제약 조건은 위에서 설명한 것과 동일한 API를 이용하여 정의되는데,
다만 labelSelector는 비워 두어야 한다.
셀렉터는 파드가 속한 서비스, 레플리카셋, 스테이트풀셋, 또는 레플리케이션 컨트롤러를 바탕으로 계산한다.
예시 구성은 다음과 같다.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
내장 기본 제약 조건
기능 상태:
Kubernetes v1.24 [stable]
파드 토폴로지 분배에 대해 클러스터 수준의 기본 제약을 설정하지 않으면, kube-scheduler는 다음과 같은 기본 토폴로지 제약이 설정되어 있는 것처럼 동작한다.
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
또한, 같은 동작을 제공하는 레거시 SelectorSpread 플러그인은
기본적으로 비활성화되어 있다.
참고:
PodTopologySpread 플러그인은
분배 제약 조건에 지정된 토폴로지 키가 없는 노드에 점수를 매기지 않는다.
이로 인해 기본 토폴로지 제약을 사용하는 경우의
레거시 SelectorSpread 플러그인과는 기본 정책이 다를 수 있다.
노드에 kubernetes.io/hostname 및 topology.kubernetes.io/zone
레이블 세트가 둘 다 설정되지 않을 것으로 예상되는 경우,
쿠버네티스 기본값을 사용하는 대신 자체 제약 조건을 정의하자.
클러스터에 기본 파드 분배 제약 조건을 사용하지 않으려면,
PodTopologySpread 플러그인 구성에서 defaultingType 을 List 로 설정하고
defaultConstraints 를 비워두어 기본값을 비활성화할 수 있다.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
파드어피니티(PodAffinity) 및 파드안티어피니티(PodAntiAffinity)와의 비교
쿠버네티스에서, 파드간 어피니티 및 안티 어피니티는 파드가 다른 파드에 서로 어떤 연관 관계를 지니며 스케줄링되는지를 제어하며, 이는 파드들이 서로 더 밀집되도록 하거나 흩어지도록 하는 것을 의미한다.
podAffinity- 파드를 끌어당긴다. 조건이 충족되는 토폴로지 도메인에는 원하는 수의 파드를 얼마든지 채울 수 있다.
podAntiAffinity- 파드를 밀어낸다.
이를
requiredDuringSchedulingIgnoredDuringExecution모드로 설정하면 각 토폴로지 도메인에는 하나의 파드만 스케줄링될 수 있다. 반면preferredDuringSchedulingIgnoredDuringExecution로 설정하면 제약 조건이 강제성을 잃게 된다.
더 세밀한 제어를 위해, 토폴로지 분배 제약 조건을 지정하여 다양한 토폴로지 도메인에 파드를 분배할 수 있고, 이를 통해 고 가용성 또는 비용 절감을 달성할 수 있다. 이는 또한 워크로드의 롤링 업데이트와 레플리카의 원활한 스케일링 아웃에 도움이 될 수 있다.
더 자세한 내용은 파드 토폴로지 분배 제약 조건에 대한 개선 제안의 동기(motivation) 섹션을 참고한다.
알려진 제한사항
-
파드가 제거된 이후에도 제약 조건이 계속 충족된다는 보장은 없다. 예를 들어 디플로이먼트를 스케일링 다운하면 그 결과로 파드의 분포가 불균형해질 수 있다.
Descheduler와 같은 도구를 사용하여 파드 분포를 다시 균형있게 만들 수 있다.
-
테인트된(tainted) 노드에 매치된 파드도 계산에 포함된다. 이슈 80921을 본다.
-
스케줄러는 클러스터가 갖는 모든 존 또는 다른 토폴로지 도메인에 대한 사전 지식을 갖고 있지 않다. 이 정보들은 클러스터의 기존 노드로부터 획득된다. 이로 인해 오토스케일된 클러스터에서 문제가 발생할 수 있는데, 예를 들어 노드 풀(또는 노드 그룹)이 0으로 스케일 다운되고, 클러스터가 다시 스케일 업 되기를 기대하는 경우, 해당 토폴로지 도메인은 적어도 1개의 노드가 존재하기 전에는 고려가 되지 않을 것이다.
이를 극복하기 위해, 파드 토폴로지 분배 제약 조건과 전반적인 토폴로지 도메인 집합에 대한 정보를 인지하고 동작하는 클러스터 오토스케일링 도구를 이용할 수 있다.
다음 내용
- 블로그: PodTopologySpread 소개에서는
maxSkew에 대해 자세히 설명하고, 몇 가지 고급 사용 예제를 제공한다. - 파드 API 레퍼런스의 스케줄링 섹션을 읽어 본다.
11.6 - 테인트(Taints)와 톨러레이션(Tolerations)
노드 어피니티는 노드 셋을 (기본 설정 또는 어려운 요구 사항으로) 끌어들이는 파드의 속성이다. 테인트 는 그 반대로, 노드가 파드 셋을 제외시킬 수 있다.
톨러레이션 은 파드에 적용된다. 톨러레이션을 통해 스케줄러는 그와 일치하는 테인트가 있는 파드를 스케줄할 수 있다. 톨러레이션은 스케줄을 허용하지만 보장하지는 않는다. 스케줄러는 그 기능의 일부로서 다른 매개변수를 고려한다.
테인트와 톨러레이션은 함께 작동하여 파드가 부적절한 노드에 스케줄되지 않게 한다. 하나 이상의 테인트가 노드에 적용되는데, 이것은 노드가 테인트를 용인하지 않는 파드를 수용해서는 안 된다는 것을 나타낸다.
개요
kubectl taint를 사용하여 노드에 테인트을 추가한다. 예를 들면 다음과 같다.
kubectl taint nodes node1 key1=value1:NoSchedule
node1 노드에 테인트을 배치한다. 테인트에는 키 key1, 값 value1 및 테인트 이펙트(effect) NoSchedule 이 있다.
이는 일치하는 톨러레이션이 없으면 파드를 node1 에 스케줄할 수 없음을 의미한다.
위에서 추가했던 테인트를 제거하려면, 다음을 실행한다.
kubectl taint nodes node1 key1=value1:NoSchedule-
PodSpec에서 파드에 대한 톨러레이션를 지정한다. 다음의 톨러레이션은
위의 kubectl taint 라인에 의해 생성된 테인트와 "일치"하므로, 어느 쪽 톨러레이션을 가진 파드이던
node1 에 스케줄 될 수 있다.
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
톨러레이션을 사용하는 파드의 예는 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
지정하지 않으면 operator 의 기본값은 Equal 이다.
톨러레이션은, 키와 이펙트가 동일한 경우에 테인트와 "일치"한다. 그리고 다음의 경우에도 마찬가지다.
operator가Exists인 경우(이 경우value를 지정하지 않아야 함), 또는operator는Equal이고value는value로 같다.
참고:
두 가지 특별한 경우가 있다.
operator Exists 가 있는 비어있는 key 는 모든 키, 값 및 이펙트와 일치하므로
모든 것이 톨러레이션 된다.
비어있는 effect 는 모든 이펙트를 키 key1 와 일치시킨다.
위의 예는 NoSchedule 의 effect 를 사용했다. 또는, PreferNoSchedule 의 effect 를 사용할 수 있다.
이것은 NoSchedule 의 "기본 설정(preference)" 또는 "소프트(soft)" 버전이다. 시스템은 노드의 테인트를 허용하지 않는
파드를 배치하지 않으려고 시도 하지만, 필요하지는 않다. 세 번째 종류의 effect 는
나중에 설명할 NoExecute 이다.
동일한 노드에 여러 테인트를, 동일한 파드에 여러 톨러레이션을 둘 수 있다. 쿠버네티스가 여러 테인트 및 톨러레이션을 처리하는 방식은 필터와 같다. 모든 노드의 테인트로 시작한 다음, 파드에 일치하는 톨러레이션이 있는 것을 무시한다. 무시되지 않은 나머지 테인트는 파드에 표시된 이펙트를 가진다. 특히,
NoSchedule이펙트가 있는 무시되지 않은 테인트가 하나 이상 있으면 쿠버네티스는 해당 노드에 파드를 스케줄하지 않는다.NoSchedule이펙트가 있는 무시되지 않은 테인트가 없지만PreferNoSchedule이펙트가 있는 무시되지 않은 테인트가 하나 이상 있으면 쿠버네티스는 파드를 노드에 스케쥴하지 않으려고 시도 한다NoExecute이펙트가 있는 무시되지 않은 테인트가 하나 이상 있으면 파드가 노드에서 축출되고(노드에서 이미 실행 중인 경우), 노드에서 스케줄되지 않는다(아직 실행되지 않은 경우).
예를 들어, 이와 같은 노드를 테인트하는 경우는 다음과 같다.
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
그리고 파드에는 두 가지 톨러레이션이 있다.
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
이 경우, 세 번째 테인트와 일치하는 톨러레이션이 없기 때문에, 파드는 노드에 스케줄 될 수 없다. 그러나 세 번째 테인트가 파드에서 용인되지 않는 세 가지 중 하나만 있기 때문에, 테인트가 추가될 때 노드에서 이미 실행 중인 경우, 파드는 계속 실행할 수 있다.
일반적으로, NoExecute 이펙트가 있는 테인트가 노드에 추가되면, 테인트를
용인하지 않는 파드는 즉시 축출되고, 테인트를 용인하는 파드는
축출되지 않는다. 그러나 NoExecute 이펙트가 있는 톨러레이션은
테인트가 추가된 후 파드가 노드에 바인딩된 시간을 지정하는
선택적 tolerationSeconds 필드를 지정할 수 있다. 예를 들어,
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
이것은 이 파드가 실행 중이고 일치하는 테인트가 노드에 추가되면, 파드는 3600초 동안 노드에 바인딩된 후, 축출된다는 것을 의미한다. 그 전에 테인트를 제거하면, 파드가 축출되지 않는다.
유스케이스 예시
테인트 및 톨러레이션은 파드를 노드에서 멀어지게 하거나 실행되지 않아야 하는 파드를 축출할 수 있는 유연한 방법이다. 유스케이스 중 일부는 다음과 같다.
-
전용 노드: 특정 사용자들이 독점적으로 사용하도록 노드 셋을 전용하려면, 해당 노드에 테인트를 추가(예:
kubectl taint nodes nodename dedicated=groupName:NoSchedule)한 다음 해당 톨러레이션을 그들의 파드에 추가할 수 있다(사용자 정의 [어드미션 컨트롤러] (/docs/reference/access-authn-authz/admission-controllers/)를 작성하면 가장 쉽게 수행할 수 있음). 그런 다음 톨러레이션이 있는 파드는 테인트된(전용) 노드와 클러스터의 다른 노드를 사용할 수 있다. 노드를 특정 사용자들에게 전용으로 지정하고 그리고 그 사용자들이 전용 노드 만 사용하려면, 동일한 노드 셋에 테인트와 유사한 레이블을 추가해야 하고(예:dedicated=groupName), 어드미션 컨트롤러는 추가로 파드가dedicated=groupName으로 레이블이 지정된 노드에만 스케줄될 수 있도록 노드 어피니티를 추가해야 한다. -
특별한 하드웨어가 있는 노드: 작은 서브셋의 노드에 특별한 하드웨어(예: GPU)가 있는 클러스터에서는, 특별한 하드웨어가 필요하지 않는 파드를 해당 노드에서 분리하여, 나중에 도착하는 특별한 하드웨어가 필요한 파드를 위한 공간을 남겨두는 것이 바람직하다. 이는 특별한 하드웨어가 있는 노드(예:
kubectl taint nodes nodename special=true:NoSchedule또는kubectl taint nodes nodename special=true:PreferNoSchedule)에 테인트를 추가하고 특별한 하드웨어를 사용하는 파드에 해당 톨러레이션을 추가하여 수행할 수 있다. 전용 노드 유스케이스에서와 같이, 사용자 정의 어드미션 컨트롤러를 사용하여 톨러레이션를 적용하는 것이 가장 쉬운 방법이다. 예를 들어, 확장된 리소스를 사용하여 특별한 하드웨어를 나타내고, 확장된 리소스 이름으로 특별한 하드웨어 노드를 테인트시키고 ExtendedResourceToleration 어드미션 컨트롤러를 실행하는 것을 권장한다. 이제, 노드가 테인트되었으므로, 톨러레이션이 없는 파드는 스케줄되지 않는다. 그러나 확장된 리소스를 요청하는 파드를 제출하면,ExtendedResourceToleration어드미션 컨트롤러가 파드에 올바른 톨러레이션을 자동으로 추가하고 해당 파드는 특별한 하드웨어 노드에서 스케줄된다. 이렇게 하면 이러한 특별한 하드웨어 노드가 해당 하드웨어를 요청하는 파드가 전용으로 사용하며 파드에 톨러레이션을 수동으로 추가할 필요가 없다. -
테인트 기반 축출: 노드 문제가 있을 때 파드별로 구성 가능한 축출 동작은 다음 섹션에서 설명한다.
테인트 기반 축출
기능 상태:
Kubernetes v1.18 [stable]
앞에서 우리는 노드에서 이미 실행 중인 파드에 영향을 주는 NoExecute 테인트 이펙트를
다음과 같이 언급했다.
- 테인트를 용인하지 않는 파드는 즉시 축출된다.
- 톨러레이션 명세에
tolerationSeconds를 지정하지 않고 테인트를 용인하는 파드는 계속 바인딩된다. tolerationSeconds가 지정된 테인트를 용인하는 파드는 지정된 시간 동안 바인딩된 상태로 유지된다.
노드 컨트롤러는 특정 컨디션이 참일 때 자동으로 노드를 테인트시킨다. 다음은 빌트인 테인트이다.
node.kubernetes.io/not-ready: 노드가 준비되지 않았다. 이는 NodeConditionReady가 "False"로 됨에 해당한다.node.kubernetes.io/unreachable: 노드가 노드 컨트롤러에서 도달할 수 없다. 이는 NodeConditionReady가 "Unknown"로 됨에 해당한다.node.kubernetes.io/memory-pressure: 노드에 메모리 할당 압박이 있다.node.kubernetes.io/disk-pressure: 노드에 디스크 할당 압박이 있다.node.kubernetes.io/pid-pressure: 노드에 PID 할당 압박이 있다.node.kubernetes.io/network-unavailable: 노드의 네트워크를 사용할 수 없다.node.kubernetes.io/unschedulable: 노드를 스케줄할 수 없다.node.cloudprovider.kubernetes.io/uninitialized: "외부" 클라우드 공급자로 kubelet을 시작하면, 이 테인트가 노드에서 사용 불가능으로 표시되도록 설정된다. 클라우드-컨트롤러-관리자의 컨트롤러가 이 노드를 초기화하면, kubelet이 이 테인트를 제거한다.
노드가 축출될 경우, 노드 컨트롤러 또는 kubelet은 NoExecute 이펙트로 관련
테인트를 추가한다. 장애 상태가 정상으로 돌아오면 kubelet 또는 노드 컨트롤러가
관련 테인트를 제거할 수 있다.
참고:
콘트롤 플레인은 노드에 새 테인트를 추가하는 비율을 제한한다. 이 비율-제한은 많은 노드가 동시에 도달할 수 없을 때(예를 들어, 네트워크 중단으로) 트리거될 축출 개수를 관리한다.이 기능을 tolerationSeconds 와 함께 사용하면, 파드에서
이러한 문제 중 하나 또는 둘 다가 있는 노드에 바인딩된 기간을 지정할 수 있다.
예를 들어, 로컬 상태가 많은 애플리케이션은 네트워크 분할의 장애에서 네트워크가 복구된 후에 파드가 축출되는 것을 피하기 위해 오랫동안 노드에 바인딩된 상태를 유지하려고 할 수 있다. 이 경우 파드가 사용하는 톨러레이션은 다음과 같다.
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
참고:
쿠버네티스는 사용자나 컨트롤러에서 명시적으로 설정하지 않았다면, 자동으로
node.kubernetes.io/not-ready 와 node.kubernetes.io/unreachable 에 대해
tolerationSeconds=300 으로
톨러레이션을 추가한다.
자동으로 추가된 이 톨러레이션은 이러한 문제 중 하나가 감지된 후 5분 동안 파드가 노드에 바인딩된 상태를 유지함을 의미한다.
데몬셋 파드는 tolerationSeconds 가 없는
다음 테인트에 대해 NoExecute 톨러레이션를 가지고 생성된다.
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
이렇게 하면 이러한 문제로 인해 데몬셋 파드가 축출되지 않는다.
컨디션(condition)을 기준으로 노드 테인트하기
컨트롤 플레인은 노드 컨트롤러를 이용하여
노드 컨디션에 대한
NoSchedule 효과를 사용하여 자동으로 테인트를 생성한다.
스케줄러는 스케줄링 결정을 내릴 때 노드 컨디션을 확인하는 것이 아니라 테인트를 확인한다.
이렇게 하면 노드 컨디션이 스케줄링에 직접적인 영향을 주지 않는다.
예를 들어 DiskPressure 노드 컨디션이 활성화된 경우
컨트롤 플레인은 node.kubernetes.io/disk-pressure 테인트를 추가하고 영향을 받는 노드에 새 파드를 할당하지 않는다.
MemoryPressure 노드 컨디션이 활성화되면
컨트롤 플레인이 node.kubernetes.io/memory-pressure 테인트를 추가한다.
새로 생성된 파드에 파드 톨러레이션을 추가하여 노드 컨디션을 무시하도록 할 수 있다.
또한 컨트롤 플레인은 BestEffort 이외의
QoS 클래스를 가지는 파드에
node.kubernetes.io/memory-pressure 톨러레이션을 추가한다.
이는 쿠버네티스가 Guaranteed 또는 Burstable QoS 클래스를 갖는 파드(메모리 요청이 설정되지 않은 파드 포함)를
마치 그 파드들이 메모리 압박에 대처 가능한 것처럼 다루는 반면,
새로운 BestEffort 파드는 영향을 받는 노드에 할당하지 않기 때문이다.
데몬셋 컨트롤러는 다음의 NoSchedule 톨러레이션을
모든 데몬에 자동으로 추가하여, 데몬셋이 중단되는 것을 방지한다.
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressure(1.14 이상)node.kubernetes.io/unschedulable(1.10 이상)node.kubernetes.io/network-unavailable(호스트 네트워크만 해당)
이러한 톨러레이션을 추가하면 이전 버전과의 호환성이 보장된다. 데몬셋에 임의의 톨러레이션을 추가할 수도 있다.
다음 내용
- 노드-압박(node-pressure) 축출과 어떻게 구성하는지에 대해 알아보기
- 파드 우선순위에 대해 알아보기
11.7 - 스케줄러 성능 튜닝
기능 상태:
Kubernetes 1.14 [beta]
kube-scheduler는 쿠버네티스의 기본 스케줄러이다. 그것은 클러스터의 노드에 파드를 배치하는 역할을 한다.
파드의 스케줄링 요건을 충족하는 클러스터의 노드를 파드에 적합한(feasible) 노드라고 한다. 스케줄러는 파드에 대해 적합한 노드를 찾고 기능 셋을 실행하여 해당 노드의 점수를 측정한다. 그리고 스케줄러는 파드를 실행하는데 적합한 모든 노드 중 가장 높은 점수를 가진 노드를 선택한다. 이후 스케줄러는 바인딩 이라는 프로세스로 API 서버에 해당 결정을 통지한다.
본 페이지에서는 상대적으로 큰 규모의 쿠버네티스 클러스터에 대한 성능 튜닝 최적화에 대해 설명한다.
큰 규모의 클러스터에서는 스케줄러의 동작을 튜닝하여 응답 시간 (새 파드가 빠르게 배치됨)과 정확도(스케줄러가 배치 결정을 잘 못하는 경우가 드물게 됨) 사이에서의 스케줄링 결과를 균형 잡을 수 있다.
kube-scheduler 의 percentageOfNodesToScore 설정을 통해
이 튜닝을 구성 한다. 이 KubeSchedulerConfiguration 설정에 따라 클러스터의
노드를 스케줄링할 수 있는 임계값이 결정된다.
임계값 설정하기
percentageOfNodesToScore 옵션은 0과 100 사이의 값을
허용한다. 값 0은 kube-scheduler가 컴파일 된 기본값을
사용한다는 것을 나타내는 특별한 숫자이다.
percentageOfNodesToScore 를 100 보다 높게 설정해도 kube-scheduler는
마치 100을 설정한 것처럼 작동한다.
값을 변경하려면,
kube-scheduler 구성 파일을
편집한 다음 스케줄러를 재시작한다.
대부분의 경우, 구성 파일은 /etc/kubernetes/config/kube-scheduler.yaml 에서 찾을 수 있다.
이를 변경한 후에 다음을 실행해서
kubectl get pods -n kube-system | grep kube-scheduler
kube-scheduler 컴포넌트가 정상인지 확인할 수 있다.
노드 스코어링(scoring) 임계값
스케줄링 성능을 향상시키기 위해 kube-scheduler는 실행 가능한 노드가 충분히 발견되면 이를 찾는 것을 중단할 수 있다. 큰 규모의 클러스터에서는 모든 노드를 고려하는 고지식한 접근 방식에 비해 시간이 절약된다.
클러스터에 있는 모든 노드의 정수 백분율로 충분한 노두의 수에 대한 임계값을 지정한다. kube-scheduler는 이 값을 노드의 정수 값(숫자)로 변환 한다. 스케줄링 중에 kube-scheduler가 구성된 비율을 초과 할만큼 충분히 실행 가능한 노드를 식별한 경우, kube-scheduler는 더 실행 가능한 노드를 찾는 검색을 중지하고 스코어링 단계를 진행한다.
스케줄러가 노드 탐색을 반복(iterate)하는 방법 은 이 프로세스를 자세히 설명한다.
기본 임계값
임계값을 지정하지 않으면 쿠버네티스는 100 노드 클러스터인 경우 50%, 5000 노드 클러스터인 경우 10%를 산출하는 선형 공식을 사용하여 수치를 계산한다. 자동 값의 하한선은 5% 이다.
즉, percentageOfNodesToScore 를 명시적으로 5보다 작게 설정하지
않은 경우 클러스터가 아무리 크더라도 kube-scheduler는
항상 클러스터의 최소 5%를 스코어링을 한다.
스케줄러가 클러스터의 모든 노드에 스코어링을 하려면
percentageOfNodesToScore 를 100으로 설정 한다.
예시
아래는 percentageOfNodesToScore를 50%로 설정하는 구성 예시이다.
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
percentageOfNodesToScore 튜닝
percentageOfNodesToScore는 1과 100 사이의 값이어야 하며
기본값은 클러스터 크기에 따라 계산된다. 또한 100 노드로 하드 코딩된
최솟값도 있다.
참고:
클러스터에서 적합한 노드가 100 미만인 경우, 스케줄러는 여전히 모든 노드를 확인한다. 그 이유는 스케줄러가 탐색을 조기 중단하기에는 적합한 노드의 수가 충분하지 않기 때문이다.
규모가 작은 클러스터에서는 percentageOfNodesToScore 에 낮은 값을 설정하면,
비슷한 이유로 변경 사항이 거의 또는 전혀 영향을 미치지 않게 된다.
클러스터에 수백 개 이하의 노드가 있는 경우 이 구성 옵션을 기본값으로 둔다. 이는 변경사항을 적용하더라도 스케줄러의 성능이 크게 향상되지 않는다.
이 값을 세팅할 때 중요하고 자세한 사항은, 클러스터에서 적은 수의 노드에 대해서만 적합성을 확인하면, 주어진 파드에 대해서 일부 노드의 점수는 측정이되지 않는다는 것이다. 결과적으로, 주어진 파드를 실행하는데 가장 높은 점수를 가질 가능성이 있는 노드가 점수 측정 단계로 조차 넘어가지 않을 수 있다. 이것은 파드의 이상적인 배치보다 낮은 결과를 초래할 것이다.
percentageOfNodesToScore 를 매우 낮게 설정해서 kube-scheduler가
파드 배치 결정을 잘못 내리지 않도록 해야 한다. 스케줄러의 처리량에
대해 애플리케이션이 중요하고 노드 점수가 중요하지 않은 경우가 아니라면
백분율을 10% 미만으로 설정하지 말아야 한다. 즉, 가능한 한
모든 노드에서 파드를 실행하는 것이 좋다.
스케줄러가 노드 탐색을 반복(iterate)하는 방법
이 섹션은 이 특징의 상세한 내부 방식을 이해하고 싶은 사람들을 위해 작성되었다.
클러스터의 모든 노드가 파드 실행 대상으로 고려되어 공정한 기회를
가지도록, 스케줄러는 라운드 로빈(round robin) 방식으로 모든 노드에 대해서 탐색을
반복한다. 모든 노드가 배열에 나열되어 있다고 생각해보자. 스케줄러는 배열의
시작부터 시작하여 percentageOfNodesToScore에 명시된 충분한 수의 노드를
찾을 때까지 적합성을 확인한다. 그 다음 파드에 대해서는, 스케줄러가
이전 파드를 위한 노드 적합성 확인이 마무리된 지점인 노드 배열의 마지막
포인트부터 확인을 재개한다.
만약 노드들이 다중의 영역(zone)에 있다면, 다른 영역에 있는 노드들이 적합성 확인의 대상이 되도록 스케줄러는 다양한 영역에 있는 노드에 대해서 탐색을 반복한다. 예제로, 2개의 영역에 있는 6개의 노드를 생각해보자.
영역 1: 노드 1, 노드 2, 노드 3, 노드 4
영역 2: 노드 5, 노드 6
스케줄러는 노드의 적합성 평가를 다음의 순서로 실행한다.
노드 1, 노드 5, 노드 2, 노드 6, 노드 3, 노드 4
모든 노드를 검토한 후, 노드 1로 돌아간다.
다음 내용
11.8 - 리소스 빈 패킹(bin packing)
kube-scheduler의 스케줄링 플러그인 NodeResourcesFit에는,
리소스의 빈 패킹(bin packing)을 지원하는 MostAllocated과 RequestedToCapacityRatio라는 두 가지 점수 산정(scoring) 전략이 있다.
MostAllocated 전략을 사용하여 빈 패킹 활성화하기
MostAllocated 전략은 리소스 사용량을 기반으로 할당량이 많은 노드를 높게 평가하여 노드에 점수를 매긴다.
각 리소스 유형별로 가중치를 설정하여 노드 점수에 미치는 영향을 조정할 수 있다.
NodeResourcesFit 플러그인에 대한 MostAllocated 전략을 설정하려면,
다음과 유사한 스케줄러 설정을 사용한다.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
type: MostAllocated
name: NodeResourcesFit
기타 파라미터와 기본 구성에 대한 자세한 내용은
NodeResourcesFitArgs에 대한 API 문서를 참조한다.
RequestedToCapacityRatio을 사용하여 빈 패킹 활성화하기
RequestedToCapacityRatio 전략은 사용자가 각 리소스에 대한 가중치와 함께 리소스를 지정하여
용량 대비 요청 비율을 기반으로 노드의 점수를 매길 수 있게 한다.
이를 통해 사용자는 적절한 파라미터를 사용하여 확장된 리소스를 빈 팩으로 만들 수 있어
대규모의 클러스터에서 부족한 리소스의 활용도를 향상시킬 수 있다. 이 전략은
할당된 리소스의 구성된 기능에 따라 노드를 선호하게 한다. NodeResourcesFit점수 기능의
RequestedToCapacityRatio 동작은 scoringStrategy필드를
이용하여 제어할 수 있다.
scoringStrategy 필드에서 requestedToCapacityRatio와 resources라는 두 개의 파라미터를
구성할 수 있다. requestedToCapacityRatio파라미터의
shape를 사용하면 utilization과 score 값을 기반으로
최소 요청 혹은 최대 요청된 대로 기능을 조정할 수 있게 한다.
resources 파라미터는 점수를 매길 때 고려할 리소스의 name 과
각 리소스의 가중치를 지정하는 weight 로 구성된다.
다음은 requestedToCapacityRatio 를 이용해
확장된 리소스 intel.com/foo 와 intel.com/bar 에 대한 빈 패킹 동작을
설정하는 구성의 예시이다.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
requestedToCapacityRatio:
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
type: RequestedToCapacityRatio
name: NodeResourcesFit
kube-scheduler 플래그 --config=/path/to/config/file 을 사용하여
KubeSchedulerConfiguration 파일을 참조하면 구성이 스케줄러에
전달된다.
기타 파라미터와 기본 구성에 대한 자세한 내용은
NodeResourcesFitArgs에 대한 API 문서를 참조한다.
점수 기능 튜닝하기
shape 는 RequestedToCapacityRatio 기능의 동작을 지정하는 데 사용된다.
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
위의 인수는 utilization 이 0%인 경우 score 는 0, utilization 이
100%인 경우 10으로 하여, 빈 패킹 동작을 활성화한다. 최소 요청을
활성화하려면 점수 값을 다음과 같이 변경해야 한다.
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources 는 기본적으로 다음과 같이 설정되는 선택적인 파라미터이다.
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
다음과 같이 확장된 리소스를 추가하는 데 사용할 수 있다.
resources:
- name: intel.com/foo
weight: 5
- name: cpu
weight: 3
- name: memory
weight: 1
weight 파라미터는 선택 사항이며 지정되지 않은 경우 1로 설정 된다. 또한,
weight 는 음수로 설정할 수 없다.
용량 할당을 위해 노드에 점수 매기기
이 섹션은 이 기능 내부의 세부적인 사항을 이해하려는 사람들을 위한 것이다. 아래는 주어진 값의 집합에 대해 노드 점수가 계산되는 방법의 예시이다.
요청된 리소스는 다음과 같다.
intel.com/foo : 2
memory: 256MB
cpu: 2
리소스의 가중치는 다음과 같다.
intel.com/foo : 5
memory: 1
cpu: 3
FunctionShapePoint {{0, 0}, {100, 10}}
노드 1의 사양은 다음과 같다.
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
노드 점수는 다음과 같다.
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = (7 * 5) + (5 * 1) + (3 * 3) / (5 + 1 + 3)
= 5
노드 2의 사양은 다음과 같다.
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
노드 점수는 다음과 같다.
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
Memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = (5 * 5) + (7 * 1) + (10 * 3) / (5 + 1 + 3)
= 7
다음 내용
- 스케줄링 프레임워크에 대해 더 읽어본다.
- 스케줄러 구성에 대해 더 읽어본다.
11.9 - 파드 우선순위(priority)와 선점(preemption)
기능 상태:
Kubernetes v1.14 [stable]
파드는 우선순위 를 가질 수 있다. 우선순위는 다른 파드에 대한 상대적인 파드의 중요성을 나타낸다. 파드를 스케줄링할 수 없는 경우, 스케줄러는 우선순위가 낮은 파드를 선점(축출)하여 보류 중인 파드를 스케줄링할 수 있게 한다.
경고:
모든 사용자를 신뢰할 수 없는 클러스터에서, 악의적인 사용자가 우선순위가 가장 높은 파드를 생성하여 다른 파드가 축출되거나 스케줄링되지 않을 수 있다. 관리자는 리소스쿼터를 사용하여 사용자가 우선순위가 높은 파드를 생성하지 못하게 할 수 있다.
자세한 내용은 기본적으로 프라이어리티클래스(Priority Class) 소비 제한을 참고한다.
우선순위와 선점을 사용하는 방법
우선순위와 선점을 사용하려면 다음을 참고한다.
-
하나 이상의 프라이어리티클래스를 추가한다.
-
추가된 프라이어리티클래스 중 하나에
priorityClassName이 설정된 파드를 생성한다. 물론 파드를 직접 생성할 필요는 없다. 일반적으로 디플로이먼트와 같은 컬렉션 오브젝트의 파드 템플릿에priorityClassName을 추가한다.
이 단계에 대한 자세한 내용은 계속 읽어보자.
참고:
쿠버네티스는 이미system-cluster-critical 과 system-node-critical,
두 개의 프라이어리티클래스를 제공한다.
이들은 일반적인 클래스이며 중요한(critical) 컴포넌트가 항상 먼저 스케줄링이 되도록 하는 데 사용된다.프라이어리티클래스
프라이어리티클래스는 프라이어리티클래스 이름에서 우선순위의 정수 값으로의 매핑을
정의하는 네임스페이스가 아닌(non-namespaced) 오브젝트이다. 이름은
프라이어리티클래스 오브젝트의 메타데이터의 name 필드에 지정된다. 값은
필수 value 필드에 지정되어 있다. 값이 클수록, 우선순위가
높다.
프라이어리티클래스 오브젝트의 이름은 유효한
DNS 서브 도메인 이름이어야 하며,
system- 접두사를 붙일 수 없다.
프라이어리티클래스 오브젝트는 10억 이하의 32비트 정수 값을 가질 수 있다. 일반적으로 선점하거나 축출해서는 안되는 중요한 시스템 파드에는 더 큰 숫자가 예약되어 있다. 클러스터 관리자는 원하는 각 매핑에 대해 프라이어리티클래스 오브젝트를 하나씩 생성해야 한다.
프라이어리티클래스에는 globalDefault 와 description 두 개의 선택적인 필드도 있다.
globalDefault 필드는 이 프라이어리티클래스의 값을 priorityClassName 이 없는
파드에 사용해야 함을 나타낸다. 시스템에서 globalDefault 가 true 로 설정된
프라이어리티클래스는 하나만 존재할 수 있다. globalDefault 가 설정된
프라이어리티클래스가 없을 경우, priorityClassName 이 없는 파드의
우선순위는 0이다.
description 필드는 임의의 문자열이다. 이 필드는 이 프라이어리티클래스를 언제
사용해야 하는지를 클러스터 사용자에게 알려주기 위한 것이다.
PodPriority와 기존 클러스터에 대한 참고 사항
-
이 기능없이 기존 클러스터를 업그레이드 하는 경우, 기존 파드의 우선순위는 사실상 0이다.
-
globalDefault가true로 설정된 프라이어리티클래스를 추가해도 기존 파드의 우선순위는 변경되지 않는다. 이러한 프라이어리티클래스의 값은 프라이어리티클래스를 추가한 후 생성된 파드에만 사용된다. -
프라이어리티클래스를 삭제하면, 삭제된 프라이어리티클래스의 이름을 사용하는 기존 파드는 변경되지 않고 남아있지만, 삭제된 프라이어리티클래스의 이름을 사용하는 파드는 더 이상 생성할 수 없다.
프라이어리티클래스 예제
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "이 프라이어리티클래스는 XYZ 서비스 파드에만 사용해야 한다."
비-선점 프라이어리티클래스
기능 상태:
Kubernetes v1.24 [stable]
preemptionPolicy: Never 를 가진 파드는 낮은 우선순위 파드의 스케줄링 대기열의
앞쪽에 배치되지만,
그 파드는 다른 파드를 축출할 수 없다.
스케줄링 대기 중인 비-선점 파드는 충분한 리소스가 확보되고
스케줄링될 수 있을 때까지
스케줄링 대기열에 대기한다.
다른 파드와 마찬가지로,
비-선점 파드는
스케줄러 백오프(back-off)에 종속된다.
이는 스케줄러가 이러한 파드를 스케줄링하려고 시도하고 스케줄링할 수 없는 경우,
더 적은 횟수로 재시도하여,
우선순위가 낮은 다른 파드를 미리 스케줄링할 수 있음을 의미한다.
비-선점 파드는 다른 우선순위가 높은 파드에 의해 축출될 수 있다.
preemptionPolicy 는 기본값으로 PreemptLowerPriority 로 설정되어,
해당 프라이어리티클래스의 파드가 우선순위가 낮은 파드를 축출할 수
있다(기존의 기본 동작과 동일).
preemptionPolicy 가 Never 로 설정된 경우,
해당 프라이어리티클래스의 파드는 비-선점될 것이다.
예제 유스케이스는 데이터 과학 관련 워크로드이다.
사용자는 다른 워크로드보다 우선순위가 높은 잡(job)을 제출할 수 있지만,
실행 중인 파드를 축출하여 기존의 작업을 삭제하지는 않을 것이다.
클러스터 리소스가 "자연스럽게" 충분히 사용할 수 있게 되면,
preemptionPolicy: Never 의 우선순위가 높은 잡이
다른 대기 중인 파드보다 먼저 스케줄링된다.
비-선점 프라이어리티클래스 예제
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "이 프라이어리티클래스는 다른 파드를 축출하지 않는다."
파드 우선순위
프라이어리티클래스가 하나 이상 있으면, 그것의 명세에서 이들 프라이어리티클래스 이름 중 하나를
지정하는 파드를 생성할 수 있다. 우선순위 어드미션
컨트롤러는 priorityClassName 필드를 사용하고 우선순위의 정수 값을
채운다. 프라이어리티클래스를 찾을 수 없으면, 파드가 거부된다.
다음의 YAML은 이전 예제에서 생성된 프라이어리티클래스를 사용하는 파드 구성의 예이다. 우선순위 어드미션 컨트롤러는 명세를 확인하고 파드의 우선순위를 1000000으로 해석한다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
스케줄링 순서에 대한 파드 우선순위의 영향
파드 우선순위가 활성화되면, 스케줄러가 우선순위에 따라 보류 중인 파드를 주문하고 보류 중인 파드는 스케줄링 대기열에서 우선순위가 낮은 다른 보류 중인 파드보다 우선한다. 결과적으로, 스케줄링 요구 사항이 충족되는 경우 우선순위가 더 낮은 파드보다 우선순위가 높은 파드가 더 빨리 스케줄링될 수 있다. 이러한 파드를 스케줄링할 수 없는 경우, 스케줄러는 계속 진행하고 우선순위가 낮은 다른 파드를 스케줄링하려고 한다.
선점
파드가 생성되면, 대기열로 이동하여 스케줄링을 기다린다. 스케줄러가 대기열에서 파드를 선택하여 노드에 스케줄링하려고 한다. 파드의 지정된 모든 요구 사항을 충족하는 노드가 없으면, 보류 중인 파드에 대해 선점 로직이 트리거된다. 보류 중인 파드를 P라 하자. 선점 로직은 P보다 우선순위가 낮은 하나 이상의 파드를 제거하면 해당 노드에서 P를 스케줄링할 수 있는 노드를 찾는다. 이러한 노드가 발견되면, 하나 이상의 우선순위가 낮은 파드가 노드에서 축출된다. 파드가 축출된 후, P는 노드에 스케줄링될 수 있다.
사용자 노출 정보
파드 P가 노드 N에서 하나 이상의 파드를 축출할 경우, 파드 P의 상태 nominatedNodeName
필드는 노드 N의 이름으로 설정된다. 이 필드는 스케줄러가 파드 P에
예약된 리소스를 추적하는 데 도움이 되고 사용자에게 클러스터의 선점에 대한
정보를 제공한다.
파드 P는 반드시 "지정된 노드"로 스케줄링되지는 않는다.
스케줄러는 다른 노드에 스케줄링을 시도하기 전에 항상 "지정된 노드"부터 시도한다.
피해자 파드가 축출된 후, 그것은 정상적(graceful)으로 종료되는 기간을 갖는다.
스케줄러가 종료될 피해자 파드를 기다리는 동안 다른 노드를 사용할 수
있게 되면, 스케줄러는 파드 P를 스케줄링하기 위해 다른 노드를 사용할 수 있다. 그 결과,
파드 스펙의 nominatedNodeName 과 nodeName 은 항상 동일하지 않다. 또한,
스케줄러가 노드 N에서 파드를 축출했지만, 파드 P보다 우선순위가 높은 파드가
도착하면, 스케줄러가 노드 N에 새로운 우선순위가 높은 파드를 제공할 수 있다. 이러한
경우, 스케줄러는 파드 P의 nominatedNodeName 을 지운다. 이렇게하면, 스케줄러는
파드 P가 다른 노드에서 파드를 축출할 수 있도록 한다.
선점의 한계
선점 피해자의 정상적인 종료
파드가 축출되면, 축출된 피해자 파드는 정상적인 종료 기간을 가진다. 피해자 파드는 작업을 종료하고 빠져나가는 데(exit) 많은 시간을 가진다. 그렇지 않으면, 파드는 강제종료(kill) 된다. 이 정상적인 종료 기간은 스케줄러가 파드를 축출하는 지점과 보류 중인 파드(P)를 노드(N)에서 스케줄링할 수 있는 시점 사이의 시간 간격을 만든다. 그 동안, 스케줄러는 보류 중인 다른 파드를 계속 스케줄링한다. 피해자 파드가 빠져나가거나 종료되면, 스케줄러는 보류 대기열에서 파드를 스케줄하려고 한다. 따라서, 일반적으로 스케줄러가 피해자 파드를 축출하는 시점과 파드 P가 스케줄링된 시점 사이에 시간 간격이 있다. 이러한 차이를 최소화하기 위해, 우선순위가 낮은 파드의 정상적인 종료 기간을 0 또는 작은 수로 설정할 수 있다.
PodDisruptionBudget을 지원하지만, 보장하지 않음
Pod Disruption Budget(PDB)은 애플리케이션 소유자가 자발적 중단에서 동시에 다운된 복제된 애플리케이션의 파드 수를 제한할 수 있다. 쿠버네티스는 파드를 선점할 때 PDB를 지원하지만, PDB를 따르는 것이 최선의 노력이다. 스케줄러는 선점에 의해 PDB를 위반하지 않은 피해자 파드를 찾으려고 하지만, 그러한 피해자 파드가 발견되지 않으면, 선점은 여전히 발생하며, PDB를 위반하더라도 우선순위가 낮은 파드는 제거된다.
우선순위가 낮은 파드에 대한 파드-간 어피니티
이 질문에 대한 답변이 '예'인 경우에만 노드가 선점 대상으로 간주된다. "대기 중인 파드보다 우선순위가 낮은 모든 파드가 노드에서 제거되면, 보류 중인 파드를 노드에 스케줄링할 수 있습니까?"
참고:
선점으로 우선순위가 낮은 모든 파드를 반드시 제거할 필요는 없다. 우선순위가 낮은 모든 파드보다 적은 수를 제거하여 보류 중인 파드를 스케줄링할 수 있는 경우, 우선순위가 낮은 파드의 일부만 제거된다. 그럼에도 불구하고, 앞의 질문에 대한 대답은 '예'여야 한다. 답변이 '아니오'인 경우, 노드가 선점 대상으로 간주되지 않는다.보류 중인 파드가 노드에 있는 하나 이상의 우선순위가 낮은 파드에 대한 파드-간 어피니티를 가진 경우에, 우선순위가 낮은 파드가 없을 때 파드-간 어피니티 규칙을 충족할 수 없다. 이 경우, 스케줄러는 노드의 파드를 축출하지 않는다. 대신, 다른 노드를 찾는다. 스케줄러가 적합한 노드를 찾거나 찾지 못할 수 있다. 보류 중인 파드를 스케줄링할 수 있다는 보장은 없다.
이 문제에 대한 권장 솔루션은 우선순위가 같거나 높은 파드에 대해서만 파드-간 어피니티를 생성하는 것이다.
교차 노드 선점
보류 중인 파드 P가 노드 N에 스케줄링될 수 있도록 노드 N이 선점 대상으로 고려되고 있다고 가정한다. 다른 노드의 파드가 축출된 경우에만 P가 N에서 실행 가능해질 수 있다. 예를 들면 다음과 같다.
- 파드 P는 노드 N에 대해 고려된다.
- 파드 Q는 노드 N과 동일한 영역의 다른 노드에서 실행 중이다.
- 파드 P는 파드 Q(
topologyKey: topology.kubernetes.io/zone)와 영역(zone) 전체의 안티-어피니티를 갖는다. - 영역에서 파드 P와 다른 파드 간의 안티-어피니티에 대한 다른 경우는 없다.
- 노드 N에서 파드 P를 스케줄링하기 위해, 파드 Q를 축출할 수 있지만, 스케줄러는 교차-노드 선점을 수행하지 않는다. 따라서, 파드 P가 노드 N에서 스케줄링할 수 없는 것으로 간주된다.
파드 Q가 노드에서 제거되면, 파드 안티-어피니티 위반이 사라지고, 파드 P는 노드 N에서 스케줄링될 수 있다.
수요가 충분하고 합리적인 성능의 알고리즘을 찾을 경우 향후 버전에서 교차 노드 선점의 추가를 고려할 수 있다.
문제 해결
파드 우선순위와 선점은 원하지 않는 부작용을 가질 수 있다. 다음은 잠재적 문제의 예시와 이를 해결하는 방법이다.
파드가 불필요하게 선점(축출)됨
선점은 우선순위가 높은 보류 중인 파드를 위한 공간을 만들기 위해 리소스 압박을 받고 있는
클러스터에서 기존 파드를 제거한다. 실수로 특정 파드에 높은 우선순위를
부여하면, 의도하지 않은 높은 우선순위 파드가 클러스터에서
선점을 유발할 수 있다. 파드 우선순위는 파드 명세에서
priorityClassName 필드를 설정하여 지정한다. 그런 다음
우선순위의 정수 값이 분석되어 podSpec 의 priority 필드에 채워진다.
문제를 해결하기 위해, 해당 파드가 우선순위가 낮은 클래스를 사용하도록 priorityClassName 을
변경하거나, 해당 필드를 비워둘 수 있다. 빈
priorityClassName 은 기본값이 0으로 해석된다.
파드가 축출되면, 축출된 파드에 대한 이벤트가 기록된다. 선점은 클러스터가 파드에 대한 리소스를 충분히 가지지 못한 경우에만 발생한다. 이러한 경우, 선점은 보류 중인 파드(선점자)의 우선순위가 피해자 파드보다 높은 경우에만 발생한다. 보류 중인 파드가 없거나, 보류 중인 파드의 우선순위가 피해자 파드와 같거나 낮은 경우 선점이 발생하지 않아야 한다. 그러한 시나리오에서 선점이 발생하면, 이슈를 올리기 바란다.
파드가 축출되었지만, 선점자는 스케줄링되지 않음
파드가 축출되면, 요청된 정상적인 종료 기간(기본적으로 30초)이 주어진다. 이 기간 내에 대상 파드가 종료되지 않으면, 강제 종료된다. 모든 피해자 파드가 사라지면, 선점자 파드를 스케줄링할 수 있다.
선점자 파드가 피해자 파드가 없어지기를 기다리는 동안, 동일한 노드에 적합한 우선순위가 높은 파드가 생성될 수 있다. 이 경우, 스케줄러는 선점자 대신 우선순위가 높은 파드를 스케줄링한다.
이것은 예상된 동작이다. 우선순위가 높은 파드는 우선순위가 낮은 파드를 대체해야 한다.
우선순위가 높은 파드는 우선순위가 낮은 파드보다 우선함
스케줄러가 보류 중인 파드를 실행할 수 있는 노드를 찾으려고 한다. 노드를 찾지 못하면, 스케줄러는 임의의 노드에서 우선순위가 낮은 파드를 제거하여 보류 중인 파드를 위한 공간을 만든다. 우선순위가 낮은 파드가 있는 노드가 보류 중인 파드를 실행할 수 없는 경우, 스케줄러는 선점을 위해 우선순위가 높은 다른 노드(다른 노드의 파드와 비교)를 선택할 수 있다. 피해자 파드는 여전히 선점자 파드보다 우선순위가 낮아야 한다.
선점할 수 있는 여러 노드가 있는 경우, 스케줄러는 우선순위가 가장 낮은 파드 세트를 가진 노드를 선택하려고 한다. 그러나, 이러한 파드가 위반될 PodDisruptionBudget을 가지고 있고 축출된 경우 스케줄러는 우선순위가 높은 파드를 가진 다른 노드를 선택할 수 있다.
선점을 위해 여러 개의 노드가 존재하고 위의 시나리오 중 어느 것도 적용되지 않는 경우, 스케줄러는 우선순위가 가장 낮은 노드를 선택한다.
파드 우선순위와 서비스 품질 간의 상호 작용
파드 우선순위와 QoS 클래스는
상호 작용이 거의 없고 QoS 클래스를 기반으로 파드 우선순위를 설정하는 데 대한
기본 제한이 없는 두 개의 직교(orthogonal) 기능이다. 스케줄러의
선점 로직은 선점 대상을 선택할 때 QoS를 고려하지 않는다.
선점은 파드 우선순위를 고려하고 우선순위가 가장 낮은 대상 세트를
선택하려고 한다. 우선순위가 가장 높은 파드는 스케줄러가
선점자 파드를 스케줄링할 수 없거나 우선순위가 가장 낮은 파드가
PodDisruptionBudget 으로 보호되는 경우에만, 우선순위가 가장 낮은 파드를
축출 대상으로 고려한다.
kubelet은 우선순위를 사용하여 파드의 노드-압박(node-pressure) 축출 순서를 결정한다. 사용자는 QoS 클래스를 사용하여 어떤 파드가 축출될 것인지 예상할 수 있다. kubelet은 다음의 요소들을 통해서 파드의 축출 순위를 매긴다.
- 기아(starved) 리소스 사용량이 요청을 초과하는지 여부
- 파드 우선순위
- 요청 대비 리소스 사용량
더 자세한 내용은 kubelet 축출을 위한 파드 선택을 참조한다.
kubelet 노드-압박 축출은 사용량이 요청을 초과하지 않는 경우 파드를 축출하지 않는다. 우선순위가 낮은 파드가 요청을 초과하지 않으면, 축출되지 않는다. 요청을 초과하는 우선순위가 더 높은 다른 파드가 축출될 수 있다.
다음 내용
- 프라이어리티클래스와 함께 리소스쿼터 사용에 대해 읽기: 기본으로 프라이어리티 클래스 소비 제한
- 파드 중단(disruption)에 대해 학습한다.
- API를 이용한 축출에 대해 학습한다.
- 노드-압박(node-pressure) 축출에 대해 학습한다.
11.10 - 노드-압박 축출
노드-압박 축출은 kubelet이 노드의 자원을 회수하기 위해 파드를 능동적으로 중단시키는 절차이다.
kubelet은 클러스터 노드의 메모리, 디스크 공간, 파일시스템 inode와 같은 자원을 모니터링한다. 이러한 자원 중 하나 이상이 특정 소모 수준에 도달하면, kubelet은 하나 이상의 파드를 능동적으로 중단시켜 자원을 회수하고 고갈 상황을 방지할 수 있다.
노드-압박 축출 과정에서, kubelet은 축출할 파드의 PodPhase를
Failed로 설정함으로써 파드가 종료된다.
노드-압박 축출은 API를 이용한 축출과는 차이가 있다.
kubelet은 이전에 설정된 PodDisruptionBudget 값이나 파드의 terminationGracePeriodSeconds 값을 따르지 않는다.
소프트 축출 임계값을 사용하는 경우,
kubelet은 이전에 설정된 eviction-max-pod-grace-period 값을 따른다.
하드 축출 임계값을 사용하는 경우, 파드 종료 시 0s 만큼 기다린 후 종료한다(즉, 기다리지 않고 바로 종료한다).
실패한 파드를 새로운 파드로 교체하는
워크로드 리소스(예:
스테이트풀셋(StatefulSet) 또는
디플로이먼트(Deployment))가 파드를 관리하는 경우,
컨트롤 플레인이나 kube-controller-manager가 축출된 파드를 대신할 새 파드를 생성한다.
참고:
kubelet은 최종 사용자 파드를 종료하기 전에 먼저 노드 수준 자원을 회수하려고 시도한다. 예를 들어, 디스크 자원이 부족하면 사용하지 않는 컨테이너 이미지를 먼저 제거한다.kubelet은 축출 결정을 내리기 위해 다음과 같은 다양한 파라미터를 사용한다.
- 축출 신호
- 축출 임계값
- 모니터링 간격
축출 신호
축출 신호는 특정 시점에서 특정 자원의 현재 상태이다. kubelet은 노드에서 사용할 수 있는 리소스의 최소량인 축출 임계값과 축출 신호를 비교하여 축출 결정을 내린다.
kubelet은 다음과 같은 축출 신호를 사용한다.
| 축출 신호 | 설명 |
|---|---|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
nodefs.available |
nodefs.available := node.stats.fs.available |
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
이 표에서, 설명 열은 kubelet이 축출 신호 값을 계산하는 방법을 나타낸다.
각 축출 신호는 백분율 또는 숫자값을 지원한다.
kubelet은 총 용량 대비 축출 신호의 백분율 값을
계산한다.
memory.available 값은 free -m과 같은 도구가 아니라 cgroupfs로부터 도출된다.
이는 free -m이 컨테이너 안에서는 동작하지 않고, 또한 사용자가
node allocatable
기능을 사용하는 경우 자원 부족에 대한 결정은 루트 노드뿐만 아니라
cgroup 계층 구조의 최종 사용자 파드 부분에서도 지역적으로 이루어지기 때문에 중요하다.
이 스크립트는
kubelet이 memory.available을 계산하기 위해 수행하는 동일한 단계들을 재현한다.
kubelet은 메모리 압박 상황에서 메모리가 회수 가능하다고 가정하므로,
inactive_file(즉, 비활성 LRU 목록의 파일 기반 메모리 바이트 수)을
계산에서 제외한다.
kubelet은 다음과 같은 파일시스템 파티션을 지원한다.
nodefs: 노드의 메인 파일시스템이며, 로컬 디스크 볼륨, emptyDir, 로그 스토리지 등에 사용된다. 예를 들어nodefs는/var/lib/kubelet/을 포함한다.imagefs: 컨테이너 런타임이 컨테이너 이미지 및 컨테이너 쓰기 가능 레이어를 저장하는 데 사용하는 선택적 파일시스템이다.
kubelet은 이러한 파일시스템을 자동으로 검색하고 다른 파일시스템은 무시한다. kubelet은 다른 구성은 지원하지 않는다.
아래의 kubelet 가비지 수집 기능은 더 이상 사용되지 않으며 축출로 대체되었다.
| 기존 플래그 | 새로운 플래그 | 이유 |
|---|---|---|
--image-gc-high-threshold |
--eviction-hard 또는 --eviction-soft |
기존의 축출 신호가 이미지 가비지 수집을 트리거할 수 있음 |
--image-gc-low-threshold |
--eviction-minimum-reclaim |
축출 회수도 동일한 작업을 수행 |
--maximum-dead-containers |
- | 오래된 로그들이 컨테이너의 컨텍스트 외부에 저장된 이후로 사용되지 않음 |
--maximum-dead-containers-per-container |
- | 오래된 로그들이 컨테이너의 컨텍스트 외부에 저장된 이후로 사용되지 않음 |
--minimum-container-ttl-duration |
- | 오래된 로그들이 컨테이너의 컨텍스트 외부에 저장된 이후로 사용되지 않음 |
축출 임계값
kubelet이 축출 결정을 내릴 때 사용하는 축출 임계값을 사용자가 임의로 설정할 수 있다.
축출 임계값은 [eviction-signal][operator][quantity] 형태를 갖는다.
eviction-signal에는 사용할 축출 신호를 적는다.operator에는 관계연산자를 적는다(예:<- 미만)quantity에는1Gi와 같이 축출 임계값 수치를 적는다.quantity에 들어가는 값은 쿠버네티스가 사용하는 수치 표현 방식과 맞아야 한다. 숫자값 또는 백분율(%)을 사용할 수 있다.
예를 들어, 노드에 총 10Gi의 메모리가 있고
1Gi 아래로 내려갔을 때 축출이 시작되도록 만들고 싶으면, 축출 임계값을
memory.available<10% 또는 memory.available<1Gi 형태로 정할 수 있다. 둘을 동시에 사용할 수는 없다.
소프트 축출 임계값과 하드 축출 임계값을 설정할 수 있다.
소프트 축출 임계값
소프트 축출 임계값은 관리자가 설정하는 유예 시간(필수)과 함께 정의된다. kubelet은 유예 시간이 초과될 때까지 파드를 제거하지 않는다. 유예 시간이 지정되지 않으면 kubelet 시작 시 오류가 반환된다.
kubelet이 축출 과정에서 사용할 수 있도록, '소프트 축출 임계값'과 '최대 허용 파드 종료 유예 시간' 둘 다를 설정할 수 있다. '최대 허용 파드 종료 유예 시간'이 설정되어 있는 상태에서 '소프트 축출 임계값'에 도달하면, kubelet은 두 유예 시간 중 작은 쪽을 적용한다. '최대 허용 파드 종료 유예 시간'을 설정하지 않으면, kubelet은 축출된 파드를 유예 시간 없이 즉시 종료한다.
소프트 축출 임계값을 설정할 때 다음과 같은 플래그를 사용할 수 있다.
eviction-soft: 축출 임계값(예:memory.available<1.5Gi)의 집합이며, 지정된 유예 시간동안 이 축출 임계값 조건이 충족되면 파드 축출이 트리거된다.eviction-soft-grace-period: 축출 유예 시간의 집합이며, 소프트 축출 임계값 조건이 이 유예 시간동안 충족되면 파드 축출이 트리거된다.eviction-max-pod-grace-period: '최대 허용 파드 종료 유예 시간(단위: 초)'이며, 소프트 축출 임계값 조건이 충족되어 파드를 종료할 때 사용한다.
하드 축출 임계값
하드 축출 임계값에는 유예 시간이 없다. 하드 축출 임계값 조건이 충족되면, kubelet은 고갈된 자원을 회수하기 위해 파드를 유예 시간 없이 즉시 종료한다.
eviction-hard 플래그를 사용하여 하드 축출
임계값(예: memory.available<1Gi)을 설정할 수 있다.
kubelet은 다음과 같은 하드 축출 임계값을 기본적으로 설정하고 있다.
memory.available<100Minodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(리눅스 노드)
이러한 하드 축출 임계값의 기본값은 매개변수가 변경되지 않은 경우에만 설정된다. 어떤 매개변수의 값을 변경한 경우, 다른 매개변수의 값은 기본값으로 상속되지 않고 0으로 설정된다. 사용자 지정 값을 제공하려면, 모든 임계값을 각각 제공해야 한다.
축출 모니터링 시간 간격
kubelet은 housekeeping-interval에 설정된 시간 간격(기본값: 10s)마다
축출 임계값을 확인한다.
노드 컨디션
kubelet은 하드/소프트 축출 임계값 조건이 충족되어 노드 압박이 발생했다는 것을 알리기 위해, 설정된 유예 시간과는 관계없이 노드 컨디션을 보고한다.
kubelet은 다음과 같이 노드 컨디션과 축출 신호를 매핑한다.
| 노드 컨디션 | 축출 신호 | 설명 |
|---|---|---|
MemoryPressure |
memory.available |
노드의 가용 메모리 양이 축출 임계값에 도달함 |
DiskPressure |
nodefs.available, nodefs.inodesFree, imagefs.available, 또는 imagefs.inodesFree |
노드의 루트 파일시스템 또는 이미지 파일시스템의 가용 디스크 공간 또는 inode의 수가 축출 임계값에 도달함 |
PIDPressure |
pid.available |
(리눅스) 노드의 가용 프로세스 ID(PID)가 축출 임계값 이하로 내려옴 |
kubelet은 --node-status-update-frequency에 설정된
시간 간격(기본값: 10s)마다 노드 컨디션을 업데이트한다.
노드 컨디션 진동(oscillation)
경우에 따라, 노드의 축출 신호값이 사전에 설정된 유예 시간 동안 유지되지 않고
소프트 축출 임계값을 중심으로 진동할 수 있다. 이로 인해 노드 컨디션이 계속
true와 false로 바뀌며, 잘못된 축출 결정을 야기할 수 있다.
이러한 진동을 방지하기 위해, eviction-pressure-transition-period 플래그를
사용하여 kubelet이 노드 컨디션을 다른 상태로 바꾸기 위해 기다려야 하는 시간을
설정할 수 있다. 기본값은 5m이다.
노드-수준 자원 회수하기
kubelet은 최종 사용자 파드를 축출하기 전에 노드-수준 자원 회수를 시도한다.
DiskPressure 노드 컨디션이 보고되면,
kubelet은 노드의 파일시스템을 기반으로 노드-수준 자원을 회수한다.
imagefs가 있는 경우
컨테이너 런타임이 사용할 전용 imagefs 파일시스템이 노드에 있으면,
kubelet은 다음 작업을 수행한다.
nodefs파일시스템이 축출 임계값 조건을 충족하면, kubelet은 종료된 파드와 컨테이너에 대해 가비지 수집을 수행한다.imagefs파일시스템이 축출 임계값 조건을 충족하면, kubelet은 모든 사용중이지 않은 이미지를 삭제한다.
imagefs가 없는 경우
노드에 nodefs 파일시스템만 있고 이것이 축출 임계값 조건을 충족한 경우,
kubelet은 다음 순서로 디스크 공간을 확보한다.
- 종료된 파드와 컨테이너에 대해 가비지 수집을 수행한다.
- 사용중이지 않은 이미지를 삭제한다.
kubelet 축출을 위한 파드 선택
kubelet이 노드-수준 자원을 회수했음에도 축출 신호가 임계값 아래로 내려가지 않으면, kubelet은 최종 사용자 파드 축출을 시작한다.
kubelet은 파드 축출 순서를 결정하기 위해 다음의 파라미터를 활용한다.
- 파드의 자원 사용량이 요청량을 초과했는지 여부
- 파드 우선순위
- 파드의 자원 요청량 대비 자원 사용량
결과적으로, kubelet은 다음과 같은 순서로 파드의 축출 순서를 정하고 축출을 수행한다.
BestEffort또는Burstable파드 중 자원 사용량이 요청량을 초과한 파드. 이 파드들은 파드들의 우선순위, 그리고 자원 사용량이 요청량을 얼마나 초과했는지에 따라 축출된다.Guaranteed,Burstable파드 중 자원 사용량이 요청량보다 낮은 파드는 우선순위에 따라 후순위로 축출된다.
참고:
kubelet이 파드 축출 순서를 결정할 때 파드의 QoS 클래스는 이용하지 않는다. 메모리 등의 자원을 회수할 때, QoS 클래스를 이용하여 가장 가능성이 높은 파드 축출 순서를 예측할 수는 있다. QoS는 EphemeralStorage 요청에 적용되지 않으므로, 노드가 예를 들어DiskPressure 아래에 있는 경우 위의 시나리오가 적용되지 않는다.Guaranteed 파드는 모든 컨테이너에 대해 자원 요청량과 제한이 명시되고
그 둘이 동일할 때에만 보장(guaranteed)된다. 다른 파드의 자원 사용으로 인해
Guaranteed 파드가 축출되는 일은 발생하지 않는다. 만약 시스템 데몬(예:
kubelet, journald)이 system-reserved 또는 kube-reserved
할당을 통해 예약된 것보다 더 많은 자원을 소비하고, 노드에는 요청량보다 적은 양의
자원을 사용하고 있는 Guaranteed / Burstable 파드만 존재한다면,
kubelet은 노드 안정성을 유지하고 자원 고갈이 다른 파드에 미칠 영향을 통제하기 위해
이러한 파드 중 하나를 골라 축출해야 한다.
이 경우, 가장 낮은 Priority를 갖는 파드가 선택된다.
inodes와 PIDs에 대한 요청량은 정의하고 있지 않기 때문에, kubelet이 inode
또는 PID 고갈 때문에 파드를 축출할 때에는 파드의 Priority를 이용하여 축출
순위를 정한다.
노드에 전용 imagefs 파일시스템이 있는지 여부에 따라 kubelet이 파드 축출 순서를
정하는 방식에 차이가 있다.
imagefs가 있는 경우
nodefs로 인한 축출의 경우, kubelet은 nodefs
사용량(모든 컨테이너의 로컬 볼륨 + 로그)을 기준으로 축출 순서를 정한다.
imagefs로 인한 축출의 경우, kubelet은 모든 컨테이너의
쓰기 가능한 레이어(writable layer) 사용량을 기준으로 축출 순서를 정한다.
imagefs가 없는 경우
nodefs로 인한 축출의 경우, kubelet은 각 파드의 총
디스크 사용량(모든 컨테이너의 로컬 볼륨 + 로그 + 쓰기 가능한 레이어)을 기준으로 축출 순서를 정한다.
최소 축출 회수량
경우에 따라, 파드를 축출했음에도 적은 양의 자원만이 회수될 수 있다. 이로 인해 kubelet이 반복적으로 축출 임계값 도달을 감지하고 여러 번의 축출을 수행할 수 있다.
--eviction-minimum-reclaim 플래그 또는
kubelet 설정 파일을 이용하여
각 자원에 대한 최소 회수량을 설정할 수 있다. kubelet이 자원 부족 상황을 감지하면,
앞서 설정한 최소 회수량에 도달할때까지 회수를 계속 진행한다.
예를 들어, 다음 YAML은 최소 회수량을 정의하고 있다.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi"
imagefs.available: "100Gi"
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi"
imagefs.available: "2Gi"
이 예제에서, 만약 nodefs.available 축출 신호가 축출 임계값 조건에 도달하면,
kubelet은 축출 신호가 임계값인 1Gi에 도달할 때까지 자원을 회수하며,
이어서 축출 신호가 1.5Gi에 도달할 때까지 최소 500Mi 이상의 자원을
회수한다.
유사한 방식으로, kubelet은 imagefs.available 축출 신호가
102Gi에 도달할 때까지 imagefs 자원을 회수한다.
모든 자원에 대해 eviction-minimum-reclaim의 기본값은 0이다.
노드 메모리 부족 시의 동작
kubelet의 메모리 회수가 가능하기 이전에 노드에 메모리 부족(out of memory, 이하 OOM) 이벤트가 발생하면, 노드는 oom_killer에 의존한다.
kubelet은 각 파드에 설정된 QoS를 기반으로 각 컨테이너에 oom_score_adj 값을 설정한다.
| 서비스 품질(Quality of Service) | oom_score_adj |
|---|---|
Guaranteed |
-997 |
BestEffort |
1000 |
Burstable |
min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
노드가 OOM을 겪기 전에 kubelet이 메모리를 회수하지 못하면, oom_killer가 노드의
메모리 사용률 백분율을 이용하여 oom_score를 계산하고, 각 컨테이너의 실질
oom_score를 구하기 위해 oom_score_adj를 더한다. 그 뒤 oom_score가 가장 높은
컨테이너부터 종료시킨다.
이는 곧, 스케줄링 요청에 비해 많은 양의 메모리를 사용하면서 QoS가 낮은 파드에 속한 컨테이너가 먼저 종료됨을 의미한다.
파드 축출과 달리, 컨테이너가 OOM으로 인해 종료되면,
kubelet이 컨테이너의 RestartPolicy를 기반으로 컨테이너를 다시 실행할 수 있다.
추천 예시
아래 섹션에서 축출 설정에 대한 추천 예시를 소개한다.
스케줄 가능한 자원과 축출 정책
kubelet에 축출 정책을 설정할 때, 만약 어떤 파드 배치가 즉시 메모리 압박을 야기하기 때문에 축출을 유발한다면 스케줄러가 그 파드 배치를 수행하지 않도록 설정해야 한다.
다음 시나리오를 가정한다.
- 노드 메모리 용량:
10Gi - 운영자는 시스템 데몬(커널,
kubelet등)을 위해 메모리 용량의 10%를 확보해 놓고 싶어 한다. - 운영자는 시스템 OOM 발생을 줄이기 위해 메모리 사용률이 95%인 상황에서 파드를 축출하고 싶어한다.
이것이 실현되도록, kubelet이 다음과 같이 실행된다.
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
이 환경 설정에서, --system-reserved 플래그는 시스템 용으로 1.5Gi 메모리를
확보하는데, 이는 총 메모리의 10% + 축출 임계값에 해당된다.
파드가 요청량보다 많은 메모리를 사용하거나 시스템이 1Gi 이상의 메모리를
사용하여, memory.available 축출 신호가 500Mi 아래로 내려가면 노드가 축출
임계값에 도달할 수 있다.
데몬셋(DaemonSet)
파드 우선 순위(Priority)는 파드 축출 결정을 내릴 때의 주요 요소이다.
kubelet이 DaemonSet에 속하는 파드를 축출하지 않도록 하려면
해당 파드의 파드 스펙에 충분히 높은 priorityClass를 지정한다.
또는 낮은 priorityClass나 기본값을 사용하여
리소스가 충분할 때만 DaemonSet 파드가 실행되도록 허용할 수도 있다.
알려진 이슈
다음 섹션에서는 리소스 부족 처리와 관련된 알려진 이슈에 대해 다룬다.
kubelet이 메모리 압박을 즉시 감지하지 못할 수 있음
기본적으로 kubelet은 cAdvisor를 폴링하여
일정한 간격으로 메모리 사용량 통계를 수집한다.
해당 타임 윈도우 내에서 메모리 사용량이 빠르게 증가하면 kubelet이
MemoryPressure를 충분히 빠르게 감지하지 못해 OOMKiller가 계속 호출될 수 있다.
--kernel-memcg-notification 플래그를 사용하여
kubelet의 memcg 알림 API가 임계값을 초과할 때 즉시 알림을 받도록
할 수 있다.
사용률(utilization)을 극단적으로 높이려는 것이 아니라 오버커밋(overcommit)에 대한 합리적인 조치만 원하는 경우,
이 문제에 대한 현실적인 해결 방법은 --kube-reserved 및
--system-reserved 플래그를 사용하여 시스템에 메모리를 할당하는 것이다.
active_file 메모리가 사용 가능한 메모리로 간주되지 않음
리눅스에서, 커널은 활성 LRU 목록의 파일 지원 메모리 바이트 수를 active_file
통계로 추적한다. kubelet은 active_file 메모리 영역을 회수할 수 없는 것으로
취급한다. 임시 로컬 스토리지를 포함하여 블록 지원 로컬 스토리지를 집중적으로
사용하는 워크로드의 경우 파일 및 블록 데이터의 커널 수준 캐시는 최근에 액세스한
많은 캐시 페이지가 active_file로 계산될 가능성이 있음을 의미한다. 활성 LRU
목록에 이러한 커널 블록 버퍼가 충분히 많으면, kubelet은 이를 높은 자원 사용
상태로 간주하고 노드가 메모리 압박을 겪고 있다고 테인트를 표시할 수 있으며, 이는
파드 축출을 유발한다.
자세한 사항은 https://github.com/kubernetes/kubernetes/issues/43916를 참고한다.
집중적인 I/O 작업을 수행할 가능성이 있는 컨테이너에 대해 메모리 제한량 및 메모리 요청량을 동일하게 설정하여 이 문제를 해결할 수 있다. 해당 컨테이너에 대한 최적의 메모리 제한량을 추정하거나 측정해야 한다.
다음 내용
- API를 이용한 축출에 대해 알아본다.
- 파드 우선순위와 선점에 대해 알아본다.
- PodDisruptionBudgets에 대해 알아본다.
- 서비스 품질(QoS)에 대해 알아본다.
- 축출 API를 확인한다.
11.11 - API를 이용한 축출(API-initiated Eviction)
API를 이용한 축출은 축출 API를 사용하여
생성된 Eviction 오브젝트로 파드를 정상 종료한다.
축출 API를 직접 호출하거나, 또는 kubectl drain 명령과 같이
API 서버의 클라이언트를 사용하여 프로그램적인 방법으로 축출 요청을 할 수 있다.
이는 Eviction 오브젝트를 만들며, API 서버로 하여금 파드를 종료하도록 만든다.
API를 이용한 축출은 사용자가 설정한 PodDisruptionBudgets 및
terminationGracePeriodSeconds 값을 준수한다.
API를 사용하여 Eviction 오브젝트를 만드는 것은
정책 기반의 파드 DELETE 동작을 수행하는 것과
비슷한 효과를 낸다.
축출 API 호출하기
각 언어 별 쿠버네티스 클라이언트를 사용하여
쿠버네티스 API를 호출하고 Eviction 오브젝트를 생성할 수 있다.
이를 실행하려면, 아래의 예시를 참고하여 POST 호출을 수행한다.
참고:
policy/v1 축출은 v1.22 이상에서 사용 가능하다. 이전 버전에서는 policy/v1beta1를 사용한다.{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
참고:
v1.22에서 사용 중단 및policy/v1으로 대체되었다.{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
또는 다음 예시와 같이 curl 또는 wget으로 API에 접근하여
축출 동작을 시도할 수도 있다.
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
API를 이용한 축출의 동작
API를 사용하여 축출을 요청하면, API 서버는 인가 확인(admission checks)를 수행하고 다음 중 하나로 응답한다.
200 OK: 축출 요청이 허용되었고,Eviction서브리소스가 생성되었고, (마치 파드 URL에DELETE요청을 보낸 것처럼) 파드가 삭제되었다.429 Too Many Requests: 현재 설정된 PodDisruptionBudget 때문에 축출이 현재 허용되지 않는다. 또는 API 요청 속도 제한(rate limiting) 때문에 이 응답을 받았을 수도 있다.500 Internal Server Error: 잘못된 환경 설정(예: 여러 PodDisruptionBudget이 하나의 동일한 파드를 참조함)으로 인해 축출이 허용되지 않는다.
축출하려는 파드가
PodDisruptionBudget이 설정된 워크로드에 속하지 않는다면,
API 서버는 항상 200 OK를 반환하고 축출을 허용한다.
API 서버가 축출을 허용하면, 파드는 다음과 같이 삭제된다.
- API 서버 내
Pod리소스의 삭제 타임스탬프(deletion timestamp)가 업데이트되며, 이 타임스탬프에 명시된 시각이 경과하면 API 서버는 해당Pod리소스를 종료 대상으로 간주한다. 또한 설정된 그레이스 시간(grace period)이Pod리소스에 기록된다. - 로컬 파드가 실행되고 있는 노드의 kubelet이
Pod가 종료 대상으로 표시된 것을 감지하고 로컬 파드의 그레이스풀 셧다운을 시작한다. - kubelet이 파드를 종료하는 와중에, 컨트롤 플레인은 엔드포인트 및 엔드포인트슬라이스 오브젝트에서 파드를 삭제한다. 이 결과, 컨트롤러는 파드를 더 이상 유효한 오브젝트로 간주하지 않는다.
- 파드의 그레이스 시간이 만료되면, kubelet이 로컬 파드를 강제로 종료한다.
- kubelet이 API 서버에
Pod리소스를 삭제하도록 지시한다. - API 서버가
Pod리소스를 삭제한다.
문제가 있어 중단된 축출 트러블슈팅하기
일부 경우에, 애플리케이션이 잘못된 상태로 돌입하여,
직접 개입하기 전에는 축출 API가 429 또는 500 응답만 반환할 수 있다.
이러한 현상은, 예를 들면 레플리카셋이 애플리케이션을 서비스할 파드를 생성했지만
새 파드가 Ready로 바뀌지 못하는 경우에 발생할 수 있다.
또는 마지막으로 축출된 파드가 긴 종료 그레이스 시간을 가진 경우에 이러한 현상을 목격할 수도 있다.
문제가 있어 중단된 축출을 발견했다면, 다음 해결책 중 하나를 시도해 본다.
- 이 문제를 발생시키는 자동 동작(automated operation)을 중단하거나 일시 중지한다. 해당 동작을 재시작하기 전에, 문제가 있어 중단된 애플리케이션을 조사한다.
- 잠시 기다린 뒤, 축출 API를 사용하는 것 대신 클러스터 컨트롤 플레인에서 파드를 직접 삭제한다.
다음 내용
- Pod Disruption Budget을 사용하여 애플리케이션을 보호하는 방법에 대해 알아본다.
- 노드-압박 축출에 대해 알아본다.
- 파드 우선순위와 선점에 대해 알아본다.
12 - 클러스터 관리
쿠버네티스 클러스터 생성 또는 관리에 관련된 로우-레벨(lower-level)의 세부 정보를 설명한다.
클러스터 관리 개요는 쿠버네티스 클러스터를 생성하거나 관리하는 모든 사람들을 위한 것이다. 핵심 쿠버네티스 개념에 어느 정도 익숙하다고 가정한다.
클러스터 계획
쿠버네티스 클러스터를 계획, 설정 및 구성하는 방법에 대한 예는 시작하기에 있는 가이드를 참고한다. 이 문서에 나열된 솔루션을 배포판 이라고 한다.
참고:
모든 배포판이 활발하게 유지되는 것은 아니다. 최신 버전의 쿠버네티스에서 테스트된 배포판을 선택한다.가이드를 선택하기 전에 고려해야 할 사항은 다음과 같다.
- 컴퓨터에서 쿠버네티스를 한번 사용해보고 싶은가? 아니면, 고가용 멀티 노드 클러스터를 만들고 싶은가? 사용자의 필요에 따라 가장 적합한 배포판을 선택한다.
- 구글 쿠버네티스 엔진(Google Kubernetes Engine)과 같은 클라우드 제공자의 쿠버네티스 클러스터 호스팅 을 사용할 것인가? 아니면, 자체 클러스터를 호스팅 할 것인가?
- 클러스터가 온-프레미스 환경 에 있나? 아니면, 클라우드(IaaS) 에 있나? 쿠버네티스는 하이브리드 클러스터를 직접 지원하지는 않는다. 대신 여러 클러스터를 설정할 수 있다.
- 온-프레미스 환경에 쿠버네티스 를 구성하는 경우, 어떤 네트워킹 모델이 가장 적합한 지 고려한다.
- 쿠버네티스를 "베어 메탈" 하드웨어 에서 실행할 것인가? 아니면, 가상 머신(VM) 에서 실행할 것인가?
- 클러스터만 실행할 것인가? 아니면, 쿠버네티스 프로젝트 코드를 적극적으로 개발 하는 것을 기대하는가? 만약 후자라면, 활발하게 개발이 진행되고 있는 배포판을 선택한다. 일부 배포판은 바이너리 릴리스만 사용하지만, 더 다양한 선택을 제공한다.
- 클러스터를 실행하는 데 필요한 컴포넌트에 익숙해지자.
클러스터 관리
클러스터 보안
-
인증서 생성은 다른 툴 체인을 사용하여 인증서를 생성하는 단계를 설명한다.
-
쿠버네티스 컨테이너 환경은 쿠버네티스 노드에서 Kubelet으로 관리하는 컨테이너에 대한 환경을 설명한다.
-
쿠버네티스 API에 대한 접근 제어는 쿠버네티스가 자체 API에 대한 접근 제어를 구현하는 방법을 설명한다.
-
인증은 다양한 인증 옵션을 포함한 쿠버네티스에서의 인증에 대해 설명한다.
-
인가는 인증과는 별개로, HTTP 호출 처리 방법을 제어한다.
-
어드미션 컨트롤러 사용하기는 인증과 권한 부여 후 쿠버네티스 API 서버에 대한 요청을 가로채는 플러그인에 대해 설명한다.
-
쿠버네티스 클러스터에서 Sysctls 사용하기는 관리자가
sysctl커맨드라인 도구를 사용하여 커널 파라미터를 설정하는 방법에 대해 설명한다 . -
감사(audit)는 쿠버네티스의 감사 로그를 다루는 방법에 대해 설명한다.
kubelet 보안
선택적 클러스터 서비스
-
DNS 통합은 DNS 이름을 쿠버네티스 서비스로 직접 확인하는 방법을 설명한다.
-
클러스터 액티비티 로깅과 모니터링은 쿠버네티스에서의 로깅이 어떻게 작동하는지와 구현 방법에 대해 설명한다.
12.1 - 인증서
클러스터를 위한 인증서를 생성하기 위해서는, 인증서를 참고한다.
12.2 - 리소스 관리
애플리케이션을 배포하고 서비스를 통해 노출했다. 이제 무엇을 해야 할까? 쿠버네티스는 확장과 업데이트를 포함하여, 애플리케이션 배포를 관리하는 데 도움이 되는 여러 도구를 제공한다. 더 자세히 설명할 기능 중에는 구성 파일과 레이블이 있다.
리소스 구성 구성하기
많은 애플리케이션들은 디플로이먼트 및 서비스와 같은 여러 리소스를 필요로 한다. 여러 리소스의 관리는 동일한 파일에 그룹화하여 단순화할 수 있다(YAML에서 --- 로 구분). 예를 들면 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
단일 리소스와 동일한 방식으로 여러 리소스를 생성할 수 있다.
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
리소스는 파일에 표시된 순서대로 생성된다. 따라서, 스케줄러가 디플로이먼트와 같은 컨트롤러에서 생성한 서비스와 관련된 파드를 분산시킬 수 있으므로, 서비스를 먼저 지정하는 것이 가장 좋다.
kubectl apply 는 여러 개의 -f 인수도 허용한다.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
그리고 개별 파일 대신 또는 추가로 디렉터리를 지정할 수 있다.
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectl 은 접미사가 .yaml, .yml 또는 .json 인 파일을 읽는다.
동일한 마이크로서비스 또는 애플리케이션 티어(tier)와 관련된 리소스를 동일한 파일에 배치하고, 애플리케이션과 연관된 모든 파일을 동일한 디렉터리에 그룹화하는 것이 좋다. 애플리케이션의 티어가 DNS를 사용하여 서로 바인딩되면, 스택의 모든 컴포넌트를 함께 배포할 수 있다.
URL을 구성 소스로 지정할 수도 있다. 이는 GitHub에 체크인된 구성 파일에서 직접 배포하는 데 편리하다.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectl에서의 대량 작업
kubectl 이 대량으로 수행할 수 있는 작업은 리소스 생성만이 아니다. 또한 다른 작업을 수행하기 위해, 특히 작성한 동일한 리소스를 삭제하기 위해 구성 파일에서 리소스 이름을 추출할 수도 있다.
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
두 개의 리소스가 있는 경우, 리소스/이름 구문을 사용하여 커맨드 라인에서 둘다 모두 지정할 수도 있다.
kubectl delete deployments/my-nginx services/my-nginx-svc
리소스가 많을 경우, -l 또는 --selector 를 사용하여 지정된 셀렉터(레이블 쿼리)를 지정하여 레이블별로 리소스를 필터링하는 것이 더 쉽다.
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
kubectl 은 입력을 받아들이는 것과 동일한 구문으로 리소스 이름을 출력하므로, $() 또는 xargs 를 사용하여 작업을 연결할 수 있다.
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service | xargs -i kubectl get {}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
위의 명령을 사용하여, 먼저 examples/application/nginx/ 에 리소스를 생성하고 -o name 출력 형식으로 생성한 리소스를 출력한다(각 리소스를 resource/name으로 출력).
그런 다음 "service"만 grep 한 다음 kubectl get 으로 출력한다.
특정 디렉터리 내의 여러 서브 디렉터리에서 리소스를 구성하는 경우, --filename,-f 플래그와 함께 --recursive 또는 -R 을 지정하여, 서브 디렉터리에 대한 작업을 재귀적으로 수행할 수도 있다.
예를 들어, 리소스 유형별로 구성된 개발 환경에 필요한 모든 매니페스트를 보유하는 project/k8s/development 디렉터리가 있다고 가정하자.
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
기본적으로, project/k8s/development 에서 대량 작업을 수행하면, 서브 디렉터리를 처리하지 않고, 디렉터리의 첫 번째 레벨에서 중지된다. 다음 명령을 사용하여 이 디렉터리에 리소스를 생성하려고 하면, 오류가 발생할 것이다.
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
대신, 다음과 같이 --filename,-f 플래그와 함께 --recursive 또는 -R 플래그를 지정한다.
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursive 플래그는 kubectl {create,get,delete,describe,rollout} 등과 같이 --filename,-f 플래그를 허용하는 모든 작업에서 작동한다.
--recursive 플래그는 여러 개의 -f 인수가 제공될 때도 작동한다.
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectl 에 대해 더 자세히 알고 싶다면, 명령줄 도구 (kubectl)를 참조한다.
효과적인 레이블 사용
지금까지 사용한 예는 모든 리소스에 최대 한 개의 레이블만 적용하는 것이었다. 세트를 서로 구별하기 위해 여러 레이블을 사용해야 하는 많은 시나리오가 있다.
예를 들어, 애플리케이션마다 app 레이블에 다른 값을 사용하지만, 방명록 예제와 같은 멀티-티어 애플리케이션은 각 티어를 추가로 구별해야 한다. 프론트엔드는 다음의 레이블을 가질 수 있다.
labels:
app: guestbook
tier: frontend
Redis 마스터와 슬레이브는 프론트엔드와 다른 tier 레이블을 가지지만, 아마도 추가로 role 레이블을 가질 것이다.
labels:
app: guestbook
tier: backend
role: master
그리고
labels:
app: guestbook
tier: backend
role: slave
레이블은 레이블로 지정된 차원에 따라 리소스를 분할하고 사용할 수 있게 한다.
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
카나리(canary) 디플로이먼트
여러 레이블이 필요한 또 다른 시나리오는 동일한 컴포넌트의 다른 릴리스 또는 구성의 디플로이먼트를 구별하는 것이다. 새 릴리스가 완전히 롤아웃되기 전에 실제 운영 트래픽을 수신할 수 있도록 새로운 애플리케이션 릴리스(파드 템플리트의 이미지 태그를 통해 지정됨)의 카나리 를 이전 릴리스와 나란히 배포하는 것이 일반적이다.
예를 들어, track 레이블을 사용하여 다른 릴리스를 구별할 수 있다.
기본(primary), 안정(stable) 릴리스에는 값이 stable 인 track 레이블이 있다.
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
그런 다음 서로 다른 값(예: canary)으로 track 레이블을 전달하는 방명록 프론트엔드의 새 릴리스를 생성하여, 두 세트의 파드가 겹치지 않도록 할 수 있다.
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
프론트엔드 서비스는 레이블의 공통 서브셋을 선택하여(즉, track 레이블 생략) 두 레플리카 세트에 걸쳐 있으므로, 트래픽이 두 애플리케이션으로 리디렉션된다.
selector:
app: guestbook
tier: frontend
안정 및 카나리 릴리스의 레플리카 수를 조정하여 실제 운영 트래픽을 수신할 각 릴리스의 비율을 결정한다(이 경우, 3:1). 확신이 들면, 안정 릴리스의 track을 새로운 애플리케이션 릴리스로 업데이트하고 카나리를 제거할 수 있다.
보다 구체적인 예시는, Ghost 배포에 대한 튜토리얼을 확인한다.
레이블 업데이트
새로운 리소스를 만들기 전에 기존 파드 및 기타 리소스의 레이블을 다시 지정해야 하는 경우가 있다. 이것은 kubectl label 로 수행할 수 있다.
예를 들어, 모든 nginx 파드에 프론트엔드 티어로 레이블을 지정하려면, 다음과 같이 실행한다.
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
먼저 "app=nginx" 레이블이 있는 모든 파드를 필터링한 다음, "tier=fe" 레이블을 지정한다. 레이블을 지정한 파드를 보려면, 다음을 실행한다.
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
그러면 파드 티어의 추가 레이블 열(-L 또는 --label-columns 로 지정)과 함께, 모든 "app=nginx" 파드가 출력된다.
더 자세한 내용은, 레이블 및 kubectl label을 참고하길 바란다.
어노테이션 업데이트
때로는 어노테이션을 리소스에 첨부하려고 할 수도 있다. 어노테이션은 도구, 라이브러리 등과 같은 API 클라이언트가 검색할 수 있는 임의의 비-식별 메타데이터이다. 이는 kubectl annotate 으로 수행할 수 있다. 예를 들면 다음과 같다.
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
더 자세한 내용은, 어노테이션 및 kubectl annotate 문서를 참고하길 바란다.
애플리케이션 스케일링
애플리케이션의 로드가 증가하거나 축소되면, kubectl 을 사용하여 애플리케이션을 스케일링한다. 예를 들어, nginx 레플리카 수를 3에서 1로 줄이려면, 다음을 수행한다.
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
이제 디플로이먼트가 관리하는 파드가 하나만 있다.
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
시스템이 필요에 따라 1에서 3까지의 범위에서 nginx 레플리카 수를 자동으로 선택하게 하려면, 다음을 수행한다.
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
이제 nginx 레플리카가 필요에 따라 자동으로 확장되거나 축소된다.
더 자세한 내용은, kubectl scale, kubectl autoscale 및 horizontal pod autoscaler 문서를 참고하길 바란다.
리소스 인플레이스(in-place) 업데이트
때로는 자신이 만든 리소스를 필요한 부분만, 중단없이 업데이트해야 할 때가 있다.
kubectl apply
구성 파일 셋을 소스 제어에서 유지하는 것이 좋으며
(코드로서의 구성 참조),
그렇게 하면 구성하는 리소스에 대한 코드와 함께 버전을 지정하고 유지할 수 있다.
그런 다음, kubectl apply를 사용하여 구성 변경 사항을 클러스터로 푸시할 수 있다.
이 명령은 푸시하려는 구성의 버전을 이전 버전과 비교하고 지정하지 않은 속성에 대한 자동 변경 사항을 덮어쓰지 않은 채 수정한 변경 사항을 적용한다.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
참고로 kubectl apply 는 이전의 호출 이후 구성의 변경 사항을 판별하기 위해 리소스에 어노테이션을 첨부한다. 호출되면, kubectl apply 는 리소스를 수정하는 방법을 결정하기 위해, 이전 구성과 제공된 입력 및 리소스의 현재 구성 간에 3-way diff를 수행한다.
현재, 이 어노테이션 없이 리소스가 생성되므로, kubectl apply 의 첫 번째 호출은 제공된 입력과 리소스의 현재 구성 사이의 2-way diff로 대체된다. 이 첫 번째 호출 중에는, 리소스를 생성할 때 설정된 특성의 삭제를 감지할 수 없다. 이러한 이유로, 그 특성들을 삭제하지 않는다.
kubectl apply 에 대한 모든 후속 호출, 그리고 kubectl replace 및 kubectl edit 와 같이 구성을 수정하는 다른 명령은, 어노테이션을 업데이트하여, kubectl apply 에 대한 후속 호출이 3-way diff를 사용하여 삭제를 감지하고 수행할 수 있도록 한다.
kubectl edit
또는, kubectl edit로 리소스를 업데이트할 수도 있다.
kubectl edit deployment/my-nginx
이것은 먼저 리소스를 get 하여, 텍스트 편집기에서 편집한 다음, 업데이트된 버전으로 리소스를 apply 하는 것과 같다.
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# 편집한 다음, 파일을 저장한다.
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
이를 통해 보다 중요한 변경을 더 쉽게 수행할 수 있다. 참고로 EDITOR 또는 KUBE_EDITOR 환경 변수를 사용하여 편집기를 지정할 수 있다.
더 자세한 내용은, kubectl edit 문서를 참고하길 바란다.
kubectl patch
kubectl patch 를 사용하여 API 오브젝트를 인플레이스 업데이트할 수 있다. 이 명령은 JSON 패치,
JSON 병합 패치 그리고 전략적 병합 패치를 지원한다.
kubectl patch를 사용한 인플레이스 API 오브젝트 업데이트와
kubectl patch를
참조한다.
파괴적(disruptive) 업데이트
경우에 따라, 한 번 초기화하면 업데이트할 수 없는 리소스 필드를 업데이트해야 하거나, 디플로이먼트에서 생성된 손상된 파드를 고치는 등의 재귀적 변경을 즉시 원할 수도 있다. 이러한 필드를 변경하려면, replace --force 를 사용하여 리소스를 삭제하고 다시 만든다. 이 경우, 원래 구성 파일을 수정할 수 있다.
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
서비스 중단없이 애플리케이션 업데이트
언젠가는, 위의 카나리 디플로이먼트 시나리오에서와 같이, 일반적으로 새 이미지 또는 이미지 태그를 지정하여, 배포된 애플리케이션을 업데이트해야 한다. kubectl 은 여러 가지 업데이트 작업을 지원하며, 각 업데이트 작업은 서로 다른 시나리오에 적용할 수 있다.
디플로이먼트를 사용하여 애플리케이션을 생성하고 업데이트하는 방법을 안내한다.
nginx 1.14.2 버전을 실행한다고 가정해 보겠다.
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
3개의 레플리카를 포함한다(이전과 새 개정판이 공존할 수 있음).
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
1.16.1 버전으로 업데이트하려면, 위에서 배운 kubectl 명령을 사용하여 .spec.template.spec.containers[0].image 를 nginx:1.14.2 에서 nginx:1.16.1 로 변경한다.
kubectl edit deployment/my-nginx
이것으로 끝이다! 디플로이먼트는 배포된 nginx 애플리케이션을 배후에서 점차적으로 업데이트한다. 업데이트되는 동안 특정 수의 이전 레플리카만 중단될 수 있으며, 원하는 수의 파드 위에 특정 수의 새 레플리카만 생성될 수 있다. 이에 대한 더 자세한 내용을 보려면, 디플로이먼트 페이지를 방문한다.
다음 내용
- 애플리케이션 검사 및 디버깅에
kubectl을 사용하는 방법에 대해 알아본다. - 구성 모범 사례 및 팁을 참고한다.
12.3 - 클러스터 네트워킹
네트워킹은 쿠버네티스의 중심적인 부분이지만, 어떻게 작동하는지 정확하게 이해하기가 어려울 수 있다. 쿠버네티스에는 4가지 대응해야 할 네트워킹 문제가 있다.
- 고도로 결합된 컨테이너 간의 통신: 이 문제는
파드와
localhost통신으로 해결된다. - 파드 간 통신: 이 문제가 이 문서의 주요 초점이다.
- 파드와 서비스 간 통신: 이 문제는 서비스에서 다룬다.
- 외부와 서비스 간 통신: 이 문제도 서비스에서 다룬다.
쿠버네티스는 애플리케이션 간에 머신을 공유하는 것이다. 일반적으로, 머신을 공유하려면 두 애플리케이션이 동일한 포트를 사용하지 않도록 해야 한다. 여러 개발자 간에 포트를 조정하는 것은 대규모로 실시하기가 매우 어렵고, 사용자가 통제할 수 없는 클러스터 수준의 문제에 노출된다.
동적 포트 할당은 시스템에 많은 복잡성을 야기한다. 모든 애플리케이션은 포트를 플래그로 가져와야 하며, API 서버는 동적 포트 번호를 구성 블록에 삽입하는 방법을 알아야 하고, 서비스는 서로를 찾는 방법 등을 알아야 한다. 쿠버네티스는 이런 것들을 다루는 대신 다른 접근법을 취한다.
쿠버네티스 네트워킹 모델에 대한 상세 정보는 여기를 참고한다.
쿠버네티스 네트워크 모델의 구현 방법
네트워크 모델은 각 노드의 컨테이너 런타임에 의해 구현된다. 가장 일반적인 컨테이너 런타임은 컨테이너 네트워크 인터페이스(CNI) 플러그인을 사용하여 네트워크 및 보안 기능을 관리한다. 여러 공급 업체의 다양한 CNI 플러그인이 존재하며, 이들 중 일부는 네트워크 인터페이스를 추가 및 제거하는 기본 기능만 제공하는 반면, 다른 일부는 다른 컨테이너 오케스트레이션 시스템과의 통합, 여러 CNI 플러그인 실행, 고급 IPAM 기능 등과 같은 보다 정교한 솔루션을 제공한다.
쿠버네티스에서 지원하는 네트워킹 애드온의 일부 목록은 이 페이지를 참조한다.
다음 내용
네트워크 모델의 초기 설계와 그 근거 및 미래의 계획은 네트워킹 디자인 문서에 자세히 설명되어 있다.
12.4 - 로깅 아키텍처
애플리케이션 로그는 애플리케이션 내부에서 발생하는 상황을 이해하는 데 도움이 된다. 로그는 문제를 디버깅하고 클러스터 활동을 모니터링하는 데 특히 유용하다. 대부분의 최신 애플리케이션에는 일종의 로깅 메커니즘이 있다. 마찬가지로, 컨테이너 엔진들도 로깅을 지원하도록 설계되었다. 컨테이너화된 애플리케이션에 가장 쉽고 가장 널리 사용되는 로깅 방법은 표준 출력과 표준 에러 스트림에 작성하는 것이다.
그러나, 일반적으로 컨테이너 엔진이나 런타임에서 제공하는 기본 기능은 완전한 로깅 솔루션으로 충분하지 않다.
예를 들어, 컨테이너가 크래시되거나, 파드가 축출되거나, 노드가 종료된 경우에 애플리케이션의 로그에 접근하고 싶을 것이다.
클러스터에서 로그는 노드, 파드 또는 컨테이너와는 독립적으로 별도의 스토리지와 라이프사이클을 가져야 한다. 이 개념을 클러스터-레벨 로깅이라고 한다.
클러스터-레벨 로깅은 로그를 저장, 분석, 쿼리하기 위해서는 별도의 백엔드가 필요하다. 쿠버네티스가 로그 데이터를 위한 네이티브 스토리지 솔루션을 제공하지는 않지만, 쿠버네티스에 통합될 수 있는 기존의 로깅 솔루션이 많이 있다. 아래 내용은 로그를 어떻게 처리하고 관리하는지 설명한다.
파드와 컨테이너 로그
쿠버네티스는 실행중인 파드의 컨테이너에서 출력하는 로그를 감시한다.
아래 예시는, 초당 한 번씩 표준 출력에 텍스트를 기록하는
컨테이너를 포함하는 파드 매니페스트를 사용한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
이 파드를 실행하려면, 다음의 명령을 사용한다.
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
출력은 다음과 같다.
pod/counter created
로그를 가져오려면, 다음과 같이 kubectl logs 명령을 사용한다.
kubectl logs counter
출력은 다음과 같다.
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
kubectl logs --previous 를 사용해서 컨테이너의 이전 인스턴스에 대한 로그를 검색할 수 있다.
파드에 여러 컨테이너가 있는 경우,
다음과 같이 명령에 -c 플래그와 컨테이너 이름을 추가하여 접근하려는 컨테이너 로그를 지정해야 한다.
kubectl logs counter -c count
자세한 내용은 kubectl logs 문서를 참조한다.
노드가 컨테이너 로그를 처리하는 방법
컨테이너화된 애플리케이션의 stdout(표준 출력) 및 stderr(표준 에러) 스트림에 의해 생성된 모든 출력은 컨테이너 런타임이 처리하고 리디렉션 시킨다.
다양한 컨테이너 런타임들은 이를 각자 다른 방법으로 구현하였지만,
kubelet과의 호환성은 CRI 로깅 포맷 으로 표준화되어 있다.
기본적으로 컨테이너가 재시작하는 경우, kubelet은 종료된 컨테이너 하나를 로그와 함께 유지한다. 파드가 노드에서 축출되면, 해당하는 모든 컨테이너와 로그가 함께 축출된다.
kubelet은 쿠버네티스의 특정 API를 통해 사용자들에게 로그를 공개하며,
일반적으로 kubectl logs를 통해 접근할 수 있다.
로그 로테이션
기능 상태:
Kubernetes v1.21 [stable]
kubelet이 로그를 자동으로 로테이트하도록 설정할 수 있다.
로테이션을 구성해놓으면, kubelet은 컨테이너 로그를 로테이트하고 로깅 경로 구조를 관리한다. kubelet은 이 정보를 컨테이너 런타임에 전송하고(CRI를 사용), 런타임은 지정된 위치에 컨테이너 로그를 기록한다.
kubelet 설정 파일을 사용하여
두 개의 kubelet 파라미터
containerLogMaxSize 및 containerLogMaxFiles를 설정 가능하다.
이러한 설정을 통해 각 로그 파일의 최대 크기와 각 컨테이너에 허용되는 최대 파일 수를 각각 구성할 수 있다.
기본 로깅 예제에서와 같이 kubectl logs를
실행하면, 노드의 kubelet이 요청을 처리하고 로그 파일에서 직접 읽는다.
kubelet은 로그 파일의 내용을 반환한다.
참고:
kubectl logs를 통해서는
최신 로그만 확인할 수 있다.
예를 들어, 파드가 40MiB 크기의 로그를 기록했고 kubelet이 10MiB 마다 로그를 로테이트하는 경우
kubectl logs는 최근의 10MiB 데이터만 반환한다.
시스템 컴포넌트 로그
시스템 컴포넌트에는 두 가지 유형이 있는데, 컨테이너에서 실행되는 것과 실행 중인 컨테이너와 관련된 것이다. 예를 들면 다음과 같다.
- kubelet과 컨테이너 런타임은 컨테이너에서 실행되지 않는다. kubelet이 컨테이너(파드와 그룹화된)를 실행시킨다.
- 쿠버네티스의 스케줄러, 컨트롤러 매니저, API 서버는
파드(일반적으로 스태틱 파드)로 실행된다.
etcd는 컨트롤 플레인에서 실행되며, 대부분의 경우 역시 스태틱 파드로써 실행된다.
클러스터가 kube-proxy를 사용하는 경우는
데몬셋(DaemonSet)으로써 실행된다.
로그의 위치
kubelet과 컨테이너 런타임이 로그를 기록하는 방법은, 노드의 운영체제에 따라 다르다.
systemd를 사용하는 시스템에서는 kubelet과 컨테이너 런타임은 기본적으로 로그를 journald에 작성한다.
journalctl을 사용하여 이를 확인할 수 있다.
예를 들어 journalctl -u kubelet.
systemd를 사용하지 않는 시스템에서, kubelet과 컨테이너 런타임은 로그를 /var/log 디렉터리의 .log 파일에 작성한다.
다른 경로에 로그를 기록하고 싶은 경우에는, kube-log-runner를 통해
간접적으로 kubelet을 실행하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
kubelet을 실행할 때 --log-dir 인자를 통해 로그가 저장될 디렉토리를 지정할 수 있다.
그러나 해당 인자는 더 이상 지원되지 않으며(deprecated), kubelet은 항상 컨테이너 런타임으로 하여금
/var/log/pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
kubelet은 기본적으로 C:\var\logs 아래에 로그를 기록한다
(C:\var\log가 아님에 주의한다).
C:\var\log 경로가 쿠버네티스에 설정된 기본값이지만,
몇몇 클러스터 배포 도구들은 윈도우 노드의 로그 경로로 C:\var\log\kubelet를 사용하기도 한다.
다른 경로에 로그를 기록하고 싶은 경우에는, kube-log-runner를 통해
간접적으로 kubelet을 실행하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
그러나, kubelet은 항상 컨테이너 런타임으로 하여금
C:\var\log\pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
파드로 실행되는 쿠버네티스 컴포넌트의 경우,
기본 로깅 메커니즘을 따르지 않고 /var/log 아래에 로그를 기록한다
(즉, 해당 컴포넌트들은 systemd의 journal에 로그를 기록하지 않는다).
쿠버네티스의 저장 메커니즘을 사용하여, 컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
etcd와 etcd의 로그를 기록하는 방식에 대한 자세한 정보는 etcd 공식 문서를 확인한다. 다시 언급하자면, 쿠버네티스의 저장 메커니즘을 사용하여 컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
참고:
스케줄러와 같은 쿠버네티스 클러스터의 컴포넌트를 배포하여 상위 노드에서 공유된 볼륨에 로그를 기록하는 경우, 해당 로그들이 로테이트되는지 확인하고 관리해야 한다. 쿠버네티스는 로그 로테이션을 관리하지 않는다.
몇몇 로그 로테이션은 운영체제가 자동적으로 구현할 수도 있다.
예를 들어, 컴포넌트를 실행하는 스태틱 파드에 /var/log 디렉토리를 공유하여 로그를 기록하면,
노드-레벨 로그 로테이션은 해당 경로의 파일을
쿠버네티스 외부의 다른 컴포넌트들이 기록한 파일과 동일하게 취급한다.
몇몇 배포 도구들은 로그 로테이션을 자동화하지만, 나머지 도구들은 이를 사용자의 책임으로 둔다.
클러스터-레벨 로깅 아키텍처
쿠버네티스는 클러스터-레벨 로깅을 위한 네이티브 솔루션을 제공하지 않지만, 고려해야 할 몇 가지 일반적인 접근 방법을 고려할 수 있다. 여기 몇 가지 옵션이 있다.
- 모든 노드에서 실행되는 노드-레벨 로깅 에이전트를 사용한다.
- 애플리케이션 파드에 로깅을 위한 전용 사이드카 컨테이너를 포함한다.
- 애플리케이션 내에서 로그를 백엔드로 직접 푸시한다.
노드 로깅 에이전트 사용
각 노드에 노드-레벨 로깅 에이전트 를 포함시켜 클러스터-레벨 로깅을 구현할 수 있다. 로깅 에이전트는 로그를 노출하거나 로그를 백엔드로 푸시하는 전용 도구이다. 일반적으로, 로깅 에이전트는 해당 노드의 모든 애플리케이션 컨테이너에서 로그 파일이 있는 디렉터리에 접근할 수 있는 컨테이너이다.
로깅 에이전트는 모든 노드에서 실행되어야 하므로, 에이전트를
DaemonSet 으로 동작시키는 것을 추천한다.
노드-레벨 로깅은 노드별 하나의 에이전트만 생성하며, 노드에서 실행되는 애플리케이션에 대한 변경은 필요로 하지 않는다.
컨테이너는 로그를 stdout과 stderr로 출력하며, 합의된 형식은 없다. 노드-레벨 에이전트는 이러한 로그를 수집하고 취합을 위해 전달한다.
로깅 에이전트와 함께 사이드카 컨테이너 사용
다음 중 한 가지 방법으로 사이드카 컨테이너를 사용할 수 있다.
- 사이드카 컨테이너는 애플리케이션 로그를 자체
stdout으로 스트리밍한다. - 사이드카 컨테이너는 로깅 에이전트를 실행하며, 애플리케이션 컨테이너에서 로그를 가져오도록 구성된다.
사이드카 컨테이너 스트리밍
사이드카 컨테이너가 자체 stdout 및 stderr 스트림으로
기록하도록 하면, 각 노드에서 이미 실행 중인 kubelet과 로깅 에이전트를
활용할 수 있다. 사이드카 컨테이너는 파일, 소켓 또는 journald에서 로그를 읽는다.
각 사이드카 컨테이너는 자체 stdout 또는 stderr 스트림에 로그를 출력한다.
이 방법을 사용하면 애플리케이션의 다른 부분에서 여러 로그 스트림을
분리할 수 있고, 이 중 일부는 stdout 또는 stderr 에
작성하기 위한 지원이 부족할 수 있다. 로그를 리디렉션하는 로직은
최소화되어 있기 때문에, 심각한 오버헤드가 아니다. 또한,
stdout 및 stderr 가 kubelet에서 처리되므로, kubectl logs 와 같은
빌트인 도구를 사용할 수 있다.
예를 들어, 파드는 단일 컨테이너를 실행하고, 컨테이너는 서로 다른 두 가지 형식을 사용하여 서로 다른 두 개의 로그 파일에 기록한다. 다음은 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
두 컴포넌트를 컨테이너의 stdout 스트림으로 리디렉션한 경우에도, 동일한 로그
스트림에 서로 다른 형식의 로그 항목을 작성하는 것은
추천하지 않는다. 대신, 두 개의 사이드카 컨테이너를 생성할 수 있다. 각 사이드카
컨테이너는 공유 볼륨에서 특정 로그 파일을 테일(tail)한 다음 로그를
자체 stdout 스트림으로 리디렉션할 수 있다.
다음은 사이드카 컨테이너가 두 개인 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
이제 이 파드를 실행하면, 다음의 명령을 실행하여 각 로그 스트림에 개별적으로 접근할 수 있다.
kubectl logs counter count-log-1
출력은 다음과 같다.
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
출력은 다음과 같다.
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
클러스터에 노드-레벨 에이전트를 설치했다면, 에이전트는 추가적인 설정 없이도 자동으로 해당 로그 스트림을 선택한다. 원한다면, 소스 컨테이너에 따라 로그 라인을 파싱(parse)하도록 에이전트를 구성할 수도 있다.
CPU 및 메모리 사용량이 낮은(몇 밀리코어 수준의 CPU와 몇 메가바이트 수준의 메모리 요청) 파드라고 할지라도,
로그를 파일에 기록한 다음 stdout 으로 스트리밍하는 것은
노드가 필요로 하는 스토리지 양을 두 배로 늘릴 수 있다.
단일 파일에 로그를 기록하는 애플리케이션이 있는 경우,
일반적으로 스트리밍 사이드카 컨테이너 방식을 구현하는 대신
/dev/stdout 을 대상으로 설정하는 것을 추천한다.
사이드카 컨테이너를 사용하여
애플리케이션 자체에서 로테이션할 수 없는 로그 파일을 로테이션할 수도 있다.
이 방법의 예시는 정기적으로 logrotate 를 실행하는 작은 컨테이너를 두는 것이다.
그러나, stdout 및 stderr 을 직접 사용하고 로테이션과
유지 정책을 kubelet에 두는 것이 더욱 직관적이다.
로깅 에이전트가 있는 사이드카 컨테이너
노드-레벨 로깅 에이전트가 상황에 맞게 충분히 유연하지 않은 경우, 애플리케이션과 함께 실행하도록 특별히 구성된 별도의 로깅 에이전트를 사용하여 사이드카 컨테이너를 생성할 수 있다.
참고:
사이드카 컨테이너에서 로깅 에이전트를 사용하면 상당한 리소스 소비로 이어질 수 있다. 게다가, kubelet에 의해 제어되지 않기 때문에,kubectl logs 를 사용하여 해당 로그에
접근할 수 없다.아래는 로깅 에이전트가 포함된 사이드카 컨테이너를 구현하는 데 사용할 수 있는 두 가지 매니페스트이다.
첫 번째 매니페스트는 fluentd를 구성하는
컨피그맵(ConfigMap)이 포함되어 있다.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
참고:
예제 매니페스트에서, 꼭 fluentd가 아니더라도, 애플리케이션 컨테이너 내의 모든 소스에서 로그를 읽어올 수 있는 다른 로깅 에이전트를 사용할 수 있다.두 번째 매니페스트는 fluentd가 실행되는 사이드카 컨테이너가 있는 파드를 설명한다. 파드는 fluentd가 구성 데이터를 가져올 수 있는 볼륨을 마운트한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
애플리케이션에서 직접 로그 노출
애플리케이션에서 직접 로그를 노출하거나 푸시하는 클러스터-로깅은 쿠버네티스의 범위를 벗어난다.
다음 내용
- 쿠버네티스 시스템 로그 살펴보기.
- 쿠버네티스 시스템 컴포넌트에 대한 추적(trace) 살펴보기.
- 파드가 실패했을 때 쿠버네티스가 어떻게 로그를 남기는지에 대해, 종료 메시지를 사용자가 정의하는 방법 살펴보기.
12.5 - 쿠버네티스 시스템 컴포넌트에 대한 메트릭
시스템 컴포넌트 메트릭으로 내부에서 발생하는 상황을 더 잘 파악할 수 있다. 메트릭은 대시보드와 경고를 만드는 데 특히 유용하다.
쿠버네티스 컴포넌트의 메트릭은 프로메테우스 형식으로 출력된다. 이 형식은 구조화된 평문으로 디자인되어 있으므로 사람과 기계 모두가 쉽게 읽을 수 있다.
쿠버네티스의 메트릭
대부분의 경우 메트릭은 HTTP 서버의 /metrics 엔드포인트에서 사용할 수 있다.
기본적으로 엔드포인트를 노출하지 않는 컴포넌트의 경우 --bind-address 플래그를 사용하여 활성화할 수 있다.
해당 컴포넌트의 예는 다음과 같다.
프로덕션 환경에서는 이러한 메트릭을 주기적으로 수집하고 시계열 데이터베이스에서 사용할 수 있도록 프로메테우스 서버 또는 다른 메트릭 수집기(scraper)를 구성할 수 있다.
참고로 kubelet도
/metrics/cadvisor, /metrics/resource 그리고 /metrics/probes 엔드포인트에서 메트릭을 노출한다.
이러한 메트릭은 동일한 라이프사이클을 가지지 않는다.
클러스터가 RBAC을 사용하는 경우, 메트릭을 읽으려면
/metrics 에 접근을 허용하는 클러스터롤(ClusterRole)을 가지는 사용자, 그룹 또는 서비스어카운트(ServiceAccount)를 통한 권한이 필요하다.
예를 들면, 다음과 같다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
메트릭 라이프사이클
알파(Alpha) 메트릭 → 안정적인(Stable) 메트릭 → 사용 중단된(Deprecated) 메트릭 → 히든(Hidden) 메트릭 → 삭제된(Deleted) 메트릭
알파 메트릭은 안정성을 보장하지 않는다. 따라서 언제든지 수정되거나 삭제될 수 있다.
안정적인 메트릭은 변경되지 않는다는 것을 보장한다. 이것은 다음을 의미한다.
- 사용 중단 표기가 없는 안정적인 메트릭은, 이름이 변경되거나 삭제되지 않는다.
- 안정적인 메트릭의 유형(type)은 수정되지 않는다.
사용 중단된 메트릭은 해당 메트릭이 결국 삭제된다는 것을 나타내지만, 아직은 사용 가능하다는 뜻이다. 이 메트릭은 어느 버전에서부터 사용 중단된 것인지를 표시하는 어노테이션을 포함한다.
예를 들면,
- 사용 중단 이전에는 다음과 같다.
# HELP some_counter this counts things
# TYPE some_counter counter
some_counter 0
- 사용 중단 이후에는 다음과 같다.
# HELP some_counter (Deprecated since 1.15.0) this counts things
# TYPE some_counter counter
some_counter 0
히든 메트릭은 깔끔함(scraping)을 위해 더 이상 게시되지는 않지만, 여전히 사용은 가능하다. 히든 메트릭을 사용하려면, 히든 메트릭 표시 섹션을 참고한다.
삭제된 메트릭은 더 이상 게시되거나 사용할 수 없다.
히든 메트릭 표시
위에서 설명한 것처럼, 관리자는 특정 바이너리의 커맨드 라인 플래그를 통해 히든 메트릭을 활성화할 수 있다. 관리자가 지난 릴리스에서 사용 중단된 메트릭의 마이그레이션을 놓친 경우 관리자를 위한 임시방편으로 사용된다.
show-hidden-metrics-for-version 플래그는 해당 릴리스에서 사용 중단된 메트릭을 보여주려는
버전을 사용한다. 버전은 xy로 표시되며, 여기서 x는 메이저(major) 버전이고,
y는 마이너(minor) 버전이다. 패치 릴리스에서 메트릭이 사용 중단될 수 있지만, 패치 버전은 필요하지 않다.
그 이유는 메트릭 사용 중단 정책이 마이너 릴리스에 대해 실행되기 때문이다.
플래그는 그 값으로 이전의 마이너 버전만 사용할 수 있다. 관리자가 이전 버전을
show-hidden-metrics-for-version 에 설정하면 이전 버전의 모든 히든 메트릭이 생성된다.
사용 중단 메트릭 정책을 위반하기 때문에 너무 오래된 버전은 허용되지 않는다.
1.n 버전에서 사용 중단되었다고 가정한 메트릭 A 를 예로 들어보겠다.
메트릭 사용 중단 정책에 따르면, 다음과 같은 결론에 도달할 수 있다.
1.n릴리스에서는 메트릭이 사용 중단되었으며, 기본적으로 생성될 수 있다.1.n+1릴리스에서는 기본적으로 메트릭이 숨겨져 있으며,show-hidden-metrics-for-version=1.n커맨드 라인에 의해서 생성될 수 있다.1.n+2릴리스에서는 코드베이스에서 메트릭이 제거되어야 한다. 더이상 임시방편은 존재하지 않는다.
릴리스 1.12 에서 1.13 으로 업그레이드 중이지만, 1.12 에서 사용 중단된 메트릭 A 를 사용하고 있다면,
커맨드 라인에서 --show-hidden-metrics=1.12 플래그로 히든 메트릭을 설정해야 하고,
1.14 로 업그레이드하기 전에 이 메트릭을 사용하지 않도록 의존성을 제거하는 것을 기억해야 한다.
액셀러레이터 메트릭 비활성화
kubelet은 cAdvisor를 통해 액셀러레이터 메트릭을 수집한다. 이러한 메트릭을 수집하기 위해, NVIDIA GPU와 같은 액셀러레이터의 경우, kubelet은 드라이버에 열린 핸들을 가진다. 이는 인프라 변경(예: 드라이버 업데이트)을 수행하기 위해, 클러스터 관리자가 kubelet 에이전트를 중지해야 함을 의미한다.
액셀러레이터 메트릭을 수집하는 책임은 이제 kubelet이 아닌 공급 업체에 있다. 공급 업체는 메트릭을 수집하여 메트릭 서비스(예: 프로메테우스)에 노출할 컨테이너를 제공해야 한다.
DisableAcceleratorUsageMetrics 기능 게이트는
이 기능을 기본적으로 사용하도록 설정하는 타임라인를
사용하여 kubelet에서 수집한 메트릭을 비활성화한다.
컴포넌트 메트릭
kube-controller-manager 메트릭
컨트롤러 관리자 메트릭은 컨트롤러 관리자의 성능과 상태에 대한 중요한 인사이트를 제공한다. 이러한 메트릭에는 go_routine 수와 같은 일반적인 Go 언어 런타임 메트릭과 etcd 요청 대기 시간 또는 Cloudprovider(AWS, GCE, OpenStack) API 대기 시간과 같은 컨트롤러 특정 메트릭이 포함되어 클러스터의 상태를 측정하는 데 사용할 수 있다.
쿠버네티스 1.7부터 GCE, AWS, Vsphere 및 OpenStack의 스토리지 운영에 대한 상세한 Cloudprovider 메트릭을 사용할 수 있다. 이 메트릭은 퍼시스턴트 볼륨 동작의 상태를 모니터링하는 데 사용할 수 있다.
예를 들어, GCE의 경우 이러한 메트릭을 다음과 같이 호출한다.
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
kube-scheduler 메트릭
기능 상태:
Kubernetes v1.21 [beta]
스케줄러는 실행 중인 모든 파드의 요청(request)된 리소스와 요구되는 제한(limit)을 보고하는 선택적 메트릭을 노출한다. 이러한 메트릭은 용량 계획(capacity planning) 대시보드를 구축하고, 현재 또는 과거 스케줄링 제한을 평가하고, 리소스 부족으로 스케줄할 수 없는 워크로드를 빠르게 식별하고, 실제 사용량을 파드의 요청과 비교하는 데 사용할 수 있다.
kube-scheduler는 각 파드에 대해 구성된 리소스 요청과 제한을 식별한다. 요청 또는 제한이 0이 아닌 경우 kube-scheduler는 메트릭 시계열을 보고한다. 시계열에는 다음과 같은 레이블이 지정된다.
- 네임스페이스
- 파드 이름
- 파드가 스케줄된 노드 또는 아직 스케줄되지 않은 경우 빈 문자열
- 우선순위
- 해당 파드에 할당된 스케줄러
- 리소스 이름 (예:
cpu) - 알려진 경우 리소스 단위 (예:
cores)
파드가 완료되면 (Never 또는 OnFailure의 restartPolicy가 있고
Succeeded 또는 Failed 파드 단계에 있거나, 삭제되고 모든 컨테이너가 종료된 상태에 있음)
스케줄러가 이제 다른 파드를 실행하도록 스케줄할 수 있으므로 시리즈가 더 이상 보고되지 않는다.
두 메트릭을 kube_pod_resource_request 및 kube_pod_resource_limit 라고 한다.
메트릭은 HTTP 엔드포인트 /metrics/resources에 노출되며
스케줄러의 /metrics 엔드포인트와 동일한 인증이 필요하다.
이러한 알파 수준의 메트릭을 노출시키려면 --show-hidden-metrics-for-version=1.20 플래그를 사용해야 한다.
메트릭 비활성화
커맨드 라인 플래그 --disabled-metrics 를 통해 메트릭을 명시적으로 끌 수 있다.
이 방법이 필요한 이유는 메트릭이 성능 문제를 일으키는 경우을 예로 들 수 있다.
입력값은 비활성화되는 메트릭 목록이다(예: --disabled-metrics=metric1,metric2).
메트릭 카디널리티(cardinality) 적용
제한되지 않은 차원의 메트릭은 계측하는 컴포넌트에서 메모리 문제를 일으킬 수 있다.
리소스 사용을 제한하려면, --allow-label-value 커맨드 라인 옵션을 사용하여
메트릭 항목에 대한 레이블 값의 허용 목록(allow-list)을 동적으로 구성한다.
알파 단계에서, 플래그는 메트릭 레이블 허용 목록으로 일련의 매핑만 가져올 수 있다.
각 매핑은 <metric_name>,<label_name>=<allowed_labels> 형식이다. 여기서
<allowed_labels> 는 허용되는 레이블 이름의 쉼표로 구분된 목록이다.
전체 형식은 다음과 같다.
--allow-label-value <metric_name>,<label_name>='<allow_value1>, <allow_value2>...', <metric_name2>,<label_name>='<allow_value1>, <allow_value2>...', ...
예시는 다음과 같다.
--allow-label-value number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
다음 내용
- 메트릭에 대한 프로메테우스 텍스트 형식 에 대해 읽어본다
- 안정 버전의 쿠버네티스 메트릭 목록을 살펴본다
- 쿠버네티스 사용 중단 정책에 대해 읽어본다
12.6 - 시스템 로그
시스템 컴포넌트 로그는 클러스터에서 발생하는 이벤트를 기록하며, 이는 디버깅에 아주 유용하다. 더 많거나 적은 세부 정보를 표시하도록 다양하게 로그를 설정할 수 있다. 로그는 컴포넌트 내에서 오류를 표시하는 것 처럼 간단하거나, 이벤트의 단계적 추적(예: HTTP 엑세스 로그, 파드의 상태 변경, 컨트롤러 작업 또는 스케줄러의 결정)을 표시하는 것처럼 세밀할 수 있다.
Klog
klog는 쿠버네티스의 로깅 라이브러리다. klog는 쿠버네티스 시스템 컴포넌트의 로그 메시지를 생성한다.
klog 설정에 대한 더 많은 정보는, 커맨드라인 툴을 참고한다.
쿠버네티스는 각 컴포넌트의 로깅을 간소화하는 중에 있다. 다음 klog 명령줄 플래그는 쿠버네티스 1.23에서 사용 중단되었으며 이후 릴리스에서 제거될 것이다.
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
출력은 출력 형식에 관계없이 항상 표준 에러(stderr)에 기록될 것이다. 출력 리다이렉션은 쿠버네티스 컴포넌트를 호출하는 컴포넌트가 담당할 것으로 기대된다. 이는 POSIX 셸 또는 systemd와 같은 도구일 수 있다.
배포판과 무관한(distroless) 컨테이너 또는 윈도우 시스템 서비스와 같은 몇몇 경우에서, 위의 옵션은
사용할 수 없다. 그런 경우
출력을 리다이렉트하기 위해
kube-log-runner
바이너리를 쿠버네티스 컴포넌트의 래퍼(wrapper)로 사용할 수 있다.
미리 빌드된 바이너리가 몇몇 쿠버네티스 베이스 이미지에 기본 이름 /go-runner 와
서버 및 노드 릴리스 아카이브에는 kube-log-runner라는 이름으로 포함되어 있다.
다음 표는 각 kube-log-runner 실행법이 어떤 셸 리다이렉션에 해당되는지 보여준다.
| 사용법 | POSIX 셸 (예:) bash) | kube-log-runner <options> <cmd> |
|---|---|---|
| stderr와 stdout을 합치고, stdout으로 출력 | 2>&1 |
kube-log-runner (기본 동작)) |
| stderr와 stdout을 로그 파일에 기록 | 1>>/tmp/log 2>&1 |
kube-log-runner -log-file=/tmp/log |
| 로그 파일에 기록하면서 stdout으로 출력 | 2>&1 | tee -a /tmp/log |
kube-log-runner -log-file=/tmp/log -also-stdout |
| stdout만 로그 파일에 기록 | >/tmp/log |
kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
Klog 출력
klog 네이티브 형식 예 :
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
메시지 문자열은 줄바꿈을 포함하고 있을 수도 있다.
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
구조화된 로깅
기능 상태:
Kubernetes v1.23 [beta]
경고:
구조화된 로그메시지로 마이그레이션은 진행중인 작업이다. 이 버전에서는 모든 로그 메시지가 구조화되지 않는다. 로그 파일을 파싱할 때, 구조화되지 않은 로그 메시지도 처리해야 한다.
로그 형식 및 값 직렬화는 변경될 수 있다.
구조화된 로깅은 로그 메시지에 유니폼 구조를 적용하여 정보를 쉽게 추출하고, 로그를 보다 쉽고 저렴하게 저장하고 처리하는 작업이다. 로그 메세지를 생성하는 코드는 기존의 구조화되지 않은 klog 출력을 사용 또는 구조화된 로깅을 사용할지 여부를 결정합니다.
구조화된 로그 메시지의 기본 형식은 텍스트이며, 기존 klog와 하위 호환되는 형식이다.
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
예시:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
문자열은 따옴표로 감싸진다. 다른 값들은
%+v로 포맷팅되며, 이로 인해
데이터에 따라 로그 메시지가 다음 줄로 이어질 수 있다.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
컨텍스츄얼 로깅(Contextual Logging)
기능 상태:
Kubernetes v1.24 [alpha]
컨텍스츄얼 로깅은 구조화된 로깅을 기반으로 한다. 컨텍스츄얼 로깅은 주로 개발자가 로깅 호출을 사용하는 방법에 관한 것이다. 해당 개념을 기반으로 하는 코드는 좀 더 유연하며, 컨텍스츄얼 로깅 KEP에 기술된 추가적인 사용 사례를 지원한다.
개발자가 자신의 구성 요소에서
WithValues 또는 WithName과 같은 추가 기능을 사용하는 경우,
로그 항목에는 호출자가 함수로 전달하는 추가 정보가 포함된다.
현재 이 기능은 StructuredLogging 기능 게이트 뒤에 있으며
기본적으로 비활성화되어 있다.
이 기능을 위한 인프라는 구성 요소를 수정하지 않고 1.24에 추가되었다.
component-base/logs/example
명령은 새 로깅 호출을 사용하는 방법과
컨텍스츄얼 로깅을 지원하는 구성 요소가 어떻게 작동하는지 보여준다.
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
runtime 메시지 및 duration="1m0s" 값을 로깅하는
기존 로깅 함수를 수정하지 않고도,
이 함수의 호출자에 의해 example 접두사 및 foo="bar" 문자열이 로그에 추가되었다.
컨텍스츄얼 로깅이 비활성화되어 있으면, WithValues 및 WithName 은 아무 효과가 없으며,
로그 호출은 전역 klog 로거를 통과한다.
따라서 이 추가 정보는 더 이상 로그 출력에 포함되지 않는다.
$ go run . --feature-gates ContextualLogging=false
...
I0404 18:03:31.171945 452150 logger.go:94] "runtime" duration="1m0s"
I0404 18:03:31.171962 452150 logger.go:95] "another runtime" duration="1m0s"
JSON 로그 형식
기능 상태:
Kubernetes v1.19 [alpha]
경고:
JSON 출력은 많은 표준 klog 플래그를 지원하지 않는다. 지원하지 않는 klog 플래그 목록은, 커맨드라인 툴을 참고한다.
모든 로그가 JSON 형식으로 작성되는 것은 아니다(예: 프로세스 시작 중). 로그를 파싱하려는 경우 JSON 형식이 아닌 로그 행을 처리할 수 있는지 확인해야 한다.
필드 이름과 JSON 직렬화는 변경될 수 있다.
--logging-format=json 플래그는 로그 형식을 klog 기본 형식에서 JSON 형식으로 변경한다.
JSON 로그 형식 예시(보기좋게 출력된 형태)는 다음과 같다.
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
특별한 의미가 있는 키:
ts- Unix 시간의 타임스탬프 (필수, 부동 소수점)v- 자세한 정도 (필수, 정수, 기본 값 0)err- 오류 문자열 (선택 사항, 문자열)msg- 메시지 (필수, 문자열)
현재 JSON 형식을 지원하는 컴포넌트 목록:
로그 상세 레벨(verbosity)
-v 플래그로 로그 상세 레벨(verbosity)을 제어한다. 값을 늘리면 기록된 이벤트 수가 증가한다.
값을 줄이면 기록된 이벤트 수가 줄어든다. 로그 상세 레벨(verbosity)를 높이면
점점 덜 심각한 이벤트가 기록된다. 로그 상세 레벨(verbosity)을 0으로 설정하면 중요한 이벤트만 기록된다.
로그 위치
시스템 컴포넌트에는 컨테이너에서 실행되는 것과 컨테이너에서 실행되지 않는 두 가지 유형이 있다. 예를 들면 다음과 같다.
- 쿠버네티스 스케줄러와 kube-proxy는 컨테이너에서 실행된다.
- kubelet과 컨테이너 런타임은 컨테이너에서 실행되지 않는다.
systemd를 사용하는 시스템에서는, kubelet과 컨테이너 런타임은 jounald에 기록한다.
그 외 시스템에서는, /var/log 디렉터리의 .log 파일에 기록한다.
컨테이너 내부의 시스템 컴포넌트들은 기본 로깅 메커니즘을 무시하고,
항상 /var/log 디렉터리의 .log 파일에 기록한다.
컨테이너 로그와 마찬가지로, /var/log 디렉터리의 시스템 컴포넌트 로그들은 로테이트해야 한다.
kube-up.sh 스크립트로 생성된 쿠버네티스 클러스터에서는, logrotate 도구로 로그가 로테이트되도록 설정된다.
logrotate 도구는 로그가 매일 또는 크기가 100MB 보다 클 때 로테이트된다.
다음 내용
- 쿠버네티스 로깅 아키텍처 알아보기
- 구조화된 로깅 알아보기
- 컨텍스츄얼 로깅 알아보기
- klog 플래그 사용 중단 알아보기
- 로깅 심각도(serverity) 규칙 알아보기
12.7 - 쿠버네티스 시스템 컴포넌트에 대한 추적(trace)
기능 상태:
Kubernetes v1.22 [alpha]
시스템 컴포넌트 추적은 클러스터 내에서 수행된 동작들 간의 지연(latency)과 관계(relationship)를 기록한다.
쿠버네티스 컴포넌트들은 OpenTelemetry 프로토콜과 gRPC exporter를 이용하여 추적을 생성하고 OpenTelemetry 수집기를 통해 추적 백엔드(tracing backends)로 라우팅되거나 수집될 수 있다.
추적 수집
추적 수집 및 수집기에 대한 전반적인 가이드는 OpenTelemetry 수집기 시작하기에서 제공한다. 그러나, 쿠버네티스 컴포넌트에 관련된 몇 가지 사항에 대해서는 특별히 살펴볼 필요가 있다.
기본적으로, 쿠버네티스 컴포넌트들은 IANA OpenTelemetry 포트인 4317 포트로 OTLP에 대한 grpc exporter를 이용하여 추적를 내보낸다. 예를 들면, 수집기가 쿠버네티스 컴포넌트에 대해 사이드카(sidecar)로 동작한다면, 다음과 같은 리시버 설정을 통해 스팬(span)을 수집하고 그 로그를 표준 출력(standard output)으로 내보낼 것이다.
receivers:
otlp:
protocols:
grpc:
exporters:
# 이 exporter를 사용자의 백엔드를 위한 exporter로 변경
logging:
logLevel: debug
service:
pipelines:
traces:
receivers: [otlp]
exporters: [logging]
컴포넌트 추적
kube-apiserver 추적
kube-apiserver는 들어오는 HTTP 요청들과 webhook, etcd 로 나가는 요청들, 그리고 재진입 요청들에 대해 span을 생성한다. kube-apiserver는 자주 퍼블릭 엔드포인트로 이용되기 때문에, 들어오는 요청들에 첨부된 추적 컨택스트를 사용하지 않고, 나가는 요청들을 통해 W3C Trace Context를 전파한다.
kube-apiserver 에서의 추적 활성화
추적을 활성화하기 위해서는, kube-apiserve에서 APIServerTracing
기능 게이트를 활성화한다.
또한, kube-apiserver의 추적 설정 파일에
--tracing-config-file=<path-to-config>을 추가한다.
다음은 10000개 요청 당 1개에 대한 span을 기록하는 설정에 대한 예시이고, 이는 기본 OpenTelemetry 엔드포인트를 이용한다.
apiVersion: apiserver.config.k8s.io/v1alpha1
kind: TracingConfiguration
# 기본값
#endpoint: localhost:4317
samplingRatePerMillion: 100
TracingConfiguration 구조체에 대해 더 많은 정보를 얻고 싶다면
API server config API (v1alpha1)를 참고한다.
kubelet 추적
기능 상태:
Kubernetes v1.25 [alpha]
kubelet CRI 인터페이스와 인증된 http 서버는 추적(trace) 스팬(span)을 생성하도록 설정 할수 있다. apiserver와 마찬가지로 해당 엔드포인트 및 샘플링률을 구성할 수 있다. 추적 컨텍스트 전파(trace context propagation)도 구성할 수 있다. 상위 스팬(span)의 샘플링 설정이 항상 적용된다. 제공되는 설정의 샘플링률은 상위가 없는 스팬(span)에 기본 적용된다. 엔드포인트를 구성하지 않고 추적을 활성화로 설정하면, 기본 OpenTelemetry Collector receiver 주소는 "localhost:4317"으로 기본 설정된다.
kubelet tracing 활성화
추적을 활성화하려면 kubelet에서 KubeletTracing
기능 게이트(feature gate)을 활성화한다.
또한 kubelet에서
tracing configuration을 제공한다.
tracing 구성을 참조한다.
다음은 10000개 요청 중 1개에 대하여 스팬(span)을 기록하고, 기본 OpenTelemetry 앤드포인트를 사용하도록 한 kubelet 구성 예시이다.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
# 기본값
#endpoint: localhost:4317
samplingRatePerMillion: 100
안정성
추적의 계측화(tracing instrumentation)는 여전히 활발히 개발되는 중이어서 다양한 형태로 변경될 수 있다. 스팬(span)의 이름, 첨부되는 속성, 계측될 엔드포인트(instrumented endpoints)들 등이 그렇다. 이 속성이 안정화(graduates to stable)되기 전까지는 이전 버전과의 호환성은 보장되지 않는다.
다음 내용
12.8 - 쿠버네티스에서 프락시(Proxy)
이 페이지는 쿠버네티스에서 함께 사용되는 프락시(Proxy)를 설명한다.
프락시
쿠버네티스를 이용할 때에 사용할 수 있는 여러 프락시가 있다.
-
- 사용자의 데스크탑이나 파드 안에서 실행한다.
- 로컬 호스트 주소에서 쿠버네티스의 API 서버로 프락시한다.
- 클라이언트로 프락시는 HTTP를 사용한다.
- API 서버로 프락시는 HTTPS를 사용한다.
- API 서버를 찾는다.
- 인증 헤더를 추가한다.
-
- API 서버에 내장된 요새(bastion)이다.
- 클러스터 외부의 사용자가 도달할 수 없는 클러스터 IP 주소로 연결한다.
- API 서버 프로세스에서 실행한다.
- 클라이언트로 프락시는 HTTPS(또는 API서버에서 HTTP로 구성된 경우는 HTTP)를 사용한다.
- 사용 가능한 정보를 이용하여 프락시에 의해 선택한 HTTP나 HTTPS를 사용할 수 있는 대상이다.
- 노드, 파드, 서비스에 도달하는데 사용할 수 있다.
- 서비스에 도달할 때에는 로드 밸런싱을 수행한다.
-
- 각 노드에서 실행한다.
- UDP, TCP, SCTP를 이용하여 프락시 한다.
- HTTP는 이해하지 못한다.
- 로드 밸런싱을 제공한다.
- 서비스에 도달하는데만 사용한다.
-
API 서버 앞단의 프락시/로드밸런서
- 존재 및 구현은 클러스터 마다 다르다. (예: nginx)
- 모든 클라이언트와 하나 이상의 API 서버에 위치한다.
- 여러 API 서버가 있는 경우 로드 밸런서로서 작동한다.
-
외부 서비스의 클라우드 로드 밸런서
- 일부 클라우드 제공자는 제공한다. (예: AWS ELB, 구글 클라우드 로드 밸런서)
- 쿠버네티스 서비스로
LoadBalancer유형이 있으면 자동으로 생성된다. - 일반적으로 UDP/TCP만 지원한다.
- SCTP 지원은 클라우드 제공자의 구현에 달려 있다.
- 구현은 클라우드 제공자에 따라 다양하다.
쿠버네티스 사용자는 보통 처음 두 가지 유형 외의 것은 걱정할 필요없다. 클러스터 관리자는 일반적으로 후자의 유형이 올바르게 구성되었는지 확인한다.
요청을 리다이렉트하기
프락시는 리다이렉트 기능을 대체했다. 리다이렉트는 더 이상 사용하지 않는다.
12.9 - 애드온 설치
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
애드온은 쿠버네티스의 기능을 확장한다.
이 페이지는 사용 가능한 일부 애드온과 관련 설치 지침 링크를 나열한다. 이 목차에서 전체를 다루지는 않는다.
네트워킹과 네트워크 폴리시
- ACI는 Cisco ACI로 통합 컨테이너 네트워킹 및 네트워크 보안을 제공한다.
- Antrea는 레이어 3/4에서 작동하여 쿠버네티스를 위한 네트워킹 및 보안 서비스를 제공하며, Open vSwitch를 네트워킹 데이터 플레인으로 활용한다.
- Calico는 네트워킹 및 네트워크 폴리시 제공자이다. Calico는 유연한 네트워킹 옵션을 지원하므로 BGP 유무에 관계없이 비-오버레이 및 오버레이 네트워크를 포함하여 가장 상황에 맞는 옵션을 선택할 수 있다. Calico는 동일한 엔진을 사용하여 서비스 메시 계층(service mesh layer)에서 호스트, 파드 및 (이스티오(istio)와 Envoy를 사용하는 경우) 애플리케이션에 대한 네트워크 폴리시를 적용한다.
- Canal은 Flannel과 Calico를 통합하여 네트워킹 및 네트워크 폴리시를 제공한다.
- Cilium은 네트워킹, 관측 용의성(Observability), 보안 특징을 지닌 eBPF 기반 데이터 플레인을 갖춘 솔루션입니다. Cilium은 기본 라우팅 및 오버레이/캡슐화 모드를 모두 지원하며, 여러 클러스터를 포괄할 수 있는 단순한 플랫(flat) Layer 3 네트워크를 제공합니다. 또한, Cilium은 (네트워크 주소 지정 방식에서 분리된) 신원 기반 보안 모델(identity-based security model)을 사용하여 L3-L7에서 네트워크 정책을 시행할 수 있습니다. Cilium은 kube-proxy를 대체하는 역할을 할 수 있습니다. 또한 부가적으로, 옵트인(opt-in) 형태로 관측 용의성(Observability) 및 보안 기능을 제공합니다.
- CNI-Genie를 사용하면 쿠버네티스는 Calico, Canal, Flannel, Romana 또는 Weave와 같은 CNI 플러그인을 완벽하게 연결할 수 있다.
- Contiv는 다양한 유스케이스와 풍부한 폴리시 프레임워크를 위해 구성 가능한 네트워킹(BGP를 사용하는 네이티브 L3, vxlan을 사용하는 오버레이, 클래식 L2 그리고 Cisco-SDN/ACI)을 제공한다. Contiv 프로젝트는 완전히 오픈소스이다. 인스톨러는 kubeadm을 이용하거나, 그렇지 않은 경우에 대해서도 설치 옵션을 모두 제공한다.
- Contrail은 Tungsten Fabric을 기반으로 하며, 오픈소스이고, 멀티 클라우드 네트워크 가상화 및 폴리시 관리 플랫폼이다. Contrail과 Tungsten Fabric은 쿠버네티스, OpenShift, OpenStack 및 Mesos와 같은 오케스트레이션 시스템과 통합되어 있으며, 가상 머신, 컨테이너/파드 및 베어 메탈 워크로드에 대한 격리 모드를 제공한다.
- Flannel은 쿠버네티스와 함께 사용할 수 있는 오버레이 네트워크 제공자이다.
- Knitter는 쿠버네티스 파드에서 여러 네트워크 인터페이스를 지원하는 플러그인이다.
- Multus는 쿠버네티스의 다중 네트워크 지원을 위한 멀티 플러그인이며, 모든 CNI 플러그인(예: Calico, Cilium, Contiv, Flannel)과 쿠버네티스 상의 SRIOV, DPDK, OVS-DPDK 및 VPP 기반 워크로드를 지원한다.
- OVN-Kubernetes는 Open vSwitch(OVS) 프로젝트에서 나온 가상 네트워킹 구현인 OVN(Open Virtual Network)을 기반으로 하는 쿠버네티스용 네트워킹 제공자이다. OVN-Kubernetes는 OVS 기반 로드 밸런싱과 네트워크 폴리시 구현을 포함하여 쿠버네티스용 오버레이 기반 네트워킹 구현을 제공한다.
- Nodus는 클라우드 네이티브 기반 서비스 기능 체인(SFC)을 제공하는 OVN 기반 CNI 컨트롤러 플러그인이다.
- NSX-T 컨테이너 플러그인(NCP)은 VMware NSX-T와 쿠버네티스와 같은 컨테이너 오케스트레이터 간의 통합은 물론 NSX-T와 PKS(Pivotal 컨테이너 서비스) 및 OpenShift와 같은 컨테이너 기반 CaaS/PaaS 플랫폼 간의 통합을 제공한다.
- Nuage는 가시성과 보안 모니터링 기능을 통해 쿠버네티스 파드와 비-쿠버네티스 환경 간에 폴리시 기반 네트워킹을 제공하는 SDN 플랫폼이다.
- Romana는 네트워크폴리시 API도 지원하는 파드 네트워크용 Layer 3 네트워킹 솔루션이다.
- Weave Net은 네트워킹 및 네트워크 폴리시를 제공하고, 네트워크 파티션의 양면에서 작업을 수행하며, 외부 데이터베이스는 필요하지 않다.
서비스 검색
시각화 & 제어
- 대시보드는 쿠버네티스를 위한 대시보드 웹 인터페이스이다.
인프라스트럭처
- KubeVirt는 쿠버네티스에서 가상 머신을 실행하기 위한 애드온이다. 일반적으로 베어 메탈 클러스터에서 실행한다.
- node problem detector는 리눅스 노드에서 실행되며, 시스템 이슈를 이벤트 또는 노드 컨디션 형태로 보고한다.
레거시 애드온
더 이상 사용되지 않는 cluster/addons 디렉터리에 다른 여러 애드온이 문서화되어 있다.
잘 관리된 것들이 여기에 연결되어 있어야 한다. PR을 환영한다!
13 - 쿠버네티스 확장
쿠버네티스 클러스터의 동작을 변경하는 다양한 방법
쿠버네티스는 매우 유연하게 구성할 수 있고 확장 가능하다. 결과적으로 쿠버네티스 프로젝트를 포크하거나 코드에 패치를 제출할 필요가 거의 없다.
이 가이드는 쿠버네티스 클러스터를 사용자 정의하기 위한 옵션을 설명한다. 쿠버네티스 클러스터를 업무 환경의 요구에 맞게 조정하는 방법을 이해하려는 클러스터 운영자를 대상으로 한다. 잠재적인 플랫폼 개발자 또는 쿠버네티스 프로젝트 컨트리뷰터인 개발자에게도 어떤 익스텐션(extension) 포인트와 패턴이 있는지, 그리고 그것의 트레이드오프와 제약을 이해하는 데 도움이 될 것이다.
사용자 정의 방식은 크게 플래그, 로컬 구성 파일 또는 API 리소스 변경만 포함하는 구성과 추가적인 프로그램, 추가적인 네트워크 서비스, 또는 둘 다의 실행을 요구하는 익스텐션으로 나눌 수 있다. 이 문서는 주로 익스텐션 에 관한 것이다.
구성
구성 파일 및 명령행 인자 는 온라인 문서의 레퍼런스 섹션에 각 바이너리 별로 문서화되어 있다.
호스팅된 쿠버네티스 서비스 또는 매니지드 설치 환경의 배포판에서 명령행 인자 및 구성 파일을 항상 변경할 수 있는 것은 아니다. 변경 가능하더라도 일반적으로 클러스터 오퍼레이터를 통해서만 변경될 수 있다. 또한 향후 쿠버네티스 버전에서 변경될 수 있으며, 이를 설정하려면 프로세스를 다시 시작해야 할 수도 있다. 이러한 이유로 다른 옵션이 없는 경우에만 사용해야 한다.
리소스쿼터, 네트워크폴리시 및 역할 기반 접근 제어(RBAC)와 같은 빌트인 정책 API(Policy API) 는 선언적으로 구성된 정책 설정을 제공하는 내장 쿠버네티스 API이다. API는 일반적으로 호스팅된 쿠버네티스 서비스 및 매니지드 쿠버네티스 설치 환경과 함께 사용할 수도 있다. 빌트인 정책 API는 파드와 같은 다른 쿠버네티스 리소스와 동일한 규칙을 따른다. 안정적인 정책 API를 사용하는 경우 다른 쿠버네티스 API와 같이 정의된 지원 정책의 혜택을 볼 수 있다. 이러한 이유로 인해 적절한 상황에서는 정책 API는 구성 파일 과 명령행 인자 보다 권장된다.
익스텐션
익스텐션은 쿠버네티스를 확장하고 쿠버네티스와 긴밀하게 통합되는 소프트웨어 컴포넌트이다. 이들 컴포넌트는 쿠버네티스가 새로운 유형과 새로운 종류의 하드웨어를 지원할 수 있게 해준다.
많은 클러스터 관리자가 호스팅 또는 배포판 쿠버네티스 인스턴스를 사용한다. 이러한 클러스터들은 미리 설치된 익스텐션을 포함한다. 결과적으로 대부분의 쿠버네티스 사용자는 익스텐션을 설치할 필요가 없고, 새로운 익스텐션을 만들 필요가 있는 사용자는 더 적다.
익스텐션 패턴
쿠버네티스는 클라이언트 프로그램을 작성하여 자동화 되도록 설계되었다. 쿠버네티스 API를 읽고 쓰는 프로그램은 유용한 자동화를 제공할 수 있다. 자동화 는 클러스터 상에서 또는 클러스터 밖에서 실행할 수 있다. 이 문서의 지침에 따라 고가용성과 강력한 자동화를 작성할 수 있다. 자동화는 일반적으로 호스트 클러스터 및 매니지드 설치 환경을 포함한 모든 쿠버네티스 클러스터에서 작동한다.
쿠버네티스와 잘 작동하는 클라이언트 프로그램을 작성하기 위한 특정 패턴은
컨트롤러 패턴이라고 한다.
컨트롤러는 일반적으로 오브젝트의 .spec을 읽고, 가능한 경우 수행한 다음
오브젝트의 .status를 업데이트 한다.
컨트롤러는 쿠버네티스 API의 클라이언트이다. 쿠버네티스가 클라이언트이고 원격 서비스를 호출할 때, 쿠버네티스는 이를 웹훅(Webhook) 이라고 한다. 원격 서비스는 웹훅 백엔드 라고 한다. 커스텀 컨트롤러와 마찬가지로 웹훅은 새로운 장애 지점이 된다.
참고:
쿠버네티스와 별개로 "웹훅"이라는 용어는 일반적으로 비동기 알림 메커니즘을 의미한다. 이때 웹훅 호출은 다른 시스템 혹은 컴포넌트로 보내지는 단방향적인 알림의 역할을 수행한다. 쿠버네티스 생태계에서는 동기적인 HTTP 호출도 "웹훅"이라고 불린다.웹훅 모델에서 쿠버네티스는 원격 서비스에 네트워크 요청을 한다. 그 대안인 바이너리 플러그인 모델에서는 쿠버네티스에서 바이너리(프로그램)를 실행한다. 바이너리 플러그인은 kubelet(예: CSI 스토리지 플러그인과 CNI 네트워크 플러그인) 및 kubectl에서 사용된다. (플러그인으로 kubectl 확장을 참고하자.)
익스텐션 포인트
이 다이어그램은 쿠버네티스 클러스터의 익스텐션 포인트와 그에 접근하는 클라이언트를 보여준다.
쿠버네티스 익스텐션 포인트
그림의 핵심
-
사용자는 종종
kubectl을 사용하여 쿠버네티스 API와 상호 작용한다. 플러그인을 통해 클라이언트의 행동을 커스터마이징할 수 있다. 다양한 클라이언트들에 적용될 수 있는 일반적인 익스텐션도 있으며,kubectl을 확장하기 위한 구체적인 방법도 존재한다. -
apiserver는 모든 요청을 처리한다. apiserver의 여러 유형의 익스텐션 포인트는 요청을 인증하거나, 콘텐츠를 기반으로 요청을 차단하거나, 콘텐츠를 편집하고, 삭제 처리를 허용한다. 이 내용은 API 접근 익스텐션 섹션에 설명되어 있다.
-
apiserver는 다양한 종류의 리소스 를 제공한다.
pod와 같은 빌트인 리소스 종류 는 쿠버네티스 프로젝트에 의해 정의되며 변경할 수 없다. 쿠버네티스 API를 확장하는 것에 대한 내용은 API 익스텐션에 설명되어 있다. -
쿠버네티스 스케줄러는 파드를 어느 노드에 배치할지 결정한다. 스케줄링을 확장하는 몇 가지 방법이 있으며, 이는 스케줄링 익스텐션 섹션에 설명되어 있다.
-
쿠버네티스의 많은 동작은 API-Server의 클라이언트인 컨트롤러라는 프로그램으로 구현된다. 컨트롤러는 종종 커스텀 리소스와 함께 사용된다. 새로운 API와 자동화의 결합과 빌트인 리소스 변경에 설명되어 있다.
-
kubelet은 서버(노드)에서 실행되며 파드가 클러스터 네트워크에서 자체 IP를 가진 가상 서버처럼 보이도록 한다. 네트워크 플러그인을 사용하면 다양한 파드 네트워킹 구현이 가능하다.
-
장치 플러그인을 사용하여 커스텀 하드웨어나 노드에 설치된 특수한 장치와 통합하고, 클러스터에서 실행 중인 파드에서 사용 가능하도록 할 수 있다. kubelet을 통해 장치 플러그인를 조작할 수 있다.
kubelet은 컨테이너의 볼륨을 마운트 및 마운트 해제한다. 스토리지 플러그인을 사용하여 새로운 종류의 스토리지와 다른 볼륨 타입에 대한 지원을 추가할 수 있다.
익스텐션 포인트 선택 순서도
어디서부터 시작해야 할지 모르겠다면, 이 순서도가 도움이 될 수 있다. 일부 솔루션에는 여러 유형의 익스텐션이 포함될 수 있다.

익스텐션 방법 선택을 가이드하기 위한 순서도
클라이언트 익스텐션
kubectl을 위한 플러그인은 별도의 바이너리로 특정한 하위 명령어를 추가하거나 변경해준다.
또한 kubectl 은 자격증명 플러그인과 통합될 수도 있다.
이러한 익스텐션은 개별 사용자의 로컬 환경에만 영향을 주기 때문에 거시적인 정책을 강제할 수 없다.
kubectl 자체를 확장하는 방법은 플러그인으로 kubectl 확장에 설명되어 있다.
API 익스텐션
커스텀 리소스 데피니션
새 컨트롤러, 애플리케이션 구성 오브젝트 또는 기타 선언적 API를 정의하고
kubectl 과 같은 쿠버네티스 도구를 사용하여 관리하려면
쿠버네티스에 커스텀 리소스 를 추가하자.
커스텀 리소스에 대한 자세한 내용은
커스텀 리소스 개념 가이드를 참고하길 바란다.
API 애그리게이션 레이어
쿠버네티스의 API 애그리게이션 레이어를 사용하면 메트릭 등을 목적으로 쿠버네티스 API를 추가적인 서비스와 통합할 수 있다.
새로운 API와 자동화의 결합
사용자 정의 리소스 API와 컨트롤 루프의 조합을 컨트롤러 패턴이라고 한다. 만약 컨트롤러가 의도한 상태에 따라 인프라스트럭쳐를 배포하는 인간 오퍼레이터의 역할을 대신하고 있다면, 컨트롤러는 오퍼레이터 패턴을 따르고 있을지도 모른다. 오퍼레이터 패턴은 특정 애플리케이션을 관리하는 데 사용된다. 주로 이러한 애플리케이션들은 상태를 지니며 상태를 어떻게 관리해야 하는지에 관한 주의를 요한다.
또한 스토리지와 같은 다른 리소스를 관리하거나 접근 제어 제한 등의 정책을 정의하기 위해 커스텀 API와 제어 루프를 만드는 것도 가능하다.
빌트인 리소스 변경
사용자 정의 리소스를 추가하여 쿠버네티스 API를 확장하면 추가된 리소스는 항상 새로운 API 그룹에 속한다. 기존 API 그룹을 바꾸거나 변경할 수 없다.
API를 추가해도 기존 API(예: 파드)의 동작에 직접 영향을 미치지는 않지만 API 접근 익스텐션 은 영향을 준다.
API 접근 익스텐션
요청이 쿠버네티스 API 서버에 도달하면 먼저 인증 이 되고, 그런 다음 인가 된 후 다양한 유형의 어드미션 컨트롤 을 거치게 된다. (사실, 일부 요청은 인증되지 않고 특별한 과정을 거친다.) 이 흐름에 대한 자세한 내용은 쿠버네티스 API에 대한 접근 제어를 참고하길 바란다.
쿠버네티스의 인증/인가 흐름의 각 단계는 익스텐션 포인트를 제공한다.
인증
인증은 모든 요청의 헤더 또는 인증서를 요청하는 클라이언트의 사용자 이름에 매핑한다.
쿠버네티스는 몇 가지 빌트인 인증 방법을 지원한다.
이러한 방법이 사용자 요구 사항을 충족시키지 못한다면
인증 프록시 뒤에 위치하면서 Authorization: 헤더로 받은 토큰을 원격 서비스로 보내 검증받는
방법(인증 웹훅)도 존재하므로, 참고하길 바란다.
인가
인가는 특정 사용자가 API 리소스에서 읽고, 쓰고, 다른 작업을 수행할 수 있는지를 결정한다. 전체 리소스 레벨에서 작동하며 임의의 오브젝트 필드를 기준으로 구별하지 않는다.
빌트인 인증 옵션이 사용자의 요구를 충족시키지 못하면 인가 웹훅을 통해 사용자가 제공한 코드를 호출하여 인증 결정을 내릴 수 있다.
동적 어드미션 컨트롤
요청이 승인된 후, 쓰기 작업인 경우 어드미션 컨트롤 단계도 수행된다. 빌트인 단계 외에도 몇 가지 익스텐션이 있다.
- 이미지 정책 웹훅은 컨테이너에서 실행할 수 있는 이미지를 제한한다.
- 임의의 어드미션 컨트롤 결정을 내리기 위해 일반적인 어드미션 웹훅을 사용할 수 있다. 어드미션 웹훅은 생성 또는 업데이트를 거부할 수 있다. 어떤 어드미션 웹훅은 쿠버네티스에 의해 처리되기 전에 들어오는 요청의 데이터에 변경을 가할 수도 있다.
인프라스트럭처 익스텐션
장치 플러그인
장치 플러그인 은 노드가 장치 플러그인을 통해 (CPU 및 메모리와 같은 빌트인 자원 외에 추가적으로) 새로운 노드 리소스를 발견할 수 있게 해준다.
스토리지 플러그인
컨테이너 스토리지 인터페이스 (CSI) 플러그인은 새로운 종류의 볼륨을 지원하도록 쿠버네티스를 확장할 수 있게 해준다. 볼륨은 내구성 높은 외부 스토리지에 연결되거나, 일시적인 스토리지를 제공하거나, 파일시스템 패러다임을 토대로 정보에 대한 읽기 전용 인터페이스를 제공할 수도 있다.
또한 쿠버네티스는 (CSI를 권장하며) v1.23부터 사용 중단된 FlexVolume 플러그인에 대한 지원도 포함한다.
FlexVolume 플러그인은 쿠버네티스에서 네이티브하게 지원하지 않는 볼륨 종류도 마운트할 수 있도록 해준다. FlexVolume 스토리지에 의존하는 파드를 실행하는 경우 kubelet은 바이너리 플러그인을 호출하여 볼륨을 마운트한다. 아카이브된 FlexVolume 디자인 제안은 이러한 접근방법에 대한 자세한 설명을 포함하고 있다.
스토리지 플러그인에 대한 전반적인 정보는 스토리지 업체를 위한 쿠버네티스 볼륨 플러그인 FAQ에서 찾을 수 있다.
네트워크 플러그인
제대로 동작하는 파드 네트워크와 쿠버네티스 네트워크 모델의 다양한 측면을 지원하기 위해 쿠버네티스 클러스터는 네트워크 플러그인 을 필요로 한다.
네트워크 플러그인을 통해 쿠버네티스는 다양한 네트워크 토폴로지 및 기술을 활용할 수 있게 된다.
스케줄링 익스텐션
스케줄러는 파드를 감시하고 파드를 노드에 할당하는 특수한 유형의 컨트롤러이다. 다른 쿠버네티스 컴포넌트를 계속 사용하면서 기본 스케줄러를 완전히 교체하거나, 여러 스케줄러를 동시에 실행할 수 있다.
이것은 중요한 부분이며, 거의 모든 쿠버네티스 사용자는 스케줄러를 수정할 필요가 없다는 것을 알게 된다.
어떤 스케줄링 플러그인을 활성화시킬지 제어하거나, 플러그인들을 다른 이름의 스케줄러 프로파일과 연결지을 수도 있다. kube-scheduler의 익스텐션 포인트 중 하나 이상과 통합되는 플러그인을 직접 작성할 수도 있다.
마지막으로 빌트인 kube-scheduler 컴포넌트는 원격 HTTP 백엔드 (스케줄러 익스텐션)에서
kube-scheduler가 파드를 위해 선택한 노드를
필터링하고 우선하도록 지정할 수 있도록 하는
웹훅을 지원한다.
참고:
노드 필터링과 노트 우선순위에 영향을 미치는 것은 스케줄러 인스텐션 웹훅을 통해서만 가능하다. 다른 익스텐션 포인트는 웹훅 통합으로 제공되지 않는다.다음 내용
- 인프라스트럭처 익스텐션에 대해 더 알아보기
- kubectl 플러그인에 대해 알아보기
- 커스텀 리소스에 대해 더 알아보기
- 익스텐션 API 서버에 대해 알아보기
- 동적 어드미션 컨트롤에 대해 알아보기
- 오퍼레이터 패턴에 대해 알아보기
13.1 - 오퍼레이터(operator) 패턴
오퍼레이터(Operator)는 사용자 정의 리소스를 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션이다. 오퍼레이터는 쿠버네티스 원칙, 특히 컨트롤 루프를 따른다.
동기 부여
오퍼레이터 패턴 은 서비스 또는 서비스 셋을 관리하는 운영자의 주요 목표를 포착하는 것을 목표로 한다. 특정 애플리케이션 및 서비스를 돌보는 운영자는 시스템의 작동 방식, 배포 방법 및 문제가 있는 경우 대처 방법에 대해 깊이 알고 있다.
쿠버네티스에서 워크로드를 실행하는 사람들은 종종 반복 가능한 작업을 처리하기 위해 자동화를 사용하는 것을 좋아한다. 오퍼레이터 패턴은 쿠버네티스 자체가 제공하는 것 이상의 작업을 자동화하기 위해 코드를 작성하는 방법을 포착한다.
쿠버네티스의 오퍼레이터
쿠버네티스는 자동화를 위해 설계되었다. 기본적으로 쿠버네티스의 중추를 통해 많은 빌트인 자동화 기능을 사용할 수 있다. 쿠버네티스를 사용하여 워크로드 배포 및 실행을 자동화할 수 있고, 또한 쿠버네티스가 수행하는 방식을 자동화할 수 있다.
쿠버네티스의 오퍼레이터 패턴 개념을 통해 쿠버네티스 코드 자체를 수정하지 않고도 컨트롤러를 하나 이상의 사용자 정의 리소스(custom resource)에 연결하여 클러스터의 동작을 확장할 수 있다. 오퍼레이터는 사용자 정의 리소스의 컨트롤러 역할을 하는 쿠버네티스 API의 클라이언트다.
오퍼레이터 예시
오퍼레이터를 사용하여 자동화할 수 있는 몇 가지 사항은 다음과 같다.
- 주문형 애플리케이션 배포
- 해당 애플리케이션의 상태를 백업하고 복원
- 데이터베이스 스키마 또는 추가 구성 설정과 같은 관련 변경 사항에 따른 애플리케이션 코드 업그레이드 처리
- 쿠버네티스 API를 지원하지 않는 애플리케이션에 서비스를 게시하여 검색을 지원
- 클러스터의 전체 또는 일부에서 장애를 시뮬레이션하여 가용성 테스트
- 내부 멤버 선출 절차없이 분산 애플리케이션의 리더를 선택
오퍼레이터의 모습을 더 자세하게 볼 수 있는 방법은 무엇인가? 예시는 다음과 같다.
- 클러스터에 구성할 수 있는 SampleDB라는 사용자 정의 리소스.
- 오퍼레이터의 컨트롤러 부분이 포함된 파드의 실행을 보장하는 디플로이먼트.
- 오퍼레이터 코드의 컨테이너 이미지.
- 컨트롤 플레인을 쿼리하여 어떤 SampleDB 리소스가 구성되어 있는지 알아내는 컨트롤러 코드.
- 오퍼레이터의 핵심은 API 서버에 구성된 리소스와 현재 상태를
일치시키는 방법을 알려주는 코드이다.
- 새 SampleDB를 추가하면 오퍼레이터는 퍼시스턴트볼륨클레임을 설정하여 내구성있는 데이터베이스 스토리지, SampleDB를 실행하는 스테이트풀셋 및 초기 구성을 처리하는 잡을 제공한다.
- SampleDB를 삭제하면 오퍼레이터는 스냅샷을 생성한 다음 스테이트풀셋과 볼륨도 제거되었는지 확인한다.
- 오퍼레이터는 정기적인 데이터베이스 백업도 관리한다. 오퍼레이터는 각 SampleDB 리소스에 대해 데이터베이스에 연결하고 백업을 수행할 수 있는 파드를 생성하는 시기를 결정한다. 이 파드는 데이터베이스 연결 세부 정보 및 자격 증명이 있는 컨피그맵 및 / 또는 시크릿에 의존한다.
- 오퍼레이터는 관리하는 리소스에 견고한 자동화를 제공하는 것을 목표로 하기 때문에 추가 지원 코드가 있다. 이 예제에서 코드는 데이터베이스가 이전 버전을 실행 중인지 확인하고, 업그레이드된 경우 이를 업그레이드하는 잡 오브젝트를 생성한다.
오퍼레이터 배포
오퍼레이터를 배포하는 가장 일반적인 방법은 커스텀 리소스 데피니션의 정의 및 연관된 컨트롤러를 클러스터에 추가하는 것이다. 컨테이너화된 애플리케이션을 실행하는 것처럼 컨트롤러는 일반적으로 컨트롤 플레인 외부에서 실행된다. 예를 들어 클러스터에서 컨트롤러를 디플로이먼트로 실행할 수 있다.
오퍼레이터 사용
오퍼레이터가 배포되면 오퍼레이터가 사용하는 리소스의 종류를 추가, 수정 또는 삭제하여 사용한다. 위의 예에 따라 오퍼레이터 자체에 대한 디플로이먼트를 설정한 후 다음을 수행한다.
kubectl get SampleDB # 구성된 데이터베이스 찾기
kubectl edit SampleDB/example-database # 일부 설정을 수동으로 변경하기
…이것으로 끝이다! 오퍼레이터는 변경 사항을 적용하고 기존 서비스를 양호한 상태로 유지한다.
자신만의 오퍼레이터 작성
에코시스템에 원하는 동작을 구현하는 오퍼레이터가 없다면 직접 코딩할 수 있다.
또한 쿠버네티스 API의 클라이언트 역할을 할 수 있는 모든 언어 / 런타임을 사용하여 오퍼레이터(즉, 컨트롤러)를 구현한다.
다음은 클라우드 네이티브 오퍼레이터를 작성하는 데 사용할 수 있는 몇 가지 라이브러리와 도구들이다.
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
- Charmed Operator Framework
- Java Operator SDK
- Kopf (Kubernetes Operator Pythonic Framework)
- kube-rs (Rust)
- kubebuilder 사용하기
- KubeOps (.NET 오퍼레이터 SDK)
- 웹훅(WebHook)과 함께 Metacontroller를 사용하여 직접 구현하기
- 오퍼레이터 프레임워크
- shell-operator
다음 내용
- CNCF 오퍼레이터 백서 읽어보기
- 사용자 정의 리소스에 대해 더 알아보기
- OperatorHub.io에서 유스케이스에 맞는 이미 만들어진 오퍼레이터 찾기
- 다른 사람들이 사용할 수 있도록 자신의 오퍼레이터를 게시하기
- 오퍼레이터 패턴을 소개한 CoreOS 원본 글 읽기 (이 링크는 원본 글에 대한 보관 버전임)
- 오퍼레이터 구축을 위한 모범 사례에 대한 구글 클라우드(Google Cloud)의 기사 읽기
13.2 - 컴퓨트, 스토리지 및 네트워킹 익스텐션
해당 섹션은 쿠버네티스 자체에 포함되어있지 않지만 클러스터에 설정할 수 있는 익스텐션들에 대해 다룬다. 이러한 익스텐션을 활용하여 클러스터의 노드를 향상시키거나, 파드들을 연결시키는 네트워크 장치를 제공할 수 있다.
-
CSI 와 FlexVolume 스토리지 플러그인
컨테이너 스토리지 인터페이스 (CSI) 플러그인은 새로운 종류의 볼륨을 지원하도록 쿠버네티스를 확장할 수 있게 해준다. 볼륨은 내구성 높은 외부 스토리지에 연결되거나, 일시적인 스토리지를 제공하거나, 파일시스템 패러다임을 토대로 정보에 대한 읽기 전용 인터페이스를 제공할 수도 있다.
또한 쿠버네티스는 (CSI를 권장하며) v1.23부터 사용 중단된 FlexVolume 플러그인에 대한 지원도 포함한다.
FlexVolume 플러그인은 쿠버네티스에서 네이티브하게 지원하지 않는 볼륨 종류도 마운트할 수 있도록 해준다. FlexVolume 스토리지에 의존하는 파드를 실행하는 경우 kubelet은 바이너리 플러그인을 호출하여 볼륨을 마운트한다. 아카이브된 FlexVolume 디자인 제안은 이러한 접근방법에 대한 자세한 설명을 포함하고 있다.
스토리지 플러그인에 대한 전반적인 정보는 스토리지 업체를 위한 쿠버네티스 볼륨 플러그인 FAQ에서 찾을 수 있다.
-
장치 플러그인은 노드에서 (
cpu와memory와 같은 내장 노드 리소스에서 추가로) 새로운 노드 장치(Node facility)를 발견할 수 있게 해주며, 이러한 커스텀 노드 장치를 요청하는 파드들에게 이를 제공한다. -
네트워크 플러그인을 통해 쿠버네티스는 다양한 네트워크 토폴로지 및 기술을 활용할 수 있게 된다. 제대로 동작하는 파드 네트워크을 구성하고 쿠버네티스 네트워크 모델의 다양한 측면을 지원하기 위해 쿠버네티스 클러스터는 네트워크 플러그인을 필요로 한다.
쿠버네티스 1.31은 CNI 네트워크 플러그인들에 호환된다.
13.2.1 - 네트워크 플러그인
쿠버네티스 1.31 버전은 클러스터 네트워킹을 위해 컨테이너 네트워크 인터페이스(CNI) 플러그인을 지원한다. 사용 중인 클러스터와 호환되며 사용자의 요구 사항을 충족하는 CNI 플러그인을 사용해야 한다. 더 넓은 쿠버네티스 생태계에 다양한 플러그인이 (오픈소스와 클로즈드 소스로) 존재한다.
CNI 플러그인은 쿠버네티스 네트워크 모델을 구현해야 한다.
v0.4.0 이상의 CNI 스펙과 호환되는 CNI 플러그인을 사용해야 한다. 쿠버네티스 플러그인은 CNI 스펙 v1.0.0과 호환되는 플러그인의 사용을 권장한다(플러그인은 여러 스펙 버전과 호환 가능).
설치
네트워킹 컨텍스트에서 컨테이너 런타임은 kubelet을 위한 CRI 서비스를 제공하도록 구성된 노드의 데몬이다. 특히, 컨테이너 런타임은 쿠버네티스 네트워크 모델을 구현하는 데 필요한 CNI 플러그인을 로드하도록 구성되어야 한다.
참고:
쿠버네티스 1.24 이전까지는 cni-bin-dir과 network-plugin 커맨드 라인 파라미터를 사용해 kubelet이 CNI 플러그인을 관리하게 할 수도 있었다.
이 커맨드 라인 파라미터들은 쿠버네티스 1.24에서 제거되었으며, CNI 관리는 더 이상 kubelet 범위에 포함되지 않는다.
도커심 제거 후 문제가 발생하는 경우 CNI 플러그인 관련 오류 문제 해결을 참조하자.
컨테이너 런타임에서 CNI 플러그인을 관리하는 방법에 관한 자세한 내용은 아래 예시와 같은 컨테이너 런타임에 대한 문서를 참조하자.
CNI 플러그인을 설치하고 관리하는 방법에 관한 자세한 내용은 해당 플러그인 또는 네트워킹 프로바이더 문서를 참조하자.
네트워크 플러그인 요구 사항
쿠버네티스를 빌드하거나 배포하는 플러그인 개발자와 사용자들을 위해, 플러그인은 kube-proxy를 지원하기 위한 특정 설정이 필요할 수도 있다.
iptables 프록시는 iptables에 의존하며, 플러그인은 컨테이너 트래픽이 iptables에 사용 가능하도록 해야 한다.
예를 들어, 플러그인이 컨테이너를 리눅스 브릿지에 연결하는 경우, 플러그인은 net/bridge/bridge-nf-call-iptables sysctl을
1로 설정하여 iptables 프록시가 올바르게 작동하는지 확인해야 한다.
플러그인이 Linux 브리지를 사용하지 않고 대신 Open vSwitch나 다른 메커니즘을 사용하는 경우, 컨테이너 트래픽이 프록시에 대해 적절하게 라우팅되도록 해야 한다.
kubelet 네트워크 플러그인이 지정되지 않은 경우, 기본적으로 noop 플러그인이 사용되며,
net/bridge/bridge-nf-call-iptables=1을 설정하여 간단한 구성(브릿지가 있는 도커 등)이 iptables 프록시에서 올바르게 작동하도록 한다.
루프백 CNI
쿠버네티스 네트워크 모델을 구현하기 위해 노드에 설치된 CNI 플러그인 외에도, 쿠버네티스는 각 샌드박스(파드 샌드박스, VM 샌드박스 등)에
사용되는 루프백 인터페이스 lo를 제공하기 위한 컨테이너 런타임도 요구한다.
루프백 인터페이스 구현은 CNI 루프백 플러그인을
재사용하거나 자체 코드를 개발하여 수행할 수 있다. (CRI-O 예시 참조)
hostPort 지원
CNI 네트워킹 플러그인은 hostPort 를 지원한다. CNI 플러그인 팀이 제공하는 공식
포트맵(portmap)
플러그인을 사용하거나 portMapping 기능이 있는 자체 플러그인을 사용할 수 있다.
hostPort 지원을 사용하려면, cni-conf-dir 에 portMappings capability 를 지정해야 한다.
예를 들면 다음과 같다.
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true}
}
]
}
트래픽 셰이핑(shaping) 지원
실험적인 기능입니다
CNI 네트워킹 플러그인은 파드 수신 및 송신 트래픽 셰이핑도 지원한다. CNI 플러그인 팀에서 제공하는 공식 대역폭(bandwidth) 플러그인을 사용하거나 대역폭 제어 기능이 있는 자체 플러그인을 사용할 수 있다.
트래픽 셰이핑 지원을 활성화하려면, CNI 구성 파일 (기본값 /etc/cni/net.d)에 bandwidth 플러그인을
추가하고, 바이너리가 CNI 실행 파일 디렉터리(기본값: /opt/cni/bin)에 포함되어 있는지 확인한다.
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
이제 파드에 kubernetes.io/ingress-bandwidth 와 kubernetes.io/egress-bandwidth 어노테이션을 추가할 수 있다.
예를 들면 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
...
다음 내용
13.2.2 - 장치 플러그인
장치 플러그인을 사용하여 GPU, NIC, FPGA, 또는 비휘발성 주 메모리와 같이 공급 업체별 설정이 필요한 장치 또는 리소스를 클러스터에서 지원하도록 설정할 수 있다.
기능 상태:
Kubernetes v1.26 [stable]
쿠버네티스는 시스템 하드웨어 리소스를 Kubelet에 알리는 데 사용할 수 있는 장치 플러그인 프레임워크를 제공한다.
공급 업체는 쿠버네티스 자체의 코드를 커스터마이징하는 대신, 수동 또는 데몬셋으로 배포하는 장치 플러그인을 구현할 수 있다. 대상이 되는 장치에는 GPU, 고성능 NIC, FPGA, InfiniBand 어댑터 및 공급 업체별 초기화 및 설정이 필요할 수 있는 기타 유사한 컴퓨팅 리소스가 포함된다.
장치 플러그인 등록
kubelet은 Registration gRPC 서비스를 노출시킨다.
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
장치 플러그인은 이 gRPC 서비스를 통해 kubelet에 자체 등록할 수 있다. 등록하는 동안, 장치 플러그인은 다음을 보내야 한다.
- 유닉스 소켓의 이름.
- 빌드된 장치 플러그인 API 버전.
- 알리려는
ResourceName. 여기서ResourceName은 확장된 리소스 네이밍 체계를vendor-domain/resourcetype의 형식으로 따라야 한다. (예를 들어, NVIDIA GPU는nvidia.com/gpu로 알려진다.)
성공적으로 등록하고 나면, 장치 플러그인은 kubelet이 관리하는
장치 목록을 전송한 다음, kubelet은 kubelet 노드 상태 업데이트의 일부로
해당 자원을 API 서버에 알리는 역할을 한다.
예를 들어, 장치 플러그인이 kubelet에 hardware-vendor.example/foo 를 등록하고
노드에 두 개의 정상 장치를 보고하고 나면, 노드 상태가 업데이트되어
노드에 2개의 "Foo" 장치가 설치되어 사용 가능함을 알릴 수 있다.
그러고 나면, 사용자가 장치를 파드 스펙의 일부로 요청할 수
있다(container 참조).
확장 리소스를 요청하는 것은 다른 자원의 요청 및 제한을 관리하는 것과 비슷하지만,
다음과 같은 차이점이 존재한다.
- 확장된 리소스는 정수(integer) 형태만 지원되며 오버커밋(overcommit) 될 수 없다.
- 컨테이너간에 장치를 공유할 수 없다.
예제
쿠버네티스 클러스터가 특정 노드에서 hardware-vendor.example/foo 리소스를 알리는 장치 플러그인을 실행한다고
가정해 보자. 다음은 데모 워크로드를 실행하기 위해 이 리소스를 요청하는 파드의 예이다.
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: registry.k8s.io/pause:2.0
resources:
limits:
hardware-vendor.example/foo: 2
#
# 이 파드는 2개의 hardware-vendor.example/foo 장치가 필요하며
# 해당 요구를 충족할 수 있는 노드에만
# 예약될 수 있다.
#
# 노드에 2개 이상의 사용 가능한 장치가 있는 경우
# 나머지는 다른 파드에서 사용할 수 있다.
장치 플러그인 구현
장치 플러그인의 일반적인 워크플로우에는 다음 단계가 포함된다.
-
초기화. 이 단계에서, 장치 플러그인은 공급 업체별 초기화 및 설정을 수행하여 장치가 준비 상태에 있는지 확인한다.
-
플러그인은 다음의 인터페이스를 구현하는 호스트 경로
/var/lib/kubelet/device-plugins/아래에 유닉스 소켓과 함께 gRPC 서비스를 시작한다.service DevicePlugin { // GetDevicePluginOptions는 장치 관리자와 통신할 옵션을 반환한다. rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {} // ListAndWatch는 장치 목록 스트림을 반환한다. // 장치 상태가 변경되거나 장치가 사라질 때마다, ListAndWatch는 // 새 목록을 반환한다. rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {} // 컨테이너를 생성하는 동안 Allocate가 호출되어 장치 // 플러그인이 장치별 작업을 실행하고 kubelet에 장치를 // 컨테이너에서 사용할 수 있도록 하는 단계를 지시할 수 있다. rpc Allocate(AllocateRequest) returns (AllocateResponse) {} // GetPreferredAllocation은 사용 가능한 장치 목록에서 할당할 // 기본 장치 집합을 반환한다. 그 결과로 반환된 선호하는 할당은 // devicemanager가 궁극적으로 수행하는 할당이 되는 것을 보장하지 // 않는다. 가능한 경우 devicemanager가 정보에 입각한 할당 결정을 // 내릴 수 있도록 설계되었다. rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {} // PreStartContainer는 등록 단계에서 장치 플러그인에 의해 표시되면 각 컨테이너가 // 시작되기 전에 호출된다. 장치 플러그인은 장치를 컨테이너에서 사용할 수 있도록 하기 전에 // 장치 재설정과 같은 장치별 작업을 실행할 수 있다. rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {} }참고:
GetPreferredAllocation()또는PreStartContainer()에 대한 유용한 구현을 제공하기 위해 플러그인이 필요하지 않다. 이러한 호출(있는 경우) 중 사용할 수 있는 경우를 나타내는 플래그는GetDevicePluginOptions()호출에 의해 다시 전송된DevicePluginOptions메시지에 설정되어야 한다.kubelet은 항상GetDevicePluginOptions()를 호출하여 사용할 수 있는 선택적 함수를 확인한 후 직접 호출한다. -
플러그인은 호스트 경로
/var/lib/kubelet/device-plugins/kubelet.sock에서 유닉스 소켓을 통해 kubelet에 직접 등록한다. -
성공적으로 등록하고 나면, 장치 플러그인은 서빙(serving) 모드에서 실행되며, 그 동안 플러그인은 장치 상태를 모니터링하고 장치 상태 변경 시 kubelet에 다시 보고한다. 또한 gRPC 요청
Allocate를 담당한다.Allocate하는 동안, 장치 플러그인은 GPU 정리 또는 QRNG 초기화와 같은 장치별 준비를 수행할 수 있다. 작업이 성공하면, 장치 플러그인은 할당된 장치에 접근하기 위한 컨테이너 런타임 구성이 포함된AllocateResponse를 반환한다. kubelet은 이 정보를 컨테이너 런타임에 전달한다.
kubelet 재시작 처리
장치 플러그인은 일반적으로 kubelet의 재시작을 감지하고 새로운
kubelet 인스턴스에 자신을 다시 등록할 것으로 기대된다. 새 kubelet 인스턴스는 시작될 때
/var/lib/kubelet/device-plugins 아래에 있는 모든 기존의 유닉스 소켓을 삭제한다. 장치 플러그인은 유닉스 소켓의
삭제를 모니터링하고 이러한 이벤트가 발생하면 다시 자신을 등록할 수 있다.
장치 플러그인 배포
장치 플러그인을 데몬셋, 노드 운영 체제의 패키지 또는 수동으로 배포할 수 있다.
표준 디렉터리 /var/lib/kubelet/device-plugins 에는 특권을 가진 접근이 필요하므로,
장치 플러그인은 특권을 가진 보안 컨텍스트에서 실행해야 한다.
장치 플러그인을 데몬셋으로 배포하는 경우, 플러그인의
PodSpec에서
/var/lib/kubelet/device-plugins 를
볼륨으로 마운트해야 한다.
데몬셋 접근 방식을 선택하면 쿠버네티스를 사용하여 장치 플러그인의 파드를 노드에 배치하고, 장애 후 데몬 파드를 다시 시작하고, 업그레이드를 자동화할 수 있다.
API 호환성
과거에는 장치 플러그인의 API 버전을 반드시 kubelet의 버전과 정확하게 일치시켜야 했다. 해당 기능이 v1.12의 베타 버전으로 올라오면서 이는 필수 요구사항이 아니게 되었다. 해당 기능이 베타 버전이 된 이후로 API는 버전화되었고 그동안 변하지 않았다. 그러므로 kubelet 업그레이드를 원활하게 진행할 수 있을 것이지만, 안정화되기 전까지는 향후 API가 변할 수도 있으므로 업그레이드를 했을 때 절대로 문제가 없을 것이라고는 보장할 수는 없다.
주의:
쿠버네티스의 장치 관리자 컴포넌트는 안정화된(GA) 기능이지만 _장치 플러그인 API_는 안정화되지 않았다. 장치 플러그인 API와 버전 호환성에 대한 정보는 장치 플러그인 API 버전를 참고하라.프로젝트로서, 쿠버네티스는 장치 플러그인 개발자에게 다음 사항을 권장한다.
- 향후 릴리스에서 장치 플러그인 API의 변경 사항을 확인하자.
- 이전/이후 버전과의 호환성을 위해 여러 버전의 장치 플러그인 API를 지원하자.
최신 장치 플러그인 API 버전의 쿠버네티스 릴리스로 업그레이드해야 하는 노드에서 장치 플러그인을 실행하기 위해서는, 해당 노드를 업그레이드하기 전에 두 버전을 모두 지원하도록 장치 플러그인을 업그레이드해야 한다. 이러한 방법은 업그레이드 중에 장치 할당이 지속적으로 동작할 것을 보장한다.
장치 플러그인 리소스 모니터링
기능 상태:
Kubernetes v1.15 [beta]
장치 플러그인에서 제공하는 리소스를 모니터링하려면, 모니터링 에이전트가
노드에서 사용 중인 장치 셋을 검색하고 메트릭과 연관될 컨테이너를 설명하는
메타데이터를 얻을 수 있어야 한다. 장치 모니터링 에이전트에 의해 노출된
프로메테우스 지표는
쿠버네티스 Instrumentation 가이드라인을 따라
pod, namespace 및 container 프로메테우스 레이블을 사용하여 컨테이너를 식별해야 한다.
kubelet은 gRPC 서비스를 제공하여 사용 중인 장치를 검색하고, 이러한 장치에 대한 메타데이터를 제공한다.
// PodResourcesLister는 kubelet에서 제공하는 서비스로, 노드의 포드 및 컨테이너가
// 사용한 노드 리소스에 대한 정보를 제공한다.
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
}
List gRPC 엔드포인트
List 엔드포인트는 실행 중인 파드의 리소스에 대한 정보를 제공하며,
독점적으로 할당된 CPU의 ID, 장치 플러그인에 의해 보고된 장치 ID,
이러한 장치가 할당된 NUMA 노드의 ID와 같은 세부 정보를 함께 제공한다. 또한, NUMA 기반 머신의 경우, 컨테이너를 위해 예약된 메모리와 hugepage에 대한 정보를 포함한다.
// ListPodResourcesResponse는 List 함수가 반환하는 응답이다.
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources에는 파드에 할당된 노드 리소스에 대한 정보가 포함된다.
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources는 컨테이너에 할당된 리소스에 대한 정보를 포함한다.
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
}
// ContainerMemory는 컨테이너에 할당된 메모리와 hugepage에 대한 정보를 포함한다.
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// 토폴로지는 리소스의 하드웨어 토폴로지를 설명한다.
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA 노드의 NUMA 표현
message NUMANode {
int64 ID = 1;
}
// ContainerDevices는 컨테이너에 할당된 장치에 대한 정보를 포함한다.
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
참고:
List 엔드포인트의 ContainerResources 내부에 있는 cpu_ids은 특정 컨테이너에 할당된
독점 CPU들에 해당한다. 만약 공유 풀(shared pool)에 있는 CPU들을 확인(evaluate)하는 것이 목적이라면, 해당 List
엔드포인트는 다음에 설명된 것과 같이, GetAllocatableResources 엔드포인트와 함께 사용되어야
한다.
GetAllocatableResources를 호출하여 할당 가능한 모든 CPU 목록을 조회- 시스템의 모든
ContainerResources에서GetCpuIds를 호출 GetAllocateableResources호출에서GetCpuIds호출로 얻은 모든 CPU를 빼기
GetAllocatableResources gRPC 엔드포인트
기능 상태:
Kubernetes v1.23 [beta]
GetAllocatableResources는 워커 노드에서 처음 사용할 수 있는 리소스에 대한 정보를 제공한다. kubelet이 APIServer로 내보내는 것보다 더 많은 정보를 제공한다.
참고:
GetAllocatableResources는 할당 가능(allocatable) 리소스를 확인(evaluate)하기 위해서만
사용해야 한다. 만약 목적이 free/unallocated 리소스를 확인하기 위한 것이라면
List() 엔드포인트와 함께 사용되어야 한다. GetAllocableResources로 얻은 결과는 kubelet에
노출된 기본 리소스가 변경되지 않는 한 동일하게 유지된다. 이러한 변경은 드물지만, 발생하게 된다면
(예를 들면: hotplug/hotunplug, 장치 상태 변경) 클라이언트가 GetAlloctableResources 엔드포인트를
호출할 것으로 가정한다.
그러나 CPU 및/또는 메모리가 갱신된 경우 GetAllocateableResources 엔드포인트를 호출하는 것만으로는
충분하지 않으며, kubelet을 다시 시작하여 올바른 리소스 용량과 할당 가능(allocatable) 리소스를 반영해야 한다.
// AllocatableResourcesResponses에는 kubelet이 알고 있는 모든 장치에 대한 정보가 포함된다.
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
쿠버네티스 v1.23부터, GetAllocatableResources가 기본으로 활성화된다.
이를 비활성화하려면 KubeletPodResourcesGetAllocatable
기능 게이트(feature gate)를 끄면 된다.
쿠버네티스 v1.23 이전 버전에서 이 기능을 활성화하려면 kubelet이 다음 플래그를 가지고 시작되어야 한다.
--feature-gates=KubeletPodResourcesGetAllocatable=true
ContainerDevices 는 장치가 어떤 NUMA 셀과 연관되는지를 선언하는 토폴로지 정보를 노출한다.
NUMA 셀은 불분명한(opaque) 정수 ID를 사용하여 식별되며, 이 값은
kubelet에 등록할 때 장치 플러그인이 보고하는 것과 일치한다.
gRPC 서비스는 /var/lib/kubelet/pod-resources/kubelet.sock 의 유닉스 소켓을 통해 제공된다.
장치 플러그인 리소스에 대한 모니터링 에이전트는 데몬 또는 데몬셋으로 배포할 수 있다.
표준 디렉터리 /var/lib/kubelet/pod-resources 에는 특권을 가진 접근이 필요하므로, 모니터링
에이전트는 특권을 가진 보안 컨텍스트에서 실행해야 한다. 장치 모니터링 에이전트가
데몬셋으로 실행 중인 경우, 해당 장치 모니터링 에이전트의 PodSpec에서
/var/lib/kubelet/pod-resources 를
볼륨으로 마운트해야 한다.
PodResourcesLister service 를 지원하려면 KubeletPodResources 기능 게이트를 활성화해야 한다.
이것은 쿠버네티스 1.15부터 기본으로 활성화되어 있으며, 쿠버네티스 1.20부터는 v1 상태이다.
토폴로지 관리자로 장치 플러그인 통합
기능 상태:
Kubernetes v1.18 [beta]
토폴로지 관리자는 kubelet 컴포넌트로, 리소스를 토폴로지 정렬 방식으로 조정할 수 있다.
이를 위해, 장치 플러그인 API가 TopologyInfo 구조체를 포함하도록 확장되었다.
message TopologyInfo {
repeated NUMANode nodes = 1;
}
message NUMANode {
int64 ID = 1;
}
토폴로지 관리자를 활용하려는 장치 플러그인은 장치 ID 및 장치의 정상 상태와 함께 장치 등록의 일부로 채워진 TopologyInfo 구조체를 다시 보낼 수 있다. 그런 다음 장치 관리자는 이 정보를 사용하여 토폴로지 관리자와 상의하고 리소스 할당 결정을 내린다.
TopologyInfo 는 nodes 필드에 nil(기본값) 또는 NUMA 노드 목록을 설정하는 것을 지원한다.
이를 통해 복수의 NUMA 노드에 연관된 장치에 대해 장치 플러그인을 설정할 수 있다.
특정 장치에 대해 TopologyInfo를 nil로 설정하거나 비어있는 NUMA 노드 목록을 제공하는 것은
장치 플러그인이 해당 장치에 대한 NUMA 선호도(affinity)를 지니지 못함을 시사한다.
장치 플러그인으로 장치에 대해 채워진 TopologyInfo 구조체의 예는 다음과 같다.
pluginapi.Device{ID: "25102017", Health: pluginapi.Healthy, Topology:&pluginapi.TopologyInfo{Nodes: []*pluginapi.NUMANode{&pluginapi.NUMANode{ID: 0,},}}}
장치 플러그인 예시
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는 CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에 콘텐츠 가이드를 읽어본다.
다음은 장치 플러그인 구현의 예이다.
- AMD GPU 장치 플러그인
- 인텔 GPU, FPGA, QAT, VPU, SGX, DSA, DLB 및 IAA 장치용 인텔 장치 플러그인
- 하드웨어 지원 가상화를 위한 KubeVirt 장치 플러그인
- 컨테이너에 최적화된 OS를 위한 NVIDIA GPU 장치 플러그인
- RDMA 장치 플러그인
- SocketCAN 장치 플러그인
- Solarflare 장치 플러그인
- SR-IOV 네트워크 장치 플러그인
- Xilinx FPGA 장치용 Xilinx FPGA 장치 플러그인
다음 내용
- 장치 플러그인을 사용한 GPU 리소스 스케줄링에 대해 알아보기
- 노드에서의 확장 리소스 알리기에 대해 배우기
- 토폴로지 관리자에 대해 알아보기
- 쿠버네티스에서 TLS 인그레스에 하드웨어 가속 사용에 대해 읽기
13.3 - 쿠버네티스 API 확장하기
13.3.1 - 커스텀 리소스
커스텀 리소스 는 쿠버네티스 API의 익스텐션이다. 이 페이지에서는 쿠버네티스 클러스터에 커스텀 리소스를 추가할 시기와 독립형 서비스를 사용하는 시기에 대해 설명한다. 커스텀 리소스를 추가하는 두 가지 방법과 이들 중에서 선택하는 방법에 대해 설명한다.
커스텀 리소스
리소스 는 쿠버네티스 API에서 특정 종류의 API 오브젝트 모음을 저장하는 엔드포인트이다. 예를 들어 빌트인 파드 리소스에는 파드 오브젝트 모음이 포함되어 있다.
커스텀 리소스 는 쿠버네티스 API의 익스텐션으로, 기본 쿠버네티스 설치에서 반드시 사용할 수 있는 것은 아니다. 이는 특정 쿠버네티스 설치에 수정이 가해졌음을 나타낸다. 그러나 많은 핵심 쿠버네티스 기능은 이제 커스텀 리소스를 사용하여 구축되어, 쿠버네티스를 더욱 모듈화한다.
동적 등록을 통해 실행 중인 클러스터에서 커스텀 리소스가 나타나거나 사라질 수 있으며 클러스터 관리자는 클러스터 자체와 독립적으로 커스텀 리소스를 업데이트 할 수 있다. 커스텀 리소스가 설치되면 사용자는 파드 와 같은 빌트인 리소스와 마찬가지로 kubectl을 사용하여 해당 오브젝트를 생성하고 접근할 수 있다.
커스텀 컨트롤러
자체적으로 커스텀 리소스를 사용하면 구조화된 데이터를 저장하고 검색할 수 있다. 커스텀 리소스를 커스텀 컨트롤러 와 결합하면, 커스텀 리소스가 진정한 선언적(declarative) API 를 제공하게 된다.
쿠버네티스 선언적 API는 책임의 분리를 강제한다. 사용자는 리소스의 의도한 상태를 선언한다. 쿠버네티스 컨트롤러는 쿠버네티스 오브젝트의 현재 상태가 선언한 의도한 상태에 동기화 되도록 한다. 이는 서버에 무엇을 해야할지 지시하는 명령적인 API와는 대조된다.
클러스터 라이프사이클과 관계없이 실행 중인 클러스터에 커스텀 컨트롤러를 배포하고 업데이트할 수 있다. 커스텀 컨트롤러는 모든 종류의 리소스와 함께 작동할 수 있지만 커스텀 리소스와 결합할 때 특히 효과적이다. 오퍼레이터 패턴은 사용자 정의 리소스와 커스텀 컨트롤러를 결합한다. 커스텀 컨트롤러를 사용하여 특정 애플리케이션에 대한 도메인 지식을 쿠버네티스 API의 익스텐션으로 인코딩할 수 있다.
쿠버네티스 클러스터에 커스텀 리소스를 추가해야 하나?
새로운 API를 생성할 때 쿠버네티스 클러스터 API와 생성한 API를 애그리게이트할 것인지 아니면 생성한 API를 독립적으로 유지할 것인지 고려하자.
| API 애그리게이트를 고려할 경우 | 독립 API를 고려할 경우 |
|---|---|
| API가 선언적이다. | API가 선언적 모델에 맞지 않다. |
kubectl을 사용하여 새로운 타입을 읽고 쓸 수 있기를 원한다. |
kubectl 지원이 필요하지 않다. |
| 쿠버네티스 UI(예: 대시보드)에서 빌트인 타입과 함께 새로운 타입을 보길 원한다. | 쿠버네티스 UI 지원이 필요하지 않다. |
| 새로운 API를 개발 중이다. | 생성한 API를 제공하는 프로그램이 이미 있고 잘 작동하고 있다. |
| API 그룹 및 네임스페이스와 같은 REST 리소스 경로에 적용하는 쿠버네티스의 형식 제한을 기꺼이 수용한다. (API 개요를 참고한다.) | 이미 정의된 REST API와 호환되도록 특정 REST 경로가 있어야 한다. |
| 자체 리소스는 자연스럽게 클러스터 또는 클러스터의 네임스페이스로 범위가 지정된다. | 클러스터 또는 네임스페이스 범위의 리소스는 적합하지 않다. 특정 리소스 경로를 제어해야 한다. |
| 쿠버네티스 API 지원 기능을 재사용하려고 한다. | 이러한 기능이 필요하지 않다. |
선언적 API
선언적 API에서는 다음의 특성이 있다.
- API는 상대적으로 적은 수의 상대적으로 작은 오브젝트(리소스)로 구성된다.
- 오브젝트는 애플리케이션 또는 인프라의 구성을 정의한다.
- 오브젝트는 비교적 드물게 업데이트 된다.
- 사람이 종종 오브젝트를 읽고 쓸 필요가 있다.
- 오브젝트의 주요 작업은 CRUD-y(생성, 읽기, 업데이트 및 삭제)이다.
- 오브젝트 간 트랜잭션은 필요하지 않다. API는 정확한(exact) 상태가 아니라 의도한 상태를 나타낸다.
명령형 API는 선언적이지 않다. 자신의 API가 선언적이지 않을 수 있다는 징후는 다음과 같다.
- 클라이언트는 "이 작업을 수행한다"라고 말하고 완료되면 동기(synchronous) 응답을 받는다.
- 클라이언트는 "이 작업을 수행한다"라고 말한 다음 작업 ID를 다시 가져오고 별도의 오퍼레이션(operation) 오브젝트를 확인하여 요청의 완료 여부를 결정해야 한다.
- RPC(원격 프로시저 호출)에 대해 얘기한다.
- 대량의 데이터를 직접 저장한다. 예: > 오브젝트별 몇 kB 또는 > 1000개의 오브젝트.
- 높은 대역폭 접근(초당 10개의 지속적인 요청)이 필요하다.
- 최종 사용자 데이터(예: 이미지, PII 등) 또는 애플리케이션에서 처리한 기타 대규모 데이터를 저장한다.
- 오브젝트에 대한 자연스러운 조작은 CRUD-y가 아니다.
- API는 오브젝트로 쉽게 모델링되지 않는다.
- 작업 ID 또는 작업 오브젝트로 보류 중인 작업을 나타내도록 선택했다.
컨피그맵을 사용해야 하나, 커스텀 리소스를 사용해야 하나?
다음 중 하나에 해당하면 컨피그맵을 사용하자.
mysql.cnf또는pom.xml과 같이 잘 문서화된 기존 구성 파일 형식이 있다.- 전체 구성 파일을 컨피그맵의 하나의 키에 넣고 싶다.
- 구성 파일의 주요 용도는 클러스터의 파드에서 실행 중인 프로그램이 파일을 사용하여 자체 구성하는 것이다.
- 파일 사용자는 쿠버네티스 API가 아닌 파드의 환경 변수 또는 파드의 파일을 통해 사용하는 것을 선호한다.
- 파일이 업데이트될 때 디플로이먼트 등을 통해 롤링 업데이트를 수행하려고 한다.
참고:
민감한 데이터에는 시크릿을 사용하자. 이는 컨피그맵과 비슷하지만 더 안전하다.다음 중 대부분이 적용되는 경우 커스텀 리소스(CRD 또는 애그리게이트 API(aggregated API))를 사용하자.
- 쿠버네티스 클라이언트 라이브러리 및 CLI를 사용하여 새 리소스를 만들고 업데이트하려고 한다.
kubectl의 최상위 지원을 원한다. 예:kubectl get my-object object-name.- 새 오브젝트에 대한 업데이트를 감시한 다음 다른 오브젝트를 CRUD하거나 그 반대로 하는 새로운 자동화를 구축하려고 한다.
- 오브젝트의 업데이트를 처리하는 자동화를 작성하려고 한다.
.spec,.status및.metadata와 같은 쿠버네티스 API 규칙을 사용하려고 한다.- 제어된 리소스의 콜렉션 또는 다른 리소스의 요약에 대한 오브젝트가 되기를 원한다.
커스텀 리소스 추가
쿠버네티스는 클러스터에 커스텀 리소스를 추가하는 두 가지 방법을 제공한다.
- CRD는 간단하며 프로그래밍 없이 만들 수 있다.
- API 애그리게이션에는 프로그래밍이 필요하지만, 데이터 저장 방법 및 API 버전 간 변환과 같은 API 동작을 보다 강력하게 제어할 수 있다.
쿠버네티스는 다양한 사용자의 요구를 충족시키기 위해 이 두 가지 옵션을 제공하므로 사용의 용이성이나 유연성이 저하되지 않는다.
애그리게이트 API는 기본 API 서버 뒤에 있는 하위 API 서버이며 프록시 역할을 한다. 이 배치를 API 애그리게이션(AA)이라고 한다. 사용자에게는 쿠버네티스 API가 확장된 것으로 나타난다.
CRD를 사용하면 다른 API 서버를 추가하지 않고도 새로운 타입의 리소스를 생성할 수 있다. CRD를 사용하기 위해 API 애그리게이션을 이해할 필요는 없다.
설치 방법에 관계없이 새 리소스는 커스텀 리소스라고 하며 빌트인 쿠버네티스 리소스(파드 등)와 구별된다.
참고:
커스텀 리소스를 애플리케이션, 최종 사용자, 데이터 모니터링을 위한 데이터 스토리지로 사용하는 것은 피해야 한다. 쿠버네티스 API에서 애플리케이션 데이터를 저장하는 아키텍처 구조는 일반적으로 결합도가 너무 높기 때문이다.
아키텍처적으로 클라우드 네이티브 애플리케이션 아키텍처들은 컴포넌트 간 결합도를 낮추는 것을 선호한다. 워크로드 중 일부가 주기적인 작업을 위해 보조 서비스를 필요로 한다면, 해당 보조 서비스를 별도의 컴포넌트로 실행하거나 외부 서비스로 사용하자. 이를 통해 해당 워크로드는 일반적인 작업을 위해 쿠버네티스 API에 의존하지 않게 된다.
커스텀리소스데피니션
커스텀리소스데피니션 API 리소스를 사용하면 커스텀 리소스를 정의할 수 있다. CRD 오브젝트를 정의하면 지정한 이름과 스키마를 사용하여 새 커스텀 리소스가 만들어진다. 쿠버네티스 API는 커스텀 리소스의 스토리지를 제공하고 처리한다. CRD 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
따라서 커스텀 리소스를 처리하기 위해 자신의 API 서버를 작성할 수 없지만 구현의 일반적인 특성으로 인해 API 서버 애그리게이션보다 유연성이 떨어진다.
새 커스텀 리소스를 등록하고 새 리소스 타입의 인스턴스에 대해 작업하고 컨트롤러를 사용하여 이벤트를 처리하는 방법에 대한 예제는 커스텀 컨트롤러 예제를 참고한다.
API 서버 애그리게이션
일반적으로 쿠버네티스 API의 각 리소스에는 REST 요청을 처리하고 오브젝트의 퍼시스턴트 스토리지를 관리하는 코드가 필요하다. 주요 쿠버네티스 API 서버는 파드 및 서비스 와 같은 빌트인 리소스를 처리하고, 일반적으로 CRD를 통해 커스텀 리소스를 처리할 수 있다.
애그리게이션 레이어를 사용하면 자체 API 서버를 작성하고 배포하여 커스텀 리소스에 대한 특수한 구현을 제공할 수 있다. 주(main) API 서버는 사용자의 커스텀 리소스에 대한 요청을 사용자의 자체 API 서버에 위임하여 모든 클라이언트가 사용할 수 있게 한다.
커스텀 리소스를 추가할 방법 선택
CRD는 사용하기가 더 쉽다. 애그리게이트 API가 더 유연하다. 자신의 요구에 가장 잘 맞는 방법을 선택하자.
일반적으로 CRD는 다음과 같은 경우에 적합하다.
- 필드가 몇 개 되지 않는다
- 회사 내에서 또는 소규모 오픈소스 프로젝트의 일부인(상용 제품이 아닌) 리소스를 사용하고 있다.
사용 편의성 비교
CRD는 애그리게이트 API보다 생성하기가 쉽다.
| CRD | 애그리게이트 API |
|---|---|
| 프로그래밍이 필요하지 않다. 사용자는 CRD 컨트롤러에 대한 모든 언어를 선택할 수 있다. | 프로그래밍하고 바이너리와 이미지를 빌드해야 한다. |
| 실행할 추가 서비스가 없다. CR은 API 서버에서 처리한다. | 추가 서비스를 생성하면 실패할 수 있다. |
| CRD가 생성된 후에는 지속적인 지원이 없다. 모든 버그 픽스는 일반적인 쿠버네티스 마스터 업그레이드의 일부로 선택된다. | 업스트림에서 버그 픽스를 주기적으로 선택하고 애그리게이트 API 서버를 다시 빌드하고 업데이트해야 할 수 있다. |
| 여러 버전의 API를 처리할 필요가 없다. 예를 들어, 이 리소스에 대한 클라이언트를 제어할 때 API와 동기화하여 업그레이드할 수 있다. | 인터넷에 공유할 익스텐션을 개발할 때와 같이 여러 버전의 API를 처리해야 한다. |
고급 기능 및 유연성
애그리게이트 API는 보다 고급 API 기능과 스토리지 레이어와 같은 다른 기능의 사용자 정의를 제공한다.
| 기능 | 설명 | CRD | 애그리게이트 API |
|---|---|---|---|
| 유효성 검사 | 사용자가 오류를 방지하고 클라이언트와 독립적으로 API를 발전시킬 수 있도록 도와준다. 이러한 기능은 동시에 많은 클라이언트를 모두 업데이트할 수 없는 경우에 아주 유용하다. | 예. OpenAPI v3.0 유효성 검사를 사용하여 CRD에서 대부분의 유효성 검사를 지정할 수 있다. 웹훅 유효성 검사를 추가해서 다른 모든 유효성 검사를 지원한다. | 예, 임의의 유효성 검사를 지원한다. |
| 기본 설정 | 위를 참고하자. | 예, OpenAPI v3.0 유효성 검사의 default 키워드(1.17에서 GA) 또는 웹훅 변형(mutating)(이전 오브젝트의 etcd에서 읽을 때는 실행되지 않음)을 통해 지원한다. |
예 |
| 다중 버전 관리 | 두 가지 API 버전을 통해 동일한 오브젝트를 제공할 수 있다. 필드 이름 바꾸기와 같은 API 변경을 쉽게 할 수 있다. 클라이언트 버전을 제어하는 경우는 덜 중요하다. | 예 | 예 |
| 사용자 정의 스토리지 | 다른 성능 모드(예를 들어, 키-값 저장소 대신 시계열 데이터베이스)나 보안에 대한 격리(예를 들어, 암호화된 시크릿이나 다른 암호화) 기능을 가진 스토리지가 필요한 경우 | 아니오 | 예 |
| 사용자 정의 비즈니스 로직 | 오브젝트를 생성, 읽기, 업데이트 또는 삭제를 할 때 임의의 점검 또는 조치를 수행한다. | 예, 웹훅을 사용한다. | 예 |
| 서브리소스 크기 조정 | HorizontalPodAutoscaler 및 PodDisruptionBudget과 같은 시스템이 새로운 리소스와 상호 작용할 수 있다. | 예 | 예 |
| 서브리소스 상태 | 사용자가 스펙 섹션을 작성하고 컨트롤러가 상태 섹션을 작성하는 세분화된 접근 제어를 허용한다. 커스텀 리소스 데이터 변형 시 오브젝트 생성을 증가시킨다(리소스에서 별도의 스펙과 상태 섹션 필요). | 예 | 예 |
| 기타 서브리소스 | "logs" 또는 "exec"과 같은 CRUD 이외의 작업을 추가한다. | 아니오 | 예 |
| strategic-merge-patch | 새로운 엔드포인트는 Content-Type: application/strategic-merge-patch+json 형식의 PATCH를 지원한다. 로컬 및 서버 양쪽에서 수정할 수도 있는 오브젝트를 업데이트하는 데 유용하다. 자세한 내용은 "kubectl 패치를 사용한 API 오브젝트 업데이트"를 참고한다. |
아니오 | 예 |
| 프로토콜 버퍼 | 새로운 리소스는 프로토콜 버퍼를 사용하려는 클라이언트를 지원한다. | 아니오 | 예 |
| OpenAPI 스키마 | 서버에서 동적으로 가져올 수 있는 타입에 대한 OpenAPI(스웨거(swagger)) 스키마가 있는가? 허용된 필드만 설정하여 맞춤법이 틀린 필드 이름으로부터 사용자를 보호하는가? 타입이 적용되는가(즉, string 필드에 int를 넣지 않는가?) |
예, OpenAPI v3.0 유효성 검사를 기반으로 하는 스키마(1.16에서 GA) | 예 |
일반적인 기능
CRD 또는 AA를 통해 커스텀 리소스를 생성하면 쿠버네티스 플랫폼 외부에서 구현하는 것과 비교하여 API에 대한 많은 기능이 제공된다.
| 기능 | 설명 |
|---|---|
| CRUD | 새로운 엔드포인트는 HTTP 및 kubectl을 통해 CRUD 기본 작업을 지원한다. |
| 감시 | 새로운 엔드포인트는 HTTP를 통해 쿠버네티스 감시 작업을 지원한다. |
| 디스커버리 | kubectl 및 대시보드와 같은 클라이언트는 리소스에 대해 목록, 표시 및 필드 수정 작업을 자동으로 제공한다. |
| json-patch | 새로운 엔드포인트는 Content-Type: application/json-patch+json 형식의 PATCH를 지원한다. |
| merge-patch | 새로운 엔드포인트는 Content-Type: application/merge-patch+json 형식의 PATCH를 지원한다. |
| HTTPS | 새로운 엔드포인트는 HTTPS를 사용한다. |
| 빌트인 인증 | 익스텐션에 대한 접근은 인증을 위해 기본 API 서버(애그리게이션 레이어)를 사용한다. |
| 빌트인 권한 부여 | 익스텐션에 접근하면 기본 API 서버(예: RBAC)에서 사용하는 권한을 재사용할 수 있다. |
| Finalizer | 외부 정리가 발생할 때까지 익스텐션 리소스의 삭제를 차단한다. |
| 어드미션 웹훅 | 생성/업데이트/삭제 작업 중에 기본값을 설정하고 익스텐션 리소스의 유효성 검사를 한다. |
| UI/CLI 디스플레이 | Kubectl, 대시보드는 익스텐션 리소스를 표시할 수 있다. |
| 설정하지 않음(unset)과 비어있음(empty) | 클라이언트는 값이 없는 필드 중에서 설정되지 않은 필드를 구별할 수 있다. |
| 클라이언트 라이브러리 생성 | 쿠버네티스는 일반 클라이언트 라이브러리와 타입별 클라이언트 라이브러리를 생성하는 도구를 제공한다. |
| 레이블 및 어노테이션 | 공통 메타데이터는 핵심 및 커스텀 리소스를 수정하는 방법을 알고 있는 도구이다. |
커스텀 리소스 설치 준비
클러스터에 커스텀 리소스를 추가하기 전에 알아야 할 몇 가지 사항이 있다.
써드파티 코드 및 새로운 장애 포인트
CRD를 생성해도 새로운 장애 포인트(예를 들어, API 서버에서 장애를 유발하는 써드파티 코드가 실행됨)가 자동으로 추가되지는 않지만, 패키지(예: 차트(Charts)) 또는 기타 설치 번들에는 CRD 및 새로운 커스텀 리소스에 대한 비즈니스 로직을 구현하는 써드파티 코드의 디플로이먼트가 포함되는 경우가 종종 있다.
애그리게이트 API 서버를 설치하려면 항상 새 디플로이먼트를 실행해야 한다.
스토리지
커스텀 리소스는 컨피그맵과 동일한 방식으로 스토리지 공간을 사용한다. 너무 많은 커스텀 리소스를 생성하면 API 서버의 스토리지 공간이 과부하될 수 있다.
애그리게이트 API 서버는 기본 API 서버와 동일한 스토리지를 사용할 수 있으며 이 경우 동일한 경고가 적용된다.
인증, 권한 부여 및 감사
CRD는 항상 API 서버의 빌트인 리소스와 동일한 인증, 권한 부여 및 감사 로깅을 사용한다.
권한 부여에 RBAC를 사용하는 경우 대부분의 RBAC 역할은 새로운 리소스에 대한 접근 권한을 부여하지 않는다(클러스터 관리자 역할 또는 와일드 카드 규칙으로 생성된 역할 제외). 새로운 리소스에 대한 접근 권한을 명시적으로 부여해야 한다. CRD 및 애그리게이트 API는 종종 추가하는 타입에 대한 새로운 역할 정의와 함께 제공된다.
애그리게이트 API 서버는 기본 API 서버와 동일한 인증, 권한 부여 및 감사를 사용하거나 사용하지 않을 수 있다.
커스텀 리소스에 접근
쿠버네티스 클라이언트 라이브러리를 사용하여 커스텀 리소스에 접근할 수 있다. 모든 클라이언트 라이브러리가 커스텀 리소스를 지원하는 것은 아니다. Go 와 python 클라이언트 라이브러리가 지원한다.
커스텀 리소스를 추가하면 다음을 사용하여 접근할 수 있다.
kubectl- 쿠버네티스 동적 클라이언트
- 작성한 REST 클라이언트
- 쿠버네티스 클라이언트 생성 도구를 사용하여 생성된 클라이언트(하나를 생성하는 것은 고급 기능이지만, 일부 프로젝트는 CRD 또는 AA와 함께 클라이언트를 제공할 수 있다).
다음 내용
- 애그리게이션 레이어(aggregation layer)로 쿠버네티스 API 확장하는 방법에 대해 배우기.
- 커스텀리소스데피니션으로 쿠버네티스 API 확장하는 방법에 대해 배우기.
13.3.2 - 쿠버네티스 API 애그리게이션 레이어(aggregation layer)
애그리게이션 레이어는 코어 쿠버네티스 API가 제공하는 기능 이외에 더 많은 기능을 제공할 수 있도록 추가 API를 더해 쿠버네티스를 확장할 수 있게 해준다. 추가 API는 메트릭 서버와 같이 미리 만들어진 솔루션이거나 사용자가 직접 개발한 API일 수 있다.
애그리게이션 레이어는 kube-apiserver가 새로운 종류의 오브젝트를 인식하도록 하는 방법인 사용자 정의 리소스와는 다르다.
애그리게이션 레이어
애그리게이션 레이어는 kube-apiserver 프로세스 안에서 구동된다. 확장 리소스가 등록되기 전까지, 애그리게이션 레이어는 아무 일도 하지 않는다. API를 등록하기 위해서, 사용자는 쿠버네티스 API 내에서 URL 경로를 "요구하는(claim)" APIService 오브젝트를 추가해야 한다. 이때, 애그리게이션 레이어는 해당 API 경로(예: /apis/myextensions.mycompany.io/v1/...)로 전송되는 모든 것을 등록된 APIService로 프록시하게 된다.
APIService를 구현하는 가장 일반적인 방법은 클러스터 내에 실행되고 있는 파드에서 extension API server 를 실행하는 것이다. extension API server를 사용해서 클러스터의 리소스를 관리하는 경우 extension API server("extension-apiserver" 라고도 한다)는 일반적으로 하나 이상의 컨트롤러와 쌍을 이룬다. apiserver-builder 라이브러리는 extension API server와 연관된 컨틀로러에 대한 스켈레톤을 제공한다.
응답 레이턴시
Extension-apiserver는 kube-apiserver로 오가는 연결의 레이턴시가 낮아야 한다. kube-apiserver로 부터의 디스커버리 요청은 왕복 레이턴시가 5초 이내여야 한다.
Extension API server가 레이턴시 요구 사항을 달성할 수 없는 경우 이를 충족할 수 있도록 변경하는 것을 고려한다.
다음 내용
- 사용자의 환경에서 Aggregator를 동작시키려면, 애그리게이션 레이어를 설정한다.
- 다음에, 확장 API 서버를 구성해서 애그리게이션 레이어와 연계한다.
- API 레퍼런스에서 API 서비스에 대해 읽어본다.
대안으로, 어떻게 쿠버네티스 API를 커스텀 리소스 데피니션으로 확장하는지를 배워본다.